
Год назад мы добавили в наш агент сбор метрик из S.M.A.R.T. атрибутов дисков на серверах клиентов. В тот момент мы не стали добавлять их в интерфейс и показывать клиентам. Дело в том, что метрики мы снимаем не через через smartctl, а дергаем ioctl прямо из кода, чтобы этот функционал работал без установки smartmontools на серверы клиентов.
Агент снимает не все доступные атрибуты, а только самые значимые на наш взгляд и наименее вендор-специфичные (иначе пришлось бы поддерживать базу дисков, аналогичную smartmontools).
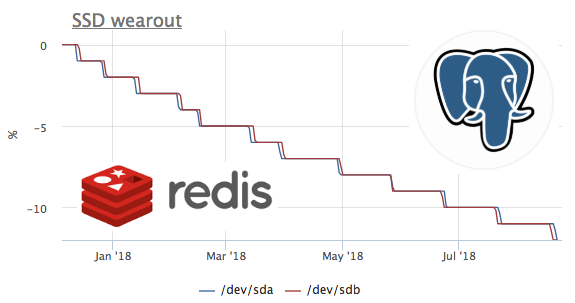
Сейчас наконец дошли руки до того, чтобы проверить, что мы там наснимали. А начать было решено с атрибута "media wearout indicator", который показывает в процентах оставшийся ресурс записи SSD. Под катом несколько историй в картинках о том, как расходуется этот ресурс в реальной жизни на серверах.
Существуют ли убитые SSD?
Бытует мнение, что новые более производительные ssd выходят чаще, чем старые успевают убиться. Поэтому первым делом было интересно посмотреть на самый убитый с точки зрения ресурса записи диск. Минимальное значение по всем ssd всех клиентов — 1%.
Мы сразу же написали клиенту об этом, это оказался дедик в hetzner. Поддержка хостера сразу же заменила ssd:

Очень интересно было бы посмотреть, как выглядит с точки зрения операционной системы ситуация, когда ssd перестает обслуживать запись (мы сейчас ищем возможность провести умышленное издевательство над ssd, чтобы посмотреть на метрики этого сценария:)
Как быстро убиваются SSD?
Так как сбор метрик мы начали год назад, а метрики мы не удаляем, есть возможность посмотреть на эту метрику во времени. К сожалению сервер с наибольшей скоростью расхода подключен к okmeter только 2 месяца назад.

На этом графике мы видим, как за 2 месяца сожгли 8% ресурса записи. То есть при таком же профиле записи, этих ssd хватит на 100/(8/2) = 25 месяцев. Много это или мало не знаю, но давайте посмотрим, что за нагрузка там такая?

Видим, что с диском работает только ceph, но мы же понимаем, что ceph это только прослойка. В данном случае у клиента ceph на нескольких нодах выступает хранилищем для кластера kubernetes, посмотрим, что внутри k8s генерирует больше всего записи на диск:

Абсолютные значения не совпадают скорее всего из-за того, что ceph работает в кластере и запись от redis приумножается из-за репликации данных. Но профиль нагрузки позволяет уверенно говорить, что запись иницирует именно redis. Давайте смотреть, что там в редисе происходит:

тут видно, что в среднем выполняется меньше 100 запросов в секунду, которые могут изменять данные. Вспоминаем, что у redis есть 2 способа записывать данные на диск:
- RDB — периодические снэпшоты всей баз на диск, при старте redis читаем последний дамп в память, а данные между дампами мы теряем
- AOF — пишем лог всех изменений, при старте redis проигрывает этот лог и в памяти оказываются все данные, теряем только данные между fsync этого лога
Как все наверное уже догадались в данном случае используется RDB с периодичность дампа 1 минута:

SSD + RAID
По нашим наблюдениям существуют три основных конфигурации дисковой подсистемы серверов с присутствием SSD:
- в сервере 2 SSD собраные в raid-1 и там живет всё
- в сервере есть HDD + raid-10 из ssd, обычно используется для классических РСУБД (система, WAL и часть данных на HDD, а на SSD самые горячие с точки зрения чтения данные)
- в сервере есть отдельностоящие SSD (JBOD), обычно используется для nosql типа кассандры
В случае, если ssd собраны в raid-1, запись идет на оба диска, соответственно износ идет с одинаковой скоростью:
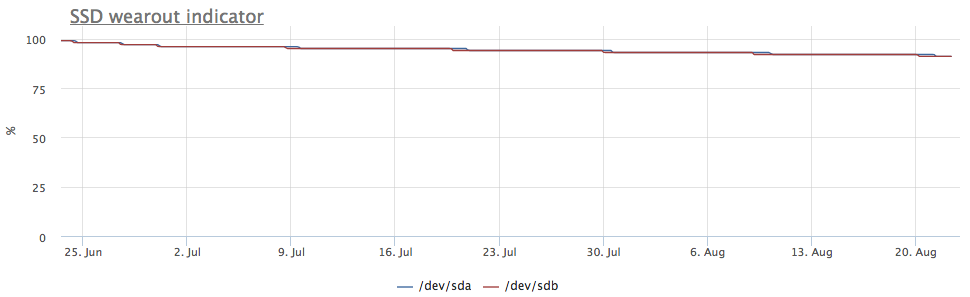
Но на глаза попался сервер, в котором картинка другая:

При этом cмонтированы только партиции mdraid (все массивы raid-1):

По метрикам записи тоже видно, что на /dev/sda долетает больше записи:

