

Привет, друзья!
Представляю вашему вниманию вторую часть перевода этой замечательной книги по WebRTC. Данная часть посвящена безопасности, процессу установки соединения и обмену медиаданными (части 4-6 оригинала).
Ссылка на первую часть перевода.
Если вам это интересно, прошу под кат.
Содержание этой части
-
Безопасность
-
Коммуникация в реальном времени
- Какие атрибуты делают сети сложными?
- Перегрузка
- Динамичность
- Решение проблемы потери данных
- Acknowledgments
- Selective Acknowledgments
- Negative Acknowledgments
- Forward Error Correction
- Решение проблемы джиттера
- Определение перегрузки
- Решение проблемы перегрузки
- Снижение скорости передачи данных
- Уменьшение количества передаваемых данных
-
Обмен медиаданными
- Как это работает?
- Задержка против качества
- Ограничения реального мира
- Видео является сложным
- Video 101
- Сжатие с потерей и без потери качества
- Внутри и межкадровое сжатие
- Типы межкадрового сжатия
- Видео является деликатным
- RTP
- Формат пакета
- RTCP
- Формат пакета
- Полный запрос INTRA-frame (FIR) и Picture Loss Indication (PLI)
- Негативные подтверждения
- Отчеты отправителя и получателя
- Как RTP/RTCP решают проблемы вместе?
- Forward Error Correction
- Адаптивная оценка битрейта и пропускной способности
- Идентификация и передача состояния сети
- Отчеты отправителя/получателя
-
TMMBR, TMMBN, REMB и TWCC в сочетании с GCC
- TMMBR, TMMBN и REMB
- Transport Wide Congestion Control
- Другие способы оценки пропускной способности
Безопасность
Каждое соединение WebRTC аутентифицируется и шифруется. Это позволяет быть уверенным в том, что третья сторона не видит того, что мы отправляем, и не может добавлять (вставлять) фиктивные сообщения. Также можно быть уверенным, что агент, генерирующий описание сессии — это действительно тот, с кем мы хотим общаться.
Очень важно, чтобы никто не мог подменять сообщения. Не страшно, если третья сторона прочитает описание сессии во время передачи. Однако, WebRTC не предоставляет защиты от ее модификации. Злоумышленник может осуществить атаку "человек посередине" (атака посредника) путем подмены кандидатов ICE и обновления отпечатка сертификата.
Как это работает?
Для обеспечения безопасности соединения WebRTC использует 2 существующих протокола: DTLS и SRTP.
DTLS позволяет выполнять подготовку сессии и безопасно обмениваться данными между пирами. Он похож на TLS, который используется в HTTPS, но в качестве протокола транспортного уровня DTLS использует UDP вместо TCP. Это означает, что DTLS не гарантирует надежную доставку сообщений. SRTP был специально разработан для безопасного обмена медиаданными. Он предоставляет несколько оптимизаций по сравнению с DTLS.
Сначала используется DTLS. Он выполняет рукопожатие через соединение ICE. DTLS — это клиент-серверный протокол, поэтому одна из сторон должна инициировать рукопожатие. Роли "клиент/сервер" определяются в процессе сигнализации. В ходе рукопожатия DTLS каждая сторона генерирует сертификат. После завершения рукопожатия каждый сертификат сравнивается с его хешем, содержащимся в описании сессии. Это позволяет убедиться в том, что рукопожатие произошло с ожидаемым агентом. Затем соединение DTLS может использоваться для коммуникации с помощью DataChannel.
Для создания сессии SRTP мы инициализируем ее с помощью ключей, сгенерированных DTLS. SRTP не предоставляет механизма рукопожатия, поэтому подготовка соединения осуществляется с помощью внешних ключей. После установки SRTP-соединения стороны могут обмениваться зашифрованными медиаданными.
Security 101
Давайте познакомимся с терминами, употребляемыми в криптографии.
Обычный текст и зашифрованный текст
Обычный текст (plaintext) — это входные данные для шифрования. Зашифрованный текст (ciphertext) — это результат шифрования.
Шифрование
Шифрование (шифр, cipher) — это последовательность операций по преобразованию обычного текста в зашифрованный. Шифр может быть сохранен для последующей расшифровки зашифрованного текста. Как правило, шифр имеет ключ, меняющий его поведение. Данный процесс также называется encrypting (шифрование) и decrypting (расшифровка).
Примером простого шифра является ROT13. Каждая буква исходного текста сдвигается на 13 символов вперед. Для расшифровки каждая буква сдвигается на 13 символов назад. Обычный текст HELLO становится зашифрованным текстом URYYB. В данном случае шифр — это ROT, а ключ — 13.
Хеш-функции
Хеш-функция (hash function) — это необратимый (однонаправленный) процесс преобразования входных данных в хеш (digest — фарш, мешанина). Для одних и тех же входных данных всегда получается одинаковый результат. Важно, чтобы результат был необратимым. Результат не должен позволять определить входные данные. Хеширование позволяет убедиться в том, что сообщение не было подменено.
Простой функцией хеширования будет функция, пропускающая каждую вторую букву. HELLO станет HLO. Мы не можем "вернуться" к HELLO, но мы можем убедиться, что HELLO совпадает с хешем.
Публичные и приватные ключи
Криптография на основе публичного/приватного ключей (public/private key) описывает тип шифрования, используемого DTLS и SRTP. В такой системе у нас имеется два ключа: публичный (открытый) и приватный (закрытый). Публичный ключ используется для шифрования и его можно передавать другим лицам. Приватный ключ используется для расшифровки и должен быть известен только нам. Расшифровать зашифрованное сообщение можно только с помощью соответствующего приватного ключа.
Протокол Диффи-Хеллмана
Протокол Диффи — Хеллмана (Diffie–Hellman Protocol) позволяет двум пользователям, которые никогда не встречались, безопасно создавать общие секреты через Интернет. Пользователь A может отправлять секреты пользователю B, не опасаясь прослушки (eavesdropping). Это зависит от сложности решения проблемы дискретного логарифмирования. Это делает возможным рукопожатие DTLS.
Псевдослучайная функция
Псевдослучайная функция (Pseudorandom Function, PRF) — предварительно определенная функция, генерирующая значения, которые на первый взгляд кажутся случайными. Она может принимать несколько входных значений и генерировать один результат.
Функция формирования ключа
Формирование (деривация) ключа (key derivation) — это разновидность псевдослучайной функции. Данная функция используется для усиления ключа. Одним из наиболее распространенных паттернов является растяжка (растяжение) ключа (key stretching).
Предположим, что у нас имеется ключ размером 8 байтов. Мы можем использовать KDF для того, чтобы сделать его сильнее (длиннее).
Однократно используемое число
Однократно используемое число (nonce) — это дополнительные входные данные для шифрования. Оно используется для получения разных результатов при шифровании одного и того же сообщения. Для каждого сообщения используется уникальный nonce.
Код аутентификации сообщения
Код аутентификации сообщения (message authentication code) — это хеш, помещаемый в конец сообщения. MAC позволяет идентифицировать источник сообщения.
Ротация ключей
Ротация ключей (key rotation) — это практика периодической замены ключей. Это позволяет снизить ущерб от возможной кражи (утечки) ключа, т.е. добиться того, что украденный или раскрытый другим способом ключ может использоваться для расшифровки лишь ограниченного количества сообщений.
DTLS
DTLS позволяет двум пирам устанавливать безопасное соединение без предварительной настройки. Даже если кто-то будет прослушивать соединение, он не сможет расшифровать сообщения.
Для того, чтобы коммуникация между клиентом и сервером DTLS, стало возможной, они должны прийти к соглашению о шифре и ключе. Эти значения определяются в процессе рукопожатия. В ходе рукопожатия сообщения представлены в виде обычного текста. После того, как клиент или сервер обменяются достаточным количеством информации для начала шифрования, отправляется Change Cipher Spec. После этого все последующие сообщения подвергаются шифрованию.
Формат пакета
Каждый пакет DTLS начинается с заголовка.
