
В самом начале нового рабочего года — несколько слов об одном из событий года прошедшего.
Data Modeling Zone — франшиза, которая объединяет конференции по вопросам построения логической архитектуры баз данных. Последние несколько лет проводилась в США и Европе, а в этом году впервые пройдет в Австралии. В 2017 году под брендом DMZ было организовано два форума, оба прошли осенью: 16—18 октября — в Хартфорде, США, а 23—25 октября — в немецком Дюссельдорфе. Мне довелось принять участие в роли слушателя в последней из них. В этой статье представлен краткий обзор презентаций, которые я увидел на конференции, и мои впечатления о ней в целом.
Название конференции недвусмысленно намекает, что ключевой вопрос — разные аспекты построения модели данных. Большинство анонсированных тем связаны с хранилищами данных, но были и актуальные для любой информационной системы. Мои ожидания были противоречивыми: с одной стороны, в числе выступающих — признанные лидеры сообщества, с другой — обилие часовых презентаций, не предусматривающих глубокого рассмотрения вопросов.
Основная программа была представлена пятью треками:
Вместе с бейджем участникам выдавался набор наклеек. С их помощью владелец бейджа мог указать языки, на которых говорит, и выбрать одну или несколько профессиональных ролей. Идея оригинальная и занятная, но бесполезная.

Первый день начался с трехчасовой лекции о различных аспектах версионного сохранения данных. Построение историчности — тема, вокруг которой велось много оживленных споров внутри нашей команды. Поэтому я не смог пройти мимо ключевых слов merging timelines, Data Vault Satellites, historization в анонсе выступления.
Докладчик — Дирк Лернер, один из миссионеров Data Vault в Германии, учредитель компании TEDAMOH (The Data Modeling Hub), автор неплохого профессионального блога.
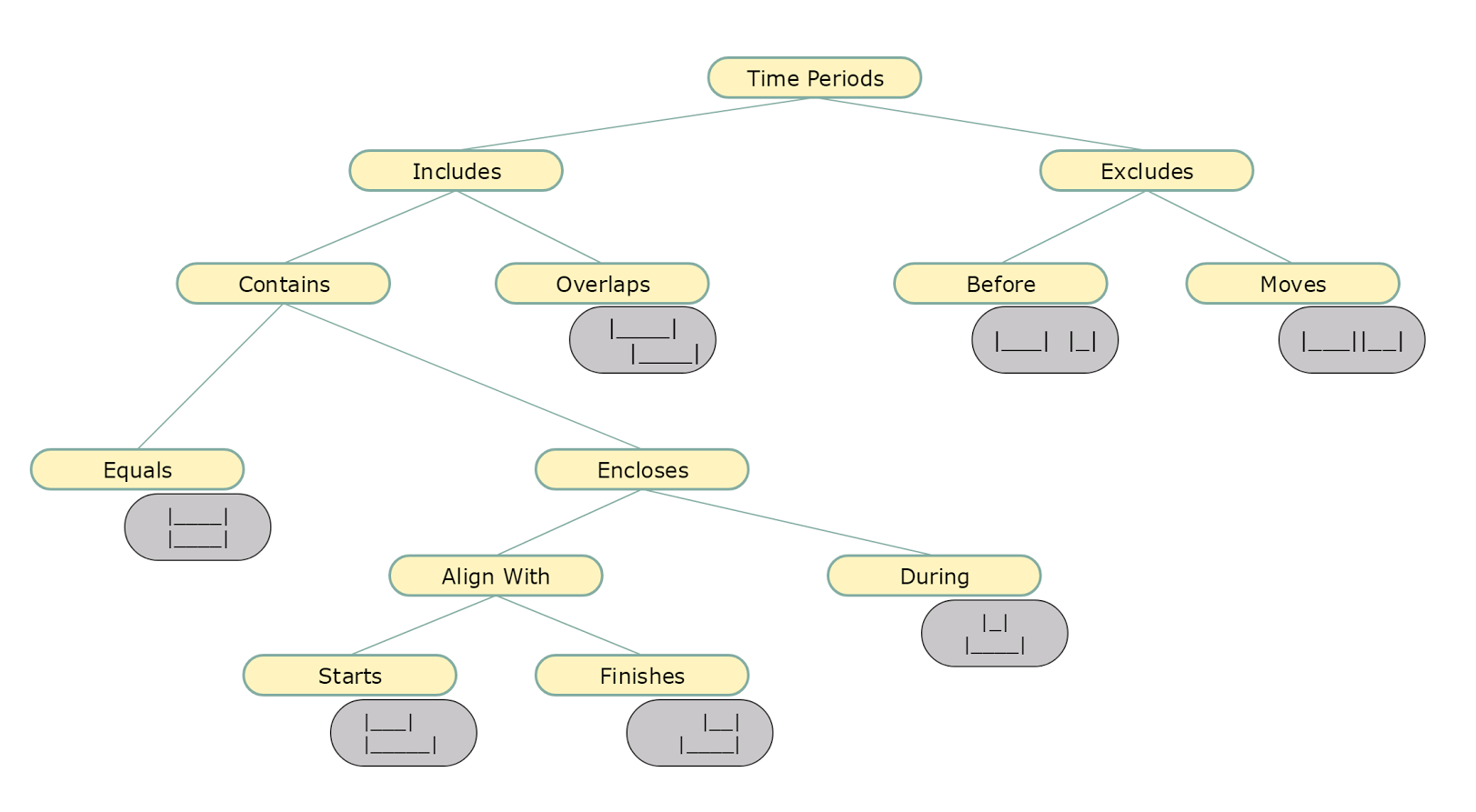
Презентация началась с обзора форматов записи интервалов времени. Рассмотрели 4 формата, отличавшихся способом записи начала и конца интервала: open или closed. В первом примере была выбрана последовательность двух интервалов: T1 = 2016 год, T2 = 2017 год. Из объяснений я понял, что открытый формат записи границы интервала (open) подразумевает исключение границы, а закрытый (closed) — включение. Наподобие того, как записываются числовые интервалы в алгебре.
Но следующий пример поставил меня в тупик. В нем был один интервал — период проведения конференции. Первый пункт задачи (closed/closed) ни у кого не вызвал затруднений. А вот по поводу трех остальных возникла дискуссия, в ходе которой определения всех форматов окончательно прояснились.

Суть в том, что граница периода в формате open обозначается первым определенным значением из смежного периода. То есть «открытый» конец периода обозначается как первый такт следующего периода, а начало — как последний такт предыдущего. Периоды из первого примера имели «соседей» по факту их принадлежности к григорианскому календарю. Второй пример был более конкретным и локальным, поэтому определить границы предложенного интервала через «открытый» формат было невозможно.
В завершение говорили о предпочтительности формата close/open, поскольку именно он позволяет не зависеть от величины такта часов системы наблюдения. Действительно, если строить непрерывную историю изменения состояния объекта, то окончание текущего периода происходит в момент смены состояния, то есть с началом следующего периода. Чтобы вычислить окончание закрывающегося интервала при использовании формата close/close, приходится от времени, когда зафиксировано новое состояние, отнимать 1 такт часов. Тогда как использование формата close/open позволяет время смены состояния указать и в качестве начала нового периода, и в качестве конца старого. И неважно, в каких единицах измеряется время — формат close/open независим от величины такта часов хранилища. Это одна из причин, по которой он наиболее популярен и внесен в стандарт ISO 9075:2011.
Следующей темой была классификация пересечений временных интервалов. Дирк наглядно продемонстрировал, как не запутаться в вопросах, которые кажутся очевидными. По существу — ничего нового, но системность рассмотрения вопроса производит приятное впечатление.
