

Основная проблема в высоконагруженных приложениях — отказоустойчивость. Нагрузка с упавших узлов в кластере должна переключаться на живые. Это кажется несложной задачей, но на практике появляется много подводных камней. Мы с yngvar_antonsson потратили много времени на поддержку различных кластеров, построенных на Tarantool и наших кластерных фреймворках Cartridge и TDG, и сегодня расскажем вам, как обеспечивается отказоустойчивость в наших приложениях. Будет интересно всем, кто хочет подробнее узнать, как устроен фейловер в Cartridge, и тем, кто хочет узнать о нашем опыте создания автоматических фейловеров.
Общая информация
За отказоустойчивость Tarantool в кластерах на Cartridge (Open Source) и Tarantool Data Grid (Enterprise edition) отвечает процесс, который называется Failover. При включение фейловера на каждом узле запускается специальный Failover fiber (корутина). Он управляет переключением лидеров (Read-write-узлов) в репликасетах (наборе узлов Tarantool, соединенных репликационными потоками) в зависимости от порядка узлов в списке Failover priority.
В Cartridge есть 4 типа фейловеров:
- Disabled
- Eventual
- Raft
- Stateful
и два типа хранилища состояний: Tarantool Stateboard и etcd.
Далее мы подробно расскажем, что делает каждый из режимов, как их можно применять и с какими проблемами мы встретились при их эксплуатации.
Disabled failover
В этом режиме фейловер выключен и переключение лидеров производится вручную. Кажется, что выключенный фейловер не интересен в контексте высоконагруженных кластеров, но в некоторых случаях это полезно:
-
Обновление кластера. Обновление приложений на Tarantool производится с помощью перезапуска, поэтому во время обновления появляется дополнительная нагрузка на фейловер. На больших кластерах мы рекомендуем выключать фейловер на время обновления.
-
Плановая перезагрузка узлов. В процессе эксплуатации, помимо обновления, иногда приходится перезагружать узлы. Например, для ребутстрапа реплики с мастера или при возникших проблемах с фрагментацией.
-
Хрупкие кластеры. В случае ненадежных кластеров — например, с нестабильной сетью или когда узлы перегружены тяжелыми запросами — фейловер может переключать лидеров в моменты, когда этого делать не нужно (подробнее ниже).
