

Скажете, это же все электрические приборы? Бесспорно. Но еще у них есть дисплей. Да, холодильники чаще могут обходиться без дисплея, чем смартфоны, но это неточно. В этом вопросе время на стороне холодильников.
В огромном числе современных электронных устройств, как в узкоспециализированных приборах, так и в массовых гаджетах, применяются средства отображения информации, среди которых растровые графические дисплеи занимают доминирующее место. Дисплеи повышают на порядок (часто на несколько) информативность и способствуют созданию более лаконичного, не перегруженного механическими органами управления, корпуса устройства. Также графические дисплеи дают разработчику свободу в создании пользовательского интерфейса: от простого с несколькими строками текста до навороченного с таким количеством текстовой и графической информации, на какое только способна фантазия разработчика.
Монохромная анимация
Например

Однако, графический интерфейс пользователя практически никогда не может быть реализован только графическими примитивами — точками, линиями, геометрическими фигурами — без использования текста. Текст точно и однозначно "рассказывает" человеку о параметрах системы, ее настройках, прошлом и текущем состояниях.
Сегодня широкое распространение получила пользовательская и специальная электронная техника, значительная часть которой построена на базе микроконтроллеров. Микроконтроллер представляет собой вычислительную платформу, которая может быть запрограммирована почти неограниченным количеством алгоритмов, реализованных на разных языках программирования. Правда, на реализацию накладывают свои ограничения небольшой размер памяти программ (в среднем от единиц килобайт до единиц мегабайт) и ещё меньший размер оперативной памяти, обычно на порядок. А вот драйверы дисплеев, графические библиотеки и сам пользовательский графический интерфейс — отнюдь не компактные алгоритмы. Именно поэтому Вы вряд ли отыщете графические библиотеки для систем на микроконтроллерах, которые бы использовали "взрослые" векторные шрифты для вывода текста. Конечно, есть и такие микроконтроллеры, которые могут дать жару многим серьезным микропроцессорам прошлых лет, но это уже отдельная "весовая категория".
Embedded-шрифт изнутри
Обычно для решения задачи вывода текста в памяти программ создаётся специальный массив данных, так называемая таблица знакогенератора. Не пугайтесь, что он специальный, — все очень просто. В массиве-таблице по сути хранятся растровые изображения всех необходимых приложению символов. Функция графической библиотеки, выводящая текстовые строки, по очереди считывает из таблицы изображение каждого символа и "рисует" его в нужной позиции на дисплее. Все! Идея проста, как столб.
Рассмотрим пример такой таблицы. Предположим, что нам требуется изображение символа шириной 6 и высотой 8 пикселей. Причем, вертикальный ряд пикселей — столбец высотой 8 пикселей — будем кодировать ровно одним байтом. Самый первый байт будет кодировать самый левый столбец. Самый младший бит будет кодировать самый верхний пиксель столбца. Вот пример части такой таблицы:
0x5F, 0x00, 0x00, 0x00, 0x00, 0x00, // Символ 33 <!>
...
0x7E, 0x09, 0x09, 0x09, 0x7E, 0x00, // Символ 65 <A>
0x7F, 0x49, 0x49, 0x49, 0x36, 0x00, // Символ 66 <B>
0x3E, 0x41, 0x41, 0x41, 0x22, 0x00, // Символ 67 <C> А вот та же часть в двоичной записи (посмотрите внимательно на биты — каждый из них кодирует один пиксель изображения):
0b01011111, 0b00000000, 0b00000000, 0b00000000, 0b00000000, 0b00000000, // Символ 33 <!>
...
0b01111110, 0b00001001, 0b00001001, 0b00001001, 0b01111110, 0b00000000, // Символ 65 <A>
0b01111111, 0b01001001, 0b01001001, 0b01001001, 0b00110110, 0b00000000, // Символ 66 <B>
0b00111110, 0b01000001, 0b01000001, 0b01000001, 0b00100010, 0b00000000, // Символ 67 <C> И, конечно же, посмотрим, как эти символы выводятся на дисплее (прямоугольники для лучшего представления знакомест символов):