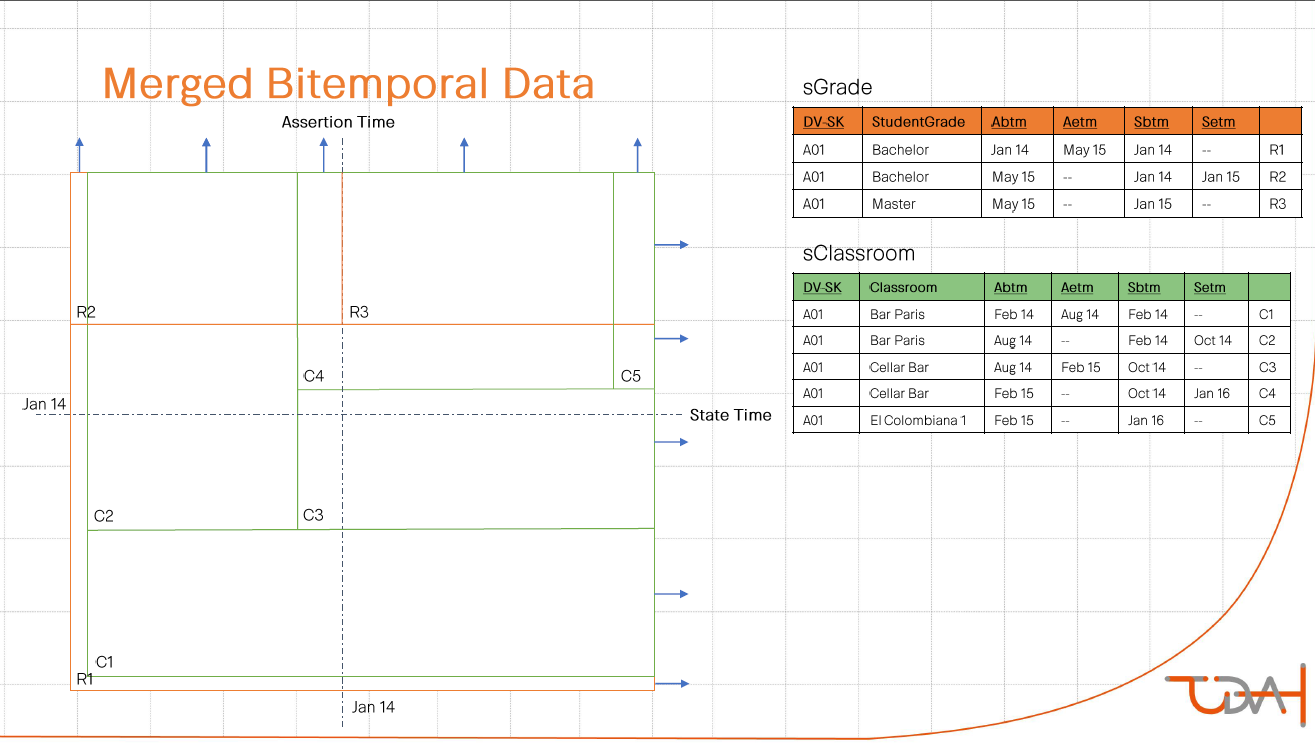
Но всё это было разминкой перед основной темой презентации, а именно — сохранением данных в разрезе двух хронологий: бизнесовой и технической. Необычное слово bitemporal в названии темы — как раз об этом. Дирк начал с достаточно простого абстрактного примера, в котором на входе мы имеем массив данных с ключом, парой бизнес-атрибутов, датой начала актуальности записи с точки зрения бизнеса и датой загрузки данных в staging.
StagingTable
Satellite
Идея заключается в том, чтобы сохранять историю изменений истории. Рассмотрим обработку первых двух записей из staging. С первой записью проблем нет — на момент ее загрузки не идет речи об обработке изменений. В сателлит добавляется запись о том, что у заданного ключа вектор атрибутов (10,10) — «на века». Вторая запись из staging содержит обновление по одному из атрибутов, в результате чего вектор принял значение (11,10). Для обработки этого события необходимо сделать три действия:
Следующий пример слушатели решали самостоятельно. В нем речь шла о студенческом расписании.
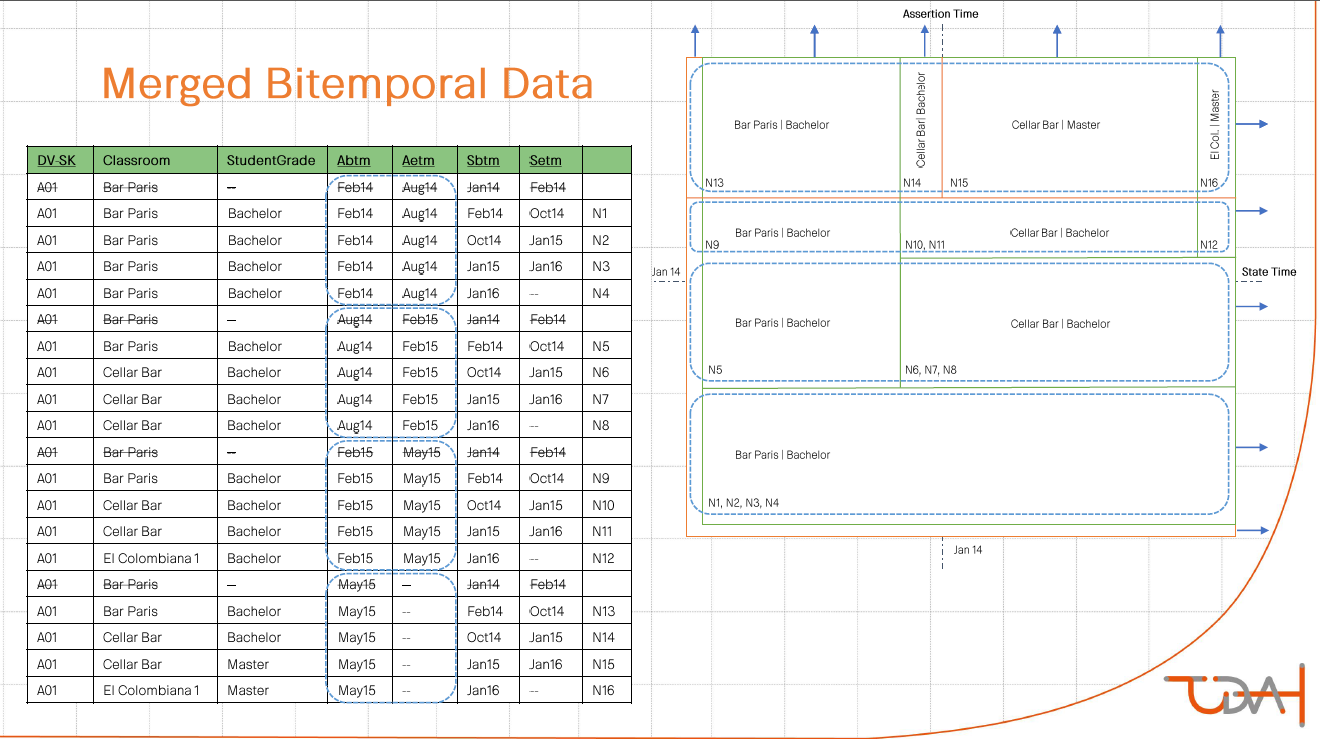
Для демонстрации решения использовалась любопытная визуализация. Двойная историчность была представлена в виде координатной плоскости. На оси абсцисс — бизнес-время, на оси ординат — техническое. Каждой записи соответствует одна из областей плоскости. Нарезка идет по диагонали — направо и вверх.
Заключительный пример был самым сложным. Исходные данные — план изменения цен в привязке ко дню проведения маркетинговой акции «Черная пятница».
Staging Table
Сложность была в том, что план пересматривался не только в части изменения самой цены, но и в части разбивки временного континуума решения. Отмечу, что ключом к успешному выполнению задания стало понимание, что для любого момента «технического» времени в хранилище должны быть данные, полностью покрывающие всю «бизнесовую» хронологию. Не без усилий задачу удалось решить «на бумажке», но вопрос автоматизации этого не самого тривиального алгоритма остался открытым.
