
Когда люди слышат про искусственный интеллект, глубокое обучение и машинное обучение, многие представляют роботов из фильмов, интеллект которых сравним или даже превосходит интеллект человека. Другие считают, что такие машины просто потребляют информацию и учатся на ней самостоятельно. Но на самом деле это далеко от истины: без человеческой помощи возможности компьютерных систем ограничены, и чтобы они стали «умными», необходима разметка данных.
В этой статье мы расскажем, что такое разметка данных, как она работает, о типах разметки данных и о рекомендациях, позволяющих сделать этот процесс беспроблемным.
Что такое разметка данных?
Разметка данных (Data labeling) (иногда называемая аннотированием данных (data annotation)) — это процесс добавления тэгов в сырые данные, чтобы показать модели машинного обучения целевые атрибуты (ответы), которые она должна предсказывать. Метка (label) или тэг (tag) — это описательный элемент, сообщающий модели, чем является отдельный элемент данных, чтобы она могла учиться на примере. Допустим, модели нужно предсказывать музыкальные жанры. В таком случае обучающий массив данных будет состоять из множества композиций с метками жанров pop, jazz, rock и т. п.
Таким образом, размеченные данные выделяют признаки (характеристики) данных, чтобы помочь модели анализировать информацию и идентифицировать паттерны в исторических данных для выполнения точных предсказаний на новых, относительно близких входящих данных.

Процесс разметки объектов на фотографии при помощи инструмента аннотирования графических изображений LabelImg. Источник: GitHub
Процесс разметки данных — один из важнейших этапов в подготовке данных для процессов машинного обучения с учителем.
Подробнее о предварительной обработке данных для машинного обучения можно узнать из видео и/или статьи о подготовке массива данных для ML.
Итак, какие же сложности существуют в разметке данных?
Сложности в разметке данных
Высокие затраты времени и труда. Сложность заключается не только в получении большого объёма данных (особенно в высокоспециализированных нишах наподобие здравоохранения): ручное добавление тэгов к каждому элементу данных — это тоже трудная, долгая задача, требующая труда живых разметчиков. В рамках полного цикла разработки ML подготовка данных (включая разметку) занимает почти 80% от всего времени проекта.
Необходимость экспертных знаний. Для добавления тэгов вам может понадобиться нанимать специалистов. Например, если вы собираетесь создать модель ML, способную распознавать опухоли на рентгеновских снимках, то неподготовленные аннотаторы вряд ли с этим справятся.
Риск несогласованности. В большинстве случаев для повышения точности необходима перекрёстная разметка — процесс, при котором несколько людей размечают одинаковые массивы данных. Но поскольку люди имеют разный уровень опыта, критерии разметки и сами метки могут быть несогласованными, что тоже представляет собой сложность. У двух или более аннотаторов могут возникнуть разногласия по поводу некоторых тэгов. Например, один специалист может оценить отзыв об отеле как положительный, а другой может посчитать его саркастическим и присвоить отрицательную метку.
Риск ошибок. Какими бы опытными и внимательными ни были ваши разметчики, разметка вручную подвержена человеческим ошибкам. Это неизбежно, поскольку аннотаторы обычно работают с большими массивами сырых данных. Представьте, что человек размечает 150 тысяч изображений, на каждом из которых до десяти объектов!
Тем не менее, несмотря на все эти недостатки, разметка данных по-прежнему является краеугольным камнем большинства проектов машинного обучения. Давайте разберёмся, как происходит этот процесс.
Подходы к разметке данных
Существуют разные способы выполнения разметки данных. Выбор стиля зависит от сложности формулировки задачи, количества размечаемых данных, размера команды дата-саентистов и, разумеется, от финансовых ресурсов и имеющегося времени. В этом разделе мы вкратце рассмотрим каждый из подходов. Подробнее о каждом можно прочитать в статье, посвящённой организации разметки данных в проекте машинного обучения.
