

Вступление
Всем привет! Я работаю Dev-Ops инженером в небольшой команде и мы уже 4-ый месяц используем Yandex Cloud для наших сервисов. Так сложилось, что с Kubernetes и облачными вычислениями я столкнулся впервые, поэтому многое приходится изучать на ходу, иногда на "горьком" опыте. На данный момент наши микросервисы развернуты в зональном кластере Kubernetes с одним рабочим узлом, по одной реплике на каждый Deployment. Это означает, что никакой отказоустойчивости и масштабируемости нет и при малейшей нагрузке приложения упадут.
Поэтому, пока нагрузка идет только от команды разработчиков, я решил заранее побеспокоиться об отказоустойчивости наших сервисов, развернутых в Yandex Managed Service for Kubernetes. Сегодня я разверну на своем облаке Kubernetes кластер и покажу как будет вести себя автомасштабируемое приложение под нагрузкой. Для управления инфраструктурой воспользуемся Terraform, для имитирования нагрузки сервисом Yandex Load Testing (в стадии Preview) от Yandex Cloud.
Перед началом
У вас должно быть настроено свое облако в Yandex Cloud и добавлен платежный аккаунт.
Также убедитесь, что у вас установлены:
yc
kubectl
terraform с настроенным ~/.terraformrc
удобный текстовый редактор для YAML и HCL, например Visual Studio Code
Создание сервисного аккаунта и аутентификация в yc
Чтобы использовать terraform для управления инфраструктурой сначала нужно создать сервисный аккаунт, от лица которого будут создаваться ресурсы.
Перейдем в каталог в облаке -> Сервисные аккаунты -> Создать сервисный аккаунт. Введем произвольное имя, описание по желанию, а также назначим роль admin, чтобы у terraform была возможность создавать любые ресурсы, а также назначать роли.

После создания сервисного аккаунта необходимо создать авторизированный ключ для аутентификации в yc (Yandex Cloud CLI). Выберите созданный сервисный аккаунт в списке -> Создать авторизированный ключ -> Алгоритм шифрования оставьте RSA_2048:

Нажмите создать и скачайте файл в формате JSON.
Зайдем в терминал и настроим доступ к облаку в yc. Для начала создадим профиль. Профили служат для хранения конфигурации для доступа к различным облакам если у вас их несколько:
$ yc config profiles create yc-k8s-scale
Profile 'yc-k8s-scale' created and activated
Назначим service-account-key (путь до authorized-key.json, который мы установили ранее), cloud-id и folder-id:
$ yc config set cloud-id <your_cloud_id>
$ yc config set folder-id <your_folder_id>
$ yc config set service-account-key <your_path_to_authorized_key>
Убедимся, что настроили доступ к облаку в yc корректно. Попробуем получить список всех сервисных аккаунтов:
$ yc iam service-account list
+----------------------+--------------+
| ID | NAME |
+----------------------+--------------+
| ajevk652eetmf0dn96eo | terraform-sa |
+----------------------+--------------+
Terraform
Как говорилось ранее, разворачивать инфраструктуру будем не через GUI консоль облака, а через Terraform (Infrastructure as Code инструмент для управления инфраструктурой). Исходный код для создания нужных ресурсов можно посмотреть в GitHub, тут же заденем только один файл: set_env.sh. В нем будет активироваться наш профиль, назначаться переменные окружения, нужные для работы Terraform с провайдером Yandex Cloud (YC_TOKEN, YC_CLOUD_ID, YC_FOLDER_ID):
echo "You are using yc-k8s-scale profile!"
yc config profiles activate yc-k8s-scale
export YC_TOKEN=$(yc iam create-token)
export YC_CLOUD_ID=$(yc config get cloud-id)
export YC_FOLDER_ID=$(yc config get folder-id)
Для аутентификации будет создаваться IAM токен, время жизни которого 12 часов.
Выполним terraform plan, чтобы узнать какие ресурсы будут созданы:
$ terraform plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
...
Plan: 10 to add, 0 to change, 0 to destroy.
Примем изменения при помощи команды terraform apply и подтвердим действие, написав 'yes':
$ terraform apply
Plan: 10 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
Дождитесь пока все ресурсы не будут созданы, это может занять от 15 до 30 минут.
