
В этой статье поговорим о том, как сделать простой процесс загрузки данных с помощью Microsoft Azure Data Factory и Databricks в 2023/2024 году. Во второй части разберем миграцию init scripts из DBFS в Workspace в связи с новым обновлением от Databricks, если ее не сделать, то не удивляйтесь, что в конце 2023 года у вас начнут падать ADF pipelines и кластера в Databricks. 1 декабря 2023 г. Databricks отключит сценарии инициализации (init scripts) с именем кластера для всех рабочих областей. Этот тип сценария инициализации ранее считался устаревшим и не будет больше использоваться.
Azure Data Factory и Databricks
Во многих проектах, которые работают с данными и используют облачные технологии Microsoft Azure в Pipelines Azure Data Factory присутствует activity “Databricks Notebook”. С помощью нее запускается notebook в сервисе Azure Databricks, который выполняет вычислительные операции с данными. Для соединения этих двух сервисов конечно же используется Liked Service, где указаны параметры подключения.
Логику работы попробовал отобразить в схеме, в моем примере для соединения Azure Data Factory и Databrucks я использовал Managed Identity:
Также мы знаем, что для вычислений в Databricks используется кластер, поэтому в настройках Linked Service нам нужно указать какой именно мы будем использовать:
New job cluster,
Existing interactive cluster,
Existing instance pool
Job cluster создается автоматически с указанными параметрами для одного конкретного запуска. Время ожидания запуска 3–5 минут. Все созданные ресурсы/узлы назначаются этому конкретному запуску. Кластер завершает работу, как только завершается выполнение блокнота, повторный запуск не возможен.
Interactive cluster создается заранее командой администраторов. Кластер запускается, когда в кластере запускается любой блокнот (это может быть специалист по данным или Azure Data Factory). Если кластер находится в автономном режиме, время загрузки составит 3–5 минут. Однако, если кластер уже запущен, выполнение начнется практически сразу.
Interactive cluster - это общий ресурс, все, что работает в кластере, использует ресурсы совместно со всеми остальными, кто работает в кластере. Можно настроить автоматическое выключение при простое, минимальное значение 10 минут, если администраторы не забыли ее настроить.

Как установить дополнительные библиотеки для кластера Databricks
Иногда для запуска кластера могут понадобиться дополнительные библиотеки. Устанавливать внутри каждого Notebook можно, но не очень удобно. Есть следующие способы:
1.) Global init scripts на уровне рабочей области. Это влияет на все кластеры в рабочей области, но может использоваться, если пользователь знает, как использовать глобальные сценарии инициализации (Databricks -> Admin Settings -> Global init scripts).

2.) Для Interactive cluster библиотеки устанавливаются на уровне кластера (Databricks -> Compute -> Name cluster - > Configuration -> Advanced option -> Init Scripts).

3.) Для Job cluster существует несколько вариантов загрузки библиотек. Библиотеки могут быть перечислены на уровне отдельного конвейера. Это обеспечивает большую гибкость, но требует дополнительных усилий по включению списка библиотек в каждый конвейер. Они устанавливаются поверх библиотек, упомянутых в сценариях глобальных и связанных служб. Также можно указать init scripts в linked service при запуске из azure Data Factory. Таким образом, все Pipelines Azure Data Factory, которым нужны одни и те же библиотеки, могут вызывать одну и тот же linked service, если Notebook находятся в одной рабочей области.
С Existing interactive cluster проблемы бывают редко, так как они создаются в Databricks и там же можно проверить их работоспособность, но в реальных проектах чаще используются Job cluster, так как они завершаются сразу после выполнения Notebook.
Установка библиотек в Databricks в Linked service из Azure Data Factory
Вы можете столкнуться с устаревшими статьями, где описан процесс настройки init scripts с расположением в DBFS.
1.) Для начала у вас должен быть включены настройки для Workspace (Databricks -> Admin settings -> Workspace settings)