Тип содержимого
Тип содержимого (content type) может быть одним из:
-
20—Change Chipher Spec; -
22— рукопожатие (Handshake); -
23— данные приложения (Application Data).
Handshake используется для обмена информацией, необходимой для начала сессии. Change Chipher Spec используется для уведомления другой стороны о начале шифрования сообщений. Application Data — это сами зашифрованные сообщения.
Версия
Версия (version) может иметь значение 0x0000feff (для DTLS v1.0) или 0x0000fefd (для DTLS v1.2). Версии 1.1 не существует.
Эпоха
Эпоха (epoch) начинается с 0 и принимает значение 1 после Change Chipher Spec. Любые сообщения с "ненулевой эпохой" зашифровываются.
Последовательный номер
Последовательный номер (sequence number) используется для сохранения порядка сообщений. При каждой отправке сообщения данный номер увеличивается. При увеличении эпохи, данный номер обнуляется.
Длина сообщения и полезная нагрузка
Полезная нагрузка (payload) — это конкретный тип содержимого. Для Application Data полезной нагрузкой являются зашифрованные данные. Для Handshake полезная нагрузка зависит от вида сообщения. Длина сообщения (length) определяет размер полезной нагрузки.
Рукопожатие
В процессе рукопожатия клиент и сервер обмениваются серией сообщений. Эти сообщения группируются в пакеты (flights). Каждый пакет может содержать несколько сообщений или только одно. Пакет считается полученным только после доставки всех содержащихся в нем сообщений. Далее мы рассмотрим назначение каждого сообщения.
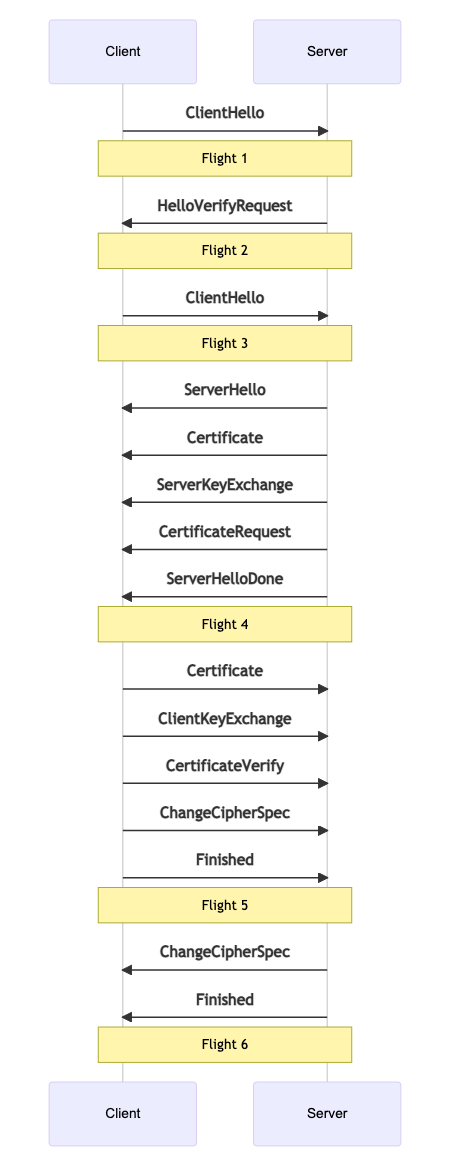
ClientHello
ClientHello — это начальное сообщение от клиента. Оно содержит перечень атрибутов. Эти атрибуты сообщают серверу шифр и возможности, поддерживаемые клиентом. Данный шифр также используется в качестве шифра SCTP. ClientHello также содержит случайные данные, которые впоследствии используются для генерации ключей сессии.
HelloVerifyRequest
HelloVerifyRequest — это сообщение от сервера клиенту. Оно позволяет убедиться, что клиент действительно имел намерение отправить ClientHello. После этого клиент снова отправляет ClientHello, но уже с токеном из HelloVerifyRequest.
ServerHello
ServerHello — это ответ сервера с настройками сессии. Он содержит шифр и случайные данные.
Certificate
Certificate содержит сертификат для клиента или сервера. Сертификат используется для идентификации другой стороны коммуникации. После окончания рукопожатия мы проверяем, что хеш сертификата совпадает с его отпечатком в SessionDescription.
ServerKeyExchange/ClientKeyExchange
Эти сообщения используются для передачи публичного ключа. При инициализации клиент и сервер генерируют пару ключей. После рукопожатия эти значения используются для генерации Pre-Master Secret.
CertificateRequest
CertificateRequest — сообщение от сервера клиенту о желании первого получить сертификат. Сервер может просить (request) или требовать (require) получение сертификата.
ServerHelloDone
ServerHelloDone уведомляет клиента о завершении рукопожатия сервером.
CertificateVerify
CertificateVerify — так отправитель подтверждает наличие у него приватного ключа из сообщения с сертификатом.
ChangeCipherSpec
ChangeCipherSpec информирует получателя о том, что последующие сообщения будут зашифрованными.
Finished
Finished является зашифрованным и содержит хеш всех предыдущих сообщений. Это позволяет убедиться в отсутствии модификации рукопожатия.
Генерация ключей
После завершения рукопожатия мы можем отправлять зашифрованные данные. Шифр выбирается сервером и содержится в его ServerHello. Но как выбирается ключ?
Сначала мы генерируем Pre-Master Secret. Для получения этого значения используется протокол Диффи-Хелмана для ключей, обмениваемых с помощью ServerKeyExchange и ClientKeyExchange. Детали зависят от выбранного шифра.
Затем генерируется Master Secret. Каждая версия DTLS имеет определенную псевдослучайную функцию. Для DTLS v1.2 функция "берет" Pre-Master Secret и случайные значения из ClientHello и ServerHello. Результатом выполнения псевдослучайной функции является Master Secret. Master Secret — это значение, которое используется для шифра.
Обмен данными
Рабочей лошадкой DTLS является ApplicationData. После получения инициализированного шифра мы можем шифровать и передавать сообщения.
Сообщения ApplicationData используют заголовок DTLS, как описывалось ранее. Payload заполняется зашифрованным текстом. Теперь у нас имеется сессия DTLS и мы можем общаться безопасно.
SRTP
SRTP — это протокол, разработанный специально для шифрования пакетов RTP. Для начала сессии SRTP необходимо определить ключи и шифр. В отличии от DTLS здесь у нас нет механизма рукопожатия. Все настройки и ключи генерируются в ходе рукопожатия DTLS.
DTLS предоставляет отдельный API для экспорта ключей с целью их использования в других процессах. Данный API определяется в RFC 5705.
Создание сессии
SRTP определяет функцию деривации ключей, которая применяется в отношении входных данных. При создании сессии SRTP входные данные пропускаются через эту функцию для генерации ключей для шифра SRTP. После этого можно переходить к обработке данных.
Обмен медиаданными
Каждый пакет RTP имеет 16-битный SequenceNumber (последовательный номер). Этот номер используется для сохранения правильного порядка доставки пакетов (последовательные номера напоминают первичные ключи — primary keys). В ходе сессии этот номер автоматически увеличивается. Для этого используется специальный счетчик (rollover counter).
При шифровании пакета SRTP использует счетчик и последовательный номер в качестве одноразового значения (nonce). Это позволяет добиться того, что даже при повторной отправке сообщения, его зашифрованный текст будет разным. Это защищает от идентификации паттерна атакующим, а также от выполнения повторной атаки.
Коммуникация в реальном времени
Сети — это ограничительный фактор для коммуникации в реальном времени. В идеальном мире размер передаваемых данных неограничен и пакеты доставляются мгновенно. В реальном мире это не так. Возможности сетей являются ограниченными, условия могут измениться в любое время. Измерение и мониторинг сетей также представляет собой сложную задачу. Мы получаем разное поведение в зависимости от "железа", программного обеспечения и их настроек.
