
Привет, Хабр!
Если ваш проект вырос, в нем бэкенд с фронтендом, различные точки входа API, интеграции с внешними системами, сложные алгоритмы, проверки введенных данных пользователем на валидность, диаграммы бизнес-процессов имеют тысячи ветвей, то скорее всего регрессионное тестирование занимает кучу времени, и проводить его вручную уже невыгодно. Проще эту работу поручить машине и тестировать продукт автоматически. Первый вопрос, который возникает — «Как генерировать данные?», а конкретнее, как генерировать то, что может ввести пользователь. Этот вопрос мы и разберем в данной статье.
Обычно введенные строки сравнивают с некими шаблонами, среди которых наиболее распространенный– RegExr (регулярное выражение). Самый логичный способ — тестировать шаблон шаблоном.
Что такое и из чего состоит RegExr:
RegExr — шаблон, в котором представлена совокупность правил для конкретных позиций в строке.

Для единичных символов понятно, на этой позиции может быть только он. А в квадратных скобках указаны возможные варианты символов, например [1-9#] на этой позиции возможны только символы — 123456789#, а для правила [^@\.] возможны любые символы кроме @ и . (напомню, что символ ^ после открывающей скобки означает «кроме»)

Квантификатор даёт нам информацию о том, на сколько позиций распространяется символ или символьная группа перед ним.
Квантификатор |
Использование |
{n} |
Ровно n повторений |
{m,n} |
От m до n повторений |
{m,} |
Не менее m повторений |
{,n} |
Не более n повторений |
? |
Ноль или одно повторение То же, что и {0,1} |
* |
Ноль или более повторений То же, что и {0,} |
+ |
Одно или более повторений То же, что и {1,} |

Все как в алгебре, скобки группируют и в основном работают с квантификаторами. В примере выражение в скобках может повторяться один и более раз:

Логика “или” позволяет сделать наше выражение более эластичным. В примере строка может состоять либо из 6 цифр, либо из 10. Выражений разделенных элементом | может быть сколько угодно, но на этом месте может быть только одно из них.
Проблематика:
Например, поле email не принимает случайный набор символов, естественно там присутствует проверка через регулярное выражение, и в самом простом виде это [^@]+@([^@\.]+\.)+[^@\.]+. Соответственно, нам нужно либо захардкодить значение на каждое поле, либо при каждом тесте генерировать строку, которая подойдет под это выражение.
Чем обернется хардкод:
1. Вы не сможете поддерживать свои тесты, так как ваш продукт меняется, и искать часами, где именно прошлый разработчик указал данные для этого поля долго и невыгодно.
2. Возникает риск ошибки, ведь по основному принципу тестирования мы тестируем черный ящик и не знаем какое там регулярное выражение, так как программист мог спокойно указать [^@]+@[^@\.]+\.[^@\.]+, и misha@mail.ru пройдет, а diana@inform.bigdata.ru нет.
3. Банально под ваши тесты могут подогнать регулярное выражение :)
Соответственно, правильно будет каждый раз генерировать новую случайную строку. Рекомендую писать свое регулярное выражение для генерации, основываясь на ТЗ, а не таскать их из кода. Для того, чтобы сгенерировать случайную строку, нужно решить две основные проблемы:
1. Какие рамки поставить для квантификаторов +, {m,}, *. Ведь бесконечное количество символов мы сгенерировать не можем, а строка из тысячи символов только нагрузит интерфейс и особо никак не повлияет на тестирование. Тут нужно найти баланс и случайно не написать стресс-тест.
2. Откуда брать символы для генерации такого выражения — [^@\.]? Из таблицы ASCI? Но там довольно много специальных символов, и в итоге мы получим непонятную кашу.
Ответив на эти вопросы, мы сможем реализовать генерацию. Первый вопрос решается выбором верхней планки длины строки или квантификатора, например 50 символов. А второй — собственной библиотекой символов для проекта.
Задача:
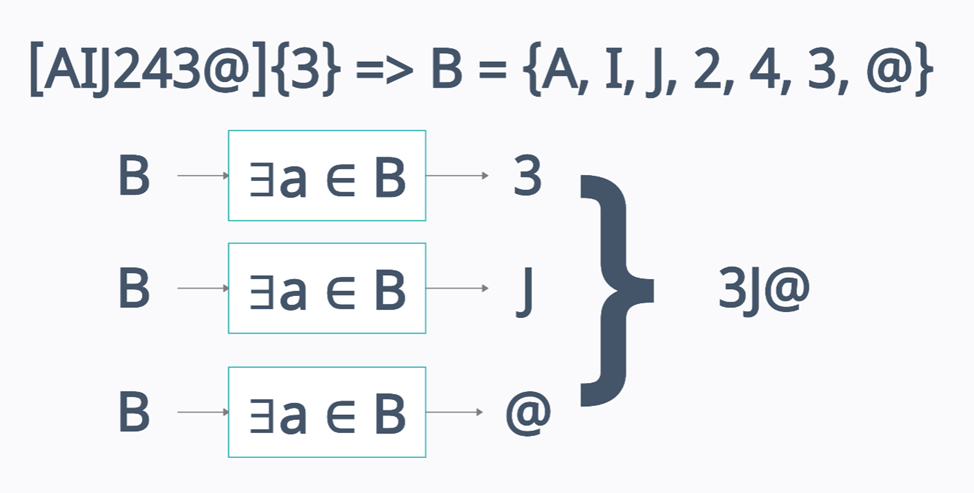
Для генерации строки из выражения нужно разложить его на такие части, которые будет принимать конечный автомат. То есть нужно привести к такому виду, что некая функция будет принимать его части на вход (множество символов B), выбирать такой символ a, который принадлежит этому множеству и выдавать этот символ.

