
Я пришел в компанию Lineate работать именно на Node.js. В процессе выполнения проектов мне приходилось обращаться к более опытным коллегам и выяснять ответы на возникающие у меня вопросы, но, как оказалось, никто не был уверен в своих ответах на 100%. C Event loop разобраться сложно и не всегда понятно, зачем это нужно на практике. Поэтому даже у опытных коллег знания по этой технологии часто только теоретические — в рабочих условиях ее применяют редко. Опрос, созданный мной в Google Form, прошли около 25 человек, вопросы были совершенно стандартные, из тех, что обычно задают на собеседованиях. Правильных ответов было очень мало, около 23-24%.
И тут возникли такие задачи, где без хорошего понимания Node.js было бы сложно повысить перфоманс, а следовательно, и лояльность клиента. Тогда мы решили более глубоко изучить теорию, а позже и поделиться полученной информацией о том, что происходит под капотом в Node.js.
Результаты публикуем на Хабре. Если мы хотим добиться производительности, нам нужно отойти от стандартных идей и играть по правилам Node.js.
Детали, на которых базируется Node.js
Паттерн Reactor
Обратимся к классической модели блокирующего I/O: есть сервер, и есть некий компонент системы, обращающийся к БД ( это может быть и другой сервис, и чтение из файла, то есть все то, что заставляет ждать).
В данном примере выполнение кода блокируется, пока не придет ответ компоненту от БД:

Это создаст некоторую сложность, если как минимум два пользователя одновременно обратятся к серверу. Поэтому самый логичный вариант, который позволит выйти из этой ситуации – создать для другого подключения отдельный поток или процесс (или повторно использовать один из имеющихся в пуле), в котором он бы выполнял свои задачи.
Рассмотрим рисунок, который отображает суть модели:

Желтым цветов выделена полезная работа, которая совершается, когда мы получаем новые данные из одного конкретного потока, а бежевым – бездействие потока. На каждый поток у нас тратится ресурс памяти, а также вызывается переключение контекстов, что при достаточно большом количестве подключений делает работу сервера не оптимальной.
Кроме блокирующего I/O существует неблокирующий I/O. При его использовании системные вызовы немедленно возвращают управление, не ожидая чтения файла или сетевого запроса. Одним из вариантов неблокирующего I/O будет реализация цикла ожидания (busy-waiting).
Идея алгоритма заключается в том, что мы проводим активный опрос ресурсов, пока не получим ответа об их готовности:

Через цикл ожидания мы можем обрабатывать несколько ресурсов в одном потоке, но этот метод будет не слишком эффективен, так как мы тратим драгоценное процессорное время на обход ресурсов, недоступных большую часть времени.
Вообще цикл ожиданий можно представить как консьержа, который работает в большом отеле: он бегает по всем номерам и спрашивает, что принести постояльцам. Он будет бегать с первого до последнего этажа и обратно. А если отель очень большой, то для консьержа эта задача станет крайне сложной.

Поэтому нужно избавить наш цикл от опроса ресурсов, которые еще не завершились, а сосредоточить на работе только с теми ресурсами, которые нам уже доступны.
Рассмотрим другой вариант, который является более эффективным механизмом параллельной работы с ресурсами. Механизм называется синхронным демультиплексированием событий или интерфейсом уведомления событий.
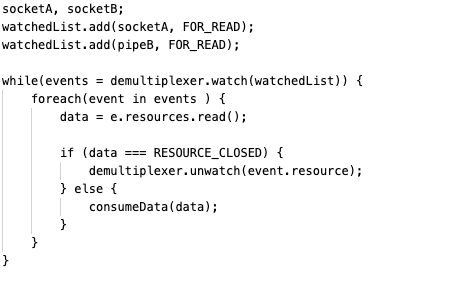
Основная идея, заложенная в этом принципе, такова: у нас есть структура, которая добавляет в себя ресурсы с неким статусом для использования, а механизм оповещения наблюдает за группой ресурсов. Этот вызов работает синхронно и блокирует выполнение до готовности к чтению любого из наблюдаемых ресурсов. Когда вызов выполняется, демультиплексор возобновляет работу и становится доступным для обработки нового набора событий.
В вызове обрабатываются все события, возвращенные демультиплексором. Здесь ресурс, связанный с событием, гарантировано готов к чтению и не блокирует выполнение. После обработки всех событий поток демультиплексора вновь блокируется до готовности обработки новых событий.
Данная реализация уже работает не как простой консьерж: теперь ему помогает менеджер отеля.

