

Привет, Хабр! Меня зовут Антон, я ведущий инженер по ИБ в компании R-Vision, принимаю активное участие в развитии экспертизы в части расследования инцидентов и реагирования на них. А в свободное время я увлекаюсь расследованиями в направлении Digital Forensics & Incident Response (DFIR), Malware Analysis.
В последнее время публичное пространство пестрит новостями о резонансных инцидентах в России и мире, связанных с фишинговыми атаками на крупные компании и государственный сектор.
Замечу, что одной из самых популярных техник взлома крупных мировых корпораций был и остается фишинг с вредоносным вложением T1566.001. Пожалуй, яркий тому пример – взлом Garmin в июле 2020 года, когда известный производитель умных устройств подвергся атаке хакеров-вымогателей. Преступники атаковали системы Garmin с помощью малвари WastedLocker. В результате, сервисы компании на три дня вышли из строя, так как авторы малваря зашифровали данные и требовали выкуп в размере $10 млн за ключи дешифровки.
Как известно, логика подобного проникновения в инфраструктуру довольно проста: атакующие проводят таргетированную фишинговую кампанию – targetor sprear [T1566.001], доставляют в корпоративную среду зловреды с помощью рассылки электронных писем с вредоносными вложениями и ссылками. Пользователь открывает файл (pdf, xlsx, docx и др.), тем самым запуская вложенный туда вредоносный код, который подгружает недостающие для атаки компоненты (вирусы, трояны, шифровальщики, бэкдоры и тд.).
В этой статье я не буду углубляться в тактики и инструменты фишинговых атак, а хочу поделиться с вами личным опытом разбора техники с фишингом вредоносного файла * pdf и наглядно продемонстрировать ход расследования подобного инцидента на примере лабораторного задания GetPDF с ресурса Cyberdefenders.
Для успешного прохождения задания GetPDF, нам необходимо будет ответить на 11 вопросов, касающихся файла Malware PDF.
Список вопросов для задания
1. How many URL path(s) are involved in this incident?
2. What is the URL which contains the JS code?
3. What is the URL hidden in the JS code?
4. What is the MD5 hash of the PDF file contained in the packet?
5. How many object(s) are contained inside the PDF file?
6. How many filtering schemes are used for the object streams?
7. What is the number of the 'object stream' that might contain malicious JS code?
8. Analyzing the PDF file. What 'object-streams' contain the JS code responsible for executing the shellcodes? The JS code is divided into two streams. Format: two numbers separated with ','. Put the numbers in ascending order
9. The JS code responsible for executing the exploit contains shellcodes that drop malicious executable files. What is the full path of malicious executable files after being dropped by the malware on the victim machine?
10. The PDF file contains another exploit related to CVE-2010-0188. What is the URL of the malicious executable that the shellcode associated with this exploit drop?
11.How many CVEs are included in the PDF file?
Прежде чем приступить, обращаю ваше внимание: если вы захотите провести подобное расследование самостоятельно, то крайне не рекомендуется выполнять его на реальном хосте. Для этого лучше поднять лабораторный стенд на виртуальной машине.
В моем случае лабораторный стенд для выполнения задачи состоит из двух хостов, соединённых между собой. Но при этом они имеют ограниченный средствами виртуальной машины VMWare доступ в сеть Интернет. Первый хост на Kali, второй под Windows 10.
В ходе подготовки лабораторного стенда для работы с Malware файлами, нам потребуется:
1. Ограничить доступ к сети;
2. Отключить мониторинг вредоносной активности в режиме реального времени Windows Defender (для хоста под Windows 10) до следующей перезагрузки. С помощью команды:
Set-MpPreference-DisableRealtimeMonitoring $true
Утилиты, которые будут использоваться
Wireshark — незаменимая утилита для разбора .pcap и анализа трафика;
NetworkMiner — утилита для анализа сетевого трафика, c GUI;
Pdf-parser.py — аналогичная утилита для анализа PDF;
Pdfid — показывает подробную информацию по PDF;
PDFStreamDumper — позволяет работать с PDF, имеет GUI и встроенные утилиты декодирования;
Origami — написана на perl, позволяет экспортировать streams, скрипты, картинки из pdf, работать с shell кодом, извлекать метаданные и многое другое;
scdbg.exe — для эмуляции и анализа вредоносного shell кода;
De4js — «JavaScript Deobfuscator & Unpacker»;
CyberChief — фреймворк для декодирования, деобфускации кода.
Итак, начнем.
Изучаем дамп трафика из задания
После загрузки архива из GetPDF на лабораторный стенд с заданием, в нашем распоряжении находится дамп трафика lala.pcap. Загружаем его в NetworkMiner. Этот дамп трафика предоставляет нам информацию о URL paths, которые были вовлечены в инцидент — их 6. Тем самым мы получаем ответ на Вопрос 1. How many URL path(s) are involved in this incident?
Для решения второго и последующих вопросов, необходимо подгрузить lala.pcap в Wireshark и выполнить следующие действия:
1. Файл —> Экспортировать Объекты —> HTTP (все)