Разметка данных внутри компании. Как понятно из названия, разметка данных внутри компании проводится специалистами организации. Этот способ подойдёт, если у вас достаточно времени, человеческих и финансовых ресурсов. Он обеспечивает наибольшую точность разметки. С другой стороны, он медленный.
Краудсорсинг. Существуют специальные платформы краудсорсинга, например, Amazon Mechanical Turk (MTurk), на которых можно зарегистрироваться как работодатель и закреплять различные задачи разметки за доступными подрядчиками. Этот подход доступен и относительно быстр, однако не гарантирует высокого качества аннотированных данных.
Аутсорсинг. Ещё один способ выполнения задачи — аутсорсинг задач разметки данных фрилансерам, которых можно найти на различных платформах для найма и фриланса, например, на Upwork. Этот подход схож с предыдущим, это быстрый способ получения услуг разметки данных, однако качество может оказаться неудовлетворительным.
Автоматическая разметка данных. Кроме ручной разметки можно использовать помощь ПО. Тэги могут автоматически определяться и добавляться в обучающий массив данных при помощи методики под названием активное обучение. По сути, живые специалисты создают ИИ-модель автоматической разметки, размечающую сырые, неразмеченные данные. После этого они определяют, выполнила ли модель разметку верно. В случае ошибок живые разметчики исправляют их и обучают модель повторно.
Создание синтетических данных. Синтетический датасет — это искусственно сгенерированный массив данных с метками, который является альтернативой данным из реального мира. Он создаётся компьютерными симуляциями или алгоритмами, и часто используется для обучения моделей машинного обучения. В контексте методик разметки синтетические данные являются отличным решением задач дефицита и разнообразия данных. Решение заключается в создании с нуля искусственных данных. Разработчики массивов данных создают 3D-среды с объектами и фонами, которые модель должна распознать. При этом можно рендерить любой нужный для проекта объём синтетических данных.
Как работает разметка данных
Каким бы ни был подход, процесс разметки данных выполняется в следующем хронологическом порядке:
Сбор данных. Начальным этапом любого проекта ML является сбор нужного количества сырых данных (изображений, аудиофайлов, видео, текстов и т. п.). Источники данных у разных компаний могут различаться. Некоторые организации сами годами накапливали информацию, другие используют публично доступные массивы данных. Как бы то ни было, такие данные часто бывают несогласованными, повреждёнными или попросту неподходящими для конкретного случая. Поэтому перед созданием меток их необходимо подвергнуть очистке и предварительной обработке. Как правило, для обеспечения более точных результатов модели необходимо предоставить большой объём разнообразных данных.
Аннотирование данных. Это основная часть всего процесса. Специалисты изучают данные и добавляют к ним метки. Таким образом они добавляют осмысленный контекст, который модель может использовать в качестве эталонных данных (ground truth) — целевых переменных, которые должна предсказывать модель. Например, это могут быть тэги на изображении, описывающие запечатлённые на нём объекты.
Контроль качества. Данные должны быть качественными, надёжными, точными и согласованными. Качество массивов данных в обучении модели ML определяется тем, насколько точно метки добавлены к конкретному обучающему примеру данных. Для обеспечения точности меток и их оптимизации должны быть реализованы постоянные проверки качества (QA).
Для этой цели разметчики часто используют следующие алгоритмы QA:
- алгоритм консенсуса — надёжность данных достигается благодаря достижению согласия об отдельном примере данных между различными системами и людьми
- тест альфы Кронбаха — измерение средней согласованности элементов данных в массиве.
Контролем качества часто пренебрегают, однако он сильно влияет на точность результатов.
Обучение и тестирование модели. Логическим продолжением предыдущих этапов является использование для обучения модели размеченных данных, содержащих правильные ответы. В этом процессе обычно применяется тестирование модели на неразмеченном массиве данных для проверки того, обеспечивает ли она ожидаемые прогнозы или оценки. В зависимости от конкретного случая используются метрика уверенности или уровни точности. Допустим, модель считается успешно обученной, если её точность составляет 96 и более процентов, то есть она делает 960 правильных прогнозов для 1000 примеров.