В случае с коммуникацией в реальном времени существует еще одна проблема, которой нет в других средах. Для разработчика медленная работа сайта в некоторых сетях не является серьезной проблемой. До тех пор, пока все данные приходят, пользователи счастливы. Однако в WebRTC "старые" данные являются бесполезными. Никого не интересует, что было сказано на конференции пять секунд назад. Поэтому при разработке систем, работающих в режиме рального времени, зачастую приходится выбирать между задержкой в передаче и размером передаваемых данных.
Какие атрибуты делают сети сложными?
Код, который эффективно работает во всех сетях, является сложным. Необходимо учитывать множество разных факторов, которые могут неочевидным образом влиять друг на друга. Ниже представлен список наиболее общих задач, с решением которых сталкиваются разработчики.
Пропускная способность
Пропускная способность (bandwidth) — это количество данных, которые можно передать по сети. Важно понимать, что данная величина не является постоянной. Пропускная способность зависит от нагрузки, т.е. от количества людей, использующих этот маршрут (роут).
Время передачи и время в пути туда и обратно
Время передачи (transmission time) — это время достижения пакетом пункта назначения. Как и пропускная способность, это значение не является константным. Время передачи может меняться в ходе сессии.
transmission_time = receive_time - send_timeДля расчета время передачи нам нужны часы на стороне отправителя и получателя, синхронизированные с точностью до миллисекунд. Даже небольшая разница может привести к ненадежному измерению времени. Поскольку WebRTC функционирует в высокогетерогенных средах, достижение совершенной синхронизации между хостами является почти невозможным.
Время туда и обратно (round trip time) — это попытка решения проблемы синхронизации.
Вместо использования распределенных часов пир WebRTC отправляет специальный пакет, содержащий время в sendertime1. Второй пир получает пакет, фиксирует время и отправляет пакет обратно. После получения пакета отправителем, он вычитает время, записанное в sendertime1, из текущего времени sendertime2. Эта разница во времени называется временем в пути туда и обратно.
rtt = sendertime2 - sendertime1Половина времени туда и обратно считается хорошим приближением времени передачи. Этот подход имеет некоторые недостатки. При его использовании мы исходим из предположения, что отправка и получение пакета занимают равное время. Однако в сотовых сетях операции по отправке и получению могут быть несимметричными по времени. Вы могли замечать, что скорость передачи данных на телефоне почти всегда меньше скорости загрузки данных.
transmission_time = rtt/2Технические детали измерения времени туда и обратно подробно описаны в следующем разделе.
Джиттер
Причиной джиттера (jitter) является разное время передачи пакетов. Пакеты могут запаздывать и прибывать группами.
Потеря пакетов
Потеря пакетов (packets loss) — это когда сообщения теряются при передаче, т.е. не доходят до адресата. Потеря может быть постоянной или случайной. Это может быть связано с типом сети, например, спутниковая или Wi-Fi. Это также может быть связано с ПО, встретившимся на пути сообщения.
Максимальная единица передачи
Максимальная единица передачи (maximum transmission unit) — это максимальный размер единичного пакета. Сети не позволяют отправлять одно гигантское сообщение. На уровне протокола сообщения разбиваются (split) на более мелкие пакеты.
MTU также различается в зависимости от выбранного маршрута. Для определения MTU можно использовать протокол Исследования MTU по пути.
Перегрузка
Перегрузка (congestion) возникает при достижении лимитов сети. Обычно, это связано с достижением предельной пропускной способности текущего роута. Или это может быть связано с временными ограничениями, накладываемыми вашим Интернет-провайдером.
Перегрузка проявляется по-разному. Не существует стандартного поведения. В большинстве случаев при возникновении перегрузки лишние пакеты начинают игнорироваться. В других случаях происходит буферизация. Это приводит к увеличению времени передачи. В перегруженных сетях также можно наблюдать усиление джиттера. Все, о чем мы тут говорим, – быстро развивающаяся сфера и в ней продолжают появляться новые алгоритмы для определения перегрузки.
Динамичность
Сети являются невероятно динамичными, их условия меняются очень быстро. Во время звонка мы можем отправлять и получать сотни тысяч пакетов. Эти пакеты будут проходить через несколько переходов (посредников, ретрансляторов) (hops). Эти переходы будут распределены между миллионами других пользователей. Даже в локальной сети мы можем загружать фильм в формате HD или наше устройство может загружать обновление во время звонка.
Поддержка стабильности звонка является не такой простой задачей, как исследование сети при инициализации. Необходимо проводить постоянные вычисления. Также необходимо учитывать все факторы, на которые оказывают влияние сетевое "железо" и ПО.
Решение проблемы потери данных
Потеря пакетов — это первая задача, которую необходимо решить при разработке системы коммуникации в реальном времени. Существует множество способов это сделать, каждый со своими плюсами и минусами. Это зависит от того, что мы отправляем и насколько критичной является задержка. Также следует отметить, что не всякая потеря является фатальной. Потеря незначительного количества видеоданных будет незаметна для человеческого глаза. Однако потеря текста сообщения является фатальной.
Предположим, что мы отправили 10 пакетов и пакеты 5 и 6 были потеряны. Давайте разберем, как можно решить эту проблему.
Acknowledgments
Acknowledgments (подтверждения) — это способ, которым получатель сообщает отправителю о получении каждого пакета. Отправитель узнает о потере пакета при получении повторного подтверждения о пакете, который не является последним. Когда отправитель получает ACK для пакета 4 дважды, он понимает, что пакет 5 был потерян.
Selective Acknowledgments
Selective Acknowledgments (выборочные подтверждения) — это улучшение обычных подтверждений. Получатель может отправить SACK с подтверждениями для нескольких пакетов и таким образом уведомить отправителя о потере пакетов. Отправитель получает SACK для пакетов 4 и 7 и понимает, что пакеты 5 и 6 были потеряны. В ответ он повторно отправляет потерянные пакеты.
Negative Acknowledgments
Negative Acknowledgments (негативные подтверждения) решают проблему противоположным образом. Вместо уведомления отправителя о полученном, получатель уведомляет его о том, что было потеряно. В нашем случае NACK отправляется для пакетов 5 и 6. Отправитель знает только о пакетах, которые необходимо отправить повторно.
Forward Error Correction
Forward Error Correction (превентивное исправление ошибок) пытается решить проблему потери данных заблаговременно. Отправитель отправляет дополнительные данных, чтобы потеря пакетов не повлияла на результат. Одним из примеров FEC является код Рида-Соломона.
Это уменьшает задержку/сложность отправки и получения подтверждений. FEC является пустой тратой полосы пропускания в случае, если потеря данных в сети близка к нулю.
Решение проблемы джиттера
Джиттер присутствует в большинстве сетей. Даже внутри LAN у нас много устройств, отправляющих данные с разной скоростью. Вы можете легко увидеть джиттер, "пропинговав" (pinging) другое устройство с помощью команды ping, и наблюдая за флуктуациями, происходящими во время пути туда и обратно (rtt).
Для преодоления джиттера клиенты используют JitterBuffer. Он обеспечивает постоянную скорость доставки пакетов. Недостатком является задержка, которую JitterBuffer добавляет к пакетам, которые прибыли слишком рано. А его преимущество в том, что опоздавшие пакеты не вызывают джиттер. Представьте, что в течение звонка вы видите такое время прибытия пакетов:
* time=1.46 ms
* time=1.93 ms
* time=1.57 ms
* time=1.55 ms
* time=1.54 ms
* time=1.72 ms
* time=1.45 ms
* time=1.73 ms
* time=1.80 msВ данном случае хорошим выбором будет 1,8 мс. Пакеты, которые будут прибывать позднее, смогут использовать наше окно задержки или временной зазор (window of latency). Пакеты, прибывающие рано, будут немного задержаны и затем помещены в окно вместе с опоздавшими пакетами. Это означает, что мы избавляемся от дрожания и обеспечиваем плавную доставку сообщений клиенту.
