

Как DevOps-инженер я часто сталкиваюсь с необходимостью глубокого понимания тонких аспектов Kubernetes. Одним из таких ключевых элементов является управление хранилищем данных. Хотя этот элемент иногда остаётся в тени других задач, его важность для успешного развёртывания и поддержки приложений велика.
Накопленный мною опыт в этой области стал основой для этой статьи.
Я сфокусируюсь на трёх ключевых элементах управления хранилищем в Kubernetes:
- PersistentVolumes (PV).
- PersistentVolumeClaims (PVC).
- Storage Classes.
Эти компоненты играют важную роль не только в выборе подходящих типов хранилищ, но и в их эффективном управлении, особенно в сценариях высокой нагрузки.
Так, при развёртывании масштабируемого веб-приложения, которое обрабатывает большие объёмы пользовательских данных и транзакций, хорошо настроенное управление хранилищем заметно повышает производительность и доступность данных. И тогда при увеличении нагрузки на приложение доступ к данным остаётся быстрым и надёжным, задержки уменьшаются, общее взаимодействие пользователя с приложением улучшается.
Например, у нас была задача обеспечить надёжное и масштабируемое хранение данных в веб-приложении для управления клиентскими заказами. Мы настроили в Kubernetes Storage Class на основе SSD для базы данных (что не является хорошей практикой): это помогло обеспечить быстрый доступ и обработку транзакций. А для логов и нечасто применяемых данных использовали отдельный Storage Class с HDD, и это позволило снизить затраты.
А главное, Storage в Kubernetes — это такая штука, которую ты сделал и забыл, дальше оно там само работает.
Рассказываю детально.
PersistentVolume (PV)
Подсистемы PV представляют собой абстракции реальных хранилищ данных, которые размещаются на физических или виртуальных дисках. PV предоставляют интерфейс для управления жизненным циклом данных независимо от того, на каком уровне инфраструктуры они фактически хранятся (например, NFS, iSCSI, cloudstorage и т. д.).
Путешествие данных: от пода — к PV
Когда вы работаете с подами в Kubernetes, одним из первых вопросов, который приходит в голову, является: «Куда деваются мои данные после завершения пода?»
Именно здесь на сцену выходят PV. Они как бы говорят вашим данным: «Не волнуйтесь, я сохраню вас». Это не просто хранилище — это хранилище, спроектированное так, чтобы выжить в условиях постоянных изменений, характерных для кластеров Kubernetes.
Статическое vs динамическое создание
Создание PV может быть статическим или динамическим, и это одна из его наиболее привлекательных особенностей. В статическом режиме администратор заранее создаёт ряд PV с различными характеристиками. Это как заранее приготовленный шкаф с разными ящиками для хранения. В динамическом режиме PV создаётся «на лету» на основе требований, указанных в PersistentVolumeClaim (PVC). Это как если бы у вас был магический шкаф, который сам создаёт нужный вам ящик, когда вы его запросите.
Жизненный цикл и политики восстановления
Один из наиболее интересных аспектов PV — это его жизненный цикл и политики восстановления. Когда PVC удаляется, что происходит с PV? Он может быть сохранён для будущего использования, может быть полностью удалён или даже «рециклирован» для очистки данных. Это даёт администраторам гибкость в управлении ресурсами и обеспечивает высокую степень контроля над данными.
Affinity узлов: почему это важно?
Affinity узлов в PV позволяет вам уточнить, на каких узлах этот конкретный PV может быть использован. Это особенно полезно в больших и разнородных кластерах, где у разных узлов могут быть разные характеристики хранилища. С помощью аффинности узлов вы можете гарантировать, что ваш PV будет размещён там, где это наиболее эффективно с точки зрения производительности и надёжности.
Схема работы PV
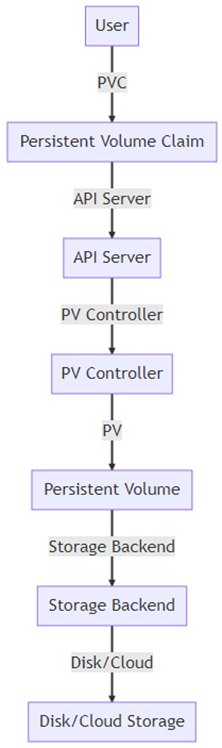
На этой схеме показан процесс работы с PV в Kubernetes:
- User: пользователь или приложение создаёт PVC.
- Persistent Volume Claim (PVC): запрос на выделение PV.
- API Server: обрабатывает запрос и передаёт его PV Controller.
- PV Controller: управляет жизненным циклом PV.
- PersistentVolume (PV): фактическое хранилище.
- Storage Backend: backend, который обеспечивает хранение данных (может быть локальным или облачным).
- Disk/Cloud Storage: физическое хранилище данных.
Примеры
YAML для Persistent Volume:
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-local-pv
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: my-local-sc
hostPath:
path: "/mnt/local-storage"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: "kubernetes.io/hostname"
operator: In
values:
- node1
- node2
В этом примере:
- `name: my-local-pv` — имя Persistent Volume.