2. Нажать ПКМ на поток трафика в окне WireShark с протоколом http и далее — «Follow»
После чего мы увидим GET – запрос с URL. Данный URL - ответ на Вопрос 2. What is the URL which contains the JS code? В запросе содержится вредоносный обфусцированный JS code.
Чтобы ответить на Вопрос 3. What is the URL hidden in the JS code?, нам необходимо продебажить обфусцированный JS код, чтобы получить скрытое содержимое. Для этого скопируем код в de4js и приведем его к нормальному виду. Посмотрев внимательно, можно понять, что после кода деобфускации в обфусцированную функцию передается переменная ZeJexn. Теперь давайте выведем содержимое этой переменной с помощью функции alert(ZeJexn):
Вот наша ссылка и ответ на третий вопрос!
В Вопросе 4. What is the MD5 hash of the PDF file contained in the packet? мы должны посчитать MD5 Хэш от ранее экспортированного через Wireshark файла fcexploit.pdf. Я сделаю это через PowerShell:
Get-FileHash -Algorithm MD5 fcexploit.pdf
И получу необходимый нам хэш:

Погружаемся в структуру файла PDF и его содержимое
Прежде чем переходить к анализу PDF файла, нужно разобраться со структурой файлов такого формата.
Если коротко, PDF файл состоит из:
заголовка (Header);
тела (Body);
таблицы перекрестных ссылок Cross-reference table;
и трейлера.

Header содержит информацию о версии %PDF-1.3.% — в нашем случае это также можно увидеть во время анализа http потока в дампе через Wireshark (как и остальные элементы документа).
Body документа содержит objects (streams), картинки и другие элементы.
Cross-reference table позволяет взаимодействовать с каждым из объектов, которые содержатся в теле.
Trailer определяет, как приложения будут читать документ, так как чтение документа начинается с конца (именно отсюда), где приложение находит Cross-reference table и обращается к объектам по ссылкам из таблицы.
Нам ничего не мешает добавлять наши новые Body, Cross-reference table, Trailer в конец существующего документа, неизменным останется лишь Header.
Разобравшись с архитектурой PDF файла, детальнее изучим содержимое Body. Здесь хранятся потоки объектов — последовательность байтов, которая может иметь неограниченный размер. У всех объектов есть идентификатор, по которому можно ссылаться для обработки PDF. Например, в нашем кейсе присутствует ссылка на объект «/JS 5 0 R», R — от reference. С помощью нее можно узнать содержимое какого объекта будет обработано на следующем этапе.
Кроме того, в PDF документе присутствует возможность работать с содержимым потока, использовав схемы фильтрации (/Filter), например, /Filter [/FlateDecode]. Это говорит о том, что данные были закодированы с использованием сжатия zlib/deflate….
Подробнее о структуре PDF можно почитать здесь.
Теперь, когда мы имеем представление о структуре PDF-файлов, можно ответить на остальные вопросы из лабораторного задания GetPDF.
Далее следует Вопрос 5. How many object(s) are contained inside the PDF file? Чтобы узнать ответ, воспользуемся pdfid и посмотрим на количество содержащихся объектов в PDF файле – их 19.
Обратите внимание, что количество obj != endobj значит, что документ деформирован (malformed).
Отвечая на Вопрос 6. How many filtering schemes are used for the object streams?, посмотрим еще раз на наш http поток в Wireshark’e. Мы увидим, что для object streams (например, 10) используется 4 схемы фильтрации:

Ответом на Вопрос 7. What is the number of the ‘object stream’ that might contain malicious JS code? станет уже ранее знакомая ссылка «/JS 5 0 R» из 4-го object stream’а.
Немного деобфускации содержимого потоков
Прежде чем продолжить, я выдерну дампы потоков с помощью pdfextract из Origami:
./pdfextract fcexploit.pdf