Оказалось, что одна из партиций на /dev/sda используется в качестве swap, а swap i/o на этом сервере достаточно заметно:

Износ SSD и PostgreSQL
На самом деле я хотел посмотреть скорость износа ssd при различных нагрузках на запись в Postgres, но как правило на нагруженных базах ssd используются очень аккуратно и массивная запись идет на HDD. Пока искал подходящий кейс, наткнулся на один очень интересный сервер:

Износ двух ssd в raid-1 за 3 месяца составил 4%, но судя по скорости записи WAL данный постгрес пишет меньше 100 Kb/s:
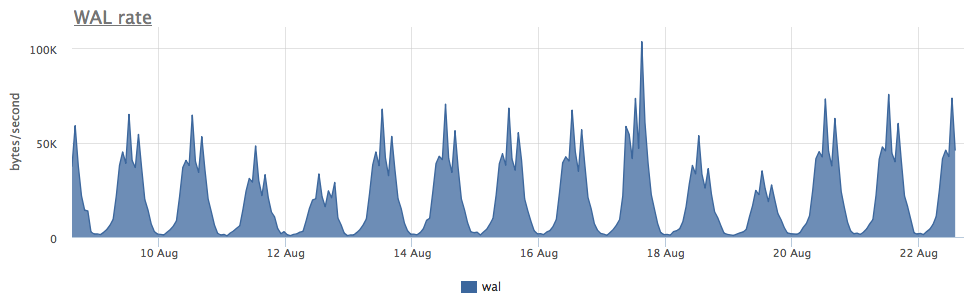
Оказалось, что постгрес активно использует временные файлы, работа с которыми и создает постоянный поток записи на диск:

Так как в postgresql с диагностикой достаточно неплохо, мы можем с точностью до запроса узнать, что именно нам нужно чинить:

Как вы видите тут, это какой-то конкретный SELECT порождает кучу временных файлов. А вообще в постгресе SELECT'ы иногда порождают запись и без всяких временных файлов — вот тут мы уже про это рассказывали.
Итого
- Количество записи на диск, которую создает Redis+RDB зависит не от количества модификаций в базе, а от размера базы + интервала дампов (и вообще, это наибольший уровень write amplification в известных мне хранилищах данных)
- Активно используемый swap на ssd — плохо, но если вам нужно внести jitter в износ ssd (для надежности raid-1), то может сойти за вариант:)
- Помимо WAL и datafiles базы данных могут ещё писать на диск всякие временные данные
Мы в okmeter.io считаем, что для того, чтобы докопаться до причины проблемы инженеру нужно много метрик про все слои инфраструктуры. Мы изо всех сил в этом помогаем:)
Комментарии (118)

