
- свой профиль;
- чужой профиль (если его владелец это разрешил);
- свой рейтинг, отражающий популярность пользователя на сайте;
- награды, полученные пользователем за свои действия или действия других пользователей.
Чтобы пользователю хотелось делиться всем этим, мы генерируем специальные изображения, которые называем бейджами. Вот пример бейджа, который может получить пользователь:

Особенность бейджей состоит в том, что на них присутствуют фото самих пользователей, поэтому каждый видит и делится уникальными изображениями. В этой статье я расскажу, как мы генерируем такие изображения, с какими проблемами сталкивались и как их решали.
Генерация изображений
Мы генерируем изображения для бейджей в реальном времени по запросу пользователей или ботов из социальных сетей. Мы не можем готовить их заранее, т.к. это потребовало бы очень много места для хранения и ресурсов сервера для генерации абсолютно всех изображений, которые могут потребоваться (но не факт, что действительно потребуются).
За основу схемы генерации мы взяли ту, по которой работают наши фотографии, но немного ее изменили. С точки зрения сервера генерация выглядит следующим образом:
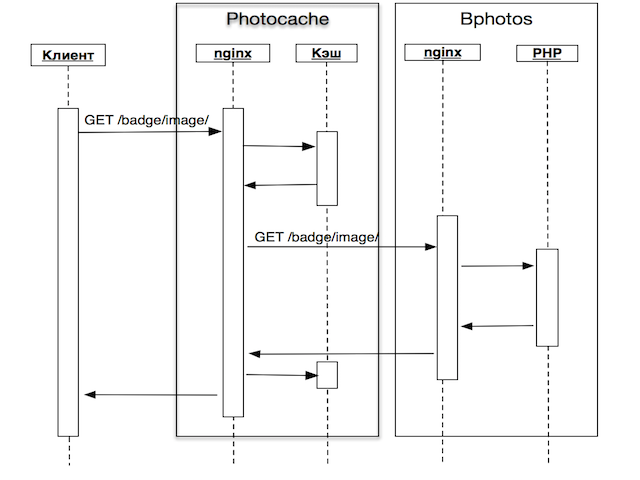
- HTTP-запрос на генерацию бейджа приходит на сервер Photocache, назначение которого — принимать на себя запросы, хранить у себя кэш ответов
- и тем самым снижать нагрузку на сервера, хранящие сами фотографии;
- nginx на Photocache ищет изображение в своем кэше, и если он есть, то отдает его клиенту. Тут появляется первое отличие бейджей: т.к. запросов сравнительно немного, здесь используется стандартный кэш nginx, а не самописный модуль, как при работе с обычными фотографиями;
- Если в кэше ничего нет, то запрос проксируется на Bphotos — сервер, на котором хранятся фото пользователя, бейдж которого мы генерируем;
- nginx на Bphotos передает запрос PHP-скрипту, который загружает все необходимые ресурсы, запускает генерацию и отдает готовое изображение. В этом заключается воторое отличие: обычные пользовательские фотографии nginx отдает без помощи каких бы то ни было php-скриптов;
- Photocache отдает полученное изображение бейджа клиенту и кэширует его.
Каждый тип бейджа имеет свой собственный формат URL, в который мы включаем идентификаторы фотографий пользователя и других ресурсов (например, наград), которые нужны для генерации; служебные параметры, влияющие на передачу запроса к правильному серверу; коды языка и соцсети, для которой генерируется этот бейдж.
Код языка в URL очень важен, потому что Badoo — проект, локализованный под несколько языков. В обычных запросах для получения лексем мы используем объект локализации, основанный на настройках текущего пользователя. В бейджах это не работает, т.к. примерно треть запросов приходит от ботов соцсетей, которых наша система трактует как неавторизованных пользователей и пытается угадать их язык по IP-адресу. Поначалу мы об этом не подумали и получалось так, что на нашем сайте или в приложении пользователь видел картинку с текстом на одном языке, добавлял ее в свой фейсбук и видел ее же, но с текстом на английском.