Теперь давайте перейдём к обзору типичных видов разметки данных для каждой сферы ИИ, а именно:
- разметки изображений и видео,
- разметки текста,
- разметки аудио.
Разметка изображений и видео для задач computer vision
Computer vision (CV, «компьютерное зрение») — это подмножество искусственного интеллекта (AI), позволяющее машинам "видеть". Хотя это звучит футуристично, способность компьютеров видеть, по сути, сводится к тому, что они могут извлекать значимую информацию из визуальных данных наподобие цифровых изображений, имитируя визуальное восприятие человека. Для этого компьютерам необходимо следующее:
- аннотирование изображений — процесс присвоения тэгов изображениям
- аннотирование видео — процесс добавления меток в видеокадры (неподвижные изображения, извлечённые из видеозаписи).
В зависимости от задачи CV работники могут использовать разные типы аннотирования изображений/видео.
Классификация изображений
Классификация изображений — это важная задача CV, процесс которой заключается в присвоении одной метки (классификация одной меткой) или нескольких меток (классификация множеством меток) самому изображению на основании того, к какому классу принадлежит запечатлённый на нём объект. Вне зависимости от того, одна или две кошки находятся на фотографии, она будет размечена как «cat». То же самое относится и к классификации видеоклипов.

Пример классификации изображений
Ограничивающие прямоугольники
Ограничивающие прямоугольники — это самый распространённый способ аннотирования изображений. Они представляют собой прямоугольники или квадраты, отрисовываемые вокруг объектов для указания их местонахождения на изображении. Прямоугольники задаются координатами на оси X и Y в левом верхнем и правом нижнем углах прямоугольника.
Ограничивающие прямоугольники в основном используются для распознавания и классификации объектов в задачах локализации.
- Распознавание объектов — обнаружение и классификация набора объектов на изображении или в видеокадре с указанием позиций каждого объекта ограничивающими прямоугольниками.
- Классификация изображений с локализацией — классификация изображений по нескольким заранее определённым классам на основании запечатлённых объектов и ограничивающих прямоугольников этих объектов. В отличие от распознавания объектов, эта методика обычно используется для определения местоположения одного объекта или нескольких объектов как одной сущности (см. фотографию ниже).

Аннотирование многоугольниками
При аннотировании многоугольниками используются замкнутые полигоны, определяющие местоположение и форму объектов. Так как в реальном мире чаще встречаются непрямоугольные фигуры (например, мотоцикл), многоугольники являются более подходящим вариантом аннотирования изображений, чем ограничивающие прямоугольники.

Мотоцикл, аннотированный многоугольником Источник: массив данных COCO
При работе с многоугольниками аннотаторы данных могут использовать больше линий и углов, менять направление вертикалей, чтобы точнее указывать истинную форму объекта.
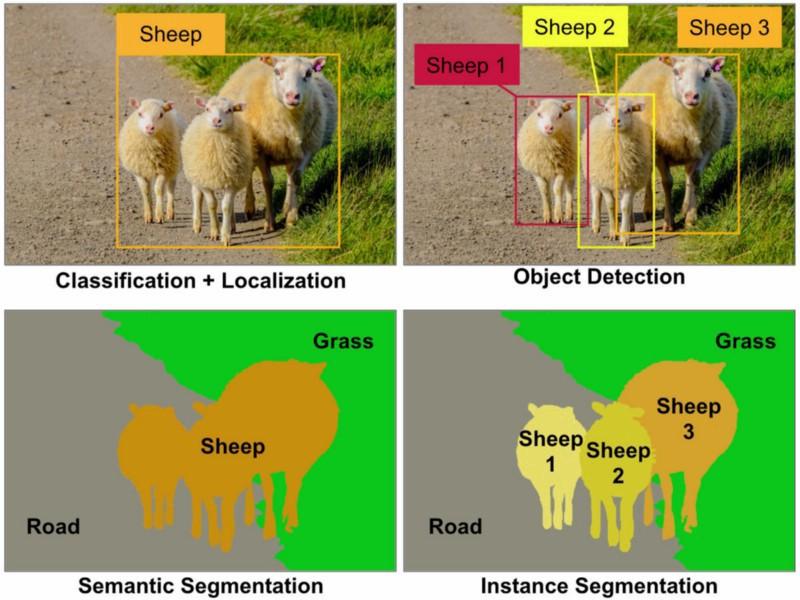
Семантическая сегментация
Семантическая сегментация — это методика аннотирования, используемая для присвоения меток конкретным пикселям изображения, принадлежащим соответствующему классу. Аннотаторы рисуют многоугольники вокруг множества пикселей, которые они хотят разметить, и группируют их как одну сущность одного класса, отделяя их от фона и других объектов. Например, на фотографии ниже все овцы сегментированы как один объект, а дорога и трава представляют ещё два объекта.
