
У нас в SberDevices очень сильная команда, разрабатывающая и развивающая решения в сфере речевых технологий. Раньше мы уже рассказывали о том, как обучить модель распознавания речи на открытых данных, и о том, как устроен наш синтез.

Однако, помимо распознавания и синтеза речи, мы развиваем технологии распознавания эмоций голоса для линейки наших умных устройств, а также для решений, позволяющих анализировать общение по телефону. Например, на этой технологии базируется наш новый продукт SaluteSpeech Insights, который автоматически оценивает эмоции клиента и оператора колл-центра по каждой произнесённой ими фразе, классифицирует все диалоги на позитивные, нейтральные и негативные, определяет более 300 различных речевых характеристик, а ещё прогнозирует оценку CSI (Customer Satisfaction Index).
Передаю слово одному из авторов датасета, моему коллеге Владимиру Кондратенко.
Когда мы приступили к решению задачи по распознаванию эмоций в устной речи, мы столкнулись с нехваткой открытых данных, особенно на русском языке. Общепризнанный бенчмарк для Speech Emotion Recognition (SER), IEMOCAP насчитывает всего лишь 5к семплов/12 часов аудио. Поэтому мы собрали свой датасет на 320к семплов/350 часов аудио и решили продолжить славную традицию, выложив его в открытый доступ. Дополнительно мы опубликовали сырые данные разметки до агрегации и код для обучения бейзлайнов.
Таким образом, мы преследуем две цели: предоставить хороший бенчмарк для задачи SER и дать толчок развитию области распознавания эмоций, так как наш датасет отлично подходит для исследовательских целей.
Обзор прошлых датасетов
За годы работы над решением задач, связанных с распознаванием эмоций, было собрано множество разнообразных наборов данных. Они отличаются между собой языком, модальностями (могут включать видео и текст), разметкой, натуральностью эмоций (естественные или игра актёров) и объёмом данных. Хороший разбор уже был представлен нашими коллегами вот в этой статье. Мы не будем повторяться и ещё раз перечислять существующие наборы, которые там уже достаточно подробно описаны, но напомним ключевые мысли этого поста:
Проблема создания эмоциональных датасетов во многом заключается в определении звучащей эмоции. При разметке таких данных сложность заключается в неоднозначности интерпретации эмоции теми, кто их оценивает. Эту проблему можно решать с помощью увеличения количества «судей». Правда, это не гарантирует, что их оценка будет согласована.
Не всё хорошо с объёмами данных в открытых датасетах для решения задач распознавания эмоций. Если датасеты с большим количеством семплов и находятся (к примеру, CMU-MOSEI, MURCO), то у них очень ярко проявляется проблема из п1.
Де-факто, в подавляющем большинстве случаев, бенчмарком для новых моделей распознавания эмоций является англоязычный датасет IEMOCAP с игрой профессиональных актёров. Иногда EMO-DB, ещё реже — все остальные. Искусственность эмоций не берём в расчёт, но малый объём данных этих бенчмарков усложняет работу с ними и с проверкой полученных моделей в естественных условиях.
Сбор Dusha
Столкнувшись с описанными выше проблемами, мы решили собрать свой датасет для распознавания эмоций и назвали его Dusha, по аналогии с датасетом для распознавания речи — Golos.
Первая часть нашего датасета состоит из реплик, озвученных с помощью краудсорсинга. Для её формирования прежде всего нужно было получить тексты, которые и будут озвучены. Да, можно было взять тексты из открытых источников и озвучить их, но есть несколько подводных камней.
Во-первых, если текст по смыслу негативный, то попытка произнести его с позитивной интонацией будет не очень реалистичной (то же самое, если переставить позитив и негатив местами).
Во-вторых, реалистично озвучить какую-то белиберду с эмоциональным окрасом тоже затруднительно. Поэтому нам пришлось немного заморочиться, следите за руками.
Мы решили взять тексты, максимально похожие на реальные запросы пользователей к виртуальным ассистентам Салют. Однако оказалось, что большинство из них носят довольно рутинный характер, без намёка на эмоции. Например:
«Салют, включи YouTube»
«Салют, поставь будильник на 7:00»
При этом у наших ассистентов есть специальный режим, в котором с ними можно поговорить на произвольные темы — для этого нужно сказать: «Давай поболтаем». Между собой мы его так и называем — «болталка». Для решения нашей задачи мы сгенерировали тексты, похожие как раз на общение с ассистентами Салют в режиме «болталки».