Менеджер соберет все данные, которые получит от постояльцев, обработает их, выполнит все задачи и только потом делегирует обязанности консьержу, который будет работать только с теми постояльцами, которые действительно оставляли запрос.
Те идеи, которые мы рассмотрели выше, содержатся в паттерне Reactor, на котором основана сама технология Node.js.
Детальный разбор паттерна
-
У нас есть приложение, которое использует паттерн Reactor.

-
Приложение создает новую операцию I/O, передает запрос демультиплексору событий, а также определяет обработчика для этой операции . Демультиплексор не блокирует приложение, а немедленно передает ему управление. Все работы по операциям происходят на уровне ОС.

-
После обработки набора операции I/O демультиплексор добавляет новые события в очередь событий.

-
Цикл событий приступает к обходу очереди событий.

-
Для каждого события выполняется свой обработчик.

-
Обработчики делятся на две группы:
те, которые выполняются и передают управление в цикл событий, чтобы тот взял новое событие;
-
те, которые создают новую операцию I/O, что приводит к добавлению новой операции в демультиплексор событий до возврата обратно к циклу событий.

-
После обработки всех событий в очереди событий демультиплексор блокирует цикл. Он снова заработает, когда демультиплексор событий отправит новые события в очередь.

Реализация демультиплексора событий
Поскольку операции I/O происходят на уровне ОС, то любая операция может вести себя совершенно различно в разных ОС. К примеру, в Unix не поддерживается неблокирующий I/O, так что для имитации этой операции приходится создавать отдельный поток вне цикла событий. Подобные таким несоответствия привели инженеров к созданию адаптера между приложением и системными вызовами ОС.
Библиотека, реализующая этот адаптер, называется libuv.

Но libuv не только выполняет функцию адаптера, его создатели также добавили туда реализацию самого паттерна Reactor, цикл событий и очередь событий.

Итак, по сравнению с концепцией «один поток на одно соединение», Node.js предоставляет иной подход к обработке запросов. Если классическая модель создает на каждую задачу отдельный поток (то есть для этого она выделяет системные ресурсы), то Node.js работает в одном потоке. Поэтому единственным ресурсом, на котором Node.js может выполнять много задач, является время. Из этого вытекает правило: для лучшей работы на обработчик не нужно вешать очень сложные задачи, затрагивающие ресурс процессора.

Может возникнуть вопрос: почему для своих проектов мы выбрали именно Node.js? Наш текущий проект развивается с 2014 года, Node.js уже тогда был удобен для использования, потому что позволял быстро и качественно, потратив всего несколько дней, получить готовый работающий прототип. Мы работаем с Node.js до сих пор, за 7 лет, конечно, он изменился, вышли новые версии библиотек, но остались юзабилити и высокая скорость работы.
Цикл событий – Event Loop
О цикле событий мы говорили выше, когда обсуждали паттерн Reactor. Его задачей было разбирать события, которые нам отдает демультиплексор событий, и затухать, когда очередь пуста, а у демультиплексора событий еще есть задачи блокирующего I/O.
Но цикл событий выполняет приходящие в очередь события довольно нетривиально, что фактически и делает его довольно быстрым.
Структурно Event Loop выглядит так:
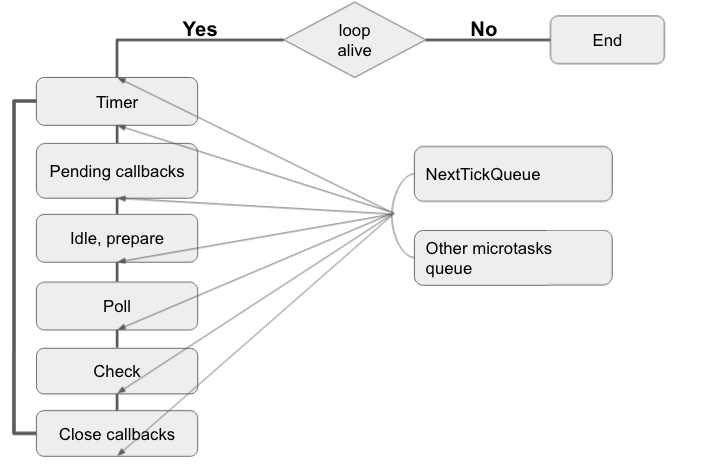
Кратко рассмотрим каждую фазу:
Timer – обрабатываем все колбэки setTimeout() и setInterval(). Интересный факт: для libuv эти две функции – одно и тоже, просто в интервальном таймере параметр repeat стоит с 1.
Pending callbacks – эта фаза выполняет обратные вызовы для некоторых системных операций, например, ошибки TCP.
Idle, prepare – это системные фазы, у нас нет к ним доступа, Node.js сама их вызывает ( особо нас не интересует).
Poll – занимается обработкой I/O операций.
Check – выполняет колбэки setImmediate().
Close callbacks – выполняются события ‘close’, socket.on(‘close’)
Отдельно есть так называемые микротаски:
NextTickQueue – выполняются вызовы process.nextTick()
Other microtasks queue – в основном здесь выполняются Promise.
Данные микротаски выполняются, если цикл событий не находится в одной из 6 вышеописанных фаз.
Хочется заметить, что каждая фаза представляет из себя очередь, в которой содержатся колбэки одного типа. Они выполнятся все: если мы оказались в конкретной фазе и в ней есть определенное количество колбэков, то это все количество колбэков поочередно выполнятся, потом фаза завершится.
Приступим к разбору кода
Обратите внимание: версия ноды, на которой запускался скрипт – 14.15.0, если ваша версия отличается, то вывод на экран может быть другим.