Код соцсети нужен, потому что у разных соцсетей есть разные предпочтения по размерам изображений. Например, для Facebook нужны картинки 1200х630, а для Instagram — 640x640. Если мы знаем, для кого мы генерируем изображение, то мы можем подстроиться под получателя:

Кроме всего этого, обычно мы оставляем в URL место под битовую маску модификаций, которая будет использоваться, если какой-то функционал в генераторе нужно включать лишь в некоторых случаях. Например, мы использовали это поле, когда Apple просил не распространять фотографии с рейтингом пользователей iOS-приложения. Тогда мы добавили флаг для скрытия рейтинга, что позволило, с одной стороны, не ссориться с Apple, а с другой — оставить уже имеющийся бейдж там, где это возможно. Можно обойтись и без этого поля, но тогда придется создавать новый формат URL под каждую модифицированную версию бейджа, что приведет к разрастанию этих форматов и со временем усложнит поддержку.
С точки зрения кода скрипт генерации изображений выглядит следующим образом:
- Есть единый контроллер, который принимает запросы от сервера, определяет по формату URL необходимый тип бейджа и создает пару объектов, один из которых — непосредственно генератор, создающий изображение бейджа, а второй — источник данных для генератора.
- В объект-источник передаются параметры из URL, по которым он понимает, какие ресурсы нужны для создания бейджа и загружает их.
- В объект-генератор «сеттится» объект-источник, что позволяет генератору заниматься только только сборкой изображения из уже загруженных ресурсов.
- Контроллер получает результат работы объекта-генератора и возвращает его с нужными заголовками.
Структура объектов-источников данных, как правило, сильно отличается в зависимости от типа бейджа, а объекты-генераторы имеют похожую структуру, поэтому есть абстрактный класс, от которого они наследуются. Выглядит он примерно так:
abstract class AbstractBadgeGenerator
{
/**
* Возвращает сгенерированное изображение бейджа либо false в случае неудачи
* @return bool|\FastImageEditor
*/
final public function getImage()
{
$this->startPinbaTimer('isAvailable');
$is_available = $this->isAvailable();
$this->stopPinbaTimer();
if (!$is_available) {
return false;
}
$this->startPinbaTimer('generate');
$Result = $this->generate();
$this->stopPinbaTimer();
return $Result;
}
/**
* Позволяет проверить, возможно ли сгенерировать бейдж по имеющимся ресурсам.
* Основная идея — быстро отловить ситуацию, когда бейдж нельзя сформировать,
* и не тратить в таком случае время на работу с изображениями
* @return bool
*/
public function isAvailable()
{
return true;
}
/**
* Генерирует изображение бейджа или возвращает false, если сгенероровать его не получилось
* @return bool|\FastImageEditor
*/
abstract public function generate();
// Некоторые вспомогательные методы
}
Самое главное тут — метод getimage, который «дергается» из контроллера. Если он не вернет объект изображения, то контроллер вернет ошибку 404. Вызовы методов проверки доступности и сборки изображения обложены Pinba-таймерами, причем мы подставляем в названия имена конкретных классов, что дает нам данные о времени, необходимом для генерации каждого типа бейджей. Кроме этого, мы стараемся обкладывать таймерами все манипуляции с изображениями в конкретных классах-генераторах и собираем в контроллере информацию по общему времени работы источника и генератора, после чего пишем ее в базу с помощью нашей системы сбора статистики (На Хабре можно найти видео с ее описанием).
При работе с изображениями мы используем очень ограниченное число операций: поворот на произвольный угол, resize и crop изображений, наложение слоёв (в том числе с прорачностью) и добавление текста. Для их выполнения мы используем библиотеку Leptonica, обертку для которой написал Антон Довгаль (старую версию можно найти у него на github-е). Именно ее выбрали несколько лет назад за то, что она работала быстрее конкурентов. Чтобы продемонстрировать это, я сделал небольшой сравнительный тест GD, ImageMagick и Leptonica.
Для каждой из библиотек я написал скрипт, который создает новое изображение размером 1000х1000, на которое накладывается другое изображение, загруженное с диска (аналог ресурса). Чтобы приблизить код к тому, что используется при генерации бейджей, я добавил еще несколько операций над загруженным изображением — оно будет уменьшено и повернуто. Результат манипуляций будет сохранен на диск в формате JPEG. Такой сценарий позволяет оценить скорость почти всех операций, которые мы используем при генерации бейджей. Сам код в статье я приводить не буду из-за его большого размера, но для интересующихся выложу исходники на GitHub.