Обзор созданных ресурсов
После завершения команды будут созданы следующие ресурсы: одна сеть с 4 подсетями, две из которых для ресурсов облака в зонах доступности ru-central1-a и ru-central1-b, остальные две для подов и сервисов Kubernetes кластера.
Также будет создан кластер в Managed Service for PostgreSQL с базой данных db1 и пользователем user1 с паролем password12345
Будет создан один кластер в Managed Service for Kubernetes с двумя группами узлов:
yc-scale-node-group-1 (подсеть default-ru-central1-a, начальное кол-во узлов 1, максимальное кол-во узлов 3)
yc-scale-node-group-2 (подсеть default-ru-central1-b, начальное кол-во узлов 0, максимальное кол-во узлов 3)
Узлы используют самую дешевую конфигурацию, чтобы избежать больших расходов.
Автоматическое масштабирование
В Yandex Managed service For Kubernetes поддерживается три вида автомасштабирования:
Cluster Autoscale
HPA
VPA
В Kubernetes поддерживается два вида масштабирования: горизонтальное и вертикальное. При горизонтальном масштабировании создается ресурс HPA (HorizatalPodAutoscaler), который отслеживает одну из метрик (обычно CPU или кол-во запросов) и увеличивает/уменьшает количество подов, при этом можно задать минимальное и максимальное количество подов.
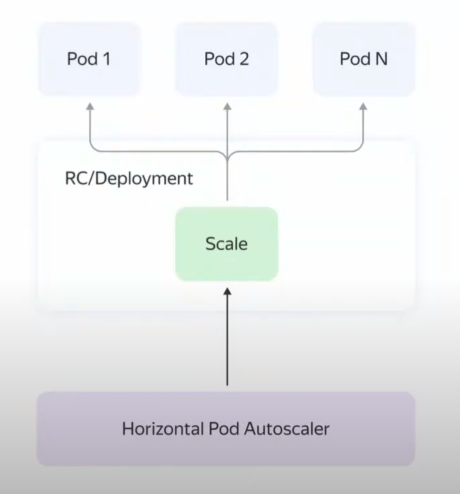
В случае с вертикальным масштабированием создается ресурс VPA (VerticalPodAutoscaler), автоматический назначающий (или дающий рекомендации) ресурсы для пода.
Облачные провайдеры, в том числе Yandex Cloud, предлагают автоматическое масштабирование рабочих узлов (Cluster Autoscale). В случае, если планировщик (kube-scheduler) не может назначить поду узел из-за нехватки ресурсов, Managed Service for Kubernetes создаcт дополнительный узел в одной из группе узлов и развернет там под. В случае, если поды можно разместить на меньшем количестве узлов, Cluster Autoscale будет выселять поды из узла и впоследствии удалит его. Зона доступности, начальное, минимальное и максимальное количество узлов указывается при создании группы узлов. В нашем случае, terraform создаст две группы узлов в двух зонах доступности. В группе узлов в зоне доступности ru-central1-a изначально будет создан один рабочий узел с возможностью масштабирования до 3. В группе узлов в зоне доступности ru-central1-b начальное количество узлов равно 0, максимальное количество узлов такое же, как и у первой группы узлов - 3.
Создание ресурсов через kubectl
Настроим доступ к нашему кластеру из kubectl. Для этого нужно получить конфигурационный файл при помощи yc:
$ yc managed-kubernetes cluster get-credentials --name yc-scale --external
Context 'yc-yc-scale' was added as default to kubeconfig '/home/azamat/.kube/config'.
Check connection to cluster using 'kubectl cluster-info --kubeconfig /home/azamat/.kube/config'.
Note, that authentication depends on 'yc' and its config profile 'yc-k8s-scale'.
To access clusters using the Kubernetes API, please use Kubernetes Service Account.
Проверим количество рабочих узлов:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
cl1a9h5asplrhnjmkn5g-unaq Ready <none> 6m57s v1.26.2
Изначально используется один рабочий узел.
