

Пару дней назад Дэвид Робинсон опубликовал на Stack Overflow статью с очень провокационным названием: Разработчики, использующие пробелы, зарабатывают больше использующих табуляцию (перевод на Хабре). Автор взял данные из исследования разработчиков, проведённого Stack Overflow, и в самом деле показал, что использование пробелов ассоциируется с более высокими зарплатами, даже принимая в расчёт одинаковый уровень опыта. Так что, нужно вместо табуляций использовать пробелы, чтобы увеличить свою зарплату?

Ответ однозначно «нет», потому что проведённая корреляция не подразумевает причинности, и интуиция подсказывает, что отступы в коде не имеют прямой связи с чьей-либо зарплатой. Вся эта история озадачила многих людей и даже попала в новостной выпуск ВВС.
Я верю, что конечная цель теории анализа и обработки данных — получение ответов на вопросы и выявление новых причинно-следственных связей. К сожалению, исходная статья не даёт ответов на многие вопросы. Это забавная корреляция, но что за ней стоит? В своей статье я попытаюсь пролить свет на этот вопрос. Первоисточник многих заставил подумать над этой проблемой, в том числе и меня. Так что предлагаю вам свою небольшую научно-детективную историю с глубоким изучением данных из исследования Stack Overflow. Вы увидите, что табуляция и пробелы не то, чем кажутся. Спойлер: ваша зарплата больше зависит от типа компании и окружения, в котором вы работаете, чем от типа используемых отступов.
Исходные данные
В своей статье Дэвид показывает, что использование пробелов вместо табуляций ассоциируется с более высокой зарплатой, и этот эффект проявляется вне зависимости от уровня опыта. При этом те, кто использует и пробелы, и табуляцию, имеют те же зарплаты, что и те, кто использует табуляцию.

Кроме того, этот эффект якобы не зависит от языка программирования или вашей специализации как разработчика. То же самое можно сказать и о размере компании. Так почему более высокооплачиваемые разработчики предпочитают пробелы? Очевидно, что тут должен быть какой-то искажающий фактор, но я не была уверена, что он был упомянут в исследовании. Я начала проводить собственное расследование, анализируя линейно-регрессионную модель из исходной статьи.
Данные для линейной регрессии
Исходная статья включает в себя линейно-регрессионную модель, прогнозирующую зарплаты на основе нескольких переменных:
- Страна.
- Стаж программирования.
- Использование табуляций и пробелов.
- Специализация разработчика и язык программирования.
- Формальное образование (бакалавр, магистр, кандидат).
- Наличие вклада в open source.
- Является ли программирование хобби.
- Размер компании.
Я решила внимательнее изучить данные и поиграть с модифицированными моделями. Для своей линейной регрессии я взяла разработчиков из США. Отчасти потому, что это крупнейшая выборка в исследовании, и анализ по одной стране избавляет от многих региональных различий, и отчасти потому, что я сомневалась в достоверности уровня зарплат в некоторых странах (об этом ниже). Теперь давайте возьмём статистические данные и проанализируем их. Я хочу показать вам цепочку своих рассуждений, которые привели меня к определённым выводам.
Анализируем линейную регрессию
Хочу отметить, что я изменила регрессионную модель, использованную Дэвидом, потому что она не включала в себя постоянное смещение (bias term, постоянное слагаемое), что привело к модели типа ANOVA. Я воспользовалась стандартной линейной регрессией с постоянным смещением и применила две модели:
- Полную модель с информацией о табуляциях и пробелах.
- Сокращённую модель без информации о табуляциях и пробелах.
Сравнение моделей должно было подсказать мне, сколько информации можно получить за счёт использования предпочтительного вида отступов. Обе модели одинаково хорошо прогнозируют зарплаты — или одинаково плохо, в зависимости от вашей точки зрения. Откуда это известно? Можно посмотреть на коэффициент детерминации R2, определяющий степень отклонения зарплаты, которую можно объяснить с помощью входных переменных (стаж, язык и так далее). Чем выше коэффициент, тем лучше можно смоделировать зарплату как комбинацию других факторов.
| Модель | R2 | R2adj |
|---|---|---|
| Полная модель | 0,4008 | 0,3892 |
| Сокращённая модель | 0,3938 | 0,3892 |
У обеих моделей очень близкая точность, обе могут объяснить около 40 % отклонения зарплаты. У полной модели R2 выше, что вполне ожидаемо для модели с большим количеством переменных. Скорректированное значение R2adj можно использовать для сравнения двух моделей, чтобы понять, какая удовлетворяет лучше. У полной модели R2adj тоже выше, но разница составляет всего 0,0068. Похоже, что информация об использовании табуляций и пробелов важна, но не вносит заметного вклада. В сокращённой линейно-регрессионной модели отсутствующие данные можно отчасти компенсировать использованием других переменных.
Я проверила на коллинеарность, которая всегда опасна для прогнозных моделей. Коллинеарность — это ситуация, когда какие-то переменные высоко коррелируют друг с другом, что затрудняет выделение их отдельного влияния. Я не нашла признаков её наличия, а коэффициенты регрессии не изменяются массово в зависимости от модели.
Так в чём отличия между полной и сокращённой моделью? Я решила взглянуть на р-значения регрессионных коэффициентов, отражающих значимость каждой переменной в модели. Значимость хотя бы одного параметра увеличилась существенно? Я искала переменные, чьи р-значения упали как минимум на порядок (в 10 раз), чтобы выяснить, какие из переменных в сокращённой модели оказались важнее, чем в полной.
Выяснилось, что в сокращённой модели выросла значимость переменных:
- Стаж программирования.
- Вклад в open source.
- PHP.
Коэффициенты для этих переменных тоже изменились, но не драматично. Всё вместе это означает, что если убрать данные о табуляциях и пробелах, то модель скомпенсирует это за счёт стажа и вклада в open source (а также тем, работаете ли вы с PHP). Опыт — очевидный фактор, влияющий на зарплату, что не удивительно. Моим следующим кандидатом для расследования стал opensource.
Я подробнее рассмотрела данные о вкладе в opensource и сделала интересный вывод о том, что это связано с более высокой зарплатой, как минимум если вы живёте в США. Вероятно, люди с более высокими зарплатами чаще вносят свой вклад в движение за открытый код? Этот эффект наблюдается во всём диапазоне опыта.

Сторонники open source чаще используют пробелы
Как opensource связан с нашими дебатами относительно пробелов и табуляций? Похоже, участники opensource-движения используют пробелы гораздо чаще других. Среди тех, кто не участвует в opensource, примерно поровну использующих табуляцию и пробелы.

Среди участников opensource «пробельщиков» более чем вдвое больше, чем использующих табуляцию. Это различие также статистически значимо учитывая р-значение 9,1981718?10?24. Та же тенденция наблюдается и в других странах, хотя там сторонники opensource используют табуляцию чуть чаще.

Думаю, теперь мы ближе к потенциальному объяснению причин полученных Дэвидом результатов. Главное преимущество табуляций — возможность настройки их отображения в IDE, а с пробелами получается фиксированный макет. Это означает, что для разных людей один и тот же код с табуляциями будет выглядеть совершенно по-разному. А когда начинают смешивать пробелы и табуляция в одном файле, то это приводит к бардаку. Я думаю, что когда над opensource-проектом работают без принятия единого стиля кода, то возможные проблемы с форматированием заставляют людей использовать пробелы, чтобы код выглядел для всех одинаковым.
Это лишь одна из возможных теорий. Я не оценивала, насколько активно участвуют в opensource сообщества языков, где преимущественно используются пробелы (например, Python или Ruby). Повторюсь, корреляция не предполагает причинности.
Табуляция, пробелы, open source и зарплата: как всё это совместить?
Теперь вопрос: объясняет ли работа в opensource более высокие зарплаты у тех, кто использует пробелы чаще табуляций? Если построить график зарплат на основе данных о вкладе в opensource и виде отступов, то получим более сложную картину, чем в исходной статье, где сравнивались только пробелы и табуляция.