larrabee
27.08.2018 17:01Интересная статья, спасибо. А не могли бы вы посчитать (среднюю, и 95/99 перцентиль) скорость износа SSD с разбиением на серверные и консьюмерские модели?
Тот же хецнер грешит тем, что ставит в дешевые сервера десктопные SSD, причем самые дешевые. У нас их десктопные SSD живут примерно пол года с репликами БД, а ентерпрайзные самсунги уже по 2.5 года работают и умирать не собираются.NikolaySivko Автор
27.08.2018 17:06Мне кажется персентили тут ничего не скажут, так как нагрузка разная. Максимальная скорость износа (которую я показал) позволит жить на таких дисках 2 года.
Но с другой стороны, если у вас дедик и хостер меняет диски по запросу, это не такая уж и проблема (если не брать во внимание, что у hetzner диски не hot-swap).
albudnikov
27.08.2018 17:39а какие именно enterprise самсунги?
krab90
27.08.2018 17:56www.samsung.com/semiconductor/ssd/enterprise-ssd если эти то там заявляют 3 года «работоспособности».
larrabee
27.08.2018 18:22Офф гарантия — 3.6 перезаписи всего объема накопителя (500 Гб) в день в течение 5 лет. У нас нагрузка должна быть сильно меньше, до 500 Гб в день. С такой нагрузкой скорее контроллер умрет, чем выработается ресурс.
kalininmr
29.08.2018 02:03там интересная статистика, у самсунгов.
иногда EVO более живучи, чем PRO.
хотя счет у них на петабайтыkalininmr
29.08.2018 11:26есть интересная версия.
ежели много операций на одном месте(что то постоянно обновляем с фсинком)
то кеш у evo очень хорошо работать должен в плане снижения износа.
novice2001
27.08.2018 17:05Только речь не об износе SSD, а о показаниях одного из индикаторов SMART. Который, на самом деле, не измеряет собственно износ ячеек, а просто суммирует количество записанной информации.
NikolaySivko Автор
27.08.2018 17:09Да, именно так, но так как вендоры ничего другого не предлагают, пользователям приходится ориентироваться на этот индикатор. Да и хостеры диски меняют по этому же критерию.
divanikus
27.08.2018 17:07Формально, Wear Out в ноль не означает что диск все. Судя по длительным тестам некоторые диски живут сильно дольше чем заложенный производителем ресурс. Правда на проде я бы конечно не рисковал.
NikolaySivko Автор
27.08.2018 17:12Кстати, ниже 1% индикатор не опускается никогда
brers
27.08.2018 17:42А что означает график в разделе «Износ SSD и PostgreSQL» где от нуля до -4% или в «Как быстро убиваются SSD» где до -7,5%?
NikolaySivko Автор
27.08.2018 17:44Это я так показал "сжигание" — то, как уменьшается показатель. Просто показать 100->92 получалось не особо наглядно.
divanikus
27.08.2018 21:22Если не путаю, то опускается. Ловил круглый 0% и статус FAILED в смарте. Про статус точно, а вот про процент не помню.
BerliozNSK
28.08.2018 07:52У нас была другая ситуация.
По смарту SSD был нормальный. Используется схема HDD+SSD. На SSD система и БД, а на HDD ceph.
Вдруг Zabbix взбесился — посыпались триггеры. Мы пулей к серверу подрубаться. На SSD все разделы стали ro, и ничего не помогает. Даже принудительные пинки на переключение в rw. Я так до конца и не понял, что за фигня неведомая это была. Похоже на то, что SSD исчерпал свой ресурсDrDeimos
28.08.2018 08:32На некоторых марках дисков при исчерпании ресурса записи, например по тому же wearout, ssd принудительно впадает в RO. Так нам намекает производитель, что диск пора заменить.
Frankenstine
28.08.2018 13:16Возможно контролер отловил ошибку записи, с которой не смог справиться, и переключился в режим защиты данных, обрубив возможность записи. У меня такое случилось на консьюмерском кингстоне «из первых», на 64 ГБ, стоявшем в ноуте чуть больше года. Данные слил, ссд юзал как массогабаритную болванку для макетирования. Потом как-то раз включил интереса ради — так он уже и не определялся.
novice2001
27.08.2018 19:10Это не то, чтобы «заложенный», а гарантированный.
И я бы сказал, что не некоторые, а большинство качественных SSD, вроде Samsung, Intel и Kingston. И даже многие более «простые»Mad__Max
28.08.2018 19:19Не гарантированный. В расчет этого показателя закладывают намного большие значения чем в гарантированный ресурс, обычно в несколько раз больше. Хотя многие качественные диски вполне способны работать еще больше, если повезет — еще в разы больше (и соответственно где-то на порядок больше чем назначил производитель в условиях гарантии).
novice2001
30.08.2018 09:37Какого «этого»? В комментарии речь как раз о гарантированном производителем ресурсе.
citius
27.08.2018 17:33Посмотрел на свои сервера с постгресом в окметре, но не увидел там метрик по ssd (хотя очень интересен их wearout).
Нужно что-то сделать, чтобы эти метрики появились?
krab90
27.08.2018 17:51-1Мда у сайта бесконечная загрузка из-за не доступности какого-то rum.okmeter.io
Возможность мониторить каждый запрос БД даже по IO это мощно сделано.ky0
27.08.2018 19:20Возможность мониторить каждый запрос БД даже по IO это мощно сделано.
Хотя казалось бы — это фича постгреса, а не кого-то ещё :)
maximd4
27.08.2018 20:57+1Мой Samsung 850 Evo 500GB потерял 10% ресурса всего лишь после одного процессинга pbf-файла (planet-latest, OSRM). На нем был всего лишь своп на 100GB и файл подкачки STXXL на 200GB. И все.
Archon
28.08.2018 09:44Помещая любого вида своп на SSD, вы автоматически подписываете ему смертный приговор. По-моему, это аксиома.
Самый дешёвый способ обработки подобного рода данных, если нет под рукой машины с нужным количеством памяти — раскрутить виртуалку в облаке, посчитать что надо, выгрузить результат, погасить виртуалку.JC_IIB