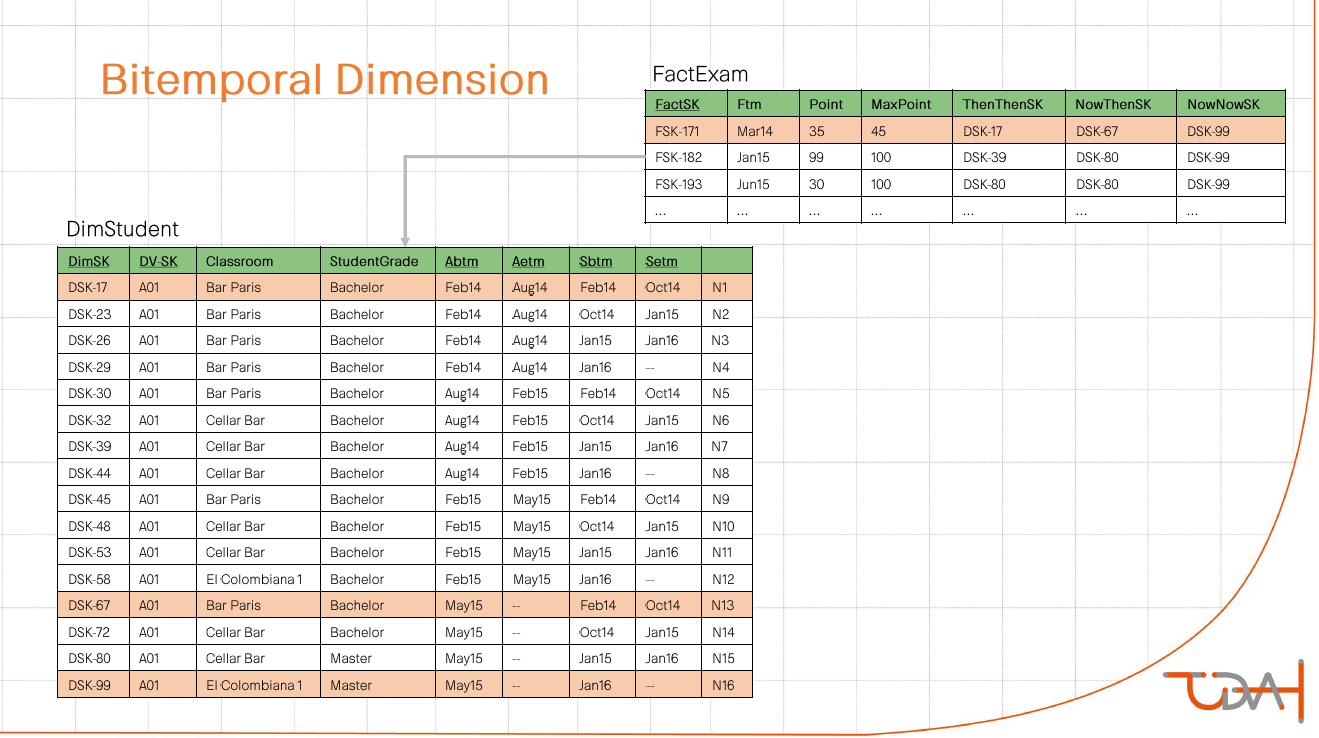
Следующим пунктом программы было описание, как сливать информацию из двух сателлитов с двойной историчностью в одно измерение. Для демонстрации выбрали пример со студентом с определенным расписанием занятий. У него есть история изменения ученой степени. Суть предложенного метода: cross join со схлопыванием последовательных интервалов.
Последним рассмотренным аспектом этой темы была вариантивность в интерпретации информации, полученной на выходе. Есть факт сдачи студентом экзамена. Информацию о расписании и ученой степени студента для этого факта мы можем определять тремя разными способами:
Пожалуй, именно эта презентация была самой содержательной и познавательной лично для меня. После нее последовал блок выступлений в жанре key notes.
Организаторы произнесли набор дежурных фраз, из которых запомнилось упоминание о гендерном распределении среди участников: 165 мужчин на 17 женщин. После чего на сцену вышла «рок-звезда» моделирования данных, автор многочисленных книг по теме — Стив Хоберман. Стив рассказал о том, что сегодня самые популярные в этой области IT вопросы — nosql базы данных и взращивание новых моделеров. На втором он остановился подробнее, рассказав, что рост объема метаданных значительно превышает рост числа моделеров. В связи с этим он выделил 5 самых востребованных в ближайшие годы навыков:
Следующим спикером был архитектор данных центробанка Нидерландов — Рональд Дамхов. Рональд рассказал, как ему с коллегами удалось построить хранилище по принципу «мультиреальности». Речь шла о методологии, которая:
Идея в том, чтобы представить все хранилище в виде квадранта, построенного в системе координат «гибкость-систематизация» + «источники-бизнес» и разделенного на 4 сектора:
При этом подчеркивалось, что разделение данных на «мастер-данные», «большие данные», «метаданные» и прочие неэффективно.
В полученной системе координат был порядок решения каждой из 7 основных задач по проектированию ХД:
Для решение вопроса построения, например, предложили варианты (зеленый — ok, красный — не ok):
После Рональда слово опять взял Стив Хоберман. Он рассказал, как главный определяющий фактор развития IT в ближайшем десятилетии — технология блокчейн — влияет на вопросы моделирования данных. Поскольку Стив — гуру моделирования всего и вся, блокчейну сразу было дано определение в виде логической модели данных.

По мнению Стива наиболее сильно влияние блокчейна будет ощущаться в вопросах управления данными, стандартизации данных и проектирования архитектуры систем хранения данных. Блокчейн вряд ли коснется вектора развития реляционных СУБД. А вот как он скажется на методологии Agile — пока непонятно.
Любопытно, что в качестве примера распространения этой технологии Стив рассказал об украинском проекте, в рамках которого предлагается перейти на использование криптовалюты для расчета по сделкам продажи госсобственности. Это должно помочь в борьбе с коррупцией.
Всем желающим предложили потренироваться в сдаче самого известного в сфере управления данных сертификационного DAMA DMBOK2. Тренировочные вариант экзамена включал в себя 20 вопросов. Например:
И так далее.
Любопытная теория. Достаточно абстрактная, вместе с тем последовательная и логичная.
Изначально демонстрация системы, предоставляющей комплекс услуг по построению архитектуры хранилища, была запланирована в формате семинара. Но ноутбуков оказалось сильно меньше участников, поэтому формат изменили на презентацию.
В качестве преамбулы был декларирован ряд утверждений класса «Волга впадает в Каспийское море». Например, о том, что главное — это слушать бизнес, а автоматизация — часть процесса, а не техническое решение. Для примера был приведен провальный проект с заказчиком в лице российской компании, представители которой «полагали, что покупая систему, они покупают волшебную палочку». После презентации я подошел, чтобы расспросить поподробнее про этот проект. Но всё, что услышал — это просьбу не воспринимать эти слова как хулу русского народа — «эта ошибка свойственна всем». В завершение вступительной части был основательно раскритикован Power Designer — старый, некрасивый, сложный, смысла хранить версии нет.
Сама система в ходе демонстрации выглядела действительно эффектно. В деле мы увидели лишь часть возможностей, но было заявлено, что WhereScape Red обеспечивает полный набор возможностей по управлению метаданными и ETL. В качестве подтверждения была представлена схема, на которой красненьким были отмечены стандартные элементы архитектуры хранилища, охваченные функциональностью системы:
Начали с того, что модели систем источников описаны, их изменения отслеживаются. Сам процесс моделирования заключается в построении логической модели пользовательских витрин и определении маппингов их полей с источниками. После этого нажатием волшебной кнопки запускается процесс автоматического построения модели слоя staging и data vault в соответствии с заранее настроенными правилами. Последним шагом стала генерация ETL-кода и определение расписания. На примерах класса tutorial все работало, разумеется, складно и нарядно. Среди особенностей я бы выделил линейдж по колонкам. Верификации и валидации изменений пока нет, но в ближайшем релизе должны появиться. Больше о возможностях системы можно прочитать на странице вендора.
Первый день завершился самодеятельным юмористическим шоу. Сценки двух взрослых мужиков, лейтмотивом которых была самоирония по поводу ажиотажа вокруг Data Vault, наскучили после первых 15 минут, хотя всё представление длилось больше часа. Глядя на количество экранов телефонов, горящих в темноте, сложно было не проникнуться сочувствием к выступающим дяденькам.
Трехчасовой семинар австралийца Джона Гиллза по сути был кратким изложением его же книги «The Nimble Elephant», выпущенной в 2012 году. Тема полезная и не теряющая своей актуальности. Речь идет об использовании промышленных шаблонов при проектировании модели. В настоящее время крупные вендоры (например, IBM и TeraData) предлагают готовые верхнеуровневые шаблоны модели для разных предметных областей — «Industry Reference Model». Самая общая классификация сущностей у многих шаблонов совпадает. Концепция, о которой рассказал Джон, — не исключение. Она предусматривает использование типов:
На семинаре участникам нужно было по описанию производственной деятельности предприятия построить модель данных, описывающих этот бизнес-процесс. Предлагалось сделать это с помощью:
Кроме этого, Джон представил точный план-график построения модели данных с использованием такого подхода:
Полученную концептуальную модель можно использовать не только для построения логической модели ХД, но и как единую формализованную бизнес-модель предприятия, в соответствии с которой следует создавать логические модели данных операционных бизнес-систем.
