

Привет. Сегодня я бы хотел рассказать про проблему снятия снапшота для бэкапа, про свежее ядро Linux, и что мы на нём потеряли. Так что если вы используете Linux и делаете резервные копии — вам просто необходимо это знать. В противном случае вы можете оказаться без резервных копий.
Если кто не в курсе, то Veeam Software предлагает средства для резервного копирования. Список платформ и решений довольно внушительный, но я не об этом. Когда наша команда взялась за проект Veeam Agent for Linux (а в первой версии он назывался Linux Endpoint), то первый вопрос, который мы поставили перед собой: «Как снять снапшот?». И пришлось поресёрчить… А почему? Потому что open source. В Linux нет одного хорошего решения какой-то проблемы. Есть несколько, и все со своими «граблями». Но давайте по порядку.
А что у других?
Для начала рассмотрим кратко, как подобная проблема решается в других — а значит, проприетарных системах.
В самой популярной из систем есть для решения этой задачи целый сервис Volume Shadow Copy Service, он же VSS. Возможно, я бы поискал для этой задачи другое решение, но другого нет, а VSS есть и работает «из коробки». VSS снапшоты работают довольно интересно. В нашем блоге есть ознакомительная статья на эту тему. Из приятного: поддерживается взаимодействие с приложениями через VSS-Writers. VSS-Writers — это такой механизм, который позволяет предупредить, к примеру, движок базы данных: «Товьсь! Снимаем снапшот! Всем сбросить буфера и держаться за поручни!». Кроме того, так называемая «diff area», куда сбрасываются блоки, перезаписанные на оригинальном томе и которая может располагаться на любом томе с NTFS, в том числе и на том, с которого снимаем снапшот.
Отдельная прелесть — документация. Как её ругает один мой коллега — у меня уши в трубочку сворачиваются. Почти каждый день он её читает, и ругает, и что-то для себя находит. Не всегда, правда… На этот случай у него есть дизассемблер и дебагер, а я купил беруши.
В другой довольно популярной OS от одной «фруктовой» компании есть Time Machine. Другой мой коллега, который как раз разбирался со снапшотами, которые использует Time Machine, не ругался на документацию. Он хоть и более сдержан, но дело не в этом. Сложно ругаться на то, чего нет. Именно поэтому ссылка на википедию, а не на официальный сайт. Ресёрч на тему того, как с этим добром работать, удовольствия никакого не приносит, разве что вы мазохист. Но снапшоты на файловой системе APFS есть и довольно неплохо работают. Причём работают именно через APFS и никак иначе. Хотя, кажется, у HFS+ был свой механизм, но мы его не поддерживаем, ибо deprecated.
В нашей копилке есть и решение и для Unix. Кто-то cпросит: «Чта? Оно разве не засохло и отвалилось, когда появился Linux?». Отвечаю: «Да, засыхает, но пока не отвалилось.» Старые солярки тоже бэкапятся. Но тут всё выглядит так, как будто зализанный гоночный авто тащит на прицепе повидавший многое на своём веку Ролс-Ройс. Снапшотов нет. Только файловый бэкап, и, как следствие — минимум фичей. Едет, и слава богу.
Нельзя обойти стороной и гипервизоры. vSphere и Hyper-V молодцы. Можно снять снапшот с виртуальной машины. Можно получить change-tracking, то есть узнать заранее, какие блоки на дисках машины действительно изменились, а какие можно и не читать. KVM, кстати, тоже планируем поддержать в ближайшее время. Поддержка снапшотов там есть.
Снапшоты в Linux
Но вернёмся к нашим… в open source. Что тут есть из штатных средств? Есть LVM и BTRFS. Тут я слышу крики: «Даёшь ZFS!». Но замечу, что его нет в upstream ядра (пока). Хотя в Ubuntu 21.04 ZFS уже появился в диалоге при установке системы. Теперь сходу можно развернуть на ZFS рутовую систему, если, конечно не полениться нажать на кнопочку «Advanced features...».
