
 Не так давно в датацентре, в котором мы арендуем серверы случился очередной мини-инцидент. Никаких серьезных последствий для нашего сервиса в итоге не было, по имеющимся метрикам нам удалось понять что происходит буквально за минуту. А потом я представил, как пришлось бы ломать голову, если бы не хватало всего 2х простеньких метрики. Под катом коротенькая история в картинках.
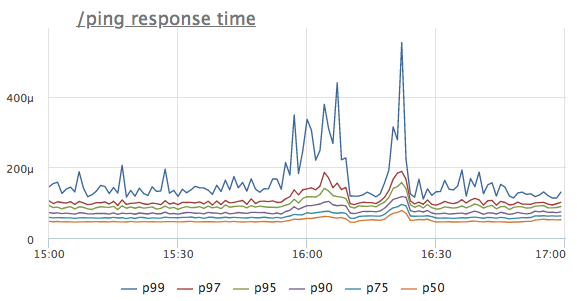
Не так давно в датацентре, в котором мы арендуем серверы случился очередной мини-инцидент. Никаких серьезных последствий для нашего сервиса в итоге не было, по имеющимся метрикам нам удалось понять что происходит буквально за минуту. А потом я представил, как пришлось бы ломать голову, если бы не хватало всего 2х простеньких метрики. Под катом коротенькая история в картинках.Представим, что мы увидели аномалию на графике времени ответа некоторого сервиса. Для простоты возьмем хэндлер /ping, который не обращается ни в базы данных, ни в соседние сервисы, а просто отдает '200 OK' (он нужен для балансировщиков нагрузки и k8s для health check сервиса)

Какая мысль возникает первой? Правильно, сервису не хватает ресурсов, скорее всего CPU! Смотрим, на потребление проца:
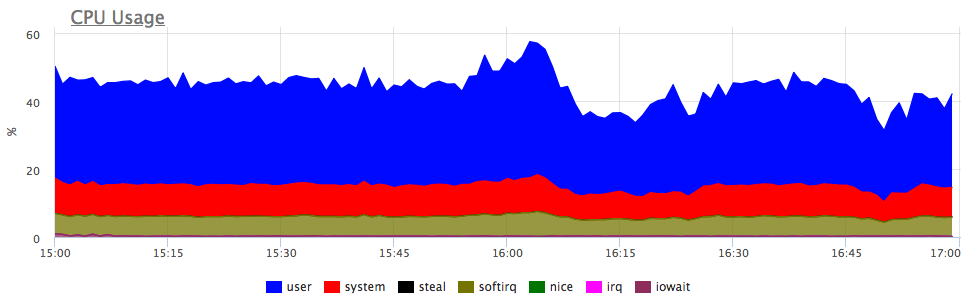
Да, есть похожие всплески. Дальше смотрим, на потребление в разрезе сервисов на сервере:
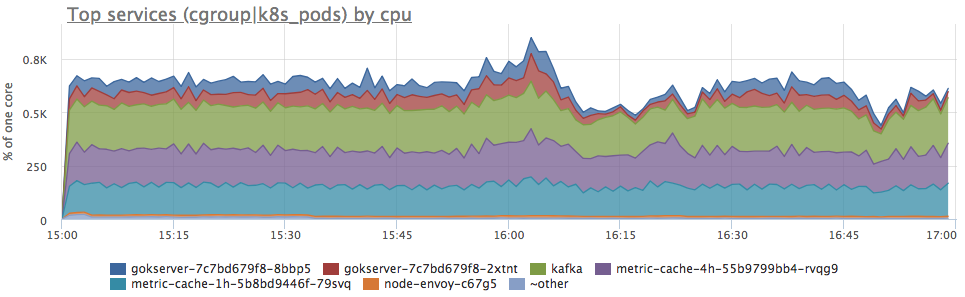
Видим, что потребление проца выросло по всем сервисам пропорционально. Дальше однозначно ничего сказать нельзя: можно идти и смотреть, изменился ли профиль нагрузки (так как все компоненты связаны и увеличение запросов на входе может реально вызвать пропорциональное повышение потребления ресурсов) или разбираться, что стало с ресурсами сервера.
Я конечно как мог пытался сохранить интригу, но по началу статьи вы наверное уже догадались, что у сервера просто уменьшилось количество доступных cpu тактов. В dmesg это выглядит примерно так:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
Грубо говоря, у нас понижена частота из-за перегрева процессора. Смотрим на температуру:
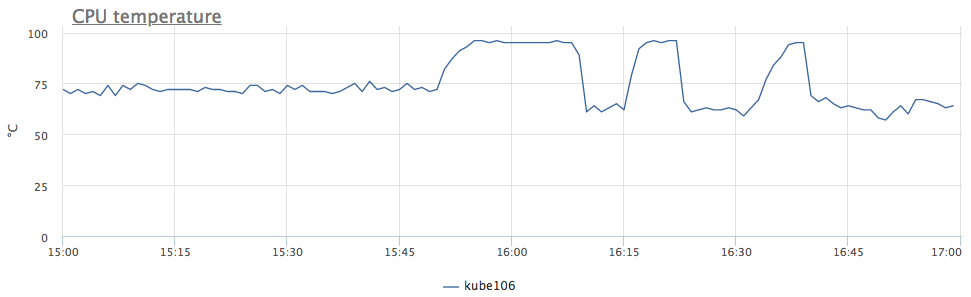
теперь все понятно. Так как у нас подобное поведение наблюдалось сразу у 6 серверов, мы поняли, что проблема в ДЦ, причем не во всем, а только в определенных рядах стоек.
Но вернемся к метрикам. Мы потенциально хотим знать, если серверы будут перегреваться в будущем, но это же не повод добавлять график температуры процессоров на все дашборды и каждый раз это проверять.
Обычно для оптимизации процесса слежение за какими-то метриками используют триггеры. Но какой порог выбрать для триггера по температуре процессора?
Именно из-за сложности выбрать хороший порог для триггера, многие инженеры мечтают о детекторе аномалий, который без настроек сам найдет то, незнаю что :)
Первая мысль — поставить в качестве порога температуру, при которой у нашего сервиса начались проблемы. А если у вас ни разу не было перегрева? Вы конечно можете посмотреть, на мой график и решить для себя, что 95 °С это то, что вам нужно, но давайте еще немного подумаем.
Проблема же у нас не из-за градусов, а из-за того, что понизилась частота! Давайте будем отслеживать количество таких событий.
В linux это можно снять из sysfs:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