Второй семинар, который мне удалось посетить, проводил Стив Хоберман. Стив известен не только своими книжками и запатентованной системой оценки качества модели «Data Model Scorecard». Он также популярен как преподаватель на семинарах и курсах по теме. В целом он подтвердил свою репутацию: рассказывал доступно, интересно и с юмором. Правда, название семинара не соответствовало действительности: речь шла о важных и полезных, но все-таки базовых принципах построения модели.
Сперва он рассказал про концепцию супер-сущностей и их расширений, что пересекалось с содержанием предыдущего семинара. После последовало задание: нужно было изучить небольшой набор данных, представленных в плоской денормализованной витрине и описывающих ассортимент книжного магазина, и построить 3NF-модель. По мнению Стива, выполняя это задание, мы должны были почувствовать себя археологами данных.
Следующее задание было более занятным. Исходными данными было расписание движения пригородных поездов по одному из направлений в окрестностях Нью-Йорка.
Задача заключалась в проектировании модели данных, на базе которой можно строить аналитику по качеству работы электричек, а именно — насколько точно выполняется расписание. Целевая модель должна была предусматривать сохранение данных и о расписании, и о фактическом графике движения поездов. Модели, представленные тремя командами, практически не отличались по набору сущностей, если не считать различий в названиях. То, что у нас принято называть «веткой» или «линией» в разных моделях называлось: line, journey, route, trip, а «перегон» — link или leg. Из этого было выведено одно из очевидных, но крайне важных правил моделирования — необходимость давать четкое, максимально исчерпывающее определение сущностям, представленным в модели. Принципиальным различием моделей был способ сохранения фактических данных о движении поездов: у части моделей гранулярность этих данных была определена как факт прибытия поезда от начальной станции к заданной. Альтернативным подходом было сохранение факта перемещения поезда между двумя соседними станциями. В ходе сравнения двух способов, мы пришли к выводу о том, как важно при построении модели помнить, какой процесс мы хотим измерять с ее помощью.
Кроме этого, различались парадигмы построения логических моделей: одна команда выбрала Multi-Dimensional, остальные — 3NF. На основе мы сформулировали тезис о приоритетности создания качественной концептуальной модели, которую без труда можно конвертировать в Multi-Dimensional, 3NF, Data Vault, и так далее.
Пространная философская презентация о роли архитекторов в современном мире. Ключевую мысль лучше всего выражает цитата архитектора Нормана Фостера:
«As an architect you design for the present,
with an awareness of the past,
for a future which is essentially unknown».
Из великих еще был процитирован Аристотель с его словами о том, что архитектура держится на трех китах: долговечность, красота и функциональность.
Это было что-то обо всем и ни о чем протяженностью в час в формате keynote. Среди прочего стоит выделить крайне важное наблюдение: архитектор здания отличается от архитектора промышленной системы тем, что не встроен в объект своего творения.
Не самая захватывающая презентация на тему того, как правильно сохранять историю изменения сущности. Ключевые мысли:
Для демонстрации этих хороших и важных мыслей был выбран примитивный пример с моделью жизненного цикла антилопы гну:
А для закрепления полученной информации нам предложили построить модель данных, позволяющую автоматизировать процесс гашения банковских чеков. Либо задача была сформулирована слишком абстрактно, либо участники к концу второго дня подустали, но в итоге готовых решений не было.
Автор — Габор Гольнхофер, архитектор с 20-летним опытом работы на проектах ХД в финансах, страховании, телекоме, ритейле и образовании. Презентованный проект заключался в переводе хранилища неопределенно-смешанной архитектуры на Data Vault. Название компании-заказчика не называлось, сказали лишь, что она лидер рынка в своей сфере в Венгрии и входит в международный холдинг. По «тактико-техническим характеристикам» их хранилище сопоставимо с нашим Tinkoff DWH:
C технической точки зрения главной предпосылкой к перестроению хранилища была дороговизна процесса доработок и проблемы с производительностью. Кроме этого, 20 лет эволюции, включающей переход от 3NF к Dimensional и внедрение версионности, привели к архитектурному хаосу. Со стороны бизнеса были требования: высокая скорость изменений, полнота сохранения истории, возможности для self-service BI. Короче говоря, как обычно — побольше, побыстрее и подешевле.
Основные проблемы, с которыми столкнулись коллеги, уверен, знакомы многим. Это и отсутствие в исходных данных подходящих бизнес-ключей, только суррогатные, и низкое качество исходных данных, и нарушения целостности в источниках. Также немало сил пришлось потратить на автоматизацию построения Dimensional — витрин на основе DV — и разработку шаблонов ETL-процедур для загрузки больших массивов данных. Пожалуй, ключевой особенностью проекта был упор на автоматизацию изменений модели и ETL, в результате чего:
Кроме этого, справедливо утверждалось, что Data Vault полезен в деле контроля качества данных, поскольку позволяет сохранять «факты», а не «правду».
Доклад получился интересным и содержательным. В личной беседе после презентации сошлись с Габором в том, что Data Vault не стоит воспринимать как догму, но адаптировать под нужды конкретного проекта.
Резюмируя содержательную часть конференции, отмечу:
Не хватало презентаций реальных проектов, рассказывающих о способах решения настоящих, а не гипотетических проблем, с которыми сталкиваются проектные команды при использовании красивых и стройных [на бумаге] методологий, об адаптации таких подходов к суровой прозе жизни.
Если говорить об общем впечатлении, основной эффект — мотивирующий. Мотивирующий к тому, чтобы почитать больше о представленных подходах. Мотивирующий заниматься этим достаточно востребованным делом. Пожалуй, аналитиков DWH с опытом до трех лет в первую очередь интересовали бы сами презентации, а их старшие товарищи-архитекторы нашли бы большее удовольствие в общении с коллегами «на полях». Лично мне удалось познакомиться с несколькими коллегами из Европы, Америки, и, как ни странно, России. Повезло пообщаться с некоторыми гуру. К слову, Ханс Хальтгрен в личной беседе сказал, что два русских парня, с которыми он работает в Долине — просто «amazing». И оставил автограф на своей, пожалуй, самой популярной книжке про Data Vault.

Введение
Data Modeling Zone — франшиза, которая объединяет конференции по вопросам построения логической архитектуры баз данных. Последние несколько лет проводилась в США и Европе, а в этом году впервые пройдет в Австралии. В 2017 году под брендом DMZ было организовано два форума, оба прошли осенью: 16—18 октября — в Хартфорде, США, а 23—25 октября — в немецком Дюссельдорфе. Мне довелось принять участие в роли слушателя в последней из них. В этой статье представлен краткий обзор презентаций, которые я увидел на конференции, и мои впечатления о ней в целом.
Название конференции недвусмысленно намекает, что ключевой вопрос — разные аспекты построения модели данных. Большинство анонсированных тем связаны с хранилищами данных, но были и актуальные для любой информационной системы. Мои ожидания были противоречивыми: с одной стороны, в числе выступающих — признанные лидеры сообщества, с другой — обилие часовых презентаций, не предусматривающих глубокого рассмотрения вопросов.
Основная программа была представлена пятью треками:
- Foundational Data Modeling
- Agile and Requirements
- Big Data and Architecture
- Hands-On and Case Studies
- Advanced Data Modeling
1-й день
Регистрация
Вместе с бейджем участникам выдавался набор наклеек. С их помощью владелец бейджа мог указать языки, на которых говорит, и выбрать одну или несколько профессиональных ролей. Идея оригинальная и занятная, но бесполезная.
Send Bitemporal data from Ground to Vault to the Stars
Первый день начался с трехчасовой лекции о различных аспектах версионного сохранения данных. Построение историчности — тема, вокруг которой велось много оживленных споров внутри нашей команды. Поэтому я не смог пройти мимо ключевых слов merging timelines, Data Vault Satellites, historization в анонсе выступления.
Докладчик — Дирк Лернер, один из миссионеров Data Vault в Германии, учредитель компании TEDAMOH (The Data Modeling Hub), автор неплохого профессионального блога.