Операция JitterBuffer
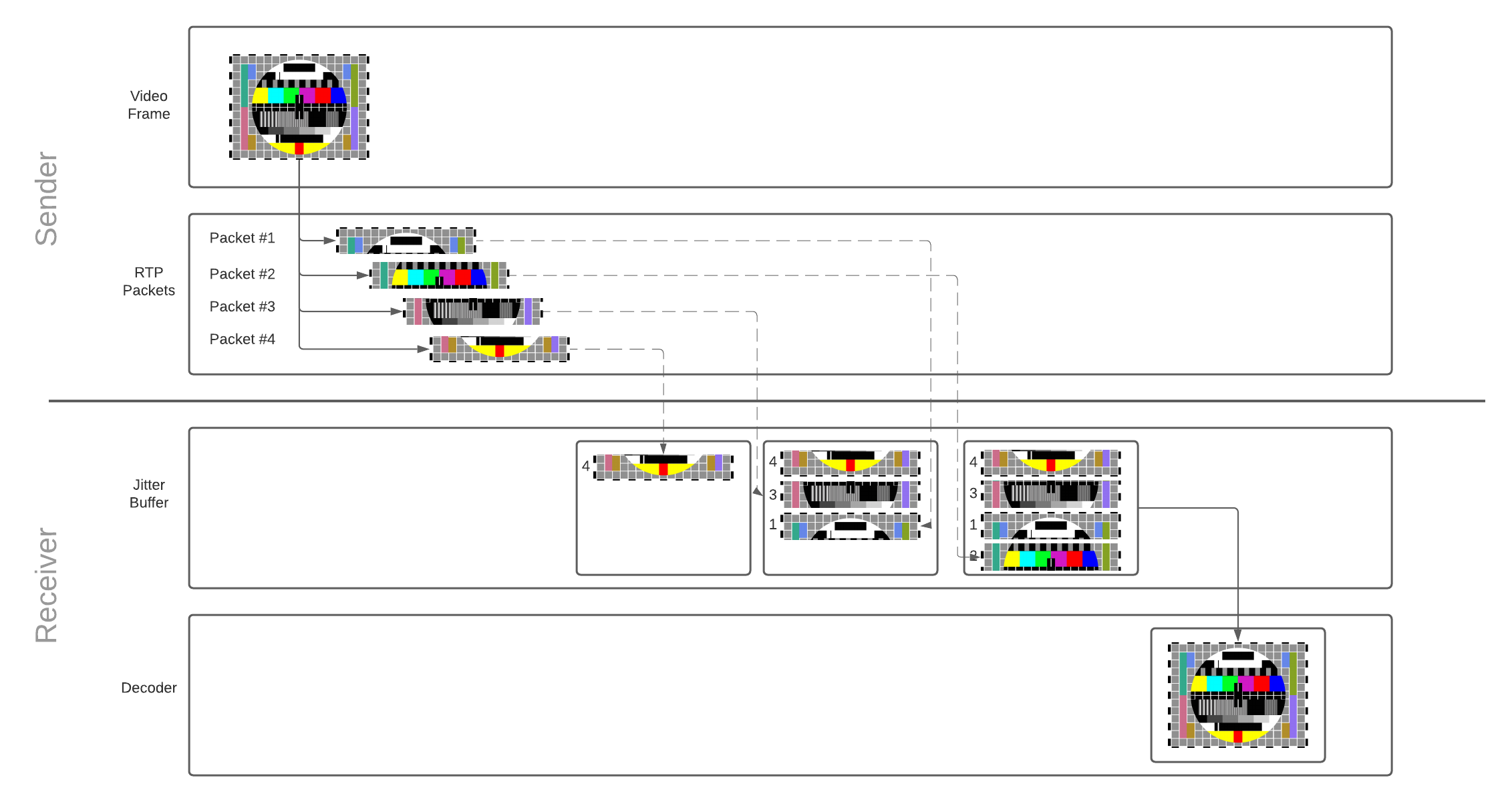
Каждый пакет помещается в буфер при получении. Когда пакетов становится достаточно для реконструкции фрейма (кадра), фрейм высвобождается (release) из буфера и отправляется на расшифровку (decoding). Декодер, в свою очередь, расшифровывает и отрисовывает видеофрейм на экране пользователя. Поскольку буфер имеет ограниченную вместимость, пакеты, которые находятся там слишком долго, отклоняются (discarded).
jitterBufferDelay предоставляет хорошие данные о производительности сети и ее влиянии на плавность воспроизведения. jitterBufferDelay является частью WebRTC statictics API, относящейся к входящему потоку получателя. Задержка (delay) определяет время, которое видеофреймы проводят в буфере перед отправкой декодеру. Большая задержка означает, что наша сеть сильно нагружена.
Определение перегрузки
Перед решением проблемы перегрузки сети, необходимо эту перегрузку определить. Для этого используется congestion controller (контроллер перегрузки). Это сложная вещь, которая в настоящее время активно развивается. Все время публикуются и тестируются новые алгоритмы. На самом высоком уровне все они делают одно и тоже. Контроллер перегрузки выполняет оценку пропускной способности на основе некоторых входных данных, например:
- потеря пакетов — потеря пакетов в перегруженных сетях увеличивается;
- джиттер — по мере увеличения нагрузки время доставки пакетов становится все более нестабильным;
- время туда и обратно — время туда и обратно при высокой нагрузке увеличивается;
- явные уведомления о перегрузке (explicit congestion notification) — новейшие сети могут помечать пакеты как находящиеся под угрозой потери для уменьшения нагрузки.
В процессе звонка эти значения должны все время измеряться. Использование сети может увеличиваться и уменьшаться, следовательно, будет меняться пропускная способность.
Решение проблемы перегрузки
После измерения пропускной способности нам необходимо настроить то, что мы отправляем. Настройки зависят от типа передаваемых данных.
Снижение скорости передачи данных
Ограничение скорости передачи данных — первое решение проблемы перегрузки. Контроллер нагрузки предоставляет расчеты, а отправитель ограничивает скорость.
В большинстве случаев используется именно этот способ. В случае с TCP это берет на себя операционная система, процесс является полностью прозрачным для пользователей и разработчиков.
Уменьшение количества передаваемых данных
В некоторых случаях мы можем отправлять меньшее количество информации для удовлетворения лимитов. В WebRTC мы не можем снижать скорость передачи данных.
Если нам не хватает пропускной способности, мы можем, например, снизить качество передаваемого видео. Для этого требуется тесная связь между видеокодером и контроллером перегрузок.
Обмен медиаданными
WebRTC позволяет отправлять и получать неограниченное количество аудио и видеопотоков. Мы можем добавлять и удалять эти потоки в любое время в течение сессии. Потоки могут быть автономными или объединяться в один. Мы можем отправлять видео захвата экрана и добавлять к нему аудио и видео из вебкамеры.
Протокол WebRTC не зависит от кодеков. Лежащий в его основе транспорт поддерживает все, даже то, чего еще не существует. Однако агент, с которым мы общаемся, может не иметь инструментов, необходимых для принятия звонка.
WebRTC спроектирован для работы в динамичных условиях сетей. Во время звонка пропускная способность может увеличиваться и уменьшаться. Мы можем внезапно столкнуться с сильной потерей пакетов. Протокол предоставляет возможности для решения этой проблемы. WebRTC реагирует на изменение условий сети и старается обеспечить наилучший опыт использования с учетом доступных ресурсов.
Как это работает?
WebRTC использует 2 протокола, RTP и RTCP, определенные в RFC 1889.
RTP — это протокол для передачи медиаданных. Он был разработан для передачи видео в реальном времени. Он не устанавливает никаких правил относительно задержки или надежности доставки пакетов, но предоставляет инструменты для их настройки. RTP предоставляет потоки, которые могут передаваться через одно соединение. Он также предоставляет информацию о времени отправки и порядке пакетов, необходимую для правильного формирования медиаконвейера (media pipeline).
RTCP — это протокол, содержащий метаданные о звонке. Формат протокола является очень гибким и позволяет добавлять любые метаданные. Это используется для сбора статистики о звонке. Также это может использоваться для обработки потери пакетов и реализации контроля перегрузки. Он предоставляет двунаправленную коммуникацию, автоматически адаптирующуюся к постоянно меняющимся сетевым условиям.
