
Эта заметка продолжает разбор улучшений производительности, которые могли бы стать явью, если бы не разные "но". Предыдущая часть о StringBuilder-е находится здесь.
Здесь мы рассмотрим несколько "улучшений", отклонённых из-за непонимания тонкостей спецификации языка, неочевидных угловых случаев и других причин. Поехали!
Когда ничто не предвещает беды
Думаю, каждый из нас работал с методами Collections.emptySet() / Collections.emptyList(). Это очень полезные методы, которые позволяют вернуть пустую неизменяемую коллекцию без создания нового объекта. Посмотрев внутрь класса EmptyList мы увидим там вот это:
private static class EmptyList<E> {
public Iterator<E> iterator() {
return emptyIterator();
}
public Object[] toArray() {
return new Object[0];
}
}Видите мощный потенциал для улучшения? Метод EmptyList.iterator() возвращает пустой итератор из наличия, почему бы не сделать такой же финт ушами для массива, возвращаемого методом toArray()?
The returned array will be "safe" in that no references to it are maintained by this list. (In other words, this method must allocate a new array even if this list is backed by an array). The caller is thus free to modify the returned array.
http://mail.openjdk.java.net/pipermail/core-libs-dev/2017-September/049170.html
http://hg.openjdk.java.net/jdk/jdk12/file/ffac5eabbf28/src/java.base/share/classes/java/util/List.java#l185
Иными словами, метод должен всегда возвращать новый массив.
Вы скажете: "Он же неизменяемый! Что может пойти не так!?"
Ответить на этот вопрос могут только опытные знатоки:
— Кто отвечает?
— Отвечают знатоки Пол Сандоз и Тагир Валеев
http://mail.openjdk.java.net/pipermail/core-libs-dev/2017-September/049171.html
Also note that this changes visible behavior. E. g. somebody might synchronize on the array object returned by toArray call, so this change might cause unwanted lock sharing.
Once I suggested similar improvement: to return EMPTY_LIST from Arrays.asList() when supplied array has zero length. It was declined with the same reason [1].
http://mail.openjdk.java.net/pipermail/core-libs-dev/2015-September/035197.html
By the way, probably it's reasonable then for Arrays.asList to check the array length like:
public static <T> List<T> asList(T... a) { if(a.length == 0) return Collections.emptyList(); return new ArrayList<>(a); }
Звучит разумно, не так ли? Зачем создавать новый список для пустого массива, если можно бесплатно взять уже готовый?
There is a reason not to do this. At the moment Arrays.asList specifies no constraints on the identity of the returned List. Adding the micro-optimisation will change that. It’s an edge case and a questionable use-case too, but considering that i would conservatively leave things as they are.
Вот это утверждение наверняка вызовет у вас недоумение:
E. g. somebody might synchronize on the array object returned by toArray call, so this change might cause unwanted lock sharing.
Вы скажете: "Кто в здравом уме будет синхронизироваться на массиве (!) возвращаемом (!!!) из коллекции!?"
Звучит не очень правдоподобно, но такую возможность язык предоставляет, а значит существует вероятность того, что некий пользователь сделает это (а то и уже сделал). Тогда предлагаемое изменение в лучшем случае изменит поведение кода, а в худшем — приведёт к поломке в синхронизации (поди потом, отлови её). Риск настолько неоправдан, а предполагаемый выигрыш столь незначителен, что лучше оставить всё как есть.
Вообще возможность синхронизации на любом объекте, кмк, была ошибкой разработчиков языка. Во-первых, в заголовке каждого объекта содержится структура, отвечающая за синхронизацию, а во-вторых мы оказываемся в описанной выше ситуации, когда вроде бы неизменяемый объект нельзя возвращать многократно, т. к. на нём могут синхронизироваться.
Мораль сей басни такова: спецификация и обратная совместимость — священные коровы острова Ява. Даже не пытайтесь покушаться на них: стража стреляет без предупреждения.
Стараешься-стараешься...
В JDK существует сразу несколько классов, основанных на массиве, и все они реализуют методы List.indexOf() и List.lastIndexOf():
- java.util.ArrayList
- java.util.Arrays$ArrayList
- java.util.Vector
- java.util.concurrent.CopyOnWriteArrayList
Код указанных методов в этих классах повторяется почти один к одному. Свои решения для этой же задачи предлагают также многие приложения и фреймворки:
- org.hibernate.bytecode.enhance.internal.tracker.SimpleFieldTracker
- com.intellij.util.ArrayUtil
- com.intellij.util.ArrayUtilRt
- org.springframework.oxm.jibx.JibxMarshaller
В итоге имеем бродячий код, который нужно компилировать (при чём иногда по несколько раз), который занимает место в ReserverCodeCache, который нужно тестировать и который просто кочует из класса в класс почти без изменений.