- `storage: 10Gi` — размер хранилища в гигабайтах.
- `ReadWriteOnce` — режим доступа, позволяющий чтение и запись только одним пользователем.
- `storageClassName: my-local-sc` — имя Storage Class, к которому привязан этот PV.
- `path: /mnt/local-storage` — локальный путь на узле для хранилища.
- `nodeAffinity` — условия, определяющие, на каких узлах может быть размещён этот PV.
PersistentVolumes в Kubernetes — не просто механизм хранения данных. Это продуманный и гибкий инструмент, который позволяет администраторам и разработчикам сосредоточиться на своей основной работе, не беспокоясь о данных. Они обеспечивают уровень абстракции и управления, который делает работу с хранилищем не только возможной, но и эффективной.
Persistent Volume Claim (PVC) в Kubernetes
PersistentVolumeClaims (PVC) — это как заявки на аренду недвижимости в мире Kubernetes.
Если PersistentVolumes (PV) являются зданиями, готовыми к заселению, то PVC — это ваша анкета, в которой вы указываете, какие условия вам нужны: количество комнат, наличие балкона и так далее.
PVC — это запрос на выделение хранилища из общего пула PV. Когда приложение в кластере нуждается в постоянном хранилище, оно не обращается напрямую к PV. Вместо этого оно создаёт PVC, в котором описывает свои требования к хранилищу. Это абстракция, которая позволяет разработчикам фокусироваться на коде, не задумываясь о деталях инфраструктуры.
Как только PVC создан, Kubernetes начинает поиск подходящего PV. Этот процесс называется «связыванием». Если подходящий PV найден, то он «связывается» с PVC, и приложение может начать использовать этот том для хранения данных. Если подходящего PV нет, то PVC остаётся в состоянии Pending до тех пор, пока не появится соответствующий PV или пока не будет выполнено динамическое выделение хранилища.
Принципы работы PVC:
- Декларативность: PVC создаётся через YAML-файл, который описывает требуемые параметры хранилища, такие, как размер, тип и режимы доступа.
- Динамическое выделение: если в кластере настроены Storage Classes, то PVC может динамически создавать PersistentVolumes (PV) на основе этих классов.
- Привязка к PV: после создания PVC автоматически привязывается к соответствующему PV. Если подходящего PV нет, то PVC остаётся в состоянии Pending до тех пор, пока не будет найден или создан подходящий PV.
- Изоляция ресурсов: PVC обеспечивает изоляцию хранилища между различными приложениями и пользователями, позволяя каждому из них иметь свои собственные требования к хранилищу.
Ключевые концепции
Access Modes
В Kubernetes PersistentVolumeClaim (PVC) предоставляет различные режимы доступа к хранилищу. Эти режимы определяют, как поды могут взаимодействовать с соответствующим
PersistentVolume (PV). Вот подробное описание каждого режима:
- ReadWriteOnce (RWO). Этот режим позволяет одному поду читать и записывать данные на хранилище. Ни один другой под не может подключиться к этому же хранилищу для чтения или записи. Применение: идеально подходит для баз данных, где требуется эксклюзивный доступ к хранилищу для обеспечения целостности данных.
- ReadOnlyMany (ROX). Этот режим позволяет множеству подов подключаться к хранилищу только для чтения данных. Применение: подходит для сценариев, где множество подов должно читать общие данные, например, конфигурации или общие ресурсы.
- ReadWriteMany (RWX). Этот режим позволяет множеству подов читать и записывать данные на одно и то же хранилище. Применение: используется в сценариях, где несколько подов должно иметь возможность читать и записывать данные, например, в системах совместной работы.
Storage Class
Представляет собой способ описания классов хранилища, которые можно использовать для динамического выделения PersistentVolumes (PV) при создании PersistentVolumeClaims (PVC).
Storage Class определяет, какой провайдер хранилища будет использоваться, какие параметры будут применены и другие специфические для провайдера настройки.
Selector
Селекторы в PVC позволяют вам фильтровать и выбирать PersistentVolumes (PV) на основе меток. Это предоставляет дополнительный уровень контроля при привязке PVC к PV, позволяя вам удостовериться, что выбранный том соответствует определённым требованиям или политикам. Селекторы в PVC используют метки, которые были присвоены PV. Когда PVC создаётся с определённым селектором, он будет привязан только к тем PV, которые соответствуют меткам селектора.
Reclaim Policy
Определяет, что произойдёт с PersistentVolume (PV) после удаления соответствующего PersistentVolumeClaim (PVC). Это важный аспект управления жизненным циклом хранилища в Kubernetes.
Виды политик восстановления:
1. Retain (сохранить).
- Что происходит: после удаления PVC соответствующий PV не удаляется. Он остаётся в системе в состоянии Released.
- Применение: этот вариант полезен, если вы хотите вручную управлять данными на томе после удаления PVC.
2. Delete (удалить).
- Что происходит: после удаления PVC соответствующий PV также удаляется.
- Применение: полезно в динамических окружениях, где ресурсы хранилища должны быть освобождены как можно быстрее.