Как выключить фейловер? Он выключен по умолчанию. Если включен другой режим, нажать на кнопку Failover в WebUI и выбрать режим Disabled.

Как сменить лидера? Поменять список Failover priority. Это можно сделать с помощью WebUI: нажать на кнопку Edit replica set и поменять порядок узлов с помощью курсора.
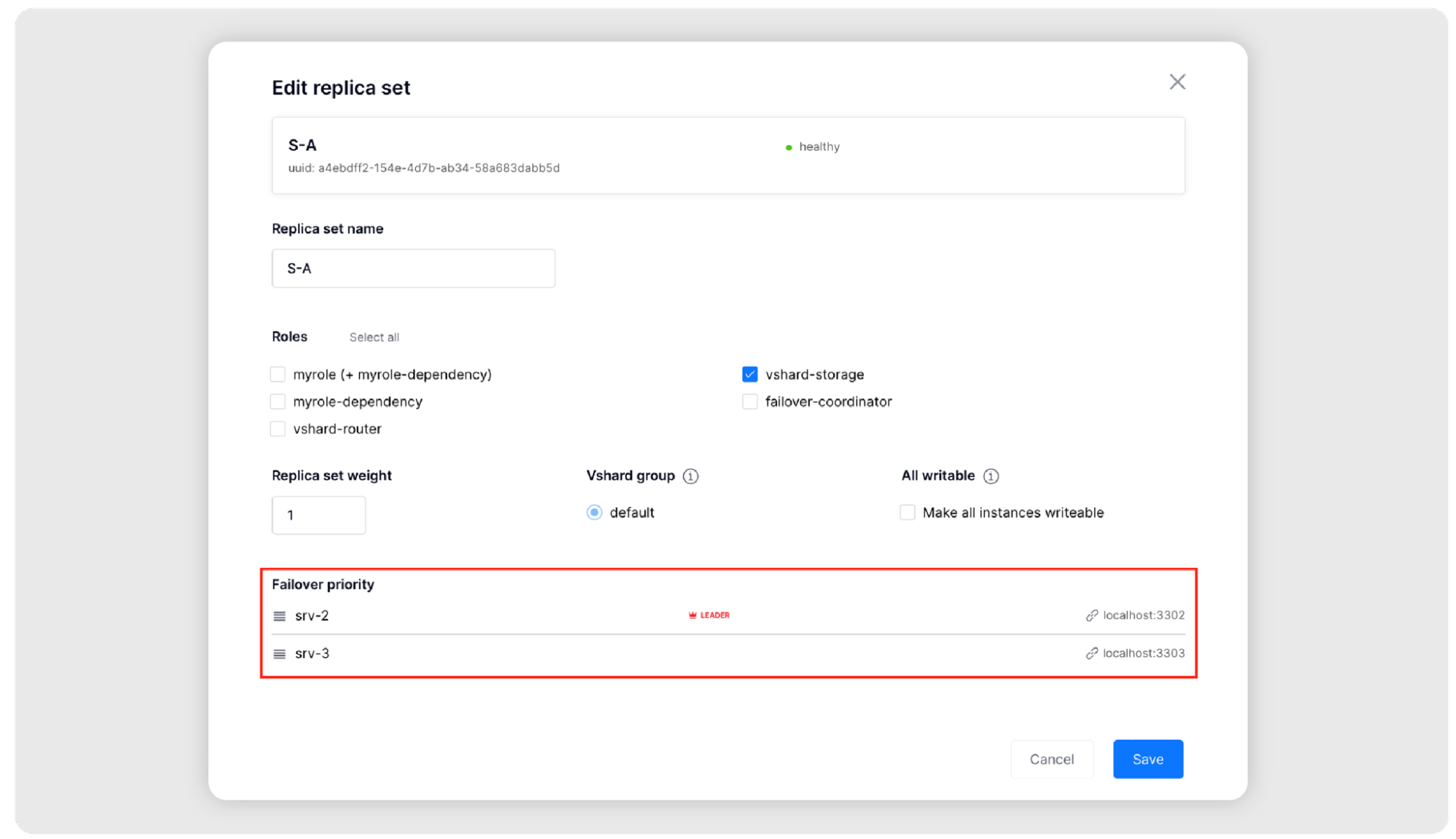
Или с помощью GraphQL:
mutation($replicasets: [EditReplicasetInput]) {
cluster {
edit_topology(replicasets: $replicasets) {}
}
}
replicasets = [{
uuid = "replicaset_uuid",
failover_priority = ["instance1_uuid", "instance2_uuid", ...],
}]
Eventual failover
Подходит для небольших кластеров с невысокой нагрузкой — 4–20 узлов до 30 ГБ каждый.
В этом режиме узлы распространяют слухи о состоянии других узлов по протоколу SWIM. Соседние узлы в репликасете собирают слухи и осуществляют переключение лидера в случае смерти текущего лидера. После восстановления узла происходит обратное переключение — восстановление старого лидера.
Проблема в следующем: в случае нестабильных узлов (тяжелые транзакции, тяжелая выборка данных, нестабильная сеть) переключение мастера может происходить очень часто, что вызывает так называемые «шторма фейловера». Узлы начинают неконтролируемо переключаться, и в один момент в репликасете может быть два лидера, что вызывает конфликты в репликации.

В случае штормов мы рекомендуем один из двух вариантов:
- Перейти на Stateful failover (почему он решит эту проблему, будет рассказано ниже).
- Включить настройки подавления фейловера (Failover supperessing). Узлы не станут лидерами в случае частого переключения и перейдут в Read only.
Лидером в Eventual-режиме всегда стремится стать первый узел в списке Failover priority. Чтобы изменить текущего лидера вручную, нужно поменять инстансы в этом списке местами, как в варианте с выключенным фейловером.
Как включить фейловер? Нажать на кнопку Failover в WebUI и выбрать режим eventual.
Как сменить лидера? Поменять список Failover priority.
Сейчас Eventual-фейловер перешел в состояние Deprecated. Мы не рекомендуем использовать его на больших кластерах. Тем не менее это все еще отличный вариант для небольших хранилищ данных.
Raft failover
Команда Tarantool уже неоднократно рассказывала про нашу реализацию алгоритма выбора лидеров Raft. Мы решили поддержать Raft в Cartridge и TDG, и так появился Raft(-based) failover.