Задержка против качества
Обмен медиаданными в реальном времени всегда сопряжен с выбором между задержкой и качеством. Чем большую задержку мы можем себе позволить, тем выше будет качество медиа.
Ограничения реального мира
Это обусловлено ограничениями реального мира — характеристиками сети, которые необходимо учитывать.
Видео является сложным
Передача видео — сложный процесс. Для хранения 30-минутного несжатого 720 8-битного видео требуется около 110 Гб. В таких условиях конференция с четырьмя участниками является невозможной. Следовательно, нам нужен какой-то способ уменьшения размера видео и ответом является сжатие (compression). Однако, это имеет некоторые недостатки.
Video 101
Мы не будем рассматривать сжатие видео в подробностях. Мы рассмотрим его в степени, достаточной для понимания того, почему RTP спроектирован так, как спроектирован. Сжатие видео — это его кодировка, преобразование в другой формат, который требует меньшего количества битов для представления аналогичного видео.
Сжатие с потерей и без потери качества
Мы можем кодировать видео без потери (lossless compression) и с потерей (lossy compresion) качества. Поскольку кодировка без потери требует большего количества данных для передачи пиру, увеличивая задержку и потерю пакетов, RTP, как правило, применяет кодировку с потерей, несмотря на то, что это приводит к снижению качества видео.
Внутри и межкадровое сжатие
Сжатие видео делится на 2 вида. Первый — это сжатие внутри кадра (или просто сжатие кадра, intra-frame compression). Такое сжатие уменьшает количество бит, используемых для описания единичного видеофрейма. Аналогичная техника используется для сжатия неподвижных (still) изображений, например, JPEG.
Второй тип — это межкадровое сжатие (inter-frame compression). Поскольку видео состоит из большого количества изображений (кадров, фреймов), мы ищем способы не отправлять одинаковую информацию дважды.
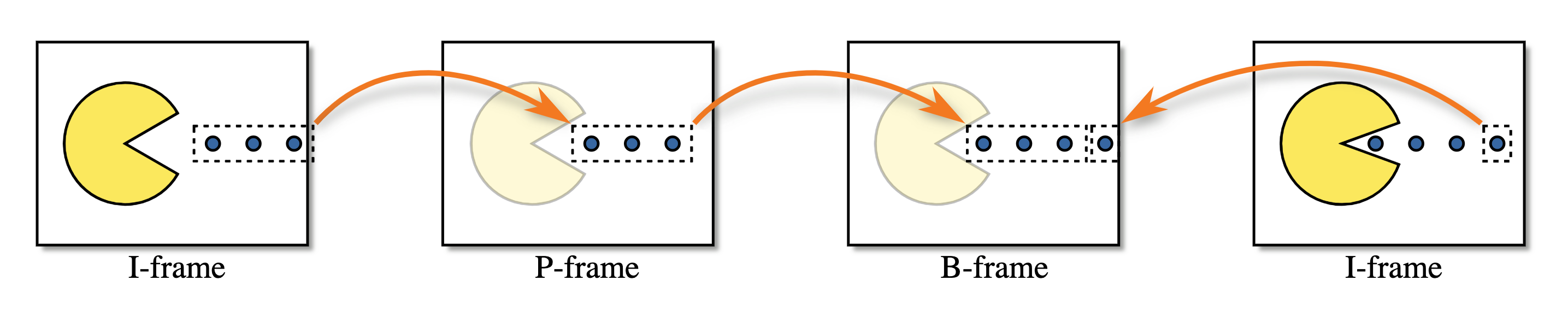
Типы межкадрового сжатия
Межкадровое сжатие делится на 3 типа:
- I-Frame — полное изображение, может кодироваться во что угодно;
- P-Frame — частичное изображение, содержащее только изменения предыдущего изображения;
- B-Frame — частичное изображение — совмещение предыдущего и будущего изображений.
Визуализация этих типов:
Видео является деликатным
Сжатие видео очень сильно зависит от его состояния, что делает сложным его передачу по сети. Что случится, если мы потеряем часть I-Frame? Откуда P-Frame знает, что модифицировать? С ростом сложности сжатия, вопросов становится все больше и больше. К счастью, RTP и RTCP предоставляют решение этих проблем.
RTP
Формат пакета
Каждый пакет RTP имеет следующую структуру:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC |M| PT | Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Timestamp |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Synchronization Source (SSRC) identifier |
+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+=+
| Contributing Source (CSRC) identifiers |
| .... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+Version (V)
Version (версия) всегда имеет значение 2.
Padding (P)
Padding (заполнение) — логическое значение, определяющее, имеет ли полезная нагрузка заполнение.
Последний байт полезной нагрузки содержит количество байтов заполнения.
Extension (X)
Если установлен, заголовок RTP будет содержать расширения. Мы поговорим об этом позже.
CSRC count (CC)
Количество идентификаторов CSRC, следующих после SSRC, но перед полезной нагрузкой.
Marker (M)
Бит маркера не имеет предопределенного значения и может использоваться как угодно.
В некоторых случаях он устанавливается, когда пользователь что-нибудь говорит. Также он часто используется для индикации ключевого кадра (keyframe).
Payload Type (PT)
Payload Type (тип полезной нагрузки) — это уникальный идентификатор кодека, который используется данным пакетом.
Payload Type является динамическим. VP8 в одном звонке может отличаться от VP8 в другом звонке. Инициатор звонка (offerer) определяет связь между Payload Types и кодеками в Session Description (описании сессии).
Sequence Number
Sequence Number (последовательный номер) используется для упорядочивания пакетов в потоке. При каждой отправке пакета Sequence Number увеличивается на единицу.
RTP спроектирован таким образом, что получатель имеет возможность своевременно обнаруживать потерю пакетов.
Timestamp
Момент выборки (sampling instant) для данного пакета. Это не глобальные часы, а время, прошедшее с начала передачи потока. Несколько пакетов RTP могут иметь одинаковый Timestamp, если они, например, являются частью одного фрейма.
Synchronization Source (SSRC)
SSRC (источник синхронизации) — это уникальный идентификатор потока. Это позволяет передавать несколько медиапотоков через одно соединение RTP.
Contributing Source (CSRC)
CSRC (вспомогательный источник) обычно используется для индикаторов речи. Скажем, на сервере мы объединили несколько аудиопотоков в один RTP-поток. Далее мы используем это поле для определения того, что "входящие потоки A и C в данный момент разговаривают между собой".
Payload
Payload — это полезная нагрузка, фактически передаваемые данные.
RTCP
Формат пакета
Каждый пакет RTCP имеет следующую структуру:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P| RC | PT | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+Version (V)
Version всегда имеет значение 2.
Padding (P)
Аналогично RTP.
Reception Report Count (RC)
Количество отчетов (reports) в данном пакете. Один пакет RTCP может содержать несколько событий (events).
Packet Type (PT)
Уникальный идентификатор типа пакета RTCP. Агент WebRTC не обязан поддерживать все типы, поддержка между агентами может отличаться. На практике можно встретить следующие типы:
-
192— полный запрос INTRA-frame (FIR); -
193— негативные подтверждения (NACK); -
200— отчет отправителя (sender report); -
201— отчет получателя (receiver report); -
205— общая обратная связь (feedback)RTP; -
206— обратная связь определенной полезной нагрузки.
Значимость каждого из этих типов пакетов будет описана ниже.
Полный запрос INTRA-frame (FIR) и Picture Loss Indication (PLI)
Сообщения FIR и PLI (обнаружение потери изображения) служат одной цели. Эти сообщения запрашивают у отправителя полный ключевой кадр. PLI используется, когда декодер получает частичные фреймы и не может их декодировать. Это может произойти из-за потери данных или ошибки декодера.
Согласно RFC 5104 FIR не должен использоваться при потере пакетов или фреймов. Это задача PLI. FIR запрашивает ключевой кадр, например, при подключении к сессии нового участника. Для начала декодирования видео требуется ключевой кадр, декодер будет отклонять кадры до его получения.