Разработчики, в свою очередь, очень любят писать что-то вроде
int i = Arrays.asList(array).indexOf(obj);
// или
boolean contains = Arrays.asList(array).contains(obj);
// при тяжёлом стримозе
boolean contains = Arrays.stream(names).anyMatch(nm -> nm.equals(name));Хотелось бы ввести в JDK обобщённые утилитный методы, и использовать их повсюду, что и было предложено. Заплатка простая как две копейки:
1) реализации List.indexOf() и List.lastIndexOf() переезжают в java.util.Arrays
2) вместо них вызываются, соответственно, Arrays.indexOf() и Arrays.lastIndexOf()
Казалось бы, что может пойти не так? Выигрыш от этого подхода [вроде бы] очевиден. Но статья о провалах, поэтому подумайте, что может пойти нет так.
— Кто отвечает?
— Отвечают знатоки Мартин Бухгольц и Пол Сандоз
Мартин Бухгольц:
Сергей, I'm sort of maintaining all those collection classes, and I have on occasion also wanted to have indexOf methods in Array.java. But:
Arrays are generally discouraged. Any new static methods on Arrays (or, where I actually want them, on the array object itself! Requires a java language change!) will meet resistance.
We've come to regret supporting nulls in collections, so newer collection classes like ArrayDeque don't support them.
Another variant users might want is what kind of equality comparison to use.
We've come to regret having ArrayList with zero-based start index — it would have been better to have ArrayDeque's circular array behavior in from day one.
The code to search array slices is very small, so you're not saving much. It's easy to make an off-by-one error, but that's true for an Arrays API as well.
Пол Сандоз:
I would not go so far as to say arrays are discouraged, i would positively spin it as "use with care” as they are prickly e.g. always mutable. They could certainly be improved. I would be very happy to see arrays implement a common array’ish interface, we might be able to make some progress after value types sediment.
Any new additions to Arrays would be met with some resistance though, by me at least :-) It’s never adding just one or two methods, many others want come along for the ride as well (all primitives plus range variants). So any new feature needs to be sufficiently beneficial and in this case i don’t think the benefits are strong enough (such as a possible reduction code cache pressure).
Paul.
Переписка: http://mail.openjdk.java.net/pipermail/core-libs-dev/2018-March/051968.html
Мораль сей басни такова: ваш гениальный патч могут зарезать на ревью просто потому, что не увидят в нём особой ценности. Ну да, есть повторяющийся код, но он никому особо не мешает, так что пусть живёт.
Улучшения для ArrayList-a? Их есть у меня
Мопед патч не мой, я просто размещу для подумать. Само предложение было озвучено здесь, и выглядит оно очень даже привлекательно. Смотрите сами:
Невооруженным глазом видно, что предложение очень и очень логично. Измерить производительность можно с помощью простого бенчмарка:
@State(Scope.Benchmark)
public class ArrayListBenchmark {
@State(Scope.Benchmark)
public static class Data {
@Param({"10", "100", "1000", "10000"})
public int size;
ArrayList<Integer> arrayRandom = new ArrayList<Integer>(size);
@Setup(Level.Invocation)
public void initArrayList() {
Random rand = new Random();
rand.setSeed(System.currentTimeMillis());
// Populate the ArrayList with size-5 elements
for (int i = 0; i < size - 5; i++) {
Integer r = rand.nextInt() % 256;
arrayRandom.add(r);
}
}
}
@Benchmark
public ArrayList construct_new_array_list(Data d) {
ArrayList al = new ArrayList(d.arrayRandom);
// once a new ArrayList is created add a new element
al.add(new Integer(900));
return al;
}
}Итоги:
Benchmark (size) Mode Cnt Score Error Units
До
construct_new_array_list 10 thrpt 25 388.212 ± 23.110 ops/s
construct_new_array_list 100 thrpt 25 90.208 ± 7.995 ops/s
construct_new_array_list 1000 thrpt 25 23.289 ± 1.687 ops/s
construct_new_array_list 10000 thrpt 25 7.659 ± 0.560 ops/s
После
construct_new_array_list 10 thrpt 25 562.678 ± 37.370 ops/s
construct_new_array_list 100 thrpt 25 119.791 ± 13.232 ops/s
construct_new_array_list 1000 thrpt 25 33.811 ± 3.812 ops/s
construct_new_array_list 10000 thrpt 25 10.889 ± 0.564 ops/sСовсем неплохо как для такого простого изменения. Главное, что подвохов-то вроде бы нет. Честно создаём массив, честно копируем данные и про размер не забываем. Вот сейчас патч точно должны принять!
