

PHP и потоки выполнения (threads). Предложение всего лишь из четырёх слов, а по этой теме можно написать книгу. Как обычно, я не буду так делать, зато дам вам информацию, чтобы вы стали разбираться в предмете до определённой степени.
Начнём с путаницы, которая есть в головах у некоторых программистов. PHP — это не многопоточный язык. Внутри самого PHP не используются потоки выполнения, и PHP не даёт возможности пользовательскому коду нативно использовать их в качестве механизма параллелизации.
PHP очень далёк от других технологий. Например, в Java очень активно используются потоки выполнения, ещё они могут встречаться в пользовательских программах. В PHP такого нет. И тому есть причины.
Движок PHP обходится без потоков выполнения в основном ради упрощения структуры. Прочитав следующий раздел, вы узнаете, что потоки выполнения — не «магическая технология, позволяющая ускорить работу любой программы». Похоже на речь продавца, правда? Но мы не торговцы — мы технари, и мы знаем, о чём говорим. В настоящий момент в движке PHP нет потоков выполнения. Возможно, в будущем они появятся. Но это повлечёт за собой столько сложностей, что результат может оказаться далёк от ожидаемого. Главная трудность — кроссплатформенное многопоточное программирование (thread programming). Вторая трудность — общие ресурсы (shared resources) и управление блокировками. Третья — потоки выполнения подходят не для каждой программы. Архитектура PHP зародилась в районе 2000 года, а в то время потоковое программирование было малораспространённым и незрелым. Поэтому авторы PHP (преимущественно движка Zend) решили сделать цельный движок без потоков. Да и не было у них нужных ресурсов для создания стабильного кроссплатформенного многопоточного движка.
Кроме того, потоки выполнения невозможно применять в пользовательском пространстве PHP. Этот язык не так выполняет код. Концепция PHP — «выстрелил и забыл». Запрос должен обрабатываться как можно быстрее, чтобы освободить PHP для следующего запроса. PHP создан как связующий язык: вы не обрабатываете сложные задачи, требующие потоков. Вместо этого обращаетесь к fast-and-ready ресурсам, связываете всё воедино и отправляете обратно пользователю. PHP — язык действия, а если что-то требует на обработку «больше времени, чем обычно», то это нужно делать не в PHP. Поэтому для асинхронной обработки каких-то тяжёлых задач используется система на базе очередей (Gearman, AMQP, ActiveMQ и т. д.). В Unix принято делать так: «Разрабатывай маленькие, самодостаточные инструменты и связывай их друг с другом». PHP не рассчитан на активное распараллеливание, это удел других технологий. Каждой проблеме — правильный инструмент.
Несколько слов о потоках выполнения
Освежим в памяти, что такое потоки выполнения. Не будем углубляться в подробности, их вы найдёте в интернете и книгах.
Поток выполнения — «малая» единица обработки (light unit of work treatment), находящаяся внутри процесса. Процесс может создавать многочисленные потоки выполнения. Поток должен быть частью только одного процесса. Процесс — «большая» единица обработки в рамках операционной системы. На многоядерных (многопроцессорных) компьютерах несколько ядер (процессоров) работают параллельно и обрабатывают часть нагрузки исполняемых задач. Если процессы А и Б готовы к постановке в очередь и два ядра (процессора) готовы к работе, то А и Б должны быть одновременно отправлены в обработку. Тогда компьютер эффективно обрабатывает несколько задач в единицу времени (временной интервал, timeframe). Мы называем это «параллелизм».
Процесс:
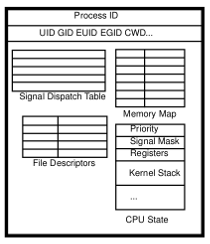
Поток выполнения:

Всё вместе:
Раньше A и Б были процессами: полностью независимыми обработчиками. Но потоки выполнения — это не процессы. Потоки — это единицы, живущие внутри процессов. То есть процесс может распределить работу по нескольким более мелким задачам, выполняемым одновременно. К примеру, процессы А и Б могут породить потоки А1, А2, Б1 и Б2. Если компьютер оснащён несколькими процессорами, например восемью, то все четыре потока могут выполняться в одном временном интервале (timeframe).
Потоки выполнения — это способ разделения работы процесса на несколько мелких подзадач, решаемых параллельно (в одном временном интервале). Причём потоки выполняются примерно так же, как и процессы: диспетчер программного потока ядра (Kernel thread scheduler) управляет потоками с помощью состояний.