Джуниоры, использующие пробелы и табуляцию, участвующие в opensource, имеют чуть более высокую среднюю зарплату, чем не участвующие «пробельщики». А участвующие в opensource, имеющие стаж более 15 лет и использующие табы, имеют более высокую среднюю зарплату, чем «пробельщики». Кроме того, если у вас стаж меньше 15 лет и используете табуляцию, то участие в opensource не влияет на зарплату. Но если используете пробелы, то при участии в opensource будете получать больше, чем если участвовать не будете. Эти результаты можно воспринимать с определённой долей скепсиса, потому в некоторых группах результаты относительно малы.
В целом какой-то эффект есть, но он не меняет общей картины: «пробельщики» в целом зарабатывают больше, чем те, кто использует табы. Есть ещё что-то, что можно проанализировать?
Исследуем распределения зарплат
В этот момент я была убеждёна, что любые переменные, влияющие на зарплаты «пробельщиков» и тех кто использует табуляцию, не входили в простую регрессионную модель. Я не хотела выполнять мартышкин труд и добавлять все доступные переменные (их более 150, и все категорийные). Я решила проанализировать распределения зарплат для разных видов отступов: имеют ли «пробельщики» в целом более высокие зарплаты, или есть подгруппы «пробельщиков», искажающих результаты?
Я построила график с разными стажами. Ниже показаны плотности распределения зарплат для разработчиков со стажем менее 5 лет, здесь эффект наиболее заметен. Все три распределения имеют основной пик в районе одного уровня зарплаты в районе $65 000—70 000. Этот пик отражает большинство джуниоров, и судя по всему, здесь использование пробелов и табуляций никак не влияет на зарплату.

Любопытно, что распределение зарплат «пробельщиков» является бимодальным (имеет два пика). Большинство получает те же деньги, что и другие разработчики, но есть две подгруппы, преимущественно использующие пробелы и получающие гораздо больше остальных. Чем они отличаются? Я поискала ответ на этот вопрос в результатах исследования. Для этого использовала ?2, чтобы посмотреть, сильно ли различалось количество «пробельщиков» и тех кто использует табы в разных категориях.
Важность версионирования
Поскольку количество программистов в категории с высокими зарплатами было невелико, у меня получилось много потенциальных кандидатов. Меня удивило, что одной из переменных, чьи значения сильно отличаются для высокооплачиваемой группы и остальных, является версионирование. Я отфильтровала системы версионирования, часто использующиеся джуниорами в США (как минимум по 20 пользователей в исследовании):
| Зарплата выше | Зарплата ниже | |
|---|---|---|
| Git | 168 | 660 |
| Другая система | 17 | 30 |
| Subversion | 4 | 47 |
| Team Foundation Server | 6 | 92 |
Оказывается, использование системы версионирования зависит от используемого вида отступов, и это справедливо для разработчиков по всему миру, не только для джуниоров в США (p-значение 1,5336476 х 10-44)! Это означает, что есть твёрдая связь между табуляциями, пробелами и системами версионирования.
Давайте проанализируем этот факт. Две самые популярные среди американских разработчиков системы (как минимум по 200 пользователей в датасете) — Git и Team Foundation Server (TFS). Как они влияют на зарплаты?

Пользователи Git зарабатывают больше вне зависимости от опыта. Интересный вывод, который может быть связан с нашим предыдущим исследованием участников opensource. Но куда интереснее, как связано всё вместе: версионирование, табуляция с пробелами и зарплата?

Системы версионирования разрушают шаблон, что высокие зарплаты всегда ассоциируются с использованием пробелов. Компании, использующие Git, платят больше денег вне зависимости от вида отступов, как минимум разработчикам со стажем вплоть до 10 лет! Использующие Git и табы, зарабатывают больше «пробельщиков», использующих TFS, вне зависимости от опыта. В группе пользователей Git «пробельщики» всё ещё имеют более высокие зарплаты. Но в группе TFS ситуация иная: «пробельщики» получают меньше всего.
В других странах картина несколько отличается, но вы всё равно вряд ли захотите быть программистом со стажем 15+ лет, использующим пробелы и TFS.

Также я проанализировала пользователей системы Subversion, в мире она чуть популярнее TFS. Subversion тоже не подтверждает утверждение, что «пробельщики» в целом зарабатывают больше. Пользователи «Git + табуляция» зарабатывают почти столько же, сколько «Subversion + пробелы» и «Git + пробелы и табуляция».

Итог №1: Почему важно версионирование?
Подводя итоги, комбинация факторов «участие в opensource» и «использование системы версионирования» как минимум отчасти влияет на разницу зарплат между пользователями табуляций и пробелов. Это не означает, что вы должны начать использовать Git и вносить вклад в opensource, чтобы вам платили больше (хотя в любом случае это приветствуется!).
Думаю, эти два фактора указывают скорее на разницу окружений и типов компаний, насколько они придерживаются традиционных подходов и используют современные технологии. Более консервативные олдскульные компании, не использующие Git и opensource-код, в целом платят меньше. Тип окружения трудно оценить напрямую из результатов исследования, так что оба этих фактора лишь косвенно наводят на подобные размышления.
Это не конец истории, и я уверена, что есть другие переменные, которые могут пролить свет на ситуацию с пробелами и табуляциями. Также мои выводы в целом основаны на данных о разработчиках из США, здесь эффект наиболее заметен. Ниже я расскажу, почему у меня возникли проблемы с анализом зарплат в других странах.
Почему я анализировала только американцев?
Когда я оценивала распределения зарплат с учётом других факторов, моё внимание привлекла одна вещь, которая для меня непонятна. Данные, с которыми я работала, относились только к профессиональным разработчикам, работающих полный рабочий день. Но есть и большая группа людей с очень низким годовым доходом меньше $3000. К сожалению, само по себе это неудивительно, потому что доходы в разных странах мира различаются очень сильно. Но странным было то, в каких именно странах люди получают такие низкие зарплаты.

Больше всего низкооплачиваемых респондентов было из Индии, что вполне понятно в данном контексте. Средняя зарплата в Индии значительно ниже, чем в других странах ОЭСР. Но после неё идут Польша, Россия и даже Германия. Там, возможно, не гигантские зарплаты, но сильно меньше $3000 в год для разработчика на полную ставку — крайне мало.
Я сам приехала из Чехии, поэтому знаю об особенностях региона и у меня есть предположение, почему такая странная ситуация с данными. Поэтому проверила распределение зарплат в паре стран из Центральной и Восточной Европы, а также сравнила их с распределениями в странах из других частей мира.