28.08.2018 10:27Помещая любого вида своп на SSD, вы автоматически подписываете ему смертный приговор. По-моему, это аксиома.
Я, признаться, до последнего избегал SSD, как-то все на хардах да на хардах. Сейчас собрал себе новый комп, там в качестве единственного носителя данных — EVO 960й. Ему около 2-х месяцев. ОС Win10. Мне бежать отключать своп? Я при помощи самсунговской утилитки посматриваю — вроде пока все норм, но если у вас есть негативный опыт — поделитесь, пожалуйста. Собственно, потому и избегал SSD, что наслышан о том, что они «убиваются» и «внезапно умирают», причем так, что данные не снять никак.
Может, лучше поставить еще хард под своп и файлопомойку?Am0ralist
28.08.2018 10:47+1Да чуть ли не ради свопа переход и нужен) Единственно, напрягают браузеры, которые просто льют и льют инфу десятками гигабайт за день.
Лучше скинуть все папки, которые лежат мертвым грузом на ссд из ОС: папку с дровами виндовыми, папку с помощью и примерами для VS, папку с интаслами и деиннсталами — это в сумме легко может занимать пару десятков гигов, а обращается к этому система единично. А лишнее место на ссд никогда не помешает (и вообще советуют процентов 20 держать свободным).
Так то 840 PRO у меня на ноуте уже год третий как нормально работает под виндой.
А в конторе 750 всякие используем тоже без проблем.JC_IIB
28.08.2018 11:21Кстати да, темп-папка браузера должна здорово нагружать SSD.
А мы ее на RAM-disc положим. Заодно и гарантированно сдыхать будет все при выключении — кукисы, трекеры, пикселы, прочее следящее дерьмо.reff
28.08.2018 12:19+2Паникёры, блин. Вы "затёрли" хотя бы один SSD на десктопных нагрузках?
Одному из используемых 80-гигабайтных накопителей от Intel (модель не помню) уже 10 лет. 10, Карл. Своп не выключен, браузеры пишут на него, даже торрент-клиент пишет туда свою временную мелочь.
Попробовав в работе SSD, обратно вы не вернётесь.
Am0ralist
28.08.2018 12:43Вы «затёрли» хотя бы один SSD на десктопных нагрузках?
И никакого желания этого сделать — нет. Потому что бегай потом, покупай новый, настраивай систему… теряй зря время.
А так, в свободное время поковырялся, перестраховался и пущай работает.
Ну или объясните, зачем на ссд хранить холодные данные, скорость доступа к которой не важна от слова совсем, если рядом есть в разы более емкий hdd?reff
28.08.2018 13:04Второго накопителя может не быть, например, потому что это ноутбук или ПК любителя тишины.
Am0ralist
28.08.2018 13:12Для начала, обсуждение пошло с вопроса человека про второй винт.
Во-вторых, в старых ноутах и части новых — вместо CD-привода, в другой части новых M2 и Sata.
Ну и в третьих:
Так то 840 PRO у меня на ноуте уже год третий как нормально работает под виндой.
И да, второй винт — тихий, просто — тормоз, чтоб тормозами ОС достать. А шум охлаждения (особенно в ноутах), фоновый гул колонок и шумы жилого дома убрать намного сложнее.
sumanai
28.08.2018 20:50-2настраивай систему
Если SSD исчерпал ресурс, то он переходит в RO режим, и слить опию на новый диск не проблема.Am0ralist
28.08.2018 21:07+1Даже тут в комментах писалось, как некоторые SSD при проблемах с износом ячеек начинают чудить.
Да, самсунги этим вроде не грешат, но кто ж гарантию даст.
ClearAirTurbulence
28.08.2018 22:42Потому что бегай потом, покупай новый, настраивай систему…
Образы вроде не вчера придумали. Покупку с доставкой на дом тоже. Только до этой покупки еще дожить надо, убить SSD довольно нелегко, мне не удавалось пока, хотя у меня там и своп, и профили, и даже торренты на него лью.
Wizard_of_light
28.08.2018 12:43Я таки ушатал 128GB RevoDrive3, где-то лет за пять. Года четыре стояла Win7, профили пользователей и программы, настроено всё было по моде 2013 года — отключен prefetch и своп, временные файлы вынесены на рамдиск, рабочий стол и документы вытащены на HDD. Потом стало не хватать места, система переехала на 512GB Plextor уже без особых заморочек на оптимизацию, а на реводрайв свалился своп и временные файлы, которые его ещё через год доконали — стал доступен только для чтения, при попытке что-то записать виснет и делает вид, что его нет. Сейчас на полочке лежит как экспонат, надо будет проверить теперь, сколько он информацию в отключенном состоянии держит :)
reff
28.08.2018 13:04Он же энергонезависимый.
Am0ralist
28.08.2018 13:17Он же энергонезависимый.
поздравляю, вы только что узнали много нового про SSD)))
Wizard_of_light
28.08.2018 13:17Изоляция в ячейках флеша не идеальная, со временем заряд утекает. Ходят слухи, что через пару-тройку лет данные уже не прочитать. В смысле, еcли эту пару-тройку лет SSD без питания пролежит. Читал рекомендации хранить в холодильнике, при низких температурах темп потери заряда снижается :)
novice2001
30.08.2018 09:51Да-да, лучше купить SSD и положить на полочку, чтобы не износился и не покупать потом новый.
Am0ralist
30.08.2018 09:59Демагогический прием — опровержение мнения, искусственно доведя его до абсурда.
Archon
28.08.2018 11:08Я не использую своп на десктопах вообще, поэтому конкретным опытом поделиться не могу. Но логика подсказывает, что лучше его выключать, если нет необходимости запускать программы, не помещающиеся в ОЗУ.
Ну а вообще, у полноценных серий (а-ля 960 эво) количество циклов перезаписи уже такое, что можно не заморачиваться ничем. Лет 10 всяко прослужит, а там уже в любом случае будет неактуально.JC_IIB