Презентация началась с обзора форматов записи интервалов времени. Рассмотрели 4 формата, отличавшихся способом записи начала и конца интервала: open или closed. В первом примере была выбрана последовательность двух интервалов: T1 = 2016 год, T2 = 2017 год. Из объяснений я понял, что открытый формат записи границы интервала (open) подразумевает исключение границы, а закрытый (closed) — включение. Наподобие того, как записываются числовые интервалы в алгебре.
| Формат | T1 | T1 |
|---|---|---|
| Closed / Closed | Jan16 — Dec16 | Jan17 — Dec17 |
| Closed / Open | Jan16 — Jan17 | Jan17 — Jan18 |
| Open / Closed | Dec15 — Dec16 | Dec16 — Dec17 |
| Open / Open | Dec15 — Jan17 | Dec16 — Jan18 |
Но следующий пример поставил меня в тупик. В нем был один интервал — период проведения конференции. Первый пункт задачи (closed/closed) ни у кого не вызвал затруднений. А вот по поводу трех остальных возникла дискуссия, в ходе которой определения всех форматов окончательно прояснились.
Суть в том, что граница периода в формате open обозначается первым определенным значением из смежного периода. То есть «открытый» конец периода обозначается как первый такт следующего периода, а начало — как последний такт предыдущего. Периоды из первого примера имели «соседей» по факту их принадлежности к григорианскому календарю. Второй пример был более конкретным и локальным, поэтому определить границы предложенного интервала через «открытый» формат было невозможно.
В завершение говорили о предпочтительности формата close/open, поскольку именно он позволяет не зависеть от величины такта часов системы наблюдения. Действительно, если строить непрерывную историю изменения состояния объекта, то окончание текущего периода происходит в момент смены состояния, то есть с началом следующего периода. Чтобы вычислить окончание закрывающегося интервала при использовании формата close/close, приходится от времени, когда зафиксировано новое состояние, отнимать 1 такт часов. Тогда как использование формата close/open позволяет время смены состояния указать и в качестве начала нового периода, и в качестве конца старого. И неважно, в каких единицах измеряется время — формат close/open независим от величины такта часов хранилища. Это одна из причин, по которой он наиболее популярен и внесен в стандарт ISO 9075:2011.
Следующей темой была классификация пересечений временных интервалов. Дирк наглядно продемонстрировал, как не запутаться в вопросах, которые кажутся очевидными. По существу — ничего нового, но системность рассмотрения вопроса производит приятное впечатление.
Но всё это было разминкой перед основной темой презентации, а именно — сохранением данных в разрезе двух хронологий: бизнесовой и технической. Необычное слово bitemporal в названии темы — как раз об этом. Дирк начал с достаточно простого абстрактного примера, в котором на входе мы имеем массив данных с ключом, парой бизнес-атрибутов, датой начала актуальности записи с точки зрения бизнеса и датой загрузки данных в staging.
StagingTable
| SomeBK | Attr_1 | Attr_2 | ValidFrom | STGLoadDTS |
|---|---|---|---|---|
| %662HK!..? | 10 | 10 | 2014-12-01 | 2015-01-01 |
| %662HK!..? | 11 | 10 | 2015-01-03 | 2015-02-10 |
| %662HK!..? | 11 | 100 | 2015-03-30 | 2015-02-23 |
Satellite
| H_ID | Attr_1 | Attr_2 | Tech_from | Tech_to | Bsns_from | Bsns_to |
|---|---|---|---|---|---|---|
| 1 | 10 | 10 | 2015-01-01 | 2015-02-10 | 2014-12-01 | 2999-12-31 |
| 1 | 10 | 10 | 2015-02-10 | 2999-12-31 | 2014-12-01 | 2015-01-03 |
| 1 | 11 | 10 | 2015-02-10 | 2015-02-23 | 2015-01-03 | 2999-12-31 |
| 1 | 11 | 10 | 2015-02-23 | 2999-12-31 | 2015-01-03 | 2015-03-30 |
| 1 | 11 | 100 | 2015-02-23 | 2999-12-31 | 2015-03-30 | 2999-12-31 |
Идея заключается в том, чтобы сохранять историю изменений истории. Рассмотрим обработку первых двух записей из staging. С первой записью проблем нет — на момент ее загрузки не идет речи об обработке изменений. В сателлит добавляется запись о том, что у заданного ключа вектор атрибутов (10,10) — «на века». Вторая запись из staging содержит обновление по одному из атрибутов, в результате чего вектор принял значение (11,10). Для обработки этого события необходимо сделать три действия:
- Сохранить информацию, что в период с момента получения данных о первом значении (10,10) до получения данных о втором (11,10) мы думали, что значение (10,10) — «на века». Для этого мы обновляем первую запись закрыв ей интервал «технической» актуальности, оставив открытой «бизнесовую».
- С момента получения данных (11,10) мы знаем, что значение (10,10) было актуально только в определенный период времени, и это наше знание уже не подлежит пересмотру. Для сохранения этой информации мы вставили вторую запись с (10,10) с открытым интервалом «технической» актуальности, но с закрытым «бизнесовой».
- Для сохранения нашего актуального представления, что значение (11,10) действительно сейчас и будет таковым в течение неопределенного будущего, вставляется третья запись именно с этим значением вектора атрибутов и открытыми интервалами и «технической», и «бизнесовой» актуальности (на слайде у этой записи «технический» интервал закрыт, потому что сателлит содержит результаты обработки последующих обновлений).
Следующий пример слушатели решали самостоятельно. В нем речь шла о студенческом расписании.
Для демонстрации решения использовалась любопытная визуализация. Двойная историчность была представлена в виде координатной плоскости. На оси абсцисс — бизнес-время, на оси ординат — техническое. Каждой записи соответствует одна из областей плоскости. Нарезка идет по диагонали — направо и вверх.
Заключительный пример был самым сложным. Исходные данные — план изменения цен в привязке ко дню проведения маркетинговой акции «Черная пятница».
Staging Table
| Product | Price | DayStart | DayEnd | STG Load DTS |
|---|---|---|---|---|
| Jeans | 100 | D1 | BF | D1 |
| Jeans | 80 | BF | BF+w | D1 |
| Jeans | 110 | BF+w | 9999 | D1 |
| Jeans | 95 | D1 | BF | D10 |
| Jeans | 82 | BF | BF+2w | D10 |
Сложность была в том, что план пересматривался не только в части изменения самой цены, но и в части разбивки временного континуума решения. Отмечу, что ключом к успешному выполнению задания стало понимание, что для любого момента «технического» времени в хранилище должны быть данные, полностью покрывающие всю «бизнесовую» хронологию. Не без усилий задачу удалось решить «на бумажке», но вопрос автоматизации этого не самого тривиального алгоритма остался открытым.
Следующим пунктом программы было описание, как сливать информацию из двух сателлитов с двойной историчностью в одно измерение. Для демонстрации выбрали пример со студентом с определенным расписанием занятий. У него есть история изменения ученой степени. Суть предложенного метода: cross join со схлопыванием последовательных интервалов.
Последним рассмотренным аспектом этой темы была вариантивность в интерпретации информации, полученной на выходе. Есть факт сдачи студентом экзамена. Информацию о расписании и ученой степени студента для этого факта мы можем определять тремя разными способами:
- Что нам известно сейчас о расписании и степени, актуальной на сегодня.
- Что нам известно сейчас о расписании и степени, актуальной на момент сдачи экзамена.
- Что нам было известно на момент сдачи экзамена о расписании и степени, актуальных на момент сдачи экзамена.
Пожалуй, именно эта презентация была самой содержательной и познавательной лично для меня. После нее последовал блок выступлений в жанре key notes.
Официальное открытие
Организаторы произнесли набор дежурных фраз, из которых запомнилось упоминание о гендерном распределении среди участников: 165 мужчин на 17 женщин. После чего на сцену вышла «рок-звезда» моделирования данных, автор многочисленных книг по теме — Стив Хоберман. Стив рассказал о том, что сегодня самые популярные в этой области IT вопросы — nosql базы данных и взращивание новых моделеров. На втором он остановился подробнее, рассказав, что рост объема метаданных значительно превышает рост числа моделеров. В связи с этим он выделил 5 самых востребованных в ближайшие годы навыков:
- Общения
- Моделирования
- Управления данными в парадигме Agile
- Знание различных типов СУБД
- Знание бизнес-процессов
Data, a Managerial Perspective
Следующим спикером был архитектор данных центробанка Нидерландов — Рональд Дамхов. Рональд рассказал, как ему с коллегами удалось построить хранилище по принципу «мультиреальности». Речь шла о методологии, которая:
- предусматривает одновременно и полноту отражения источников, и адекватное представление бизнес-контекста;
- позволяет использовать преимущества гибкого подхода к разработке вместе с четкой регламентацией процессов изменения.
