
Всем привет! Я Тимур, лид одной из android-команд. Больше трех лет работаю в Тинькофф, все это время был в привлечении и занимался флоу получения разных банковских продуктов.
Расскажу, как мы сделали свой DSL для того, чтобы строить логику навигации в наших флоу.
Оцениваем флоу
В самом простом варианте клиент в первый раз установит приложение и введет свои персональные данные. Мы попросим его выбрать какой-нибудь продукт. Если он выберет дебетовую карту, сразу создадим ее, выпустим и предложим назначить встречу.
Если клиент выберет кредит наличными, его клиентский флоу будет похож на лестницы в Хогвартсе:

Пути клиента могут зависеть от того, какие варианты ответов он выбирает в формах, какие сейчас AB-тесты проходят, какие конфиги присылает Бэк. Немного подслащает пилюлю то, что многие экраны похожи друг на друга.
Например, экраны «Выбери из списка», «Выбери несколько из списка» или экраны с формами. Еще есть всяческие кастомные экраны в каждой заявке. Нам нужно уметь миксовать повторяющиеся экраны.
Практически на каждом экране заявки есть очень маленький, но коварный progress bar. Казалось бы, чтобы его отрисовать, нам нужно просто посчитать, сколько шагов клиент прошел и сколько всего шагов в заявке. Но количество шагов может зависеть от того, какие варианты ответов выбирает клиент.
Progress bar может зависеть от ответов Бэка, при этом не каждый шаг заявки считается за шаг. Он шарится между всеми экранами, то есть это общая вьюха, которая находится над шагами. Но при этом не на каждом шаге нужно отображать progress bar. И это только часть проблем, которые возникают с этим маленьким элементом.
Что нам нужно как разработчикам:
Переиспользовать внешне похожие экраны: если там вдруг произойдет какой-нибудь редизайн, мы можем быстренько в одном месте все поменять — и готово.
Считать прогресс заявки.
Делать очень длинный флоу с большим количеством переходов, условий и при этом не сходить с ума.
Переиспользовать повторяющуюся логику навигации. Она повторяется зачастую между многими заявками.
Видеть то, как в коде матчатся логики навигации с тем, как она выглядит в дизайне. То есть видеть ее в одном центральном месте.
Писать проще код, так как у нас много логики навигации и много тестов, связанных с навигацией.
Планируем библиотеку
Мы оценили требования к работе, подумали-помозговали и придумали графы, в которых каждый экран представлен как data class.
Например, экран «Выбери из списка» — у него есть заголовок, список из элементов, которые можно выбрать, а у экрана с формой есть конфиг этой формы. Если есть какой-то кастомный экран, то для него создается своя кастомная структура данных, помещаемая в граф. Каждую стрелочку в графе мы храним как лямбды — условия перехода с одного экрана на другой.

Так родилась библиотека Tinkoff Forms Navigation, которая все наши требования и реализовывает. Она состоит из четырех компонентов.
Node — data class, который описывает один тип экрана.
Page — фрагмент, немного необычный тем, что он отрисовывает свой контент по этой самой ноде.
Graph — описывает навигацию и состоит из этих же самых нодов. И описывает условия перехода между ними.
Host Fragment — фрагмент, который все соединяет, то есть он берет Graph и, следуя ему, показывает нужные ноды в нужное время.
Описываем экран
Разберем, что такое Node. Как пример возьмем экран с выбором из списка:

Есть билдер для Node этого экрана с обязательным параметром — это ViewModelKey. Параметр описывает, какую ViewModel будет использовать экран. Можно взять дефолтную ViewModel, которая просто берет данные и закидывает в абстрактный consumer данных, а можно написать свою реализацию, которая необходима в вашем контексте.
Tag нужен для аналитики, дебага и прочей внутрянки. Дальше мы можем использовать билдер самого экрана: указать заголовок, список опций, которые присутствуют на этом экране. Указываем title для каждого элемента, то есть какой текст будет отображаться, и payload — то, как мы в коде увидим, что именно выбрал клиент, обычно там просто какой-то Enum.

Формы создаются так: указываем, какая ViewModel будет использоваться, Tag, заголовок и создаем провайдер формы. Провайдер формы — это штука, внутри которой мы билдим нашу формочку.
Реализуем экран
Посмотрим, как реализуется один из пейджей: возьмем кастомный экран, где есть калькулятор кредитов. Сначала напишем ноду для этого экрана. У ноды есть параметры, которые описывает экран: Key, тот самый, который указывает ViewModel, и Tag.
PageAttributes указывают на то, как экран ведет себя глобально во флоу и может влиять на какие-то параметры навигации. Например, какую анимацию перехода использовать. Нужно ли этот экран считать как шаг, когда мы считаем прогресс-бар? Нужно ли показывать стрелочку назад и крестик?