В таких странах, как Великобритания, Франция и даже Индия, распределения зарплат имеют один пик. А во всех странах Центральной и Восточной Европы — два пика. Первый соответствует очень низкой зарплате, второй — большой, куда большее соответствующей годовому доходу. Это менее выражено в Германии, более выражено в Польше и гораздо больше — в России. Я проанализировала ещё несколько стран, включая Чехию и Украину, там эта тенденция тоже существует. Во всех странах этого региона бимодальное распределение зарплат. Что там происходит?
Согласно моему опыту, чехи всегда обсуждают зарплаты с точки зрения не годового, а месячного дохода. Я никогда не слышала от чехов, чтобы они говорили о годовом доходе. Мой польский друг подтвердил эту версию — все оперируют только месячными доходами. Похоже, многие респонденты просто невнимательно прочитали вопросы в исследовании и назвали свои месячные доходы, а не годовые, потому что именно этим понятием они оперируют в повседневной жизни.
Можно ли как-то поправить данные? К примеру, создать смешанную модель и умножить низкозарплатную группу на 12. Так мы получим распределение, усечённое слева, но точнее отражающее реальные зарплаты в странах по сравнению с изначальными распределениями. Вот пример Польши:
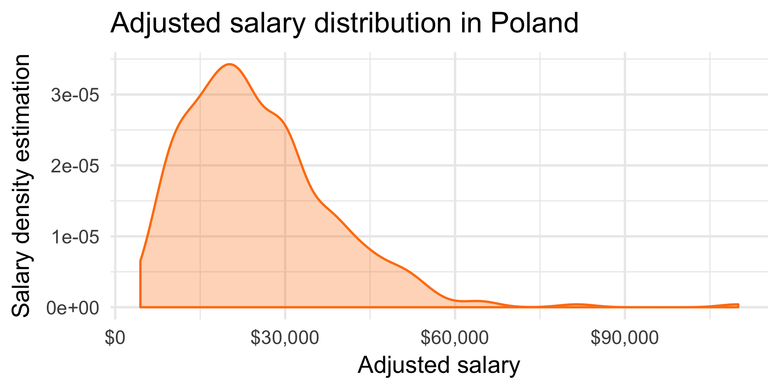
Итог №2: Ловушки в данных
Главный вывод заключается в том, что к данным всегда нужно относиться внимательно. В результатах исследования есть много искажений, и некоторые из них весьма неожиданные. Если бы я не была знакома с особенностями менталитета, то вероятно предположила бы, что в ряде стран действительно очень много низкооплачиваемых позиций уровня стажёров. Я не уверена, из каких именно стран респонденты называли ежемесячные зарплаты вместо годовых, поэтому ограничился при анализе американской выборкой. Надеюсь, эти данные наиболее консистентны.
К сожалению, люди не всегда корректно отвечают на вопросы исследований, и это очень трудно обнаружить. Возможно, это повлияло и на ситуацию с пробелами и табуляциями. Учитывая реакцию в соцмедиа, кто-то указал использование табуляций, потому что нажимают клавишу Tab, даже хотя табы неявно преобразуются редакторами в пробелы.
Итог №3
Я вполне уверена, что разница в доходах между «пробельщиками» и тему кто использует табы в основном связана с типом компании и рабочим окружением. Окружения, где используется Git и вносится вклад в opensource, больше ассоциируются с более высокими зарплатами и пробелами. Уверена, что есть и другие факторы. Но будьте внимательны: никогда нельзя целиком доверять данным.
В завершение хочу поблагодарить Дэвида за предоставленный им код и Stack Overflow за публикацию данных из исследования. Можете скачать мой код, который я использовала для этого анализа.
Комментарии (143)

Alexeyco
27.06.2017 15:22+2Кроме того, если у вас стаж меньше 15 лет и используете табуляцию, то участие в opensource не влияет на зарплату. Но если используете пробелы, то при участии в opensource будете получать больше, чем если участвовать не будете.
Нет, я понимаю, что это такая фигура речи. Но звучит забавно… как будто рекомендация.

edge790
27.06.2017 15:38+15а) Табы и пробелы отображаются у всех по разному(у меня размер таба = 2 пробела, а стандартный = 4) поэтому в больших компаниях создают / используют Coding Conventions с целью на пробелы(т.к. гораздо сложнее следить чтобы у всех всё было "правильно")
б) Одна из самых популярных code style'ов, которые может использовать любая компания, вместо изобретения своих велосипедов, для улучшения качества кода является Google Code Style, который для всех языков советует использовать пробелы. (Следовательно все сотрудники гугл используют пробелы), а бОльшая часть open source проектов на них ссылается
в) "Те странные ребята постоянно стучащие по пробелу" на самом деле просто люди, которые умеют настраивать IDE, чтобы она автоматически вместо таба ставила пробелы (например при импорте Google CodeStyle'а в любую Intellij IDE эти настройки проставляются автоматически, и разработчик даже не видит разницы)
P.s. я не вижу ни одной причины для крупных компаний использовать табы в коде, тем более и табы и пробелы, отсюда и закономерность: Большие компании с хорошим качеством кода = Пробелы => сотрудники больших компаний с хорошим качеством кода = пробелы |= зарплата
alexeykuzmin0
27.06.2017 15:58+3С табами еще одна проблема есть: периодически в коде приходится выравнивать относительно друг друга строки с разной идентацией, например:
илиif (first_part_of_long_condition() || second_part_of_long_condition())
В таком коде, если написать его с табами, при изменении размера таба все развалится.int class_with_long_name::method_with_long_name(type1 param1, type2 param2, type3 param3, type4 param4)edge790
27.06.2017 16:05+2Да, спасибо. Я это и хотел сказать в первом пункте, но описал только причину и решение, вместо самой проблемы...
Goury
27.06.2017 18:22+5С табами только одна проблема: культисты не понимают когда их надо использовать и когда не надо.
Всё очень просто: для индетнации надо, для выравнивания — нет.
Вот так:
https://pastebin.com/zGcpQdss
И ничего никуда не уедет ни при какой настройке ширины табов.
Странно что двадцать лет назад это было очевидно каждому программисту, а сегодня почему-то придумывают какие-то сомнительные кодстайлы.
AngReload
27.06.2017 19:37+5Для поддержки такого смешанного стиля придется подсвечивать табы и пробелы, а выглядит это не очень. О пробелах проще договориться.
Если использовать для соответствия кодастайлу
- автоматическую конвертацию пробелов в табы при открытии файла и
- обратную при сохранении файла
то IDE такие участки поломает.
Goury
27.06.2017 19:40Поэтому не надо допускать культистов до кода в приличных проектах.
Не культистам почему-то подсветка вайтспейса не мешает и даже помогает.
И никаких костылей с конвертациями почему-то не нужно.

Pakos
28.06.2017 10:35После чего ещё и подчищать за IDE при переносе, когда вставила не то и не туда. Двадцать лет назад кому-то где-то было очевидно. но более 20 лет назад вполне пользовались пробелами без табов и спокойно работали.

LynXzp
28.06.2017 03:16-2А в первой строчке запрещено ставить табы?

Мне кажется как раз выравнивание табами это еще одна их сильная сторона — если приходиться изменять выровненный текст, то в случае с табами заново выравнивать придется меньше.Dionis_mgn
28.06.2017 10:44+2Поставьте размер таба == 2 пробела и удивитесь. Для отступов — табы, для выравнивания — пробелы.
LynXzp
28.06.2017 14:05Я не вижу принципиальной разницы между этими тремя правилами:
— использовать только пробелы;
— только табы и они фиксированной ширины;
— для отступов — табы, для выравнивания — пробелы.
Чтобы все у всех было хорошо достаточно одного из трех.
Поставьте размер таба == 2 пробела и удивитесь.
И будет не выровненный код в первой строке, как обычно выглядит даже при использовании пробелов в большинстве кода что я встречал (в смысле мало кто выравнивает вообще). К тому же есть функции конвертации одного стиля в другой, но табо-пробельного я не встречал, если Вы так программируете, то наверное и знаете такие. И это происходить должно один раз при импорте стороннего кода в проект, а в проекте уже одно из трех правил выше.

medvedGrizli
29.06.2017 12:38+1Работал в одной компании, где code conventions предусматривали смешанное использование пробелов и табов. Долго воевал за пробелы, но аргумент от тимлида был — у каждого свои настройки табов, которые ему удобны, и мы должны уважить каждого. Достаточно сложно было контролировать правильную расстановку, но ничего не ехало. Но я все-таки предпочитаю пробелы, так как создавать самому себе лишние сложности в виде контроля расстановки табов и пробелов вместо сосредоточения на написании кода как такового — такое себе занятие.
<tab>int class_with_long_name::method_with_long_name(type1 param1, type2 param2, <tab> type3 param3, type4 param4)michael_vostrikov
29.06.2017 18:50+1Ну я так понимаю, начальный таб IDE сама вставляет. Получается, неудобство в том что надо много пробелов вручную добавлять, раз они теперь табом не вставляются.
Предлагаю решение — сделать общепринятый хоткей Shift+Space, который будет вставлять 4 пробела) Или 2, или 8. А таб использовать для логического отступа, для чего его обычно и нажимают.medvedGrizli
30.06.2017 00:10Да, в целом как вариант. Но я сейчас преимущественно пишу на python, поэтому обозначенная проблема отпадает сама собой.

