
Привет, Хабр! Представляю вашему вниманию перевод второй части статьи «Java Memory Model» автора Jakob Jenkov. Первая часть тут.
Современная аппаратная архитектура памяти несколько отличается от внутренней Java-модели памяти. Важно понимать аппаратную архитектуру, чтобы понять, как с ней работает Java-модель. В этом разделе описывается общая аппаратная архитектура памяти, а в следующем разделе описывается, как с ней работает Java.
Вот упрощенная схема аппаратной архитектуры современного компьютера:
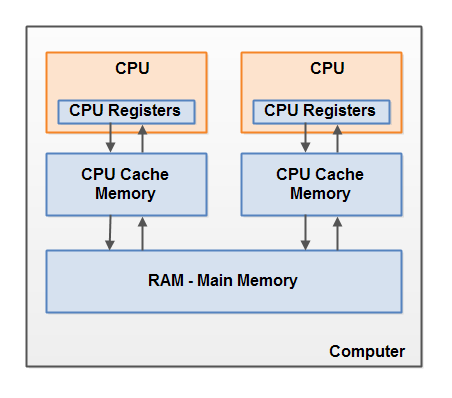
Современный компьютер часто имеет 2 или более процессоров. Некоторые из этих процессоров также могут иметь несколько ядер. На таких компьютерах возможно одновременное выполнение нескольких потоков. Каждый процессор (прим. переводчика — тут и далее под процессором автор вероятно подразумевает ядро процессора или одноядерный процессор) способен запускать один поток в любой момент времени. Это означает, что если ваше Java-приложение является многопоточным, то внутри вашей программы может быть запущен одновременно один поток на один процессор.
Каждый процессор содержит набор регистров, которые, по существу, находятся в его памяти. Он может выполнять операции над данными в регистрах намного быстрее, чем в над данными, которые находятся в основной памяти компьютера (ОЗУ). Это связано с тем, что процессор может получить доступ к этим регистрам гораздо быстрее.
Каждый ЦП также может иметь слой кэш-памяти. Фактически, большинство современных процессоров его имеют. Процессор может получить доступ к своей кэш-памяти намного быстрее, чем к основной памяти, но, как правило, не так быстро, как к своим внутренним регистрам. Таким образом, скорость доступа к кэш-памяти находится где-то между скоростями доступа к внутренним регистрам и к основной памяти. Некоторые процессоры могут иметь многоуровневый кэш, но это не так важно знать, чтобы понять, как Java-модель памяти взаимодействует с аппаратной памятью. Важно знать, что процессоры могут иметь некоторый уровень кэш-памяти.
Компьютер также содержит область основной памяти (ОЗУ). Все процессоры могут получить доступ к основной памяти. Основная область памяти обычно намного больше, чем кэш-память процессоров.
Как правило, когда процессору нужен доступ к основной памяти, он считывает её часть в свою кэш-память. Он может также считывать часть данных из кэша в свои внутренние регистры и затем выполнять операции над ними. Когда ЦПУ необходимо записать результат обратно в основную память, он сбрасывает данные из своего внутреннего регистра в кэш-память и в какой-то момент в основную память.
Данные, хранящиеся в кэш-памяти, обычно сбрасываются обратно в основную память, когда процессору необходимо сохранить в кэш-памяти что-то еще. Кэш может очищать свою память и записывать в неё новые данные одновременно. Процессор не должен читать/записывать полный кэш каждый раз, когда он обновляется. Обычно кэш обновляется небольшими блоками памяти, называемыми «строками кэша». Одна или несколько строк кэша могут быть считаны в кэш-память, и одна или более строк кэша могут быть сброшены назад в основную память.
Как уже упоминалось, Java-модель памяти и аппаратная архитектура памяти различны. Аппаратная архитектура не различает стеки потоков и кучу. На оборудовании стек потоков и куча (heap) находятся в основной памяти. Части стеков и кучи потоков могут иногда присутствовать в кэшах и внутренних регистрах ЦП. Это показано на диаграмме:

Когда объекты и переменные могут храниться в различных областях памяти компьютера, могут возникнуть определенные проблемы. Вот две основные:
• Видимость изменений, которые произвёл поток над общими переменными.
• Состояние гонки при чтении, проверке и записи общих переменных.
Обе эти проблемы будут объяснены в следующих разделах.
Если два или более потока делят между собой объект без надлежащего использования volatile-объявления или синхронизации, то изменения общего объекта, сделанные одним потоком, могут быть невидимы для других потоков.
Представьте, что общий объект изначально хранится в основной памяти. Поток, выполняющийся на ЦП, считывает общий объект в кэш этого же ЦП. Там он вносит изменения в объект. Пока кэш ЦП не был сброшен в основную память, измененная версия общего объекта не видна потокам, работающим на других ЦП. Таким образом, каждый поток может получить свою собственную копию общего объекта, каждая копия будет находиться в отдельном кэше ЦП.