Такой подход в хранении шрифта имеет свои преимущества и недостатки.
К преимуществам можно отнести небольшой размер таблицы знакогенератора в сравнении с размером файлов стандартных форматов шрифтов для "больших" систем, а также простоту программной реализации графических библиотек, основанных на этом подходе. И первое, и второе чрезвычайно важны в условиях жесткого дефицита памяти и вычислительных возможностей микроконтроллеров.
К недостаткам следует отнести проблемы с масштабированием, что является прямым следствием растровой природы такого шрифта. Приемлемый по качеству результат получается только, если увеличивать размер символов в кратное количество раз, например, в два, три или четыре раза. В таком случае нет искажений изображений символов, но чем больше кратность увеличения, тем более заметна "растровость" символов. Если в разрабатываемой системе требуется иметь несколько разных шрифтов и масштабирование одного не решает задачу удовлетворительно, тогда используют несколько шрифтов — таблиц знакогенератора.
Предыстория
В своё время мне пришлось разрабатывать программное обеспечение для устройства с графическим дисплеем RDX0120 на контроллере UC1601s. Использовался микроконтроллер Microchip PIC18. Тогда была найдена только одна работающая реализация драйвера, которая была жутко медленной и использовала моноширинный шрифт, внешним видом которого можно разве что отпугнуть будущего пользователя.
И вот, не впечатлившись результатом, была изучена документация на контроллер дисплея и разработана довольно быстрая библиотека. Шрифт, естественно, было решено сделать заново. Хотелось также, чтобы шрифт был не только моноширинным, но и пропорциональным, то есть чтобы символы в ширину занимали ровно столько места, сколько им требуется, с равным межсимвольным расстоянием.
Тут-то и понадобилось приложение, умеющее создать ту самую таблицу знакогенератора. Разработчики, которые хоть раз сталкивались с подобной проблемой, сразу же скажут: "Задача известная, решение тоже — утилита от MikroElektronika для создания именно таких шрифтов, и код генерирует аж на трех языках". Действительно, есть такая утилита. Я тоже пробовал ее использовать. Впечатления двоякие. Вроде бы все работает, и в то же время не хватает удобства и гибкости, сама таблица знакогенератора генерируется только по одному единственному алгоритму, который, очевидно, используется в графических библиотеках от той же MikroElektronika.
Идея
Народная мудрость гласит: "Если хочешь сделать что-то хорошо, сделай это сам". После изучения утилиты от MikroElektronika вдоль и впоперек пришло понимание, что так жить дальше нельзя. Тогда было решено начать собственный проект приложения, которое смогло бы удовлетворить самого требовательного разработчика. Хотелось видеть удобный редактор символов, предварительный просмотр образцов текста, наглядный импорт системных шрифтов, компактный формат хранения шрифтов, настраиваемый генератор кода и, конечно же, гибкость внешнего вида и функций приложения.
Как, наверное, большинство начинающих разработчиков, я был величайшим оптимистом и оценил время разработки в несколько месяцев. Как же я ошибался! Нет, действительно, за несколько месяцев был сделан рабочий прототип, но в таком виде его даже друзьям показывать было стыдно. Начался долгий процесс доведения до ума, в ходе которого приложение много раз изменилось внешне, обросло многими полезными и удобными инструментами. К сожалению, проект всегда был хоббийным, поэтому разработка была сильно неравномерной и разорванной во времени. Что в итоге сказалось на сроках выпуска готового приложения. Ведь старт проекту был дан где-то в конце 2015, а сейчас уже 2021.
Показывай уже!
"Вот он! Вот он — этот коварный тип..." (с).
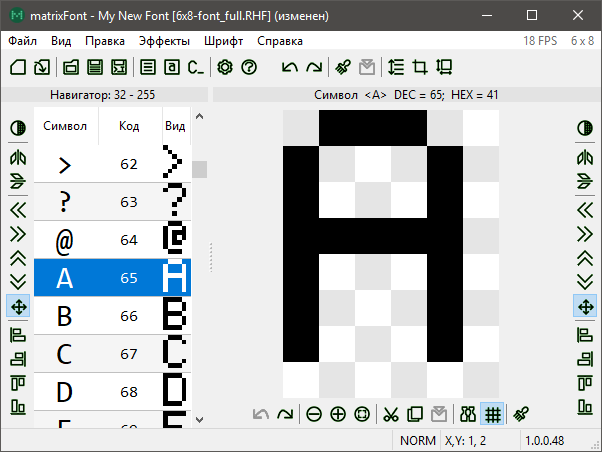
Это приложение, которое умеет создавать растровые шрифты с нуля или на основе установленных системных. Имеет широкие возможности редактирования как отдельных символов, так и всего шрифта. Есть удобная навигация по символам, предпросмотр образцов текста, выбор кодировки и всяческие полезные настройки. И, конечно же, генерирует код на Си — ту самую таблицу знакогенератора. Причём этот генератор также имеет множество настроек, что позволяет интегрировать созданный шрифт в разные программные решения.
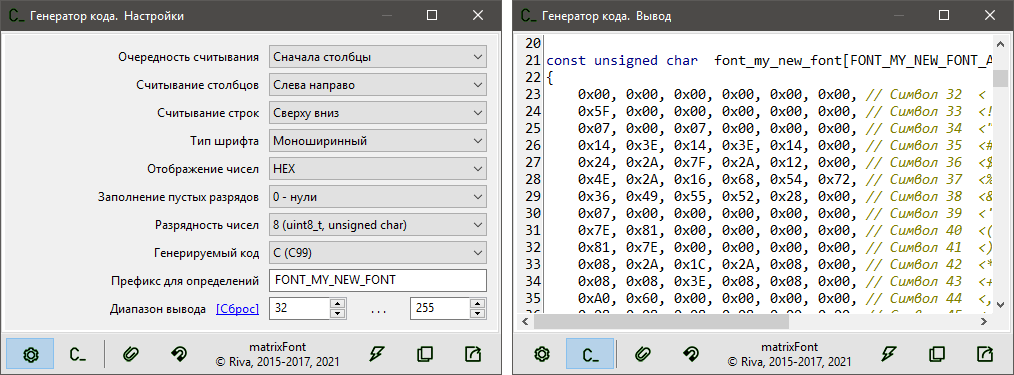
Полагаю, что дальше расписывать работу приложения будет нецелесообразно — получится длинное руководство пользователя. Которое, кстати, присутствует в репозитории проекта.
Пример реализации очень мелкого шрифта — меньше просто физически некуда.

Послесловие
Проект приложения имеет открытые исходные коды и является свободным программным обеспечением.
Сейчас приложение выпущено только под Windows. Может быть, в неопределённом будущем, будут выпуски и под другие ОС.
На сегодня в приложении доступно две локализации интерфейса — русская и английская. Если в сообществе появятся желающие помочь перевести приложение и справочные материалы на свой родной язык, добро пожаловать в репозиторий проекта. Там Вы найдёте всю необходимую информацию для перевода.
И, естественно, автор ждёт Ваших отзывов и комментариев — от похвалы до жёсткой критики. Всем удобной работы и хорошего настроения!
Обновление 1. Чтобы не превращать статью в сборник картинок, добавил ссылки на разделы справки, где есть иллюстрирующие скриншоты.
Комментарии (75)

le2
30.08.2021 15:24Я сам несколько раз делал коммерческие железки с монохромным графическим интерфейсом и все мне нравилось.
Потом однажды на работе мне заменили ip телефон с таким интерфейсом и я понял что не хочу разбираться в меню. Все это уже морально устарело. В моем старом квадратном ipod'е - идеальный тачевый интерфейс. В новой беззеркалке также экран поддерживает мультитач. Сейчас уже в станках и тракторах андроид.
Короче, ниша конечно осталась - сверхнизкое потребление, малая стоимость (уже спорно) ну или просто лучше одного мигающего светодиода зарядного устройства ничего придумать нельзя - светодиод видно в темноте. Но в остальном подобных интерфейсов лучше избегать. Иначе твое изделие попадает в разряд кустарщины или изделия низкого класса.

Karlson_rwa
30.08.2021 15:47+4Иначе твое изделие попадает в разряд кустарщины или изделия низкого класса.
Как же глубоко вы заблуждаетесь, относительно применимости и распространенности монохромных интерфейсов.