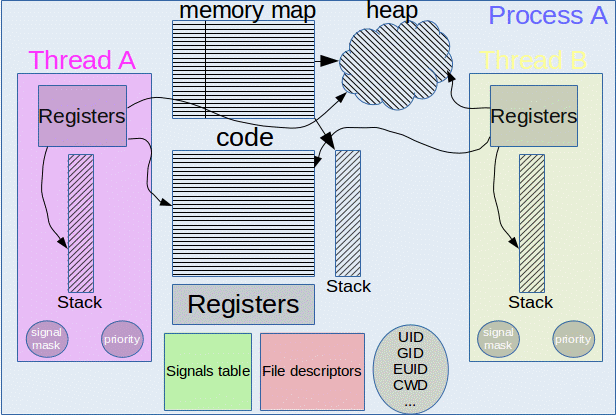
Потоки выполнения легче процессов, им для работы нужен лишь стек и несколько регистров. А процессам требуется много всего: новый кадр виртуальной машины (VM frame) от ядра, куча, разная сигнальная информация, информация о файловых дескрипторах, блокировках и т. д.
Память процесса управляется на аппаратном уровне ядром и MMU, а память потока выполнения — на программном уровне программистом и потоковыми библиотеками (threading library).
Так что запомните: потоки выполнения легче процессов и проще управляются. При грамотном использовании они ещё и работают быстрее процессов, поскольку ядро ОС почти не вмешивается в управление потоками и их диспетчеризацию.
Схема памяти потоков выполнения
У потоков выполнения есть свой стек. Поэтому при обращении к переменным, объявленным в функциях, они получают собственную копию этих данных.
Куча процесса совместно используется потоками выполнения, как и глобальные переменные, и файловые дескрипторы. Это и преимущество, и недостаток. Если мы только считываем из глобальной памяти, то нужно это делать вовремя. Например, после потока Х и до потока Y. Если мы пишем в глобальную память, то стоит удостовериться, что туда же и в то же время не попытаются записать несколько потоков. Иначе эта область памяти окажется в непредсказуемом состоянии — так называемом состоянии гонки (race condition). Это главная проблема в потоковом программировании.
На случай одновременного доступа вам нужно внедрить в код некоторые механизмы вроде повторного входа (reentrancy) или подпрограмм синхронизации (synchronization routine). Повторный вход нарушает согласованность (concurrency). А синхронизация позволяет управлять согласованностью предсказуемым образом.
Процессы не используют память совместно, они идеально изолированы на уровне ОС. А потоки выполнения внутри одного процесса совместно используют большой объём памяти.
Поэтому им нужны инструменты синхронизации доступа к общей памяти, например семафоры и мьютексы (mutexes). Работа этих инструментов основана на принципе «блокировки»: если ресурс заблокирован, а поток пытается получить к нему доступ, то по умолчанию поток будет ожидать разблокировки ресурса. Поэтому потоки выполнения сами по себе не сделают вашу программу быстрее. Без эффективного распределения задач по потокам и управления блокировками общей памяти ваша программа станет работать ещё медленнее, чем при использовании одного процесса без потоков выполнения. Просто потоки будут постоянно ожидать друг друга (и я ещё не говорю о взаимоблокировках, голодании и т. д.).
Если у вас нет опыта в потоковом программировании, то оно окажется для вас непростым занятием. Чтобы наработать опыт работы с потоками выполнения, понадобится много часов практики и решения WTF-моментов. Стоит забыть о какой-то мелочи — и вся программа пойдёт в разнос. Труднее отлаживать программу с потоками, чем без них, если мы говорим о реальных проектах с сотнями или тысячами потоков в одном процессе. Вы сойдёте с ума и просто утонете во всём этом.
Потоковое программирование — трудная задача. Чтобы стать мастером, нужно потратить массу времени и сил.
Такая схема совместного использования памяти потоками не всегда удобна. Поэтому появилось локальное хранилище потока (Thread Local Storage, TLS). TLS можно описать как «глобалы, принадлежащие какому-то одному потоку и не используемые другими». Это области памяти, отражающие глобальное состояние, приватные для конкретного потока выполнения (как в случае использования одних лишь процессов). При создании потока выделяется часть кучи процесса — хранилище. У потоковой библиотеки запрашивается ключ, который ассоциируется с этим хранилищем. Он должен использоваться потоком выполнения при каждом обращении к своему хранилищу. Для уничтожения выделенных ресурсов в конце жизни потока требуется деструктор.
Приложение «потокобезопасно» (thread safe), если каждое обращение к глобальным ресурсам находится под полным контролем и полностью предсказуемо. В противном случае вам перейдёт дорогу диспетчер (scheduler): будут неожиданно выполняться какие-то задачи, и производительность упадёт.
Потоковые библиотеки
Потокам выполнения нужна помощь ядра ОС. В операционных системах потоки выполнения появились в середине 1990-х, так что методики работы с ними отшлифованы.