Получатель запрашивает полный ключевой кадр сразу после подключения, это позволяет минимизировать задержку между подключением и появлением изображения на экране пользователя.
Пакеты PLI являются частью сообщений с ответной реакцией на определенную полезную нагрузку.
На практике ПО, которое умеет работать с пакетами PLI и FIR, используется в обоих случаях. Оно отправляет сигнал кодеру о предоставлении нового полного ключевого кадра.
Негативные подтверждения
NACK "просит" отправителя повторить отправку пакета RTP. Обычно, это связано с потерей пакета, но также может быть связано с его задержкой.
NACK является гораздо более эффективным с точки зрения пропускной способности решением, чем запрос всего фрейма. Поскольку RTP разбивает пакеты на части (chunks), запрашивается лишь маленький недостающий кусочек. Получатель создает сообщение с SSRC и последовательным номером. Если отправитель не может повторно отправить запрошенный пакет, он просто игнорирует это сообщение.
Отчеты отправителя и получателя
Эти отчеты используются для обмена статистикой между агентами. Статистика содержит информацию о количестве полученных пакетов и джиттере.
Отчеты могут использоваться для диагностики и контроля перегрузки.
Как RTP/RTCP решают проблемы вместе?
RTP и RTCP работают вместе над решением упомянутых выше проблем, связанных с динамичными условиями сетей. Эти техники все еще активно развиваются.
Forward Error Correction
Также известное как FEC (превентивное исправление ошибок) — другой способ решения проблемы потери пакетов. FEC — это когда мы отправляем данные несколько раз, без запроса на их повторную отправку. Это происходит на уровне RTP или даже на уровне кодека.
Если потеря пакетов является постоянной, FEC является более эффективным с точки зрения задержки, чем NACK. Время туда и обратно (round-trip time, rtt) запроса на повторную отправку недостающего пакета и отправку этого пакета может быть значительным в случае с NACK.
Адаптивная оценка битрейта и пропускной способности
Как говорилось в предыдущем разделе, сети являются непредсказуемыми и ненадежными. Пропускная способность может меняться несколько раз на протяжении одной сессии. Нередки случаи резкого изменения доступной пропускной способности (на порядки величины) в течение одной секунды.
Основная идея заключается в том, чтобы настраивать битрейт кодирования на основе прогнозируемой, текущей и будущей пропускной способности сети. Это позволяет обеспечить наилучшее качество передаваемого аудио или видео и избежать разрыва соединения по причине перегрузки. Эвристические техники, моделирующие поведение сети и пытающиеся его предсказать, известны как оценка пропускной способности (bandwidth estimation).
Здесь существует много нюансов, остановимся на некоторых из них подробнее.
Идентификация и передача состояния сети
RTP/RTCP используются в разных сетях, как следствие, иногда происходят обрывы соединения. Будучи построенными поверх UDP, эти протоколы не предоставляют встроенного механизма для повторной передачи пакетов, не говоря уже о контроле перегрузки.
Для обеспечение наилучшего пользовательского опыта WebRTC должен вычислять качество сетевого маршрута и адаптироваться к его изменениям. Ключевыми факторами мониторинга является следующее: доступная пропускная способность (в каждом направлении, может быть ассиметричной), время туда и обратно и джиттер (флуктуации, возникающие в пути туда и обратно). Это необходимо для расчета потери пакетов и обмена информацией об изменении этих свойств в процессе эволюции сетевых условий.
Рассматриваемые протоколы преследуют две главные цели:
- Вычисление доступной пропускной способности (в каждом направлении), поддерживаемой сетью.
- Обмен информацией о характеристиках сети между отправителем и получателем.
RTP/RTCP предоставляет три подхода к решению этих задач. Каждый подход имеет свои плюсы и минусы. Применяемый подход зависит от стека ПО, доступного клиентам, а также от библиотек, используемых в приложении.
Отчеты отправителя/получателя
Эти сообщения RTCP определяются в RFC 3550 и используются для обмена характеристиками сети между конечными точками. Отчеты получателя (receiver reports) посвящены качеству сети (включая потерю пакетов, время туда и обратно и джиттер) и используются в алгоритмах, предназначенных для расчета доступной пропускной способности.
Отчеты отправителя и получателя (sender reports/receiver reports, SR/RR) вместе формируют картину качества сети. Они отправляются для каждого SSRC и являются входными данными для вычисления пропускной способности. Эти вычисления производятся отправителем после получения данных RR, содержащих следующие поля:
-
Fraction Lost(доля потерянных пакетов) — какой процент пакетов был потерян после последнегоRR; -
Cumulative Number of Packets Lost(совокупное количество потерянных пакетов) — сколько пакетов было потеряно в течение сессии; -
Extended Highest Sequence Number Received(полученный расширенный максимальный последовательный номер) — какой последовательный номер был получен последним, и сколько раз он был получен; -
Interarrival Jitter(общий джиттер) — джиттер всего звонка; -
Last Sender Report Timestamp(время последнего отчета отправителя) — последнее известное время отправителя, используется для расчета времени туда и обратно.
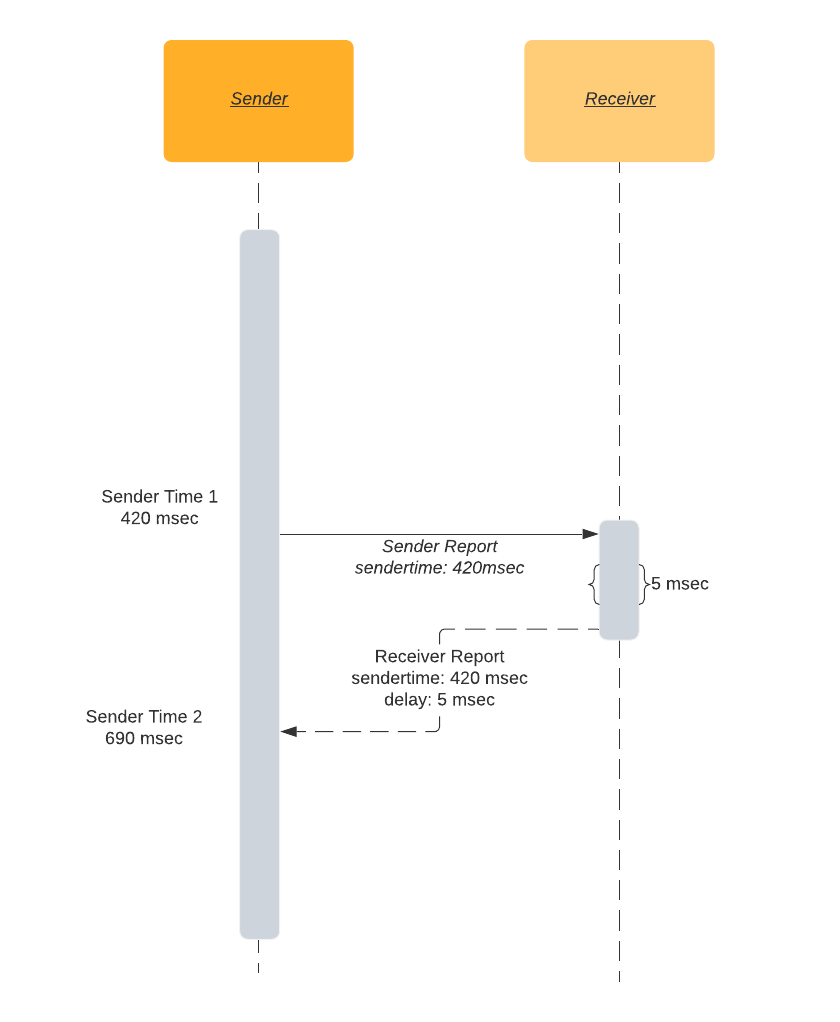
SR и RR используются для вычисления времени туда и обратно.