PrinceKorwin
30.08.2021 16:07+2Иначе твое изделие попадает в разряд кустарщины или изделия низкого класса.
Мой только что купленный рекордер категорически с вами не согласен, да и я на его стороне.

tmin10
30.08.2021 17:53Хм, мой Mi band имеет неплохой монохромный интерфейс на oled экране. В новых версиях появились цветные, но и этот вполне неплох. Хотя тут тач скрин и жесты.

redsh0927
31.08.2021 06:05+4Монохромный рефлективный индикатор прекрасно виден и при палящем солнце, и не слепит в темноте. Потребляет жалкие копейки. Графика не перегружена глянцем и т.н. «красивостями».
Цветной экран в новых звонилках — абсолютная победа мракетологов над здравым смыслом…

engine9
31.08.2021 08:27+1Хорошее дополнение, но мне кажется нужно уточнить сферу применимости. Если этот девайс предназначен для бытовой электроники с сетевым питанием, то действительно матричные ЖК выглядят как анахронизм. А если это какой-то узкоспецифический девайс предназначенный для профессионалов (типа рекордеров, панелей станков, GPS приемников и т.п.) то там такой дисплей пользователь простит :)
le2
31.08.2021 14:11В одном изделии мы выбирали экран и чуть не остановились на новомодном OLED. Бабло победило, а потом оказалось что в этом изделии сверхважен малопотребляющий режим (это редкий и неочевидный кейс, потому что изделие включено всегда). И у ЖК есть уникальное свойство - его видно и без подсветки. То есть у экрана есть два режима - с подсветкой и без. Это уникальное свойство, чего нет ни у какого другого.
Но у айфоноподобного интерфейса есть другое уникальное свойство - "работа без документации". Это не "победа маркетологов", это то что бизнес может оцифровать. Обучение сотрудников стоит денег.

NeoCode
30.08.2021 18:46+2Для цветных экранов с как минимум 256 цветами дополнительно можно добавить сглаживание (4 или 16 бит на пиксель). Я такое делал, надписи получаются гораздо приятнее.
Ну и сам способ организации массива может быть разным Иногда удобнее сплошным массивом, а иногда — когда не нужны все символы из диапазона — удобнее таблица указателей на отдельные массивы для каждого символа.
riva-lab Автор
31.08.2021 09:26Спасибо за отзыв и интересные конструктивные идеи. Надо подумать, как их реализовать в приложении. Тут ведь дело в том, что я задумывал приложение именно под простые монохромные шрифты, т.к. рассчитывал на использование в жестко ограниченных по ресурсам системах — 8-битные МК, Arduino и т.п. И чем проще представляются данные, тем проще алгоритм их обработки, и тем быстрее он исполняется. Но, конечно, на 32-битных МК использовать вариант со сглаживанием действительно имеет смысл.
peleron
30.08.2021 21:45+4Огромное спасибо. Давно искал похожее решение, всё что находил - было не очень юзабельным. Попробовал вашу утилиту - мега-круто. Даже не вериться что это сделано в Lazarus - настолько смотрится красиво.
Полностью затестить пока нет возможности, но для одного проекта, как доберусь, точно использую.

Sabubu
31.08.2021 00:30+1Ваша утилита ориентирована на редактирование и просмотр символов по одному. Но в реальном тексте будут не отдельные символы, а слова из них. И хорошо иметь возможность видеть, как символы сочетаются друг с другом. Причем желательно в реальном времени, чтобы при редактировании сразу же обновлялась картинка.
Например, на картинке в начале поста жутко выглядит слово "муль-т-иметра" — большие промежутки справа и слева от "т". Сравните промежутки в "ьт" и "им". Возможно, букву "т" стоило сделать более узкой.
В шрифтах, которые используются на Хабре, это исправлено с помощью кернинга — в паре "ьт" мягкий знак заезжает под перекладинку буквы "т".
Если бы в программе справа была панелька для просмотра букв в тексте, это было бы легко заметить.
engine9
31.08.2021 08:24Так это неизбежная проблема моноширинных шрифтов, которые вынуждены быть вписанными в фиксированное знакоместо. Глиф "т" и "ш" располагаются на одинаковой плашке, разве есть возможность их двигать как векторные?
riva-lab Автор
31.08.2021 09:47+1Возможность видеть сочетание символов есть. И кстати, работает именно в реальном времени.
По поводу межсимвольного расстояния. Это же все-таки растровый шрифт, об этом и статья. Но если очень нужен кернинг, то мне видится единственное, возможно корявое, решение: в графической библиотеке при выводе символов анализировать текущий и предыдущий, и выбирать нужное смещение по горизонтали.
И таки да, на картинке в начале символ "т" и правда не удался, его можно было бы сделать не таким широким.


nickolaym
31.08.2021 02:47+2Давным-давно занимался растровыми шрифтами для промышленных принтеров.
Если не сочинять ещё один проприетарный стандарт для себя лично, - то, с одной стороны, те же Adobe Type 1 давно придуманы за нас, а с другой, это изрядный труд - и сделать собственную библиотеку загрузки шрифта в память и вывода текста, и удобный редактор (в котором не только попиксельно вкл-выкл, но и хоть какие-то чертилки и копипасты).

murz85
31.08.2021 09:48Вот бы ещё был импорт из си-кода.
riva-lab Автор
31.08.2021 09:53Интересная мысль. Возможно, это появится в будущих версиях. Но тут надо учитывать одну вещь: импортируемый код должен содержать данные в таком же формате, какой генерируется самим приложением. Конечно, там есть некоторые настройки, но ведь это только несколько вариантов из бесконечного множества доступных.

DenSyo
31.08.2021 13:26обратите внимание на этот проект:
он ужасен, я знаю, но если разовьёте идею, сделаете этот мир лучше)
riva-lab Автор
31.08.2021 13:32Спасибо за ссылку. Глянул на страничку. Из идей этого проекта можно было бы взять поддержку формата Adobe BDF и предустановки генератора кода для разных библиотек.
DenSyo
31.08.2021 13:48ну вообще-то там реализован импорт/экспорт си-файлов для популярных библиотек ардуины и ставил целью привлечь ваше внимание к нему именно ради этого в поддержку просьбы murz85. это действительно ооочень удобный функционал при работе с мк - на что-то поправить в символах тратишь несоизмеримо меньше времени, чем при использовании промежуточных форматов. парсер там конечно примитивный, на больших файлах приходится подождать, я тогда еще многого не умел. очень бы хотелось, что бы идея работы со шрифтами для мк непосредственно с си-файлами продолжала жить.

