

Все началось с коллеги, который закинул в локальный чат сообщение, что он сыграл в игру #59 и угадал слово с 33 попыток и одной подсказки. Игра оказалась простая и сложная одновременно: сайт загадал слово и нужно его отгадать. В поле ввода отправляешь слово, а искусственный интеллект на сайте определяет, насколько отправленное слово близко по смыслу к загаданному.
Интересная игра, тренирующая ассоциативное мышление и умение строить связи. Новое слово появляется каждый день, что в некотором смысле выглядит ограничителем. Также игра доступна только на португальском и английском языках. С одной стороны, это дополнительная практика, а с другой — сомнения «а знаю ли я это слово?» смазывают впечатления от игры.
Так я задумался о локализации игры на русский язык. Свою игру «Русо контексто» я разместил на объектном хранилище, которое более устойчиво примет читателей Хабра.
Дисклеймер. Оригинальная игра расположена по адресу contexto.me. В процессе подготовки статьи я узнал о существовании русскоязычной версии guess-word.com. Но эта версия имеет более ограниченную функциональность.
Как работает игра?
У сайта минималистичный интерфейс:
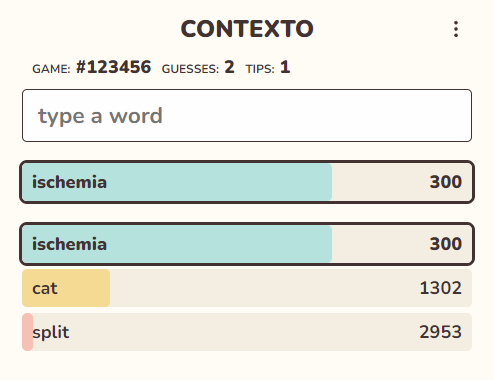
- Сведения об игре: номер, количество попыток и количество подсказок.
- Поле ввода слова.
- Список отгаданных слов в виде полосы загрузки. Чем ближе, тем более она заполнена. Номер справа обозначает расстояние в словах, но его можно отключить.
В выпадающем меню есть настройки и дополнительные игровые опции:
- Выбрать игру.
- Взять подсказку.
- Сдаться.
Если отгадать слово, то игра предложит поделиться результатом и взглянуть на ближайшие 500 слов. Игра очень быстро возвращает ответ и умеет определять начальную форму слова. Иными словами, cat и cats считаются одним словом и выводиятся как cat. Все введенные слова трактуются как существительные, и в списке 500 ближайших слов глагола не встретить.
Это наводит на мысль, что список ближайших слов формируется отдельно, а игра просто обращается к списку. Остается вопрос: как составить список ближайших слов?
Текстовые эмбеддинги
Изначально компьютеры не владеют ни одним человеческим языком. Но человек делает все возможное, чтобы это исправить. Человек может сказать одну команду, используя разные слова и в разном порядке. Машине нужно уметь не просто различать слова, но и понимать смысл, который прячется за этими словами.
Здесь на помощь приходят текстовые эмбеддинги. Если упрощать, то эмбеддинг — это превращение слова в набор чисел, который называют кортежем или вектором. Эти числа задают положение слова в виде точки в пространстве, но не в трехмерном, а в многомерном. Чем ближе две точки, тем ближе слова по смыслу, а компьютеры умеют вычислять.
В рамках данной статьи оставим процесс сопоставления слов векторам в виде черного ящика, которым мы хотим пользоваться, но нам неинтересно, как он работает. Однако если любопытство берет верх, то рекомендую ознакомиться со статьями из секции дополнительного чтения в конце текста.
После операции сопоставления появляется модель — файл, который описывает соответствие «слово — вектор» или как-то описывает правила сопоставления или вычисления. Для работы модели нужно программное обеспечение, которое понимает формат модели.
Проще и быстрее всего «потрогать» эмбеддинги на языке Python. Библиотека gensim реализует один из самых популярных подходов — word2vec. Для работы необходима модель, обученная на достаточном количестве текстов. В документации gensim есть ссылки на англоязычные модели, но нас это не устраивает.
К счастью, проект RusVectores предоставляет модели на русском языке. На сайте представлены контекстуализированные и статические модели. Так как игра принимает на вход одно слово, то нам подходит статическая модель.
Я использовал модель, обученную на Национальном Корпусе Русского Языка (НКРЯ), ее название — ruscorpora_upos_cbow_300_20_2019. Скачиваем архив и распаковываем. Модель представлена в двух видах: бинарном (model.bin) и текстовом (model.txt).
Попробуем воспользоваться этой моделью. Сперва загружаем.
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format("model.txt", binary=False)
Теперь можем найти слова, ближайшие к слову «провайдер»:
>>> model.most_similar(positive=["провайдер"])
…
KeyError: "Key 'провайдер' not present in vocabulary"
К сожалению, такого слова не нашлось. Дело в том, что данная модель принимает слова вместе с меткой, которая определяет часть слова. Это сделано для различия слов с одинаковым написанием. Например, «печь» можно представить как «печь_NOUN» и «печь_VERB», то есть как существительное и глагол соответственно.
>>> model.most_similar(positive=["провайдер_NOUN"])
[
('ip_PROPN', 0.677890419960022),
('internet_PROPN', 0.6627045273780823),
('интернет_PROPN', 0.6595873832702637),
('интернет_NOUN', 0.6567919850349426),
('веб_NOUN', 0.6510902047157288),
('сервер_NOUN', 0.6460723280906677),
('модем_NOUN', 0.6433334946632385),
('трафик_NOUN', 0.6332165002822876),
('безлимитный_ADJ', 0.6230701208114624),
('ритейлер_NOUN', 0.6218529939651489)
]Также возьмем более простой пример с несколькими словами. Зададим два слова: король и женщина. Человек догадается, что женщина-король — это скорее всего королева.
>>> model.most_similar(positive=["король_NOUN", "женщина_NOUN"], topn=1)
[
('королева_NOUN', 0.6674807071685791),
('королева_ADV', 0.6368524432182312),
('принцесса_NOUN', 0.6262999176979065),
('герцог_NOUN', 0.613500714302063),
('герцогиня_NOUN', 0.5999450087547302)
]
Метод most_similar выводит список наиболее похожих слов и некоторую метрику расстояния до этого слова. Чем ближе метрика к единице, тем ближе слово. Список слов отсортирован по убыванию этой метрики. Так как сортировка производится при выводе, то значение метрики далее мы использовать не будем.
Аргумент topn позволяет задать количество слов, которые мы хотим получить. Таким образом можно запросить какое-нибудь большое количество слов и получить список, необходимый для создания игры. Давайте зададим более современное слово «киберпространство» и посмотрим на ближайшее слово и на слово, например, на десятитысячной позиции.