3. Recycle (переработать).
- Что происходит: после удаления PVC данные на PV удаляются, и он может быть автоматически перепривязан к новому PVC.
- Применение: этот метод устарел и обычно заменяется динамическим выделением хранилища.
Вот диаграмма, которая поможет понять ключевые компоненты и взаимодействия, связанные с PersistentVolumeClaim:
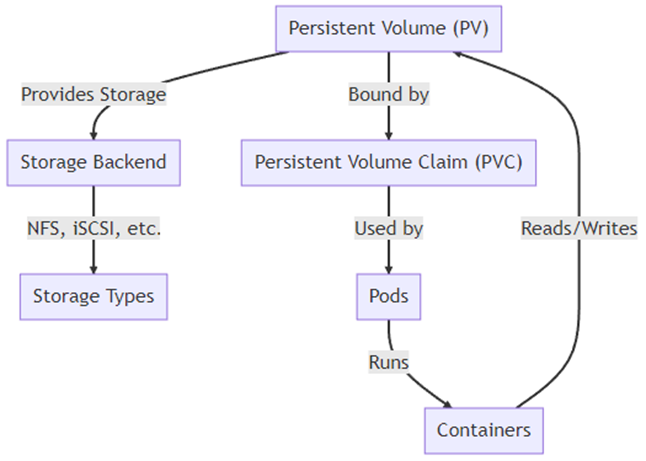
На диаграмме:
- PersistentVolume (PV): представляет собой фактический ресурс хранилища в кластере.
- Storage Backend: фактическая система хранения, где хранятся данные, такие, как NFS, iSCSI и т. д.
- Типы хранилищ: различные типы систем хранения, которые могут быть использованы.
- PersistentVolumeClaim (PVC): запрос на хранилище от пользователя.
- Поды: наименьшие развёртываемые единицы вычислений, которые могут быть созданы и управляемы в Kubernetes.
- Контейнеры: контейнеры, которые работают внутри подов и выполняют фактические вычисления.
Пример YAML для PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: standard
Использование PVC в Pod:
apiVersion: v1
kind: Pod
metadata:
name: "myapp"
namespace: default
labels:
app: "myapp"
spec:
volumes:
- name: my-storage
persistentVolumeClaim:
claimName: my-pvc
containers:
- name: myapp
image: "debian-slim:latest"
volumeMounts:
- name: my-storage
mountPath: "/data"
Управление жизненным циклом:
- Создание: как только PVC создан, Kubernetes автоматически ищет подходящий PV и привязывает его к PVC.
- Использование: поды могут использовать PVC для хранения данных.
- Удаление: при удалении PVC PV может быть либо удалён, либо сохранён (в зависимости от политики).
StorageClass (SC) в Kubernetes
Это нечто вроде каталога аренды жилья, где каждый класс представляет собой набор характеристик и условий для хранилища. Это ключевой элемент, который управляет динамическим выделением хранилища в кластере. Этот механизм описывает различные классы хранилища, которые предлагаются в кластере. Каждый класс имеет свои уникальные характеристики, такие, как тип диска, скорость IOPS и параметры шифрования.
SC определяет, как должны быть созданы PersistentVolumes (PV) при динамическом выделении хранилища на основе PersistentVolumeClaims (PVC). Возможность динамического выделения, когда приложение создаёт PVC и указывает в нём Storage Class, Kubernetes автоматически создаёт PV с нужными характеристиками.
Ключевые аспекты Storage Class:
- Provisioner: определяет, какой провайдер хранилища будет использоваться, например, для AWS это будет `kubernetes.io/aws-ebs`.
- Reclaim Policy: определяет, что произойдёт с PV после того, как PVC будет удалён. Обычно это Retain или Delete.
- Parameters: это дополнительные параметры, которые можно установить для хранилища, например, для AWS EBS это может быть тип диска (`io1`, `gp2` и т. д.).
- VolumeBinding Mode: этот параметр определяет, когда PV будет привязан к PVC. Он может быть либо Immediate, либо WaitForFirstConsumer.
- AllowedTopologies: это ограничения на топологию, в которой могут быть созданы PV.
Пример YAML для Storage Class:
apiVersion: v1
kind: StorageClass
metadata:
name: my-local-sc
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumerВ этом примере:
- `name: my-local-sc` задаёт имя для StorageClass.
- `provisioner: kubernetes.io/no-provisioner` указывает, что хранилище не будет динамически выделяться. Вместо этого будет использоваться уже существующий PersistentVolume.
- `volumeBindingMode: WaitForFirstConsumer` означает, что фактическое привязывание PV к PVC произойдёт, только когда первый клиент (обычно под) будет готов его использовать.
Storage Class особенно полезен в многофункциональных и разнородных кластерах. Например, для базы данных вы можете создать класс с высокопроизводительным SSD, а для архива данных — класс с более дешёвым и медленным хранилищем. Это позволяет оптимизировать затраты и производительность.