Andy_Big
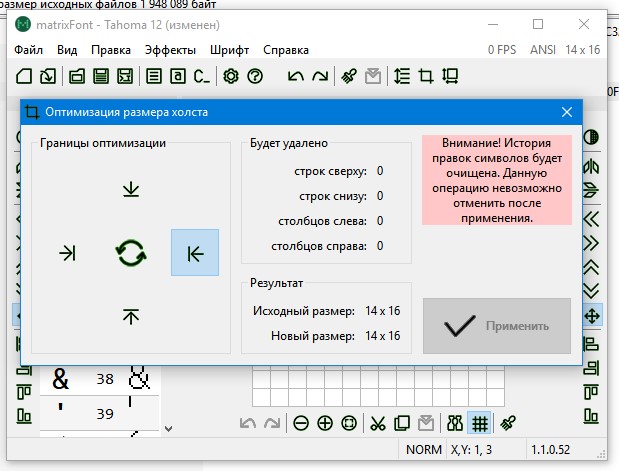
31.08.2021 12:43Импорт нового шрифта, при попытке набрать имя шрифта в поле имени выскакивает ошибка :)

При импорте нельзя сразу задать тип "пропорциональный". Ладно, есть кнопка "Оптимизировать размер холста", жму ее, но в появившемся диалоге кнопка "Применить" никак не хочет становиться активной :)
И что самое главное - нет экспорта в битовый поток. Например, если ширина символа 11 пикселей, высота 17, то чтобы сохранялось битовым массивом по 11 бит на строку, дополняя в конце при необходимости до целого байта. В указанном примере это должно быть 11*17=187 бит плюс еще 5 бит для дополнения до целого байта.
riva-lab Автор
31.08.2021 13:20Тип шрифта и не требуется задавать при создании или импорте. Это опция генератора кода. Если будет выбран пропорциональный тип, то в начале блока данных каждого символа будет еще один байт - ширина этого символа. Что позволит графической библиотеке сразу "видеть" ширину символа, не рассчитывая ее каждый раз.
По оптимизации. Вы выбрали в диалоге оптимизацию только правого края холста. Видимо в Вашем случае хотя бы один из символов содержит в крайнем правом столбце какие-то данные и поэтому оптимизация недоступна.
По поводу экспорта в битовый поток. Т.к. я никогда не пользовался таким вариантом хранения данных в таблице, то и не реализовал его. Но, похоже, это имеет свое применение, так что в будущем может появиться и такая опция генерации кода.
Andy_Big
01.09.2021 17:37Тип шрифта и не требуется задавать при создании или импорте. Это опция генератора кода.
Но мне же надо видеть как этот символ будет отображаться, какие и где будут у него поля :) Или это после оптимизации всех символов становится доступным?По оптимизации. Вы выбрали в диалоге оптимизацию только правого края холста.
Я перепробовал все варианты полей — и по одному и все сразу, и парами — нифига :) Пробовал на разных символах, в том числе и на восклицательном знаке, у которого уж точно правые 80% ширины поля ничем не заняты :)По поводу экспорта в битовый поток. Т.к. я никогда не пользовался таким вариантом хранения данных в таблице, то и не реализовал его. Но, похоже, это имеет свое применение
Это во многих случаях экономит занимаемое шрифтом место, и практически не несет никаких дополнительных накладных расходов при отрисовке :)
У меня шрифт состоит из двух массивов — один (unsigned char) с битовыми потоками символов, второй (unsigned short) с шириной символов. Если в значении ширины установлен старший бит, значит это не ширина, а номер другого символа, на который ссылается этот. То есть можно не кодировать в шрифт, например, русские буквы А, В, Е, К и т.д., а ссылаться на символы латинских букв с таким же начертанием :)riva-lab Автор
01.09.2021 20:08Я не очень понимаю, что за поля Вы имеете в виду. В проекте шрифта размер холста одинаков для всех символов. Т.е. не может быть символ пробела шириной 4 пикселя, а символ А - шириной 10 пикселей. Размеры холста - глобальное свойство проекта шрифта.
Кстати, если при импорте был установлен флажок "Оптимизировать", то естественно, что после импорта с такой опцией оптимизировать уже больше будет нечего. :) Оптимизация - это ведь автоуменьшение размера холста, если таковое возможно, сами изображения символов не передвигаются при этом.
Про битовый поток я понял Вашу мысль. Возможно в будущих выпусках появится такая опция генерации кода. И ссылки на похожие символы тоже.
Andy_Big
01.09.2021 20:31Т.е. не может быть символ пробела шириной 4 пикселя, а символ А — шириной 10 пикселей.
Но как тогда создавать пропорциональные шрифты? :)riva-lab Автор
02.09.2021 09:16Я уже писал об этом.
Это опция генератора кода. Если будет выбран пропорциональный тип, то в начале блока данных каждого символа будет еще один байт - ширина этого символа. Что позволит графической библиотеке сразу "видеть" ширину символа, не рассчитывая ее каждый раз.
В моноширинном варианте байта ширины не будет в коде. Вот и вся разница.
А насчет создания - для пропорционального лучше прижать все символы к левому краю. А вот для моноширинного - выровнять по центру (этой функции нет в приложении, думаю сделать в будущем).
Andy_Big
02.09.2021 14:04То есть в процессе редактирования я никак не увижу какая ширина будет установлена для символа при генерации пропорционального шрифта?
Вот, например, апостроф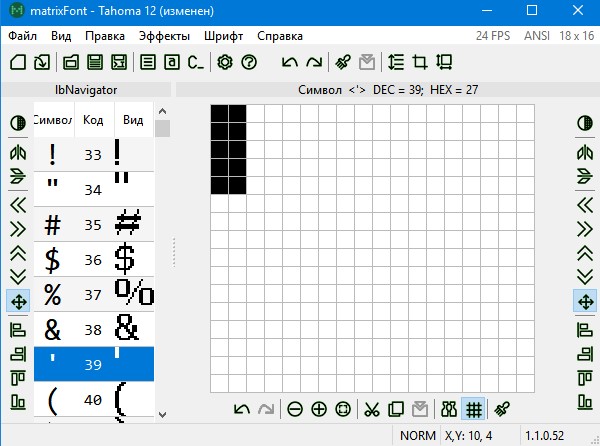
Какой ширины будет этот символ в результате? 2 пикселя? 4? 18? Где это можно указать?riva-lab Автор
02.09.2021 18:26Ширина рассчитывается автоматически генератором кода. Причем, если слева от символа будут пустые столбцы, они тоже посчитаются. Это число по смыслу можно интерпретировать как координату X правой границы символа. Да, в Вашем случае ширина апострофа будет 2.
Andy_Big
02.09.2021 18:43Не айс. Я бы хотел сам задавать ширину символам. Ну или хотя бы указать размеры полей с каждой из сторон. И, разумеется, на картинке хотелось бы видеть символ именно так как он будет выведен в итоге.
riva-lab Автор
02.09.2021 09:50Иллюстрация к предыдущему комментарию.
Различие