>>> result = model.most_similar(positive=["киберпространство_NOUN"], topn=10000)
>>> result[0]
('виртуальный_ADJ', 0.39892229437828064)
>>> result[9998]
('европбыть_VERB', 0.12139307707548141)
>>> result[9999]
('татуировкий_NOUN', 0.12139236181974411)
>>> model.most_similar(positive=["европа_NOUN"], topn=10)
[
('максимилиан::александрович_PROPN', 0.3658076822757721),
('фамилие_NOUN', 0.36153605580329895),
('санюшка_NOUN', 0.35595449805259705),
('емельян::ильич_PROPN', 0.35401633381843567),
('автостоп_NOUN', 0.35294172167778015),
('юрген_PROPN', 0.3491175174713135),
('чарльз::диккенс_PROPN', 0.3454093337059021),
('когда-тотец_NOUN', 0.3360745906829834),
('городбыть_VERB', 0.3332841098308563),
('владлен_VERB', 0.33179953694343567)
]
Пояснение: Европа — имя собственное, поэтому тег должен быть PROPN.
Нужно очистить словарь от странных слов и оставить только существительные.
Если вам понравится этот текст, у меня есть еще:
→ Подбираем скины в Counter-Strike: Global Offensive в цвет сумочки
→ Делаем тетрис в QR-коде, который работает
→ Делаем радио из Cyberpunk 2077
Обработка словаря
Один из способов хранения модели word2vec — текстовый. Формат прост: в первой строке задаются два числа — количество строк в документе и количество чисел в векторе. Далее на каждой строке задается слово и далее числа, обозначающие вектор.
Здесь удобно воспользоваться особенностью этой модели, а именно тегами. Существительные имеют тег _NOUN, что позволяет убрать из модели ненужные слова. Удалить не существительные легко, но как поступить с опечатками и странными словами? Здесь на помощь приходит другой эмбеддинг, который обучался на литературе.
Это эмбеддинг Navec (навек) из проекта Natasha. Ссылку на русскоязычную модель можно увидеть в репозитории проекта. Скачиваем и загружаем модель:
from navec import Navec
path = 'navec_hudlit_v1_12B_500K_300d_100q.tar'
navec = Navec.load(path)Теперь можно проверять слова простым синтаксисом:
>>> "виртуальный" in navec
True
>>> "европбыть" in navec
False
>>> "татуировкий" in navec
False
Таким образом можно отсеять немалое количество слов, которым в игре не место.
зачатокать
магазей
антитезть
завоевателий
налицотец
прируба
бислой
цвть
громадий
межрайонец
англиканствый
скудетто
выбытий
делаловек
чтобль
кейтеринг
фемтосекунда
углепластик
электромашиностроение
мурмолка
реанимобиль
Алгоритм очистки модели следующий:
- Если у слова тег не NOUN, то отбрасываем это слово.
- Удаляем из слова последовательность _NOUN.
- Проверяем «чистое слово» на наличие в эмбеддинге Navec. Если его там нет, слово отбрасываем.
- Слово, которое прошло все проверки, записываем в файл.
После обработки всех слов в первую строку новой модели записываем два числа: количество оставшихся строк и размерность вектора. Размерность вектора при данной обработке остается неизменной. Если все сделано правильно, то очищенную модель получится загрузить:
model = KeyedVectors.load_word2vec_format("noun_model.txt", binary=False)Стало ли после этого лучше?
>>> result = model.most_similar(positive=["киберпространство"], topn=10000)
>>> result[0]
('виртуальность', 0.4715898633003235)
>>> result[9998]
('компаунд', 0.15783849358558655)
>>> result[9999]
('хитрость', 0.15783214569091797)Определенно. Для статистики: исходная модель содержит 248 978 токенов, из них 59 104 токенов имеют метку существительног. И только 36 269 прошли «сито» второго эмбеддинга.
Время заняться бэкэндом и фронтендом игры.
Умный бэкэнд
Так как Python является моим рабочим языком программирования, бэкэнд я решил реализовать на нем. Поговорим об обработке входных данных. Обрезать пробелы и перевести текст в нижний регистр — само собой разумеющееся. Но как получить начальную форму слова?
Здесь можно воспользоваться инструментом MyStem. Для Python есть обертка pymystem3. Крайне простой инструмент для получения начальной формы слова:
import pymystem3
mystem = pymystem3.Mystem()
Метод lemmatize принимает на вход строку-предложение и возвращает список слов в начальной форме.
>>> mystem.lemmatize("кот коты котов котах кота")
['кот', ' ', 'кот', ' ', 'кот', ' ', 'кот', ' ', 'кот', '\n']
На первый взгляд даже производительность на достойном уровне: на моей виртуальной машине лемматизация одного слова занимает до 10 мс. По меркам современного веба это достаточно быстро.
Пока я работал над бэкэндом, по работе пришлось познакомиться с объектным хранилищем, среди функций которого есть возможность размещения статических сайтов. И тут мне пришла интересная мысль.
Игра на объектном хранилище
При разработке бэкэнда я продумывал способы защититься от нечестной игры:
- Сдаться нельзя.
- Список топ-500 ближайших слов получить можно, только предоставив загаданное слово.
- Подсказку можно получить по слову и позиции.
Но вскоре мне показалось это слишком суровым.
На данный момент единственное назначение бэкэнда — приведение слов к начальной форме. Правда, как показало тестирование на коллегах, и это не обязательно: все и так старались писать начальные формы слов. Да и модель эмбеддингов не лемматизирована, то есть игра понимает слова не только в начальной форме.
Получается, игру можно полностью перенести в браузер?
Так как я бэкэнд-разработчик, то отказ от бэкэнда в угоду фронтэнду — это стресс. Однако от бэкэнда полностью отказаться не получится: генератор близких слов где-то нужно запускать. Генератор принимает на вход загаданное слово и формирует текстовый файл, где на каждой строке по одному слову в порядке смыслового убывания от загаданного. Содержимое этого файла также дублируется в JSON-словарь, где каждому слову соответствует его дистанция от загаданного слова.
JSON-файл на каждую игру занимает до 2 МБ. При открытии игры файл скачивается в браузер и JavaScript реализует логику игры. Этот способ не самый производительный, но после загрузки файла позволяет играть без подключения к интернету.
Я разместил игру в облачном хранилище Selectel, которое более устойчиво к наплыву посетителей.