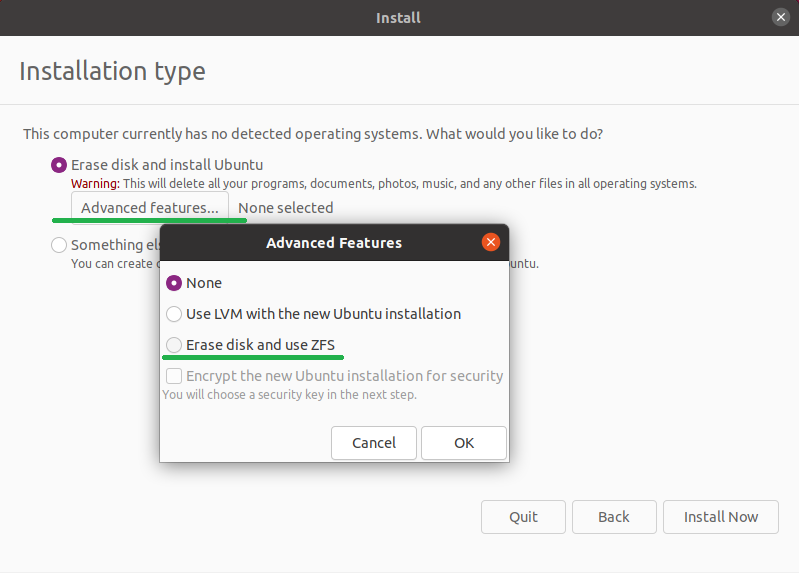
Тем не менее пока мы его не рассматриваем как штатное средство.
BTRFS мы поддержали в версии Veeam Agent for Linux версии 3.0. Основные претензии к ней — производительность. Больно уж много ресурсов требует бэкап при скорости из категории «так себе». Связано это с тем, что выполняется не просто копирование блоков, а синхронизация сорсной структуры файловой системы с таргетной. Получается что-то среднее между файловым и волюмным бэкапом. В общем, странное решение, кому интересно — читайте статью, там всё подробно описано.
Для быстрого и полного бэкапа в стиле «entire machine» лучше всего подходит именно снапшот всего блочного устройства, который как раз и реализован для томов LVM. Поэтому на нём я и остановлюсь подробнее.
DM cнапшоты LVM томов
В upstream ядра в сооставе DM есть модуль dm-snap, который позволяет создавать снапшоты блочных устройств. Звучит многообещающе, но рассмотрим, как с ним работать.

Коротко поясню понятия DM и LVM
Итак, для начала разберёмся с понятиями. Есть Logical Volume Manager, он же LVM, а есть Device Mapper, он же DM. Не путайте DM и LVM — это разные понятия, но тесно связанные :).
LVM — это user-space средство для работы со специальными метаданными на диске. В этих метаданных указано, какие логические тома есть на диске и как их собрать. Поэтому он и Manager, так как в системе есть сервис, который эти метаданные читает и парсит. А вот сами логические тома в виде блочных устройств создаёт DM, реализованный в виде дополнительного модуля ядра dm-mod и подключаемых к нему подмодулей, таких, как dm-linear, dm-raid456, dm-snap. При этом основной код для работы с DM модулями ядра реализован в проекте lvm2. Итого, Logical Volume Manager управляет логическими томами, а на уровне ядра его поддерживает DM.
LVM — это user-space средство для работы со специальными метаданными на диске. В этих метаданных указано, какие логические тома есть на диске и как их собрать. Поэтому он и Manager, так как в системе есть сервис, который эти метаданные читает и парсит. А вот сами логические тома в виде блочных устройств создаёт DM, реализованный в виде дополнительного модуля ядра dm-mod и подключаемых к нему подмодулей, таких, как dm-linear, dm-raid456, dm-snap. При этом основной код для работы с DM модулями ядра реализован в проекте lvm2. Итого, Logical Volume Manager управляет логическими томами, а на уровне ядра его поддерживает DM.
Открываем документацию на модуль ядра dm-snap, читаем:
lvcreate -L 1G -n base volumeGroup
lvcreate -L 100M --snapshot -n snap volumeGroup/base
Итак, вроде всё просто, давайте подставим вместо «volumeGroup» и «base» реальные значения и запустим этот код на вашей Linux машине и…
Fail #1 — у вас в системе диски не размечены под LVM.
При установке системы вы решили, что ни программные рейды, ни тонкие тома вам не нужны, и вообще лишние прослойки для вашего SSD будут только обузой. А что с этим можно поделать? Может, взять и смигрировать на LVM? Нельзя просто так взять и добавить LVM метаданные на диск.
