
- Научная статья
- Pytorch: YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 (main repository — use to reproduce results)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet: YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- Структура YOLOv4-CSP
Scaled YOLO v4 является самой лучшей нейронной сетью для обнаружения объектов — самой точной нейронной сетью (55.8% AP) на датасете Microsoft COCO среди всех опубликованных нейронных сетей на данный момент. А также является лучшей с точки зрения соотношения скорости к точности во всем диапазоне точности и скорости от 15 FPS до 1774 FPS. На данный момент это Top1 нейронная сеть для обнаружения объектов.
Scaled YOLO v4 обгоняет по точности нейронные сети:
- Google EfficientDet D7x / DetectoRS or SpineNet-190 (self-trained on extra-data)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Мы показываем, что подходы YOLO и Cross-Stage-Partial (CSP) Network являются лучшими с точки зрения, как абсолютной точности, так и соотношения точности к скорости.
График Точности (вертикальная ось) и Задержки (горизонтальная ось) на GPU Tesla V100 (Volta) при batch=1 без использования TensorRT:
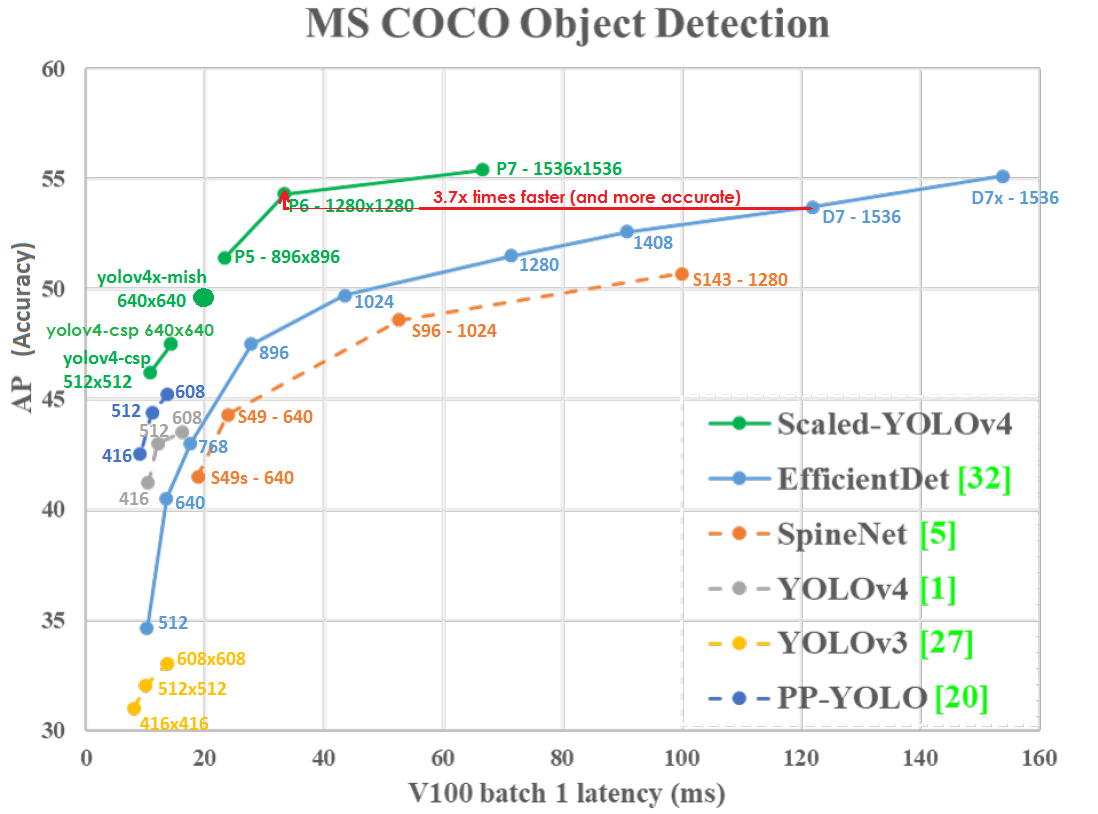
Даже при меньшем разрешении сети Scaled-YOLOv4-P6 (1280x1280) 30 FPS чуть точнее и в 3.7х раза быстрее, чем EfficientDetD7 (1536x1536) 8.2 FPS. Т.е. YOLOv4 эффективнее использует разрешение сети.