Мартин Бухгольц:
This is no question that we can optimize the case of ArrayList -> ArrayList, but what about all the other Collection implementations? ArrayDeque and CopyOnWriteArrayList come to mind.
ArrayList is a popular class to use for making copies of Collections. Where do you stop?
A pathological subclass of ArrayList could decide to not store elements in the backing array, with ensuing breakage.
The blessed solution to the list copy problem is probably List.copyOf https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/List.html#copyOf(java.util.Collection) which might do the optimization you're hoping for.
Алан Бейтман
ArrayList is not final so it's possible someone has extended it to use something other than elementData. It might be safer to use the class identity rather than instanceof.
Ничто не запрещает мне отпочковаться от ArrayList-а, а данные хранить в связанном списке. Тогда c instanceof ArrayList вернёт истину, мы попадём на участок копирования и благополучно свалимся.
Мораль сей басни такова: причиной отказа может стать возможное изменение поведения. Иными словами нужно держать в уме вероятность даже самого абсурдного изменения, если оно допускается средствами языка. И да, всё могло бы получиться, если бы ArrayList с самого начала объявили final.
Снова спецификация
Отлаживая своё приложение я случайно провалился в кишки Спринга и нашел там вот такой код:
// обратите внимание на использование переменной paramTypes
for (Constructor<?> candidate : candidates) {
Class<?>[] paramTypes = candidate.getParameterTypes();
if (constructorToUse != null && argsToUse != null && argsToUse.length > paramTypes.length) {
// Already found greedy constructor that can be satisfied ->
// do not look any further, there are only less greedy constructors left.
break;
}
if (paramTypes.length < minNrOfArgs) {
continue;
}По счастливому стечению обстоятельств, зайдя внутрь java.lang.reflect.Constructor.getParameterTypes() я прокрутил код чуть ниже и нашел прекрасное:
@Override
public Class<?>[] getParameterTypes() {
return parameterTypes.clone();
}
/**
* {@inheritDoc}
* @since 1.8
*/
public int getParameterCount() { return parameterTypes.length; }Понимаете, да? Если нам нужно узнать количество аргументов конструктора/метода, то достаточно вызвать java.lang.reflect.Method.getParameterCount() и обойтись без копирования массива. Проверим, стоит ли игра свеч на простейшем случае, в котором у метода нет параметров:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class MethodToStringBenchmark {