Это боль. Проще по новой раскатать всю систему и перетащить данные, а это timeoff, причём надолго. А если вы админ и у вас под сотню серверов, да ещё и доставшихся вам по наследству от предшественника, который давно уволился, попутно утащив с собой сакральные знания, как это работало… Ну что ж — значит, снапшоты не для вас.
Но, допустим, вы — бывалый админ, на работе всегда ходите в красной шляпе, а дома исключительно в фетровой. Тогда вы ещё при установке вашей системы примените конфигурацию диска, которую вам советует установщик по умолчанию. Тогда у вас есть и Volume group, и на них есть тома. Подставляем значения в команду lvcreate и…
Fail #2 — у вас нет свободного места в volume group.
Свежераскатанная система, куча свободного места на файловой системе, а снапшот снять нельзя. Обидно, «из коробки не работает».
Про 'из коробки не работает'
Это как, знаете, бывает: даришь ребёнку на Рождество машинку на радиоуправлении, о которой он давно мечтал (целую неделю). Счастливый ребёнок разворачивает упаковку, вскрывает коробку, достаёт, включает, а батареек нет… Из коробки не работает. Он такой бежит в слезах, спотыкаясь, к вам: «Папа! Она не работает! Дед мороз принёс сломанную машинку!». А вы такой: «Ну понимаешь, тут ещё батарейки нужны, вот магазины откроются (Рождество ведь), мы их купим, разберём машину, вставим батарейки, соберём и через пару дней она ...». Ну, вы поняли.
Что тут можно сделать? Берём в руки рашпиль, то есть bash-пиль, и дорабатываем это. Можно подключить ещё один диск, добавить его в volume group, или можно сделать ресайз файловой системы, ресайз логического тома… Ой, у вас 100 машин, и менеждер по безопасности с главой IT отдела смотрит на вас — менеджера по бэкапам — квадратными глазами и говорят, что ваш предшественник как раз и был уволен после того, как предложил подобный план, а в 4 часа ночи у него что-то не срослось на сервере бухгалерии и был offtime до самого обеда.
Но что-то я сгущаю краски. Вы опытный админ и носите балаклаву, под которой расположилась шапочка из фольги. И поэтому у вас в парке сотни машин и к каждной подключён сторедж в пару-тройку десятков терабайт. И на них базы, большие такие… И вот вы в ресторане в VIP зале со своим другом, тоже админом, попиваете дорогой коньяк. Балаклаву вы сняли, и макушка поблёскивает металлом. Только тут можно поделиться с другом, что инфраструктура ваша трещит по швам от перегрузок, причём именно ночью, когда весь ваш зоопарк нужно забэкапить. И каждую ночь ваше средство для бэкапа перечитывает ваш диск целиком, хотя изменений в нём около 2-3%. На что друг, почёсывая макушку под блестящей шапочкой, признаётся, что давно перевёл всё на виртуальную инфраструктуру, что позволяет зачитывать только инкремент, потому что гипервизор поддерживает change-tracking.
Fail #3 — просто снапшота уже давно недостатчно. Нужен change-tracking.
Объёмы данных растут, накопители тоже. Перезачитывать весь снапшот — недопустимое расточительство. Что тут можно сделать? Я слышал про dm-era. Вроде как он позволяет получить битмапину изменений. Но для меня пока загадка, как оно дружит с dm-snap и как нужно собрать стек dm устройств, чтобы оно стабильно работало. Полагаю, должен быть пирог типа:

Если кто в теме, или есть рабочая конфигурация — дайте знать. Мне очень интересно. Особенно интересно оценить перфоманс такого решения. Тут дело в том, что DM при перехвате создаёт новое bio, копирует в него флаги и указатели на страницы в памяти, в которые нужно прочитать или из которых данные нужно записать. А при завершении bio от DM вызывается и callback для завершения исходного bio. То есть при таком вот пироге мы получим дополнительные 3 выделения памяти с последующим перекладыванием байтиков из структурки в стурктурку.
А в свете новых тенденций, когда ПЗУ на микросхемах работает на невероятных скоростях и бутылочным горлышком становится не железка, а операционная система, подобный оверхед мне кажется неприемлемым.