Вот диаграмма, которая поможет вам понять ключевые компоненты и взаимодействия, связанные со Storage Class:
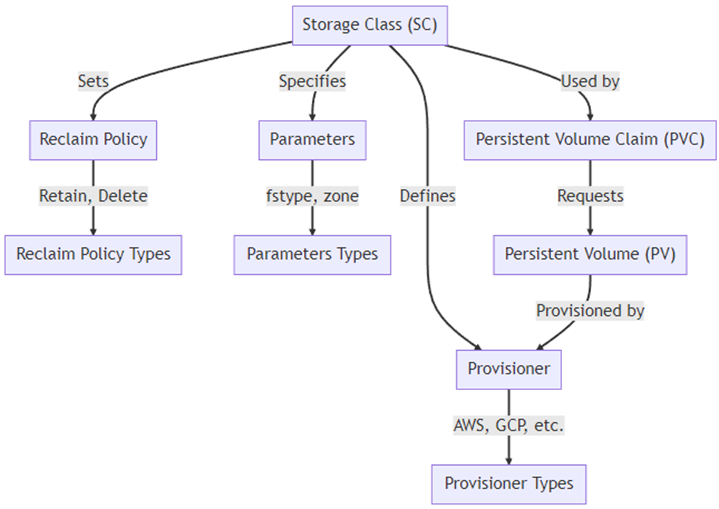
На диаграмме:
- Storage Class (SC): определяет класс хранилища в кластере.
- Provisioner: система, которая будет предоставлять хранилище (например, AWS, GCP и т. д.).
- Reclaim Policy: политика возврата ресурсов (Retain, Delete).
- Parameters: дополнительные параметры для хранилища, такие, как тип файловой системы или зона.
- PersistentVolumeClaim (PVC): запрос на хранилище от пользователя.
- PersistentVolume (PV): фактический ресурс хранилища.
В целом Storage Class в Kubernetes является инструментом, который добавляет дополнительный уровень абстракции и гибкости при работе с хранилищем данных. Он не только упрощает задачи управления, но и открывает новые возможности для оптимизации ресурсов и повышения эффективности. Эта функциональность становится особенно ценной в сложных и динамичных средах, где требования к хранилищу могут быстро меняться.
А теперь давайте копнём чуть глубже и рассмотрим внутренние процессы
VolumeBindingCaching
Описывает определённые оптимизации, которые могут быть внедрены в системе для ускорения процесса привязки между PersistentVolumeClaims (PVC) и PersistentVolumes (PV). Эти оптимизации обычно заключаются в том, чтобы избежать повторных проверок возможности привязки, когда такая информация уже известна или кэширована.
Система привязки в Kubernetes достаточно сложна, и она включает в себя несколько этапов:
- Предварительное утверждение (Pre-binding): PVC может быть явно привязан к PV в момент создания.
- Поиск: когда под со ссылкой на PVC создаётся, система ищет подходящий свободный PV.
- Проверка и одобрение: если такой PV найден, то система проверяет, может ли он быть привязан к данному PVC на основе политик, аннотаций и т. д.
- Привязка: если все проверки прошли успешно, то PV и PVC привязываются, и информация об этом сохраняется в etcd.
- Обновление статуса: после привязки статусы PV и PVC обновляются.
В больших и динамичных кластерах этот процесс может быть дорогостоящим в плане производительности и задержек. Вот тут и могут быть применены различные методы кэширования и оптимизации:
1. Кэширование списка доступных PV: система может кэшировать список PV, которые еще не привязаны, чтобы ускорить поиск.
2. Кэширование атрибутов PV и PVC: атрибуты, такие, как `storageClassName`, `accessModes` и `requests`, которые часто используются при привязке, могут быть кэшированы.
3. Кэширование результатов проверок: результаты выполненных проверок (например, соответствие политикам безопасности) могут быть кэшированы для последующего использования. Тем не менее важно учесть, что кэширование может привести к некоторым проблемам:
- неконсистентности данных: кэшированные данные могут устареть, что приведёт к проблемам с привязкой;
- сложности отладки: непонятное или неожиданное поведение системы будет сложнее отлаживать из-за кэширования;
- накладным расходам на обслуживание кэша: необходимо следить за тем, чтобы кэш был консистентным и актуальным, что может добавить дополнительной сложности.
Для примера давайте предположим, что у вас есть RESTAPI, который управляет привязкой между PV и PVC. Основная идея заключается в том, чтобы использовать кэширование для ускорения этого процесса.