private Method method;
@Setup
public void setup() throws Exception { method = getClass().getMethod("toString"); }
@Benchmark
public int getParameterCount() { return method.getParameterCount(); }
@Benchmark
public int getParameterTypes() { return method.getParameterTypes().length; }
}На моей машине и с JDK 11 получается так:
Benchmark Mode Cnt Score Error Units
getParameterCount avgt 25 2,528 ± 0,085 ns/op
getParameterCount:·gc.alloc.rate avgt 25 ? 10?? MB/sec
getParameterCount:·gc.alloc.rate.norm avgt 25 ? 10?? B/op
getParameterCount:·gc.count avgt 25 ? 0 counts
getParameterTypes avgt 25 7,299 ± 0,410 ns/op
getParameterTypes:·gc.alloc.rate avgt 25 1999,454 ± 89,929 MB/sec
getParameterTypes:·gc.alloc.rate.norm avgt 25 16,000 ± 0,001 B/op
getParameterTypes:·gc.churn.G1_Eden_Space avgt 25 2003,360 ± 91,537 MB/sec
getParameterTypes:·gc.churn.G1_Eden_Space.norm avgt 25 16,030 ± 0,045 B/op
getParameterTypes:·gc.churn.G1_Old_Gen avgt 25 0,004 ± 0,001 MB/sec
getParameterTypes:·gc.churn.G1_Old_Gen.norm avgt 25 ? 10?? B/op
getParameterTypes:·gc.count avgt 25 2380,000 counts
getParameterTypes:·gc.time avgt 25 1325,000 msЧто мы можем с этим сделать? Можем поискать использование антипаттерна Method.getParameterTypes().length в JDK (по меньшей мере в java.base) и заменить его там, где это имеет смысл:
java.lang.invoke.MethodHandleProxies
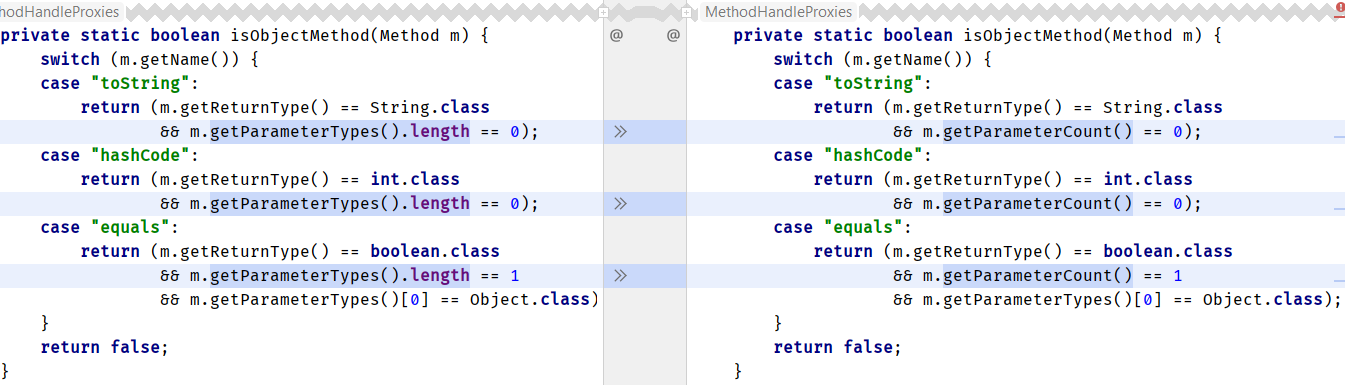
java.util.concurrent.ForkJoinTask
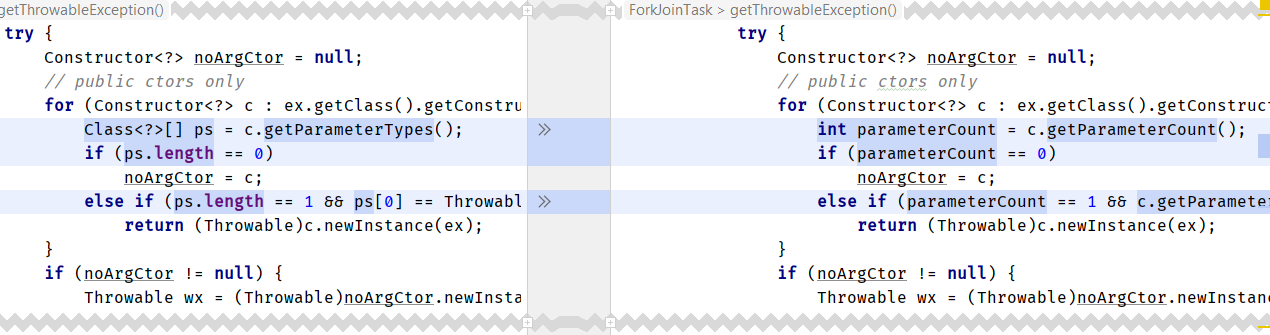
java.lang.reflect.Executable

sun.reflect.annotation.AnnotationType

Патч был отправлен вместе с сопроводительным письмом.
Внезапно оказалось, что уже несколько лет как существует похожая задача и по ней даже подготовлены изменения. В комментариях отмечен довольно приличный, как для таких простых изменений, прирост производительности. Однако, и они, и мой патч пока убраны под сукно и лежат без движения. Почему? Вероятно потому, что разработчики слишком заняты более нужными вещами и у них тупо не доходят руки.
Мораль сей басни такова: ваши гениальные изменения могут зависнуть просто из-за нехватки рабочих рук.
Но это ещё не конец! В ходе обсуждения рациональности описанной замены в других проектах более опытные товарищи выдвинули встречное предложение: может не стоит делать замену Method.getParameterTypes().length -> Method.getParameterCount() руками, а поручить это компилятору? Возможно ли это и будет ли это "законным"?