Альтернативы DM снапшотам
Ну конечно, не всё так печально, как я описал, и есть альтернативы. Когда мы ресёрчили вопрос со снапшотами для нашего Veeam Agent for Linux, мы посмотрели, как с этим справляются другие. Оказалось что многие ограничиваются файловым бэкапом. Более серьёзные вендоры предлагают использовать специальный модуль ядра, который реализует логику фильтра блочного устройства. Есть модули проприетарные, но есть и с GPL лицензией. Суть работы тех, что я видел, одинакова: выполняется перехват функции make_request_fn из структуры request_queue. А на тему того, как реализовать фильтр блочного устройства, даже статьи были типа этой.
Собственно наше решение было очевидным, был создан собственный модуль veeamsnap, об его устройстве даже статься на Хабре была. Проблема с таким модулем одна — он не в upstream, значит с каждым релизом ядра, модуль может перестать работать. За несколько лет модуль оброс довольно солидным набором директив условной компиляции, но успешно работал на ядрах от 2.6.32 до 5.8. Вопрос совместимости был поставлен на поток. Наш QA проверяет совместимость модуля с каждым релизом ванильного ядра.
Альтернатив больше нет?
Как-то прошлым летом приходит весточка из QA, что снова что-то сломалось. Я уже было приготовился сделать очередной маленький фикс для ядра 5.8, но оказалось, что ключевая функция make_request_fn() может оказаться не определена. То есть перехватывать её по старинке уже не выйдет. А заглянув в 5.9, я увидел, что она была перенесена из request_queue в gendisk и переименована. При этом трюк с перехватом более не сработает, так как теперь она const.
Выдохнув, остыв и подумав, я попробовал написать автору изменений с вопросом, а как теперь перехватывать запросы к block layer и вообще строить фильры блочного уровня. Ответ цитирую:
On Tue, Aug 18, 2020 at 09:57:29AM +0000, Sergei Shtepa wrote:
> Thank you for your quick response.
> I'm sorry, I think you misunderstood me.
> We do not need to create our own function for processing requests, but to intercept requests to "foreign" block devices.
You're out luck then, this has never been supported.
И да, нужно признать, что это чистая правда. Действительно модули ядра для перехвата запросов к блочным устройствам никогда не поддерживались. И в upstream не было таких модулей, которым перехват этой функции был бы нужен. На моё предложение реализовать какое-то альтернативное решение я ответа не получил.
Итог: альтернатив DM снапшотам больше нет. Ну, почти нет.
Немного хака с X86_CR0_WP
На самом деле, если в регистре CR0 для x86_64 архитектуры поправить 16-тый битик (WP), то можно будет перезаписать и константные значения. В принципе, это открывает широкие возможности для перехвата всего, чего угодно. Наверное, поэтому в штатной функции обращения к регистру native_write_cr0() реализована защита от «случайного» выключения этого бита.
void native_write_cr0(unsigned long val)
{
unsigned long bits_missing = 0;
set_register:
asm volatile("mov %0,%%cr0": "+r" (val) : : "memory");
if (static_branch_likely(&cr_pinning)) {
if (unlikely((val & X86_CR0_WP) != X86_CR0_WP)) {
bits_missing = X86_CR0_WP;
val |= bits_missing;
goto set_register;
}
/* Warn after we've set the missing bits. */
WARN_ONCE(bits_missing, "CR0 WP bit went missing!?\n");
}
}
EXPORT_SYMBOL(native_write_cr0);
Тем не менее, если упростить штатную функцию буквально до одной строки:
static inline void wr_cr0(unsigned long cr0) {
__asm__ __volatile__ ("mov %0, %%cr0": "+r"(cr0));
}
то перехват снова может быть реализован.
Да, мне не нравится такое решение. Да, это выглядит как rootkit. Да, майнтейнеры не одобрят. Однако это решение работает, а для out-of-tree модуля ядра не остаётся другого выбора.
Проблемы блочного уровня ядра Linux
Итак, попробую подвести итог описательной части и сфомулировать проблему более точно. А их на самом деле две.
- Отсутствует возможность реализовать модуль-фильтр блочного устройства.
- В составе штатных средств ядра Linux нет способа снять снапшот с любого блочного устройства.
Я не знаю, что думают другие вендоры средств для резервного копирования, которые должны были бы столкнуться с теми же проблемами. Никакой активности на patchwork я не зафиксировал. Только нашёл на Github как раз решение с использованием X86_CR0_WP. Причин может быть несколько. Но я бы хотел рассмотреть экономическую, как более вероятную.