28.08.2018 11:13Ага, спасибо за ответ… значит, вместо харда все же лучше купить вторые 32 Гб RAM и вырубить своп.
mayorovp
28.08.2018 12:03Но SSD того же объема намного дешевле...
JC_IIB
28.08.2018 12:17У меня один М.2 слот на матери, а DDR4 — четыре, два свободных. Да и с самого начала, когда систему будущую считал, сразу хотел 64 гигабайта.
DelphiCowboy
28.08.2018 13:03Потому у меня желание купив SSD использовать его только под своп. А если сдохнет, то своп — не жалко.
reff
Есть Persistent Memory (PMEM), находящаяся между RAM и SSD по упомянутым критериям.
Накопители в продаже есть?
Am0ralist
28.08.2018 12:03Если больших объемов холодных или архивных данных нет, а добить оперативку реально — то вполне себе решение. У меня 16 гигов максимум, но даже при этом без свопа проблем не было на домашних задачках.
ClearAirTurbulence
28.08.2018 22:50+1Если вы используете Win, это не рекомендуется делать разработчиком независимо от объемов используемой памяти.
В частности,
No matter how much RAM you have, you want the system to be able to use it efficiently. Having no paging file at all forces the operating system to use RAM inefficiently for two reasons. First, it can't make pages discardable, even if they haven't been either accessed or modified in a very long time, which forces the disk cache to be smaller. Second, it has to reserve physical RAM to back allocations that are very unlikely to ever require it (for example, a private, modifiable file mapping), leading to a case where you can have plenty of free physical RAM and yet allocations are refused to avoid overcommitting.
Consider, for example, if a program makes a writable, private memory mapping of a 4GB file. The OS has to reserve 4GB of RAM for this mapping, because the program could conceivably modify every byte and there's no place but RAM to store it. So immediately, 4GB of RAM is basically wasted (it can be used to cache clean disk pages, but that's about it).
You need to have a page file if you want to get the most out of your RAM, even if it's never used. It acts as an insurance policy that allows the operating system to actually use the RAM it has, rather than having to reserve it for possibilities that are extraordinarily unlikely.
The people who designed your operating system's behavior are not fools. Having a paging file gives the operating system more choices, and it won't make bad ones.Am0ralist
29.08.2018 09:50Но по факту его можно или урезать в край, да и при отключении на обычных задачах проблем не обнаружено уже год третий (при 16 гб оперативки).
Хотя есть вариант для извращенцев — своп на рамдиске! )))reff
29.08.2018 09:58Значит и хранение/обработка суровых баз данных в ОЗУ тоже "извращение"?
Mad__Max
30.08.2018 00:33А зачем именно рам-диск? Если оперативной памяти достаточно нормальная СУБД сама должна все активные данные в памяти постоянно держать, без костылей с размещением файлов на рам-диске.
reff
30.08.2018 10:23In-Memory OLTP в SQL Server 2014
https://habr.com/post/225167Am0ralist
30.08.2018 11:03То есть спец.инструмент для работы в памяти вы приравняли к костылю костыля для костыля? ;)
Ибо своп — это костыль из-за малого объема оперативки.
Рам-диск — это костыль из-за медленной скорости HDD (вспоминая i-RAM тот же)
А перенос своп-файла на рамдиск — это костыль, потому что ОС не привыкли работать без свопа, несмотря на то, что оперативки овердофига, а скорость доступа к данным напрямую с SSD возросла…
Alext8409
28.08.2018 19:20Вот откуда вы берете такое? «Я купил стиральную машину, но стираю в ней только носки, а все остальное руками!». SSD для того и сделан, чтобы все, от чего зависит скорость лежало на нем! Т.е. Temp, pagefile, hyberfil и профиль с кэшами. Таким образом можно оживить даже старый ноутбук с 2Гб ОЗУ и селероном, проверено. Все из-за свопа, ноут начинает работать так быстро, что даже не замечаешь, что все вкладки и документы считываются уже из свопа. Параметр TBW для кого придумали? Обычный домашний диск имеет в районе 80 TBW, т.е. на него можно гарантировано записать 80 Тб, если у вас нагрузка больше — берите более лучшую модель, например самсунги с их новой TLC. У меня плекстор M6Pro два года трудится дома, записано виндой всего 11 Тб, ничего никуда не перенесено, все по дефолту. Т.е. они морально устареют, пока закончится их ресурс, вот сейчас заказал самсунг 970 EVO, хочу NVME посмотреть в работе, виртуалки с обычного HDD тормозят, а там 150 TBW! И это домашний SSD. И при этом у меня все равно акронис делает в фоне каждую неделю бэкап на HDD + иногда бэкаплю всю систему еще и в виртуалку, преждевременный выход из строя контроллера или еще что-то никто не отменял, тем более пока что все покупают SSD именно под ОС, а не под хранилище личных файлов и их объемы 120-250Гб. Поэтому советую выкинуть из головы эти пережитки прошлого, когда свопы, кэши дома раскидывали по дискам и парковали головки дабы увеличить скорость, а также продлить жизнь драгоценному HDD.
Alext8409
28.08.2018 20:11У 960 EVO от 100 до 400 TBW (в зависимости от объема) — этого более чем достаточно для того, чтобы не отключать своп. Не слушайте паникеров, которые пытаются контролировать запись каждого файла (как автомобиль при СССР, если уж купили, то на всю жизнь ведь, потому берегли и ездили по праздникам). Своп вообще-то не рекомендуется в windows выключать, можно сделать мин размер, да и ошибки в логах не будет. SSD нужно пользоваться по макс, радуясь производительностью и откликом.