Но существуют проблемы кроссплатформенности. Особенно много различий между Windows- и Unix-системами. В этих экосистемах приняты разные модели потокового выполнения и используются разные потоковые библиотеки.
В Linux для создания потока или процесса ядро осуществляет системный вызов clone(). Но он невероятно сложен, поэтому для облегчения повседневного потокового программирования системные вызовы используют код на Си. Libc до сих пор не управляет потоковыми операциями (подобную инициативу демонстрирует стандартная библиотека из С11), этим занимаются внешние библиотеки. Сегодня в Unix-системах обычно применяется pthread (есть и другие библиотеки). Pthread — сокращение от Posix threads. Эта POSIX-нормализация использования потоков и их поведения берёт своё начало в 1995-м. Если вам нужны потоки выполнения, подключите библиотеку libpthread: передайте в GCC -lpthread. Она написана на С, её код открыт, есть собственный механизм контроля и управления версиями.
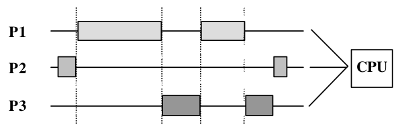
Итак, в Unix-системах чаще всего используется библиотека pthread. Она обеспечивает согласованность (concurrency), а параллелизм зависит от конкретной ОС и компьютера.
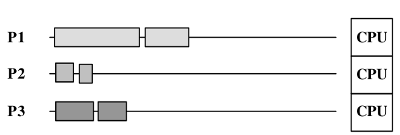
Согласованность — это когда несколько потоков беспорядочно выполняются на одном процессоре. Параллелизм — это когда несколько потоков одновременно выполняются на разных процессорах.
Согласованность:
Параллелизм:
PHP и потоки выполнения
Для начала вспомним:
- В PHP нет потоков выполнения: его движок и код обходятся без потоков для распараллеливания внутренней работы.
- PHP не предлагает потоки пользователям: вы не можете нативно использовать их в PHP. Джо Ваткинс (Joe Watkins), один из разработчиков PHP, создал хорошую библиотеку, добавляющую потоки выполнения в пользовательское пространство: ext/pthread. Но лично я не выбрал бы PHP для таких задач: он для этого не предназначен, лучше взять С или Java.
Так что насчёт потоков выполнения в PHP?
Как PHP обрабатывает запросы
Всё дело в том, как PHP будет обрабатывать HTTP-запросы. Веб-серверу необходимо обеспечить какую-то согласованность (или параллелизм) для обслуживания нескольких клиентов одновременно. Ведь, отвечая одному клиенту, нельзя поставить всех остальных на паузу.
Поэтому для ответов клиентам серверы обычно используют несколько процессов или несколько потоков выполнения.
Исторически сложилось, что под Unix работают процессы. Просто это основа Unix, с его рождением появились и процессы, способные создавать новые процессы (fork()), уничтожать их (exit()) и синхронизировать (wait(), waitpid()). В такой среде многочисленные PHP обслуживают многочисленные клиентские запросы. Но каждый работает в своём собственном процессе.
В такой ситуации PHP ничем не может помочь: процессы полностью изолированы. Процесс А, обрабатывающий запрос А о данных клиента А, не сможет взаимодействовать (читать или писать) с процессом Б, обрабатывающим запрос Б клиента Б. Нам это и нужно.
В 98 % случаев используются две архитектуры: php-fpm и Apache с mpm_prefork.
Под Windows всё сложнее, как и в Unix-серверах с потоками выполнения.
Windows — действительно замечательная ОС. У неё лишь один недостаток — закрытый исходный код. Но в сети или в книгах можно найти информацию о внутреннем устройстве многих технических ресурсов. Инженеры Microsoft много рассказывают о том, как работает Windows.
У Windows другой подход к согласованности и параллелизму. Эта ОС очень активно использует потоки выполнения. По сути, создание процесса в Windows — такая тяжёлая задача, что обычно её избегают. Вместо этого всегда и везде применяют потоки выполнения. Потоки в Windows на порядок мощнее, чем в Linux. Да, именно так.
Когда PHP работает под Windows, веб-сервер (любой) будет обрабатывать клиентские запросы в потоках, а не процессах. То есть в таком окружении PHP выполняется в потоке. И поэтому ему стоит особенно тщательно подходить к спецификациям потоков: он должен быть потокобезопасным (thread safe).
PHP должен быть потокобезопасным, т. е. управлять согласованностью, которую он не создавал, но в которой и с которой функционирует. То есть защитить свой доступ к своим собственным глобальным переменным. А их у PHP много.
За эту защиту отвечает уровень Zend Thread Safety (ZTS, потокобезопасность Zend).