Я сделал 100 последовательных запусков этих скриптов на нашем сервере и получил следующие результаты:
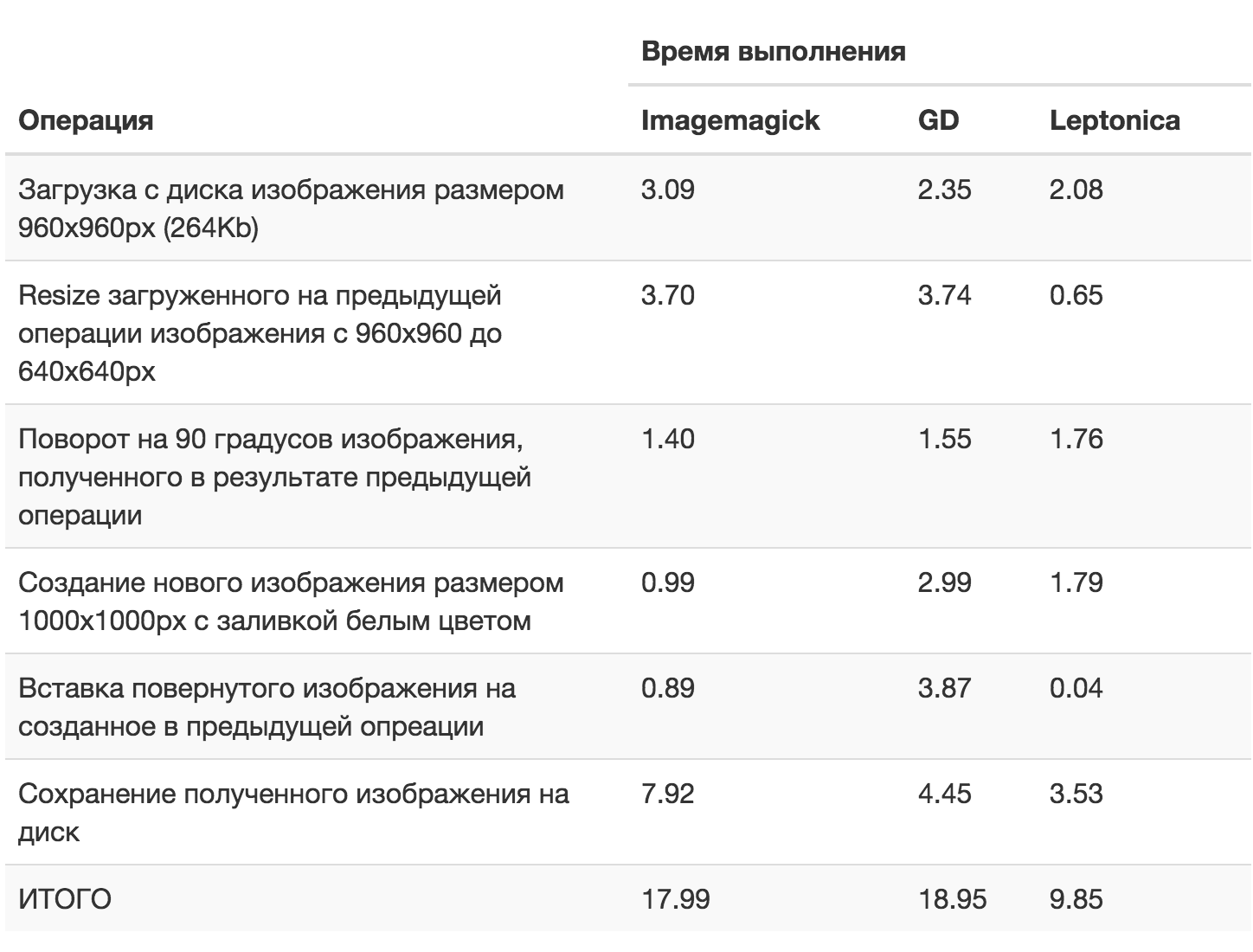
По результатам теста получилось, что в данном сценарии Leptonica оказалась практически вдвое быстрее и GD, и Imagemagick, которые показали близкое друг к другу общее время.
Конечно, в генерации реальных бейджей используется гораздо больше манипуляций с изображениями, чем в этом тесте, поэтому нужно не надеяться на то, что Leptonica и так работает быстро, а стараться минимизировать количество требуемых операций. Для этого мы стараемся проводить оптимизации на этапе подготовки ресурсов, объединяя как можно больше слоёв в одно изображение.