На мой взгляд, решать эту проблему просто экономически невыгодно. Дело в том, что изначально вендоры средств резервного копирования ориентированы на enterprise сегмент и платный софт. Зарабатывать на Linux всегда было сложно, и объём рынка не так велик. В общем, поддержка Linux выполнялась по остаточному принципу. При таком раскладе тратить значительные силы на предложение своего решения в upstream было нецелесообразно бизнесу (пока всё работало на out-of-tree модулях).
А если кто не в курсе, ситуация с ядром Linux такова: либо ты предлагаешь свои решения и участвуешь в разработке ядра, либо ты плывёшь по течению и пользуешься тем, что есть. И если ты не предложил хорошую платформу для работы своего решения, то обращаться с просьбой «сделать хорошо» просто не к кому.
Дистрибутеры, которые предлагают решения на базе Linux, тоже хотят заработать. Наверное, на платных курсах от Red Hat можно узнать, как правильно развернуть систему, чтобы обеспечить возможность резервного копирования. А сертифицированный специалист поможет сделать это для бизнеса. Опять же, нужно создавать условия, когда платная поддержка необходима.
Возможно, истинная причина ускользает от моего взгляда. Дайте знать в комментариях.
Моё видение решения проблемы
Я, как большой любитель Linux и сторонник open-source, решил, что настало время исправить ситуацию. Раз есть чёткое понимание проблемы, значит, есть отличный шанс попробовать её решить! Пришлось искать пути решения и предлагать их в upstream. Даже статью сделал, вступив на этот тернистый путь. В целом не могу назвать мои попытки успешными, но как минимум мне удалось привлечь внимание разработчиков ядра к этой проблеме и кое-что понять.
Из переписки с разработчиками ядра и мантейнерами я понял следующее: для любой фичи в ядре должен быть её реальный потребитель. Это логично. Если в ядре нет кода, который использует какую-то функцию, то она становится проблемой для дальнейшего рефакторинга и усовершенствования ядра. Она как кость в горле: ни выплюнуть, ни прожевать. То есть её нельзя убрать, поменять, изменить поведение. Это блокер для развития ядра. Если же в upstream есть реальный потребитель какой-то функции, то можно при рефакторинге изменить и саму функцию, и вызывающего его.
В нашем случае, если мы делаем API для фильтр-модулей, то в состав ядра нужно добавить сам модуль-фильтр. Вроде всё просто, но нет. Я пробовал предложить свой модуль ядра. Примерно месяц я его доводил до ума. Прежде всего работа над code style, потом устранение дубликатов кода — то есть убирал свои «велосипеды» и применял решения, уже существующие в последней версии ядра. Предложил его к просмотру и узнал, что мой модуль является сам по себе большущим дубликатом для dm-snap, который тоже снимает снапшоты. Такой вот фейл.
Тогда я взялся предложить улучшение для DM, чтобы он «на лету» мог цепляться к существующим блочным устройствам и создавать снапшоты. С головой погрузился в новый для меня код, разбираясь в его переплетениях. На мой взгляд, blk_interposer в 9-той версии выглядел вполне неплохо и позволял подключать dm-snap к любым блочным устройствам. В перспективе можно было бы и change-tracking навернуть. Но то ли я слишком никчёмный программист и не смог предложить кода достойного ядра, то ли Майк, майнтейнер DM, не очень-то заинтересован в изменении его кода. Не знаю. Сложно что-то понять, когда на твои письма просто не отвечают.
Сейчас я готовлю новый патчсет. Это будет модуль для фильтрации блоков ввода/вывода (bio). Он позволит сделать какую-то область диска недоступной для перезаписи или ограничить доступ к блочному устройству каким-то конкретным модулем или подсистемой ядра. В принципе, правило для фильтрации может быть почти любым (почти как в eBPF, но без eBPF). Кому интересно взглянуть, мой репозиторий тут. Ветка на базе ядра 5.12 здесь. Для 5.13 тоже есть ветка. На мой взгляд, решение уже выглядит работоспособным. По крайней мере, первый срез багов был зачинен. Оценка перфоманса с помощью perf показала, что издержки на фильтрацию незначительны. В ближайшее время я планирую заняться комплексным тестированием своего решения. Ну а потом буду предлагать в upstream.