Следующая диаграмма иллюстрирует набросок этой ситуации. Один поток, работающий на левом ЦП, копирует в его кэш общий объект и изменяет значение переменной

Для того, чтобы решить эту проблему, вы можете использовать
Если два или более потоков совместно используют один объект и более одного потока обновляют переменные в этом общем объекте, то может возникнуть состояние гонки.
Представьте, что поток A считывает переменную
Если бы эти приращения были выполнены последовательно, переменная
Тем не менее, два приращения были выполнены одновременно без надлежащей синхронизации. Независимо от того, какой из потоков (A или B), записывает свою обновленную версию
Эта диаграмма иллюстрирует возникновение проблемы с состоянием гонки, которое описано выше:

Для решения этой проблемы вы можете использовать синхронизированный блок Java. Синхронизированный блок гарантирует, что только один поток может войти в данный критический раздел кода в любой момент времени. Синхронизированные блоки также гарантируют, что все переменные, к которым обращаются внутри синхронизированного блока, будут считаны из основной памяти, и когда поток выйдет из синхронизированного блока, все обновленные переменные будут снова сброшены в основную память, независимо от того, объявлена ли переменная как
Аппаратная архитектура памяти
Современная аппаратная архитектура памяти несколько отличается от внутренней Java-модели памяти. Важно понимать аппаратную архитектуру, чтобы понять, как с ней работает Java-модель. В этом разделе описывается общая аппаратная архитектура памяти, а в следующем разделе описывается, как с ней работает Java.
Вот упрощенная схема аппаратной архитектуры современного компьютера:
Современный компьютер часто имеет 2 или более процессоров. Некоторые из этих процессоров также могут иметь несколько ядер. На таких компьютерах возможно одновременное выполнение нескольких потоков. Каждый процессор (прим. переводчика — тут и далее под процессором автор вероятно подразумевает ядро процессора или одноядерный процессор) способен запускать один поток в любой момент времени. Это означает, что если ваше Java-приложение является многопоточным, то внутри вашей программы может быть запущен одновременно один поток на один процессор.
Каждый процессор содержит набор регистров, которые, по существу, находятся в его памяти. Он может выполнять операции над данными в регистрах намного быстрее, чем в над данными, которые находятся в основной памяти компьютера (ОЗУ). Это связано с тем, что процессор может получить доступ к этим регистрам гораздо быстрее.
Каждый ЦП также может иметь слой кэш-памяти. Фактически, большинство современных процессоров его имеют. Процессор может получить доступ к своей кэш-памяти намного быстрее, чем к основной памяти, но, как правило, не так быстро, как к своим внутренним регистрам. Таким образом, скорость доступа к кэш-памяти находится где-то между скоростями доступа к внутренним регистрам и к основной памяти. Некоторые процессоры могут иметь многоуровневый кэш, но это не так важно знать, чтобы понять, как Java-модель памяти взаимодействует с аппаратной памятью. Важно знать, что процессоры могут иметь некоторый уровень кэш-памяти.
Компьютер также содержит область основной памяти (ОЗУ). Все процессоры могут получить доступ к основной памяти. Основная область памяти обычно намного больше, чем кэш-память процессоров.
Как правило, когда процессору нужен доступ к основной памяти, он считывает её часть в свою кэш-память. Он может также считывать часть данных из кэша в свои внутренние регистры и затем выполнять операции над ними. Когда ЦПУ необходимо записать результат обратно в основную память, он сбрасывает данные из своего внутреннего регистра в кэш-память и в какой-то момент в основную память.
Данные, хранящиеся в кэш-памяти, обычно сбрасываются обратно в основную память, когда процессору необходимо сохранить в кэш-памяти что-то еще. Кэш может очищать свою память и записывать в неё новые данные одновременно. Процессор не должен читать/записывать полный кэш каждый раз, когда он обновляется. Обычно кэш обновляется небольшими блоками памяти, называемыми «строками кэша». Одна или несколько строк кэша могут быть считаны в кэш-память, и одна или более строк кэша могут быть сброшены назад в основную память.
Совмещение Java-модели памяти и аппаратной архитектуры памяти
Как уже упоминалось, Java-модель памяти и аппаратная архитектура памяти различны. Аппаратная архитектура не различает стеки потоков и кучу. На оборудовании стек потоков и куча (heap) находятся в основной памяти. Части стеков и кучи потоков могут иногда присутствовать в кэшах и внутренних регистрах ЦП. Это показано на диаграмме:
Когда объекты и переменные могут храниться в различных областях памяти компьютера, могут возникнуть определенные проблемы. Вот две основные:
• Видимость изменений, которые произвёл поток над общими переменными.
• Состояние гонки при чтении, проверке и записи общих переменных.
Обе эти проблемы будут объяснены в следующих разделах.
Видимость общих объектов
Если два или более потока делят между собой объект без надлежащего использования volatile-объявления или синхронизации, то изменения общего объекта, сделанные одним потоком, могут быть невидимы для других потоков.