Чтобы оценить распределение эмоций в текстах, мы попросили группу разметчиков отнести каждый текст к одной из групп (ниже часть их инструкции для разметки):
Позитив: хвастается успехами («я получил пятерку»), вокруг происходит что-то хорошее («у нас классная погода», хвалит кого-то («он очень умный»), смех (есть «ха-ха» в тексте), поздравление («с Новым годом»), что-то понравилось («эта песня мне нравится»), хочу дружить/давай дружить.
Грусть: скучно/грустно/печально или плохое настроение, текст, требующий сочувствия («заболел хомячок», «что-то с ногой, хромаю»), что-то не получается («не могу уровень пройти»), жалуется на работу, погоду и т. д., («замучали меня», «я не могу на улицу выйти уже две недели»).
Злость/Раздражение: нецензурная лексика/оскорбления/ угрозы («я тебя сломаю», «слышь, я не буду это делать»)/раздражение («ты врёшь мне», «я сказала выйти из меню»)/что-то не работает, не включается.
Нейтраль: если текст не подходит ни под одну из всех остальных эмоций/люди запрашивают музыку, фильм или какой-то другой контент.
Совсем непонятно: так предлагалось помечать записи, если текст совсем несвязный.
Оказалось, что подавляющее большинство текстов нейтральные. Чтобы отобрать больше «эмоциональных» текстов, мы обратились к коллегам, у которых есть модель для классификации эмоций по тексту на основе BERT. Используя только что размеченный датасет для каждой эмоции, мы подобрали пороги, чтобы предсказания модели были достаточно точными (precision не ниже 0.8). Затем прогнали сгенерированные тексты через модель, отобрали часть из тех, на которых текстовая модель достаточно уверена и, немного подкорректировав баланс классов, чтобы «эмоциональных» текстов было больше, чем на потоке, получили пары текст = эмоция.
Следующий шаг — озвучить полученные тексты. Для этого мы попросили разметчиков произнести их с интонацией, «не противоречащей» эмоции от BERT — с этой же эмоцией или нейтралью. Например, для «позитивного» текста мы случайно выбирали для озвучивания позитив или нейтраль, для «грустного» — грусть или нейтраль, для «злого» — злость или нейтраль, для «нейтральных» текстов — нейтраль. Так, каждому из разметчиков были даны текст и эмоция, с которой предлагалось его произнести:
Позитив: текст с такой эмоцией необходимо произносить с улыбкой или смехом, стараться делать выраженные ударения на словах, подчеркивающих позитив.
Нейтраль: прочитать фразу максимально «плоско», не выражая никаких эмоций.
Грусть: произносить текст с грустью, как будто у тебя был тяжелый рабочий день или приболел хомячок.
Злость/раздражение: надо злиться, кричать, негодовать.
Осталось убедиться в том, что разметчики поняли нас правильно и действительно произнесли тексты так, как мы хотели. Для этого мы привлекли вторую группу разметчиков, которая слушала полученные записи и по аналогичной инструкции определяла, с какой интонацией без учёта текста была произнесена та или иная фраза. В итоге в наш датасет мы отобрали записи, в которых услышанная второй группой разметчиков эмоция совпала с той, которую мы «заказывали» первой. Эту часть датасета мы назвали Crowd.
Так как в реальности живые эмоции могут несколько отличаться от озвученных, с помощью краудсорсинга была добавлена вторая часть датасета. В ней мы постарались собрать семплы с реальными эмоциями в разговорной речи и сохранить пропорции между ними (спойлер — нейтраль преобладает).
Для этого мы взяли короткие нарезки русскоязычных подкастов, содержащие до пяти слов. Все аудиозаписи были сделаны на профессиональные микрофоны, которые вряд ли используются людьми на краудсорс-платформах для озвучивания текстов, что делает представленный в данной статье набор данных ещё более разнообразным.
Исходное качество аудио варьировалось от 48KHz до 16KHz, поэтому данные были унифицированы и приведены к единому, наиболее распространённому качеству, 16KHz.
Для этих аудиозаписей разметчикам предлагалось определять эмоцию, опираясь исключительно на звуковую дорожку без учёта произнесённого в ней текста. Выбирать эмоцию предлагалось из пяти вариантов:
Позитив: текст произнесён с улыбкой, смехом, восхищением, игривым тоном, или есть выраженные ударения на словах, подчеркивающих позитив (например, «вот ты красАвец!», «АХ, как здорово»).
Грусть: текст произнесён с грустью/тоской, потухшим голосом.