from flask import Flask, request, jsonify
from collections import deque
app = Flask(__name__)
# Кэш для хранения свободных PV
free_pv_cache = deque(maxlen=100)
# Кэш для хранения атрибутов PVC
pvc_attribute_cache = {}
# Список всех доступных PV (обычно это будет храниться в базе данных)
all_pv_list = [
{'name': 'pv1', 'storageClass': 'fast', 'size': 100},
{'name': 'pv2', 'storageClass': 'slow', 'size': 200},
]
@app.route('/bind', methods=['POST'])
def bind():
pvc_data = request.json
pvc_name = pvc_data.get('name')
# Обновление кэша атрибутов PVC
pvc_attribute_cache[pvc_name] = pvc_data.get('attributes', {})
# Использование кэша для ускорения поиска
for pv in list(free_pv_cache):
if is_suitable(pv, pvc_data):
free_pv_cache.remove(pv)
return jsonify({"status": "bound", "pv": pv}), 200
# Если подходящий PV не найден в кэше, выполнить обычный поиск
for pv in all_pv_list:
if is_suitable(pv, pvc_data):
return jsonify({"status": "bound", "pv": pv}), 200
return jsonify({"status": "not found"}), 404
@app.route('/add_pv', methods=['POST'])
def add_pv():
pv_data = request.json
free_pv_cache.append(pv_data)
return jsonify({"status": "added", "pv": pv_data}), 201
def is_suitable(pv, pvc):
# Использование кэшированных атрибутов PVC для ускорения проверки
pvc_attributes = pvc_attribute_cache.get(pvc.get('name'), {})
# Пример проверки совместимости
if pv.get('storageClass') != pvc_attributes.get('storageClass'):
return False
if pv.get('size') < pvc_attributes.get('size', 0):
return False
return True
if __name__ == '__main__':
app.run(debug=True)
Компоненты программы:
1. Кэш свободных PV (`free_pv_cache`): это кэш, который хранит информацию о свободных (непривязанных) PV. Он реализован как очередь с ограниченным размером, чтобы избежать переполнения.
2. Кэш атрибутов PVC (`pvc_attribute_cache`): этот кэш хранит атрибуты PVC, которые часто используются при привязке, такие, как `storageClassName`, `accessModes` и `requests`.
3. API-методы:
- `/bind`: этот метод принимает данные PVC в формате JSON и пытается найти подходящий PV, сначала — в кэше, а затем — в полном списке PV;
- `/add_pv`: этот метод позволяет добавить новый PV в кэш свободных PV.
4. Функция `is_suitable`: эта функция проверяет, подходит ли данный PV для данного PVC на основе их атрибутов.
Принцип работы программы:
- Приём PVC через API: когда приходит запрос на привязку PVC, метод `/bind` сначала обновляет кэш атрибутов PVC.
- Поиск в кэше: программа сначала проверяет, есть ли подходящий PV в кэше `free_pv_cache`. Если находит, то удаляет его из кэша и возвращает как привязанный.
- Обычный поиск: если подходящий PV не найден в кэше, то программа переходит к обычному поиску в полном списке PV (`all_pv_list`).
- Добавление PV: метод `/add_pv` позволяет добавить новый PV в кэш, чтобы ускорить будущие операции привязки.
- Проверка совместимости: всё это подкрепляется функцией `is_suitable`, которая определяет, подходит ли PV для данного PVC.
I/OOperations
Ввод-вывод (I/O) — одна из ключевых характеристик производительности в любой системе хранения данных. В контексте Kubernetes и PersistentVolumes (PV) I/O-операции играют важную роль в общей эффективности и отзывчивости приложений. Здесь стоит рассмотреть несколько ключевых аспектов:
Типы I/O-операций:
- Случайный (Random) и последовательный (Sequential) доступы: в зависимости от характера вашего приложения может потребоваться разный тип доступа к данным. Случайный доступ хорошо подходит для баз данных, тогда как последовательный — для потоковой передачи данных.
- Read- и Write-операции: чтение и запись — две стороны одной медали. Некоторые системы хранения оптимизированы для чтения, другие — для записи.
Влияние на производительность:
- Latency (задержка): время, которое требуется для выполнения отдельной операции I/O. Сетевые хранилища, такие, как NFS или cloud-basedvolumes, могут иметь высокую задержку.
- Throughput (пропускная способность): общее количество данных, которое можно передать в единицу времени. Этот параметр зависит от множества факторов, включая тип хранилища и его конфигурацию.
- IOPS (I/O-операции в секунду): метрика, которая часто используется для измерения производительности хранилища.
Оптимизация:
- Тюнинг параметров файловой системы: в зависимости от вашего хранилища различные параметры монтирования могут повлиять на производительность I/O.
- Read-ahead- и Write-back-кэширование: эти методы можно использовать для улучшения производительности I/O, но они могут добавить сложности, такие, как риск потери данных при сбое.
- QoSPolicies (политики качества обслуживания): ограничение IOPS или пропускной способности для определённых приложений.
Проблемы и решения:
- Bottlenecks («узкие места»): если несколько подов сильно зависят от I/O, то это может создать «узкое место». Решение — грамотное планирование и, возможно, использование более производительных хранилищ.
- Consistency (консистентность): в распределённых системах, таких, как Kubernetes, консистентность I/O может быть вызовом. Некоторые системы хранения предлагают строгую или слабую консистентность, и это выбор, который влияет на I/O.
- Resource Contention (конкуренция за ресурсы): несколько подов, обращающихся к одному и тому же PV, могут влиять на производительность друг друга.
Расширенные сценарии использования
Multi-AttachVolumes
Это типы PersistentVolumes (PV), которые позволяют нескольким подам одновременно подключаться к одному и тому же тому хранения данных. Это полезно в случаях, когда несколько инстансов приложения должно иметь доступ к общим данным. Такие сценарии часто встречаются в распределённых базах данных, системах кэширования и других приложениях, которые требуют высокой доступности и отказоустойчивости.