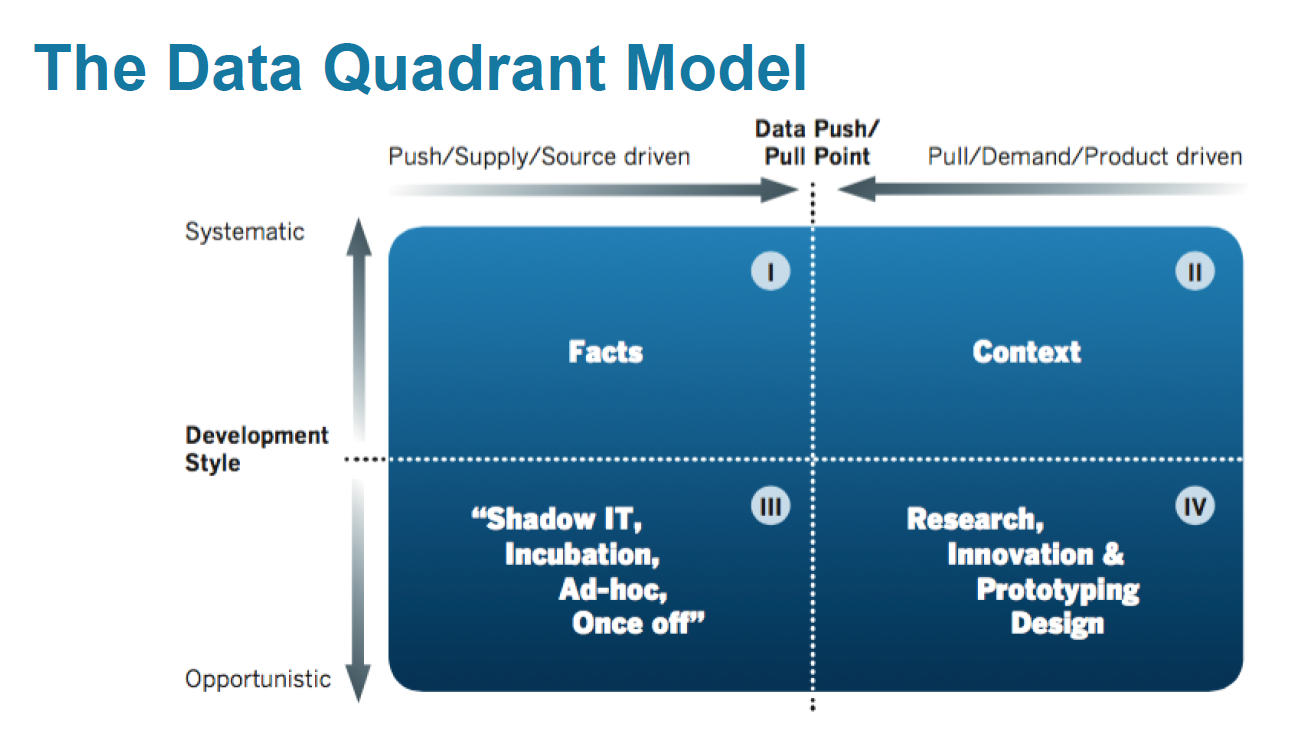
Идея в том, чтобы представить все хранилище в виде квадранта, построенного в системе координат «гибкость-систематизация» + «источники-бизнес» и разделенного на 4 сектора:
При этом подчеркивалось, что разделение данных на «мастер-данные», «большие данные», «метаданные» и прочие неэффективно.
В полученной системе координат был порядок решения каждой из 7 основных задач по проектированию ХД:
- Построение
- Автоматизация
- Систематизация
- Управление
- Доступ пользователей
- Обеспечение технологичности
- Моделирование
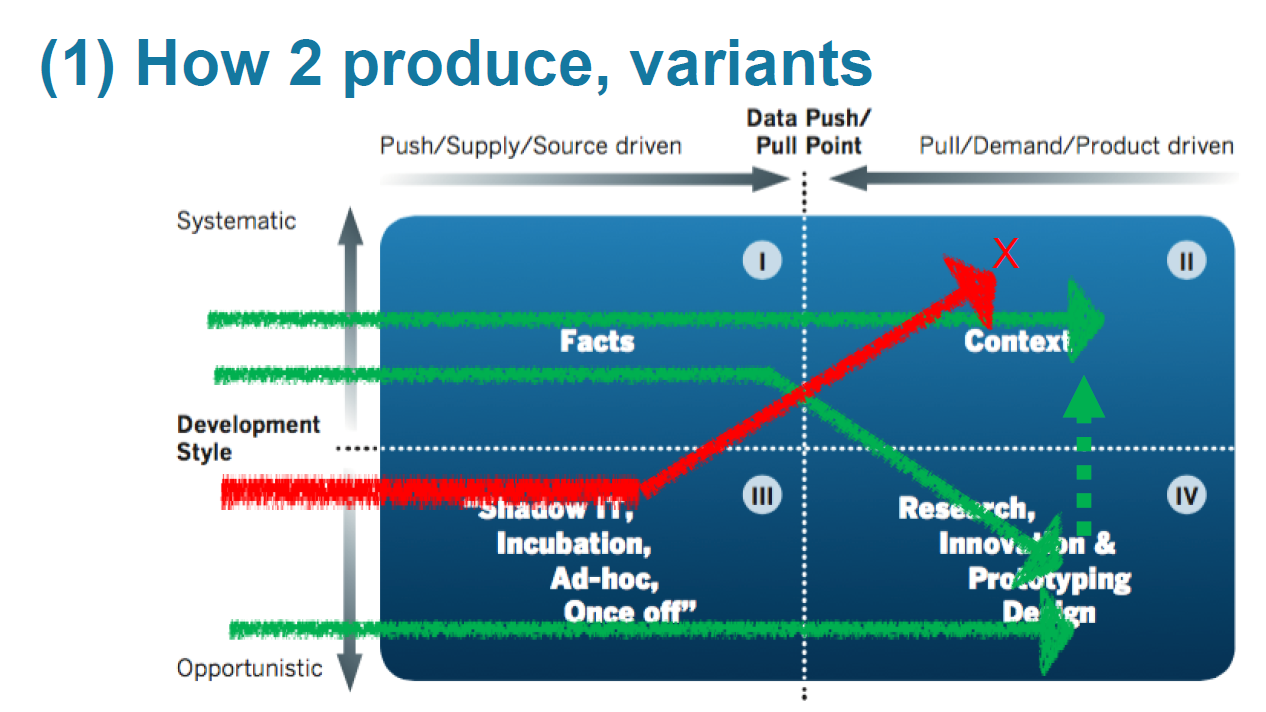
Для решение вопроса построения, например, предложили варианты (зеленый — ok, красный — не ok):
The Blockchain Billionaire
После Рональда слово опять взял Стив Хоберман. Он рассказал, как главный определяющий фактор развития IT в ближайшем десятилетии — технология блокчейн — влияет на вопросы моделирования данных. Поскольку Стив — гуру моделирования всего и вся, блокчейну сразу было дано определение в виде логической модели данных.
По мнению Стива наиболее сильно влияние блокчейна будет ощущаться в вопросах управления данными, стандартизации данных и проектирования архитектуры систем хранения данных. Блокчейн вряд ли коснется вектора развития реляционных СУБД. А вот как он скажется на методологии Agile — пока непонятно.
Любопытно, что в качестве примера распространения этой технологии Стив рассказал об украинском проекте, в рамках которого предлагается перейти на использование криптовалюты для расчета по сделкам продажи госсобственности. Это должно помочь в борьбе с коррупцией.
Introducing the DAMA DMBOK2 certification
Всем желающим предложили потренироваться в сдаче самого известного в сфере управления данных сертификационного DAMA DMBOK2. Тренировочные вариант экзамена включал в себя 20 вопросов. Например:
- Кто является «поставщиком» в контексте процесса управления данными?
- Какие активности включены в процесс разработки данных?