Злость/раздражение: если текст произнесён со злостью, раздражением, или пользователь кричит, говорит сквозь зубы, или есть выраженные ударения на словах, подчеркивающих негатив (например, «да пошёл ты!», «как ты задолБАЛ»).
Нейтраль: голос ровный, никакой характерной эмоции в голосе нет. При этом даже, если текст явно негативный (например, «да как ты надоел») или позитивный (например, «какой ты молодец»), в голосе эта эмоция не выражается, тогда необходимо ставить нейтраль.
Совсем непонятно: если запись слишком тихая, шипение, стук и никаких голосов.
Эту часть датасета мы назвали Podcast.
Во всех заданиях перед разметкой каждому из аннотаторов необходимо было пройти обучение и экзамен, который показывал, как каждый из них решает эту задачу. Те разметчики, которые не смогли выполнить экзаменационное задание с ожидаемым качеством (>80% верных ответов относительно «идеальной» разметки авторов статьи), не допускались до разметки и, соответственно, в представленный датасет включены не были.
Описание датасета
Итого мы собрали большой набор данных. Полученный датасет состоит примерно из 300 000 аудиозаписей, суммарная длительность которых около 350 часов. Так как каждая запись размечалась несколькими аннотаторами, которые время от времени ещё выполняли контрольные задания, то в разметке у нас получилось около 1,5 млн записей.
В исходной неагрегированной таблице данных содержатся следующие поля:
audio_path — путь к аудиофайлу;
annotator_id — уникальный идентификатор разметчика, который оценивает эмоцию;
annotator_emo — эмоция, которую указал разметчик;
golden_emo — эмоция контрольного задания;
speaker_text — текст, который произнёс диктор;
speaker_emo — эмоция, которую выражал диктор («заказанная» эмоция для разметчика-диктора из первой группы для семплов из Crowd, None для семплов из Podcasts);
source_id — уникальный идентификатор диктора или подкаста.
Агрегация разметки проходит при помощи алгоритма и порога 0.9, выбранного эмпирически. При этом поля «annotator_id» и «annotator_emo» объединились в одно поле «emotion». По полю «golden_emo» отфильтрованы контрольные задания. Таким образом, список полей после агрегации получился следующий:
audio_path
emotion
speaker_text
speaker_emo
source_id
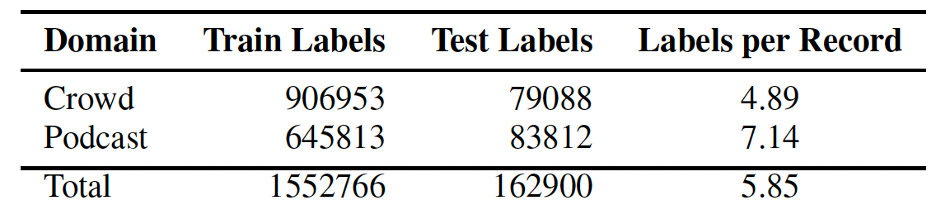
Объём данных после агрегации с разбивкой по подмножествам приведён в таблице:

Изменяя алгоритм агрегации или порог фильтрации, можно получать немного другой датасет по размеру и качеству, поэтому наш датасет отлично подходит для сравнения различных алгоритмов агрегации.
Еще интересно посмотреть распределение количества записей внутри класса и длительности:


Можно заметить, что в домене Podcast нейтральная эмоция преобладает сильнее, чем в домене Crowd, что соответствует реальному распределению эмоций в речи. Длительность домена Podcast не превышает 5 сек.
Описание репозитория
Мы создали страницу датасета на GitHub.
В репозитории вы найдёте ссылки на 4 архива, в которых содержится:
вся неагрегированная разметка и аудио семплы;
предпосчитанные для всех аудио Mel-filterbank признаки;
сагрегированная разметка, разбитая на треин и тест.
Дополнительно мы подготовили код и Docker образ, которые позволяют:
воспроизвести предложенную агрегацию разметки и попробовать свою;
обучить предложенную базовую модель/попробовать что-то свое.
В общем и целом, мы собрали всё необходимое для исследования этой задачи.
Заключение
Мы опубликовали наш датасет для того, чтобы у сообщества появилась возможность для исследований и построения систем в области распознавания эмоций на русском языке. Для сравнения моделей можно использовать Dusha как бенчмарк. «Подкастную» часть датасета можно использовать для оценки того, насколько решения готовы ко встрече с реальными эмоциями. Выложенный с датасетом код снижает порог входа, что позволяет использовать Dusha и в серьёзных исследованиях, и при написании курсовых работ, и в своих pet-projects «для души». Датасет может быть полезен и для других языков, если использовать данные для предобучения моделей. Надеемся, что корпус подтолкнёт развитие данного научного направления.