Приступим:
После запуска кода – node index.js, который содержит только функцию main и ее вызов, мы идем по коду сверху вниз, потенциально пытаясь выполнить команды на нашем пути. Встречая на пути синхронные операции, мы их сразу выполняем, асинхронные же операции мы отправляем демультиплексору событий, который займется их обработкой.
Здесь синхронными операциями будут console.log, промисы с await (не будем забывать, что main – async function), а также зарезолвленные промисы.
На момент, когда node.js дойдет до конца функции, мы будем иметь на экране и в очередях фаз:

Теперь в работу вступает цикл событий, он видит, что для него есть задачи.
Первым делом мы выполняем микротаски, которых у нас две в очереди событий. Как только мы со всеми разберемся, то перейдем уже к основным фазам.
В каждой фазе мы будем выполнять все ее готовые колбэки. Выходя из фазы, мы будем потенциально выполнять все новые микротаски, а только потом переходить к новой фазе.
На момент, как цикл событий дойдет до фазы Poll, мы будем иметь на экране и в очередях фаз:
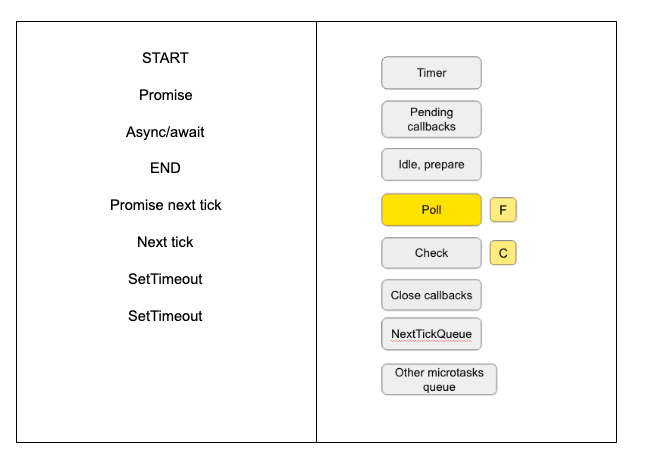
Обратите внимание: вывод на экран SetTimeout и SetImmediate может отличаться. Объяснить такую ситуацию довольно просто: если они оба запускаются из основного модуля, то из-за конкретных особенностей системы (например, из-за производительности процессора) порядок выполнения SetTimeout и SetImmediate может быть разным.
|
SetTimeout SetTimeout SetImmediate |
SetTimeout SetImmediate SetTimeout |
Перед тем, как выполнить потенциальные функции обратного вызова у Poll, цикл событий проверяет на пустоту фазу Check, если в ней что-то есть, то он немедленно переключается на нее. В рамках этой итерации цикл событий Poll уже трогать не будет.
На данный момент будем иметь такую картину:

Закончив эту итерацию, цикл проверит, нужно ли ему начать новую, есть ли еще невыполненные колбэки. На новой итерации он будет вести себя так же, как на прошлой, с единственной оговоркой, что в фазах он долго задерживаться не будет, ведь нечего обрабатывать, пока не дойдет до фазы Poll, которую пропустил на прошлой итерации.
Выполнив фазу Poll, мы получим новый результат:

После выхода из Poll цикл ведет себя штатно: он будет ходить по таскам и микротаскам, используя те правила, о которых я писал выше. Единственное, что тут можно заметить – setImmediate выполнится гарантированно раньше, чем setTimeout. Этому есть разумное объяснение: цикл событий уже прошел фазу Timer, но еще не прошел стадию Check.
Когда мы начнем новую итерацию и выполним таймеры, то будем иметь:

Мы видим, что очереди фаз пустуют, что код больше не создаст новой асинхронной операции, но циклу событий этого неизвестно, он еще раз честно пройдет начавшуюся итерацию, которую мы начали из-за необработанного колбэка таймера, а только потом прекратит свою работу:


логика Event Loop. До 11 версии Node.js последовательность действий могла меняться.
выполнение макротасков – пока все микротаски не выполнятся, макротаски не будут выполняться.
Здесь возникает вопрос – как долго Event Loop может эти микротаски выполнять? Есть определенное количество или выполнение будет происходить, пока они вообще есть в наличии или пока не закончатся ресурсы?
Чтобы Event Loop выполнял их всегда, достаточно сделать так:
пишем рекурсивную функцию с process.NextTick();
запускаем таймер, который выполнится через 10 секунд.
В итоге process.NextTick забьет таймер, и результат работы таймера мы не увидим.
Об этих кейсах мы поговорим подробнее в наших дальнейших статьях.
Event Loop иногда не справляется со своими задачами. У нас тоже возникали проблемы в работе, например, одна из них – игнорирование сложных операций.
Мы занимаемся разработкой и поддержкой сервиса, который манипулирует с огромным датасетом в специфичной теме. Данные в датасете имеют неисчисляемый вариант конфигураций, а также миллион факторов, влияющих на них. В функциональности данного сервиса есть возможность создавать различные pdf-репорты на основе агрегации датасета, а также вычислять множество различных статистических значений по нетривиальным правилам.
Когда вы реализуете сервис с такой функциональностью на Node.js, вам стоит продумать каждый аспект «от и до». Ведь вы даете любому пользователю в любое время и в любом масштабе манипулировать с данными. Такие действия могут привести к тому, что ваш перфоманс упадет, а следовательно, и лояльность к сервису испарится.
Пример работы с Node.js
Давайте с вами создадим маленькое Node.js приложение, которое будет иметь два GET запроса:
возвращает некие фиксированные данные;
вычисляет среднюю зарплату по компаниям
Чтобы упростить генерацию компаний и людей, чтобы не придумывать каждой компании свое название, я использовал https://github.com/marak/Faker.js/
Итак, мы генерим много компаний, в каждой компании у нас довольно много сотрудников, за моконые данные будет отвечать факир, а сами компании и их работников для простоты будем хранить в памяти.
Так вот, если вы сейчас вызовете эндпоинт по статистике, то сразу данные вы не получите. Разумеется, железо вашего сервера тоже влияет на скорость выполнения запроса, но всегда ведь есть свой предел по количеству данных. Например, мой локальный предел – это 10000 компаний, с 1000 сотрудников, с ЗП до 100000. В такие моменты я действительно жду, когда Node.js посчитает все среднее.

Попробуйте в этот момент пойти на первый эндпоинт. К сожалению, он тоже будет висеть.