пропорциональный моноширинный Andy_Big
02.09.2021 14:05А почему у восклицательного знака ширина 1 пиксель? У символов вообще нет пустого поля славе или справа? То есть они будут сливаться друг с другом если выводить их подряд?
riva-lab Автор
02.09.2021 18:29Ну, если Ваша графическая библиотека будет выводить их подряд, то, конечно, они сольются. Но ведь можно и задать межсимвольное расстояние, например, 1 (или больше, если хочется чтобы текст выглядел разреженным). И тогда после вывода очередного символа виртуальный курсор будет смещаться еще на 1 пиксель вправо, т.о. оставляя промежуток между символами.
Andy_Big
02.09.2021 18:41Ну можно и так, конечно… Но это не слишком удобно. Например, после левой круглой скобки промежуток не нужен, а после двоеточия промежуток желательно сделать чуть больше. Я об этом и пишу изначально — хочется видеть как будет выглядеть окончательно каждый символ. В том виде, в котором он будет сохранен.
riva-lab Автор
03.09.2021 17:55Вы перфекционист. :) Ну, а если серьезно, я ведь приложение сделал для создания шрифтов под системы с крайне ограниченными ресурсами - начиная с 8-битных МК. Сомневаюсь, что в устройствах на подобном железе возникнет острая необходимость в полиграфически безукоризненном виде текста на дисплее. Особенно, если учесть что и дисплеи эти вовсе не FullHD. В общем, нет предела совершенству, как говорится.
Andy_Big
03.09.2021 18:22Но Вы же позиционируете приложение как универсальное :) А получается, что мне приходится жертвовать хорошим видом шрифта в угоду экономии десятка байт. При том, что у меня не стоит остро вопрос в такой экономии :)
Ну то есть я бы с удовольствием использовал Ваше приложение, потому что сейчас я в полуручном режиме делаю шрифты, но не могу :)
riva-lab Автор
04.09.2021 13:10Не бывает абсолютно универсальных вещей. Всегда где-то проходит граница возможностей. :)
Я вижу, Вы основательно заинтересовались приложением. Если напишете сюда или в личку, какие конкретно вещи Вы бы добавили или изменили, я смогу оценить возможность встроить их в архитектуру приложения.





andand
31.08.2021 12:52+1Хороший редактор. Я в свое время для работы со шрифтами и спрайтами пользовался мелкими самописными утилитками. По тому опыту работы есть парочка предложений в функционал программы:
1. Добавить в генерацию кода на С вариант вывода данных в «графическом» виде:типа такого________,________, ________,________, ____OO__,________, ___OOO__,________, _OOOOO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, ____OO__,________, _OOOOOOO,O_______, ________,________, ________,________, ________,________, ________,________, ___OOOO_,________, __OO__OO,________, _OO____O,O_______, _OO____O,O_______, _______O,O_______, _______O,O_______, ______OO,________, _____OO_,________, ____OO__,________, ___OO___,________, __OO____,________, _OO_____,________, _OO_____,________, _OOOOOOO,O_______, ________,________, ________,________, ________,________, ________,________, ___OOOO_,________, __OO__OO,________, _OO____O,O_______, _OO____O,O_______, _______O,O_______, ______OO,________, ___OOOOO,________, ______OO,________, _______O,O_______, _______O,O_______, _OO____O,O_______, _OO____O,O_______, __OO__OO,________, ___OOOO_,________, ________,________, ________,________,
Для этого всего лишь требуется определитьнебольшую таблицу#define ________ 0 #define _______O 1 #define ______O_ 2 #define ______OO 3 #define _____O__ 4 #define _____O_O 5 #define _____OO_ 6 #define _____OOO 7 #define ____O___ 8 #define ____O__O 9 #define ____O_O_ 10 #define ____O_OO 11 #define ____OO__ 12 #define ____OO_O 13 #define ____OOO_ 14 #define ____OOOO 15 #define ___O____ 16 #define ___O___O 17 #define ___O__O_ 18 #define ___O__OO 19 #define ___O_O__ 20 #define ___O_O_O 21 #define ___O_OO_ 22 #define ___O_OOO 23 #define ___OO___ 24 #define ___OO__O 25 #define ___OO_O_ 26 #define ___OO_OO 27 #define ___OOO__ 28 #define ___OOO_O 29 #define ___OOOO_ 30 #define ___OOOOO 31 и т.д. до 255
2. В этой программе кроме шрифтов можно создавать и спрайты, в том числе для анимации (по типу приведенной в статье). Для этих целей максимальный размер «символа» хорошо бы увеличить хотя бы до 320x240.