Мы планируем и дальше развивать и дополнять наш репозиторий, добавляя текстовые лейблы для всех записей, и, таким образом, сделать наш корпус полностью бимодальным. Модели, использующие и голос, и текст, должны показать более высокую точность, как, например, это происходит на корпусах других языков. Не исключаем, что в будущем Dusha расширится и наполнится другими эмоциями.
Спасибо, что дочитали до конца!
Над датасетом работали: Артем Соколов, Федор Минькин, Никита Савушкин, Николай Карпов, Олег Кутузов, Владимир Кондратенко.
Мы активно внедряем наши наработки. Например, определение эмоций уже доступно в рамках сервиса распознования речи SaluteSpeech. Также распознавание эмоций используется в нашем новом продукте SaluteSpeech Insights.
Присоединяйтесь к нашей команде, чтобы развивать речевые технологии вместе! Также приглашаю в Telegram-чат Salute AI Community, там можно задать вопросы и пообщаться с авторами Dusha и другими разработчиками SberDevices.
Комментарии (6)

NXZFT
00.00.0000 00:00+1Лучше бы писали статьи без упоминания слова "сбер". Любое упоминание этого ругательного слова - моментальное отторжение и раздражение...

ilia_bonn
00.00.0000 00:00Например, на этой технологии базируется наш новый продукт SaluteSpeech Insights, который автоматически оценивает эмоции клиента и оператора колл-центра по каждой произнесенной ими фразе, классифицирует все диалоги на позитивные, нейтральные и негативные, определяет более 300 различных речевых характеристик, а еще прогнозирует оценку CSI (Customer Satisfaction Index).
Прям 1984 какой-то - как минимум, с точки зрения оператора, думаю, должно быть такое ощущение, если он знает, что за качеством его работы постоянно наблюдает и оценивает её по 300+ параметрам ИИ
snakers4
Погодите-погодите. У вас умная колонка (которая уже следит за эмоциями пользователей судя по этой статье), но эмоциональный датасет вы собираете с помощью крауд-сорсинга или из подкастов. Хм.
При этом взвешенная точность на "наигранном" датасете получается примерно (при выборе из 4 вариантов) 75%, а на подкастах 50%. Это конечно выше, чем 25%, но такое конечно, но:
Ну то есть вы уже продаете это заказчикам, даже когда точность мягко говоря не фонтан? Современные проблемы и правда требуют современных решений! Я просто видел пару презентаций распознавания эмоций по речи … и там всегда написано про 99%+
AlexanderDenisenko
На заборе тоже много чего написано. Поделитесь конкретными статьями или продуктами? Я бы с радостью почитал
vldmrkondrat
Мы собирали этот датасет для того, чтобы выложить его в opensource. Можно было бы использовать и другие источники, но, кажется, подкасты это наиболее близкий домен к реальным эмоциям в разговорной речи.
Мы выложили код для обучения бейзлайнов. Нашей целью не было показать классную модель, наша цель здесь - снизить порог входа, чтобы можно было быстро поэксперементировать с нашим датасетом и своими архитектурами.
На данный момент доступ к SaluteSpeech Insights предоставляется вместе с доступом нашему сервису синтеза и распознавания речи SaluteSpeech без дополнительной платы.
Более того, Insights работает на данных из телефонии, там другие данные, другой звук и другой спектр эмоций)
Что касается качества распознавания эмоций в сервисе SaluteSpeech. Вы же понимаете, как устроено обучение подобного рода моделей? Для наших "боевых" решений мы используем другие данные и другие модели. Как минимум, в "проде", мы учитываем не только интонацию голоса (как в опубликованных моделях), но и произносимый текст, не говоря уже об архитектурных отличиях и куче маленьких трюков (о которых мы когда-нибудь обязательно расскажем)
Было бы интересно посмотреть на ваше ультимативное сравнение с конкурентами.
Так что буду рад, если вы обучите свою модель на нашем датасете и поделитесь результатами)
snakers4
А я буду рад, если вы вернете средства из ФНБ налогоплательщикам.
Единственное, что хоть как-то работало в этой сфере, что я видел - было просто очень продвинутым набором словарей. Что по сути эта статья и подтверждает.