В первую очередь нас интересует 5-ый поток, ведь он содержит JavaScript Code и запись /Action, из-за которой исполняется JS Code из 5 object stream’a.
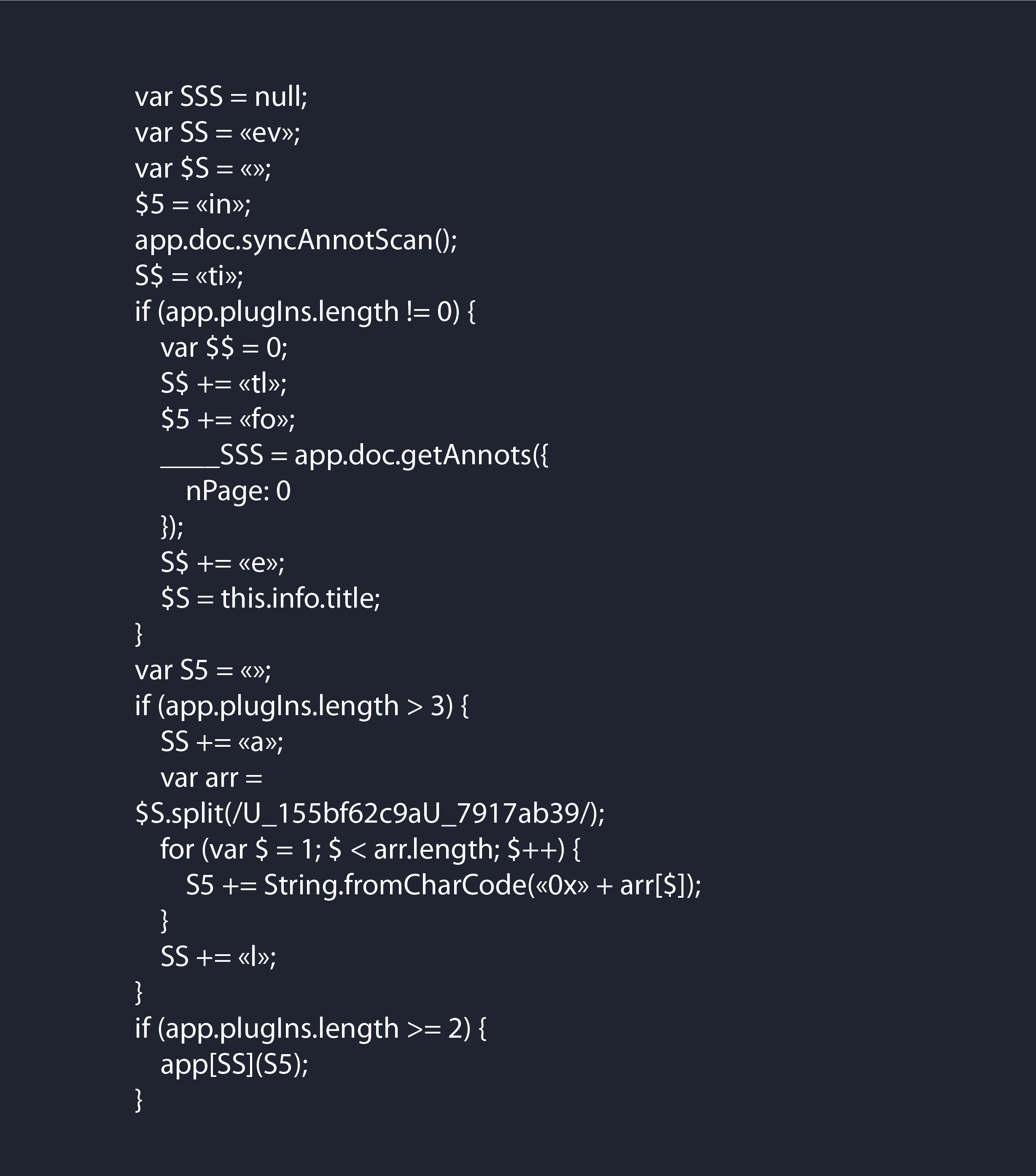
Теперь нам необходимо понять, что содержится в переменных:
“____SSS” & “$S ”
Мы с вами уже знаем, что чтение файла начинается с конца (с Trailer’а), поэтому, выполнив команду pdf-parser.py -v fcexploit.pdf получим структуру pdf.
Зайдя в Trailer, можно увидеть, что запись /Info ссылается на 11 obj:

Если посмотреть на 11 object, то мы увидим, что необходимая запись /Title находится в 10 obj, а это значит, что содержимое 10-го объекта помещается в переменную $S. Также видно, что 11 obj содержит поток байтов, однако, pdfextractor его не извлек.