Различия между классификацией изображений, распознаванием объектов, семантической сегментацией и сегментацией экземпляров. Источник: Medium
Сегментация экземпляров — это схожая методика, однако в ней разные объекты одного класса разделяются как отдельные экземпляры. Например, в дополнение к дороге и траве каждая овца на изображении сегментирована как отдельный объект.
3D-кубоиды

Пример аннотирования 3D-кубоидами. Источник: Cogito Tech
3D-кубоиды — это 3D-описания объектов, позволяющие отобразить не только длину и ширину каждого объекта, но и его глубину. Таким образом, аннотаторы кроме позиции могут указать и признак объёма. Если края объекта скрыты или перекрыты другими объектами, аннотаторы указывают их приблизительно.
Аннотирование ключевыми точками
При аннотировании ключевыми точками используется добавление на изображение точек и соединение их рёбрами. На выходе мы получаем координаты X и Y ключевых точек, пронумерованных в определённом порядке. Эта методика используется для идентификации мелких объектов и вариаций форм, имеющих одинаковую структуру (например, выражений и черт лиц, частей тела и поз человека).
Пример аннотирования видеоклипа ключевыми точками. Источник: Keymakr
Аннотирование ключевыми точками обычно используется для разметки видеокадров.
Примеры использования разметки изображений и видео
Аннотирование видео и изображений находит широкий спектр применений в различных областях.
- В здравоохранении выполняется разметка на рентгеновских снимках, результатах МРТ и КТ, а также осуществляется разметка снимков изображений с микроскопов для диагностического анализа и распознавания заболеваний (например, для распознавания раковых клеток на ранних стадиях).
- В логистике и перевозках выполняется разметка штрих-кодов, QR-кодов и других идентификационных кодов для отслеживания товаров и реализации интеллектуальной логистики.
- В автомобильной промышленности выполняется сегментирование транспортных средств, дорог, зданий, пешеходов, велосипедистов и других объектов на изображениях и видео, чтобы помочь беспилотным автомобилям различать эти сущности и избегать столкновений с ними в реальной жизни.
- В кибербезопасности выполняется распознавание черт лиц и эмоций для того, чтобы ИИ-системы могли распознавать людей на изображениях и записях камер видеонаблюдения.
Разметка текста для задач обработки естественного языка
Обработка естественного языка (Natural language processing, NLP) — это подмножество искусственного интеллекта, позволяющее машинам интерпретировать человеческий язык. В NLP мощь лингвистики, статистики и машинного обучения используется для исследования структуры и правил языка, а также для создания интеллектуальных систем, способных понять смысл текста и речи. Алгоритм может анализировать различные лингвистические аспекты: семантику, синтаксис, прагматику и морфологию, а затем применять эти знания для выполнения необходимых задач.
Вот несколько распространённых способов аннотирования текста для задач NLP.
Классификация текста
Классификация текста (также называемая категоризацией текста или тэгированием текста) — это процесс присвоения одной или нескольких меток целым текстовым блокам для их классификации по заранее выбранным категориям, трендам, объектам и другим параметрам.