Тестирование результатов генерации
Постепенно бейджей становилось все больше и нам захотелось быть уверенными, что все бейджи корректно работают после внесения изменений в код или ресурсы. Для этого мы решили использовать функциональные тесты: мы создавали заглушки пользователя, его фотографий и наград, формировали URL бейджей и передавали их генератору. Главная сложность была именно в проверке получившихся результатов. Очевидный способ — сравнивать сгенерирированное в тесте изображение с имеющимся образцом — нам очень не нравился, т.к. он либо требовал ручной сборки всех возможных образцов бейджей (чье число доходило до 50) при любом изменении и лишал нас прелести автоматизации, либо не давал гарантии, что все бейджи работают, если мы брали только часть вариантов.
После некоторых размышлений и экспериментов мы стали использовать два упрощенных типа проверок:
- Базовая проверка результатов генерации: мы проверяем, что генератор вернул именно изображение ожидаемого размера и оно содержит несколько цветов в контрольных точках;
- Сравнение нескольких результатов генерации: мы генерируем в тесте URL на два бейджа, сходных друг с другом почти во всем, но отличающихся только одним параметром (кодом языка, выводимым текстом, наградой и т.д.) и ожидаем, что мы получим два изображения, отличающиеся друг от друга. Отличие мы определяем как наличие расхождения в цветах хотя бы в одной контрольной точке.
В обеих проверках фигурирует понятие контрольных точек. Под ним я имею в виду набор точек на изображении, получаемый по какому-то правилу. Конкретно мы разбиваем изображение на 10 равных частей по горизонтали и вертикали, в результате чего на пересечении линий получаем 81 контрольную точку, для которой собираем карту цветов с помощью подобного кода:
protected function getImageColorsMap($Image, $color_grid_size = self::COLOR_GRID_SIZE)
{
$image_info = $Image->getInfo();
$dx = ceil($image_info['width'] / $color_grid_size);
$dy = ceil($image_info['height'] / $color_grid_size);
$colors_map = [];
for ($row = 1; $row < $color_grid_size; $row++) {
for ($cell = 1; $cell < $color_grid_size; $cell++) {
$x = $dx * $cell;
$y = $dy * $row;
$color = $Image->getOnePixel($x, $y);
$colors_map[$color][] = [$x, $y];
}
}
return $colors_map;
}
Совпадение всех точек у двух изображений не значит, что эти изображения полностью совпадают, но это повод насторожиться и либо увеличить число таких точек, либо поменять правила их выбора в случае частых ложных срабатываний. На практике с 81 точкой мы ни разу не столкнулись с ложными срабатываниями.
Конечно, такие простые проверки не дают гарантии, что на бейджах будет показано именно то, что мы ожидаем. Но они позволяют быстро проверить, что все бейджи работают, и помогли нам выловить ряд багов до их попадания на продакшен, причем часть из них была допущена даже не в PHP-коде генерации, а уровнем ниже — в «сишной» библиотеке по работе с изображениями.
Проблемы с выводом текстов
Хотя статья посвящена генерации изображений, проблемы, на решение которых было потрачено больше всего времени, были связаны с текстами.
Определение алфавита по тексту
Мы выводим тексты на разных языках. Некоторые языки используют алфавиты, отличные от кириллицы и латиницы, и не все шрифты их поддерживают. Поэтому важно понимать, какой алфавит нам нужен для вывода, чтобы использовать подходящий шрифт. Там, где мы выводим предопределённые лексемы, это сделать очень просто — мы знаем язык, на котором написан текст. Но кое-где мы выводим пользовательский текст (например, при «шаринге» профиля в Instagram на бейдже показавается имя пользователя) и не знаем, на каком языке он написан.
Эта проблема решилась достаточно легко, потому что найти принадлежность символа к группе можно прямо на сайте unicode.org. Все, что нам нужно было сделать — скачать таблицы и свести диапазоны групп символов в единую таблицу. Имея такую таблицу, можно проверить все символы в строке, получить список используемых групп и выбрать шрифт, поддерживающий все эти группы символов.
Главное, о чем нужно помнить: коды на сайте приводятся в UCS-4, а не в привычной многим UTF-8.
Подгонка текста под отведённые размеры
В бейджах используются тексты на разных языках, и одна и та же фраза на разных языках будет иметь разную длину (и потому требовать разного места). Для подгонки размеров текстов мы используем два алгоритма: подгонку размера шрифта и разбиение текста по строкам.