Выходит, что дело за малым. Смотрим, что хранится в stream_10.dmp (извлечены в предыдущем шаге).
Получаем, что Сat stream_10.dmp содержит следующие данные:
U_155bf62c9aU_7917ab395fU_155bf62c9aU_7917ab395fU_155bf62c9aU_7917ab395fU_155bf62c9aU_7917ab395fU_155bf62c9aU_7917ab3953U_155bf62c9aU_7917ab3953U_<……..>7917ab3924U_155bf62c9aU_7917ab3929U_155bf62c9aU_7917ab393b
А дальше надо деобфусцировать его содержимое. Можно, конечно, пойти в CyberChief, но мы воспользуемся открытой консолью браузера. После чего по коду 5-го stream’а будет видно, что идет преобразование массива из 16-го формата в ASCII. Поэтому продебажим на ходу.
Передадим в переменную S содержимое 10 потока, а далее применим кусочек кода из 5-го потока для деобфускации:

Деобфусцированное содержимое10 потока
De4js помог привести код к читаемому виду:

Выше мы видим деобфусцированное, приведенное к читаемому виду содержимое переменной $5. А в 5-ом потоке содержится app.doc.getAnnots({nPage:0});. В документе у нас всего 3 объекта, содержащих записи /Annot:

Внимательно посмотрев на содержимое этих объектов, увидим ссылки на другие не менее интересные объекты 7 и 9 с потоками байтов (видно /Lenght...). Собственно, это и есть ответ на Вопрос 8. Analyzing the PDF file. What ‘object-streams’ contain the JS code responsible for executing the shellcodes? The JS code is divided into two streams. Format: two numbers separated with ‘,’. Put the numbers in ascending order.
Объекты 7 и 9 интересны нам еще и тем, что содержат в себе потоки. При этом-pdfextract из Origami уже все сам извлек, осталось просто заглянуть в их содержимое и после деобфусцировать.
Исходя из деобфусцированного кода 10-го потока видно:


Обфусцированное содержимое потока stream_7.dmp выглядит так:
89af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889af50d3889a<….>d7489af50d6989af50d6f89af50d6e89af50d2889
Как и обфусцированное содержимое потока stream_9.dmp выглядит так:
17098774320X_17844743X_17098774320X_17844743X_17098774320X_17844743X_170987743 20X_17844743X_17098774320X_<….>17844743X_17098774320X_17844743X_17098774320
Здесь для деобфускации все же воспользуемся CyberChief и напишем свой рецепт, исходя из кода 10-го потока.
В итоге получилось следующее:

Код довольно большой и содержит 4 эксплойта:
calc.exe payload — CVE-2009-4324
freecell.exe payload – CVE-2008-2992
notepad.exe payload – CVE-2007-5659
cmd.exe payload – CVE-2009-0927
Перед анализом payload нужно аккуратненько сложить в *.sc или *.exe файл. Для этого воспользуемся сайтом shell2exe, где на вход подадим payload, а на выходе нас будет уже ждать exe-файл.
После чего добавим shellcode.exe в IDA Pro или x32 Debugger. И становится видно, что для 4-го эксплойта полный путь после подгрузки malware4 – C:\Windows\System32\a.exe. Это и будет ответом на Вопрос 9. The JS code responsible for executing the exploit contains shellcodes that drop malicious executable files. What is the full path of malicious executable files after being dropped by the malware on the victim machine?

