

Вавилонская рыбка открыла свои коды
Главный девелопер-адвокат AWS Себастьян Стормак (Sébastien Stormacq) от имени Amazon объявил с зашкаливающим радикализмом об открытии кода Babelfish: Goodbye Microsoft SQL Server, Hello Babelfish. Об этом пишут и на OpenNet:
Amazon открыл код Babelfish, расширения для замены MS SQL Server на PostgreSQL
Babelfish поддерживает сетевой протокол, используемый для подключения клиентов к SQL Server, язык T-SQL и специфичные для SQL Server расширения языка запросов, что позволяет переводить работающие приложения с Microsoft SQL Server на PostgreSQL без модификации их кода или с минимальными изменениями и без замены драйверов к СУБД. Для приложений Babelfish выглядит как штатный SQL Server. Проект уже используется в сервисе Amazon Aurora.

Это не сюрприз. Ещё в Postgresso 27 была ссылка на статью о Babelfish
Want more PostgreSQL? You just might like Babelfish, а в Postgresso 29 на Babelfish: the Elephant in the Room?
Русский перевод названия этой последней статьи, появившейся на сайте фонда испаноговорящего сообщества FUNDACIÓN POSTGRESQL звучал бы так: Вавилонская рыбка или слона-то я и не приметил?
Автор статьи — Альваро Эрнандес (Álvaro Hernández Tortosa, OnGres), недавний ньюсмейкер по части тяжбы с сообществом. В той статье он начинает с рыночной конъюнктуры, чтобы дальше предъявить гамлетовский вопрос, которым авторы Вавилонской Рыбки должны были задаться: форкать или не форкать?
Babelfish пока не может работать как расширение без доработки ядра PostgreSQL. Альваро напоминает, что 25-го января заслуженный и авторитетный в сообществе человек — Ян Вик (Jan Wieck) — предложил обсудить расширяемость протокола PostgreSQL: сделать такие хуки, которые позволят реализовать протокол SQL Server в виде расширения без изменений в ядре. Но это процесс небыстрый. Заодно решили обсудить и совместимость с MySQL. Но что делать AWS с Bablefish, если сообщество проигнорирует этот путь или интеграция пойдёт ни шатко, ни валко? Вероятней всего, считал Альваро, AWS будет развивать Bablefish как форк (так уже случилось с Aurora), как бы им не хотелось бы обойтись без форка. А если всё же придётся, то AWS это по силам.
Далее Альваро привлекает Дилемму инноватора. И задаёт ещё один интересный вопрос: хотим ли мы (то есть сообщество), чтобы Babelfish стала “MariaDB у PostgreSQL”?
История историей, теперь уже Альваро рассказывает, как разворачивать Bablefish в K8s, запустить, пользоваться протоколом TDS:
Easily Running Babelfish for PostgreSQL on Kubernetes
Но делает он это без лишнего нейтралитета: предлагает воспользоваться разработкой своей компании: StackGres 1.1.0-beta1, в которой есть поддержка Babelfish. И честно предупреждает: Babelfish даже с 1.1.0 не станет готовой к промышленной эксплуатации — только на свой страх и риск. Заодно показывает, как установить Kubernetes, если ещё не установлен. Но только не «привычный» K8s, а K3s, лёгонький, но сертифицированный дистрибутив Kubernetes от SUSE Rancher.
Ещё бы не риск: по Дугласу Адамсу вавилонская рыба питается энергией биотоков мозга.
Если же говорить об «обычной» интеграции PostgreSQL с MS SQL Server, то об этом опубликовано немало. Сейчас, в Эпоху Импортозамещения, этот вопрос интересует многих. Ещё в 2016-м на Хабре появилась статья Артура Закирова aka select_artur:
Интеграция PostgreSQL с MS SQL Server
Он интегрирует через tds_fdw, и описывает настройку подключения PostgreSQL под Linux к MS SQL Server. Там также показано, как импортировать все таблицы определенной схемы базы данных MS SQL Server в PostgreSQL без описания структуры каждой таблицы.