Этот режим управляет настройками Raft в Tarantool. Tarantool сообщает Cartridge/TDG об изменении лидера и распространяет эту информацию по протоколу SWIM на остальные узлы. Cartridge использует ее для применения во внутренних процессах — например, для вызова удаленных функций cartridge.rpc, которые должны выполняться только на лидерах.

Как включить фейловер? При запуске инстансов Tarantool передать настройки Raft. После запуска узлов нажать на кнопку Failover в WebUI и выбрать режим Raft.
Как сменить лидера? Позвать функцию
box.ctl.promote вручную (стоит помнить, что она начинает «честные» выборы и лидером не обязательно станет инстанс, на котором вы вызвали box.ctl.promote) или нажать на кнопку Promote a leader в WebUI.Raft Failover сейчас находится в beta-версии. Мы пока не рекомендуем использовать его для Production-кластеров, но вы всегда можете его попробовать и написать нам о результатах в issues.
Stateful Failover
В Stateful failover появляется новая для кластера сущность — хранилище состояний (State provider). Cartridge сохраняет в нем информацию о текущих лидерах в различных реплика-сетах и состояние репликации: vclock — список номеров lsn, которые пришли на каждый узел в отдельности.
Логика по выбору и назначению лидеров здесь вынесена на отдельные узлы, которые называются Failover-coordinator. В кластере может быть несколько таких узлов, но в каждый момент времени работать будет только один. Координатор следит за состоянием узлов с помощью протокола SWIM и после смерти текущего лидера назначает следующий живой инстанс в списке Failover priority новым лидером и записывает его в State provider. Если в ваших реплика-сетах есть узлы, которые не должны становится лидерами, вы также можете пометить их как Non-electable в WebUI или через GraphQL.
Узлы, в свою очередь, опрашивают State provider и после появления информации о новом лидере применяют изменения к себе. Помимо этого, лидеры периодически записывают в State provider состояние своих vclock.
Особенность координатора в том, что он знает, какой узел является лидером в реплика-сете и не будет выбирать нового лидера, пока жив текущий. Это частично решает проблему «штормов», потому что переключение лидера будет происходить только после гибели текущего, а не после восстановление предыдущего. Здесь возникает другая проблема: большинство инсталляций кластеров Cartridge/TDG разделены на 2 или больше ЦОДов: лидеры существуют в основном ЦОДе, а реплики в побочном, который может находиться далеко от клиентов. Хочется, чтобы лидеры большую часть времени находились в основном ЦОДе. Для этого в Stateful-режиме есть специальная настройка leader_autoreturn. При ее включении раз в заданный тайм-аут фейловер будет пытаться сменить лидера на первый узел из списка Failover priority.

В виде псевдокода это можно представить следующим образом:
------- on each node -------
while true do
new_leaders = get_leaders_from_stateboard()
if new_leaders ~= old_leaders then
if i_am_new_leader then
old_leader, lsn = get_lsn_from_stateboard()
wait_lsn(old_leader, lsn)
set_lsn_to_stateboard(box.info.uuid, box.info.lsn)
end
box.cfg{read_only = not i_am_new_leader}
end
end
------- on failover coordinator -------
leaders = {}
while true do
for replicaset in replicasets do
if leaders[replicaset] and not leaders[replicaset].is_healthy then
for instance in replicaset do
if instance.is_healthy then
leaders[replicaset] = instance
end
end
end
end
set_leaders_to_stateboard(leaders)
endЧто выступает в роли State provider? Кластер etcd (рекомендуемый вариант) или Tarantool Stateboard. Учтите, что Cartridge поддерживает только etcd API V2, так что нужно пользоваться либо etcd v2, либо etcd v3 с включенной настройкой
ETCD_ENABLE_V2.Tarantool Stateboard
Отдельно стоящий инстанс Tarantool, непосредственно в кластере не участвует и не отображается в WebUI. Сохраняет необходимую информацию для работы фейловера вместо etcd. Подходит для небольших кластеров и тестирования. Кластеризацию стейтборда придется поддерживать самостоятельно: сейчас Cartridge не позволяет указать несколько инстансов стейтборда.
Как включить фейловер?
- Поднять State provider — Tarantool Stateboard или кластер etcd.
- Назначить на несколько узлов роль Failover-coordinator.
- Нажать на кнопку Failover в WebUI и выбрать режим Stateful.
- Указать адрес State provider (в случае etcd — несколько адресов).
- Применить изменения.