Вместо заключения
Мне интересен feedback от вас, дорогие читатели и любители Linux. Может, кто-то даст дельный совет, может, кто-то озвучит свою идею. Может, кто-то сделает ревью и найдёт баг или архитектурную проблему. В идеале было бы здорово собрать группу единомышленников, которые бы были заинтересованы в решении обозначенных проблем. В этом случае шансы их решить значительно увеличатся.
А если у вас есть полезная и достаточно интересная, что немаловажно, идея для фильтра блочного устройства — пишите в комментах, пишите в личку. Может, объединив усилия, мы сможем предложить действительно нужный и полезный фильтр-модуль и API для его работы для upstream.
Возможно, проблемы на самом деле нет, а я просто не вижу очевидных решений, тогда просветите меня, пожалуйста. Я знаю, что могу ошибаться, потому что регулярно чиню свои баги.
Только не надо холиварить на тему «ZFS спасёт мир» или что какая-то ОС или дистрибутив лучше другой. Комментарии на тему «А я вот логи базы экспортирую и с помощью rsync тащу файлики» тоже не интересны, так как я рассматриваю резервную копию всей системы целиком, а не какую-то её часть.
So, feedback is welcome!
З.Ы. Тут охотники за головами прискакали на своих каблучках, тычут бумажкой с надписью «WANTED».

Там «все работы хороши — выбирай себе не вкус» — как писал классик (классик — это Маяковский, а не Пушной :).





amarao
Апстрим не достаточно хорошо написал код для решения ваших бизнес-задач. Да, бывает. Метод исправления? Напишите свой!
Но ваша претензия "сделать снапшот любого блочного устройства" — это overstretch. Смотрите, у вас область вашего интереса "мы же крутая бэкап-компания, все блочные устройства должны уметь делать снапшоты".
А вот у меня другая область видения: вот я собрал рейд из блочных рам-дисков. Он должен уметь делать снапшоты? А вот я по rbd подключил ceph. Он тоже должен давать вам host-level снапшоты? А iscsi устройство? А multipath устройство? А nvme-устройство, подключенное через PCI-E-фабрику?
Если вы потребуете, чтобы любое устройство сделало вам снашпоты, вы, фактически, требуете, чтобы мой nvme делал вам снапшоты. Простите, нет. Я ценю мой nvme за 500к IOPS, и жертвовать парой сотен тысяч IOPS во имя удобства для вашего софта я не хочу.
То же касается loop, rbd, iscsi, ataoe и множества других любопытных блочных устройств.
CodeImp Автор
«Апстрим не достаточно хорошо написал код для решения ваших бизнес-задач. Да, бывает. Метод исправления? Напишите свой!»
В принципе да. Написать можно всё что угодно. Но мало написать свой out-of-tree модуль. Чтобы решение работало гарантированно везде — нужно чтобы оно было в upstream. А чтобы добавить что-то в upstream недостаточно просто написать своё.
«А вот у меня другая область видения: вот я собрал рейд из блочных рам-дисков. Он должен уметь делать снапшоты? » — я не вижу в этом проблемы. при подключении фильтра не обязательно просаживать performance. Хотя конечно он просядет во время резервного копирования. И потом, никто не заставляет вас подключать фильтр на ваш nvme. Кому надо — тот подключит. Но мне нужна возможность подключения. Для этого я добавляю проверку, что список фильтров пуст, защищённый percpu_rw_semaphore.
amarao
Вы не можете подцепить в fastpath что-то, не просадив производительность. Посмотрите на срач в районе аудита io_uring, где добавление одного if'а (без полезной нагрузки) уронило производительность на 5%.
CodeImp Автор
Я, конечно, проверил своё решение с помощью perf. Я увидел цифры порядка десятой доли процента.
Чтобы обсуждать это предметно я предлагаю сделать эксперимент. Собрать информацию о производительности на ядре без патча. Потом собрать ядро по тому-же config-у, добавив изменения в ядро, повторить эксперимент. Третий эксперимент — уже с загруженным модулем gbdevflt и добавленным правилом.
Уверен, это будет интересный эксперимент полезный всем, если сделать его чисто.
Loxmatiymamont
Иопсы это очень хорошо, но как предлагается приводить хранящиеся данные к консистентному виду перед их копированием?
