
Некоторое время назад, в связи с планомерным увеличением количества автотестов, мы столкнулись с задачей реализовать их параллельный запуск, чтобы сократить длительность прогонов.

Наш тестовый фреймворк реализован на базе Cucumber (Java). Основной фокус – автоматизация GUI тестирования Swing-приложений (используем AssertJ Swing), а также взаимодействие с БД (SQL), REST API (RestAssured) и web UI (Selenide).
Ситуация осложнялась тем, что подключить параллелизацию стандартными средствами (например, настройкой потоков в maven-surefire-plugin) мы не могли, так как специфика тестируемых приложений не позволяет запускать более одного экземпляра приложения на одном физическом хосте.
Кроме того, требовалось учесть, что некоторые сценарии используют общие внешние ресурсы, которые не поддерживают параллельные запросы.
В данной статье хочу поделиться нашим решением и обнаруженными проблемами в процессе разработки.
Обзор реализации
Для нашей задачи мы решили использовать паттерн master-worker с коммуникацией посредством очереди сообщений.
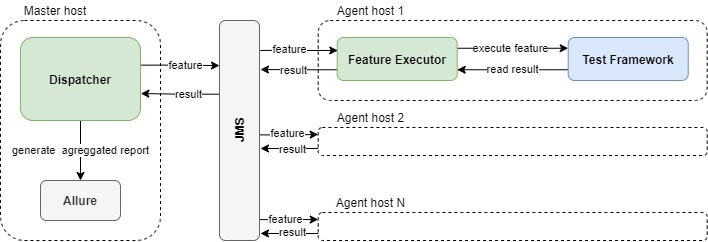
Компоненты схемы:
Master-хост, на котором запускается модуль Dispatcher, управляющий созданием очереди сценариев для параллельного запуска и последующей агрегацией результатов.
JMS server (для простоты развертывания мы поднимаем свой ActiveMQ Artemis, встроенный в Dispatcher).
Горизонтально масштабируемые agent-хосты, на которых запускается FeatureExecutor, непосредственно выполняющий сценарии из очереди. На каждый agent предварительно должен быть установлен тест фреймворк.
Master-хост при этом может одновременно выполнять роль одного из агентов (для этого запускаем на нем и Dispatcher, и FeatureExecutor).
Dispatcher при старте получает на вход директорию с features, считывает список файлов, и отправляет их в JMS очередь сценариев.
FeatureExecutor считывает сценарий из очереди и отправляет команду в Test Framework на выполнение этого сценария.
Как получить общий отчет по результатам прогона со всех хостов?
Как мы знаем, Allure складывает файлы с результатами по каждому сценарию в директорию resultsDir (по умолчанию это build/allure-results).
Так как мы уже используем JMS для создания очереди сценариев, закономерным решением мы посчитали добавление еще одной очереди для передачи результатов.
FeatureExecutor после каждого сценария архивирует содержимое resultsDir и в виде BytesMessage отправляет в эту очередь, откуда их считывает Dispatcher и распаковывает в resultsDir уже на мастер-хосте.
Таким образом, к концу прогона все результаты аккумулируются на мастер-хосте, где мы собираем общий отчет.
Что, если один из агентов упал?
Диспетчер завершает работу, когда обработал все результаты (сравниваем поштучно количество отправленных сценариев VS количество полученных результатов). Если один из агентов забрал сценарий из очереди, но не отправил результат, можно получить зависший прогон, так как диспетчер будет бесконечно ждать этот результат

Для решения этой проблемы мы добавили в Dispatcher сервис HealthChecker, который в фоновом потоке через RMI-интерфейс по шедулеру вызывает метод isAlive() на каждом зарегистрированном агенте (список агентов мы загружаем из конфигурации на старте).
Реализация метода на агенте примитивна:
@Override
public boolean isAlive() {
return true;
}Если связь хотя бы с одним агентом была потеряна, прогон завершается.
Такое условие было реализовано по принципу минимальных вложений в первой версии нашего механизма.
В планах есть доработка отслеживания, какой именно сценарий был «потерян», и его повторная отправка в очередь, чтобы продолжить работу на оставшихся агентах. Хотя фактически за год регулярных прогонов у нас еще не разу не воспроизвелся данный случай.
Альтернативные опции:
По аналогии с RMI использовать REST API.
Создать отдельную JMS очередь для сообщений типа heartbeat, которые будут отправлять агенты. А на стороне Dispatcher проверять, что от каждого агента мы получаем минимум один heartbeat в 5-10-30 минут (конфигурация по вкусу).
Как быть с тестами, которые не могут выполняться параллельно?
Например, использующие общие ресурсы.
Наше решение стилизовано под специальный Cucumber тег в feature-файле – @NoParallel. Почему «стилизовано»? Потому что читаем мы этот тег средствами java.nio.file, а не через Cucumber. Зато он красиво вписывается в файл сценария:
@NoParallel(“PrimaryLicense”)
@TestCaseId("876123")
Scenario: 001 Use of shared resourceЕсли два сценария используют общий ресурс (обозначенный в теге @NoParallel) – они не должны запускаться параллельно.
Для управления ресурсами у нас реализован ResourceManager на стороне Dispatcher с двумя методами в API:
public boolean registerResource(String resource, String agent);
public void unregisterResource(String resource, String agent);Когда FeatureExecutor получает сценарий из очереди с тегом @NoParallel, он вызывает метод registerResource().
Если метод возвращает true – ресурс успешно зарегистрирован, продолжаем выполнение сценария.
Если получаем false – ресурс занят. Сценарий возвращается в очередь.
После выполнения сценария ресурс освобождается через unregisterResource().
Взаимодействие с ResourceManager у нас реализовано через RMI.
Как вариант, можно использовать REST API.
Summary
Данное решение стоило нам 0 изменений в тестовом фреймворке.
Как следствие – имеем полную обратную совместимость. Автотесты могут запускаться и старым, и новым способом без изменений в коде.
Не нужно заботится о потокобезопасности тестов. Они изолированы, поэтому нет разницы, запускаются они параллельно или нет.
Агенты горизонтально масштабируются, легко ускорить выполнение тестов до определенного предела.
К моменту внедрения параллельного запуска, наши автотесты были полностью атомарны. В ином случае потребовалось бы еще учитывать зависимости между сценариями, либо менять их дизайн.