Метод генерации строки из регулярного выражения
Приведу свою блок-схему алгоритма генерации включающую в себя 5 основных этапов:
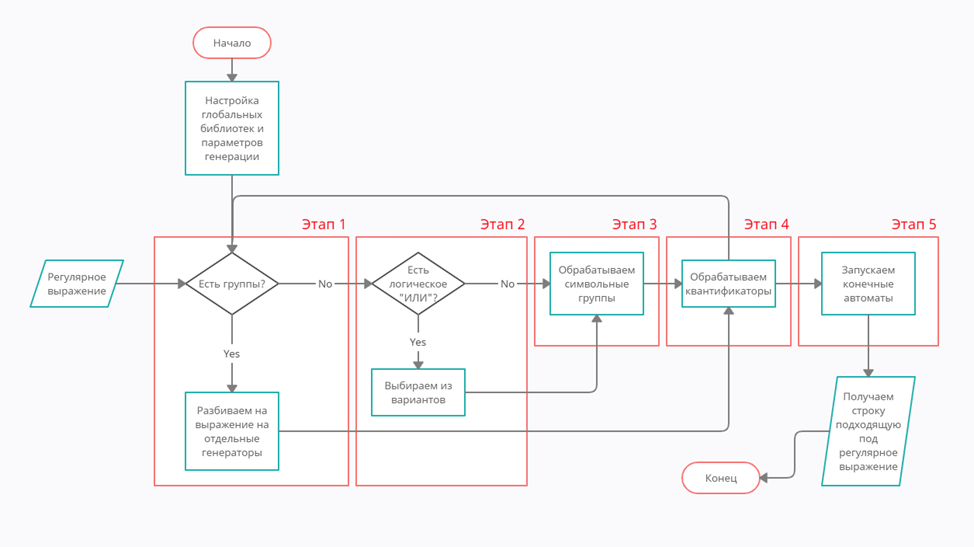
1 Этап — декомпозиция основного выражения на подгруппы:

2 Этап — выбор между возможными вариантами:

Для оптимизации времени выполнения алгоритма, этот этап выполняется сразу после декомпозиции и позволяет не тратить времени на генерацию ненужных символов.
3 Этап — обработка символьных групп:

На этапе происходит замена шаблонов и формирование множеств для конечных автоматов.
4 Этап — обработка квантификаторов:

На этом этапе нам требуется выбрать конкретные значения для квантификаторов. Тут мы сталкиваемся с проблемой описанной ранее, квантификаторы +, *, {n,} представляют диапазоны чисел от n до бесконечности, с такими диапазонами мы работать не можем, поэтому требуется ограничение, например от n до n + 50. Потом для диапазонов нам нужно выбрать конкретное значение, оно и будет означать количество запусков конечных автоматов. Далее мы «разворачиваем» выражения в круглых скобках в зависимости от значения их квантификатора.

Отмечу, что мы должны рекурсивно запускать алгоритм для каждой группы столько раз, сколько указано в её квантификаторе.