Подгонка размера шрифта. У нас есть некий «идеальный» размер шрифта и максимальная ширина, которую мы можем использовать под текст. Проверяем, помещается ли текст в эту ширину (например в GD для этого есть функции imagettfbbox и imageftbbox) и если да, то просто выводим текст. Если же текст занимает больше места, то уменьшаем размер шрифта и повторяем проверку. Код, реализующий выбор размера, выглядит следующим образом:
$font_size = $initial_font_size;
$max_x = 0;
while ($font_size > $min_font_size) {
$text_size = $Image->getTextBox($font_size, $angle, $font, $text);
$max_x = max($text_size[2], $text_size[4]);
if ($max_width >= $max_x) {
break;
}
$font_size -= 1;
}
Данный алгоритм хорош своей простотой, но использовать его можно только для небольшого разброса в длине выводимых текстов. Большие же тексты могут потребовать значительного уменьшения размера шрифта, что сделает их нечитаемыми. Для таких случаев мы используем разбиение по строкам.
Разбиение по строкам работает довольно просто: мы определяем количество символов, которое можно вывести, после чего сначала разбиваем текст на слова, а потом собираем слова в строки, каждая из которых не превышает нашего максимального числа символов. Здесь нужно помнить, что бывают длинные слова, которые могут оказаться длиннее числа символов в строке (тогда к результатам разбиения нужно будет применить подгонку размера шрифта), и некоторые языки не используют стандартные разделители (например, японский).
Разбиение по строкам плохо работает в случае, когда в одну строку не помещается лишь несколько символов. В результате такой ситуации обычно бывает одна длинная строка и одна короткая, с одним-двумя короткими словами. Чтобы исправить эту ситуацию, мы пытаемся разбить текст на две максимально близкие друг к другу по длине строки. Для этого при разбиении мы ориентируемся не на максимальную длину строки, а на половину реальной длины текста. Чтобы решить проблему длинных слов, ломающих идеальное разбиение, мы делаем два варианта: из начала текста в конец и из конца текста в начало, после чего выбираем то, у которого меньше расхождение между длинами строк.
$len = mb_strlen($text);
if ($len <= 2 * $this->max_line_size) {
$ideal_line_len = ceil($len / 2) - 1;
$lexems_list = $this->getTextLexems($text);
$direct_order_lines = $this->getDirectOrderLines($lexems_list, $ideal_line_len);
$reversed_order_lines = $this->getReversedOrderLines($lexems_list, $ideal_line_len);
$delta_direct = $this->getLinesDelta($direct_order_lines);
$delta_reversed = $this->getLinesDelta($reversed_order_lines);
return ($delta_direct < $delta_reversed) ? $direct_order_lines : $reversed_order_lines;
}
Забавный факт про тексты. По нашему опыту, больше всего места требовали лексемы на греческом языке и на суахили. Тексты на немецком обычно короче, но они плохо поддаются разбиению на строки из-за наличия длинных слов.
Обработка текстов с написанием справа налево
Тексты, использующие написание справа налево (RTL-языки), нельзя выводить как есть — они будут совершенно нечитаемы. Связано это с тем, что у таких языков есть два порядка символов: логический, который используется при хранении, и визуальный, который мы видим.
За преобразование одного порядка в другой отвечает так называемый Unicode Bidirectional Algorithm (сокращенно — BIDI). Подробнее про это можно узнать на хабре (BIDI (unicode bidirectional algorithm)), сайте W3C (Visual vs. Logical Ordering of Text, Unicode Bidirectional Algorithm Basics) и unicode.org (Unicode Bidirectional Algorithm). Современные клиенты, работающие с Юникодом, содержат реализацию этого алгоритма, а при написании текстов на изображениях об этом приходится заботиться самостоятельно.
RTL-языков несколько, но конкретно наши пользователи используют только два — арабский и иврит, которые в сумме дают чуть меньше 1% от общего числа запросов на генерацию бейджей.