Algoritmist
27.06.2017 16:10Поддерживаю! Это косвенно показывает опыт работы с чужим кодом. Давно надоела пляска с отступами в разных средах. Всегда залезаю в настройки системы, а там вместе с отступом включаю и автозамену табуляции пробелами (если есть возможность).
Goury
27.06.2017 18:16-13Карго культ силён в демагогах.
а) Зачем кому-то нужно чтобы у всех всё отображалось одинаково?
Может ещё набирать людей одного роста, пола и цвета кожи и чтобы с абсолютно одинаковыми интересами?
И имена запретить использовать, обращаться только по идентификационному номеру.
А то вдруг индивидуальность проявится, а там недалеко и до бунта, забастовки, теракта и революции.
б) А ещё гугл когда-то не делал бекапы и устроил пожал в своём датацентре. Наверное потому что они самые умные в мире.
Поэтому срочно всех разработчиков переводим на виндовс и на обед выдаём кокаколу.
Ведь миллиарды мух не могут ошибаться.
в) Именно те самые разработчики, которые не видят разницы, и являются проблемой для тех, кто видит.
И именно из-за того, что таких развелось очень много, в некоторых компаниях вводят пробелы в практику.
Это оказывается дешевле чем научить эту толпу настраивать отображение whitespace.
Итого, аргументы за табы: занимают меньше байтов и настраиваются для удобства и нет проблемы с копипастом (да, редактор сам сконвертирует пробелы в случае чего, а вот с пробелами это сработает только если их количество на отступ одинаково, что бывает не всегда).
Аргументы за пробелы: миллионы мух и непонимание табов.alexeykuzmin0
27.06.2017 18:28+3Коммент был не мне, но все же отвечу.
Нужно, чтобы у всех отображалось читабельно, не обязательно одинаково. Посмотрите на пример кода из моего коммента чуть выше — если его написать с табами, выравнивание будет плавать в зависимости от настроек редактора. А что, если два таких куска кода в одном и том же файле написали два разных человека, и у одного таб был размера 2, а у другого — 8?
Итого, аргументы за табы: сэкономить пару мегабайт размера репозитория для большого проекта.
Аргументы за пробелы: добиться гарантии читабельности кода вне зависимости от редактора.
Ну, тут уж каждый выбирает, что ему важнее в проекте.Goury
27.06.2017 18:35+5А что если включить голову и понять что «для отступов табы, для выравнивания пробелы»?
И внезапно ничего никуда больше не плавает, но настроить отступы всё-равно можно.
Итого аргумент против допуска к коду людей, не понимающих чем отступ отличается от выравнивания.
И это уже не говоря о том, что
int class_with_long_name::method_with_long_name(
?type1 param1,
?type2 param2,
?type3 param3,
?type4 param4
)
Читается гораздо лучше той каши из параметров.alexeykuzmin0
27.06.2017 19:16+9Что ж, действительно, при использовании указанного вами правила больше ничего никуда плавать не будет.
Вот только я не знаю ни одного тула, который мог бы автоматически проверить это правило, и не уверен, что они вообще существуют. Значит, правило будет проверяться вручную, а проверка расстановки whitespace символов вручную — не самое приятное занятие — оно отнимает время (которое куда дороже тех пары мегабайт места), снижает мотивацию команды, и тд.
Так что на практике, скорее всего, это правило, даже если будет задекларировано, не будет проверяться никак. А если учесть, что все мы люди и все иногда ошибаются, в кодобазе постепенно будет копиться код, в котором пробелы и табы расставлены неправильно, причем я уверен, что в компании из хотя бы пары сотен человек такое будет случаться каждый день. Так что да, это решение, но нереализуемое для более или менее приличного размера команды, и довольно дорогое.
Ну, в любом случае, каждый выбирает для себя то, что ему важнее. Может, вам и правда каждый байт дискового пространства для хранения кода стоит кучу денег?
PS: А насчет того, что параметры лучше в один столбец писать — откуда вам знать, может, они по смыслу сгруппированы?Goury
27.06.2017 19:34-2Любой тул для проверки кодстайла можен быть сконфигурирован для проверки любого правила.
Внедрять в крупной компании тул, который почему-то никто не может настроить — отличный пример культизма.
А насчёт PS — я здравый смысл ещё не пропил чтобы понять логику этих параметров.
Regis
27.06.2017 21:24+1Расскажите пожалуйста, как вы предполагаете проверять, правильные ли для куска кода отступы или нет? Ведь для этого нужно 1) понимание кода и 2) понимание, что с чем автор хотел выравнять. Это как минимум не тривиальная задача. И мне не известно ни одного инструмента проверки кода, который бы это уже умел делать.
Dionis_mgn
28.06.2017 10:55Вот только я не знаю ни одного тула, который мог бы автоматически проверить это правило, и не уверен, что они вообще существуют.
clangFormat мало того, что умеет так делать, так ещё и существует.
На моей практике проблемы с данным подходом возникают редко. И сразу видны глазу (я работаю с отображаемыми whitespace'ми уже давно. Много дольше, чем придерживаюсь системы «табы — для отступов, пробелы — для выравнивания»).
Аргумент про «будет копиться неправильный код» — это именно то, о чем говорил Goury. Тимлидам проще смириться с пробелами, чем объяснить, как пользоваться табами.
Free_ze
27.06.2017 19:26-1Ага, название метода в одной стороне, параметры — в другой. Всесто группировки на привычном для параметров месте они вывалились куда-то к подножью объявления. Их положение не несет никакой смысловой нагрузки, кроме той, что в одну строку бы они не влезли бы в экран.
Goury
27.06.2017 19:37А ещё можно так:
args = (
?type1 param1,
?type2 param2,
?type3 param3,
?type4 param4
)
int class_with_long_name::method_with_long_name(*args)
Довыровнять пробелами не мешает ничего кроме приверженности культу.Free_ze
27.06.2017 19:48Что значит «довыровнять»? С другим размером таба милота все равно поедет, вопрос лишь в том, насколько далеко. Какая практическая польза в этом, кроме как прятать исходники на whitespace?
Goury
27.06.2017 22:16-7Довыровнять значит что для отступов нужно использовать табы, а для выравнивания — пробелы.
Если не понимаешь чем выравнивание отличается от отступа — это не ко мне.Free_ze
28.06.2017 09:48+2Вы бы на вопрос о пользе ответили, а не выкабенивались.
Dionis_mgn
28.06.2017 11:01Вы бы постарались понять, что человек донести хочет, а не вот это вот всё. Тогда и вопросы не возникли бы. Он на них, кстати, уже отвечал выше.
Free_ze
28.06.2017 11:29Вот я и стараюсь понять, ибо его примеры показывают только использование табов, без «довыравнивания» пробелами.
Goury
28.06.2017 11:40-3Польза в лучшей читаемости, что ведёт к сокращению ошибок.
Если не получается понять чем выравнивание отличается от отступов — вон из профессии.Free_ze
28.06.2017 11:46+1Польза в лучшей читаемости
Выше я писал, что читаемость ваших примеров с табами уступает пробельному выравниванию и почему.
Если не получается понять чем выравнивание отличается от отступов — вон из профессии.
Вы адекватный пример «довыравнивания» можете привести или кроме этой истерики от вас ничего не получится добиться?
Dionis_mgn
28.06.2017 12:06Он давал ссылку вот на это: https://pastebin.com/zGcpQdss смотреть надо в исходном (raw) виде.
Free_ze
28.06.2017 12:37Параметры функции разъедутся относительно первого из них.
Dionis_mgn
28.06.2017 12:51Нет. Выравнивание там выполнено пробелами. Отступы — табами. Что тут сложного то? it's not rocket science.
Free_ze
28.06.2017 13:00Начиная со второго параметра, перед каждым стоит один таб в начале строки. И не суть важно, сколько там дальше идет пробелов, при изменении размера таба вся эта колонка едет. Вместо тысячи слов просто попробуте в своем любимом редакторе (=
Dionis_mgn
28.06.2017 13:41У меня просто нет слов. Давайте я вам картиночками покажу, как ребёнку? Из своего любимого редактора, да. https://ibb.co/fTxMTQ