Приведу пример работы квантификатора, который должен запускать именно то количество конечных автоматов, которое указано для него, а не «умножать» результат работы.
5 Этап — Запуск конечных автоматов.
После всех этих этапов мы получаем общность конечных автоматов, которые и требуется запустить:

Зачем изобретать велосипед?
Увы, но нет универсальных решений, и под свои задачи нужно либо модифицировать, либо писать что-то самостоятельно. Например, на нашем проекте для автоматического тестирования API был выбран язык Python. Он простой, удобный, и обучение специалиста, который сможет поддерживать фреймворк — дело буквально месяца-двух. У нас несколько требований к библиотеке генерации случайных строк:
Быстрая;
Удобная;
Должна поддерживать основную лексику регулярных выражений;
В начале и конце сгенерированной строки не должно быть пробелов.
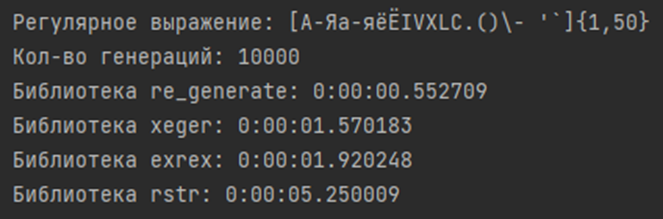
В своих поисках мы нашли 4 библиотеки: xeger, strgen, exrex, rstr.
Strgen – самая быстрая, практически идеальна, но не поддерживает многие квантификаторы.
Xeger — реализована не самая удобная работа с библиотеками символов и первоначальными настройками.
Rstr — Не самая стабильная библиотека, в некоторых моментах работает в 5 раз медленнее других.
Exrex — генерирует 1000 случайных строк в среднем за 2 секунды, не критично, но можно лучше.
Хотелось бы получить универсальную, быструю библиотеку, подходящую под наши требования. Вот так и появилась на свет библиотека re_generate (pypi.org/project/re-generate). Получилось даже лучше, чем мы думали, уже до оптимизации алгоритм выдает хорошие показатели в сравнительных бенчмарках:
Итог:
Если вы не нашли уже готового решения для вашего проекта, рекомендуем реализовать этот алгоритм, таким образом вы получите практику и прекрасный инструмент для работы. Забирайте в свои проекты, пользуйтесь, реализуйте. Спасибо за внимание!
Комментарии (7)

estet
16.01.2023 13:41+1Почему не использование библиотеки Hypothesis со стратегией from_regex?

PPR Автор
18.01.2023 13:54Очень крутая библиотека, влюблены в нее, но она увы про другое и конкретно нам не подходит, так как используем свой фреймворк для запуска тестов. Стратегии генерируют не просто данные, а удобную композицию для тестовой функции, которую можно прогнать через PyTest. Можно конечно использовать стратегию как генератор, но это будет дольше и усложнит код.

nin-jin
Так и не понял зачем генерировать случайную строку, которая гарантированно проходит проверку по регулярке. Это вы так тестовые данные готовите, чтобы тесты никогда не падали?
PPR Автор
RegExr очень прост для описания того, что должно быть в строке и очень удобен для кода. Разработчик и тестировщик получают техническую документацию на функционал, где дано не регулярное выражение, а описание требования к полю. После этого разработчик описывает эти требования регуляркой, а тестировщик описывает возможные кейсы своими RegExr. Реальный пример:
Требования к одному из полей — Только русские буквы и любое число в конце
Разработчик повесил на поле паттерн ^[А-Яа-яёЁ]+\d$
Тестировщик описал положительный кейс: ^[А-Яа-яёЁ]+([1-9]\d*|0)$ (Так как там должно быть именно число в конце. Числа не начинаются с 0, кроме 0)
и отрицательные кейсы:
^[^А-Яа-яёЁ][1-9]\d*$ (проверит можно ли ввести что-то кроме русских букв)
^[А-Яа-яёЁ]+0[1-9]+$ (проверит пропустит ли набор цифр)
^[А-Яа-яёЁ]+[^0-9]$ (проверит можно ли что-то передать кроме числа)
В итоге после тестирования стало понятно, что задача будет отправлена на доработку.
nin-jin
Если у вас даже тестировщик пишет регулярки ввиду того, что ими крайне просто описывать , то зачем их вообще тестировать? Или вы сам движок регекспов тестируете?