3. Для шрифтов больших размеров и спрайтов уже может быть актуально применять сжатие для экономии места. Алгоритм LZSS (c измененным кодированием) неплохо подходит для этого.Например здесь экономия порядка 3-х кратной получалась//const char spBigMicro_Data[] = { /* Size:120 */ /*________,________,________,________, //1 ________,________,________,________, //2 ________,________,________,________, //3 ________,________,________,________, //4 ________,________,________,________, //5 ________,________,________,________, //6 ________,________,________,________, //7 ________,________,________,________, //8 _____OOO,OOO_____,__OOOOOO,________, //9 _____OOO,OOO_____,__OOOOOO,________, //10 _____OOO,OOO_____,__OOOOOO,________, //11 _____OOO,OOO_____,__OOOOOO,________, //12 _____OOO,OOO_____,__OOOOOO,________, //13 _____OOO,OOO_____,__OOOOOO,________, //14 _____OOO,OOO_____,__OOOOOO,________, //15 _____OOO,OOO_____,__OOOOOO,________, //16 _____OOO,OOO_____,__OOOOOO,________, //17 _____OOO,OOO_____,__OOOOOO,________, //18 _____OOO,OOO_____,__OOOOOO,________, //19 _____OOO,OOO_____,__OOOOOO,________, //20 _____OOO,OOO_____,__OOOOOO,________, //21 _____OOO,OOO_____,__OOOOOO,________, //22 _____OOO,OOO_____,__OOOOOO,________, //23 ____OOOO,OOO_____,_OOOOOOO,________, //24 ____OOOO,OOOO____,_OOOOOOO,________, //25 ___OOOOO,OOOOO___,OOOOOOOO,________, //26 _OOOOOOO,OOOOOOOO,OOOOOOOO,________, //27 OOOOOOO_,OOOOOOOO,OO_OOOOO,________, //28 OOOOOO__,_OOOOOOO,O__OOOOO,________, //29 _OOOO___,__OOOOO_,___OOOOO,________ //30 }; const struct TSprite spBigMicro = {27,30,COMPRESS_NONE,spBigMicro_Data}; */ const char spBigMicro_Data[] = { /* Size:42 (35%) */ 0x28,0x00, 0x00,0xF0,0xE0,0x02,0x07,0xE0,0x3F,0xF3,0xF3,0xF3,0x83,0x02,0x0F,0xE0,0x7F,0x13, 0x00,0xF0,0x13,0x05,0x1F,0xF8,0xFF,0x00,0x7F,0xFF,0x13,0x0B,0xFE,0xFF,0xDF,0x00, 0xFC,0x7F,0x9F,0x00,0x78,0x3E,0x1F,0x00}; const struct TSprite spBigMicro = {27,30,COMPRESS_LZSS,spBigMicro_Data}; //------------------------------------------------------------------ //const char spBigMili_Data[] = { /* Size:120 */ /*________,________,________,________, //1 ________,________,________,________, //2 ________,________,________,________, //3 ________,________,________,________, //4 ________,________,________,________, //5 ________,________,________,________, //6 ________,________,________,________, //7 ________,OOOOO___,___OOOOO,________, //8 OOOOO__O,OOOOOOO_,__OOOOOO,OO______, //9 OOOOO_OO,OOOOOOOO,_OOOOOOO,OOO_____, //10 OOOOOOOO,OOOOOOOO,OOOOOOOO,OOO_____, //11 OOOOOOOO,__OOOOOO,OOO__OOO,OOOO____, //12 OOOOOOO_,___OOOOO,OO____OO,OOOO____, //13 OOOOOOO_,___OOOOO,OO____OO,OOOO____, //14 OOOOOO__,___OOOOO,O_____OO,OOOO____, //15 OOOOOO__,___OOOOO,O_____OO,OOOO____, //16 OOOOOO__,___OOOOO,O_____OO,OOOO____, //17 OOOOOO__,___OOOOO,O_____OO,OOOO____, //18 OOOOOO__,___OOOOO,O_____OO,OOOO____, //19 OOOOOO__,___OOOOO,O_____OO,OOOO____, //20 OOOOOO__,___OOOOO,O_____OO,OOOO____, //21 OOOOOO__,___OOOOO,O_____OO,OOOO____, //22 OOOOOO__,___OOOOO,O_____OO,OOOO____, //23 OOOOOO__,___OOOOO,O_____OO,OOOO____, //24 OOOOOO__,___OOOOO,O_____OO,OOOO____, //25 OOOOOO__,___OOOOO,O_____OO,OOOO____, //26 OOOOOO__,___OOOOO,O_____OO,OOOO____, //27 OOOOOO__,___OOOOO,O_____OO,OOOO____, //28 OOOOOO__,___OOOOO,O_____OO,OOOO____, //29 OOOOOO__,___OOOOO,O_____OO,OOOO____ //30 }; const struct TSprite spBigMili = {31,30,COMPRESS_NONE,spBigMili_Data}; */ const char spBigMili_Data[] = { /* Size:36 (30%) */ 0x22,0x00, 0x00,0xF0,0xB0,0x0B,0xF8,0x1F,0x00,0xF9,0xFE,0x3F,0xC0,0xFB,0xFF,0x7F,0xE0,0xFF, 0x10,0x13,0x05,0x3F,0xE7,0xF0,0xFE,0x1F,0xC3,0x43,0x02,0xFC,0x1F,0x83,0xF3,0xF3, 0xF3,0xC3}; const struct TSprite spBigMili = {31,30,COMPRESS_LZSS,spBigMili_Data};
riva-lab Автор
31.08.2021 13:03Спасибо за развернутый комментарий и интересные идеи.
Оригинальный вариант визуализации кода символов. Может быть в будущих выпусках добавлю.
Ограничение 100*100 сделал условно. Ничто не мешает перекомпилировать с другими установками лимитов. Но я исходил из следующего: моя реализация редактора оставляет желать лучшего, и нет уверенности, что при таких размерах холста не будут наблюдаться дикие тормоза. Кстати, в продолжение мысли. Кадры анимаций, особенно больших размеров, наверное имеет смысл составлять в других графических редакторах, больше пригодных для этого. А потом импортировать их в генератор кода. Правда, в приложении пока нет опции импорта изображений.
Сжатие - хорошая идея.