- Какие действия по поддержке являются базовыми для построения надежной системы хранения данных?
- Кто наиболее заинтересован в качественно внедренном процессе управления данными?
И так далее.
Любопытная теория. Достаточно абстрактная, вместе с тем последовательная и логичная.
Wherescape Test Drive
Изначально демонстрация системы, предоставляющей комплекс услуг по построению архитектуры хранилища, была запланирована в формате семинара. Но ноутбуков оказалось сильно меньше участников, поэтому формат изменили на презентацию.
В качестве преамбулы был декларирован ряд утверждений класса «Волга впадает в Каспийское море». Например, о том, что главное — это слушать бизнес, а автоматизация — часть процесса, а не техническое решение. Для примера был приведен провальный проект с заказчиком в лице российской компании, представители которой «полагали, что покупая систему, они покупают волшебную палочку». После презентации я подошел, чтобы расспросить поподробнее про этот проект. Но всё, что услышал — это просьбу не воспринимать эти слова как хулу русского народа — «эта ошибка свойственна всем». В завершение вступительной части был основательно раскритикован Power Designer — старый, некрасивый, сложный, смысла хранить версии нет.
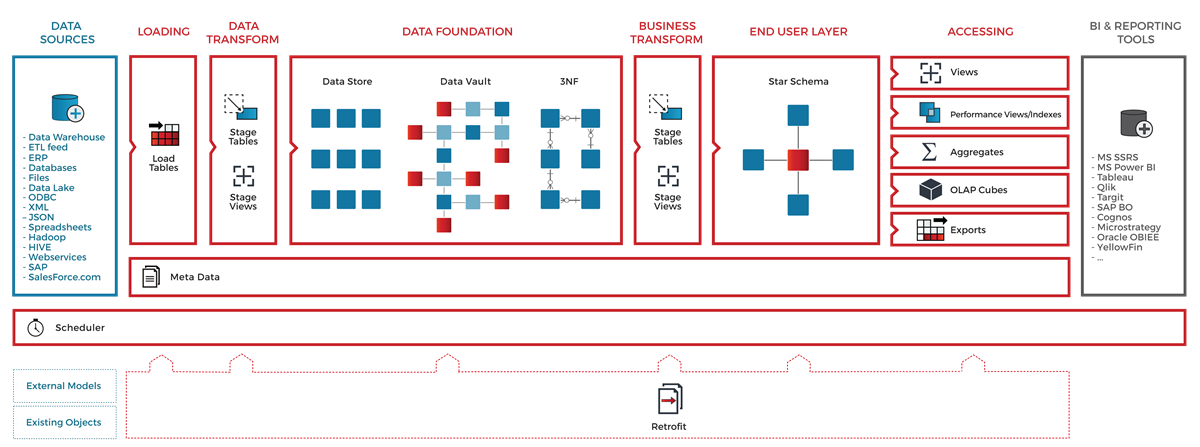
Сама система в ходе демонстрации выглядела действительно эффектно. В деле мы увидели лишь часть возможностей, но было заявлено, что WhereScape Red обеспечивает полный набор возможностей по управлению метаданными и ETL. В качестве подтверждения была представлена схема, на которой красненьким были отмечены стандартные элементы архитектуры хранилища, охваченные функциональностью системы:
Начали с того, что модели систем источников описаны, их изменения отслеживаются. Сам процесс моделирования заключается в построении логической модели пользовательских витрин и определении маппингов их полей с источниками. После этого нажатием волшебной кнопки запускается процесс автоматического построения модели слоя staging и data vault в соответствии с заранее настроенными правилами. Последним шагом стала генерация ETL-кода и определение расписания. На примерах класса tutorial все работало, разумеется, складно и нарядно. Среди особенностей я бы выделил линейдж по колонкам. Верификации и валидации изменений пока нет, но в ближайшем релизе должны появиться. Больше о возможностях системы можно прочитать на странице вендора.
How to sell Data Vault to non-technical people
Первый день завершился самодеятельным юмористическим шоу. Сценки двух взрослых мужиков, лейтмотивом которых была самоирония по поводу ажиотажа вокруг Data Vault, наскучили после первых 15 минут, хотя всё представление длилось больше часа. Глядя на количество экранов телефонов, горящих в темноте, сложно было не проникнуться сочувствием к выступающим дяденькам.
2-й день
Developing Corporate Model Using Patterns
Трехчасовой семинар австралийца Джона Гиллза по сути был кратким изложением его же книги «The Nimble Elephant», выпущенной в 2012 году. Тема полезная и не теряющая своей актуальности. Речь идет об использовании промышленных шаблонов при проектировании модели. В настоящее время крупные вендоры (например, IBM и TeraData) предлагают готовые верхнеуровневые шаблоны модели для разных предметных областей — «Industry Reference Model». Самая общая классификация сущностей у многих шаблонов совпадает. Концепция, о которой рассказал Джон, — не исключение. Она предусматривает использование типов:
- Участник и роль
- Продукт
- Ресурс
- Задание
- Счет
- Соглашение
- Документ
- Событие
- Местоположение
На семинаре участникам нужно было по описанию производственной деятельности предприятия построить модель данных, описывающих этот бизнес-процесс. Предлагалось сделать это с помощью:
- создания подтипов разного уровня вложенности по отношению к перечисленным исходным типам;
- определения связей между ними.
Кроме этого, Джон представил точный план-график построения модели данных с использованием такого подхода:
- 1 неделя: ознакомление, драфт концептуальной модели.
- 2—4 недели: семинары по проблемным местам, итеративное развитие концептуальной модели через уточнение, создание расширений основных сущностей.
- 5 неделя: бизнес определяет приоритеты, IT начинает разработку.
- 6—8 недели: построение прототипа, запуск процесса agile-разработки.
Полученную концептуальную модель можно использовать не только для построения логической модели ХД, но и как единую формализованную бизнес-модель предприятия, в соответствии с которой следует создавать логические модели данных операционных бизнес-систем.
Advanced Data Modeling Challenges
Второй семинар, который мне удалось посетить, проводил Стив Хоберман. Стив известен не только своими книжками и запатентованной системой оценки качества модели «Data Model Scorecard». Он также популярен как преподаватель на семинарах и курсах по теме. В целом он подтвердил свою репутацию: рассказывал доступно, интересно и с юмором. Правда, название семинара не соответствовало действительности: речь шла о важных и полезных, но все-таки базовых принципах построения модели.
Сперва он рассказал про концепцию супер-сущностей и их расширений, что пересекалось с содержанием предыдущего семинара. После последовало задание: нужно было изучить небольшой набор данных, представленных в плоской денормализованной витрине и описывающих ассортимент книжного магазина, и построить 3NF-модель. По мнению Стива, выполняя это задание, мы должны были почувствовать себя археологами данных.
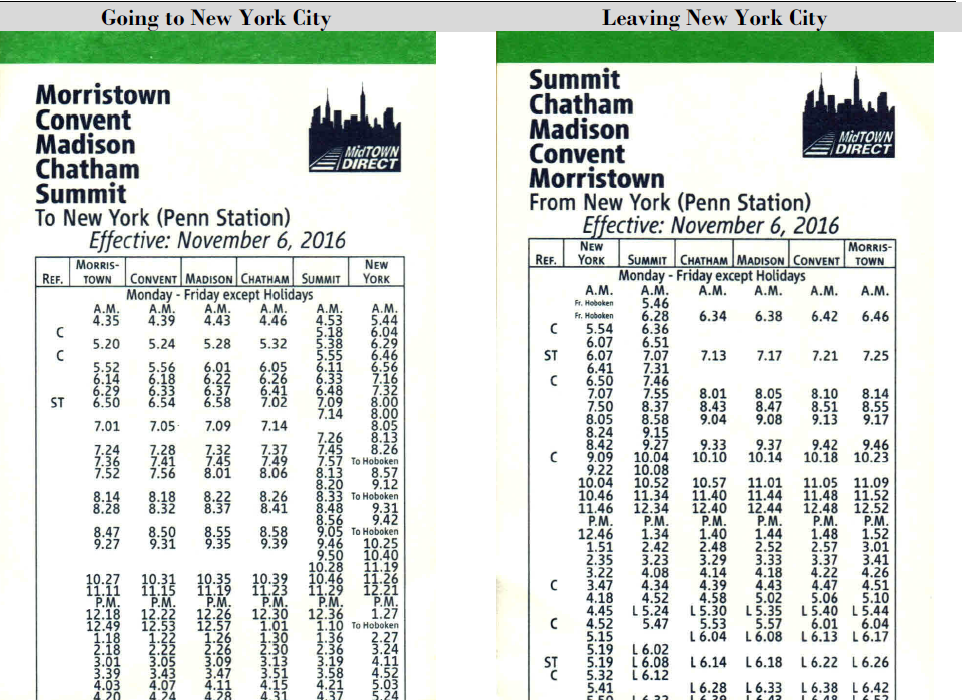
Следующее задание было более занятным. Исходными данными было расписание движения пригородных поездов по одному из направлений в окрестностях Нью-Йорка.