Gendalph
01.07.2017 10:58Тот же Bash не всегда корректно переваривает табы, да и большинство консольных редакторов принимают таб равным 8 пробелам, что ниразу не читабельно, я локально в редакторе настраиваю 4 пробела, ну а в некоторых местах у нас принято 2 пробела...
Поэтому — пробелы.
Goury
01.07.2017 11:56-3Назови мне хоть один редактор, в котором нельзя настроить ширину таба, культист.
Баш всегда корректно переваривает табы.
grossws
01.07.2017 15:02ed, т. к. tab stop'ы настраиваются не в редакторе, а в терминалеGoury
01.07.2017 15:21-3>> настраиваются
Культисты врут и не краснеютgrossws
01.07.2017 15:44По существу возражения будут? Или вы обосрались и, в очередной раз, перешли на личности?
Goury
01.07.2017 16:55-3В очередной раз обосрался ты, а не я.
И на личности сейчас перешёл ты, а не я.
И то, что такой контингент тут процветает, лишний раз подчёркивает что швабра скатилась в самое сраное днище.grossws
01.07.2017 17:51+2Давай, покажи в
ed(1P)регулирование размера таба. А по поводу терминала рекомендую ознакомиться сtermcap(5)в особенности со свойствамиit,ct,st,

CrazyFizik
28.06.2017 17:09Что значит будут плавать? У каждого своя IDE со своими настройками, каждый видит код именно так как он настроил отображение в своей среде разработки. Так что это вообще никого не должно касаться у кого какие табы — это дело вкуса, который не уходит дальше разработчика. Или погромисты нынче бедные пошли и и работают на одной машине в блокноте вдесятером по очереди?
Тем более табуляция сохраняет пропорции в коде независимо от разрешения экрана.
А вот с пробелами как раз все плывет: кто-то любит дважды жахнуть по клавише, кто-то четырежды, кто сидит за моником 4:3, кто-то за 16: 9, а кто-то 16:10. Табуляция позволяет сохранить пропорции отступов, пробелы нет.
Детский сад какой-то. Не, ну можно, конечно, отказаться от табуляции, всех обязать печатать определенное количество пробелов в той или иной ситуации, посадить за одинаковые машины, одинаково постричь(налысо) и одеть, пришить номера на одежду, а печатать синхронно с в темпе барабанщика (или надзирателя с хлыстом) — ляпота…grossws
28.06.2017 20:24А вот с пробелами как раз все плывет: кто-то любит дважды жахнуть по клавише, кто-то четырежды, кто сидит за моником 4:3, кто-то за 16: 9, а кто-то 16:10. Табуляция позволяет сохранить пропорции отступов, пробелы нет.
Детский сад какой-то. Не, ну можно, конечно, отказаться от табуляции, всех обязать печатать определенное количество пробелов в той или иной ситуации, посадить за одинаковые машины, одинаково постричь(налысо) и одеть, пришить номера на одежду, а печатать синхронно с в темпе барабанщика (или надзирателя с хлыстом) — ляпота…По-моему, детский сад устраиваете вы. Во всех разумных редакторах и IDE есть в том или ином виде поддержка soft tab stops. Обычно никто не жмёт пробелы, а спокойно использует автоформатирование, клавишу tab для отступа и автоматическую вставку отступа после открытия блока (будь то curly braces, do/end или что-то ещё).
edge790
27.06.2017 18:44+2Я надеюсь, что вы так шутите, но всё же отвечу на ваш комментарий:
а) Зачем кому-то нужно чтобы всё отображалось одинаково?
1) Форматирование кода ведет к более быстрому обнаружению ошибок = > улучшают программу
2) Паттерн билдер и (не помню как это называется, вроде chain-call) когда метод возвращает инстанс самого объекта для конфигурирования — у меня таб = 2 символа, у кого-то 4 следовательно и по разному это всё будет выглядеть: кто-то по отсупам будет сразу видеть что это вызов всё того же билдера, а кто-то не будет понимать почему это так
3) Как заметил выше alexeykuzmin0, выравнивание параметров функции в столбик
Может ещё набирать людей одного роста, пола и цвета кожи и чтобы с абсолютно одинаковыми интересами?
Код стайл у всех должен быть одинаковый — он упрощает понимание кода. В команде более чем из 5 человек это серьёзно увеличивает производительность (например Класс с большой, метод с маленькой, константы SCREAMING_SNAKE_CASE'ом — только по названию мы видим что есть что, а IDE (в моём случае IDEA) и вовсе по кейсу делает подсказки. Если я не смогу найти класс из-за того, что он написан с маленькой буквы и потрачу на это дело кучу времени — я буду недоволен, как минимум. А про производительность команды в целом, я вообще молчу.
И да. В этом воопросе я не вижу связи с рассизмом. Не надо утрировать.б) Не вижу как это относится к тому что компания, имеющая огромную кодовую базу и тысячи сотрудников составила и выложила в открытый доступ рекомендации по написанию кода. Если они вас не устраивают, то вы можете не следовать им, а следовать например Oracle Code Conventions или любым другим в зависимости от вашего языка. Рекомендации, на то и рекомендации, что, в основном, следование им, делает жизнь проще.
P.s. что гугл — самые умные в мире, я не говорил не слова(хотя спорить с этим я бы не стал, но это "моё личное скромное мнение"), но то что у них одни из самых больших зарплат(а это то что обсуждается в статье) и веб-сервисы, использующиеся сотнями миллионами людей — это факты.
в) Какая разница другим людям, от того что я вижу таб в два пробела, делаю таб, в два пробела и вообще использую пробелы, если я их комичу пробелами в репозиторий, а остальные их видят как захотят(либо пробелами, либо как я "псевдотабами")
То что они занимают меньше байтов — это не проблема, для компании, у которой столько кода, что ей не хватает обычного облака.
Со вторым, я поспорить не могу. Можете поискать/написать плагин, который вместо двух пробелов будет отображать 4.Goury
27.06.2017 19:08-7Культ самолётников он на то и культ самолётников, что культисты следуют ему непонятно зачем.
Они думают что если построить храм самолёту — появится еда.
Но еда не появится.
И от бездумного использования гуглостиля никакие проблемы не решатся, а вот от непонимания — точно появятся новые.cyberzx23
28.06.2017 13:30+2Прекратите это дурацкое манипулирование своим неуместным карго культом. Здесь вам не балаган. Уважайте собеседников и приводите адекватную аргументацию.
Goury
28.06.2017 13:44-5Здесь именно балаган культистов.
Аргументация приведена многократно.
Но каждый культист-демагог считает своим долгом обосрать любую точку зрения, выходящую за рамки его культа.
До свидания.
dimm_ddr
28.06.2017 13:44+1Извините, но на данный момент на культиста здесь больше всего похожи вы. Все остальные пытаются как-то обосновать мнения и только вы говорите что есть вот такое правило и с ним все хорошо.
Goury
28.06.2017 13:56-5Да нет, все остальные — это кучка культистов-демагогов, которые сливают любого, кто посмеет намекнуть на их неправоту и потом бегают за ним по всей швабре и рассказывают какие они все хорошие и как он ничего не умеет обосновывать.
Даже не удосужившись прочитать его железные обоснования парой каментов выше
Конечно же прочитав его железные обоснования. Но теперь надо быстро-быстро его заминусовать и посильнее обосрать, чтобы никто другой ни в коем случае не пошёл читать обоснования.
Чтобы все думали что он дурак, а культисты — самые правые.
Ни в коем случае не допустить распространения информации об отличиях отступов от выравнивания.
Правда же, гораздо проще помешать распространению знания чем пытаться научиться чему-то новому. Ведь если знание распространится — окружающие смогут понять что ты на самом деле дурак.
Наииомерзительнейшее у вас тут сообщество.
И оно такое благодаря тебе и таким как ты.
До свидания.kenik
28.06.2017 14:59+1Извините, вклинюсь сюда немножко не по теме…
Ни в коем случае не допустить распространения информации об отличиях отступов от выравнивания.
И выше в комментах ваши же комментарии:
Если не понимаешь чем выравнивание отличается от отступа — это не ко мне.
Если не получается понять чем выравнивание отличается от отступов — вон из профессии.
Я немного не понял, где тут распространение знания?
P.S. Сам использую только пробелы (исторически так сложилось). Переучиваться смысла не вижу да и не хочу. Хотя ничего против табов как таковых не имею.Goury
28.06.2017 15:05-4>> Я немного не понял
Конечно ты не понял. Ведь прочитать ветку комментариев с начала, а не с конца, это же непосильная для твоего уровня задача.kenik
28.06.2017 15:30+4Слишком много неуместной агрессии, слишком мало распространения знаний. Я прочитал всю ветку и понял о чем речь, я не понял возмущения. Комментарий со ссылкой, например, в плюсе, потому что там конкретный пример. Провокационные и излишне агрессивные комментарии без особой смысловой нагрузки в минусе. Всё вроде по делу.
dimm_ddr
28.06.2017 15:41+4Но ведь это же вы при намеке на вашу неправоту обзываете окружающих культистами и отказываетесь что-либо объяснять. Все что я увидел у вас: "Вот мой способ он работает". Ну да, работает. Почему вы при этом отказываетесь принимать то, что могут быть другие работающие способы то? Так что это именно вы отрицаете все остальные способы.
При этом вы умудрились заклеймить меня только за то, что я усомнился в вас — то есть сделали ровно то, в чем обвиняете местное сообщество.
grossws
27.06.2017 20:37+6аргументы за табы: занимают меньше байтов
Если развить этот аргумент, то одна буква на имя переменной/функции/файла — идеальный вариант. Но большинству адекватных разработчиков почему-то не нравится.