Попробуем проверить с помощью теста:
@Test
void arrayClone() {
final Object[] objects = new Object[3];
objects[0] = "azaza";
objects[1] = 365;
objects[2] = 9876L;
final Object[] clone = objects.clone();
assertEquals(objects.length, clone.length);
assertSame(objects[0], clone[0]);
assertSame(objects[1], clone[1]);
assertSame(objects[2], clone[2]);
}который проходит, и который показывает, что если клонированный массив не покидает область видимости, то его можно удалить, т. к. доступ к любому элементу из его ячеек или полю length можно получить из оригинала.
Умеет ли делать это JDK? Проверяем:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class ArrayAllocationEliminationBenchmark {
private int length = 10;
@Benchmark
public int baseline() {
return new int[length].length;
}
@Benchmark
public int baselineClone() {
return new int[length].clone().length;
}
}Вывод для JDK 13:
Benchmark Mode Cnt Score Error Units
baseline avgt 50 6,135 ± 0,140 ns/op
baseline:·gc.alloc.rate.norm avgt 50 56,000 ± 0,001 B/op
clone avgt 50 18,359 ± 0,619 ns/op
clone:·gc.alloc.rate.norm avgt 50 112,000 ± 0,001 B/opВыходит, что openjdk не умеет выбрасывать new int[length], в отличие от Грааля, хе-хе:
Benchmark Mode Cnt Score Error Units
baseline avgt 25 2,470 ± 0,156 ns/op
baseline:·gc.alloc.rate.norm avgt 25 0,005 ± 0,008 B/op
сlone avgt 25 13,086 ± 1,059 ns/op
сlone:·gc.alloc.rate.norm avgt 25 112,113 ± 0,115 B/opПолучается, что можно немного подкрутить оптимизирующий компилятор openjdk, чтобы он мог делать то же, что умеет Грааль. Т. к. влезть в плюсовый адЪ в коде ВМ и напилить что-то осмысленное могут не только лишь все, то я ограничился письмом, в котором изложил свои наблюдения.
Оказалось, и здесь есть несколько тонкостей. Владимир Иванов указывает, что:
Considering there's no way to grow/shrink Java arrays,
"cloned_array.length => original_array.length" transformation is correct
irrespective of whether cloned variant escapes or not.
Moreover, the transformation is already there:
http://hg.openjdk.java.net/jdk/jdk/file/tip/src/hotspot/share/opto/memnode.cpp#l2388
I haven't looked into the benchmarks you mentioned, but it looks like
cloned_array.length access is not the reason why cloned array is still
there.
Regarding your other ideas, redirecting accesses from cloned instance to
original is problematic (in general case) since compiler has to prove
there were no changes in both versions and indexed accesses make it even
harder. And safepoints cause problems as well (for rematerialization).
But I agree that it would be nice to cover (at least) simple cases of
defensive copying.
Т. е. грохнуть клон вроде бы и можно, и не особо сложно. А вот с преобразованием
int len = new int[arrayLength].length;-->
int len = arrayLength;возникают сложности:
We don't eliminate array allocations that doesn't have a known length
because they might cause a NegativeArraySize Exception. In this case we
should be able to prove that the length is positive though.
Anyway — I have an almost finished patch that replace unused array
allocations with a proper guard.
Иными словами нельзя просто так взять и выбросить создание массива, т. к согласно спецификации исполнение обязано бросить NegativeArraySizeException и ничего мы с этим поделать не можем:
@Test
void arrayWithNwgativeSize() {
int length = 0;
try {
int newLen = -3;
length = new Object[newLen].length; // выбросить new Object[newLen] нельзя
fail();
} catch (NegativeArraySizeException e) {
assert length == 0;
}
}Почему же Грааль смог? Думаю, причина в том, что значение поля length в бенчмарке выше было постоянным и всегда равнялось 10, что позволило профилировщику сделать вывод о том, что проверка отрицательного значения не нужна, а значит её можно убрать вместе с созданием самого массива. Поправьте в комментариях, если я ошибся.
На сегодня всё :) Добавляйте свои примеры в комментариях, будем разбираться.
Комментарии (10)

lany
18.12.2019 19:14+1Мораль сей басни такова: ваш гениальный патч могут зарезать на ревью просто потому, что не увидят в нём особой ценности. Ну да, есть повторяющийся код, но он никому особо не мешает, так что пусть живёт.