Как так? Ведь это статичные данные, которым нужно константное время? – Не забывайте про особенности Node.js.
Сейчас мы в локальных условиях продемонстрировали то, что может произойти на реальном проекте, если не просчитать все аспекты вашей системы. Но только давайте помнить, что реальный проект имеет гораздо больше данных, эндпоинтов и формул.
И сейчас я повторюсь: основной ресурс, на котором ваше Node.js приложение может работать эффективно – время. Потому что Node.js не любит сидеть на одном месте, он всегда делегирует задачу, пришедшую из бизнеса, кому-то другому.
Основываясь на этом, мы инкапсулировали почти всю ресурсозатратную логику на отдельном сервисе, что позволило Node.js не блокироваться, а обрабатывать запросы других пользователей без аффекта. Также мы стали максимально кэшировать всю полезную нагрузку с отдельных сервисов на MongoDB, чтобы еще повысить перфоманс. И даже манипуляцию с MongoDB мы отдали MongoDB, а не Node.js. Почти всю математику и перебор данных мы свели к нулю.
Вернемся к нашему примеру, теперь давайте напишем еще одно Node.js приложение и делегируем ему логику сложных вычислений, а старому эндпоинту дадим логику делегирования.
Попробуем еще раз, если мы запустим эндпоинт со статистикой, то снова будем ждать. Но: если теперь зайдем на эндпоинт с фиксированным данными, то сразу получим ответ, потому что мы не застряли на одной таске, мы пошли дальше, а к ней вернемся, когда она уже будет выполнена.

Итак, работая с Node.js, я для себя сделал следующие выводы:
Никогда не нагружай Node.js. Это самое главное правило. Чем меньше твои задачки, чем меньше Node.js будет тратить времени на их выполнение, тем перфоманс твоего проекта будет лучше. Поэтому максимально уменьшай задачи.
Если ты делаешь какие-то сложные вычислительные вещи, строишь графики, вычисляешь значения функции, и ты не можешь реализовать делегирование, то стоит задуматься, может не использовать вообще Node.js? Возможно, стоит использовать другой язык программирования.
Если все-таки выбор остается за Node.js, то можно использовать отдельный микросервис или отдельно поднимать другую ноду.
Если проект существует уже довольно долго, то от legacy стоит избавляться. Он не использует новые фишки javascript, он использует старые библиотеки, это сильно тормозит работу. Совмещать современную разработку и legacy очень тяжело, здесь есть два варианта: 1) обновлять кодовую базу как можно чаще и 2) использовать все современные практики, которые действительно упрощают разработку.
Вывод
Node.js – отличная платформа, основанная на нескольких важных принципах, которые обеспечивают быструю разработку гибких приложений. Для многих разработчиков эти идеи покажутся незнакомыми: асинхронный характер паттерна Reactor, основанный на функциях обратного вызова, требует другого стиля программирования; event loop, который имеет свой конкретный порядок и правила выполнения событий. И, если вы хотите добиться нужного вам перфоманса, все эти правила придется знать и соблюдать.
Источники:
Комментарии (30)

amarao
22.10.2021 20:35А io_uring вне досягаемости ноды?

jomb_g Автор
22.11.2021 11:32К сожалению, не копал так глубоко. Но хороший пойнт для улучшения экспертизы.
Если вам что-то известно, то буду рад почить/посмотреть =)amarao
22.11.2021 12:18io_uring: https://man.archlinux.org/man/io_uring.7.en
в сочетании с нодой не знаю, я ноду не знаю.

bankir1980
23.10.2021 00:33Что-то переделанный пример похож на инструкцию как рисовать сову. Непонятно почему статичный запрос перестал висеть, когда его запрашивают в тот момент, когда запустился"тяжёлый" код в getStatistics. Особенно это интересно в свете того, что судя из статьи первым обрабатываются микротаски, а запрос приходит через network i/o, а это как я понимаю сидит примерно в фазе Pool и должно обрабатываться после микротасков?

mayorovp
23.10.2021 13:16Потому что надо читать текст статьи, а не только примеры кода. Автор предлагает выполнять "тяжелую" работу в отдельном процессе, в то время как для основного процесса метод getStatistics выполняет всего лишь HTTP-запрос, который много процессорного времени не требует.
bankir1980
23.10.2021 13:26По-моему это вы не читали статью. getStatistics и есть функция, выполняющая тяжёлую работу - расчет средней ЗП по всем сотрудникам всех компаний.
mayorovp
23.10.2021 13:38Читайте ещё раз:
Вернемся к нашему примеру, теперь давайте напишем еще одно Node.js приложение и делегируем ему логику сложных вычислений, а старому эндпоинту дадим логику делегирования.
bankir1980
23.10.2021 13:57Вон оно что, а я то всё думал, что тут автор имел ввиду? Оказывается отдельный веб сервер для сложной функции. Я подумал что тут имелась ввиду функция getStatistics со сложным кодом, а делегирование через async await.
Ну про воркеры то автор видимо не слышал. На худой конец кластеризация. Надо отдельный веб сервер запилить, да...

