

Заинтересовавшись вопросом скорости работы операций упаковки и распаковки в .NET решил опубликовать свои небольшие и крайне субъективные наблюдения и измерения по этой теме.
Код примера доступен на github, поэтому приглашаю всех желающих сообщить о своих результатах измерений в комментариях.
Теория
Операция упаковки boxing характеризуется выделением памяти в управляемой куче (managed heap) под объект value type и дальнейшее присваивание указателя на этот участок памяти переменной в стеке.
Распаковка unboxing, напротив, выделяет память в стеке выполнения под объект, полученный из управляемой кучи с помощью указателя.
Казалось бы, в обоих случаях выделяется память и особой разницы быть не должно, если бы не одно но- крайне важной деталью является область памяти.
Вспоминая про то, что за выделение памяти в .NET в управляемой куче отвечает сборщик мусора (Garbage Collector) важно отметить, что делает он это нелинейно, ввиду возможной её фрагментации (наличия свободных участков памяти) и поиска необходимого свободного участка требуемого размера.
Update:
Как заметил blanabrother в комментариях, при выделении памяти/копировании значения в managed heap отсутствует процесс поиска свободного участка памяти и её возможная фрагментация ввиду инкриминирующегося указателя и дальнейшей её компактификации с использованием GC. Однако, опираясь на следующие измерения скорости выделения памяти в C++ посмею предположить, что область (тип) памяти является основной причиной такой разницы в производительности.
В случае же с распаковкой, память выделяется в стеке выполнения, который содержит указатель на свой конец, по совместительству являющийся началом участка памяти под новый объект.
Вывод из этого я делаю такой, что процесс упаковки должен занимать значительно больше времени, чем распаковки, ввиду возможных side effects связанных с GC и медленной скоростью выделения памяти/копирования значения в managed heap.
Практика
Для проверки этого утверждения я набросал 4 небольшие функции: 2 для boxing и 2 для unboxing типов int и struct.
public class BoxingUnboxingBenchmark {
private long LoopCount = 1000000;
private object BoxedInt = 1;
private object BoxedStruct = new ExampleStruct {
Amount = 1000,
Currency = "RUB"
};
[Benchmark]
public object BoxingInt() {
int unboxed = 1000;
for (var i = 0; i < LoopCount; i++) {
BoxedInt = (object) unboxed;
}
return BoxedInt;
}
[Benchmark]
public int UnboxingInt() {
int unboxed = 1000;
for (var i = 0; i < LoopCount; i++) {
unboxed = (int)BoxedInt;
}
return unboxed;
}
[Benchmark]
public object BoxingStruct() {
ExampleStruct unboxed = new ExampleStruct()
{
Amount = 1000,
Currency = "RUB"
};
for (var i = 0; i < LoopCount; i++) {
BoxedStruct = (object) unboxed;
}
return BoxedStruct;
}
[Benchmark]
public ExampleStruct UnBoxingStruct() {
ExampleStruct unboxed = new ExampleStruct();