Проблема с ивритом решилась очень быстро: в PHP есть функция hebrev для преобразования логического текста в визуальный, а первый же комментарий на странице с документацией этой функции показывает, как ее использовать для текстов в UTF-8:
$visual_hebrew_text = iconv("ISO-8859-8", "UTF-8", hebrev(iconv("UTF-8", "ISO-8859-8", $logical_hebrew_text)));
С арабским языком все было сложнее. Нам повезло, что наш удаленный переводчик с арабского сталкивался с такой проблемой раньше и принимал участие в создании библиотеки Ar-PHP. Библиотека содержит много функционала, но последние пару лет не очень активно развивается. Ее сайт периодически недоступен, хотя код можно найти в форках на GitHub: 1, 2, 3. В оригинальной версии преобразование текста осуществляется следующим образом:
$ArabicGlyphs = new \I18N_Arabic_Glyphs();
$visual_arabic_text = $ArabicGlyphs->utf8Glyphs($logical_arabic_text, $max_characters_count);
Если обработать тексты именно так, то их можно выводить обычными функциями вроде imagettftext. Вот как это будет выглядеть:

- Кроме обработки есть еще пара нюансов, про которые нужно помнить при работе с RTL-текстами:
- При выводе текста с помощью функций графических библиотек указывается координата левой границы текста, в то время как в RTL, как правило, нужно знать правую. Поэтому перед самим выводом нужно предварительно вычислить ширину текста и уже потом, зная ее и координату правой границы текста, можно будет вычислить координату левой границы.
- Если вы выводите текст, разбитый на несколько строк, то нужно предварительно инвертировать их порядок. Мы разбиваем текст слева направо и получаем массив строк, в котором в первом элементе хранится текст, находящийся слева. Для RTL-текстов это будет конец, а не начало, и получится, что текст написан снизу вверх, что неправильно.
Заключение
Работа с изображениями в php — не самая популярная тема и бывает непросто найти в интернете решения возникающих проблем. Надеюсь, что благодаря моей статье это станет немного легче. Если что-то в моей статье показалось вам непонятным и у вас возникли вопросы — задавайте их в комментариях, постараюсь на них ответить.
Больше статей и материалов можно найти в нашем техблоге TechBadoo.
Виктор Пряжников, разработчик отдела Features
Комментарии (22)

Alexufo
23.11.2015 22:40Вы не сталкивались с проблемой блокирования запросов из за сессии? к примеру у вас генерится два бейджа от одного человека и они будут вынуждены встать в очередь. Отсюда провал в производительности из-за предотвращения race condition.
konrness.com/php5/how-to-prevent-blocking-php-requests
С арабским везде засада, особенно при отладке в коде с арабским текстом, там такие сюрпризы с непривычки :-) А фотошоп до сих пор бывает глючит.
anarx
23.11.2015 23:42Я полагаю, там запросы от роботов соцсетей, которые никак не могут быть авторизованы на серверах генерации таких бейджей.

symbix
24.11.2015 01:14+1Если опустить уже упомянутое про отсутствие там авторизованных пользователей — вы что, правда думаете, что в проектах масштаба Badoo используются сессии на файлах? :)

tkf
24.11.2015 12:29ну сессии в памяти вполне тоже могут запросы тормозить. тут все зависит от механизма работы с ними. Но сессии не всегда нужно использовать, что здесь собственно и происходит :)
symbix
24.11.2015 14:28У стандартных сессий в мемкеше другая проблема — они неконсистентны: сохранение может затереть параллельно сделанные изменения.
Я делал через CAS, при чтении запоминается casToken, запись, если упрощать — как-то так:
https://gist.github.com/anonymous/141fea5a0ec9d3ed9697
(Понятно, что в данном кейсе сессии ни к чему — я вообще).
bikutoru
24.11.2015 10:15+1Вам правильно ответили — мы используем сессии не в файлах, а в памяти. Технически они доступны на серверах, где происходит генерация изображений, но только если запрос послал пользователь. У ботов нет доступа к данным из этой сессии, поэтому нельзя на неё полагаться и нужно передавать все необходимые параметры в URL бейджа.
Арабский еще очень тяжело отлаживать — его почти никто не знает и после внесения правок непонятно, правильно они работают или нет. Приходилось после любого изменения готовить примеры картинок, отправлять их переводчикам и ждать от них обратной связи :-)

Alexufo
23.11.2015 22:48+2Да, как то вы обошли gmaick www.graphicsmagick.org. Он позиционирует себя шустрее imagick'а.
tkf
23.11.2015 23:38Сделал PullRequest автору с gmagick. Но по факту разница не такая уж и большая. В чем то чуть быстрее, в чем то медленней. Создание и сохранение чуть медленней, операции чуть быстрее, некоторые заметно быстрее. но на итоговый результат повлияет не так уж сильно. Leptonica похоже получается быстрее, просто разница выходит где то в 1.5 а не в два раза.
bikutoru
24.11.2015 10:28К сожалению, я пока не могу прогнать ваш тест — под рукой нет сервера, где одновременно были бы и leptonica, и gmagick.