KvanTTT
28.06.2017 00:39Видимо существеннее это влияет на размер гит репозитория, если коммитов много. Хотя это тоже скорее всего мелочь.
grossws
28.06.2017 02:22Если средняя глубина отступов — 2.5 (а код с ощутимо большей средней величиной уже чуть более чем ужасен почти гарантированно), то экономия против 4 пробелов на отступ составит ~7-8 байт на строку. Куда выгоднее сокращать имена переменных, функций и классов/структур, их, в среднем, набирается ощутимо больше 8 символов на строку...
Pakos
28.06.2017 10:42Зачем кому-то нужно чтобы у всех всё отображалось одинаково?
Чтобы не было "стихов Маяковского", читать которые значительно сложнее и чтобы код на экран помещался, а то код от таб-2-пробела после попадания в среду таб-8-пробелов станет слабочитаемым. Остальная часть вашего абзаца выглядит бредом демагога карго-культа.
устроил пожал
Гуглопожатые?
аргументы за табы: занимают меньше байтов
На достаточно большом диске в 360КБ на пробелах не экономил, а сейчас вот обязательно начну, убедили. И наплевать на удобство.
В IDE есть выравнивание кода, после вставки он отформатируется под нужное выравнивание. Как итог — единственный аргумент за табы годится только не умеющим в настройку среды.

semmaxim
29.06.2017 08:571. Для этого в Coding Conventions можно прописать, что tab == 4 пробела. Но вообще, это не имеет смысла — одному удобнее отступ в 2 пробела, другому — 4. И оба этих человека могут работать с одинаковым кодом и у каждого этот код будет отображаться как им удобно. Так что этот аргумент скорее за табы, а не пробелы.
2. Ну да, конечно. Их code style написан в доисторические времена и для очень большого разнообразия языков — вплоть до скриптов, которые правились в Блокноте.
3. Опять же, нафига что-то настраивать? Нажал на tab — вставился tab. И всё. Опять же аргумент в пользу табов.
P. S. Я не видел НИ ОДНОЙ здравой причины использовать пробелы вместо табов. Меня дико бесят отступы пробелами, когда кликнул мышкой — и курсор где-то в середине отступа оказался, когда каждый код выглядит по-разному (просто в одном отступы 2 пробелами, в другом — 4, в третьем вообще 8).
Movimento5Litri
04.07.2017 10:55Одна из самых популярных code style'ов, которые может использовать любая компания, вместо изобретения своих велосипедов, для улучшения качества кода является Google Code Style, который для всех языков советует использовать пробелы
В Гугле создали язык Go в котором использование табов обязательно, лол.
Goodkat
27.06.2017 15:46+31Всё ж наоборот. Пробелы вместо табов программисты соглашаются использовать лишь за дополнительные деньги :)

saboteur_kiev
27.06.2017 15:57-6На каждой строчке на целых 7 пробелов больше написал, в конце месяца у тебя на несколько килобайт написанного кода больше. Получи премию.
Alexeyco
27.06.2017 17:28-2Ага… а для виндузятников еще знаю вариант. Но это если оценка идет по объему кода в килобайтах. Берем исходник, ставим у него кодировку UTF-8 и все.

professor_k
27.06.2017 17:40+1… Просветите виндовзятника: а в линухах кодировок нет?
Alexeyco
27.06.2017 18:02Ой, ну не надо только вредничать. В виндах или в линухе чаще всего можно встретить файлы в кодировке какой-нибудь типа win1251?

mogaika
28.06.2017 02:26Там просто русский текст в исходниках реже (нет 1с?). Иначе откуда взять разницу в размере от переезда на UTF-8?

d1Mm
27.06.2017 17:48+3При отсутствии в коде символов юникода размер не изменится. Стандартные символы даже в UTF-8 занимают один байт.
Alexeyco
27.06.2017 20:42+5Эммм… комментарии в коде на русском. На хорошем, размашистом, литературном русском языке. Языке Пушкина и Некрасова, ой ты Русь широкая, да возвращает же этот метод int. Гэй, хлопцы, грянем да принимает эта функция ID товара.
LynXzp
28.06.2017 03:27А еще расмашистые смайлы можно в комментарии добавить ? (???)?, говорят помогает.
Alexeyco
28.06.2017 18:09Нужно. И здоровенными буквищами в каждом файле исходников — заголовок с ASCII-логотипом продукта. И тоже с использованием кириллицы. И еще можно в каждый файл текст лицензии.
cyberzx23
28.06.2017 13:30И что всё? Код состоит чуть более, чем полностью из ANSI символов, который однобайтные в UTF-8
saboteur_kiev
28.06.2017 01:27Удивляюсь минусам. Неужели вы действительно считаете, отчеты между двумя версиями продукта с подсчетом количества добавленных/измененных строк бывает только в анекдотах?
Я такое наблюдал вживую буквально года 2-3 назад в весьма крупных (несколько тысяч сотрудников) компаниях. И эти компании все еще живы и отлично себя чувствуют в бизнесе.KvanTTT
28.06.2017 01:50Ну так табы и пробелы не влияют на количество добавленных/удаленных строк.
LynXzp
28.06.2017 03:30Как это? У одного сотрудника в IDE стоит автозамена табов на пробелы, а у второго пробелы на табы, по очереди правят один и тот же файл — и все в профите. (Кроме системы контроля версий)
grossws
28.06.2017 05:11Хук со стороны сервера, фиксированный общий code style и checkstyle или аналог на CI (плюс битье по рукам) — спасут мир.
Т. е. локально редактировать как угодно, хоть VT и RS ставь, а в репозитории не должно быть этого мусора.
Free_ze
28.06.2017 11:44Потом, наверное, мило смотреть пулл-реквест какой-нибудь фичи, сливающейся в общую ветку.