Отправитель включает в SR свое локальное время sendertime1. При получении пакета SR получатель отправляет в ответ RR. Кроме прочего, RR включает в себя sendertime1, полученное от отправителя. Между получением SR и отправкой RR образуется задержка. По этой причине RR также включает "задержку после последнего отчета отправителя" (delay after last sender report, DLSR). DLSR используется для корректировки вычисления времени туда и обратно. После получения отправителем RR он вычитает sendertime1 и DLSR из текущего времени sendertime2. Эта разница во времени называется временем в пути туда и обратно (round-trip time, rtt).
rtt = sendertime2 - sendertime1 - DLSRRTT простыми словами:
- я отправляю тебе сообщение, мои часы показывают 16 часов 20 минут 42 секунды и 420 миллисекунд;
- ты присылаешь мне такое же время в ответ;
- ты также присылаешь время, прошедшее между получением моего сообщения и отправкой твоего сообщения, скажем, 5 мс;
- после получения твоего сообщения, я снова смотрю на часы;
- теперь они показывают 16 ч 20 мин 42 сек 690 мс;
- это означает, что передача сообщения туда и обратно заняла 265 мс (690 — 420 — 5);
- таким образом, время туда и обратно составляет 265 мс.
TMMBR, TMMBN, REMB и TWCC в сочетании с GCC
Google Congestion Control (GCC)
Алгоритм Google Congestion Control (GCC), описанный в общих чертах в draft-ietf-rmcat-gcc-02, пытается решить проблему расчета пропускной способности. Он сочетается с множеством других протоколов для снижения требований, необходимых для установки соединения. Он хорошо подходит как для принимающей стороны (при работе с TMMBR/TMMBN или REMB), так и для отправляющей стороны (при работе с TWCC).
GCC фокусируется на потерях пакетов и колебаниях времени прибытия кадров в качестве двух основных показателей для расчета пропускной способности. Он пропускает эти показатели через два связанных контроллера: для вычисления потерь (loss-based) и для вычисления задержки (delay-based).
Первый компонент GCC — контроллер для вычисления потерь, является очень простым:
- если потери пакета превышают
10%, оценка пропускной способности снижается; - если потери находятся в диапазоне
2-10%, оценка остается неизменной; - если потери ниже
2%, оценка увеличивается.
Вычисления производятся не реже одного раза в секунду. В зависимости от парного протокола, о потере пакетов может либо сообщаться в явном виде (TWCC), либо потеря может предполагаться (TMMBR/TMMBN и REMB).
Вторая функция взаимодействует с контроллером для вычисления потерь и отслеживает изменения времени прибытия пакетов. Данный контроллер определяет, когда сетевые каналы становятся перегруженными, и снижает оценку пропускной способности. Идея состоит в том, что перегруженный интерфейс будет помещать пакеты в очередь до тех пор, пока не будет исчерпана емкость его буфера. Если такой интерфейс будет получать больше трафика, чем он может отправить, он будет вынужден отбрасывать (drop) пакеты, не помещающиеся в его буферном пространстве. Такой тип потери пакетов особенно опасен для сетей с малой задержкой или работающих в режиме реального времени, он также может негативно влиять на все типы коммуникаций в сети, поэтому его следует, по возможности, избегать. Таким образом, GCC пытается определить, растет ли глубина очереди сети перед началом действительной потери пакетов. Он уменьшает пропускную способность, если наблюдается увеличение задержек в очереди.
Для решения этой задачи GCC пытается определить увеличение глубины очереди (queue depth), измеряя незначительное увеличение времени приема-передачи. Он записывает "время между прибытиями" (inter-arrival time) кадров t(i) - t(i-1) — разницу во времени прибытия двух групп пакетов (как правило, последовательных видеокадров). Эти группы часто отправляются через равные промежутки времени (например, каждые 1/24 секунды для видео с частотой 24 кадра в секунду). В результате измерение времени между прибытиями становится таким же простым, как измерение разницы во времени между началом первой группы пакетов (т.е. кадра) и первым кадром следующей группы.
На представленной ниже диаграмме среднее увеличение задержки между пакетами составляет +20мс, что является явным показателем перегрузки сети.
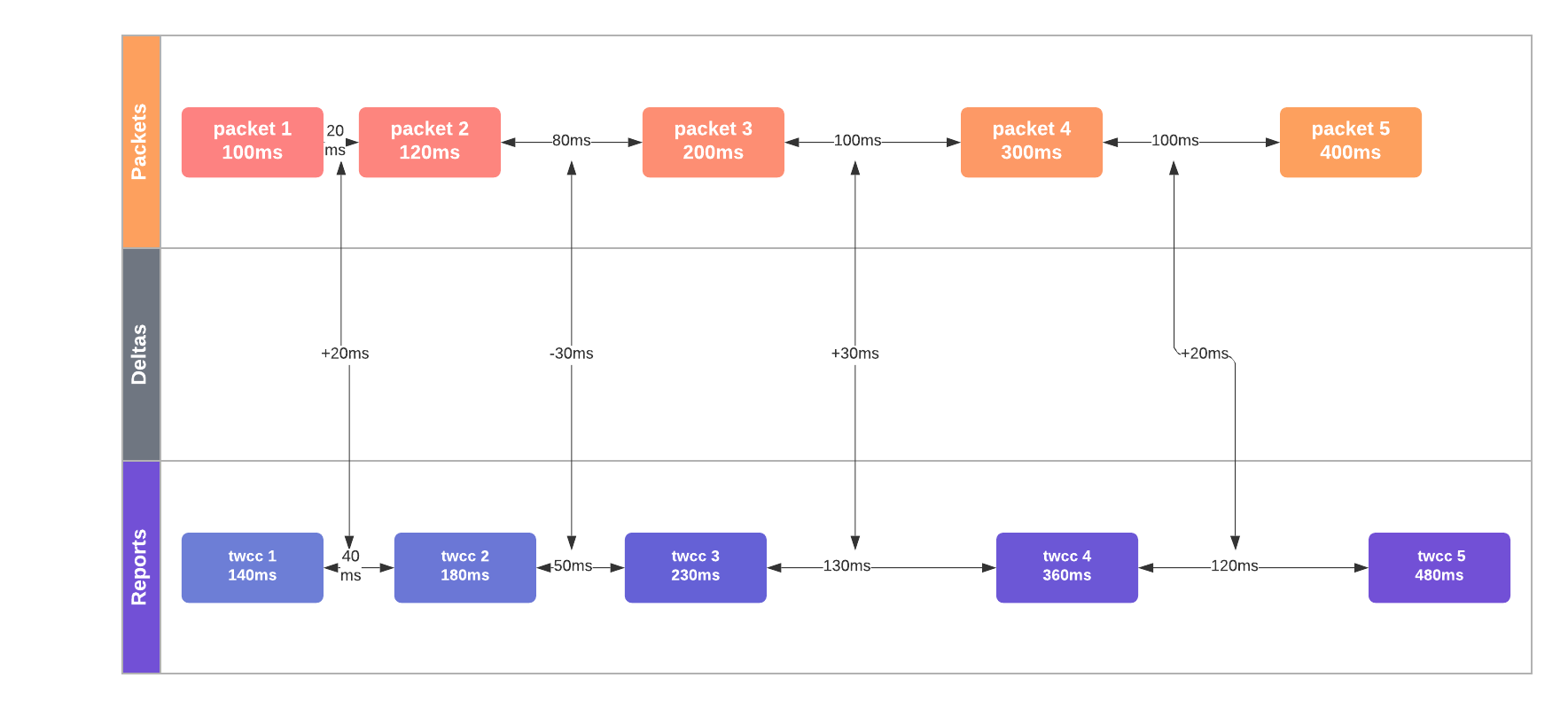
Увеличение времени между прибытиями групп пакетов является свидетельством увеличения глубины очереди в подключенных сетевых интерфейсах и, как следствие, перегрузки сети. Обратите внимание: GCC достаточно умен, чтобы учитывать колебания размеров байтов кадра. GCC уточняет проведенные измерения задержки с помощью фильтра Калмана и выполняет множество измерений времени приема-передачи (и его вариаций), прежде чем делать вывод о перегрузке сети. Фильтр Калмана в GCC можно считать заменой линейной регрессии: он позволяет делать точные прогнозы с учетом джиттера, добавляющего шум (noise) в измерения времени. При определении перегрузки GCC уменьшает доступный битрейт. В условиях стабильной сети он может медленно увеличивать оценку пропускной способности для проверки более высоких значений нагрузки.