lokkiuni
28.08.2018 10:46+2Покупая любой SSD, вы автоматически подписываете ему смертный приговор. По-моему, это тоже аксиома.
Смысл от него, если его не нагружать? Как раз с файлом подкачки он сильно ускоряет работу. Да и к тому моменту, как он реально уедет в 0, он уже 100 раз устореет, по крайней мере MLC моделей это касалось — несколько лет они живут, а жесткий… Вот не уверен, очень не уверен — в лучшем случае, старшие, дорогие модели. Тем более, что альтернатива с +- сравнимой скоростью это хотя бы 4-8 быстрых дисков в рейде, если о сата разговор (ну или 4 15000 в 10м рейде более-менее не просаживаются на случайных операциях, хотя отклик конечно и близко не тот). Помнится, HP p2000 g3 мучал с 6 15000ми — не шибко она была быстрее, чем тогда актуальный Intel x25-m, а по скорости сейчас даже бюджетные получше смотрятся.
Но способ, описанный вами, имеет право на жизнь, не спорю, хотя ради 1 раза я бы не заморачивался.
Druu
28.08.2018 11:19+2Помещая любого вида своп на SSD, вы автоматически подписываете ему смертный приговор. По-моему, это аксиома.
Так от помещения свопа на SSD основная выгода и идет. Можно не помещать, а положить SSD на полочку — тогда-то точно не умрет :)
Archon
28.08.2018 11:23Видимо, у нас с вами разные кейсы использования SSD. Если компьютеру не хватает оперативки и он лезет в своп на обычных задачах, я всегда добивал оперативки. А SSD выполняет роль быстрого хранилища данных, и не требует себя нагружать в полочку. Тем более, M.2 PCI-E в полочку особо и не понагружаешь, он будет перегреваться и снижать скорость.
Alext8409
28.08.2018 19:45Nvme ssd греются при очень длительных нагрузках, обычно дома такое случается редко, так что троттлинга я бы не боялся. На многих платах идет в комплекте радиатор, или можно отдельно с ибея заказать, а во всяких геймерских системниках столько вентиляторов, что заодно и его охлаждают. Попадают те, у кого М2 слот единственный и сразу над видюхой, которая сама греется как печка, да еще и не имеет турбины для выдува наружу. Но и тут есть решение — переходник M2-PCI-e x4.
JC_IIB
28.08.2018 20:01Попадают те, у кого М2 слот единственный и сразу над видюхой
Это вот я. Ну да у меня для игр пс4 есть, соответственно, видюха бралась по принципу «дорогущие монстры нам ни к чему» — 1050Ti.
переходник M2-PCI-e x4.
А скорость на таком бутерброде не падает?Alext8409
28.08.2018 22:15Не падает, если это нормальный адаптер, asus например. Это просто пассивное продолжение PCI-E разъема и на конце m2 разъем, главное чтобы были все 4 линии распаяны. И еще — на материнках M2 имеет и SATA и PCI-E линии, т.е. можно подключить как обычный SSD SATA AHCI в форм факторе M2, так и SSD PCI-E NVME. Переходники же имеют только PCI-E линии и обычный sata диск не будет работать.
maximd4
28.08.2018 11:43Прикиньте стоимость виртуалки с 160GB RAM и 500GB дисков. Да, можно взять spot-instance и он обойдется в 10$, но где гарантия, что за 10-20 часов использования его не заберет тот, кто предложит на 1 цент больше?
Очень тонкая грань, знаете ли. А так — SSD на 500GB стоит 90$. Раз в год посчитать планету (или чего еще, что требует много-много памяти) — да его хватит навсегда. И он весь твой. :)