RPG18
27.06.2017 15:51+1Все таки имеет смысл анализировать и языки программирования. В том же Golang: Effective Go:
We use tabs for indentation and gofmt emits them by default. Use spaces only if you must.

madkite
27.06.2017 19:55+5умножить низкозарплатную группу на 12
Тут ещё есть нюанс — обычно в странах, где считают месячную зарплату, её также считают после налогов (например, в России). А вот там, где считают годовую, обычно считают её до налогов (например, в западной Европе, США). В итоге все эти сравнения зарплат белыми нитками шиты.

AlexanderS
27.06.2017 21:05А если я использую табы, но у меня в нотепаде по умолчанию задано заменяеть его определённым количеством пробелов — это я тогда к какой группе отношусь? )

ecto
27.06.2017 22:10+9Вопрос к защитникам пробелов.
У каждого программиста свои предпочтения. как должен выглядеть код в его среде разработки.
Кому-то нравится темными буквами на светлом, кому то наоборот. При этом байты кода будут одни и те же, это просто настройки отображения.
Тоже самое с отступами, кому-то нравится сильный отступ. кому-то приятнее. что бы было все рядом.
Если мы используем табы, то все четко, один уровень вложенности соотвествует одному табу. В среде я могу настраивать отображать таб. как два пробела или как четыре. В файле это вcеравно будет один символ таба.
Если же мы используем проблемы, то во-первых надо убедиться, чтобы среда вставляла таб проблемами одиноковой размерности. Во-вторых, я не могу настроить представление кода, как мне удобнее.
В чем же плюс пробелов?
П.С. У меня в компании стандарт кода предписывает использовать проблелы, и я их использую, но реальных плюсов я что-то не вижу.
Free_ze
28.06.2017 11:09В чем же плюс пробелов?
Можно выравнивать по вертикали строки разной длины.
Переменный размер таба поломает картину, а переменный размер «таба пробелами» повлияет лишь на тот код, который пи шет сам программист, а чужие произведения будут выглядеть так, как задумал автор, вне зависимости от настроек.
напримерvar result = SomeCollection.OrderBy(x => x.Id) .Where(x => x.Param >= UPPER_BOUND) .Select(x => new { A = x.Id; B = x.Param.ToString(); });Goodkat
28.06.2017 12:12По-моему, ещё в Delphi 3 табы выравнивались в соответствии с предыдущей строкой, но точно уже не помню.
К тому же, такое форматирование делает IDE по нажатию ctrl+shift+F, alt+T, ?A+^I или на какое там сочетание клавиш у вас настроено форматирование кода по принятому у вас стайлгайду.
И вообще, все эти споры яйца выеденного не стоят, ведь можно настроить автоматическое форматирование кода под себя после выгрузки из VCS и в соответствии с корпоративным стайлгайдом — перед коммитом обратно.
Или тут все программируют php в vi на продуктивном сервере заказчика? :)Free_ze
28.06.2017 18:14+1Если будет такой тул, который сможет автоформатировать туда-обратно с сохранением семантического выравнивания — цены ему не будет.
michael_vostrikov
28.06.2017 12:13Одно да потому… Зачем во второй и далее строках нужно ставить символ, обозначающий отступ, если там нужно выравнивание? Нет, даже не так. Зачем во второй и далее строках нужно ставить символ, обозначающий отступ от левого края, если там нужно выравнивание относительно верхней строки?
Во всех строках начальных табов должно быть ровно столько, сколько их в первой строке.
CrazyFizik
28.06.2017 17:24Среды разработки уже давно умеют выравнивать в соответствии с предыдущей строкой. А ещё есть такая магическая команда как автоформат.
Это надо было наверное лет 30 на необитаемом острове провести, что бы пропустить такой прорыв.Free_ze
28.06.2017 18:05А чудодейственные редакторы выравнивают не табами/пробелами?)
CrazyFizik
28.06.2017 21:45Табами, пробелами, табы+пробелы. Как настроишь/как создатели посчитают нужными.
Так шо я не совсем понимаю суть срача.
Это вот когда деревья были большие, а единственной IDE были блокноты, тогда да, тогда срач был актуален, впрочем, в таком случае табуляция предпочтительнее и хардварные погромисты и прочие плисоводы это подтвердят.
С другой стороны, во всяких редакторах встречаются таки штуки, как smart spaces и прочие умные отступы, да выравнивания, кои на самом деле обычными пробелами не являются/не заполняются (думаю от редактора зависит, из того что я видел изнутри — никаких пробелов, только табуляция), а являются самыми обычными табами. Но яхз — я не спец по разработки IDE.Free_ze
28.06.2017 22:53Табами, пробелами, табы+пробелы. Как настроишь/как создатели посчитают нужными.
Срач о том, как настроить лучше.

Ritan
28.06.2017 11:49Просто если использовать табы, то писать вот такой код не получится:
int my_super_long func_name( void * my_super long_argument_name ar g) { }
А разве ж это дело, когда строка в какиих-то жалких 270 символов уезжает за пределы второго экрана при настройке отображения табов на 18 пробелов.
P.S. Единственный серьёзный аргумент — желание, чтобы у всех код выглядел одинаково. Но вообще может стоит просто писать так, чтобы не нужно было выравнивать по 30 строк?CrazyFizik
28.06.2017 17:37У меня среда разработки так выравнивает автоматически, каждый раз когда я жмакаю enter в пределах одной строчки. Чем она делает — мне на самом деле глубоко пофиг. В чем профит ручных пробелов в таком случае?
Тем более действительно, как тут уже многие высказались — отличает отступы (табы) от выравнивания.
reforms
28.06.2017 13:29Вы привели второй сильный аргумент в пользу табов — сжатие/растяжение кода на свой вкус. Первый — 1 символ, вместо n пробелов. На практике встречал 3 варианта: только пробелы, только табы и смешанный. Могу сказать, что подходит мне — пробелы, но не факт, что другим :) Хотя это уже сказано выше — у пробелов есть преимущество — это зрительная переносимость кода, можешь его открыть на работе, дома/ в блокноте, в ide — он все также выглядит одинаково. Можешь делать ревью в браузере — код выглядит одинаково. С табами этого добиться сложнее.
cyberzx23
28.06.2017 13:38Всё просто. Если вы работаете в команде, то код должен отображаться у всех одинаково. Если вы используете табы, а ещё со своей любимой шириной, то код будет выравненым только у вас. У других программистов, он может разъехаться и стать нечитаемым.
Dionis_mgn
28.06.2017 13:51Вы просто не умеете готовить табы. Они нужны для отступов. Но для выравнивания всегда нужно использовать пробелы. Пример: https://ibb.co/fTxMTQ. В итоге каждый может использовать удобную ему ширину отступа. У меня, например, она может меняться в зависимости от связки шрифт+монитор. Где-то пошире, где-то поуже. Иногда даже неканоничные значения типа 3 бывают приятны.
У пробелов есть проблема, похожая на то, что вы описали. В одном из проектов, над которыми я работаю, приняты пробелы для всего. Открываю я файл, начинаю его редактировать… А редактор облажался с определением ширины отступа и использует мои настройки. И вставляет не 4 пробела на отступ, а 2, например. Или наоборот. И такое не было редкостью. Но отображается у всех «одинаково», да. осталось только шрифт «стандартизовать» и его размер. =)
ecto
29.06.2017 20:12"У всех код должен отображаться одинаково" — выражение верно только условно. Цвет, размер шрифта, междуквенное растояние, каждый настраивает, как ему угодно. Разве есть задача чтобы все видели одинаковую картинку? Тогда и мониторы у всех должны быть одинаковые.
Я думаю тут подмена понятий и реальная задача здесь, это чтобы соблюдались стандарты кодирования. Например чтобы одинаковый код, сделаный двумя разными разработчиками выглядет одинакого при просмотре в одном редакторе. И в моем случае это соблюдается.
И моя идея была в том что табы используются только для формирования блоков. Тогда каждый может настроить, как визуально сдгивается код, на маленьком экране меньший отступ даст больше видимость кода.
Внутристрочное выравнивание — там нужны проблелы, но там и другая логика выравнивания, там нет бложеных блоков, более того, там по сути "ручная" работа.
Внутристрочное выравнивание это, например, когда несколько строк с присваиванием и хочется выровнять значение по вертикале.
grossws
30.06.2017 02:10+1Внутристрочное выравнивание — там нужны проблелы, но там и другая логика выравнивания, там нет бложеных блоков, более того, там по сути "ручная" работа.
Если вещи типа многострочного списка аргументов, заполнения массивов, chain call'ов, do-нотации и т. п., то зачем там ручная работа? Настроил IDE, нажал хоткей автоформатирования и всё.