for (var i = 0; i < LoopCount; i++) {
unboxed = (ExampleStruct) BoxedStruct;
}
return unboxed;
}
}Для замера производительности была использована библиотека BenchmarkDotNet в режиме Release (буду рад если DreamWalker подскажет, каким образом сделать данные замеры более объективными). Далее представлен результат измерений:
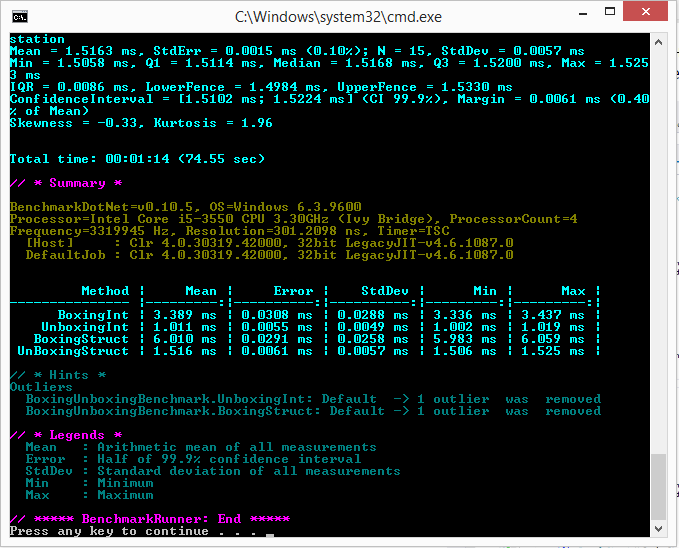
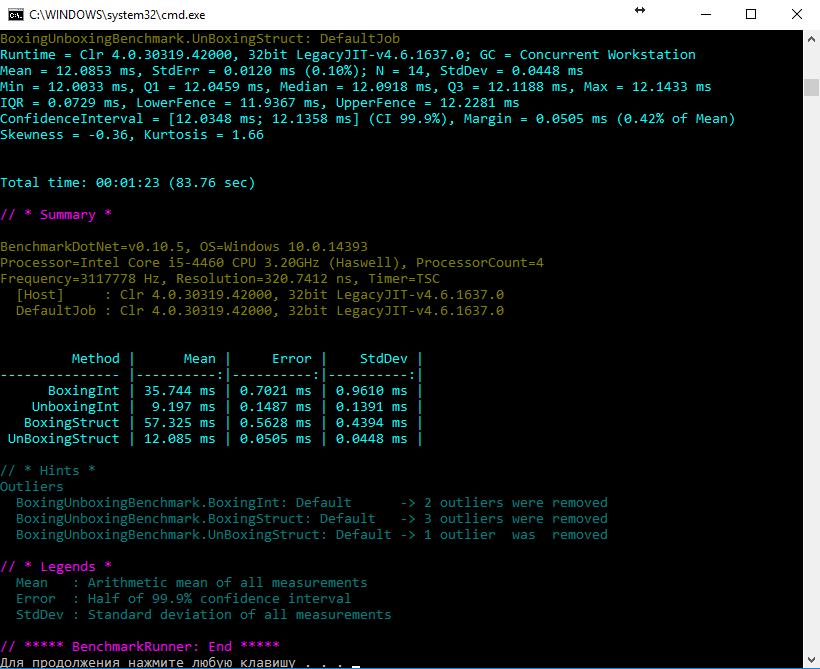
Сразу оговорюсь, что не могу быть твёрдо уверен в отсутствии оптимизаций компилятором итогового кода, однако, судя по IL коду, каждая из функций содержит проверяемую операцию в единственном числе.
Измерения проводились на нескольких машинах с разным кол-вом LoopCount, однако, скорость распаковки из раза в раз превосходила упаковку в 3-8 раз.
.method public hidebysig instance object
BoxingInt() cil managed
{
.custom instance void [BenchmarkDotNet.Core]BenchmarkDotNet.Attributes.BenchmarkAttribute::.ctor() = ( 01 00 00 00 )
// Code size 43 (0x2b)
.maxstack 2
.locals init ([0] int32 unboxed,
[1] int32 i)
IL_0000: ldc.i4 0x3e8
IL_0005: stloc.0
IL_0006: ldc.i4.0
IL_0007: stloc.1
IL_0008: br.s IL_001a
IL_000a: ldarg.0
IL_000b: ldloc.0
IL_000c: box [mscorlib]System.Int32
IL_0011: stfld object ConsoleApp1.BoxingUnboxingBenchmark::BoxedInt
IL_0016: ldloc.1
IL_0017: ldc.i4.1
IL_0018: add
IL_0019: stloc.1
IL_001a: ldloc.1
IL_001b: conv.i8
IL_001c: ldarg.0
IL_001d: ldfld int64 ConsoleApp1.BoxingUnboxingBenchmark::LoopCount
IL_0022: blt.s IL_000a
IL_0024: ldarg.0
IL_0025: ldfld object ConsoleApp1.BoxingUnboxingBenchmark::BoxedInt
IL_002a: ret
} // end of method BoxingUnboxingBenchmark::BoxingInt
.method public hidebysig instance valuetype ConsoleApp1.ExampleStruct
UnBoxingStruct() cil managed
{
.custom instance void [BenchmarkDotNet.Core]BenchmarkDotNet.Attributes.BenchmarkAttribute::.ctor() = ( 01 00 00 00 )
// Code size 40 (0x28)
.maxstack 2
.locals init ([0] valuetype ConsoleApp1.ExampleStruct unboxed,
[1] int32 i)
IL_0000: ldloca.s unboxed
IL_0002: initobj ConsoleApp1.ExampleStruct
IL_0008: ldc.i4.0
IL_0009: stloc.1
IL_000a: br.s IL_001c
IL_000c: ldarg.0
IL_000d: ldfld object ConsoleApp1.BoxingUnboxingBenchmark::BoxedStruct
IL_0012: unbox.any ConsoleApp1.ExampleStruct
IL_0017: stloc.0
IL_0018: ldloc.1
IL_0019: ldc.i4.1
IL_001a: add
IL_001b: stloc.1
IL_001c: ldloc.1
IL_001d: conv.i8
IL_001e: ldarg.0
IL_001f: ldfld int64 ConsoleApp1.BoxingUnboxingBenchmark::LoopCount
IL_0024: blt.s IL_000c
IL_0026: ldloc.0
IL_0027: ret
} // end of method BoxingUnboxingBenchmark::UnBoxingStructКомментарии (41)

blanabrother
05.05.2017 12:51+2Вспоминая про то, что за выделение памяти в .NET в управляемой куче отвечает сборщик мусора (Garbage Collector) важно отметить, что делает он это нелинейно, ввиду возможной её фрагментации (наличия свободных участков памяти) и поиска необходимого свободного участка требуемого размера.