Помним, что 11-ый объект содержит поток, но pdfextractor (из Origami) его не извлек, поэтому давайте посмотрим через PdfStreamDumper.exe. Экспортируем все потоки через ПКМ - Save all decompressed streams, так как в схеме фильтрации используется [/FlateDecode], а нам уже известно, что это говорит о степени сжатия данных zlib/deflate. Исходя из этого, я применю к потоку zlib decode. Для чего надо запустить: Tools – Zlib Decompress_File для 11-го извлеченного потока.
Таким образом, мы получим следующее содержимое:

Исходя из 10 вопроса задания (The PDF file contains another exploit related to CVE-2010-0188. What is the URL of the malicious executable that the shellcode associated with this exploit drop?), мы искали и нашли CVE-2010-0188 (подробнее по ссылке). По описанию эксплойта используется LibTiff, что мы и видим здесь. Чтобы ответить на 10 вопрос можно пойти 2-мя путями:
Легкий, у нас уже есть загруженные файлы и URL из первого вопроса http://blog.honeynet.org.my/forensic_challenge/the_real_malware.exe — этот URL и будет являться ответом на 10 вопрос.
")
Чуть более трудоемкий, но интересный путь – скопировать содержимое payload’a эксплойта, декодировать из base64, упаковать, запустить в scdbg.exe.
Итого, в исследуемом нами файле было обнаружено 5 эксплойтов и это ответ на последний Вопрос 11. How many CVEs are included in the PDF file?.
Заключение:
Анализируя PDF файл, мы познакомились с выше перечисленными утилитами, узнали структуру файлов такого формата, деобфусцировали JavaScript Code и, в итоге, нашли 5 эксплойтов. Безусловно, решить задание Get PDF на платформе Cyberdefenders.com можно было и с помощью меньшего набора утилит, однако, в статье я также хотел более подробно вас с ними познакомить. Более глубокий анализ вредоносных вложений можно найти здесь.
Надеюсь, изложенная мною информация пригодится в решении ваших реальных кейсов! Всем удачи!
Автор: @AntonyN0p Антон Кузнецов, ведущий инженер информационной безопасности R-Vision
Комментарии (7)

Chelidonium
17.08.2022 18:32может, с точки зрения простого пользователя, лучше на все скачаные pdf сразу
ставить восьмеричный атрибут 0444 и открывать их не в браузере, а в вьювере

ALito
18.08.2022 08:27Я правильно понимаю, что на Линукс такие зловреды не будут работать? Нужно ведь запустить приложение, а для этого сделать файл исполняемым, что потребует рут прав.
А вообще зреет, как и груши в саду, у меня желание отключить совсем JS в браузере. Включать его только иногда, когда совсем уж припрет.

HappyGroundhog
18.08.2022 09:13+2Не совсем. Флаг запуска +x прекрасно ставится и без рут прав. Более того, в линуксе тот же скрипт можно запустить как ./evil-script.sh, тогда он потребует прав на исполнение, но можно и как «bash evil-script.sh». Тогда права у файла могут быть только read.
Без прав рута системе навредить сложнее, но тут в дело вступают инфостилеры, им не нужны рутовые права, ваши данные STEAM или пароли в браузере они утащат и так и с радостью подключат вас к скрытому майнингу + если вдруг не обновляли систему давно, то тот же polkit предоставит им рутовые права.
Под Linux системы сейчас выходит достаточно много малвари, попробую сделать разбор интересной в ближайшее время)

AlexeyK77
Класс!
Какое по вашему мнению самый эффективный инструмент противодействия или набор мер безопасности, что бы минимизировать вероятность неприятностей от таких специально сконструированных зловредных нагрузок? ( с учетом что сеть большая, пользователей много, и кто-та по закону больших чисел да купится на фишинг).
AntonyN0p
Действительно, вероятность открытия вложения из письма пользователем есть. Но минимизировать ущерб от подобного рода атак, Вам помогут в совокупности:
1.Правильно выстроенная архитектура сети и отлаженный процесс реагирования на инциденты.
2.Постоянный мониторинг неизвестной ранее активности в сетевом трафике и на хостах.
3.Правильно настроенные средства защиты информации и высококвалифицированные специалисты ИБ.
4. Организационные меры (обучение сотрудников/проведение фейковых рассылок в организации).
AlexeyK77
Спасибо.
Из своего опыта борьбы с подобными зловредами, очень эффективно, когда средства безоапсности, умеет не просто "проверять антивирусом", а задавать политики контроля структуры документов, например:
на периметре:
1) если документ msoffice, pdf содержит скрипты или внедренные OLE объекты - в треш сразу, без игр с антивирусом.
локально:
2) если процесс адоба, ворда и т.п. создает (create file) исполняемый файл или запускает из себя внешний процесс (exec process) - блокировать. (это упрощенное описание поведенческих политик а-ля лайт песочница)
и т.п.