mctMaks
31.08.2021 13:07Алгоритм LZSS (c измененным кодированием) неплохо подходит для этого
А можно, пожалуйста, поподробней. Чем жать и каким способом разжимать на МК: динамически выделять память под нужный размер или можно потоково сразу в буфер экрана?
можете поделится ссылкой на примеры с целью повышения самообразованности?
andand
31.08.2021 16:21Программы сжатия на PC и разжатия в контроллере были самописные. Кодирование команд так же свое, заточенное под небольшой размер спрайта. От алгоритма LZSS была взята сама идея повторного использования цепочек данных. Описывать ее здесь смысла нет. Можно почитать, например здесь.
Буфер для разжатого изображения нужно иметь по самой сути LZSS. Он берет оттуда повторяющиеся цепочки данных. Динамически я его не выделял, просто фиксированный буфер под самый большой используемый спрайт.
Главная особенность LZSS — то что он асимметричный. При сравнительно сложном кодере он имеет простой и очень быстрый декодер.
Основное отличие моей реализации LZSS — кодирование команд в потоке заточенное под конкретное применение. Если интересно — распишу подробнее команды и реализацию.mctMaks
31.08.2021 17:04Если интересно — распишу подробнее команды и реализацию.
конечно интересно) можно в личку, если объем большой.
Буфер для разжатого изображения нужно иметь по самой сути LZSS. Он берет оттуда повторяющиеся цепочки данных. Динамически я его не выделял, просто фиксированный буфер под самый большой используемый спрайт.
а почему цепочку сразу нельзя писать в буфер, ведь по сути мы получаем N раз повторить байт M. вроде логично, сразу писать и можно сэкономить немного памяти.
прошу сильно не пинать, если вопросы глупые. я с графикой на МК только столкнулся.
andand
31.08.2021 17:54а почему цепочку сразу нельзя писать в буфер, ведь по сути мы получаем N раз повторить байт M. вроде логично, сразу писать и можно сэкономить немного памяти.
Это будет алгоритм RLE. Он просто пакует повторяющиеся пиксели одного цвета в команды.
LZSS при разжатии либо копирует данные из входного буфера в выходной, либо копирует ранее распакованную цепочку из выходного буфера опять во входной, т.е. нужен произвольный доступ к выходному буферу. Можно ограничить размер выходного буфера размером используемого окна, т.е. максимальным смещением в команде копирования ранее распакованной цепочки.
Существующий в ЖКИ фреймбуфер использовать для этих целей скорее всего не получится. Программный фреймбуфер использовать можно, но это скорее всего усложнит и замедлит декодер.andand
31.08.2021 21:57либо копирует ранее распакованную цепочку из выходного буфера опять во входной
Извините, описка получилась. Правильно будет:
либо копирует ранее распакованную цепочку из выходного буфера опять в выходной
mctMaks
01.09.2021 16:15Это будет алгоритм RLE.
с этим зверем знаком, как раз вчера попробовал. в целом неплохо получается для цветного дисплея с ограниченным спектром цветов.
LZSS при разжатии либо копирует данные из входного буфера в выходной, либо копирует ранее распакованную цепочку из выходного буфера опять во входной
получается что это работает быстрее, чем RLE за счет того что можно не копировать неизмененные данные. Хотя наверно при небольших размерах разница будет не существенна.
Программный фреймбуфер использовать можно, но это скорее всего усложнит и замедлит декодер.
Как раз вчера сделал декодер RLE в программный фреймбуфер, который потом отсылается в экран. получилось примерно 18 мс на картинку размером 240*240 16битный цвет. причем от самой картинки и степени сжатия не зависит. сделал вывод что основной тормоз это запись в память большого числа данных
andand
01.09.2021 22:25получается что это работает быстрее, чем RLE за счет того что можно не копировать неизмененные данные.
Распаковка LZSS и RLE по скорости примерно одинаковы. В обоих случаях в выходной буфер должны попасть все данные, а накладные расходы близки.Как раз вчера сделал декодер RLE в программный фреймбуфер, который потом отсылается в экран.
RLE последовательно только пишет в выходной буфер и не читает из него, так что можно этот поток без проблем писать как в программный так и в аппаратный фреймбуфер. Для LZSS же нужен промежуточный буфер на размер окна кодирования из которого уже можно гнать поток во фреймбуфер.получилось примерно 18 мс на картинку размером 240*240 16битный цвет
кстати, при использовании изображения с большим количеством цветов что RLE, что LZSS не смогут нормально сжать. Если фактически использовалась картинка только с несколькими цветами, то выгоднее использовать палитру, т.е. индексы цвета меньшей разрядности. Один раз в исходных данных записать соответствие, а далее, в самой картинке, в качестве цвета уже указывать индекс.mctMaks
02.09.2021 10:59цветов мало задействована, сжалось хорошо ( в среднем в 9.2 раза). Про индексирование цветов думал тоже
Для LZSS же нужен промежуточный буфер на размер окна кодирования из которого уже можно гнать поток во фреймбуфер.
теперь понял, спасибо.
Andy_Big
02.09.2021 14:11Все же LZSS несколько тяжелее в распаковке, чем RLE — гораздо больше обращений к памяти. RLE просто пишет в нее непрерывным потоком, а LZSS постоянно прыгает по адресам, копируя отдельные участки.
andand
02.09.2021 18:04Да, по обращениям к памяти LZSS конечно тяжелее. Сейчас на быстрых RISC контроллерах это особенно заметно. Раньше на медленных CISC один-два лишних такта на команду не так заметно было.
А в комментарии я имел ввиду что RLE и LZSS (и подобные ему) примерно одинаковы по накладным расходам в сравнении с другими более сложными алгоритмами распаковки.
DenSyo
31.08.2021 14:06+2как человек тоже в свое время написавший утилиты для шрифтов мк сделаю пару замечаний)
размер символов шрифтов не стоит делать больше 255х255 - нет смысла выделять на размер больше 2-х байт, память на мк надо экономить. к сжатию следует подходить разумно в виду низкой производительности процессоров мк и опять же, малого объема памяти. для изображений лучше сделать отдельный формат. хорошим вариантом сжатия изображений является старый добрый PCX - быстро, просто, достаточно эффективно. да и вообще, при работе с мк стоит почаще обращаться к знаниям предков - алгоритмы и форматы 80-х наиболее подходят этому сегменту.
mctMaks
31.08.2021 14:26Спасибо за наводку на PCX, будем посмотреть.
память на мк надо экономить
бесспорное утверждение. причем не хватает обычно именно ОЗУ, а тут решили добавить дисплей и мегабайта флеша стало внезапно как-то мало.
к сжатию следует подходить разумно в виду низкой производительности процессоров мк
современные МК достаточно шустрые плюс ускорители есть внутри разные. вон на днях наткнулся на NXP контроллер который аппаратно LZMA декомпрессию умеет.
при работе с мк стоит почаще обращаться к знаниям предков - алгоритмы и форматы 80-х наиболее подходят этому сегменту
ага, как раз и патенты кончили действовать на большую часть алгоритмов. Кстати, получается что младший брат (МК) донашивает за старшим братом (ПК) алгоритмы?
DenSyo
31.08.2021 15:40получается что младший брат (МК) донашивает за старшим братом (ПК) алгоритмы?
да, особенно в части выкручиваться с малым объемом озу)
современные МК достаточно шустрые плюс ускорители есть внутри разные
мк очень разные, каждый со своими плюсами/минусами и именно поэтому нужен редактор шрифтов умеющий импорт/экспорт си-файлов с поддержкой различных графических библиотек, и еще лучше, если этот редактор будет уметь подключать сторонние библиотеки для поддержки новых форматов. такой редактор сильно упростит выбор графической библиотеки для проекта избавив от заморочек по переносу шрифтов.
andand
31.08.2021 15:54LZSS (это модификация LZ77) тоже древний алгоритм. Тот пример сжатия что я приводил (из своих исходников почти 20 летней давности) без проблем работал на 16-битном контроллере на 16 МГц. Сжатие RLE используемое в PCX не так эффективно для мелких черно-белых спрайтов, а остальные возможности PCX для черно-белых изображений и не нужны.
DenSyo
31.08.2021 16:20не, безусловно, всё имеет право на жизнь. но всё надо пробовать. хорошее сжатие помимо производительности, так же отнимает и пзу логикой этого сжатия, не везде и не всегда доступна эта роскошь. где-то нужна скорость вывода текста на экран, а где-то можно позволить отрисовываться тексту несколько секунд. при работе с мк надо понимать плюсы и минусы разных форматов. для картинок, думаю, стоит сделать несколько вариантов сжатия - быстрые для распаковки, хорошо жатые, и что-то среднее. тот же PCX можно реализовать с разными вариантами, с горизонтальной и вертикальной последовательностями, например, и пусть каждый сам решает в каком виде хранить конкретную картинку.