ladutsko
27.08.2018 21:13Какая альтернатива RAID 1 для SSD?
yosemity
28.08.2018 00:01Взять с полки ЗИП, поменять зеркало принудительно через 2-3 месяца, исходный SSD положить на полку в роли ЗИП.
Alext8409
28.08.2018 19:02RAID1 для SSD + регулярные бэкапы + в ящике пару запасных дисков. В принципе такая схема и к HDD всегда относилась.
Wizard_of_light
27.08.2018 22:05Народ, кто знает, как вообще чаще всего умирают SSD по исчерпании ресурса? В ридонли переходят или просто тихо исчезают из системы? У меня просто лежит старый убитый OSZ RevoDrive 3, на него нельзя ничего записать, но что на нём лежит — можно прочитать или стереть, и система его видит нормально. Как я понимаю, это не самая жесть.
JerleShannara
27.08.2018 22:18Как повезет, если контроллер sandforce, то вас ожидает гарантированная лотерея.
Mad__Max
28.08.2018 00:04Это наоборот можно считать идеальный вариант. Чаще диск просто неожиданно (если за показателями SMART не следить) умирает полностью.
Пользователи грешат на «сдохший контроллер», хотя часто это именно сдохший от износа флэш. Хотя контроллер тоже виноват частично — тем что такую ситуацию не отработал корректно.
Просто сдыхают ячейки в которых была критическая служебная информация — прошивка например или таблица адресации блоков. И диск при следующем включении окирпичивается.
На 3dnews длительный тест на выносливость SSD идет, в т.ч. с описанием как именно диск умер. Ну и я сам уже несколько умерших SSD видел — все умерли после значительного износа в момент включения после длительного(дни-недели) простоя.Mad__Max
28.08.2018 00:23P.S.
Забыл уточнить — это я про диски потребительско-офисного класса писал.
Как в этом плане серверные модели себя ведут — не в курсе.
Zettabyte
28.08.2018 07:08Пользователи грешат на «сдохший контроллер», хотя часто это именно сдохший от износа флэш.
…
Просто сдыхают ячейки в которых была критическая служебная информация — прошивка например или таблица адресации блоков. И диск при следующем включении окирпичивается.
Именно так — невозможность загрузить служебную информацию — очень распространённая у современных ССД проблема.
При этом обойти её даже частично, например, для восстановления данных (однократного, хотя бы медленного чтения на специализированном оборудовании), как в целом сложнее, чем у жёстких дисков, так и наработок в этой области меньше.
Alext8409
28.08.2018 19:35Кирпич в каком смысле? Вообще не определяется мат платой или ФС нет? Пару случаев знаю, что диск из-за скачка в сети оказался без ФС, но видился в системе как будто свежеустановленный диск. R-studio восстановила все файлы. А бывает как у Foxline — именно кирпич, которого даже не видно в системе, а диску два месяца бытого использования, сбой в контроллере. Да, и все эти случаи были именно утром при включении машины с великолепной надписью inaccessible boot device :)
JerleShannara
28.08.2018 21:10+1Кирпич, когда этот диск на SATA/PCIe вообще не находится, а единственное место, куда он может что-то и отвечает — отладочный USART, который ещё и не распаян
Mad__Max
28.08.2018 21:55Да, кирпич — в смысле перестает определяется вообще как подключенное устройство. Ошибки файловой системы то поправить не велика проблема.
А подобный «кирпич» только если в хорошей мастерской оживить можно. Причем если не затягивать с этим, а заняться сразу — т.к. если причиной окирпичивания стал начавшийся сыпаться флэш, то чем дольше диск пребывает в нерабочем состоянии, тем сильнее деградируют еще оставшиеся на нем данные.
Пока диск работает, контроллер за этим следит и периодически «обновляет» (перезаписывает) все данные если это не происходит естественным образом (за счет активности пользователя). А вот на выключенном (или неисправном) диске этим заниматься уже некому.
Пока диск относительно новый это не проблема — в пределах гарантированного производителем ресурса данные ЕМНИП должны сохранятся в выключенном состоянии как минимум год(зависит еще от температуры хранения — чем выше, тем быстрее). Но вот чем дальше за пределы гарантированного ресурса уходит износ, тем выше становится риск данные на выключенном диске потерять.
P.S.
Со «слетевшей» ФС тоже пару раз сталкивался, но это именно из-за каких-то проблем непосредственно в процессе работы(записи). А вот «кирпичи» обычно были в ситуациях вида: диск вроде бы нормально работает (хоть уже и задрючен судя по SМART), в какой-то момент остается без работы (например в офисе — сотрудник в отпуск уехал и его комп неск. недель не включался никем), а при следующем включении — кирпич.
lokkiuni
28.08.2018 10:48SMedia тут сдохла — вроде бы всё читается, всё хорошо, но контроллер виснет на какой-то ячейке и всё. Т.е. образ до 20гб считывается на ура, а дальше диск висит и не отвечает. Смарты идеальные, как будто никогда не менялись. Хотя постойте...)
Throwable
28.08.2018 13:38У нас контроллер выдал ошибку записи, после чего линукс перемонтировал систему в R/O. После этого система работала еще 6 месяцев, пока не заменили диск :)
Wizard_of_light
28.08.2018 13:47Oгo… Систему полгода в режиме LiveCD гонять — это уж точно не для каждого :)
Throwable
28.08.2018 14:51Просто вовремя не заметили. Там только веб и серваки вертелись, а база была на другой машине. Поэтому все работало. Диск вроде Samsung был.

