
SELinux, как и все средства безопасности, снижает производительность системы. И хотя для большинства рабочих нагрузок такое влияние невелико (см., например, проведенное порталом Phoronix тестирование на примере платформы Fedora 31), некоторые операции, как выяснилось, могут выполняться быстрее. Кроме того, в SELinux есть определенные шероховатости, неоправданно увеличивающие размер образов виртуальных машин или требования по оперативной памяти. Сегодня мы расскажем о недоработках в SELinux, которые нашел, устранил и закоммитил наш инженер-программист, который работает в команде Red Hat, занимающейся SELinux.
В совокупности, все эти доработки позволили добиться следующих улучшений на тестовой системе Fedora (ее конфигурация приводится ниже):
Сократить время загрузки SELinux-политики в ядро с ~1.3 секунд до ~106 милисекунд (в 12 раз).
Сократить время пересборки SELinux-политики из модулей с ~21.9 до ~5.7 секунд (в 3.8 раз).
Уменьшить размер финального двоичного файла SELinux-политики с 7.6 до 3.3 МБ (в 2.3 раза).
Уменьшить ОЗУ-оверхед SELinux с ~30 МБ до ~15 МБ.
Сократить время создания файла с включенной SELinux с ~55 до ~44 микросекунд (в 1.25 раза).
Эти улучшения постепенно были внедрены на уровне ядра Linux версий 5.7–5.9 (те, что относятся к ядру) и на уровне инструментов пространства пользователя SELinux версии 3.2 (те, что относятся к пространства пользователя). Соответствующие улучшения на уровне ядра впервые появились в Fedora 32, а улучшения пространства пользователя – в Fedora 34. Планируется, что все они по наследству перейдут из Fedora в RHEL 9 и следующих версий, а некоторые из них уже появились в RHEL 8.
Приведенные в этой статье результаты производительности уровня ядра были получены на облачной виртуалке Fedora x86_64 на процессоре Intel Xeon 2 ГГц и с 2 ГБ оперативной памяти, а результаты по пространству пользователя – на физическом сервере Fedora x86_64 на процессоре Intel Core i7-8665U 1.9-4.8 ГГц и с 32 ГБ оперативной памяти. Если вы решите провести аналогичные измерения самостоятельно, то результаты могут отличаться.
Улучшения на уровне ядра
Переходы – быстрее и с меньшим расходом памяти
Со временем в SELinux-политике Fedora/RHEL накопилось довольно много так называемых именованных переходов типа (named type transitions). По сравнению с обычными правилами перехода они позволяют учитывать также имя создаваемого объекта (в дополнение к типу процесса, типу родительского объекта и классу объекта) при вычислении типа SELinux для вновь создаваемого объекта (обычно файла или каталога).
Фактически, именованных переходов стало так много, что ядро стало использовать заметно больше памяти, к тому же увеличился размер двоичного файла политики (подробнее см. BZ 1660142).
Большинство правил именованного перехода относились к узлам /dev, чтобы те получали правильную маркировку. И хотя многие из этих правил, скорее всего, не используются на практике, трудно сказать, какие из них можно безопасно удалить. Поэтому было решено оптимизировать то, как хранятся эти правила, причем, как в двоичном файле политики, так и в оперативной памяти, при загрузке в ядро.
Проблема с именованными переходами заключается в том, что их внутреннее представление не очень эффективно. Когда они вводились, их предполагалось использовать только в редких случаях, поэтому разработчики пошли по пути самого простого решения.
Анализ имеющихся в политике правил показал, что если сгруппировать все правила именованного перехода, которые есть в политике Fedora (по типу цели, по классу цели, по имени объекта), то всегда получаются правила с одним или несколькими различными типами источников, но только с одним типом результата.
Поэтому здесь можно выполнить оптимизацию, заменив сопоставление ключей (исходный тип, целевой тип, класс, имя) с типами результатов на сопоставление ключей (целевой тип, класс, имя) со списком, связывающим набор исходных типов с соответствующим типом результата.
На первом этапе было изменено внутреннее представление на уровне ядра (см. правку в ядро Linux c3a276111ea2 ("selinux: optimize storage of filename transitions")), что уже дало заметные улучшения:
Загрузка политики ускорилась с ~1.3 до ~0.95 секунд.
Kernel-подсистема SELinux стала занимать в памяти не ~30 МБ, а ~15 МБ.
Время создания файла (включая поиск в таблице именованных переходов типов) сократилось с ~55 до ~40 микросекунд.
На следующем этапе был доработан уже сам двоичный формат хранения политик, чтобы задействовать их новое представление. Здесь потребовалось обновить как ядро Linux, так и инструменты пространства пользователя, чтобы они могли работать с новым форматом (см. коммиты 430059024389 (kernel), 42ae834a7428 (user space) и 8206b8cb0039 (user space). Это дополнительно улучшило результаты (все приведенные ниже цифры достигнуты на текущей на момент тестирования версии Fedora Rawhide):
Время загрузки политики сократилось с ~157 до ~106 миллисекунд.