Обратите внимание, что всё то же самое верно и под Unix, если вы решите использовать потоки выполнения для распараллеливания обработки клиентских запросов. Но для Unix-систем это очень необычная ситуация, поскольку для таких задач здесь традиционно используются классические процессы. Хотя никто не мешает выбрать потоки, это способно повысить производительность. Потоки легче процессов, так что система может выполнять гораздо больше потоков. Кроме того, если вашему PHP-расширению нужна потокобезопасность (вроде ext/pthread), то вам потребуется и потокобезопасный PHP.
Подробности реализации ZTS
ZTS активируется с помощью --enable-maintainer-zts. Обычно вам не нужен этот переключатель, если вы не запускаете PHP под Windows или не запускаете PHP с расширением, для работы которого необходима потокобезопасность движка.
Есть ряд способов проверки текущего режима работы. CLI и php –v скажут вам, что сейчас активирован NTS (Not Thread Safe) или ZTS (Zend Thread Safe).

Также можно воспользоваться phpinfo():

Можете в своём коде считать константу PHP_ZTS из PHP.
if (PHP_ZTS) {
echo "You are running a thread safe version of the PHP engine";
}При компилировании с ZTS вся основа PHP становится потокобезопасной. Но активированные расширения при этом могут не быть потокобезопасными. Все официальные расширения (распространяемые с PHP) безопасны, но за сторонние поручиться нельзя. Ниже вы увидите, что освоение потокобезопасности расширений PHP требует особого использования API. И, как это постоянно происходит с потоками: одно упущение — и весь сервер может посыпаться.
При использовании потоков выполнения, если вы не вызываете реентерабельные функции (обычно из libc) или вслепую обращаетесь к истинной глобальной переменной (true global variable), это приведёт к странному поведению во всех одноуровневых потоках (sibling threads). Например, накосячите с потоками в одном расширении — и это повлияет на каждого клиента, обслуживаемого во всех потоках выполнения на сервере! Кошмарная ситуация: один клиент может испортить все остальные клиентские данные.
При проектировании расширений PHP:
- Необходима предельная осторожность и хорошие знания потокового программирования. В противном случае вы совершенно непредсказуемо поломаете сервер, а отладить его достаточно быстро не получится.
- Если ошибётесь с потоками, то это повлияет на всех клиентов, обслуживаемых всеми потоками на сервере. Вы можете этого даже не заметить, потому что ошибочное потоковое программирование обычно приводит к ужасному непредсказуемому поведению, которое непросто воспроизвести.*
Реентерабельные функции
При проектировании расширения PHP используйте реентерабельные функции: функции, работа которых не зависит от глобального состояния. Хотя это слишком упрощённо. Если подробнее, то реентерабельные функции могут вызываться, пока не завершился их предыдущий вызов. Они способны работать параллельно в двух и более потоках выполнения. Если бы они использовали глобальное состояние, то не были бы реентерабельными. Однако они могут блокировать собственное глобальное состояние, а значит, быть потокобезопасными ;) Многие традиционные функции из libc нереентерабельны, потому что создавались, когда ещё не придумали потоки выполнения.
Так что некоторые libc (особенно glibc) публикуют реентерабельные эквивалентные функции (reentrant equivalent functions) как функции с суффиксом _r(). Новый стандарт С11 даёт больше возможностей использования потоков выполнения. А функции из C11 libc переработаны и получили суффикс _s() (например, localtime_s()).
strtok() => strtok_r(); strerror(), strerror_r(); readdir() => readdir_r() — и т. д.
Сам PHP предоставляет некоторые функции в основном для кроссплатформенного использования. Взгляните на main/reentrancy.c.
Также не забывайте о реентерабельности при написании собственных С-функций. Функция будет реентерабельной, если вы можете передать ей всё необходимое в виде аргументов (в стеке или через регистры) и если она не использует глобальные/статические переменные или какие-либо нереентерабельные функции.
Не привязывайтесь к потоконебезопасным библиотекам
Не забывайте, что в потоковом программировании важен весь процесс совместного использования образа памяти. Сюда входят и залинкованные библиотеки.
Если ваше расширение привязано к библиотеке, которая точно потоконебезопасна, то придётся разработать собственные способы обеспечения потокобезопасности, чтобы защитить в библиотеке доступ к глобальному состоянию. В потоковом программировании и С такое бывает часто, но легко упускается из виду.
Использование ZTS
ZTS — это уровень кода, контролирующий доступ к глобальным потоковым переменным с помощью TLS (Thread Local Storage) в PHP 7.
При разработке языка PHP и его расширений нам приходится различать в коде два вида глобалов.