Технические особенности:
- ReadWriteMany (RWX) Access Mode: этот режим доступа позволяет нескольким подам читать и писать на одном томе одновременно.
- Storage Backend: не все системы хранения поддерживают множественное подключение. Например, Amazon EBS не поддерживает эту функцию, в то время как NFS, Ceph и некоторые другие распределённые файловые системы поддерживают.
- Coordination: важно координировать I/O-операции между различными подами для избегания условий гонки или несогласованности данных.
Проблемы и решения:
- Data Consistency: одна из наибольших проблем с Multi-AttachVolumes — это обеспечение консистентности данных. Решение этой проблемы может заключаться в использовании распределённых систем с транзакционной поддержкой или во внедрении блокировок на уровне приложения.
- Performance Overhead: множественное подключение может привести к дополнительной нагрузке на систему хранения и уменьшить общую производительность. Важно мониторить и, возможно, ограничивать I/O-операции для подов.
- ErrorHandling: если один из подов, подключённых к тому, сталкивается с ошибкой, то это может повлиять на все другие поды. Некоторые распределённые системы хранения предлагают функции для изоляции ошибок.
Допустим, что у нас есть приложение для обработки изображений, которое использует общий том для хранения изображений. Этот том должен быть доступен для нескольких подов, которые обрабатывают изображения параллельно.
Давайте рассмотрим схему:
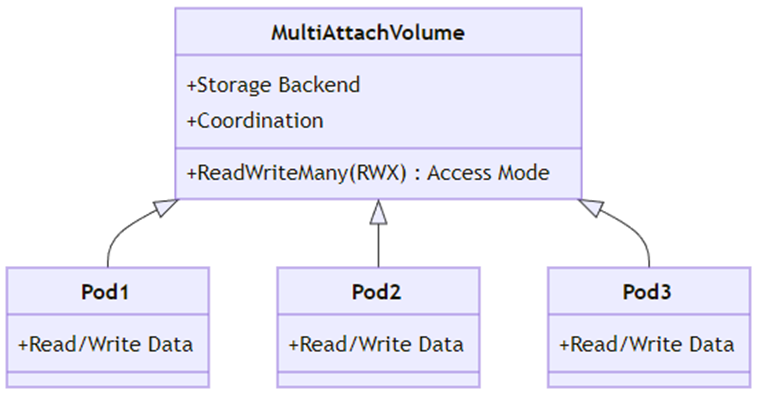
MultiAttachVolume — это класс, представляющий Multi-Attach Volume. У него есть следующие атрибуты:
1. ReadWriteMany (RWX) Access Mode: режим доступа, который позволяет нескольким подам читать и писать на одном томе одновременно.
2. Storage Backend: система хранения данных, которая поддерживает множественное подключение (например, NFS, Ceph).
3. Coordination: механизмы координации для управления I/O-операциями между различными подами.
4. Pod1, Pod2, Pod3: это классы, представляющие различные поды, которые подключены к Multi-AttachVolume. У каждого из них есть атрибут:
- Read/Write Data: поды могут читать и записывать данные на общий том;
- связи: MultiAttachVolume связан с каждым из подов (Pod1, Pod2, Pod3). Это указывает на то, что каждый из этих подов может одновременно подключаться к MultiAttachVolume для чтения и записи данных.
А вот пример YAML-конфигурации:
apiVersion: v1
kind: PersistentVolume
metadata:
name: image-storage
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
nfs:
path: /mnt/data
server: nfs-server.example.com
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: image-storage-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: Pod
metadata:
name: image-processor-1
spec:
volumes:
- name: image-storage
persistentVolumeClaim:
claimName: image-storage-pvc
containers:
- name: image-processor
image: image-processor:latest
volumeMounts:
- mountPath: /app/images
name: image-storage
---
apiVersion: v1
kind: Pod
metadata:
name: image-processor-2
spec:
volumes:
-name: image-storage
persistentVolumeClaim:
claimName: image-storage-pvc
containers:
-name: image-processor
image: image-processor:latest
volumeMounts:
-mountPath: /app/images
name: image-storage
PersistentVolume (PV): создаём PV с режимом доступа ReadWriteMany и указываем NFS-сервер.
PersistentVolumeClaim (PVC): создаём PVC, который будет использовать этот PV.
Pods: создаём два пода (image-processor-1 и image-processor-2), которые будут использовать этот общий том для чтения и записи изображений.
Теперь оба пода могут читать и записывать данные в общий том, что делает этот пример интересным и легко читаемым.
Data Gravity
Это концепция, которая описывает тенденцию больших наборов данных «притягивать» к себе различные приложения, сервисы и даже другие данные. Этот термин был введён Дэвидом Маккрори (Dave McCrory), и он описывает феномен, с которым сталкиваются многие организации в эпоху больших данных и облачных вычислений.