TMMBR, TMMBN и REMB
Для TMMBR, TMMBN и REMB получатель сначала вычисляет доступную входящую пропускную способность (с помощью GCC, например), затем передает эту информацию отправителю. Сторонам не нужно обмениваться информацией о потере пакетов или других характеристиках сети, поскольку операции, выполняемые на стороне получателя, позволяют измерить время между прибытиями и потерю пакетов напрямую. Вместо этого TMMBR, TMMBN и REMB обмениваются оценками пропускной способности:
-
Temporary Maximum Media Stream Bit Rate Request(запрос временного максимального битрейта медиапотока) — мантисса/экспонента запрошенного битрейта для одногоSSRC; -
Temporary Maximum Media Stream Bit Rate Notification(уведомление о временном максимальном битрейте медиапотока) — уведомление о полученииTMMBR; -
Receiver Estimated Maximum Bitrate(расчетный максимальный битрейт получателя) — мантисса/экспонента запрошенного битрейта для всего сеанса.
TMMBR и TMMBN появились первыми и определены в RFC 5104. REMB появился позже, был разработан черновик draft-alvestrand-rmcat-remb, который так и не был стандартизирован.
Иллюстрация сессии с использованием REMB:
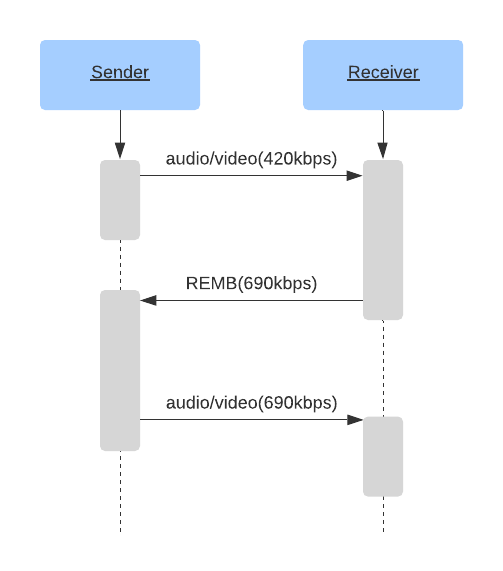
Данный метод хорошо работает на бумаге. Отправитель получает оценку от получателя, устанавливает битрейт кодировщика в полученное значение. Вуаля! Мы адаптировались к сетевым условиям.
Однако на практике REMB имеет некоторые недостатки.
Первым недостатком является неэффективность кодировщика. Когда мы устанавливаем для него битрейт, результат кодировки не обязательно будет соответствовать указанному значению. Мы можем получить больше или меньше битов в зависимости от настроек кодировщика и кодируемого кадра.
Например, результат работы кодировщика x264 с настройкой tune=zerolatency может существенно отличаться от установленного целевого битрейта. Один из возможных сценариев:
- предположим, что наш начальный битрейт составляет
1000 кбит/с; - кодировщик выдает только
700 кбит/с, поскольку ему не хватает высокочастотных признаков (high frequency features) для кодирования; - допустим, что получателю приходит видео
700 кбит/сс нулевой потерей пакетов. Затем он применяет правилоREMB 1для увеличения входящего битрейта на8%; - получатель отправляет пакет
REMBс предложением об увеличении битрейта до756 кбит/с(700 кбит/с * 1.08) отправителю; - отправитель устанавливает битрейт кодирования в значение
756 кбит/с; - кодировщик выдает еще более низкий битрейт;
- данный процесс повторяется снова и снова, что приводит к снижению битрейта до абсолютного минимума.
В конечном счете, это приведет к недоступному для просмотра видео даже при наличии прекрасного соединения.
Transport Wide Congestion Control
TWCC (контроль перегрузки на транспортном уровне) — одно из последних достижений в области оценки состояния сетевой коммуникации. Он определен в черновике draft-holmer-rmcat-transport-wide-cc-extensions-01.
В TWCC используется простой принцип:

В случае с REMB получатель сообщает отправителю о доступном битрейте загрузки. Он использует точные измерения предполагаемой потери пакетов и данные о времени между прибытиями пакетов.
TWCC — своего рода симбиоз протоколов SR/RR и REMB. Оценка пропускной способности возлагается на отправителя (как в SR/RR), но техника оценки больше похожа на REMB.
В TWCC получатель сообщает отправителю время прибытия каждого пакета. Эта информация является достаточной для того, чтобы отправитель мог измерить различные варианты задержек между прибытиями пакетов, а также идентифицировать потерянные и опоздавшие пакеты. При частом обмене такой информацией отправитель имеет возможность быстро адаптироваться к изменениям условий сети и корректировать пропускную способность с помощью таких алгоритмов, как GCC.
Отправитель следит за отправкой пакетов, их последовательными номерами, размером и временем отправки. При получении сообщения RTCP от получателя он сравнивает отправленную задержку между прибытиями пакетов с полученной. Увеличение получаемой задержки свидетельствует о перегрузке сети, в этом случае отправитель принимает необходимые меры по ее снижению.
Предоставляя отправителю необработанные данные, TWCC обеспечивает объективную оценку реальных условий сети:
- почти мгновенную информацию о потере пакетов, вплоть до индивидуальных пакетов;
- точный битрейт отправки;
- точный битрейт получения;
- измерение джиттера;
- разницу между задержками отправки и получения;
- описание того, как сеть справляется с волнообразной или стабильной пропускной способностью.
Одним из наиболее существенных преимуществ TWCC является гибкость, которую он предоставляет разработчикам WebRTC. Поскольку алгоритмы контроля перегрузки применяются на стороне отправителя, клиентский код может оставаться простым и легко масштабируемым. Сложные алгоритмы контроля перегрузки могут реализовываться быстрее на оборудовании, которым они непосредственно управляют (например, Selective Forwarding Unit — единица выборочной пересылки, обсуждаемая в следующем разделе). Для браузеров и мобильных устройств это означает, что клиенты могут извлекать выгоду из улучшений алгоритма, не дожидаясь стандартизации или обновления браузера (что может занимать продолжительное время).
Другие способы оценки пропускной способности
Наиболее разработанной реализацией является "A Google Congestion Control Algorithm for Real-Time Communication" (алгоритм контроля перегрузки для коммуникации в реальном времени), определенный в draft-alvestrand-rmcat-congestion.
Существует несколько альтернатив GCC, например, NADA: A Unified Congestion Control Scheme for Real-Time Media и SCReAM — Self-Clocked Rate Adaptation for Multimedia.
На этом вторая часть перевода завершена.
Благодарю за внимание и happy coding!

Комментарии (4)

wataru
29.03.2022 15:32Стоит так же сказать, что B-frame невозможны в webrtc, потому что в реальном времени ждать следующего кадра, чтобы через него закодировать текущий — неповолительная роскошь.
Далее, проблемы "Откуда P-Frame знает, что модифицировать" и так далее. Эта информация записана или в payload specific header, который с точки зрения RTP является частью payload. Сам по себе RTP ничем тут помочь не может.
FEC — конечно можно посылать некоторые пакеты несколько раз, но это дико не эффективно. Используются коды коррекции ошибок и генерируются пакеты из кучи оригинальных пакетов. Потом благодаря хитрой математике можно восстановить любой один потерянный пакет из группы.
По поводу RTT — Его может подсчитать и получатель по такой же схеме. Надо только включить DLRR блоки в sender report-ах.

wataru
Acknowledgments — правильнее перевести как "подтверждения", а не благодарности.
aio350 Автор
Согласен, поправил.