Есть истинные глобалы (true globals), представляющие собой просто традиционные глобальные переменные С. У них всё в порядке с архитектурой, но поскольку мы не защитили их от согласованности в потоках, то можем только считывать их, когда PHP обрабатывает запросы. Истинные глобалы создаются и записываются до того, как будет создан хотя бы один поток выполнения. По внутренней терминологии PHP этот шаг называется модульной инициализацией (module init). Это хорошо видно на примере расширений:
static int val; /* истинный глобал */
PHP_MINIT(wow_ext) /* модульная инициализация PHP */
{
if (something()) {
val = 3; /* запись в истинный глобал */
}
}Этот псевдокод показывает, как может выглядеть любое PHP-расширение. Расширения имеют несколько перехватчиков (hooks), инициализируемых в течение жизненного цикла PHP. Перехватчик MINIT() относится к инициализации PHP. При этой процедуре запускается PHP и можно безопасно читать глобальную переменную или писать в неё, как в приведённом примере.
Второй важный перехватчик — RINIT(), инициализация запроса. Эта процедура вызывается для каждого расширения, при обработке каждого нового запроса. То есть RINIT() может вызываться расширением тысячи раз. На этом этапе PHP уже уходит в поток. Веб-сервер разобьёт изначальный процесс на потоки, поэтому в RINIT() необходима потокобезопасность. Это совершенно логично в ситуации, когда создаются потоки для одновременной обработки нескольких запросов. Не забывайте — вы не создаёте потоки. Вместо PHP потоки создаёт веб-сервер.
Также мы используем потоковые глобалы (thread globals). Это глобальные переменные, чья потокобезопасность обеспечивается уровнем ZTS:
PHP_RINIT(wow_ext) /* инициализация запроса в PHP */
{
if (something()) {
WOW_G(val) = 3; /* запись в потоковый глобал */
}
}Для обращения к потоковому глобалу мы воспользовались макросом WOW_G(). Давайте разберёмся, как он работает.
Необходимость макросов
Запомните: когда PHP работает в потоках выполнения, необходимо защищать доступ ко всем глобальным состояниям, относящимся к запросам. Если потоков нет, то эта защита не нужна. Ведь каждый процесс получает собственную память, которой не пользуется никто другой.
Так что способ доступа к глобалам, относящимся к запросам, зависит от окружения (используется многозадачный движок). Поэтому надо сделать так, чтобы обращение к глобалам, связанным с запросами, выполнялось одинаково вне зависимости от окружения.
Для этого используются макросы.
Макрос WOW_G() будет обрабатываться разными способами, в соответствии с работой многозадачного движка PHP (процессы или потоки). Вы можете на это влиять, перекомпилируя своё расширение. Поэтому расширения PHP несовместимы при переключении между режимами ZTS и неZTS. Несовместимы на уровне двоичного кода (binary incompatible)!
ZTS несовместим на уровне двоичного кода с неZTS. При переключении с одного режима на другой нужно перекомпилировать исключения.
При работе в процессе макрос WOW_G() обычно обрабатывается так:
#ifdef ZTS
#define WOW_G(v) wow_globals.v
#endifПри работе в потоке:
#ifndef ZTS
#define WOW_G(v) wow_globals.v
#else
#define WOW_G(v) (((wow_globals *) (*((void ***) tsrm_get_ls_cache()))[((wow_globals_id)-1)])->v)
#endifВ ZTS-режиме сложнее.
При работе в процессе — режим неZTS (Non Zend Thread Safe) — используется истинный глобал, wow_globals. Эта переменная представляет собой структуру, содержащую глобальные переменные, и с помощью макроса мы обращаемся к каждой из них. WOW_G(foo) ведёт на wow_globals.foo. Естественно, вам нужно объявить эту переменную, чтобы она была обнулена при запуске. Это также делается с помощью макроса (в ZTS-режиме выполняется иначе):
ZEND_BEGIN_MODULE_GLOBALS(wow)
int foo;
ZEND_END_MODULE_GLOBALS(wow)
ZEND_DECLARE_MODULE_GLOBALS(wow)Тогда макрос обрабатывается так:
#define ZEND_BEGIN_MODULE_GLOBALS(module_name) typedef struct _zend_##module_name##_globals {
#define ZEND_END_MODULE_GLOBALS(module_name) } zend_##module_name##_globals;
#define ZEND_DECLARE_MODULE_GLOBALS(module_name) zend_##module_name##_globals module_name##_globals;И всё. При работе в процессе — ничего сложного.