Технические аспекты:
- Производительность и латентность. Когда данные и приложения расположены близко друг к другу, время отклика и производительность обычно улучшаются. Это особенно важно для задач, требующих высокой пропускной способности и низкой латентности, таких, как аналитика больших данных или потоковая обработка данных.
- Стоимость передачи данных. Перемещение больших объёмов данных между различными облачными провайдерами или дата-центрами может быть дорогостоящим и занимать значительное время.
- Комплексность управления. С увеличением объёма данных растёт и сложность их управления. Это включает в себя резервное копирование, шифрование, репликацию и соблюдение нормативных требований.
Проблемы и решения:
- Проблемы масштабирования. С увеличением объёма данных растут требования к хранению и обработке. Решение может заключаться в применении распределённых систем хранения и обработки, таких, как Hadoop для аналитики или Kubernetes для оркестрации контейнеров.
- Зависимость от провайдера. Data Gravity может привести к локализации данных в определённом облачном сервисе, что создаёт проблемы с переносимостью и зависимостью от одного провайдера. Многие компании решают эту проблему, используя гибридные или многооблачные архитектуры.
- Безопасность и соблюдение нормативных требований. Большие наборы данных часто содержат конфиденциальную или регулируемую информацию. Это создаёт дополнительные сложности для управления безопасностью и соответствием стандартам.
Рассмотрим пример Data Gravity: «Большая Библиотека». Представьте, что у нас есть большая библиотека, которая хранит огромное количество книг, журналов и статей.
Эта библиотека привлекает различные группы людей:
- Читатели: ищут книги для чтения и развлечения.
- Исследователи: нуждаются в редких и научных материалах.
- Писатели: ищут информацию и источники для своих новых книг.
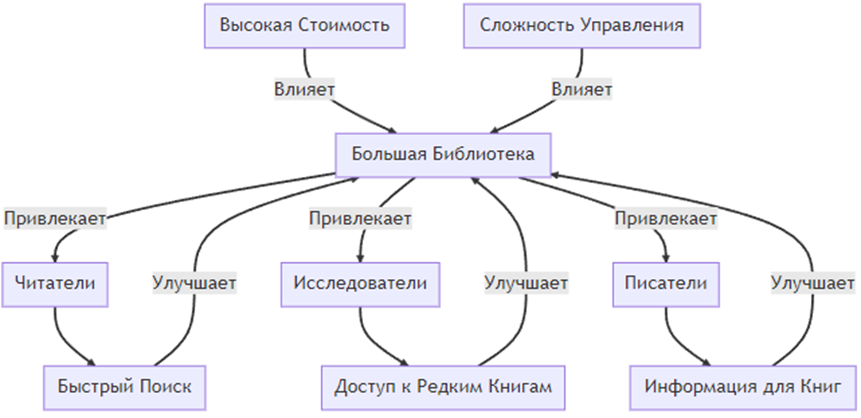
Проблемы и решения:
- Высокая стоимость. Поддержание такой большой библиотеки требует значительных финансовых затрат.
- Сложность управления. Управление таким количеством материалов может быть сложным и требовать специализированного ПО.
Таким образом, «Большая Библиотека» становится центром притяжения не только для книг, но и для различных групп людей, которые взаимодействуют с этими данными.
Неконсистентный доступ
Это ситуация, при которой разные клиенты или компоненты системы могут видеть различные версии одних и тех же данных в разное время. Это может происходить из-за различных факторов, включая кэширование, асинхронную репликацию, недостаточную синхронизацию и другие.
Технические аспекты:
- EventualConsistency. В некоторых системах, особенно распределённых, может быть использована модель eventualconsistency, где система стремится сделать данные консистентными в конечном итоге, но это не гарантировано в каждый момент времени.
- Read-After-WriteInconsistency. Это сценарий, в котором после записи нового значения некий клиент может всё ещё видеть старое значение из-за кэширования или задержек в репликации.
- Stale Data. Данные могут устареть, если изменения, внесённые одним клиентом, не сразу становятся видны другим клиентам.
Проблемы и решения:
- Race Conditions. Неконсистентный доступ может привести к условиям гонки, когда несколько операций конфликтует друг с другом. Решение может заключаться в использовании механизмов блокировки или транзакций.
- Data Corruption. В случае отсутствия адекватных механизмов синхронизации есть риск повреждения данных. Решение может включать в себя использование ACID-транзакций или других механизмов для обеспечения консистентности.
- Complexity. Поддержание консистентности в распределённой системе может добавить сложности в виде синхронизации, блокировок и т. д. В некоторых случаях системы могут принять решение работать в режиме eventualconsistency для уменьшения сложности, принимая на себя недостатки этого подхода.
Оптимизация
Capacity Planning
Это процесс оценки и определения технических ресурсов (например, вычислительных мощностей, хранилища, сетевых ресурсов), необходимых для обеспечения удовлетворительного уровня производительности и доступности приложения или системы.
Технические аспекты:
- Базовая линия. Определение текущего уровня потребления ресурсов и производительности системы. Это часто делается с использованием инструментов мониторинга и сбора метрик.