Дело не в каком-то конкретном бекапном софте, а в отсутствии более лучших вариантов в принципе.
amarao
Насколько я знаю, в linux все существенные данные находятся в консистентном состоянии. Файловая система журналированная, СУБД журналированные, файловые менеджеры используют safe transaction c fsync.
В целом, весь софт, которому нужно консистентное состояние, сам использует fsync. fsfreeze даёт вам time consistency (нет новых записей в неожиданных местах), fsync даёт вам гарантию записи (и, насколько я понимаю, fsfreeze уважает in-flight fsync'и).
Вы, наверное, хотели спросить, как делать бэкап для софта, который в случае отключения питания имеет данные в разваленном состоянии. Видимо, никак, потому что софт кривой.
CodeImp Автор
Всё так, файловая система действительно журналируемая и fsfreeze даёт консистентное состояние, но только в том случае если после fsfreeze не поступают никакие запросы на запись.
Если прочитать метаданные в начале тома, а через пять минут дочитать том до конца по живой машине — то получится фарш. И БД превратиться в тыкву. В общем, без снапшота можно делать резервную копию только неизменяемых данных.
«Вы, наверное, хотели спросить, как делать бэкап для софта, который в случае отключения питания имеет данные в разваленном состоянии. Видимо, никак, потому что софт кривой.» — нет, нам не интересен кривой софт. Нас обычно интересуют данные на файловой системе и базы данных популярных СУБД.
amarao
Вся суть fsfreeze, что у вас не поступают запросы за запись. Любой запрос на запись ставит процесс в ожидание и он перестаёт "варить".
Как раз "тыкву" от записей во время чтения данных для бэкапа fsfeeze и предупреждает.
Loxmatiymamont
Всё вокруг уже давно журналируемое, с этим не поспоришь. Правда это совершенно не мешает продолжать читать весёлые истории про то, как свет мигнул и супер-журналируемый сервер не может загрузиться. Да, журналы свели к минимуму вероятность потери данных, но не исключили её полностью.
С другой стороны, перемещая файл фс будет старательно рапортовать об успешном завершении записи очередного чанка с данными. И чисто технически, если мы прямо сейчас начнём читать блоки, они все будут абсолютно консистентны, а вот сам файл нет.
Ну и самое интересное: если мы говорим про бекап здорового человека (а не пофайловое чтение всех данных), то нас интересует приведение в консистентный вид всего что есть на диске разом, а не беготня между всеми файлами и процессами.
amarao
Истории про сервера, которые не могут загрузиться после ребута — тру стори. Но они умирают в биосе (не проходят POST) и к ОС никакого отношения не имеют.
Про порчу файловой системы после unclean shutdown я не слышал уже очень долго. Очень. Последнее было в 2009, и с тех пор прошло уже 12 лет.
Вот что реально может быть — это если у вас в зависимостях systemd написано странное. Да, сервер может бесконечно ждать запуска сервиса (если у него так в [install] написано). Но к файловым системам и бэкапам это никак не относится от слова "совсем".
amarao
FSFREEZE(8) System Administration FSFREEZE(8) NAME fsfreeze - suspend access to a filesystem (Ext3/4, ReiserFS, JFS, XFS) SYNOPSIS fsfreeze --freeze|--unfreeze mountpoint DESCRIPTION fsfreeze suspends or resumes access to a filesystem. fsfreeze halts any new access to the filesystem and creates a stable image on disk. fsfreeze is intended to be used with hardware RAID de- vices that support the creation of snapshots. fsfreeze is unnecessary for device-mapper devices. The device-mapper (and LVM) automatically freezes a filesystem on the device when a snap- shot creation is requested. For more details see the dmsetup(8) man page. The mountpoint argument is the pathname of the directory where the filesystem is mounted. The filesystem must be mounted to be frozen (see mount(8)). Note that access-time updates are also suspended if the filesystem is mounted with the traditional atime behavior (mount option strictatime, for more details see mount(8)).CodeImp Автор
Да. Но мы не можем держать файловую систему замороженной пока идёт резервное копирование. Даже в процессе резервного копирования сервер остаётся рабочим и выполняет свои функции. А для некоторых систем резервное копирование может выполняться сутки. Мы пользуемся «заморозкой» на время снятия снапшота. Когда снапшот снят — файловая система «оттаивает» и живёт своей жизнью, а снапшот своей.
Loxmatiymamont
Полностью согласен! Вот на все 146%.