TimsTims
28.06.2017 00:39А разве не выпустили уже быстрых автоматизаторов, которые просто добавляют на каждую строку столько табов/пробелов, сколько тебе надо? Например в редакторе Scite так сделано, для AutoIt: жмём ALT+T и
вот такой код#include <MsgBoxConstants.au3> Example() Func Example() ; Assign a Local variable an array containing the numbers. Local $aNumber[8] = [4.8, 4.5, 4.3, 4, -4.8, -4.5, -4.3, -4] ; Assign a Local variable a string which will contain the results. Local $sResults = "" ; Loop through the array: calculate the floor and format the result. For $i = 0 To 7 $sResults &= "Floor(" & $aNumber[$i] & ") = " & Floor($aNumber[$i]) & @CRLF & ($i = 3 ? @CRLF : "") Next ; Display the results. MsgBox($MB_SYSTEMMODAL, "", $sResults) EndFunc ;==>Examplealexeykuzmin0
28.06.2017 14:17Как уже писали выше, выравнивание строк относительно друг друга таким образом не сделать
WinPooh73
28.06.2017 01:26Жалко, что в число исследованных параметров не вошёл способ расстановки фигурных скобок. Подозреваю, корреляция с зарплатами была бы не меньше, чем у табов/пробелов.

technic93
28.06.2017 01:45+3используешь табы — тебя минусуют на хабре — у тебя плохая карма — зарплата меньше
Как вам такая корреляция?
technic93
28.06.2017 01:48У меня есть единственный аргумент в пользу табов, который тут почему-то еще не упоминался. Навигация по коду стрелочками как то проще. Хотя может IDE умеют и в этом случае «симулировать» табы.
А вот почему так много людей используют только «tabs» а не «both» для меня загадка. Для выравнивания (например длинного списка аргументов функции) использовать табы плохо потому что все съедит если поменяется размер табуляции. Неужили все кто ответил «tabs» используют их и для выравнивания?LynXzp
28.06.2017 03:40Ну у кого табы не 4? Конечно есть такие «я художник, я так вижу», ну пусть и видят все выровненное косо. И не так уж сильно все и съедет. Кроме того любой код с любыми отступами легко переводится в «твой любимый стиль» почти в любой IDE, так что никаких проблем.

Kirhgoff
28.06.2017 06:40+1Уже второй год живу с двумя пробелами на таб. Один проект в Московской бирже — Java, второй тут в Австралии — ruby (это принято, как стандарт для всей команды). Очень удобно и приятно
Free_ze
28.06.2017 11:13любой код с любыми отступами легко переводится в «твой любимый стиль» почти в любой IDE
А обратно как вернуть те части файла, которые ты не собирался менять?) Или это отличная идея для любителей мержить?
daggert
29.06.2017 02:29Перед заливкой в репозиторий у вас не делается реформат кода к стандарту команды?
Free_ze
29.06.2017 10:23+1Нет, конечно. Едва ли автоформатер лучше разработчика знает, как повысить читаемость кода.
daggert
29.06.2017 12:53Дык и разработчик не всегда знает как повысить читаемость кода. У одного моего программиста был кодстайл в 1 пробел. У меня личные предпочтения к табам + переносу фигурных скобок на новые строки. У моего фронтенда вера в не обязательность точки с запятой в JS. У человека который делал модули для проекта — приколы в ширину 60 символов на строку.
Везде приходится искать компромиссы, хотя более всего подходит словосочетание «навязать свое мнение».Free_ze
29.06.2017 13:21Дык и разработчик не всегда знает как повысить читаемость кода.
На самом деле, это показатель профессионализма (= Продукт разрабатывает коллектив, тут много взаимодействия, форматирование кода — далеко не единственный повод для разногласий.
Для этого и вводятся корпоративные стайлгайды с более или менее нейтральными правилами, без «приколов», ближе к общепринятым стандартам данной технологии. В C# скобка переносится, в JS — нет, например. Разработчик может гнуть свою линию (в рамках стайлгайда), но от этого особо никто не пострадает. Неадекватные капризы и принципиальность — это скорее признак того, что человек не работал в большом коллективе. Умение читать и писать в любом стиле вполне можно считать софт-скиллом.daggert
29.06.2017 13:34Соглашусь с вами отчасти — на моем жизненном пути самый го*код (в том числе по форматированию) был у мегаопытных людей, могущих решить любую проблему щелчком пальцев.

bro-dev
28.06.2017 04:59Какая разница что именно расставляет автоформатирование? или что кто то до сих пор вручную ставит пробелы и табы и сейчас мы обсуждаем зарплаты таких людей?
grossws
28.06.2017 05:13Несмотря на существование прекрасной фичи автоформатирования и автоматических средств проверки соответствия code style, всё равно находятся люди, которые умудряются смешивать пробелы и табы даже в одной строке.

bluetooth
28.06.2017 12:02А если я пользуюсь Ctrl+E,D по умолчанию и понятия не имею чего там Майкрософт по умолчанию поставили?

Kot_Dymok
28.06.2017 13:34Значит, в ваших коммитах может быть слишком много мусора, не относящегося к, собственно, значимому коду.
bluetooth
28.06.2017 13:53Какого мусора? Пишу код, нажимаю Ctrl+E,D один раз и все. Откуда мусор?
alexeykuzmin0
28.06.2017 16:52Возможно, имелось в виду, что вы изменили все строки в файле, и, таким образом, ваш коммит затронет весь файл вместо того, чтобы затронуть лишь необходимую часть. После этого, например, blame будет работать неверно.
Kot_Dymok
01.07.2017 11:30Именно.
Такой подход аналогичен подходу «я использую табы/пробелы/etc., но сам не знаю, что именно».
На мой взгляд, единственным реальным решением в такой ситуации является обязательное применение какого-нибудь clang-format перед коммитами.
bluetooth
06.07.2017 10:58Ничего страшного, я внимательно изучаю изменения перед коммитами и их отправкой в origin.
Dzen1
28.06.2017 14:19Да, но сколько и кто использует Enterов :-)) Как у них с зарплатами.?!
Порицаю не полный анализ.

logiciel
28.06.2017 16:19Хочу добавить еще одно предположение относительно пика зарплат. Программист, оформивший собственную фирму, пишет себе минимальную зарплату, чтобы платить минимальный соц- и подоходный налог с нее. Остальное получает в виде дивидендов. По крайней мере, я делаю именно так.

diaevd
04.07.2017 21:49Все-таки я не понимаю от чего столько эмоций. В любом проекте всегда должен определяется code-style и его должны придерживаться разработчики. В любом мало-мальски приличном IDE есть настройки для того, чтобы придерживаться данного стиля (табов, пробелов, брэйсов и т.д.). Не важно, коллегиально или только тимлидом принят этот стиль, если он есть, то следуй ему (или кто-то из присутствующих будет кричать в сторону того же Торвальдса на предмет того, что табы — это плохо, вместо того, чтобы просто настроить конкретно для данного проекта linux-style?). Здесь вообще речь идет о достаточно спорном исследовании, но достаточно интересном с точки зрения его существования.

hamnsk
а при написании статьи использовались табы или пробелы?
TOLK
крылья, ноги… главное
хвостс полом определиться :)