- Прогнозирование. Анализ трендов использования ресурсов и оценка будущих потребностей на основе бизнес-планов, планируемых масштабов и т. д.
- Буферы и избыточность. Разработка стратегий для работы с пиковыми нагрузками и отказами в системе.
Pre-WarmingVolumes
Это процесс первоначального «прогрева» блочных хранилищ или файловых систем перед их активным использованием. Этот процесс особенно актуален в облачных средах, где динамические ресурсы могут быть не полностью «горячими» прямо изначально.
Технические аспекты:
- LazyLoading. Облачные провайдеры, как правило, используют технику lazyloading для динамических ресурсов. Это означает, что реальное физическое выделение места и I/O-производительность могут быть ниже ожиданий в начальный период использования.
- Block Initialization. Процесс pre-warming часто включает в себя чтение или запись по всем блокам тома, чтобы инициализировать их и достичь максимальной производительности.
Storage Quality of Service (QoS)
Это механизм, позволяющий управлять и оптимизировать производительность и доступность хранилища данных. Это особенно актуально в средах с общим использованием ресурсов, где одно приложение или процесс может негативно влиять на другие.
Технические аспекты:
- IOPS (Input/Output Operations Per Second). Один из ключевых показателей, который можно контролировать через QoS, — это IOPS. Это количество операций ввода/вывода, которые система хранения может выполнить в секунду.
- Throttling. Ограничение пропускной способности или IOPS для определённых рабочих нагрузок для предотвращения перегрузки системы.
- Prioritization. Настройка приоритетов для различных рабочих нагрузок, чтобы критические приложения всегда имели доступ к нужным ресурсам.
- Bursting. Возможность временно увеличивать пропускную способность или IOPS для обработки пиковой нагрузки.
Латентные (latency) проблемы
Data Corruption
Это искажение или потеря данных, которые могут произойти из-за различных причин, таких, как аппаратные сбои, программные ошибки или человеческие факторы. Подобные проблемы могут проявляться на разных уровнях — от отдельных файлов до целых баз данных или хранилищ.
Технические аспекты:
- BitRot. Физическое искажение данных на диске, которое может произойти со временем.
- ChecksumMismatches. Проверка целостности данных может обнаружить искажение, но если механизмы проверки также повреждены, это может привести к большим проблемам.
- Software Bugs. Ошибки в программном обеспечении, работающем с данными, могут привести к их повреждению.
- ConcurrentWrites. В многопользовательских системах конкурентный доступ к данным может вызвать их повреждение, если не управляется должным образом.
Разногласия с Scheduler
Иногда планировщик Kubernetes может сделать неоптимальные решения при размещении подов, которые зависят от PV, особенно если различные PV имеют разные характеристики производительности или стоимости.
Технические аспекты:
- Неоднородность хранилищ. PV могут поддерживаться различными видами хранилищ с разными характеристиками, такими, как IOPS, latency и стоимость. Планировщик может не всегда принимать это во внимание, что приводит к неоптимальному размещению.
- Зависимости между подами и PV. Некоторые поды могут иметь жёсткие зависимости от определённых PV. Если эти PV привязаны к определённым узлам, то это может ограничить выбор планировщика и даже привести к его неспособности найти подходящий узел.
- Конфликт политик. Правила ограничения и предпочтения (affinity/anti-affinity, taints/tolerations) могут конфликтовать с оптимальным размещением, основанным на характеристиках PV.
Суммируя
В начале пути управление хранилищами данных в Kubernetes может казаться сложным.
Однако, освоив ключевые элементы, такие, как PersistentVolume, PersistentVolumeClaim и Storage Class, и уловив их взаимосвязь, вы обнаружите, что задачи становятся более простыми.
Я надеюсь, что эта статья не только поможет вам разобраться с основными принципами работы с хранилищами в Kubernetes, но и повысит эффективность и понятность вашей работы с этой платформой.
DimaSmirnov
Я понимаю, что сейчас отхвачу тонны хейта, но напишу. Последнее время мы читаем на хабре примеры конфигов, а смотрите как я смог ... ну что это?
Безумно раздражает отсутствие у людей понимание что под капотом. Эти хайпы на управляторы докера типа кубера и прочее.
Почему все пацаны, знающие ядро, как свои пять пальцев не пишут как нормально тюнить sysctl? Почему ушли люди, которые писали ipv4 стек, а именно русские его писали в ядро.
Извините - накипело. Психанул. Простите ещё раз.
pan_diakivnich
А потому, что в своё время начали платить больше не за тюнь sysctl, а за раскатку кубов, обмазку сиаем и красивыми дашбордиками, да ещё и понятными бизнесу.
Причём платить больше денег стал именно бизнес, соответственно ему в угоду и лепится это всё.
Я далеко за примером не пойду - сам могу укатить приложение из докера в кубы, но в компилирование ядра не полезу ни в жизнь.
Сильные штуки, порождённые сильными программистами, привели к вырождению этих программистов и скоро нас ждут тяжёлые времена, пока жипитя не раздуплится.
А как раздуплится - такие как я явно будут не нужны.
Пойду учить базу на старом Хабре.