Scaled YOLO v4 лежит на кривой оптимальности по Парето – какую бы другую нейронную сеть вы не взяли, всегда есть такая сеть YOLOv4, которая или точнее при той же скорости, или быстрее при той же точности, т.е. YOLOv4 является лучшей с точки зрения отношения скорости и точности.
Scaled YOLOv4 точнее и быстрее, чем нейронные сети:
- Google EfficientDet D0-D7x
- Google SpineNet S49s – S143
- Baidu Paddle-Paddle PP YOLO
- И многие другие
Scaled YOLO v4 это серия нейронных сетей, созданная из улучшенной и отмасштабированной сети YOLOv4. Наша нейронная сеть была обучена с нуля без использования предобученных весов (Imagenet или любых других).
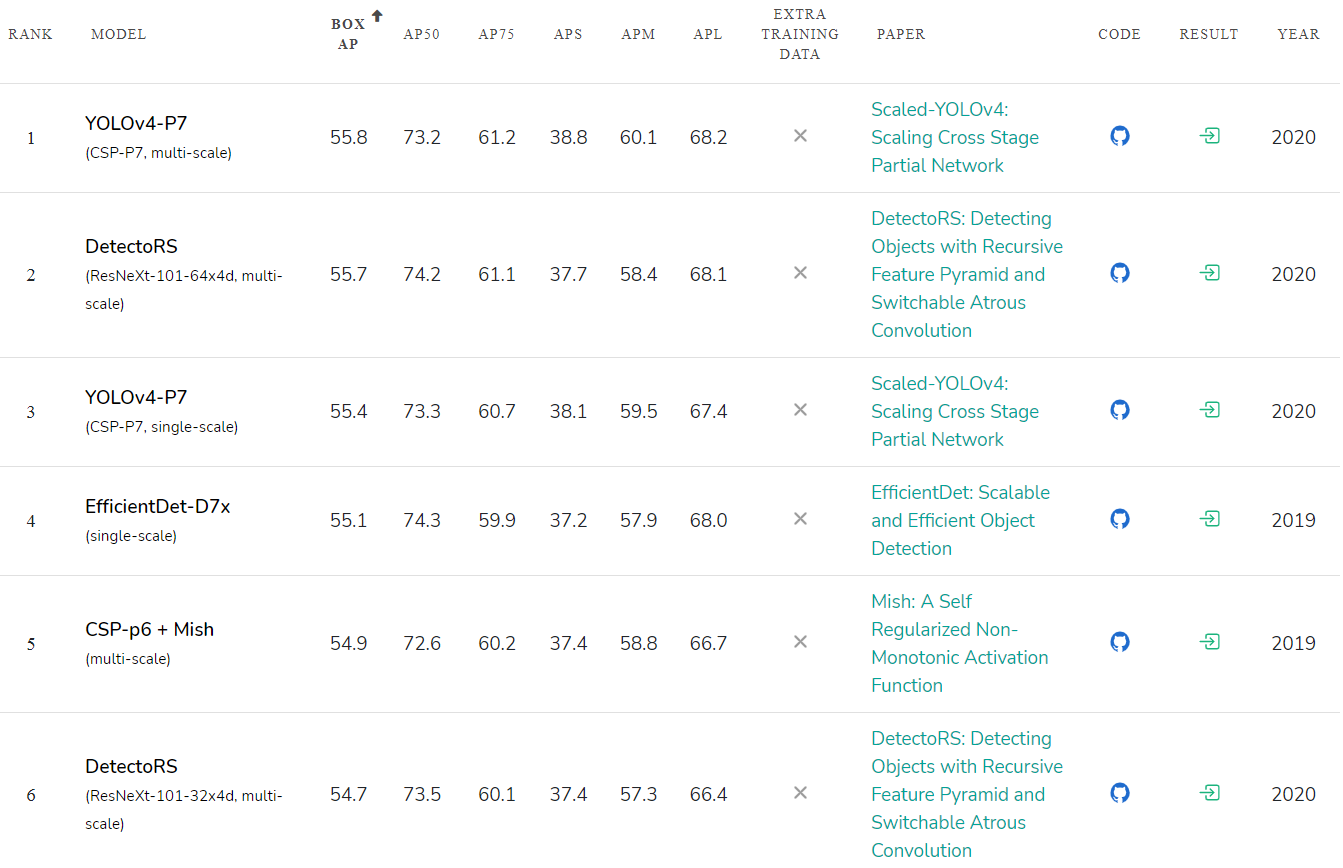
Рейтинг точности опубликованных нейронных сетей: paperswithcode.com/sota/object-detection-on-coco:
Скорость нейронной сети YOLOv4-tiny достигает 1774 FPS на игровой видеокарте GPU RTX 2080Ti при использовании TensorRT+tkDNN (batch=4, FP16): github.com/ceccocats/tkDNN
YOLOv4-tiny может исполняться в real-time со скоростью 39 FPS / 25ms Latency на JetsonNano (416x416, fp16, batch=1) tkDNN/TensorRT:

Scaled YOLOv4 намного эффективнее использует ресурсы параллельных вычислителей, таких как GPU и NPU. Например, GPU V100 (Volta) имеет производительность: 14 TFLops — 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
Если мы будем тестировать обе модели на GPU V100 с batch=1, с параметрами --hparams=mixed_precision=true и без --tensorrt=FP32, то:
- YOLOv4-CSP (640x640) — 47.5% AP – 70 FPS – 120 BFlops (60 FMA)
Исходя из BFlops, должно быть 933 FPS = (112 000 / 120), но в действительности мы получаем 70 FPS, т.е. используется 7.5% GPU = (70 / 933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