ImLoaD
23.10.2021 16:05Возможно не веб сервер, а через exec вызывается новая нода которая всё посчитает и вернет результат. Честно сказать самому не хватило информации о том, как это реализовал автор
bankir1980
23.10.2021 00:47Ещё попутный вопрос. Классическая ситуация. Нужно получить данные по выбранной page и количество данных по выборке, чтобы посчитать количество pages. Имеет ли смысл выполнять эти запросы к бд в 2-х отдельных Promise и ждать выполнения обоих, чтобы вернуть данные, или можно не париться и сделать каждый с await? Всё равно ведь они попадают в микротаски (запрос к бд асинхронный), а там они выполняются последовательно, а не одновременно? Т.е. алгоритм по факту получается одинаков в обоих случаях, только по коду с promises кажется, что они выполняются параллельно, а с await последовательно?

hello_my_name_is_dany
23.10.2021 01:02+1Посмотрите как работает await. Это будет два последовательных запроса, что через then, что через await. Если хотите всё же два запроса асинхронно сделать, то используйте Promise.all или Promise.allSetled. Но учтите, что один коннкешн нельзя использовать в этом случае, то есть для каждого запроса должен быть свой коннект из пулла.
csshacker
23.10.2021 01:08Всё равно ведь они попадают в микротаски (запрос к бд асинхронный), а там они выполняются последовательно, а не одновременно?
Одновременно. У libuv есть свой тред-пулл
Saiv46
23.10.2021 04:29Но в случае с await тогда писать придётся так:
const promiseA = getData(1) const promiseB = getData(2) const resA = await promiseA const resB = await promiseBПока мы будем ожидать выполнения первого промиса, нода сможет выполнить второй паралельно.
Проще и понятнее, конечно, будет использовать Promise.all

korob93
22.11.2021 11:42+1Кроме того, ничего не мешает комбинировать промисы с await
const [resA, resB] = await Promise.all([getData(1), getData(2)])

Alexandroppolus
23.10.2021 11:25Если не ошибаюсь, синхронным консоль.логом из примера будет только "START". То что в then и после await - это микротаски
korsetlr473
23.10.2021 13:00-5господи сколько знаний , костылей , кода , синхронизаций , ухищрений , зачем вам всё это? перейдите на нормальный язые программирования который из коробки поддерживает многопоточность например C#

dimuska139
24.10.2021 12:26+1Возможно, вы не в курсе, но в C#, кроме потоков, тоже есть async/await, и добавили их туда не просто так.


bankir1980
23.10.2021 13:29+1Нашёл интересную статью, где лучше раскрыта тема. https://snyk.io/blog/nodejs-how-even-quick-async-functions-can-block-the-event-loop-starve-io/
Promise и await не всегда обеспечивают асинхронность и в некоторых случаях блокировки происходят.
mayorovp
22.11.2021 13:11Держите потерявшуюся ссылку: Node.js Event-Loop: How even quick Node.js async functions can block the Event-Loop, starve I/O

eeeMan
22.11.2021 11:33лол, в первом же примере ошибка) не будет никакого ожидания, потому что там пропущено await
jomb_g Автор
22.11.2021 11:35На этом примере представлен псевдокод, работающий в одном потоке.
Но спасибо вам за замечание, пропишу этот момент более детально, чтобы двойственности не возникало =)
Akuma
Опрос то можно посмотреть? Что ж там такое, что не прошли. Вангую, что очередные бредовые задачи типа «посчитайте в уме что из этих 100 строк сработает первым»
jomb_g Автор
Здравствуйте, старался задавать фундаментальные вопросы, так как сам перешел из Java разработки
Некоторе вопросы, которые я задавал
Suvitruf
А зачем вообще знать о том, используется ли там Event loop из V8 или из libuv? ????
Akuma
А зачем вообзе это знать программисту, если он не дорабатывает саму ноду?
И да и нет. Вон ниже спрашивают про два параллельных запроса к БД. Это две асинхронные функции которые отправят два параллельных запроса. Но если в функциях чисто JS код, тогда нет, но если обернуть их в воркеры, то да. Условия задачи так себе.
Подозреваю, что имеется ввиду завершение программы. Но никто такими понятиями по факту же не оперирует.