

Здраствуйте читатели)
Перед тем как начать, хочу отметить, что данная статья служит для любопытствующих людей и тем, кому нужно базовое теоретическое знание MapReduce'а. Сам по себе MapReduce уже устарел. Если вы в поиске хороших решений, то увы, в этой статье не будет вестись речь о готовых инструментах. О них вы можете почитать в комментариях или написать свой, буду благодарен)
(P.S: Спасибо за замечания, интерес и активность Revertis, procfg, Stas911 и другим^^)
Пример задачи
Хотим автоматизировать огромный фруктовый рынок. На каждое событие будем писать строчку в структурированный лог.
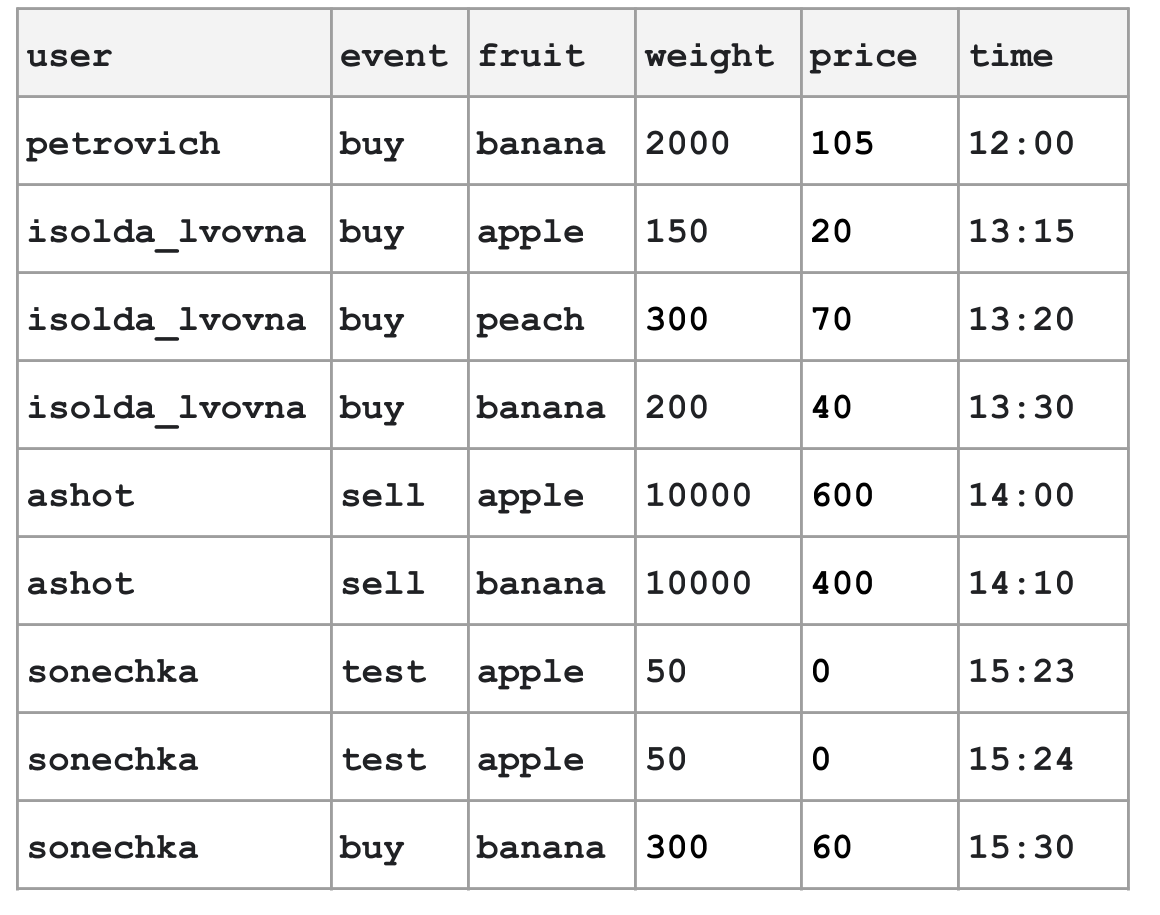
Этот лог не является частью runtime функционирования рынка, но может быть полезен для изучения статистики и аналитики. Например, на основании лога продавец может сделать вывод, что свежие яблоки выгоднее привозить к 13:00.
Хотим узнать
Сколько всего денег покупатели потратили на каждый тип фруктов?
Почему бы не реляционная бд + SQL?
Пусть все эти данные лежат в таблице log в MySQL и мы просто делаем такой запрос:
select fruit, sum(price)
from log
where event = 'buy'
group by fruit;Это будет работать. Но наш рынок огромный! И размер этого лога 100 петабайт. Он не поместится на жесткий диск одной машины.
А что если в Hadoop?
Пусть этот лог пишется в hadoop кластер. Hadoop сам разложит эту "таблицу" на разные серверы (обычно называется "ноды" node).
Например так:

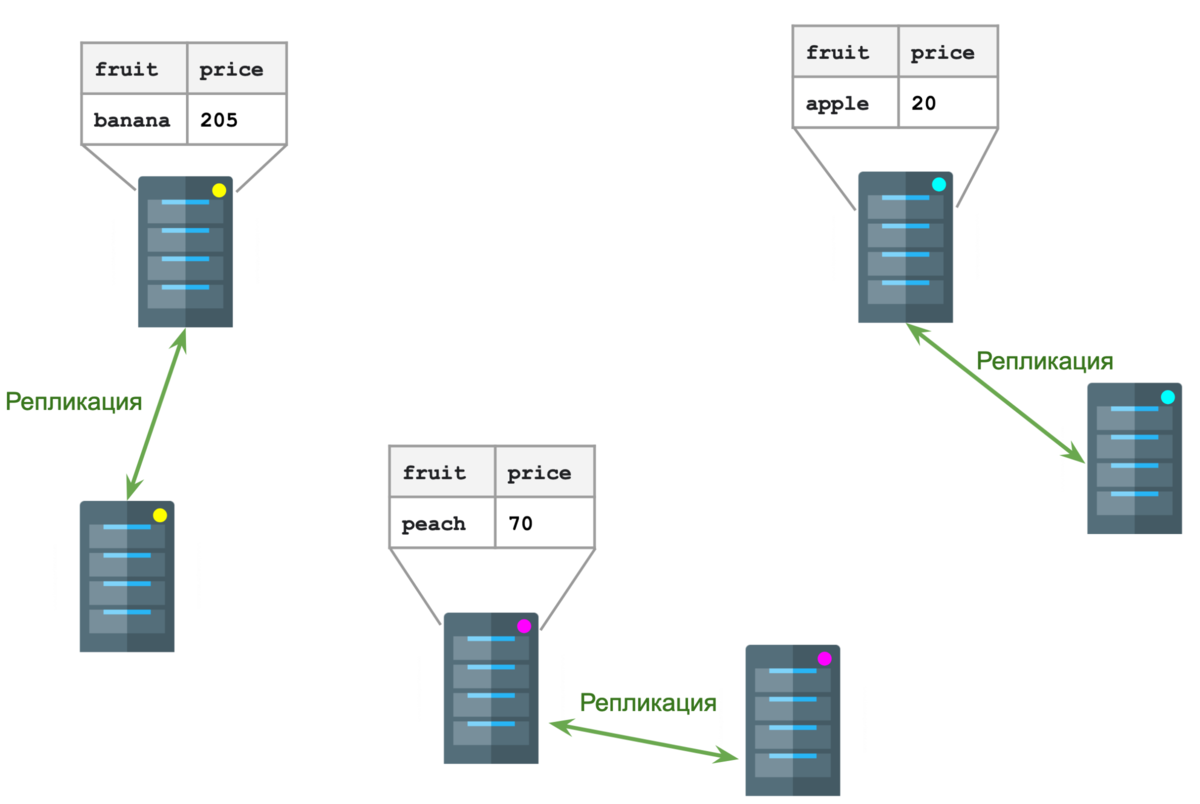
За распределение данных по кластеру отвечает HDFS (Hadoop Distributed File System). Из-за того, что данные разделены на разные ноды, объем данных не ограничен размером жесткого диска одной ноды. А репликация обеспечивает отказоустойчивость (если одна из нод сломается, реплика встанет на ее место).
Теперь с помощью двух операций map и reduce получим ответ на наш вопрос.
Пишем map
Операция map очень похожа на функцию map из функционального программирования: она преобразовывает каждую строчку. Но в добавок она может еще и выфильтровать ненужные строчки.
У map из ФП сигнатура такая, например:
Row map(Row row)
Она принимает некий объект класса Row, который представляет строку, и возвращает другой объект Row, который может иметь совсем другой формат. Однако, чтобы такая функция могла еще и фильтровать, ее нужно немного усложнить. Добавим параметр context, в который будем писать строчку вместо того, чтобы ее возвращать (но только если это необходимо):
void map(Row row, Context context)
Теперь напишем имплементацию этой функции, которая:
1. Выбрасывает все события, кроме buy
2. Выбрасывает все столбцы, кроме fruit и price
void map(Row row, Context context) {
if (row.get("event").equals("buy")) {
context.write(new Row(
"fruit", row.get("fruit"),
"price", row.get("price")
));
}
}Это функция будет вызываться для каждой строчки нашей таблицы. Результат map:

Мы получили новую (временную) таблицу.
Теперь должна произойти магия.
Как работает Shuffle?
Этот шаг произведет сам hadoop. Мы только должны сказать ему, какой столбец будет ключом. В нашем случае ключом будет столбец fruit.
Ноды будут обмениваться строчками так, чтобы
все строчки с одинаковым ключом попали на одну ноду
Результат будет такой:

Пишем reduce
Теперь, когда мы уверены, что все бананы лежат на одной и той же ноде (ровно как и другие фрукты), мы можем посчитать их стоимость.
Функция reduce, совсем не отличается от функции reduce в ФП, однако для единообразия возвращать будем так же как в map - через context.
void reduce(List<Row> rows, Context context);
Функция принимает список строчек с одинаковым ключом. И выполняется для каждой такой группы.
Реализация должна просто посчитать сумму:
void reduce(List<Row> rows, Context context) {
int sum = 0;
for (Row row : rows) {
sum += row.get("price");
}
context.write(new Row(
"fruit", rows.get(0).get("fruit"),
"price", sum
));
}Такой получим результат:
Если вычитать из HDFS новую (временную) таблицу целиком, то получим точно такой же результат, как и с SQL:

Выводы
С помощью MapReduce можно сделать все, что можно сделать с SQL.
MapReduce сложнее принять, но он изначально нацелен на масштабирование - в кластере могут быть десятки тысяч нод, а твой запрос будет работать почти также, как и с десятком нод.
Если данных не так много, то лучше использовать твою любимую реляционную БД, потому что это намного проще и быстрее.
P.S, Старался максимально упростить материал, поэтому в некоторых местах могут быть маленькие обманчики, которые помогают легче понять концепцию.
Комментарии (5)

Stas911
00.00.0000 00:00+1А можно вообще ничего не писать - сложить все в S3 и сделать SQL запрос через Athena

DenisPantushev
00.00.0000 00:00+1Как интересно все это читать после прочтения статьи, которая в ленте тремя постами раньше:
https://habr.com/ru/company/first/blog/720058/
"Огромный рынок"! Петабайты данных...
procfg
Статья хорошая, но к сожалению не актуальная MapReduce безнадежно устарел, в современных кластерах MapReduce2 который работает по верх yarn, я бы эту задачу решал spark и быстрее и проще...
sshikov
Аналогично. Причем минимум двумя способами — написал бы SQL, или воспользовался бы API Dataset. В нашей практике уже года четыре как никто не пишет MapReduce приложения.
Toor3-14 Автор
Здраствуйте! Забыл указать цели статьи (исправил). Я писал эту статью для тех, кому эта тема интересна и для тех, от кого требуют базовое теоретическое знание данной темы. Безусловно я согласен с тем, что есть инструменты, улучшающие работу. Спасибо за активность)