Но при работе в потоке — с использованием ZTS — у нас больше нет истинных глобалов С. Но объявления глобалов выглядят так же:
#define ZEND_BEGIN_MODULE_GLOBALS(module_name) typedef struct _zend_##module_name##_globals {
#define ZEND_END_MODULE_GLOBALS(module_name) } zend_##module_name##_globals;
#define WOW_G(v) (((wow_globals *) (*((void ***) tsrm_get_ls_cache()))[((wow_globals_id)-1)])->v)В ZTS и неZTS глобалы объявляются одинаково.
Но доступ к ним происходит по-разному. В ZTS вызывается функция tsrm_get_ls_cache(). Это обращение к хранилищу TLS, которое возвратит область памяти, выделенную для текущего конкретного потока выполнения. Учитывая, что в первую очередь мы выполняем приведение к типу void, с этим кодом всё не так просто.
Уровень TSRM
ZTS использует так называемый уровень TSRM — Thread Safe Resource Manager. Это просто кусок кода на С, ничего более!
Именно благодаря уровню TSRM возможна работа ZTS. По большей части он находится в папке /TSRM исходного кода PHP.
TSRM — не идеальный уровень. В целом он спроектирован хорошо и появился ещё во времена начала PHP 5 (около 2004-го). TSRM может работать с несколькими низкоуровневыми потоковыми библиотеками: Gnu Portable Thread, Posix Threads, State Threads, Win32 Threads и BeThreads. Желаемый уровень можно выбрать при конфигурировании (./configure --with-tsrm-xxxxx).
При анализе TSRM мы будем обсуждать только реализацию на основе pthreads.
Загрузка TSRM
Когда PHP грузится во время модульной инициализации, он быстро вызывает tsrm_startup(). PHP ещё не знает, сколько нужно создать потоков выполнения и сколько потребуется ресурсов для обеспечения потокобезопасности. Он подготавливает таблицы потоков (thread tables), каждая состоит из одного элемента. Позднее таблицы разрастутся, а пока они распределены с помощью malloc().
Этот начальный этап важен ещё потому, что здесь мы создаём ключ TLS и мьютекс TLS, которые понадобится синхронизировать.
static pthread_key_t tls_key;
TSRM_API int tsrm_startup(int expected_threads, int expected_resources, int debug_level, char *debug_filename)
{
pthread_key_create( &tls_key, 0 ); /* Create the key */
tsrm_error_file = stderr;
tsrm_error_set(debug_level, debug_filename);
tsrm_tls_table_size = expected_threads;
tsrm_tls_table = (tsrm_tls_entry **) calloc(tsrm_tls_table_size, sizeof(tsrm_tls_entry *));
if (!tsrm_tls_table) {
TSRM_ERROR((TSRM_ERROR_LEVEL_ERROR, "Unable to allocate TLS table"));
return 0;
}
id_count=0;
resource_types_table_size = expected_resources;
resource_types_table = (tsrm_resource_type *) calloc(resource_types_table_size, sizeof(tsrm_resource_type));
if (!resource_types_table) {
TSRM_ERROR((TSRM_ERROR_LEVEL_ERROR, "Unable to allocate resource types table"));
free(tsrm_tls_table);
tsrm_tls_table = NULL;
return 0;
}
tsmm_mutex = tsrm_mutex_alloc(); /* распределяем мьютекс */
}
#define MUTEX_T pthread_mutex_t *
TSRM_API MUTEX_T tsrm_mutex_alloc(void)
{
MUTEX_T mutexp;
mutexp = (pthread_mutex_t *)malloc(sizeof(pthread_mutex_t));
pthread_mutex_init(mutexp,NULL);
return mutexp;
}Ресурсы TSRM
Когда уровень TSRM загружен, нужно добавить в него новые ресурсы. Под ресурсом подразумевается область памяти, содержащая набор глобальных переменных, обычно относящихся к расширению PHP. Ресурс должен принадлежать текущему потоку выполнения или быть защищённым для доступа.
У этой области памяти есть какой-то размер. Ей понадобится инициализация (конструктор) и деинициализация (деструктор). Обычно инициализация ограничивается обнулением области памяти, а при деинициализации вообще ничего не делается.
Уровень TSRM передаёт ресурсу уникальный ID. Затем вызывающая функция (caller) должна сохранить этот ID, поскольку он потом понадобится для возвращения защищённой области памяти из TSRM.