Дальше идут параметры, связанные с этим экраном, например заголовок. Потом пишем флаг — показывать ли ставку по кредиту. В этом случае мы его не показываем. И дальше маленькие тексты, которые будут отображаться внизу под калькулятором.
Generic-параметр указывает на то, какой будет результат взаимодействия с экраном. На этом экране клиент вводит сумму, которую он хочет взять в кредит, а результатом будет MoneyAmount.

Далее реализуем саму пейджу, которая отрисует нам контент. Наследуемся от базовой пейджи и тоже указываем generic-параметры:
MoneyAmount— результат взаимодействия с экраном.LoanCalculatorPage.Node— какая нода используется.BaseCalculatorViewModel— какая view-модель будет использоваться у пейджи.
Реализуем знакомые нам onCreateView и onViewCreated. А все потому, что пейдж — это самый обычный фрагмент. Отличие лишь в том, что у него есть Node и мы решили в коде называть такие фрагменты Page.
Дальше нужно как-то в логике экрана перейти на следующий экран. Мы работаем из концепции, что каждый конкретный экран не знает, что может быть после него. Поэтому при нажатии на кнопку «Продолжить» вызываем метод forward и в него передаем результат взаимодействия с текущим экраном.
Описываем навигацию
Соединим все в графы — сделаем простую навигацию, где после одного экрана идет другой и неважно, что на нем было выбрано.

Дальше начинается наш Kotlin DSL для построения графов: функция navigationGraph возвращает инстанс собранного графа и имеет один обязательный параметр — стартовая нода, то, с чего будет начинаться флоу. В самом билдере графа соединяем две ноды с помощью оператора connectTo. Вся логика навигации для простого случая готова.
На деле нужна логика посложнее: если клиент говорит, что он живет по адресу регистрации, мы не хотим его спрашивать, где он проживает. Мы и так это уже знаем. Но если он говорит, что живет по другому адресу, то уточняем его адрес проживания — появляются условия перехода:

Для условий перехода снова пишем navigationGraph, и все начинается с экрана «Где вы живете». Дальше пишем, что с экрана «Где вы живете» переходим на экран «Адрес проживания» при условии, что клиент выбрал, что живет по другому адресу.
Пишем, что если он выбрал адрес регистрации, то переходим на экран «Где вы работаете». Не хватает одной стрелочки — от «Адрес проживания» до «Где вы работаете», добавляем еще один безусловный переход — все готово.

Вся логика с адресом проживания и регистрацией используется в трех заявках. В кредитах наличными, в кредитных картах, в рефинансировании. Нам хотелось бы ее как-то переиспользовать
Для переиспользования создаем отдельный Graph. Точно так же все начинается с экрана «Где вы живете». Точно так же говорим, что если было выбрано по другому адресу, то переходим на адрес проживания. А дальше пишем otherwiseLeave() — то есть в противном случае просто покидай флоу, завершай его.
Дальше этот граф закидываем в какую-нибудь переменную или делаем функцию, которая будет создавать граф. Созданный граф используем так, будто это нода и после него идет экран «Где вы работаете».
На деле после того, как граф будет собран, он заинлайнит все вложенные подграфы. И из каждой ноды, из которой можно было выйти в предыдущем вложенном графе, он создаст переход к тому месту, куда мы его соединили. Так мы можем насколько угодно большие графы выделять в отдельные компоненты, сколько угодно много вкладывать их друг в друга. И, по сути, так мы декомпозируем и переиспользуем логику навигации.
Как пример, один из реальных графов наших заявок:

chain, который все, что у него передано, показывает по очереди. То есть там будут ноды или какие-то подграфы. Оператор optionalGraph принимает в себя другой подграф и лямбду, которая указывает на то, нужно показывать этот подграф или нетПо этому флоу сразу понятно, что есть начальные экраны в подграфе startFlow, потом опциональные подграфы про паспорт, про регистрацию, про дом, про работу и так далее. И потом какой-то экранчик с дополнительной информацией.
Благодаря тому, что мы билдим эти графы как структуры данных, можем их при необходимости удобно визуализировать.

Собираем все воедино
У нас есть графы с экранами флоу, теперь соберем фрагмент, который можно отобразить и использовать. Создаем класс, наследуемся от базового фрагмента и дальше переопределяем три обязательных метода:
метод
onBuildGraph, который будет билдить граф;pageFactory— эта штука умеет создавать инстансы фрагментов для какой-то конкретной ноды;viewModelFactory— создает ViewModel, которые мы указывали в нодах графа.
Наш флоу готов!