Узнаем host созданного кластера Managed Service for PostgreSQL:
$ yc postgres hosts list --cluster-name postcreator-psql
+-------------------------------------------+
| NAME |
+-------------------------------------------+
| rc1a-0cwboiqngq4xea8z.mdb.yandexcloud.net |
+-------------------------------------------+
По этому хосту приложение будет подключаться к базе данных. Полные данные для подключения:
host: rc1a-0cwboiqngq4xea8z.mdb.yandexcloud.net
database: db1
user: user1
password: password12345
Создадим Secret, где будут храниться данные для подключения к БД. В дальнейшем данные из этого секрета будут вставляться в контейнер в качестве переменных окружения:
$ kubectl create secret generic postcreator-db-creds \
--from-literal=username=user1 \
--from-literal=password=password12345 \
--from-literal=jdbc_url='jdbc:postgresql://rc1a-0cwboiqngq4xea8z.mdb.yandexcloud.net:6432/db1'
Перед созданием Deployment, необходимо создать внутрении балансировщик нагрузки, через который внутри облачной сети можно будет обращаться к нашим подам. Узнаем id подсети в зоне доступности ru-central1-a:
$ yc vpc subnet get --name default-ru-central1-a
id: e9bg1u4mljgn5rdvs2bt
...
Создадим внутренний балансировщик нагрузки с внутренним IP адресом 10.128.0.100. Вместо $SUBNET_ID укажите id подсети, который мы получили выше:
$ kubectl apply -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: postcreator-service
annotations:
yandex.cloud/load-balancer-type: internal
yandex.cloud/subnet-id: $SUBNET_ID
spec:
selector:
app: postcreator
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
loadBalancerIP: 10.128.0.100
EOF
service/postcreator-service created
LoadBalancer позволит обращаться к подам внутри облачной сети по внутреннему адресу. Убедимся, что балансировщик нагрузки был создан с указанным IP адресом:
$ kubectl get svc/postcreator-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
postcreator-service LoadBalancer 10.96.212.0 10.128.0.100 80:30671/TCP 5m9s
Мы будем использовать этот адрес для отправки множества запросов.
В качестве приложения, которое будет под нагрузкой, мы будем использовать обычное CRUD серверное приложение, написанное на Java с использованием Spring 3. Исходный код и Docker образ опубликованы.
Развернем Deployment без указания количества реплик, а также не забудем назначить запросы и лимиты.
$ kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postcreator-deployment
spec:
selector:
matchLabels:
app: postcreator
template:
metadata:
labels:
app: postcreator
spec:
containers:
- name: postcreator-app
image: azamatkomaev/postcreator:0.0.6
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
env:
- name: DATABASE_URL
valueFrom:
secretKeyRef:
name: postcreator-db-creds
key: jdbc_url
- name: DATABASE_USERNAME
valueFrom:
secretKeyRef:
name: postcreator-db-creds
key: username
- name: DATABASE_PASSWORD
valueFrom:
secretKeyRef:
name: postcreator-db-creds
key: password
EOF
deployment.apps/postcreator-deployment created
Подождем некоторое время, чтобы Deployment развернулся и посмотрим список всех подов:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
postcreator-deployment-5975fcb7f9-445p8 1/1 Running 0 30s 10.112.128.7 cl16f30cle1m0sg9583f-awij <none> <none>
Передав параметр -o wide можно увидеть подробную информацию о поде. Как видим, единственная реплика приложения была назначена на наш единственный узел.
Создание агента Load Testing
Для нагрузочного тестирования будем использовать сервис Yandex Load Testing. Создадим агент для Load Testing со следующими параметрами:
Имя: agent112
Зона доступности: ru-central1-a (агент должен быть в той же подсети, что и балансировщик нагрузки)
Агент: Small
Подсеть: default/default-ru-central1-a
Сервисный аккаунт: terraform-sa
Логин: admin
-
SSH-ключ: сгенерируйте ключ при помощи команды ssh-keygen и вставьте в текстовое поле публичный ключ

После нажания "Создать" следует подождать пока облако выделит ресурсы для выбранного агента. Так как Load Testing находится в стадии Preview, он не тарифицируется. Плата за использование агентов взимается по тарифам Compute Cloud. Перейдем в Compute Cloud и если ВМ перешла в статус "Running", назначим ей публичный адрес. Это необходимо, чтобы агент имел доступ к сервису Load Testing.