TSRM-функция, создающая новый ресурс:
typedef struct {
size_t size;
ts_allocate_ctor ctor;
ts_allocate_dtor dtor;
int done;
} tsrm_resource_type;
TSRM_API ts_rsrc_id ts_allocate_id(ts_rsrc_id *rsrc_id, size_t size, ts_allocate_ctor ctor, ts_allocate_dtor dtor)
{
int i;
tsrm_mutex_lock(tsmm_mutex);
/* получаем id ресурса */
*rsrc_id = id_count++;
/* сохраняем новый тип ресурса в таблице размеров ресурсов */
if (resource_types_table_size < id_count) {
resource_types_table = (tsrm_resource_type *) realloc(resource_types_table, sizeof(tsrm_resource_type)*id_count);
if (!resource_types_table) {
tsrm_mutex_unlock(tsmm_mutex);
TSRM_ERROR((TSRM_ERROR_LEVEL_ERROR, "Unable to allocate storage for resource"));
*rsrc_id = 0;
return 0;
}
resource_types_table_size = id_count;
}
resource_types_table[(*rsrc_id)-1].size = size;
resource_types_table[(*rsrc_id)-1].ctor = ctor;
resource_types_table[(*rsrc_id)-1].dtor = dtor;
resource_types_table[(*rsrc_id)-1].done = 0;
/* увеличиваем массивы для уже активных потоков выполнения */
for (i=0; icount < id_count) {
int j;
p->storage = (void *) realloc(p->storage, sizeof(void *)*id_count);
for (j=p->count; jstorage[j] = (void *) malloc(resource_types_table[j].size);
if (resource_types_table[j].ctor) {
resource_types_table[j].ctor(p->storage[j]);
}
}
p->count = id_count;
}
p = p->next;
}
}
tsrm_mutex_unlock(tsmm_mutex);
return *rsrc_id;
}Как видите, этой функции нужна взаимоисключающая блокировка (mutex lock). Если она вызывается в дочернем потоке выполнения (а она будет вызвана в каждом из них), то заблокирует другие потоки, пока не закончит манипулировать глобальным состоянием хранилища потока (global thread storage state).
Новый ресурс добавляется в динамический массив resource_types_table[] и получает уникальный идентификатор — rsrc_id, который инкрементируется по мере добавления ресурсов.
Запуск запроса
Теперь мы готовы обрабатывать запросы. Помните, что каждый запрос будет обслуживаться в своём собственном потоке выполнения. Что произойдёт, когда запрос там появится? В самом начале каждого нового запроса вызывается функция ts_resource_ex(). Она считывает ID текущего потока выполнения и пытается извлечь ресурсы, выделенные для этого потока, т. е. области памяти для глобалов текущего потока. Если ресурсы не обнаруживаются (поток новый), то для текущего потока выделяются ресурсы на основе модели, созданной при запуске PHP. Делается это с помощью allocate_new_resource()
static void allocate_new_resource(tsrm_tls_entry **thread_resources_ptr, THREAD_T thread_id)
{
int i;
TSRM_ERROR((TSRM_ERROR_LEVEL_CORE, "Creating data structures for thread %x", thread_id));
(*thread_resources_ptr) = (tsrm_tls_entry *) malloc(sizeof(tsrm_tls_entry));
(*thread_resources_ptr)->storage = NULL;
if (id_count > 0) {
(*thread_resources_ptr)->storage = (void **) malloc(sizeof(void *)*id_count);
}
(*thread_resources_ptr)->count = id_count;
(*thread_resources_ptr)->thread_id = thread_id;
(*thread_resources_ptr)->next = NULL;
/* Настройка локального хранилища потока для структуры ресурсов этого нового потока */
tsrm_tls_set(*thread_resources_ptr);
if (tsrm_new_thread_begin_handler) {
tsrm_new_thread_begin_handler(thread_id);
}
for (i=0; istorage[i] = NULL;
} else
{
(*thread_resources_ptr)->storage[i] = (void *) malloc(resource_types_table[i].size);
if (resource_types_table[i].ctor) {
resource_types_table[i].ctor((*thread_resources_ptr)->storage[i]);
}
}
}
if (tsrm_new_thread_end_handler) {
tsrm_new_thread_end_handler(thread_id);
}
tsrm_mutex_unlock(tsmm_mutex);
}Кеш локального хранилища расширений
Каждое расширение в PHP 7 может объявить свой кеш в локальном хранилище. Это означает, что при запуске каждого нового потока выполнения каждое расширение должно считывать область локального хранилища своего собственного потока выполнения, а не итерировать по списку хранилищ при каждом обращении к глобалу (global access). Тут нет никакой магии, для этого нужно выполнить несколько вещей.
Для начала вы должны компилировать PHP с поддержкой кеша: введите в командной строке компиляции -DZEND_ENABLE_STATIC_TSRMLS_CACHE=1. В любом случае это должно делаться по умолчанию. Далее, при объявлении глобалов вашего расширения используйте макрос ZEND_TSRMLS_CACHE_DEFINE():
#define ZEND_TSRMLS_CACHE_DEFINE(); __thread void *_tsrm_ls_cache = ((void *)0);
Как видите, объявляется настоящий глобал C, только со специальным объявлением __thread. Это нужно для того, чтобы сказать компилятору, что это будет потоковая переменная (thread specific).