Эти заметно меньше, чем цифры на предыдущем этапе, поскольку по ходу был реализован целый ряд других улучшений (см. ниже).Размер двоичного файла политики Fedora сократился с 7.6 МБ до 3.3 МБ.
Как следствие, размер RPM-пакета selinux-policy-targeted уменьшился с 8.0 МБ до 6.2 МБ (здесь разница меньше из-за сжатия файлов и наличия в пакете других компонентов).
Оптимизация размеров внутренних хэш-таблиц
Подсистема SELinux в ядре Linux активно использует хэш-таблицы, когда работает с политикой. И почти все эти хэш-таблицы имеют жестко запрограммированный размер, вместо того, чтобы варьировать его, исходя из количества записей. Причем, жестко заданные размеры зачастую меньше оптимальных, что снижает производительность операций, в основном, при загрузке политики.
Поскольку почти во всех случаях количество элементов было известно заранее, до добавления записей, и эти записи никогда не удалялись, то создать соответствующий патч было легко.
В результате, массивы хэш-таблиц во многих случаях стали больше (при загрузке политики Fedora на платформе x86_64), но на фоне общего размера SELinux итоговый перерасход памяти от этого оказался мизерным: массивы выросли с ~58 КБ до ~163 КБ.
Более быстрый поиск ролевых переходов
После оптимизации именованных переходов оставалась еще одна вещь, сильно замедлявшая выполнение смены контекста SELinux. С момента своего появления ролевые переходы (role transitions) хранились в виде простого связанного списка. И это было узким местом, поскольку, когда в связанных списках становится чуть больше элементов, они начинают замедлять поиск. Политика Fedora содержит более 400 переходов ролей, и поиск был очень неэффективным.
Поэтому здесь просто напрашивалась замена связанных списков на хэш-таблицы, что и было реализовано в коммите e67b2ec9f617.
Это позволило практически вдвое сократить время перехода контекста SELinux и, теоретически, должно улучшить показатели создания новых файлов и выполнения файла.
Более быстрая работа с хэш-таблицами за счет встраивание при компиляции
Еще одно улучшение было достигнуто за счет перемещения части определения функций хэш-таблицы SELinux в заголовочный файл, чтобы компилятор мог встраивать их и генерировать более эффективный код. В частности, это позволило превратить несколько косвенных вызовов в прямые, что было особенно важно при устранении уязвимостей Spectre/Meltdown.
Это улучшение вошло в состав коммитов 24def7bb92c1 и 54b27f9287a7 и обеспечило дополнительное ускорение при загрузке политики, при переходах контекста и при парсинге контекстов SELinux из строкового представления.
Более быстрое обновление политики SELinux
Другой вектор улучшения производительности касался операции по пересборке политики в пространстве пользователя(в основном это происходит, когда вы запускаете semodule -B или semodule -B)
Раньше эта операция занимала более чем 20 секунд на Fedora x86_64. И это весьма ощутимая задержка, поскольку пересборка выполняется каждый раз, когда обновляется, устанавливается или удаляется selinux-policy или другой пакет политики SELinux (например, container-selinux). Или когда пользователь выполняет настройки политики SELinux (например, устанавливает или удаляет кастомный модуль политики, либо выполняет изменение булевой переменной SELinux в постоянном режиме).
Избавление от мертвого кода
При выяснении причин медленной пересборки политики внезапно обнаружилось, что она происходит значительно быстрее, когда используется самая новая на тот момент версия исходного кода для пространства пользователя SELinux, а не штатная версия, которая была в Fedora в то время.
Оказалось, что причина в том, что в этот снимок вошел патч, который всего лишь удалял мертвый код. Этот код создавал хэш-таблицы, которые затем не использовались, но на заполнение этих таблиц уходило около половины (!) всего времени сборки политики. То есть, если раньше на выполнение команды semodule -NB (опция -N означает пропуск загрузки политики в ядро) уходило ~21,9 секунды, то теперь всего ~9,4 секунды.
Профилирование с помощью Callgrind и KCachegrind
Для анализа того, что занимает больше всего времени при вызове semodule -B, использовался CLI-инструмент Callgrind, входящий в состав известной коллекции Valgrind, который помогает понять, на выполнение каких функций ваша программа на Си/Си++ тратит больше всего времени. В свою очередь, KCachegrind – это GUI для визуализации данных, собранных с помощью Callgrind и Cachegrind (это еще один инструмент отладки производительности, позволяющий оценить эффективность использования процессорного кэша).
Например, проанализировать semodule-NB можно так:
LD_BIND_NOW=1 valgrind --tool=callgrind semodule -NBОпция LD_BIND_NOW=1 говорит загрузчику динамических библиотек загружать все библиотеки при запуске, поскольку используемая по умолчанию отложенная загрузка искажает данные производительности.
На выходе получится файл callgrind.out, который затем можно открыть в KCachegrind для дальнейшего анализа. Обратите внимание, что если запускать профилированную программу от имени root, то затем надо будет использовать команду chown, чтобы переключиться на владельца и группу выходного файла и иметь доступ к нему, как обычный пользователь.