Заключение
Итоговый результат доступен по адресу words.f1remoon.com, а исходный код — в репозитории.
Дополнительное чтение
Как работают текстовые эмбеддинги?
→ Чудесный мир Word Embeddings: какие они бывают и зачем нужны? (от пользователя madrugado)
→ Word2vec в картинках (от пользователя m1rko)
Комментарии (38)

Kwent
14.12.2022 18:28+2Интересная игра, тренирующая ассоциативное мышление и умение строить связи.
Сперва мы учим машину долго и нудно выстраивать ассоциации, приближенные к человеческим, а потом учимся у той же машины ассоциативному мышлению, выглядит как преподаватель сперва учит студента, а потом просит объяснить предмет ему :)
Скорее это дрессировка на особенности нейросети, философский вопрос полезно ли это.
Так или иначе word2vec это скорее про контекст слов, то есть ближе к синонимам (точнее к словам, которые можно использовать в одном контексте), чем к ассоциациям. Например, ассоциацию тумбочка - тум-тум - африка люди смогут проследить, а эбмеддинги не очень.
Для улучшения могу порекомендовать взять эмбеддинги получше, так как нет привязки "посчитать на лету", можно скачать условные топ 10000 или предпосчитать, word2vec по меркам текущего развития позапрошлый век. Например, та же YaLM 100B яндекса уже с русским из коробки
EgorovM
14.12.2022 21:18Вместо Word2Vec можно использовать GloVe, который заточен под контексное отображение. По ощущениям он справляется лучше Word2Vec, да и голого Bert-а. А вот среднее расстояние между Bert и GloVe дает получше результаты.
Думаю скоро выпустим статью про эти задумки

gennayo
14.12.2022 19:11+3Веселая шизофрения... Без подсказок не решить за вменяемое время.