Затем нужно заполнить это хранилище void* данными из хранилища, зарезервированного для ваших глобалов уровнем TSRM. Для этого в конструкторе глобалов можете использовать ZEND_TSRMLS_CACHE_UPDATE():
PHP_GINIT_FUNCTION(my_ext)
{
#ifdef ZTS
ZEND_TSRMLS_CACHE_UPDATE();
#endif
/* Continue initialization here */
}
```cpp
Вот макрорасширение (macro expansion):
```#define ZEND_TSRMLS_CACHE_UPDATE() _tsrm_ls_cache = tsrm_get_ls_cache();```
И для реализации pthread:
```#define tsrm_get_ls_cache pthread_getspecific(tls_key)```
Наконец, вы должны лучше понять, как теперь происходит обращение к глобалам в расширениях — с помощью этого макроса:
```cpp
#ifdef ZTS
#define MY_G(v) (((my_globals *) (*((void ***) _tsrm_ls_cache))[((my_globals_id)-1)])->(v))Как видите, если брать для обращения к глобалам макрос MY_G(), при использовании среды потоков он будет расширяться, чтобы проверить область _tsrm_ls_cache с помощью ID этого расширения: my_globals_id.

Как мы уже видели, каждое расширение является ресурсом и предоставляет какое-то пространство для своих глобалов. Для возвращения хранилища конкретному расширению используется ID. TSRM создаст это хранилище для текущего потока выполнения, когда появится новый запрос/поток.
Заключение
Программирование потоков выполнения — задача непростая. Здесь я лишь показал вам, как PHP работает с управлением глобалами: он изолирует каждое глобальное хранилище с помощью TLS, создаваемого для каждого нового потока выполнения при запуске запроса, движком или выделенным уровнем — TSRM. Он блокирует мьютекс, создаёт хранилище для глобалов текущего потока, а затем разблокирует мьютекс. Таким образом, каждое расширение и каждая часть PHP может обращаться к своему собственном хранилищу без необходимости блокировать мьютекс при каждом доступе.
Всё становится абстрактным за пределами уровня TSRM: уровня С-кода, облегчающего управление глобалами, особенно для создателей расширений. Для обращения к своему глобальному пространству вы используете макрос, и если вы работаете в ZTS, то этот макрос будет преобразован в специфический код для обращения только к вашему маленькому хранилищу посреди каждого расширения. Благодаря кешу TSRM при каждом обращении к глобалу вам не нужен поиск: вам предоставили указатель на ваше конкретное хранилище, кешируйте его и берите снова, когда нужно обратиться к глобалу.
Очевидно, что всё это справедливо для глобалов, относящихся к запросу (request-bound). Вы по-прежнему можете использовать настоящие С-глобалы, но не пытайтесь писать в них, применяя servinf к запросу: вы столкнётесь со странным поведением, плохо поддающимся отладке, или даже порушите весь веб-сервер.
Комментарии (6)

gnomeby
26.05.2017 12:11Предложение всего лишь из четырёх слов, а по этой теме можно написать книгу.
Да, ладно вам, не переусложняйте. Книгу можно написать по потокам. А уже потом отдельным приложением рассказать о реализации потокобезопасного кода в расширениях PHP.
Поэтому авторы PHP (преимущественно движка Zend) решили сделать цельный движок без потоков.
Не думаю, что они что-то там решали. Просто делали самый простой рабочий вариант.
Wano987
Прочитал статью, остался озадачен вопросом:
почему нельзя это сделать боле простым способом, а именно размножить демонов?
Есть клиент, он оставляет запрос, запрос падает в базу, клиент получает отчёт.
Но: после этого ещё N времени мы обрабатываем чужие запросы, включая запрос клиента.
Если обработчику надо — он оставляет запрос/создаёт новые на следующую итерацию обработки.
Нагрузка на сервер вычисляется самим сервером по косвенным признакам: локу файлов, кол-ву файлов кэша и т.п. в зависимости от реализации. Может там 1 запрос в 10 секунд — и то не лимит, а может обсчёт в 50мс после запроса систему положит.
Отчёт клиента самостоятельно через n секунд пинает сервер, уточняя что там с обработкой.
Сервер огрызается
«приходи завтра»«ещё 10 сек» и что-то там считает.Реализация, конечно, странная, но вроде как цели своей достигать должна без создания мириад дополнительных сущностей.
maxru
Ну в самом начале статьи же написано, что много процессов — это дорого.
boblgum
Wano987
То, что Вы описываете, автор «упомянул» в самом начале статьи (пятый абзац).