2.) Вам нужно написать и загрузить ваш скрипт, к примеру test.sh в директорию Workspace. Внутри файл будет выглядеть примерно так:
#!/bin/bash
pip install msal
3.) Надеюсь, вы уже настроили соединение Data Factory и Databricks через Managed Identity (или другим способом) и добавили Application ID Data Factry в Service principals Databricks. Также нужно добавить ваш Data Factory в роль, которая имеет доступ к Workspace, в нашем примере это группа admins.
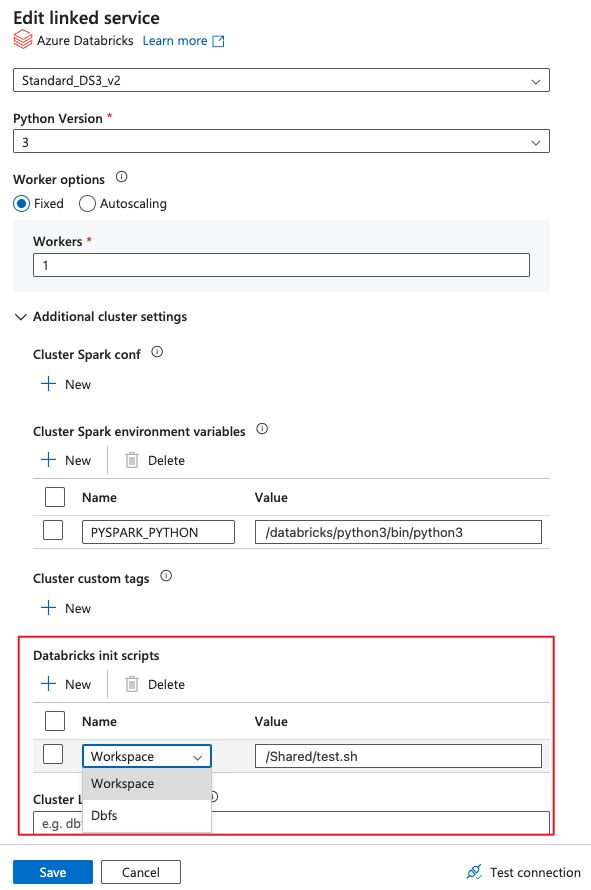
4.) Переходим в Linked Service Data Factory, чтобы указать настройки для подключения к Databricks и создания “New job cluster” (New linked service -> Compute -> Azure Databricks), именно здесь могут возникнуть трудности. Разберем один пример, с которым некоторые Data Engineers могут столкнуться в конце 2023 года.

В настройках Linked Service нужно указать ссылку на Init scripts в Databricks (пример: test.sh) которые будут запускаться при создании job cluster. Раньше все скрипты Databricks лежали в директории DBFS, но с 1 декабря 2023 их необходимо перенести в Workspace.
Казалось бы, все просто и логично, переносим, указываем путь, но при запуске возникает ошибка:
Databricks execution failed with error state: InternalError, error message: Unexpected failure while waiting for the cluster (0000-000000-00000) to be ready: Cluster 0000-000000-00000 is in unexpected state Terminated: INIT_SCRIPT_FAILURE(CLIENT_ERROR): instance_id:000000000000000000,databricks_error_message:Cluster scoped init script /Share/test.sh failed: Timed out with exception after 5 attempts (debugStr = 'Reading remote file for init script'), Caused by: java.io.FileNotFoundException: /123456789101012/Share/test.sh: No such file or directory.. For more details please check the run page url:
Если вы используете AutoResolveIntegrationRuntime, то данной ошибки у вас скорее всего не возникнет. Это был баг, который Microsoft уже исправила. Чтобы решить эту проблему, вам необходимо обновить версию Integration Runtime с типом Self-Hosted выше, чем 5.31.8570.1 в Azure Data Factory. В старых версиях вы указываете путь в Workspace, но при создании job cluster Databricks искал этот путь в DBFS.

После обновления IntegrationRuntime ваш job cluster будет успешно создан и Databricks Notebook будет успешно выполнен. Если включено автообновление, то IntegrationRuntime должен обновляться сам, но иногда служба подвисает и необходимо подключиться по RDP и сделать ее рестарт.