Статус агента во вкладке Load Testing должен перейти из "Initializing connection" в "Ready for test" Создадим тестовые данные в формате HTTP_JSON и сохраним его в файл payload.json:
{"host": "10.128.0.100", "method": "POST", "uri": "/api/v1/posts", "tag": "url1", "headers": {"Connection": "close", "Content-Type": "application/json"}, "body":"{\"title\": \"Hello!\", \"description\": \"I am not waiting for heaven\", \"author_name\": \"Azamat Komaev\"}"}
Перейдем на страницу с агентом и нажмем "Создать тест".
Укажем следующие значения:
Агент: agent112
Тестовые данные: выберем ранее созданный файл payload.json
Продолжим конфигурацию теста:
Способ настройки: Форма
Генератор нагрузки: PANDORA
Load Testing поддерживает два генератора нагрузки: Pandora и Phantom, подробнее о них можно почитать тут. Я буду использовать генератор нагрузки Pandora со ступенчатой нагрузкой.
Адрес цели: 10.128.0.100
Порт цели: 80
Тестирующие потоки: 2500
-
Тип нагрузки: + Профиль нагрузки:
Профиль 1: step
От: 500
До: 2500
Шаг: 500
Длительность: 1m
Тип запросов: HTTP_JSON
Генератор будет наращивать нагрузку от 500 до 2500 запросов в секунду в течение 1 минуты с шагом в 500 запросов. Общая длительность нагрузочного тестирования составит 5 минут.
Тип запросов: HTTP_JSON
Тестовые данные: Прикрепленный файл
Конфигурационный данные, в частности, я взял из практического руководства Yandex Cloud, подробнее по ссылке.
Начинаем нагружать
В нашем случае, для мониторинга потребления CPU и Memory контейнерами использовать Grafana + Prometheus было бы излишним, поэтому воспользуемся командой kubectl top:
$ kubectl top pod postcreator-deployment-5975fcb7f9-7mvb5
NAME CPU(cores) MEMORY(bytes)
postcreator-deployment-5975fcb7f9-7mvb5 14m 171Mi
И так! Запустим тест и посмотрим как будет себя вести под и кластер под нагрузкой.
Подождем минуту и посмотрим кол-во потребляемых ресурсов:
$ kubectl top pod postcreator-deployment-5975fcb7f9-7mvb5
NAME CPU(cores) MEMORY(bytes)
postcreator-deployment-5975fcb7f9-7mvb5 499m 318Mi
Остановим тест. Утилизация CPU не поднимется выше 500m, так как ранее мы установили для него лимит на такой отметке.
Посмотрим кол-во узлов и подов:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
cl1a9h5asplrhnjmkn5g-unaq Ready <none> 18m v1.26.2
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
postcreator-deployment-5975fcb7f9-7mvb5 1/1 Running 0 13m
- "Ну и где твое автомасштабирование?!" - захотите вы спросить меня. Его нет! Потому что помимо настройки Cluster Autoscale в Yandex Managed service for Kubernetes нужно настроить HPA.
$ kubectl autoscale deployment/postcreator-deployment --cpu-percent=70 --min=1 --max=20
horizontalpodautoscaler.autoscaling/postcreator-deployment autoscaled
Параметр --cpu-percent указывает при каком процентом соотношении нагрузки к запросам повышать кол-во подов. Например, у нас стоит запрос по CPU в 256m, в случае, если нагрузка на CPU превысит 180m, то HPA развернет дополнительный под.