Примерно тем же в начале 2019-го занимается Лука Феррари (Luca Ferrari), перебрасывая данные с Microsoft SQL Server 2005 на PostgreSQL 11:
PostgreSQL to Microsoft SQL Server Using TDS Foreign Data Wrapper
Ключ (гаечный) к PostgreSQL
Были сомнения, можно ли считать этот ход Google значимой новостью. Но когда гигант приходит в движение, он даже ненароком может зашибить соседей. К любым телодвижениям гигантов лучше быть готовым.

Google Cloud Gives Spanner a PostgreSQL Interface
В середине октября Google официально представил Spanner с интерфейсом SQL, который должен привлечь гораздо более широкий круг пользователей. До этого СУБД с синхронизаций по атомным часам и GPS, скромно названная Spanner, позиционировалась как база для тех, кому нужны петабайтные системы с миллиардами запросов в секунду. Теперь они хотят завлечь пользователей с куда более скромными потребностями и бюджетами, поэтому аренда уменьшилась в 10 раз — с $650 до $65 в месяц (пропорционально доступным арендатору ресурсам), но этого мало: нужно, чтобы арендатор не переписывал полностью свои приложения, а лишь слегка подправлял. Отсюда поддержка SQL. Хотя началась история эскуэлизации, конечно, не сейчас. SQL прикручивают давно. Вот научная статья 2017-го Becoming a SQL System.
К совместимости движутся они с двух сторон: первый — надстраивание SQL над Spanner, а вот второй — мотоцикл с коляской (sidecar), причём коляска виртуальная. Её функция — транслировать протокол PostgreSQL в протокол Spanner.
Но это не простой SQL, а постгресовый. Энди Гатманс (Andi Gutmans, вице-президент и генеральный менеджер по базам данных в Google Cloud) сразу признаётся, что целиком обеспечить совместимость с протоколом PostgreSQL им не под силу (не такой уж большой коллектив), но они в этом направлении движутся.
В документации Spanner есть раздел The PostgreSQL language in Cloud Spanner, в котором есть список того, что Spanner пока не поддерживает. Немало. Например, не поддерживаются расширения; пользовательские типы данных, функции и операторы. Работы ещё на годы (такими темпами с такими выделенными на это ресурсами).
Google Spanner – SQL compatibility — статья, написанная швейцарцем Франком Пашо (Franck Pachot) в январе этого года. Он исследует особенности PRIMARY KEY, FOREIGN KEY, CHECK CONSTRAINTS и другое, приспосабливая свои запросы к Spanner. Если проект будет развиваться быстро, это статья и устареет быстро — вот и увидим.
(Вот, кстати, статья того же Франка Пашо, но с экскурсом в особенности Yugabyte (они могут заинтересовать пользователей, имеющих дело с распределёнными базами): ORDER BY is mandatory in SQL to get a sorted result)
Приходит на ум сомнительная аналогия с распределённой и быстрой СУБД Tarantool, создатели которой решили надстроить над ней SQL. В том числе для совместимости с Postgres они сделали pg — PostgreSQL connector for Tarantool. О прикручивании SQL и ACID к своей базе рассказывали на конференциях. Но хромает аналогия не на техническую ногу, а на инвестиционную: реализуются они или нет, масштабы возможностей несопоставимы.
Три друга: Zabbix, Postgres, TimescaleDB
В статье Zabbix, временные ряды и TimescaleDB Александр Калимулин сначала объясняет, почему для хранения временнЫх рядов лучше всего подходит TimescaleDB, которая устанавливается как расширение PostgreSQL. Вот что нужно Zabbix от СУБД:
- Временные ряды могут быть расположены на диске в виде последовательности упорядоченных по времени блоков.
- Таблицы с данными временных рядов можно проиндексировать по обозначающему время столбцу.
- Большинство SQL-запросов SELECT будут использовать условия WHERE, GROUP BY или ORDER BY по обозначающему время столбцу.
- Обычно данные временных рядов имеют «срок годности» по прошествии которого их можно удалить.