В момент поиска графической библиотеки тесты показывали, что leptonica быстрее даже не в 2 раза, а процентов на 25. Было это давно и я не смог найти ни исходников тестов, ни их точных результатов, поэтому сделал новый тест просто чтобы показать (а заодно и самому понять), на каких конкретно операциях leptonica работает быстрее. Я думаю, что тут tony2001 сможет сказать больше меня.tkf
24.11.2015 12:27возможно тесты были по сишным версиям библиотек, а обертки сделали свое дело?
а можно ли где нибудь найти используемую в тестах обертку для leptonica? чтобы попробовать тесты погонять?bikutoru
24.11.2015 13:23Вот всё, что есть в паблике: https://github.com/tony2001/leptonica, но это очень старая версия.
tkf
23.11.2015 23:06+1Касательно сохранения, немного ускорить сохранение ImageMagick'ом можно если заменить
$Image2->writeImage($output_file);
на
file_put_contents($output_file, $Image2);
да, кажется немного странным. Выигрыш получается порядка 10% где то. Мелочь конечно. Но так как это самая долгая операция получается. То лучше чем ничего :)
tkf
24.11.2015 01:58Кстати, может кто просветить касательно японской локализации. У них же вроде раньше было распространенно вертикальное письмо. С распространением компьютеров тренд поменялся, и сейчас вроде почти нигде не используется, или я не прав, и вам приходилось подбирать шрифты, и разбивать тексты с учетом вертикальных, а не только горизонтальных ограничений?
bikutoru
24.11.2015 10:43Мы выводим тексты на японском слева направо, так что с этой точки зрения особенностей нет. Проблемы там скорее с разбиением на строки — нет классических пробелов и нельзя разбивать на произвольном месте, чтобы случайно не порвать слово, состоящее из нескольких символов. У меня было пару мыслей на этот счёт, но на практике их реализовывать не пришлось — у нас тексты на японском достаточно короткие и в итоге переводчики просто укоротили 1-2 лексемы, которые не помещались в одну строку.

max_m
24.11.2015 12:30+1Проблемы там скорее с разбиением на строки — нет классических пробелов и нельзя разбивать на произвольном месте,
В интернете говорят что Maximum Matching — стандартный алгоритм для разбиения японских текстов на слова. В этой лекции class.coursera.org/nlp/lecture/127 где-то с 10-ой минуты про него рассказывают. Но там нужен словарь японских слов.bikutoru
24.11.2015 13:20Как вариант я хотел использовать специальный разделитель в лексемах (например, __EOL__), который бы переводчики добавляли в места возможного разбиения тексов на «сложных» языках. При генерации бейджа код бы либо “выкусывал” его (в случае когда текст помещается в одну строку), либо вставлял на его месте перенос строки. Это бы потребовало ручной работы, но совсем немного, ведь используется всего два-три десятка лексем.
Из очевидных «граблей» — опечатки у переводчиков при вводе спецсимволов, но их можно ловить автоматически: в лексемах с опечатками после разбиения на строки будут символы из двух классов: иероглифов и латиницы, чего в корректных лексемах быть не должно.

iSage
24.11.2015 17:40У ImageMagick и GraphicsMagick есть затыки с многопоточностью при работе с одним файлом.
Каковы результаты с MAGICK_THREAD_LIMIT=1 OMP_THREAD_LIMIT=1 php…
(или Imagick::setResourceLimit (imagick::RESOURCETYPE_THREAD, 1); )tkf
24.11.2015 18:19Проверил на локальной машине, результаты вышли на уровне погрешности. Поэтому решил проверить, imagick скомпилирован уже с нужным параметром. Увеличил количество потоков. Появился затык на операции вращения, где то раза в два. в остальном +-5% что по сути сопоставимо с погрешностью.
Правда отсутствие нормальной обертки для leptonica мешает полноценно повторить тесты. Можно сколько угодно подкручивать тесты imagick/gmagick но их не с чем сравнивать. Надо будет попробовать старую версию, которая есть в паблике, и сравнить разницу.
ocnk
Мне кажется, если использовать в меджике
в место
Будут другие цифры
bikutoru
Я сделал еще один вариант теста, в котором используется ваш вариант. resizeImage() работает где-то на 5% быстрее scaleImage(), но в рамках всего теста разница будет не очень заметна.
Вот дополненная версия теста и его результаты: https://github.com/pryazhnikov/php-image-processing-tests/tree/im_resize_vs_scale