Как сменить лидера? Нажать на кнопку Promote a leader в WebUI.

Или с помощью GraphQL:
mutation { cluster { failover_promote() } }
Как происходит смена лидера
- Failover coordinator записывает в State provider uuid нового лидера.
- Новый лидер видит, что его назначили лидером.
- Старый лидер переходит в Read only.
- Новый лидер узнает из etcd, кто был последним лидером для его реплика-сета, и получает его vclock.
- Новый лидер дожидается синхронизации со старым лидером (ждет, пока их vclock’и сравняются).
- Новый лидер переходит в Read write.
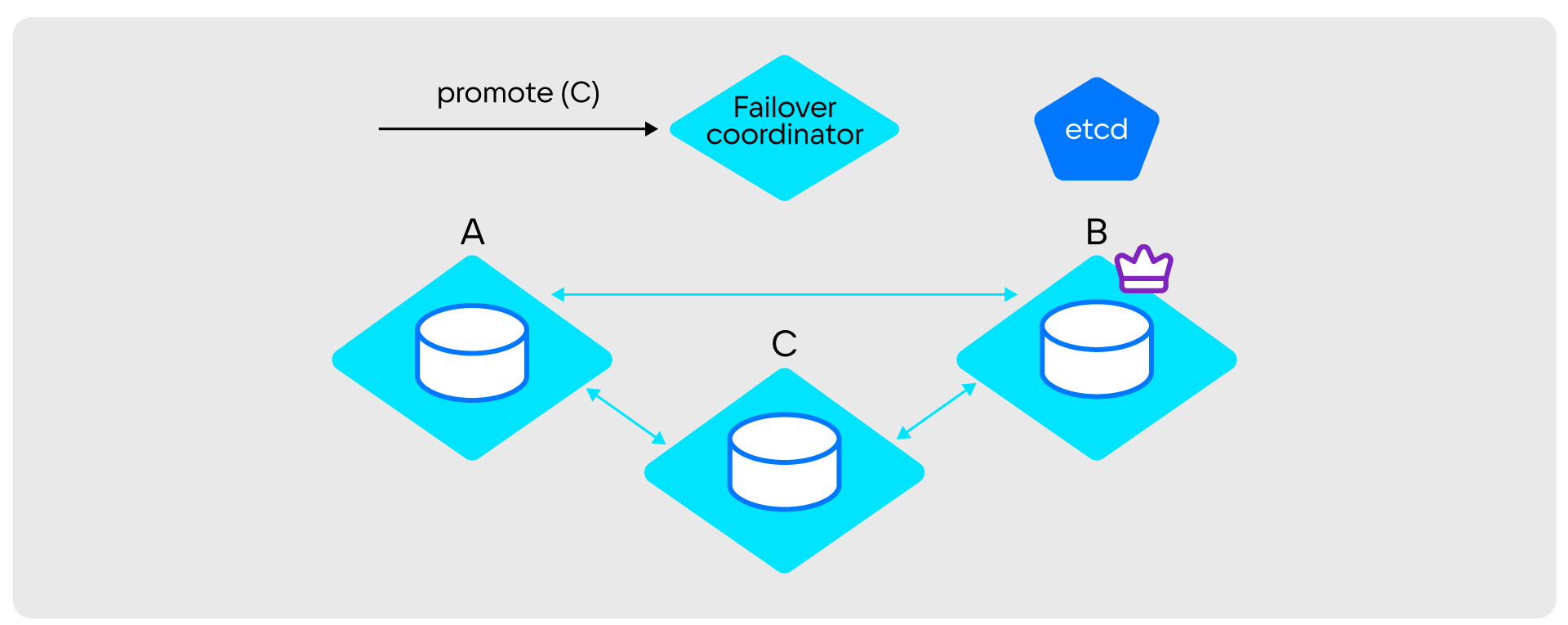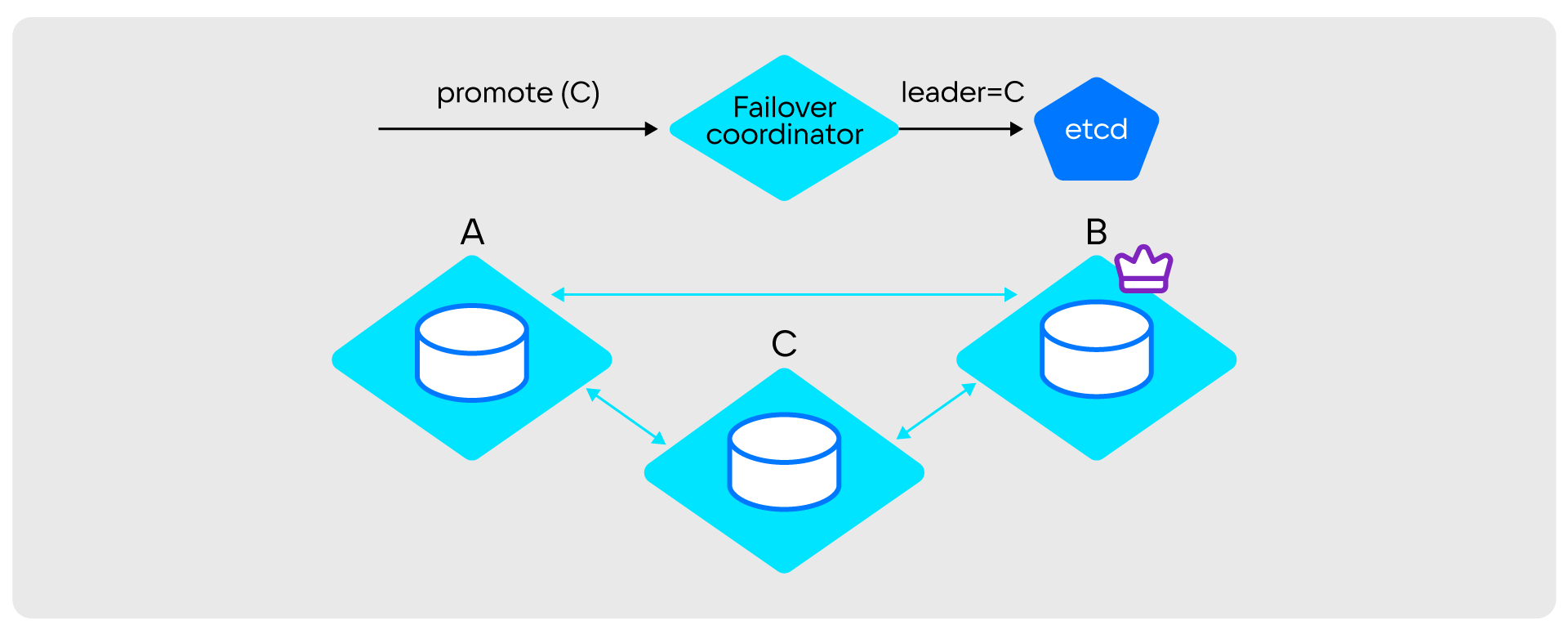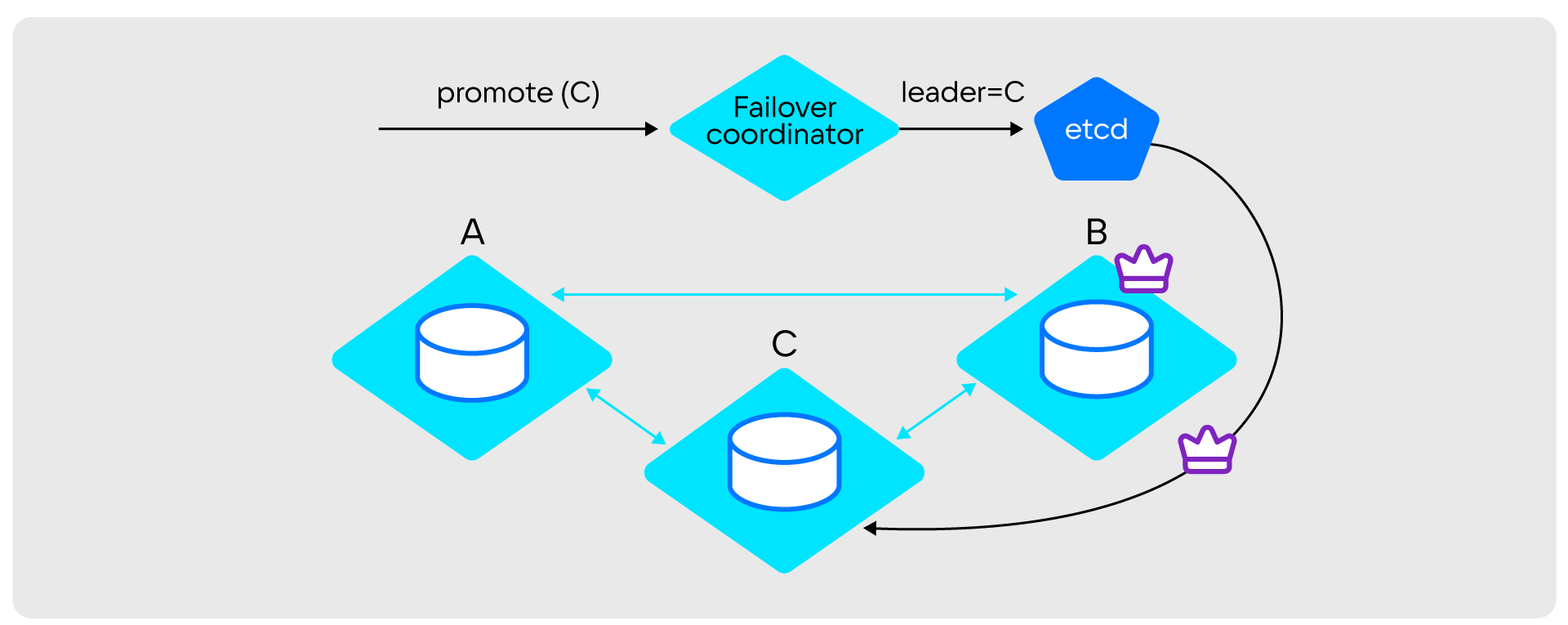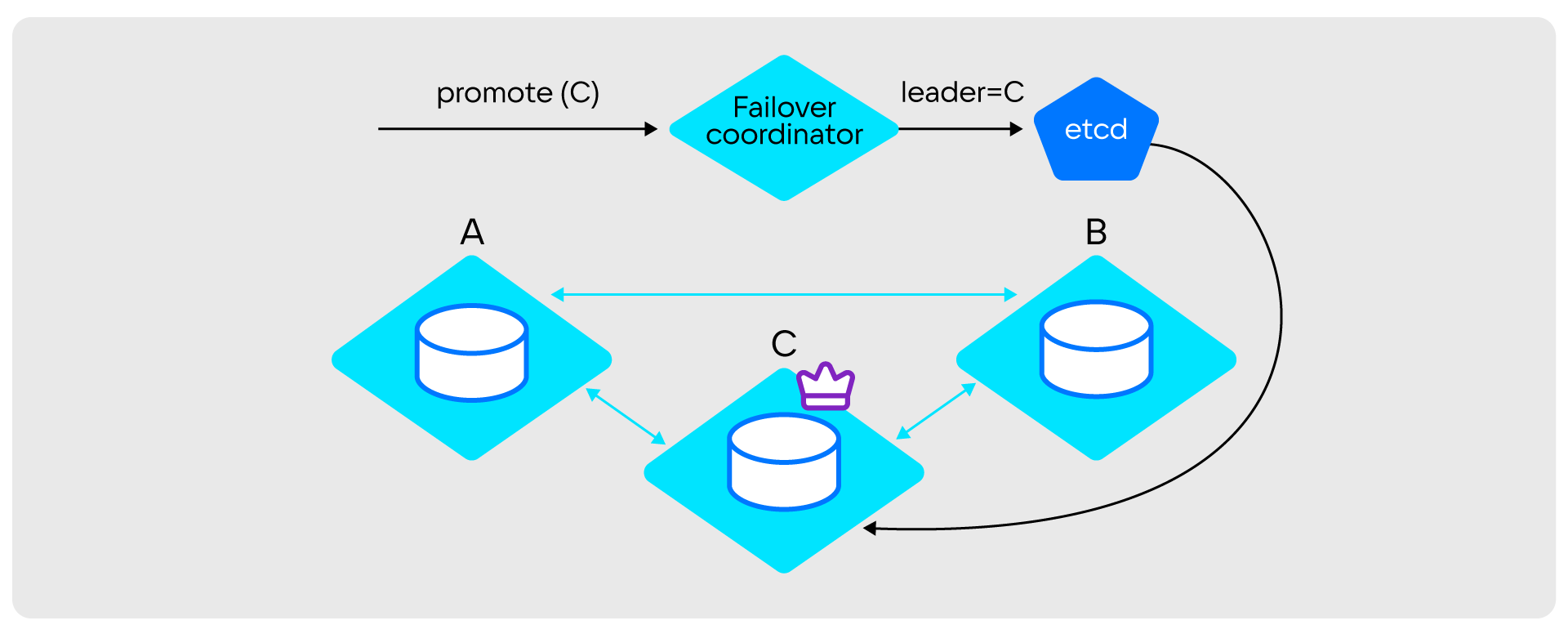
Фенсинг
При проблемах с сетью несколько инстансов могут посчитать себя лидерами и работать параллельно. Чтобы этого не случилось, в Stateful-режиме есть специальная настройка — фенсинг. Она запускает файбер, который проверяет, есть ли соединение со State provider и хотя бы с одной репликой. Если оба соединения установить не удается, узел автоматически переходит в Read-only-режим до тех пор, пока соединение не восстановится.