И вот почему стоит глянуть в сторону TimescaleDB:
«Очевидно, что традиционные базы данных SQL не подходят для хранения таких данных, так как оптимизации общего назначения не учитывают эти качества. Поэтому в последние годы появилось довольно много новых, ориентированных на временные ряды СУБД, таких как, например, InfluxDB. Но у всех популярных СУБД для временных рядов есть один существенный недостаток — отсутствие поддержки SQL в полном объёме. Более того, большинство из них даже не являются CRUD (Create, Read, Update, Delete).»
В общем, лучшее из двух миров. Александр объясняет, как это лучшее устроено, и как его заставить эффективно работать. Далее — тесты.
Статья написана 2 с половиной года назад (вышла сначала на английском за подписью alexk), поэтому не всё может показаться свежайшим: тестовый стенд — Zabbix 4.2rc1 с PostgreSQL 10.7 и TimescaleDB 1.2.1 под Debian 9.
А вот уже год с небольшим назад там же, в хабр-блоге Zabbix появляется статья Екатерины Петрухиной (aka KatePetrukhina), основанная на докладе тренера и инженера технической поддержки Zabbix Александра Петрова-Гаврилова:
Миграция с MySQL на PostgreSQL
Среди причин миграции там есть две интересные и даже приятные:
Документация на русском языке.
Преимущества PostgreSQL Pro.
Статья по сути инструкция по миграции Zabbix на PostgreSQL, про TimescaleDB там ничего нет. Зато в комментариях люди делятся опытом, например: Вот вы смигрировали на PgSQL + TimescaleDB, а специалистов по TimescaleDB не так много в наличии.
Ссылка на видео доклада Петрова-Гаврилова есть на этой страничке (также там Мониторинг PostgreSQL c использованием Zabbix (с mamonsu) Дарьи Вилковой и другие).
О TimescaleDB пишут немало, среди них Иван Муратов, технический директор «Первой Мониторинговой Компании». Он делал доклад TimescaleDB 2.0 — Time-series данные в распределенном кластере TimescaleDB поверх ОРСУБД PostgreSQL на PGConf.ru этого года, соответственно говорил уже о версии существенно более молодой (но более зрелой — как это бывает в ИТ). Этот доклад, кроме прочего, интересен тем, что Иван рассказывает о работе TSDB на кластере со многими узлами.
Между прочим, доклад Ивана Муратова на PGConf 2019 был в тройке лучших (по голосованию участников конференции) и назывался он PostgreSQL + PostGIS + TimescaleDB — хранилище для систем мониторинга транспорта.
К слову: Function pipelines: Building functional programming into PostgreSQL using custom operators — статья от TimeScale, представляющая ни много ни мало концепцию функционального программирования внутри PostgreSQL (и SQL). Для любителей Pandas и PromQL.
И ещё, пожалуй:
Generating more realistic sample time-series data with PostgreSQL generate_series()
Это 2-я статья в 3-частной серии Timescale о генерации правдоподобных данных при помощи
generate_series() (часть 1 — вот). В этой, 2-й части автор — Райан Бооз (Ryan Booz) задаёт себе философский вопрос: а что такое правдоподобные данные? Отвечает. И создаёт 2 таблички, одна из них гипертаблица с нагенерёнными данными. И обращается к ним с запросами, содержащими гиперфункции. 3-ю часть ждём. Just In Time: В самое время. Или вообще не вовремя?
Роковой каскад: JIT, и как обновление Postgres привело к 70% отказов на национальном сервисе критической важности
Это переводная статья, оригинал вот.
Оказывается, пострадал портал Coronavirus (COVID-19) in the UK (интересные данные, кстати). Сервис работает на Hyperscale (Citus) в высокодоступной экосистеме, где сбойный экземпляр может быть заменен в течение пары минут.