Если честно, мы даже никуда не выводим эту метрику, у нас есть только автотриггер для всех клиентов, который срабатывает при достижениие порога "> 10 events/second". По нашей статистике при таком пороге ложных срабатываний практически нет.
Да, этот триггер очень редко срабатывает, но когда подобное случается, он очень облегчает жизнь!
Мы в okmeter.io большую часть времени как раз и занимаемся разработкой нашей базы автотриггеров, которые упрощают нашим клиентам поиск неизвестных для них проблем.
Комментарии (10)

lioncub
20.08.2018 16:38А из-за чего температура выросла в итоге?
NikolaySivko Автор
20.08.2018 17:05В датацентре что-то было с отводом тепла, само кончилось через 40 минут. По графику скорости падения температуры мне в FB подсказали, что у нашего хостера жидкостное охлаждение процов и что-то было с циркуляцией хладагента.
sergeymartynenko
20.08.2018 17:57Именно из-за сложности выбрать хороший порог для триггера, многие инженеры мечтают о детекторе аномалий, который без настроек сам найдет то, не знаю что :)
Попробуйте мониторинг настроить при помощи карт Шухарта. Метод известен довольно давно (с 1924 года). С тех пор очень хорошо себя зарекомендовал. И эти карты просто просятся для применения в мониторинге ЦОД-а.
Критерии можно взять из ГОСТ Р 50779.42-99. А можно из какой нибудь книги по статистическому управлению. Вот с подбором размера партии придется помучиться, это да.NikolaySivko Автор
21.08.2018 10:44Детектор аномалий мы будем делать, мы периодически пробуем разные подходы на реальных данных.
youROCK
Удачи с виртуалками… Эх…
youROCK
Поясню комментарий: в виртуализированной среде зачастую очень сложно отлаживать проблемы производительности из-за многих факторов:
1. Недоступность многих метрик производительности (в том числе наверняка cpu throttle не пробрасывается)
2. «Шумные соседи» могут, к примеру, вымывать кеш процессора, повышая CPU usage в вашей системе, но при этом суммарно ресурсов будет всем хватать
3. Практически всегда отсутствие возможности посмотреть метрики хостовой системы
При этом, я не утверждаю, что виртуализация вредна, но такие проблемы до сих пор никто не решил по-человечески, и вряд ли Azure или Amazon их тоже как-то прямо очень хорошо решают, к сожалению (хотя мне ни разу не удавалось их уличить в overprovisioning'е).
NikolaySivko Автор
youROCK
2. Имеется в виду кеш L1/L2/L3 процессора, его можно вымыть с другой VM спокойно :).
khanid
Ну, справедливости ради, серьёзные хостеры и провайдеры vps не занимаются, как правилом, ощутимым оверселлом. Думаю, они закладывают некоторый запас от полного исчерпания ресурсов. Это же не какие-нибудь супербюджетные вутхостинг и альфарэкс с OVZ cерверами 1cpu/1GB/40Gb/100Mbps за $10 в год. Удовлетворённость клиента для крупных провайдеров уже не на последнем месте, ибо это имидж и будущие подписки.