Аннотирование эмоциональной наполненности используется для анализа эмоциональной наполненности текста, то есть для процесса понимания того, является ли текст позитивным, негативным или нейтральным сообщением. Пример:
«Служба поддержки выше всяких похвал». → позитивное сообщение.
«Не отвечают за просьбы о приложении и ставят звонок на удержание на полчаса». → негативное сообщение
«Новый дизайн веб-сайта в целом неплох». → нейтральное сообщение
Категоризация тем — задача идентификации темы отрывка текста. При аннотировании для анализа отзывов клиентов, например, добавляются такие тематические метки, как Pricing («цена») или Ease of Use («простота использования»).
Категоризация языка — это задача распознавания языка текста. При аннотировании текста на одном из человеческих языков добавляются метки соответствующего языка.
Аннотирование сущностей
Аннотирование сущностей — это процесс распознавания, указания местоположения и тэгирования фундаментальных сущностей в каждой строке неразмеченного текста. В отличие от классификации текста, аннотирование сущностей — это разметка отдельных слов и фраз.
Существует множество видов аннотирования сущностей, включая распознавание именованных сущностей, тэгирование ключевых фраг и тэгирование частей речи.
При распознавании именованных сущностей выполняется извлечение, вычленение и идентификация сущностей, а также аннотирование их соответствующими именами. Самые распространённые категории — это имена людей, названия продуктов, организаций, места, даты, время и т. п.

Пример аннотирования предложения именованными сущностями. Источник: Towards Data Science
Представим, что вы создаёте модель ML, предназначенную для торговли акциями в зависимости от появляющихся в новостях событий. В процессе изучения данных алгоритм находит следующий заголовок:

Заголовок новости из Financial Express
Человек с лёгкостью распознает контекст, однако машина не сможет понять, относится ли слово «Tesla» к названию компании, конкретному автомобилю Tesla или, может быть, к Николе Тесла. Аннотирование именованных сущностей выполняет эту задачу для машины и объясняет ей правильное значение.
Извлечение и тэгирование ключевых фраз или слов. Кроме именованных сущностей разметчики могут тэгировать в тексте ключевые фразы или слова. Такой вид разметки текста может использоваться для резюмирования документов/параграфов или для индексирования корпуса текстов. Эта процедура требует тщательного исследования каждого текстового блока для извлечения самых значимых ключевых слов.
Тэгирование частей речи (Part-of-Speech, POS). В этой методике выполняется аннотирование всех слов в предложении соответствующей частью речи. Слова размечаются как существительные, глаголы, предлоги, прилагательные и т. п.

Пример тэгирования POS. Источник: Towards Data Science
Методика используется для идентификации взаимосвязей между словами в предложении и извлечения их смысла. Благодаря правильному тэгированию POS алгоритмы могут определять точное определение схожих слов в разных ситуациях, а значит, обеспечивать более точные результаты.
Связывание сущностей
Связывание сущностей — процесс разметки определённых сущностей в тексте и связывания их с большими репозиториями данных. По сути, это процесс привязки тэгированных сущностей к URL с предложениями, фразами и фактами, сообщающими о них расширенную информацию. Эта процедура особенно важна в случаях, когда текст содержит данные, которые можно интерпретировать разными способами.
Примеры использования разметки текста
Существует множество интересных областей применения для процессов аннотирования текста и NLP, а именно:
- тэгирование сообщений как спам и не-спам при распознавании спама
- объяснение значения текста и связи слов для машинного перевода
- классификация документов,
- проектирование бесед для чат-ботов
- извлечение ощущений и мнений потребителей из обзоров для анализа эмоциональной наполненности.