Там любопытное и длинное расследование, которое в результате пришло к тому, что при переходе к новой версии, основанной на PostgreSQL 14, запрос, который выполнялся 1мс, стал выполняться 5с из-за того, что в новой версии по умолчанию включён JIT. На простых и частых запросах это может приводить к каскаду неприятностей. Конфигурировать надо с умом, не доверяясь значениям переменных по умолчанию (в статье упоминается
jit_above_cost, но есть и другие стоимости). В конце есть примечание переводчика: Упоминание изменения значения параметра по умолчанию в новой версии — важная часть release notes, а миграция на новую версию должна это учитывать и создавать явные конфигурации с предыдущим значением параметра. В Jmix всегда так делаем :-)
Что ж, ради последней фразы, возможно, статья и удостоилась перевода (почему бы и нет): Jmix — разработка компании Haulmont (офис в Лондоне, а головной — в Самаре), в чьём блоге и появился этот полезный перевод.
Возникает, однако, вопрос: но ведь поддержку JIT по умолчанию включили не в 14-й версии. Ещё в 2019-м Джонатан Кац (Jonathan S. Katz, Crunchy Data) пишет в Just Upgrade: How PostgreSQL 12 Can Improve Your Performance (а мы цитируем по переводу Апгрейд для ленивых: как PostgreSQL 12 повышает производительность в блоге Southbridge):
Раз JIT включен в PostgreSQL 12 по умолчанию, производительность улучшится сама по себе, но я советую потестить приложение в PostgreSQL 11, где только появился JIT, чтобы измерить производительность запросов и узнать, нужно ли что-нибудь настраивать [болд мой].
И тут напомню об полезной игрушке, придуманной Депешем (Hubert depesz Lubaczewski): Why upgrade PostgreSQL? Это веб-интерфейс, за которым генерится список изменений с версии X к версии Y. Но обратите внимание на окошечко справа: ключевые слова. Например, мы туда вписываем Jit by default, выбираем, допустим, 9.6 => 14.1 и получаем:
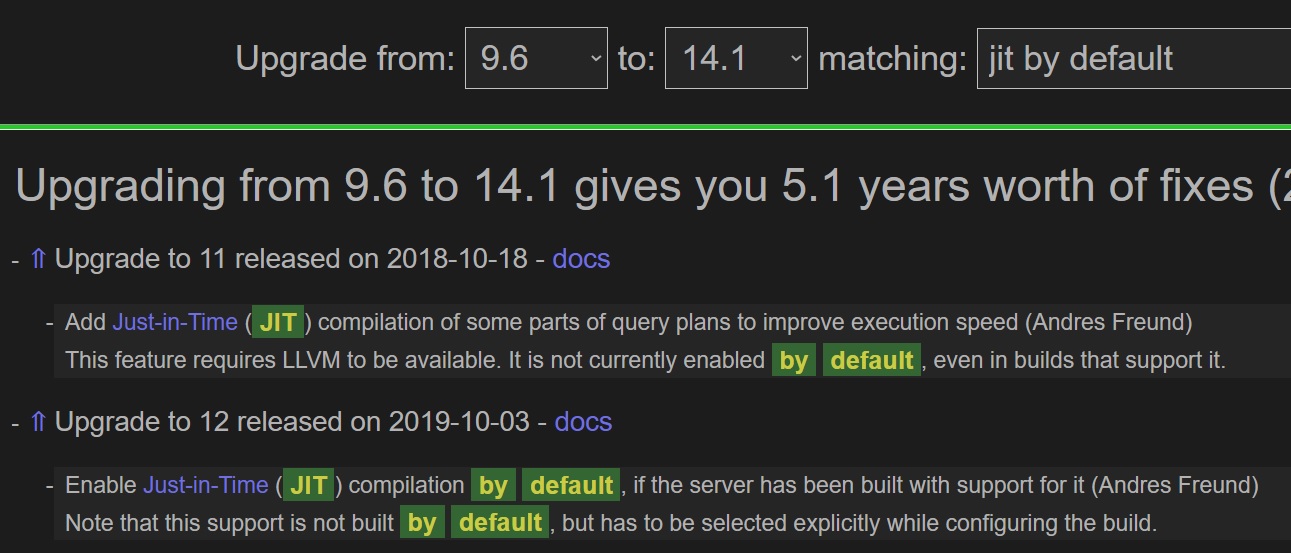
Разобравшись окончательно, видим: параметр jit появился в 11 версии и по умолчанию он был выключен, а в 12 версии умолчание изменили и параметр включили.