Исходя из BFlops, должно быть 2240 FPS = (112 000 / 50), но в действительности мы получаем 36 FPS, т.е. используется 1.6% GPU = (36 / 2240)
Т.е. эффективность вычислительных операций на устройствах с массивными параллельными вычислениями типа GPU, используемых в YOLOv4-CSP (7.5 / 1.6) = в 4.7x раза лучше, чем эффективность операций, используемых в EfficientDetD3.
Обычно нейронные сети запускаются на CPU только в исследовательских задачах для более легкой отладки, а характеристика BFlops на данный момент имеет только академический интерес. В реальных задачах важны реальные скорость и точность, а не характеристики на бумаге. Реальная скорость YOLOv4-P6 в 3.7х раза выше, чем EfficientDetD7 на GPU V100. Поэтому почти всегда используются устройства с массовым параллелизмом GPU / NPU / TPU/ DSP с гораздо более оптимальными: скоростью, ценой и тепловыделением:
- Embedded GPU (Jetson Nano/Nx)
- Mobile-GPU/NPU/DSP (Bionic-NPU/Snapdragon-DSP/Mediatek-APU/Kirin-NPU/Exynos-GPU/...)
- TPU-Edge (Google Coral/Intel Myriad/Mobileye EyeQ5/Tesla-motors TPU 144 TOPS-8bit)
- Cloud GPU (nVidia A100/V100/TitanV)
- Cloud NPU (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Также при использовании нейронных сетей On Web – обычно используется GPU через библиотеки WebGL, WebAssembly, WebGPU, в этом случае — размер модели имеет значение: github.com/tensorflow/tfjs#about-this-repo
Использование устройств и алгоритмов со слабым параллелизмом – это тупиковый путь развития, т.к. уменьшать размер литографии меньше размера атома кремния для увеличения частоты процессора не получится:
- Текущий лучший размер Литографии процессоров (Semiconductor device fabrication) равен 5 нанометров.