Failover + Synchro
Синхронная репликация появилась в Tarantool еще в версии 2.6, но мы долго не поддерживали ее в Cartridge. Начиная с Cartridge 2.8.0, вы можете пользоваться синхронными спейсами в двух режимах фейловера: в Raft и Stateful-режиме. Raft поддерживает синхронную репликацию по умолчанию, а для Stateful-фейловера настройку необходимо явно передать в
cartridge.cfg:cartridge.cfg({
...
enable_synchro_mode = true,
})
Почему это необходимо включать отдельной настройкой? Из-за особенностей реализации синхронной репликации в Tarantool лидеры должны получать владение над синхронной очередью транзакций. При включении sychro_mode в Cartridge фейловер вызывает функцию
box.ctl.promote, которая переносит владение синхронной очередью. Если вы не пользуетесь синхронной репликацией, выполнение дополнительной логики будет только тормозить процесс фейловера.В Eventual failover синхронная репликация работать не будет!
Мониторинг
Cartridge следит за состоянием и работой фейловера и сообщает пользователям, если что-то пошло не так, через систему Cartridge issues. Их можно увидеть в WebUI.
Виды предупреждений:
- отсутствие или недоступность Failover coordinator,
- различные ошибки при работе фейловера,
- использование нескольких различных кластеров по одному префиксу в etcd / с общим Tarantool Stateboard,
- использование синхронной репликации вместе с неподдерживаемым типом фейловера.
Итоги
Фейловер в Cartridge и TDG обеспечивает отказоустойчивость наших приложений. Самым продвинутым и рекомендуемым на данный момент является Stateful failover, который использует etcd как хранилище состояний. В таблице вы можете взглянуть на сравнение режимов фейловера:
|
Disabled |
Eventual |
Raft |
Stateful |
|
| Состояние |
Deprecated |
Beta |
Recommended |
|
| Поддерживаемый размер кластера |
Любой |
Маленький |
Любой |
Любой для etcd, средний для Stateboard |
| Лидер |
Задается вручную |
Первый живой узел в списке |
Выбирается автоматически |
Выбирается автоматически, выбор запоминается |
| Где сохраняется информация о текущем лидере |
На узлах Tarantool |
etcd/Stateboard |
||
| Кто управляет переключением |
Пользователь |
Failover fiber |
Raft-алгоритм в Tarantool |
Failover fiber + Failover-coordinator |
| Как поменять лидера вручную |
Изменить список Failover priority |
Изменить список Failover priority |
box.ctl.promote/ Кнопка promote в WebUI / GraphQL promote callback |
Кнопка promote в WebUI / GraphQL promote callback |
| Запрет на становление лидером |
Failover suppressing |
Raft fencing |
Fencing |
|
| Как включить |
Failover -> Disabled |
Failover -> Eventual |
Передать параметры для настройки Raft (переменные окружения, параметры запуска), Failover -> Raft |
Поднять State provider, назначить на один или несколько узлов роль Failover-coordinator, Failover -> Stateful, указать адрес State provide |
А что дальше
Начиная с Tarantool 3.0, обеспечением отказоустойчивости будет заниматься сам Tarantool. Мы продолжаем поддерживать Cartridge и улучшать наш фейловер. Оставайтесь с нами и следите за обновлениями!
Полезные ссылки
-
Масштабирование приложений на Cartridge
-
Антипаттерны при работе с Tarantool
-
Документация Cartridge Failover
- Про Raft в Tarantool: раз, два, три, четыре
-
SWIM