Проверим, что HPA развернулся:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
postcreator-deployment Deployment/postcreator-deployment 2%/70% 1 10 1 27s
Перезапустим тест и будем отслеживать состояние HPA в настоящем времени
$ kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
postcreator-deployment Deployment/postcreator-deployment 90%/70% 1 20 1 2m15s
postcreator-deployment Deployment/postcreator-deployment 200%/70% 1 20 2 2m46s
postcreator-deployment Deployment/postcreator-deployment 198%/70% 1 20 3 3m16s
postcreator-deployment Deployment/postcreator-deployment 198%/70% 1 20 6 3m32s
postcreator-deployment Deployment/postcreator-deployment 199%/70% 1 20 9 4m2s
postcreator-deployment Deployment/postcreator-deployment 197%/70% 1 20 15 4m48s
postcreator-deployment Deployment/postcreator-deployment 167%/70% 1 20 15 6m48s
postcreator-deployment Deployment/postcreator-deployment 167%/70% 1 20 17 7m3s
postcreator-deployment Deployment/postcreator-deployment 142%/70% 1 20 17 7m18s
postcreator-deployment Deployment/postcreator-deployment 142%/70% 1 20 20 7m33s
postcreator-deployment Deployment/postcreator-deployment 56%/70% 1 20 20 7m48s
postcreator-deployment Deployment/postcreator-deployment 36%/70% 1 20 20 8m34s
postcreator-deployment Deployment/postcreator-deployment 50%/70% 1 20 20 9m20s
postcreator-deployment Deployment/postcreator-deployment 38%/70% 1 20 20 9m50s
Остановим тест. Как видно по выводу в терминал, HPA постепенно поднимал количество подов до 20 Под конец нагрузка CPU на один под упала, что говорит о том, что автомасштабирование и балансировка нагрузки настроены верно.
Посмотрим список всех узлов через консоль Яндекс Облака:
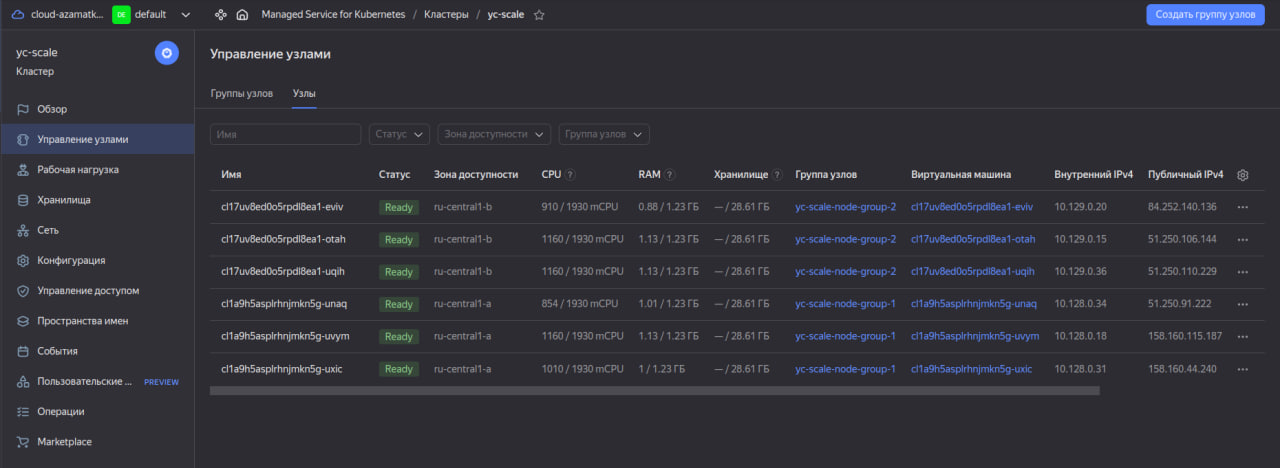
Так как новосозданным подам не хватало место на существующих узлах, кластер Managed Service for Kubernetes развернул дополнительные узлы. Обратите внимание, что он сам распределил узлы по зонам доступности (группам узлов). После падения нагрузки, HPA аналогично созданию будет постепенно удалять поды. В свою очередь, кластер Kubernetes будет сокращать количество узлов.
После тестирования
Не забудьте удалить созданные ресурсы, если они вам больше не нужны:
$ terraform destroy
Plan: 0 to add, 0 to change, 13 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
Также следует отдельно удалить агент в Load Testing, так как он не находится под управлением terraform.
Результаты работы Yandex Load Testing
Изначально я не планировал использовать Load Testing для нагрузочного тестирования. Основная цель статьи была показать как будет масштабироваться приложение, развёрнутое в Yandex Managed Service for Kubernetes под нагрузкой. Поэтому анализ нагрузочных тестов я анализировать не буду.
Вывод
Yandex Managed Service for Kubernetes предлагает отличное решение для разворачивания автомасштабируемых приложении в кластере. Но использовать только Cluster Autoscale без HPA, встроенного в Kubernetes, смысла нет, они хорошо работают в паре!