Задача заключалась в проектировании модели данных, на базе которой можно строить аналитику по качеству работы электричек, а именно — насколько точно выполняется расписание. Целевая модель должна была предусматривать сохранение данных и о расписании, и о фактическом графике движения поездов. Модели, представленные тремя командами, практически не отличались по набору сущностей, если не считать различий в названиях. То, что у нас принято называть «веткой» или «линией» в разных моделях называлось: line, journey, route, trip, а «перегон» — link или leg. Из этого было выведено одно из очевидных, но крайне важных правил моделирования — необходимость давать четкое, максимально исчерпывающее определение сущностям, представленным в модели. Принципиальным различием моделей был способ сохранения фактических данных о движении поездов: у части моделей гранулярность этих данных была определена как факт прибытия поезда от начальной станции к заданной. Альтернативным подходом было сохранение факта перемещения поезда между двумя соседними станциями. В ходе сравнения двух способов, мы пришли к выводу о том, как важно при построении модели помнить, какой процесс мы хотим измерять с ее помощью.
Кроме этого, различались парадигмы построения логических моделей: одна команда выбрала Multi-Dimensional, остальные — 3NF. На основе мы сформулировали тезис о приоритетности создания качественной концептуальной модели, которую без труда можно конвертировать в Multi-Dimensional, 3NF, Data Vault, и так далее.
Designing the Dream — Why Enterprises Need Architects
Пространная философская презентация о роли архитекторов в современном мире. Ключевую мысль лучше всего выражает цитата архитектора Нормана Фостера:
«As an architect you design for the present,
with an awareness of the past,
for a future which is essentially unknown».
Из великих еще был процитирован Аристотель с его словами о том, что архитектура держится на трех китах: долговечность, красота и функциональность.
Это было что-то обо всем и ни о чем протяженностью в час в формате keynote. Среди прочего стоит выделить крайне важное наблюдение: архитектор здания отличается от архитектора промышленной системы тем, что не встроен в объект своего творения.
Business Milestones and Data Models — an Introduction to Entity Life Histories
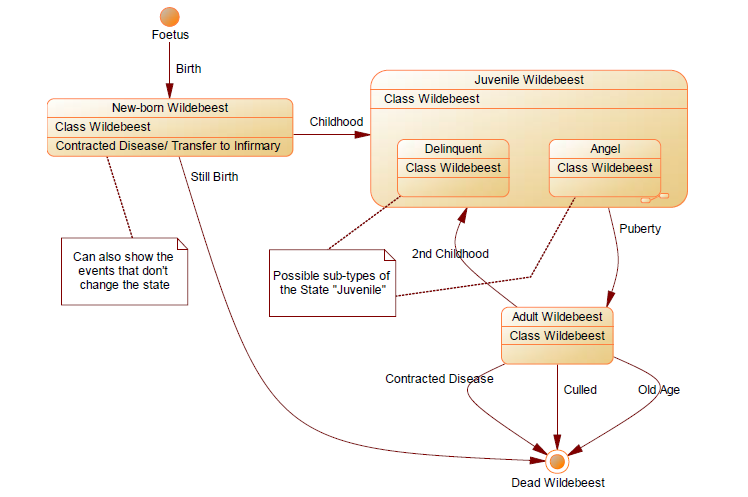
Не самая захватывающая презентация на тему того, как правильно сохранять историю изменения сущности. Ключевые мысли:
- Сохранять историю нужно максимально подробно, без какого-либо анализа.
- Важно разделять состояние сущности и новую сущность (кандидат — сотрудник, наряд — заказ).
- Не все статусы сущности одинаково полезны для аналитики — нужно схлопывать.
Для демонстрации этих хороших и важных мыслей был выбран примитивный пример с моделью жизненного цикла антилопы гну:
А для закрепления полученной информации нам предложили построить модель данных, позволяющую автоматизировать процесс гашения банковских чеков. Либо задача была сформулирована слишком абстрактно, либо участники к концу второго дня подустали, но в итоге готовых решений не было.
Migrating an Enterprise DW from “traditional” to Data Vault based
Автор — Габор Гольнхофер, архитектор с 20-летним опытом работы на проектах ХД в финансах, страховании, телекоме, ритейле и образовании. Презентованный проект заключался в переводе хранилища неопределенно-смешанной архитектуры на Data Vault. Название компании-заказчика не называлось, сказали лишь, что она лидер рынка в своей сфере в Венгрии и входит в международный холдинг. По «тактико-техническим характеристикам» их хранилище сопоставимо с нашим Tinkoff DWH:
- 40+ систем-источников.
- Вехи: 1998 — начало, 2008 — SAS > Oracle, 2016 — Data Vault.
- 22 TB,5000 таргет-таблиц, 9000 ETL-джобов.
C технической точки зрения главной предпосылкой к перестроению хранилища была дороговизна процесса доработок и проблемы с производительностью. Кроме этого, 20 лет эволюции, включающей переход от 3NF к Dimensional и внедрение версионности, привели к архитектурному хаосу. Со стороны бизнеса были требования: высокая скорость изменений, полнота сохранения истории, возможности для self-service BI. Короче говоря, как обычно — побольше, побыстрее и подешевле.
Основные проблемы, с которыми столкнулись коллеги, уверен, знакомы многим. Это и отсутствие в исходных данных подходящих бизнес-ключей, только суррогатные, и низкое качество исходных данных, и нарушения целостности в источниках. Также немало сил пришлось потратить на автоматизацию построения Dimensional — витрин на основе DV — и разработку шаблонов ETL-процедур для загрузки больших массивов данных. Пожалуй, ключевой особенностью проекта был упор на автоматизацию изменений модели и ETL, в результате чего:
- значительно увеличилась скорость внесения изменений,
- снизилось количество багов,
- качество и полнота документации повысились,
- соотношение разработчиков и аналитиков в составе команды изменилось в пользу последних.
Кроме этого, справедливо утверждалось, что Data Vault полезен в деле контроля качества данных, поскольку позволяет сохранять «факты», а не «правду».
Доклад получился интересным и содержательным. В личной беседе после презентации сошлись с Габором в том, что Data Vault не стоит воспринимать как догму, но адаптировать под нужды конкретного проекта.
Итого
Резюмируя содержательную часть конференции, отмечу:
- Использование Data Vault (Anchor Modeling — как опция) — золотой стандарт DWH.
- Тренд сегодняшнего дня — автоматизация [создания метаданных, генерации кода ETL, QA].
- Тренд завтрашнего дня — хранилище в облаке.
- Хорошее знание бизнеса — необходимое условие для построения хорошей модели.
Не хватало презентаций реальных проектов, рассказывающих о способах решения настоящих, а не гипотетических проблем, с которыми сталкиваются проектные команды при использовании красивых и стройных [на бумаге] методологий, об адаптации таких подходов к суровой прозе жизни.
Если говорить об общем впечатлении, основной эффект — мотивирующий. Мотивирующий к тому, чтобы почитать больше о представленных подходах. Мотивирующий заниматься этим достаточно востребованным делом. Пожалуй, аналитиков DWH с опытом до трех лет в первую очередь интересовали бы сами презентации, а их старшие товарищи-архитекторы нашли бы большее удовольствие в общении с коллегами «на полях». Лично мне удалось познакомиться с несколькими коллегами из Европы, Америки, и, как ни странно, России. Повезло пообщаться с некоторыми гуру. К слову, Ханс Хальтгрен в личной беседе сказал, что два русских парня, с которыми он работает в Долине — просто «amazing». И оставил автограф на своей, пожалуй, самой популярной книжке про Data Vault.
mkrupenin
Павел, отличный обзор, спасибо!
А есть где-то записи докладов и материалы этой франшизы?