Возможно ошибаюсь, но выделение памяти как раз работает очень быстро. Вомжно быстрее, чем в С/С++. В С/С++ действительно ОС должна выделять свободные страницы и искать повсюду (опустим оптимизации). В случае с CLR, память выделяется большими сегментами (одна затратная операция из того же С/С++ — VirtualAlloc), но затем CLR хранит указатель (Next Object) на следующий свободный кусок и никогда не возвращается к пробелам, а быстро выдает нужный кусок, если он в сегменте остался, иначе снова выделяет большой сегмент. После выделения под инстанс указатель смещается и все, никаких возвратов. Это описано в Under the Hood of .NET Memory Management
А фрагментация — проблема для LOH, т.к. копировать большие объекты при компактификации затратно. В случае же с SOH — есть компактификация, т.е. после того как сегмент обрабатывается GC, он ничего не делает с фрагментацией, он просто копирует выжившие объекты друг за другом. Но в целом трудно себе представить структуру (value type), которая поедет в боксинг, и вряд ли это проблема для структур.
fsou11
05.05.2017 13:12Похоже вы действительно правы касаемо инкриминирующего указателя в куче, работающему аналогично стеку и отсутствия такого понятия, как возврат к пробелам в фрагментированной памяти.
Я представлял себе ситуацию, когда у нас выделяется память под массив фикс. размера (например List), который затем выходит за границы, следствием чего, вероятно, является выделение нового участка памяти его копирование + очистка старого. Судя по всему, изначальный участок памяти не будет повторно переиспользован до компактификации.
Спасибо за исправления.

Ximik87
05.05.2017 13:42+1У рихтера написано абсолютно тоже самое… упаковка медленее, чем распаковка… в чем смысл статьи? проверить не врет ли он? =)))
fsou11
05.05.2017 13:44Всё верно. Проверить утверждение самому и предложить поделиться своими результатами читателей для оценки различий в зависимости от окружения, на котором данные benchmark'и запускаются.

imanushin
07.05.2017 14:40А вот тут я полностью на стороне fsou11.
При разработке не так сильно важна теория, как практика.
По этой статье можно уже оценивать, насколько код будет работать быстрее/медленнее после оптимизаций. А по Рихтеру — нет.
И плюс есть нормальный открытый код на GitHub, так что если будет вопрос, как всё заведется на другом процессоре — я смогу проверить и оценить. А по книге — нет.
ggrnd0
07.05.2017 15:33Да… Только тут сравнивается скорость боксинга и анбоксинга.
Вот прочитал я статью, и что я буду делать?
Переписывать код так, что бы вместо боксинга использовать анбоксинг? Ведь он быстрее!
Я не вижу ни малейшего смысла в статье...imanushin
07.05.2017 19:19+1Нет, не будешь. Пока всё быстро работает — нет смысла, даже глупо как-то.
Зато если вдруг в задаче станет вопрос: что лучше — больше боксинга или же анбоксинга (и при условии, что это не преждевременная оптимизация), то тут статья поможет.
Я вот прочитал статью и понял, что:
- Есть еще один пример использования BanchmarkDotNet от DreamWalker
- Если потребуется ответ на вопрос, заданный в начале статьи, я её найду в интернете, возьму код и проверю на заданном процессоре
ggrnd0
07.05.2017 21:47Зато если вдруг в задаче станет вопрос: что лучше — больше боксинга или же анбоксинга (и при условии, что это не преждевременная оптимизация), то тут статья поможет.