- Размер кристаллической решетки кремния равен 0.5 нанометров.
- Атомный радиус кремния равен 0.1 нанометра.
Решение – это вычислители с массивным параллелизмом: на одном кристалле или на нескольких кристаллах, соединенных интерпозером. Поэтому крайне важно создавать нейронные сети, которые эффективно используют вычислители с массивным параллелизмом, такие как GPU и NPU.
Улучшения в Scaled YOLOv4 по сравнению с YOLOv4:
- В Scaled YOLOv4 применяли оптимальные способы масштабирования сети для получения YOLOv4-CSP -> P5 -> P6 -> P7 сетей
- Улучшенная архитектура сети: оптимизирован Backbone, а также в Neck (PAN) используются Cross-stage-partial (CSP) connections и Mish-активация
- Во время обучения используется Exponential Moving Average (EMA) – это частный случай SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- Для каждого разрешения сети обучается отдельная нейронная сеть (в YOLOv4 обучали только одну нейронную сеть для всех разрешений)
- Улучшены нормализаторы в [yolo] слоях
- Изменены активации для Width и Height, что позволяет быстрее обучать сеть
- Используется параметр [net] letter_box=1 (сохраняет соотношение сторон входного изображения) для сетей с большим разрешением (для всех кроме yolov4-tiny.cfg)
Архитектура нейронной сети Scaled-YOLOv4 (примеры трех сетей: P5, P6, P7):

CSP-соединение очень эффективное, простое и может применятся к любым нейронным сетям. Суть заключается в том, что
- половина выходного сигнала идет по основному пути (генерируя больше семантической информации с большим рецептивным полем)
- а другая половина сигнала идет по обходному пути (сохраняя больше пространственной информации с малым рецептивным полем)
Простейший пример CSP-соединения (слева обычная сеть, справа CSP-сеть):

Пример CSP-соединения в YOLOv4-CSP / P5 / P6 / P7
(слева обычная сеть, справа CSP-сеть):

В YOLOv4-tiny используются 2 CSP-соединения:

YOLOv4 применяется в различных областях и задачах:
- Taiwanese government: Traffic control www.taiwannews.com.tw/en/news/3957400 and youtu.be/IiU6wFmfVnk
- Amazon: Anti-Covid19 Distance-assistant github.com/amzn/distance-assistant and Amazon Neurochip / Amazon EC2 Inf1 instances: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning-based-object-detection-with-an-aws-neuron-compiled-yolov4-model-on-aws-inferentia
- BMW Innovation Lab: github.com/BMW-InnovationLab
И во многих других задачах….
Имеются реализации на различных фреймворках:
- Pytorch: github.com/WongKinYiu/ScaledYOLOv4
- Darknet: github.com/AlexeyAB/darknet
- TensorFlow: github.com/hunglc007/tensorflow-yolov4-tflite
- o pip install yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- The structure of the network can be viewed using the Netron utility — Visualizer for neural networks: github.com/lutzroeder/netron
Как скомпилировать и запустить Обнаружение объектов в облаке бесплатно:
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- video: www.youtube.com/watch?v=mKAEGSxwOAY
Как скомпилировать и запустить Обучение в облаке бесплатно:
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- video: youtu.be/mmj3nxGT2YQ
Также подход YOLOv4 может использоваться в других задачах, например, при обнаружении 3D объектов:
- Code — Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Code — YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch







lostmsu
О, я как раз портировал на свой TensorFlow for C#: github.com/losttech/YOLOv4 (пока не оттестировано и использует невыпущенные версии библиотек)