3epg
31.08.2021 14:29ИМХО лучше было бы вместо LZSS кодирования использовать RLE, которое использовалось раньше в формате изображений PCX. И редакторы графики для этого формата наверное ещё можно найти.

fiego
31.08.2021 18:50Мне тоже недавно захотелось побаловаться с микроконтроллерами. Ардуино и прочая мелочь таки мне скучна в виду слабый возможностей коммуникации, поэтому обратил внимание на ESP32. Поскольку это моё личное время, то трачу его как хочу :) -- написал свою графическую библиотеку с поддержкой разных экранчиков, но откуда брать шрифты, не рисовать же их? Творчески переработал опенсорсную утилиту, которая на основе freetype конвертирует "обычные" шрифты в код на Си. Некоторые идеально прямо вот конвертируются в нужные размеры, но большинство "корявенько", поскольу монохром, а для качества надо бы хотя бы сглаживание. Впрочем, если требуется большой размер символов, то почти любой шрифт подойдёт для конвертации. Вот тут, например, можно видеть результат: https://www.youtube.com/watch?v=9nOHqma-i0U
riva-lab Автор
31.08.2021 19:03Хорошая работа и результат неплохой.
Да, насчет "корявости" конвертации, это действительно наблюдается. И именно поэтому, чтобы не делать лишних действий, я добавил в окно импорта своего приложения предпросмотр образца текста. Т.е. наведя мышку на список шрифтов и прокручивая его (или изменяя другие свойства), я тут же вижу как будет выглядеть текст этим шрифтом после импорта.
fiego
31.08.2021 23:53На счёт визуализации шрифта в исходнике. Вот тут можно видеть что получается: https://github.com/jef-sure/dgx_clock/blob/main/components/dgx/src/fonts/TerminusTTFMedium12.c
На счёт сжатия шрифта. Я пробовал модификацию RLE. Экономия размера до 30%, но разжатие каждого символа довольно дорого получается и требует выделения памяти хотя бы один раз в двойном размере. Поскольку у меня ESP32 и там нет такой уж явной нехватки памяти, то экономия пары килобайт на шрифт не имеет критической важности, а алгоритм упрощается заметно и скорость тоже вырастает.
riva-lab Автор
01.09.2021 08:40Мне вот интересно стало, насколько вообще востребовано иметь визуализацию символа шрифта в виде закомментированной ASCII-графики? Просто во время разработки приложения, да и с своих проектах такой необходимости не видел. Пишите или плюсуйте, если это нужная опция. Может быть в будущем она и появится :)
fiego
01.09.2021 09:57Не скажу на счёт общей востребованности, но, когда требуются не стандартные символы, то весьма полезно, считаю. https://github.com/jef-sure/dgx_clock/blob/main/components/dgx/src/fonts/WeatherIconsRegular24.c
riva-lab Автор
01.09.2021 10:18Согласен. Правда, когда я использовал нестандартные символы, то объявлял define с понятным именем для каждого спецсимвола, например
#define FONT_CHAR_H2O ((char)136)fiego
01.09.2021 12:16Название символа -- это полезно, конечно, но визуальный контроль в комментариях исходника вреда не несёт, так почему бы и нет? Не настаиваю, я сейчас на другим вопросом думаю -- как бы такой вот алфавит сделать в визуальном редакторе, а не подгонкой координат руками, как я это для десяти цифр сделал: https://www.youtube.com/watch?v=GvBGo-hvBrQ
Сам я больше бэкендер по работе, фронтендом только по случаю занимаюсь, в основном веб, редко приложения для десктопа... Мне нужен (мне нужно сделать) визуальный редактор символов, рисуемых из кубических кривых Безье на поле 100х160 (мой размер из демки) с возможностью добавления полей в разные стороны. Ну это так, лирическое отступление на тему шрифтов и их редакторов. Свой первый редактор матричных шрифтов я делал ещё на MSX-Basic году так в 1990м...
3epg
31.08.2021 19:54+1Обновил Lazarus на своей Ubuntu, скачал исходники, компильнул, запустил, работает)) Правда пришлось в юнитах повыпиливать модуль Windows (вроде нигде не используется, а добавлен лазарем по дефолту, т.к. на этот модуль не ругался), ShellAPI и целиком закомментировал функцию FileRemove в u_utilities. Если будет время, может портирую её для убунты, потому как на первый взляд удобная програмка. Писал сто лет назад редактор фонтов на спектруме на смеси ассемблера и бэйсика.
riva-lab Автор
01.09.2021 08:49Вот, честно говоря, никак не ожидал, что уже на следующий день после представления приложения найдется человек, настолько увлеченный. Приятно удивлен. Если портируете на Ubuntu, то кроме меня Вам будут благодарны и многие другие люди. Кстати, уже объявлялся человек с похожим предложением. Наверное, надо создавать отдельный репозиторий, чтобы народ видел, кто уже начал что-то делать.

vit1251
01.09.2021 03:42А может кто знает хороший архив шрифтов?
Кстати поделюсь и своим велосипедом https://github.com/lexview/pybmf позволял в свое время обычный ASCII преобразовать в бинарный формат и вставить в код.
3epg
01.09.2021 06:45Находил коллекции на сайтах посвящённых спектруму. Zx-pk.ru vtrd.in в основном 8*8, 4*8, 6*8


titbit
01.09.2021 20:22Можно делать векторные шрифты достаточно компактными. Преимущества: лучшая масштабируемость и больше символов в том же объеме (а со сжатием еще больше). Недостаток: сложнее код вывода на экран. Пример реализации (не мой) — библиотека rawdraw на гитхабе. Или старый добрый CHR формат от Борланд С/Паскаля.
riva-lab Автор
02.09.2021 09:38Согласен с Вами. Добавить только хочу, что свое приложение делал с упором по максимальную простоту кода, предполагая использование на самых слабых МК. Таких, где только графическая библиотека может "съесть" треть, а то и половину ПЗУ, а ОЗУ в пару килобайт - за счастье (почти все 8-битные МК).

COKPOWEHEU
02.09.2021 11:10Тоже делал когда-то подобное: forum.cxem.net/index.php?/topic/28404-%D0%BD%D0%B5-%D0%BC%D0%BE%D0%B3%D1%83-%D1%81%D0%BA%D0%BE%D0%BC%D0%BF%D0%B8%D0%BB%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D1%82%D1%8C-%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D1%83/&do=findComment&comment=2219950
beerware
У приборов National Instruments (осциллографы, анализаторы спектра, измерители комплексных сопротивлений) нет дисплеев, потому что это просто модули которые врубаются в блок. А морды всего вышеперечисленного - на обычном компьютерном дисплее.
riva-lab Автор
Да, действительно, много устройств (и не только от NI) имеют описанный Вами интерфейс взаимодействия с пользователем. Но, как Вы понимаете, не во всех случаях есть такая возможность, особенно в портативных устройствах.
beerware
Согласен. Пользоваться отдельными приборами или сборкой NI - дела вкуса (и еще бюджета, наверное).
Мне например отдельные больше нравятся, потому что есть ручки