Оу, обязательно сообщите мне когда у вас такая задача действительно появится =)
Ну серьезно, вы еще не поняли в чем подвох?imanushin
08.05.2017 16:50+1Нет, не понял. Я прямо пишу свои аргументы, а не скрываюсь за мнимой мудростью.
Я написал, почему я считаю, что наличие этой статьи на хабре лучше, чем отсутствие. А какие твои аргументы?
ggrnd0
08.05.2017 18:27Я написал, почему я считаю, что наличие этой статьи на хабре лучше, чем отсутствие.
Нет, вы ничего не написали… сплошная вода...
А какие твои аргументы?
Ну, как… как вы себе представляете замену боксинга на анбоксинг?
Обычно стараются вообще не использовать boxing/unboxing.
А вот замену боксинга на анбоксинг я даже представить не могу...
Deosis
11.05.2017 07:24Наиболее вероятное использование:
Распаковать структуру, поработать с ней, упаковать обратно при необходимости.
Используется в тех же фреймворках.
При этом MC++ умеет работать с упакованной структурой напрямую без копирования на стек в отличие от C#, что положительно сказывается на скорости.

BloodUnit
05.05.2017 15:05+1Для проверки этого утверждения я набросал 4 небольшие функции: 2 для boxing и 2 для unboxing типов int и struct.
int, внезапно, это тоже struct. Смысл тестировать с еще одной структурой?
Для замера производительности была использована библиотека BenchmarkDotNet в режиме Release (буду рад если DreamWalker подскажет, каким образом сделать данные замеры более объективными).
Я не DreamWalker, но вот http://benchmarkdotnet.org/RulesOfBenchmarking.htm
fsou11
05.05.2017 15:15int, внезапно, это тоже struct. Смысл тестировать с еще одной структурой?
Это действительно оказалось внезапным, однако хоть int и является структурой, он не является user defined struct.
Я не DreamWalker, но вот http://benchmarkdotnet.org/RulesOfBenchmarking.htm
Все эти рекомендации были учтены в момент измерения.
Меня интересует скорее проблема того, что в методах присутствует начальная инициализация, которую я старался нивелировать за счёт большего кол-ва прогонов внутри метода. Связано это с тем, что библиотека не позволяет использовать в benchmark'ах методы, которые имеют аргументы (а следовательно, начальную инициализацию value type'ов, к примеру, вынести не получается).ggrnd0
05.05.2017 15:36+1Тестирование с структурой имело бы смысл, если структура была размеров от 100 байт, что сильно отличало бы ее от int размером в 4 байта.

MRomaV
06.05.2017 00:26-1Boxing и unboxing — что быстрее? Рихтер ответил на этот вопрос еще несколько лет назад! Рекомендую почитать CLR via C# прежде чем выдумывать свой велосипед. Я извиняюсь но ваша статья ни о чем
GreenStore
06.05.2017 08:51+1Что бы понять, что быстрее, Рихтер не нужен. Нужно просто понимание сложности алгоритмов в одном и другом случае.
AnnunakiOrdnanceVendor
13.05.2017 19:59Все забыли что при боксинге еще нужно Method Table создать и присобачить к результату.
ggrnd0
Boxing выделяет память в куче, unboxing — нет.
И нет никакого смысла в этой статье...
fsou11
Boxing выделяет память в куче, unboxing в стеке потока выполнения. Смысл статьи в первом приближении сравнить производительность данных операций в рамках .NET.
ggrnd0
Совсем не обязательно выделять на стеке, можно в регистр кинуть.
Память на стек уже выделена, и происходит только лишь копирование + инкрементация смещения для определения свободного места на стеке.
Выделение памяти в куче требует синхронизации потоков, для стека/регистров нет.
fsou11
Я мог неправильно вас понять, но мне сложно представить почему вы считаете что память под стек уже выделена, а в куче нет. Аналогично стеку память выделяется и под процесс на момент инициализации GC и запуска процесса.
В таком случае обе эти операции лишь копируют свои значения, т.к. память под их нужды была выделена заранее.
ggrnd0
Память под стек выделяется при создании потока, динамического выделения памяти под стек на некоторых платформах присутствует, но не всегда используется.
Основных отличий 2:
память под стек выделена статически.