А на днях Депеш решил опубликовать output своего скрипта 9.6 => 14, и он выглядит впечатляюще: Upgrading from 10 to 14 gives you 4.0 years worth of fixes (1700 of them). И всё же (заодно) обратим внимание на эту маленькую заметку в Allow publishing the tables of schema в серии В ожидании PG15.
Персона недели — Павел Лузанов
Наблюдается этакое нашествие жителей и бывших жителей РФ в рубрике PostgreSQL-персона Недели: в прошлом выпуске мы радовались появлению там Ивана Панченко. Между Иваном и Лузановым там успел побывать Александр Кукушкин из Zalando (Германия). Не так давно ознакомились с предпочтениями Дмитрия Долгова (тоже Zalando), с доцентом в Уральском Федеральном Университете и разработчиком в Яндексе Андреем Бородиным, с глубоководным хобби и производственными пристрастиями Николая Самохвалова, с Анастасией Лубенниковой, славно поработавшей с нами (дедупликация индексов B-tree), успехов на новом месте!
А Паша — глава нашего отдела образования — это, извините, УРА!

Павел Лузанов изучал в Кемерово майнинг (но не сомнительный, современный, а настоящий — горнодобывающий), потом ушёл в ИТ. Сейчас читает и постгрессистам рекомендует читать книгу нашего коллеги Егора Рогова (выйдет под Новый Год).
— Что бы вы посоветовали разработчикам или пользователям PostgreSQL?
— Разработчикам серверной части я не берусь советовать. А вот разработчикам приложений и админам скажу. Самое важное, я думаю, вот что:
- надо уметь работать с документацией;
- не бойтесь экспериментировать;
- тем, кто только взялся работать с PostgreSQL, посоветую начинать с SQL. Не стоит сразу окунаться в конфигурацию, репликацию и прочее. Сначала научитесь писать запросы. Это вам пригодится и в работе с другими базами данных.
Ещё статьи
PostgreSQL 14: Часть 2 или «в тени тринадцатой» (Коммитфест 2020-09)
Павел Лузанов продолжает обозревать новые коммиты — на этот раз попавшие в Сентябрьский Коммитфест.
Егор Рогов (Отдел образования Postgres Professional) выложил все 7 частей новой серии — Запросы в PostgreSQL:
1. Этапы выполнения
2. Статистика
3. Последовательное сканирование
4. Индексное сканирование
5. Вложенный цикл
6. Хеширование
7. Сортировка и слияние
Herding elephants: Lessons learned from sharding Postgres at Notion
Гаррет Фидальго (Garrett Fidalgo, Notion, технический директор по инфраструктуре) рассказывает, как шардировали базу Postgres в его компании — некие пастухи собирали слонов в стадо, в его терминологии.
В этом году нам пришлось остановить доступ к нашему сайту на заранее запланированный 5-минутный перерыв. Невидимыми остались месяцы напряжённой, авральной работы нашей команды: мы переделывали монолитную базу PostgreSQL в горизонтально секционированный набор баз.
Разбивать базу решили не на основе готовых решений вроде Citus, а на уровне слоя-приложения — для большей управляемости. Действия пояснены наглядными схемками. В конце выводы задним числом из их умеренно горького опыта:
- шардируйте как можно раньше, не ждите, когда база будет работать под существенной нагрузкой;
- с самого начала закладывайте нулевое время простоя;
- используйте составной первичный ключ, а не отдельный ключ секционирования.
Useful queries to analyze PostgreSQL lock trees (a.k.a. lock queues)
Действительно полезные запросы, и их много. Для разминки Николай Самохвалов рекомендует для ознакомиться со статьями по теме. Близкий нам жанр, поэтому воспроизводим здесь с некоторой локализацией (статья Николая для англоязычной аудитории):
Официальная документация: Явные блокировки (Explicit Locking).