YMA
14.12.2022 21:50+1Однозначно... Только настоящий шизофреник может угадать вот так:
Моя попытка поиграть


iddqda
14.12.2022 22:27ахаха спсб за ответ. я дошел до слова "раз" и застрял
при этом английскую контексту щелкаю достаточно легко и без подсказок

Mirzapch
15.12.2022 08:58+1Неплохо. Как перезапустить игру, не удаляя Cookies?
Hidden text

minalexpro
15.12.2022 10:51Насколько я понял - загадывается одно слово в день для всех. По ссылке "Игры" можно выбрать другой день и разгадывать слово, загаданное в тот день.

GennPen
14.12.2022 22:00Да даже с подсказками типа "правеж", "недолга" пришлось гуглить что они означают.


EgorovM
14.12.2022 20:59Прикольно!
Занимались тем же самым, запустились правда не в Selectel, но хотим рассмотреть в дальнейшем такую возможность)
https://guess-word.com
SpectrumOS
15.12.2022 10:22+1Сделайте, пожалуйста, кнопку "Сдаться" или "Показать ответ". Я понятия не имею, что тут загадано




iddqda
14.12.2022 22:31немного странно, что ваш ИИ оценивает слова "раз" и "один" настолько по разному

iddqda
14.12.2022 22:35но вообще набор слов вызывает вопросы
кто нибудь в курсе что такое гарнец?

Firemoon Автор
15.12.2022 00:28Отдельной забавы стоит загадать слово, словоформы которого имеют другое значение.
Коллега загадала слово «базили́к» (трава-приправа такая). И по мнению word2vec это слово максимально близко к слову «бази́лика» (эт такой царский дом), что логично, родительный падеж для первого слова пишется так же.
Таким образом в топ-500 слов можно встретить как перечисление приправ, так и перечисление строений. Не повезло тем, кто выбрался в «зеленую» зону на строениях!
bay73
15.12.2022 03:14Гарнец - это четверть ведра. Вполне на месте смотрится в одном ряду с другими числительными и мерами.

Tarakanator
15.12.2022 10:41+1Возможно потому, что раз может применятьсян не только как число, напимер "в самый раз"?



rPman
14.12.2022 23:26Планируете использовать собранный датасет предположений игроков для дальнейшего обучения? статью напишете?
EgorovM
15.12.2022 01:43+1Вот была идея скорректировать вектора ассоциаций по последним 10 попыток людей. У нас где-то 5 миллионов попыток пользователей набралось. Попробуем что-нибудь сами порисовать, потом выложим унифицированные данные в открытый источник:)

minalexpro
15.12.2022 11:17Тема интересная. А как улучшать словарь - добавлять новые слова и удалять ненужные? Как новым словам будет назначаться вектор?

VitalySh
15.12.2022 14:19Ребят, это хардкор - 100 подсказок, 150 попыток. Это просто перебор, вам надо фильтровать редкие слова, глаголы, неправильные формы, иначе это просто упоротая игра

VitalySh
15.12.2022 14:20И да, я до сих пор без понятия, что там за фазис с разлитием прячется на нулевом месте
VitalySh
15.12.2022 14:28

А итоговое слово Течение - и какое же слово к нему ближе? Какой к черту месяц и течение, какое они вообще имеют друг другу отношение. Боже как у меня горит, столько времени убить на угадывание.
Поменяйте свою сетку на openAI, или это игра в рулетку а не угадывание.YMA
15.12.2022 14:46Алгоритм посмотрел, сколько раз упоминается словосочетание "в течение месяца" и разбил предлог "в течение" на составляющие, привязав "течение" к "месяц". А про морские течения пишут куда реже, увы...




janatem
15.12.2022 16:57('королева_ADV', 0.6368524432182312),Теперь мне не дает покоя наречие «королева», пытаюсь придумать, что оно могло бы означать и с какими глаголами употребляться.


combo_breaker
15.12.2022 23:35Просил ChatGPT загадать что угодно и отвечать да/нет на вопросы вроде "это живое?". И наоборот, когда отгадывал он. Понимание позволяет играть как с человеком. Хотя ваша игра сложнее и мозг прогревает лучше.


atepaevm
Спасибо за отличную статью!