При выделении на куче, может потребоваться обращение к ОС за очередной страницей памяти.
При выделении на куче она обязательна.
werwolfby
Память на стеке уже выделена, потому что когда метод стартует он уже знает, сколько у него локальных переменных и для них всех уже есть место на стеке.
Зачем лишний раз выделять память на стеке когда размер итак известен в момент компиляции.
Динамическая она потому что меняеется во время программы, а вот информация о размере всех переменных метода на стеке есть на момент компиляции.
Память на стеке выделяеть только
stackallockи то вunsafeрежиме.werwolfby
Даже более того. Так как это стандратная операция про выделения места для локальных переменных. В ассемблере ввели команду
enterкоторая правильно выделяет память на стеке на старте метода.И нет смысла лишний раз что-то выделять когда это можно сделать один раз.
ggrnd0
В некоторых системах реализована динамическое расширение памяти на стеке.
Но это в некоторых, и после пары прогонов размер устаканится и потребности расширять стек больше не будет.
Также, анбоксинг не всегда идет в стек.
werwolfby
Да, golang так делает например. Но мы же про C# сейчас :)
А расскажите пожалуйста когда анбоксин происходит не на стек? Я действительно не знаю таких случаев.
Во всех случая, что я знаю, анбоксин всегда проходит через стек.
ggrnd0
Не уверен в возможностях jit-компилятора c#, все таки не go и не java...
Но по идее вот тут может быть анбоксинг сразу в регистр:
Так же стек может не использоваться при вычислении длинных выражений и для локальных переменных, которые не передаются дальше в какой-либо метод и не возвращаются функцией, а используются для дальнейших локальных вычислений.
Здесь на стек попадет только переменная result, но совсем не обязательно — все будет зависеть от jit-компилятора...
werwolfby
В общем смысле вы правы. JIT действительно может сделать много оптимизаций включая анбоксинг в регистр. Но это уже то как JIT решит.
Сам по себе IL (промежуточный язык) это стекавая машина, т. е. в IL весь анбоксинг всегда проходит через стек, особенность без регистровой виртуальной машины, а вот уже потом JIT может замаппить это на регистры.
werwolfby
В общем проверил, да JIT заоптимизировал в регистр:
Первый парамет тоже всегда через
ecxприходит, так что стек используется только для бекапа регистов и то только 2-х регистров.Но в IL все ещё стек потому что регистров нет, но и локальныз перменных нет :)
fsou11
Память выделяется даже под переменные, использование которых зависит от аргументов вызова метода?
werwolfby
Конечно! Только в данном случае это будет разделяемая память. Т.е. выделится один кусок стека для одной ветки в нем будет
a, для другойb. Ну и это уже на совестиjit'а. Может выделить место и для обоих структур.Вы поймите, что зарезервировать стек один раз на число просчитанное компилятор быстрее и проще, чем делать это динамически в рантайме.
Стек всегда двигается то вверх, то вниз. И управлять им соответственно просто, это вам не динамическая память. Поэтому все и стараются уменьшить работу с ним до минимума для оптимизации.
Буду за компом посмотрю ассемблерный и il-овский код.
GreenStore
с ней
werwolfby
Я проверил, листинги ассемблера большие даже в релизе, поэтому приводить не буду, там даже конструкторы заинлайнились. Добавил конструктор, чтобы он меньше оптимизировал, так
JITего всё равно заинлайнил. В общем, по IL коду сразу видно, что независимо от ветвлений, все локальные переменные объявляются сразу в заголовке, что логично:А по дизассемблеру видно что место выделяется сразу,
JITдаже не переиспользовал место в зависимости от ветвлений, хотя точно мог это сделать, кто его знает какие оптимизации он делает.Если увеличить размер первой структуру то и место в стеке резервируется большее.
В общем магии нет, и выделения на стеке не происходит динамически, а фиксированно и известно в самом методе при его старте в виде константы.
fsou11
Спасибо, надо освежать знания по memory management :)
Bonart
В вашем примере в стеке память выделяется один раз на тест, а в куче — один раз на каждую итерацию цикла. Конец немного предсказуем.
Hydro
Хотел тоже самое написать, но побоялся словить кучу минусов за первый коммент с негативным содержанием)))
ggrnd0
ссыкло=)
Free_ze
Во истину, даже Рихтер акцентировал внимание на этом в известной книжке, которую и так все читали.