Дело не совсем в этом, тебе же сказали. Если делаешь метод в Arrays, нужны как минимум специализации для int/long/double, а желательно и для byte/boolean/short/char/float. В итоге имеем девять методов. И логично иметь версии с диапазоном поиска. Вот уже 18 методов. И ещё lastIndexOf — итого 36. Это уже серьёзная заявка. Люди надеются на светлое будущее и специализацию дженериков, когда можно будет обойтись четырьмя методами. Поэтому не хотят плодить новый код, связанный с речной специализацией. Только когда это будет — неясно.
tsypanov Автор
18.12.2019 23:04Это уже серьёзная заявка.
Это можно парировать наличием 6 методов
EnumSet.of()и 12 (!) методовList.of()и ещё стольких же уMap.of(). И всё только для того, чтобы варарги не использовать ну и с прицелом на средний размер списка/словаря.
Так что тут палка о двух концах, имхо. Тем более, что в случае с Arrays код получается довольно однотипным — только типы меняй. И раздувание класса Arrays вполне себе возмещается ужатием прочих коллекций на основе массива, ведь мы не просто добавляем методы — мы ещё и убираем их же тела из коллекций.
tsypanov Автор
19.12.2019 13:46Совсем забыл,
Arrays.sort()вполне себе используется из COWList-a, ArrayList-a и т.д. и там тоже есть все методы для всех примитивов и ссылок + отдельные методы для параллельной сортировки и сортировки слиянием.
lany
18.12.2019 19:27+1С ArrayList у тебя стандартная проблема бенчмарк-энтузиаста, кстати. Ты увидел кейс, который в твоей практике случается часто, заточил библиотеку под этот кейс и написал бенчмарк тоже под этот кейс. Почему не потестировать другие кейсы? Если туда HashSet прилетает, сколько съедает лишняя проверка? А если разные реализации прилетают, например emptyList/singletonList/ArrayList/unmodifiableList в равной пропорции (вполне жизненная ситуация)? Насколько ускорится или замедлится каждый случай? Тело метода стало больше, влияет ли это на решения об инлайнинге?
Я не к тому, что твоя идея плоха. Она может и хороша. Я к тому, что надо критически смотреть на свои гениальные идеи.
tsypanov Автор
18.12.2019 22:53Ну, пример с ArrayList-ом, справедливости ради, не мой — его предложил Стив Грёгер.
По поводу остального я согласен, что один случай не показатель. Точно так же я когда-то хотел предложить улучшение сортировки: если массив состоит всего лишь из двух элементов, то их можно просто переставить (если первый больше второго) или оставить всё как есть (в противоположном случае). Оказалось, что лишние проверки будут бить по всем остальным случаям (в массиве более 2 элементов).
tsypanov Автор
18.12.2019 23:08Я к тому, что надо критически смотреть на свои гениальные идеи.
Для этого и существует сообщество — чтобы бить советской железной линейкой по излишне шаловливым рукам. Сам всего в голове не удержишь, тем более могут вылезти грабли о которых ты даже не подозреваешь.
Как-нибудь напишу, как я пробовал
TreeMapподлатать: вроде всё идеально ложится, 150 строк кода можно выкинуть не поломав ни единого теста, производительность растёт, ну красота же! А оказалось, что если взятьTreeMapдо моих изменений, сериализовать, записать в файл, а потом превратить обратно вTreeMap(но уже с моими изменениями) то будет НПЕ :)
Ничто не предвещало беды...
konsoletyper
Ну или код по созданию массива можно заменить на код, который проверяет длину и кидает исключение, если она отрицательная. Это небольшой оверхед, но это всё равно намного лучше, чем создавать ненужный массив в куче.
tsypanov Автор
Думаю, исполнение именно так и делает, по крайней мере в Граале.
tbl
Грааль везде проверки расставляет, и в случае их нарушения фолбэчится в неоптимизированный код. В принципе, c2 тоже так делает, но у него просто не хватает знаний о внутренностях некоторых языковых конструкций байткода. Например, я не могу назвать случаи, когда c2 выкинул бы лишнее выделение памяти, когда можно было бы обойтись без него (тот же varargs). Он умеет это делать только в вручную написанных интринсиках типа конкатенации строк.
tsypanov Автор
Спасибо за интересные подробности!