«И, как всегда, [а мы бы сказали last but not the least] подробные и углублённые объяснения по
блокировкам в сериале про блокировки Егора Рогова»:
Блокировки отношений (2019)
Блокировки строк) (2019). И ещё рекомендует запросы коллег:
Active Session History in PostgreSQL: blocker and wait chain Бертрана Друво (Bertrand Drouvot) — для тех кто использует расширение pgsentinel и
locktree.sql, получающий деревья блокирующих сессий из
pg_locks и pg_stat_activity Виктора Егорова.Сам Николай экспериментировал с функцией pg_locking_pids, но это следует делать аккуратно, не забывая про
statement_timeout.Релизы
PostgreSQL 14.1, 13.5, 12.9, 11.14, 10.19, and 9.6.24 Released!
Релиз плановый, но не последнее дело залатать обнаруженные дыры:
Если сервер использует для аутентификации клиентский сертификат, злоумышленник может организовать атаку по типу
a man-in-the-middle, двумя способами, описанными в CVE-2021-23214 и CVE-2021-23214/.С этого момента больше НЕ поддерживается версия 9.6!
Кстати: PostgreSQL End of Life
Зловещее название статьи мало кого испугает: все мы знаем, что PostgreSQL жив-здоров, может и нас всех переживёт в случае ухудшения эпидемической обстановки :) Речь, конечно, о 9.6 и вообще о жизненных циклах версий. Но дело не ограничивается констатацией печальной участи 9.6, предлагается ещё и самостоятельно прикинуть окончание поддержи вашей версии, запустив предложенный скрипт, см. Find End of Life PostgreSQL Installations.
Конференции
PGConf.ru 21
Она успешно завершилась и была почти столь же многолюдна, не смотря на эпидемию. Для тех, кто не смог предъявить QR-коды или привезти признанный в РФ сертификат о вакцинации, установили столики, где девушки из Медицинского делали экспресс-тесты. Все доклады уже общедоступны в виде слайдов, а все видео будут доступны в скором времени.
Вот отчёт о конференции, появившийся на сайте Интерфакса:
В Москве состоялась международная конференция разработчиков PostgreSQL.
Infostart Event 2021 Moscow Premiere
Таково полное название конференции, прошедшей 11-12 ноября в Москве, в кинотеатре «Октябрь» — 11-я конференция по управлению и автоматизации учета на платформе 1С: Предприятие, которая впервые пройдет в Москве и соберет 1000 + участников из разных регионов России и мира.
На сайте в меню есть пункт купить видео. Вот некоторые доклады по постгресовой тематике (и не только):
Антон Дорошкевич, ИнфоСофт: Секционирование таблиц — зло или благо?
Иван Панченко, Postgres Professional, замгендир: Postgres 14: что он даст для 1С? (хорошие новости)
Олег Бартунов & Иван Панченко, Postgres Professional, гендир & замгендир «Астроликбез для айтишников» (вообще хит сезона, доклад читался на разных ивентах с неизменным успехом. Олег к тому же сотрудник ГАИШ МГУ, создатель astronet.ru, а Иван соавтор лучшей книги года: Неизвестное Солнце. Расследование. Чудеса. Факты. Загадки)
Олег Филиппов, WiseAdvice, CTO: Масштабирование 1С в облачной среде (Postgresql tablespaces & table partitioning, шардинг (имитация map-reduce через fdw), о cloud native, slony, citus, greenpulm).
и как не упомянуть:
Сергей Зырянов, «Нативи», директор: Как нейросеть помогла ускорить процесс загрузки 40 тысяч фотографий в базу 1С («Зачем в 1С нужны фотографии товаров? Спойлер: не нужны»).
Комментарии (4)

x4m
26.11.2021 12:37с профессором Уральского Федерального Университета и разработчика в Яндексе Андреем Бородиным
К сожалению, я пока только доцент в УрФУ, просто перевожу на английский как Associate Professor :) Докторская лежит на полке 4 год...

RainbowJose
Невозможно читать
boris768
обфуцированный перевод гугл транслейта, или что-то вроде этого