SergeyPerm
27.08.2018 23:43Был десктопный SSD OCZ (модель не помню), на 250 Гб, работал 3 года, жила на нем 1С маленькой кампании. И вела 1С гиговые логи. И вдруг все сломалось. При обращении к области данных, где был лог, система зависала наглухо, в том числе и Debian. То есть система загрузилась, вроде все ок, но как только происходило обращение к логу, то все рушилось и не поднималось.
Лечение было таким: загружаясь с livecd, при помощи dd, кусками копировалось все на идентичный по размеру новый SSD. Если кусок попадал на данный лог файл, то все зависало наглухо и после перезагрузки кусок уменьшался (никакие параметры а-ля «пропускать, если не читается» не прокатывали потому, что все зависало на глухо). Вот так за сутки вручную удалось почти весь диск за минусом 2-3 гб (там только сам лог 1с и был), и успешно загрузились с нового диска (+ стандартная проверка диска после этого с исправлением ошибок, система работает до сих пор и не переставлялась)Urub
28.08.2018 12:35А сколько было записано и считано на этом SSD?
Смарт показали ли что касательно сбоя?
Sap_ru
27.08.2018 23:55«Очень интересно было бы посмотреть, как выглядит с точки зрения операционной системы ситуация, когда ssd перестает обслуживать запись (мы сейчас ищем возможность провести умышленное издевательство над ssd, чтобы посмотреть на метрики этого сценария:)»
Дык, это уже ни раз делали. Тот же Intel даже пишет, что конкретно происходит и когда. Был даже тест износа Intel vs Samsung, что будет когда оба упрутся в предел. Intel перешёл в RO режим и стал возвращать ошибки записи как только дошёл до расчётного предела. Samsung пытался измерять износ и потом ушел далеко за обещанных предел, дальше не помню. Кто-там ещё вообще поломался, а после перезагрузки перешёл в R/O режим.
Sap_ru
28.08.2018 00:09+1И ещё интересно, что это за сервер такой, в котором активно работает swap и это всех устраивает.
arthi7471
28.08.2018 08:52На моей памяти были помершие SSD совсем не от износа памяти а от контроллеров. Жаль в статье об этом ни слова.
Alext8409
28.08.2018 15:19Да, и это очень важный момент. Например, всем известные (а купило их много народу) бытовые Foxline на MLC (!), которые производились год-полтора назад, все имеют один и то же косяк. Умирает контроллер при достижении какого-числа циклов R/W. Какого именно хочу выяснить на еще на нескольких живых экземплярах. Диск просто перестает видится в системе, данные вытягивали только при вскрытии и замене контроллера и конечно лишившись гарантии и обмена. Такое же еще было с серверными Кингстон, модель не помню, пару лет назад знакомый попал, отказали одновременно 4 диска в массиве из 4 дисков :) Так что бэкапы (не только данных, но и образ системы) — это наше всё.
Sap_ru
29.08.2018 03:01Выглядит, как ошибка в реализации алгоритма чередования секторов. Он где-то протирает диск до дыр и сам этого не замечает.
YuriSerpinsky
28.08.2018 15:02Год назад мы добавили в наш агент сбор метрик… В тот момент мы не стали добавлять их в интерфейс и показывать клиентам.
Ребят, вы, конечно, молодцы, и делаете отличный продукт, но что это за подход??? Вы добавляете недокументированную функцию в сервис, который начинает собирать дополнительные данные, а клиенты узнают об этом через год. Замечу, что сервис работает с серверной (как правило критически важной) инфраструктурой, обрабатывающей данные различных категорий.
Компании платят деньги за те возможности сервиса, которые зафиксированы в договоре. Любое отклонение — это плохо, особенно, когда новые возможности реализуются скрыто. Если этот сервис развивается для решения серьёзных задач и с прицелом в энтерпрайз, то с такими «пасхальными яйцами» могут быть внезапные сложности с законом.
А так то, конечно, статья интересная, желаю вам бурного роста и развития.NikolaySivko Автор
28.08.2018 15:07Согласен с вами, тут явная проблема в наших процессах. Мы сейчас активно над этим работаем. Спасибо за ваши пожелания!
Pas
Забавно видно, что RAID1 в случае SSD скорее всего не поможет года через два самовыпиливания диска/ов. Хотя это один из самых популярных сетапов bare-metal дедков.
NikolaySivko Автор
Да, в этом случае можно искусственно убивать один из дисков быстрее, например отрезав партицию и заюзав ее под своп или redis:)
Pas
А в случае HW RAID что делать? ))
А есть сеты с XOR? RAID5, ZFS, etc. Там по идее картина износа может быть иной.
Ezhyg
Что такое «партиция»?
bykvaadm
partition
Ezhyg
«Партишн», прочитал. Аффтар, зачем меняешь ник?
Поясняю, если не дошло — это не ответ на вопрос, даже если забыть, что вопрос, разумеется, риторический.
bykvaadm
а давай ты хамить не будешь случайно проходящему человеку?
Ezhyg
А давайте вы не будете хамить в ответ, даже придумав себе, что вам нахамили? :(
Хотя, я понимаю, даже очевидные сарказм и ирония, могут быть непонятны в невербальном общении, а смайлик я поставить забыл, чесслово! :-\.
Для меня хамство — отсутствие ответа, иногда и на «как бы» риторические вопросы. Хамство — ответ на вопрос не отвечающий на вопрос, а особенно и вовсе опровергающий. «Хотя каждый ответ может быть словом, не каждое слово будет ответом» (ц).
bykvaadm
Ну, во-первых мне не понравилось, что кто-то своим сарказмом, направленным на автора статьи почему-то решился пройти по мне, человеку, который никакого отношения ни к статье, ни к комментарию со словом «партиция» не имеет.
«Поясняю, если не дошло» — это чистой воды хамство. Маме своей так скажешь? если нет — не забудь добавить эту фразу в свой словарь определений.
Ezhyg
Не соблаговолите ли вы уточнить, какие конкретно слова, вам «не понравились»?
А то мне много чего не нравится… точнее, мало что нравится :(.
Я не «проходился», даже в мыслях не было, это обычный ответ с пояснением — «данный ответ — ничего не прояснил», а уж две буквы «фф» в слове «Аффтар» — яркий вымпел несерьёзности!
Эм, то есть человеку который всё решил ответить на вопрос заданный не ему? Тот самый человек, который ни к автору, к которому обращался вопрошающий, ни к слову «партиция», не имеет? О_о
Мама прекрасно знает мою манеру общения и в общении между нами допустимо даже то, что с незнакомыми людьми может показаться «из ряда вон» (во многих смыслах). Так себе аргумент.
«Поясняю, если не дошло» — не хамство, а «внезапно(!)» — просто пояснение.
До меня сейчас не доходит, вам настолько сложно признать свою ошибку? Ох уж эти слабости человеков :(
divanikus
Имею n-ое количество серверов с SSD в RAID1, как ни странно, они убиваются не одновременно, есть отрыв до 5-10%.
kalininmr
тоже замечал такое.
и у обычных hdd тоже странные артефакты порой.
возможно ТТХ дисков и, например, повторная запись по каким то причинам.
вот местами бы их поменять и посмотреть.
Melkij
Для hdd то как раз вполне объяснимо: raid1 даёт одинаковую нагрузку на запись, но на чтении она не одинаковая получается часто.
У ssd может по разному срабатывает очистка страниц
kalininmr
на тему чтения, я замечал что контроллеры по разному себя ведут.
некоторые чередуют нагрузку, некоторые вобще только по готовности обоих.
reff
Оба контроллера умеют работать c SSD? Вероятно, первый умеет и таким образом пытается как бы беречь накопители, а второй считает их НЖМД и работает соответственно.
kalininmr
второй похоже «почестному» работает, сравнивает одинаковость
Melkij
Да, об этом как раз и говорю, по балансировке чтения много различий.
Софтовый linux raid балансирует чтение вообще между потоками. Если с диска читает один поток — то нагрузка будет только на один том массива, а второй будет простаивать (вместо чередования запросов).
muxx
utcc.utoronto.ca/~cks/space/blog/linux/UnbalancedSSDMirrorReads
Мы стабильно видим, особенно разница быстро выявляется на серверах баз. Один из дисков в 2 раза раньше умирает.
Alexsandr_SE
Для SSD зеркало это защита от механических поломок. В теории один диск нужно менять на середине жизни и держать в запасе.
kalininmr
простите, а какие у SSD механические поломки бывают?
Frankenstine
Я думаю, имелись в виду выходы из строя не по причине износа. Например, выход из строя контролера.
kalininmr
мне кажется тут лучше подходит термин «аппаратные». наверное
Alexsandr_SE
Как в магнитофоне или приемнике. Электроника не выдерживает. А сервис центы если не дай бог подгорела деталь из-за выхода из строя пишут про механическое повреждение. Хотя аппаратные точнее как выше замечено.