Разметка аудио для задач распознавания речи
Распознавание речи — это сфера искусственного интеллекта, позволяющая машинам понимать голосовые сообщения распознаванием произносимых слов и преобразованием их в текст. Аудиоинформация понятна людям, однако компьютерное оборудование не может понимать её семантическую структуру столь же легко. Чтобы справиться с этой проблемой, используется разметка аудио — процесс присвоения меток и транскрипций аудиозаписям и преобразование их в формат, который может понимать модель машинного обучения.
Идентификация говорящего
Идентификация говорящего — это процесс добавления в аудиопотоки размеченных областей и определения меток времени начала и конца речи разных людей. По сути, мы разбиваем входящий аудиофайл на сегменты и назначаем метки частям с голосами людей. Часто также размечаются сегменты музыкой, фоновым шумом и тишиной.
Аннотирование транскрипций аудио
Аннотирование лингвистических данных в аудиофайлах — это более сложный процесс, в дополнение к лингвистическим областям требующий добавления тэгов для всех окружающих звуков и транскриптов речи. Многие инструменты аннотирования аудио и видео позволяют пользователям комбинировать различные входящие данные, например, аудио и текст, в один простой интерфейс транскрипции аудио.
Инструмент Prodigy
После того, как речь преобразуется в письменный вид, в дело вступает уже рассмотренная нами ранее NLP.
Классификация аудио
Для выполнения задач классификации аудио живые аннотаторы прослушивают аудиозаписи и классифицируют по заранее заданным категориям. Категории могут описывать количество или тип говорящих, коннотацию, язык или диалект, фоновый шум или информацию, относящуюся
к семантике.
Аннотирование эмоциональной наполненности аудио
Как понятно из названия, аннотирование эмоциональной наполненности аудио используется для идентификации чувств говорящего: счастья, печали, гнева, страха, удивления и т. п. Этот процесс более точен, чем текстовый анализ эмоциональной наполненности, потому что в аудиопотоках есть множество дополнительных сигналов, как то громкость голоса, тон, скачки тона и скорость речи.
Примеры использования разметки аудио
Так как добавление меток в аудио- и видеофайлы является фундаментом распознавания речи, оно применяется в следующих областях:
- разработка голосовых помощников наподобие Siri и Alexa
- транскрибирование речи в текст
- предоставление контекста бесед для сложных чат-ботов
- измерение уровня удовлетворённости клиентов для звонков в техподдержку
- проектирование приложений для изучения языков и помощи в выработке произношения
Рекомендации по правильной организации разметки данных
Как вы могли понять, ручной труд по разметке данных — непростая задача. Чтобы преодолеть проблемы и сделать процесс максимально эффективным, можно воспользоваться описанными ниже рекомендациями.
Находите качественные сырые данные
Важным шагом к точным результатам модели машинного обучения является высокое качество сырых данных. Прежде чем давать задания по разметке, убедитесь, что данные адекватны задаче, хорошо очищены и сбалансированы. Иными словами, если вы создаёте модель для классификации изображений для распознавания кошек и собак, то неразмеченные данные должны включать в себя оба вида животных в равной пропорции и без шумных элементов.
Ищите специалистов в соответствующей сфере
Половина успеха проекта по разметке данных заключается в способности аннотаторов понимать предметную область. Всегда лучше нанимать специалистов, досконально знающих соответствующую отрасль и способных точнее и быстрее размечать данные.
Напишите инструкцию по аннотированию
Определитесь с техниками и критериями аннотирования, а затем соберите все важные аспекты в инструкцию. Она должна содержать подробно объясняемые примеры правильных, неправильных и пограничных меток.
Выполняйте контроль качества массивов данных
Никогда не стоит недооценивать важность QA-тестирования. Необходимо встроить процессы QA в конвейер разметки данных, чтобы разметка выполнялась в соответствии с заданными критериями, а ошибки исправлялись вовремя.
Назначайте несколько аннотаторов для перекрёстной разметки
Какой бы ни была задача аннотирования, всегда лучше, чтобы несколько аннотаторов (до трёх) перекрёстно разметило одинаковые данные для валидации тэгов. Благодаря этой практике вы сможете обеспечить высокую точность результатов.