Представьте, что общий объект изначально хранится в основной памяти. Поток, выполняющийся на ЦП, считывает общий объект в кэш этого же ЦП. Там он вносит изменения в объект. Пока кэш ЦП не был сброшен в основную память, измененная версия общего объекта не видна потокам, работающим на других ЦП. Таким образом, каждый поток может получить свою собственную копию общего объекта, каждая копия будет находиться в отдельном кэше ЦП.
Следующая диаграмма иллюстрирует набросок этой ситуации. Один поток, работающий на левом ЦП, копирует в его кэш общий объект и изменяет значение переменной
count на 2. Это изменение невидимо для других потоков, работающих на правом ЦП, поскольку обновление для count ещё не было сброшено обратно в основную память.Для того, чтобы решить эту проблему, вы можете использовать
ключевое слово volatile при объявлении переменной. Оно может гарантировать, что данная переменная считывается непосредственно из основной памяти и всегда записывается обратно в основную память при обновлении.Состояние гонки
Если два или более потоков совместно используют один объект и более одного потока обновляют переменные в этом общем объекте, то может возникнуть состояние гонки.
Представьте, что поток A считывает переменную
count общего объекта в кэш своего процессора. Представьте также, что поток B делает то же самое, но в кэш другого процессора. Теперь поток A прибавляет 1 к значению переменной count, и поток B делает то же самое. Теперь var1 была увеличена дважды — отдельно по +1 в кэше каждого процессора.Если бы эти приращения были выполнены последовательно, переменная
count была бы увеличена в два раза и обратно в основную память было бы записано исходное значение + 2.Тем не менее, два приращения были выполнены одновременно без надлежащей синхронизации. Независимо от того, какой из потоков (A или B), записывает свою обновленную версию
count в основную память, новое значение будет только на 1 больше исходного значения, несмотря на два приращения.Эта диаграмма иллюстрирует возникновение проблемы с состоянием гонки, которое описано выше:
Для решения этой проблемы вы можете использовать синхронизированный блок Java. Синхронизированный блок гарантирует, что только один поток может войти в данный критический раздел кода в любой момент времени. Синхронизированные блоки также гарантируют, что все переменные, к которым обращаются внутри синхронизированного блока, будут считаны из основной памяти, и когда поток выйдет из синхронизированного блока, все обновленные переменные будут снова сброшены в основную память, независимо от того, объявлена ли переменная как
volatile или нет.
Badimagination
На сколько я знаю, кэш даже в обычных комп-ах (не суперкомпьютеры, там я хз) когерентен между CPU в многопроцессорных системах, a в кэше одного многоядерного камня и подавно. Некоторые технологии когерентности: Intel MESIF, AMD MOESI.
ruomserg
Тут важно понимать две вещи. Первое — Java Memory Model является попыткой абстрактно описать наиболее вероятные реализации аппаратных платформ. Она обеспечивает приемлемую производительность на существующих архитектурах, и (мы надеемся) даже на тех, которые еще не оформлены в реальных процессорах и машинах. Поэтому JMM не может делать предположение, что составные части процессора или разные процессоры имеют синхронизацию кэша (или она достаточно дешево работает).
Во-вторых, помимо кэша есть еще out-of-order execution. И вот с этим вы простой синхронизацией кэша ничего не сделаете. Ядро обязано переупорядочивать операции внутри своего конвейера так, чтобы с его (!) точки зрения результат был эквивалентен потоку изначальных операций. Но эта эквивалентность может (и будет) нарушаться с точки зрения соседних ядер. Например, выполняя последовательность операций A=A+1;B=5 ядро вынуждено упорядочить операции чтения и записи A (ну потому что иначе нельзя прибавить к нему единицу). Что касается присвоения B — оно (с точки зрения этого ядра) является чистым побочным эффектом, и его можно выполнить до присвоения A (например, пока АЛУ прибавляет единицу). А можно после. А другое ядро может выполнять свою, неизвестную первому ядру программу — где критично именно чтобы B записалось после A. Выявить такие зависимости в общем виде — невозможно. Поэтому появляются механизмы типа memfence, которые заставляют процессор гарантировать что до этой операции чтения все операции записи исполнены. Ценой просадки производительности, естественно. Java Memory Model своими happens-before задает правила, где мы жертвуем определенностью ради скорости, а где — наоборот.
А, да — еще третий фактор забыл — JIT. Например, имея последовательность операций A=A+B; A=A+C;A=A+D — компилятор и JIT в рантайме имеют по-умолчанию полное право один раз считать A в регистр, и сбросить его в память (не важно, в кэш или RAM) только после последнего сложения. Запрещать свосем это нельзя — ибо производительность. Вот и тут JMM задает пределы, до которых компилятор и JIT имеют право интерпретировать наши намерения. И в целом, сравнивая существующее положение с миром C++ — мы живем даже очень неплохо!