А вот и главный тормоз!
После создания начального шаблона профилирования стало понятно, что есть одна функция, на которую тратится почти половина времени (приблизительно, исходя из счетчика загрузки инструкций), хотя вызывается она нечасто. И это функция ebitmap_cardinality(), которая входит в библиотеку libsepol. При дальнейшем изучении выяснилось, что эта функция реализована не только простым, но и крайне неэффективным способом.
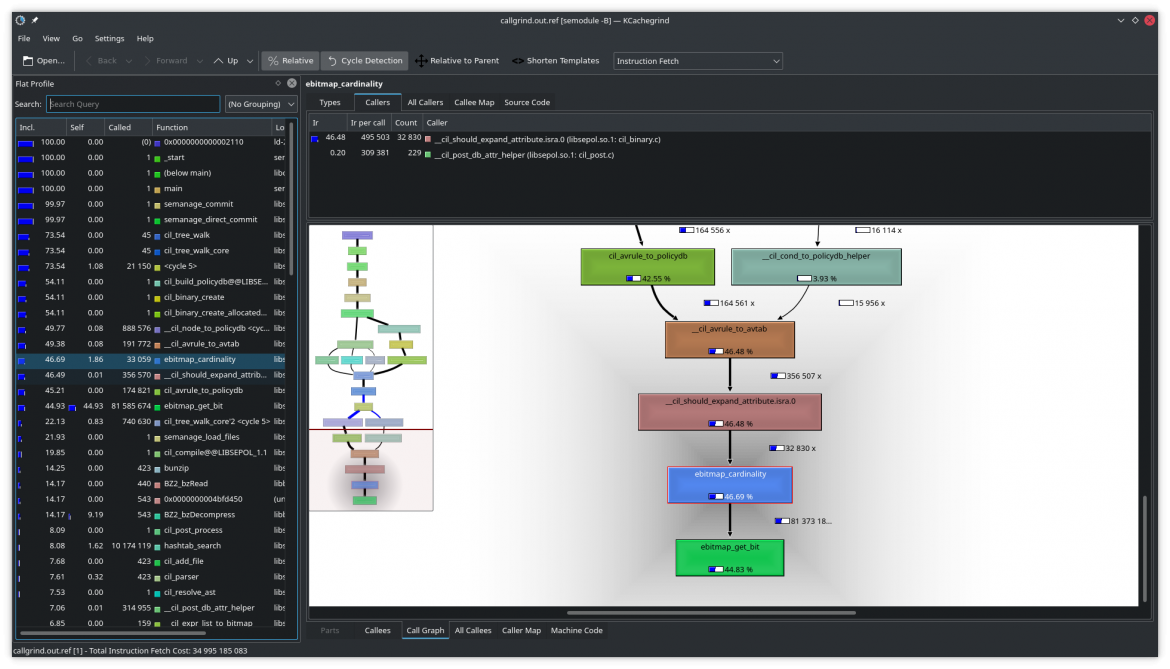
В результате оптимизации этой функции, удалось ускорить выполнение semodule -NB с ~9.4 до to ~8.0 секунд.
Автоматическое увеличение размера хэш-таблиц
Еще одна вещь, которая обнаружилась при профилировании и легко поддавалась исправлению – это плохая производительность хэш-таблиц. Как и в случае ядра, реализация хэш-таблиц в пространстве пользователя имела фиксированные и зачастую жестко запрограммированные размеры, что снижало производительности операций вставки и поиска, если фактическое количество элементов было больше заданного.
Поскольку в пространстве пользователя хэш-таблица реализует удаление элементов, а размер не всегда известен в момент создания, было решено реализовать простой авторесайзинг, когда количество элементов становится больше текущего размера таблицы. Для этого потребовалось изменить только общий код хэш-таблицы, что уместилось в совсем небольшом патче.
После этого небольшого трюка, время выполнения semodule -NB сократилось с ~8.0 до ~6.3 seconds.
Более быстрая оптимизация правил политики
И последнее узкое место, которое выявилось при профилировании, касалось функционала «оптимизации двоичного файла политики». Этот функционал представляет собой опциональный шаг при компиляции политики, в ходе которого из этого файла удаляются избыточные правила (в основном, чтобы уменьшить размер файла).
Оптимизация здесь заключалась в более эффективной реализации структуры данных «набор чисел», которая применяется для хранения некоторых вспомогательных данных, (подробнее здесь)
В итоге это дополнительно ускорило выполнение semodule -NB с ~6.3 до ~5.7 секунд.
Вывод
Подытоживая приведенные выше примеры оптимизации, можно сказать, что не стоит воспринимать проблемы производительности как данность. Если уделить им определенное время, то высок шанс, что многие из них можно устранить малой кровью, особенно если в проекте есть много унаследованного кода. А найти узкие места помогут такие связки инструментов анализа производительности, как Callgrind + KCachegrind или perf + FlameGraph.