Достоинства собственной библиотеки
С помощью графов видим явную логику навигации в одном месте, централизованно. Можем посмотреть на дизайн, на граф и увидеть, как они матчатся друг с другом. Нам не приходится заходить в onClick каждого экрана, разбираться, откуда из одного экрана можно попасть в другой. Все описано в одном месте, удобно и понятно.
Благодаря нодам мы явно расписываем контракт экрана, в его параметрах указываем, какие аргументы есть, что можно кастомизировать. А с помощью generic-параметра ноды можем понять, какой будет результат взаимодействия с этим экраном. И тем самым мы можем не связывать экраны, легко их переиспользовать в разных контекстах, разных флоу.
Кроме того, мы можем подставлять туда разные ViewModel под разные кейсы. Например, добавить бизнес-логику к определенному экрану в определенном контексте, сохранив его UI.
Нам легко описать тесты на навигацию. Если мы покроем один раз базовую Page UI-тестами, проверим то, что при конкретной конфигурации Node он будет отрабатывать конкретным образом, покроем все кейсы для этой базовой пейджи, то дальше, когда мы будем использовать ее уже в каком-то конкретном флоу, нам будет достаточно проверить, что у нас лежит правильно сконфигурированная нода в правильном месте графа.
Например, создаем самый обычный unit test, внутри делаем граф и закидываем в другой DSL для написания тестов: пишем assertGraph и внутри закладываем нужные нам проверки.
Например, можно написать expectListPage:
@Test
fun `test refinance graph example`() {
assertGraph(createRefinanceGraph()) {
expectListPage {
hasHeader("Выберите вид рефинансирования")
hasOptionWithPayload(
optionTitle = "Ипотека",
optionPayload = REFINANCE_MORTGAGE,
)
hasOptionWithPayload(
optionTitle = "Автокредит",
optionPayload = REFINANCE_AUTO_LOAN
)
}
}
}Это означает, что мы ожидаем в текущей позиции графа экран выбора из списка. Внутри этого блока мы можем проверять параметры экрана, например его заголовок с помощью hasHeader, или какие варианты предлагаются на выбор на этом экране.
Дальше можем симулировать навигацию вперед, написать forward, прокинуть то, с каким результатом мы перешли вперед по графу. И проверить то, что теперь мы ожидаем экран с формой. Еще нужно проверить заголовок, проверить то, что там лежит правильно сконфигурированная форма:
@Test
fun `test refinance graph example`() {
assertGraph(createRefinanceGraph()) {
expectListPage {...}
forward(REFINANCE_MORTGAGE)
expectFormPage {
hasHeader("Адрес ипотечной квартиры")
hasForm {
field<Address>(RefinanceFields.OPTION_MORTGAGE_ADDRESS) {
hasTitle("Адрес и номер квартиры")
}
}
}
}
}Устройство библиотеки
Посмотрим глубже, как все работает, начнем с Kotlin DSL. Напишем простенький DSL, который умеет соединять две ноды. Для этого создаем самый обычный классический Java-билдер. Добавляем метод connectNodes, который берет две ноды и соединяет их, и метод build — он создаст нам граф.
Дальше создаем функцию, которая принимает в себя extension-лямбду к этому билдеру, а в реализации создает сам билдер, применяет лямбду, а затем вызывает build. Тем самым мы получаем что-то похожее на DSL, когда у нас есть блок navigationGraph, а внутри него нам становятся доступны различные операторы.
class GraphBuilder {
fun build(): Graph = TODO()
fun connectNodes(fromNode: ContentNode, toNode: ContentNode) {
// TODO save connection
}
}
fun navigationGraph(builder: GraphBuilder.() -> Unit): Graph =
GraphBuilder().apply(builder).build()Но нам хотелось бы, чтобы connectsTo выглядел как оператор, а не как вызов функции с двумя аргументами. Для этого нужно создать connectsTo как infix-функцию, которая является extension-методом к первому аргументу нашей прошлой функции. Мы получаем оператор, а внутри в реализации можем просто дернуть старый метод, который соединял две ноды:
class GraphBuilder {
// ...
infix fun ContentNode.connectsTo(toNode: ContentNode) {
connectNodes(fromNode = this, toNode = toNode)
}
}
// Получаем:
navigationGraph {
firstNode connectsTo secondNode
}Нужно разобраться, как будет работать сохранение состояния, потому что с графами это дело не самое простое. У нас есть GrapCrawler — штука, которая умеет ходить по графу, запоминать, где клиент в данный момент находится, и после рестарта процесса возвращать клиента к текущему состоянию нашей навигации.
У GrapCrawler есть метод currentNode, возвращающий ноду, в которой мы сейчас находимся, метод forward, принимающий результат текущего экрана и возвращающий следующую ноду для отображения, и метод backward для навигации назад.
currentNode — это, по сути, состояние. Если вдруг клиент на 20-м экране свернет приложение и система убьет наш процесс, то когда мы будем снова открывать приложение, нам нужно как-то восстановить это состояние. Давайте посмотрим, как это делается.
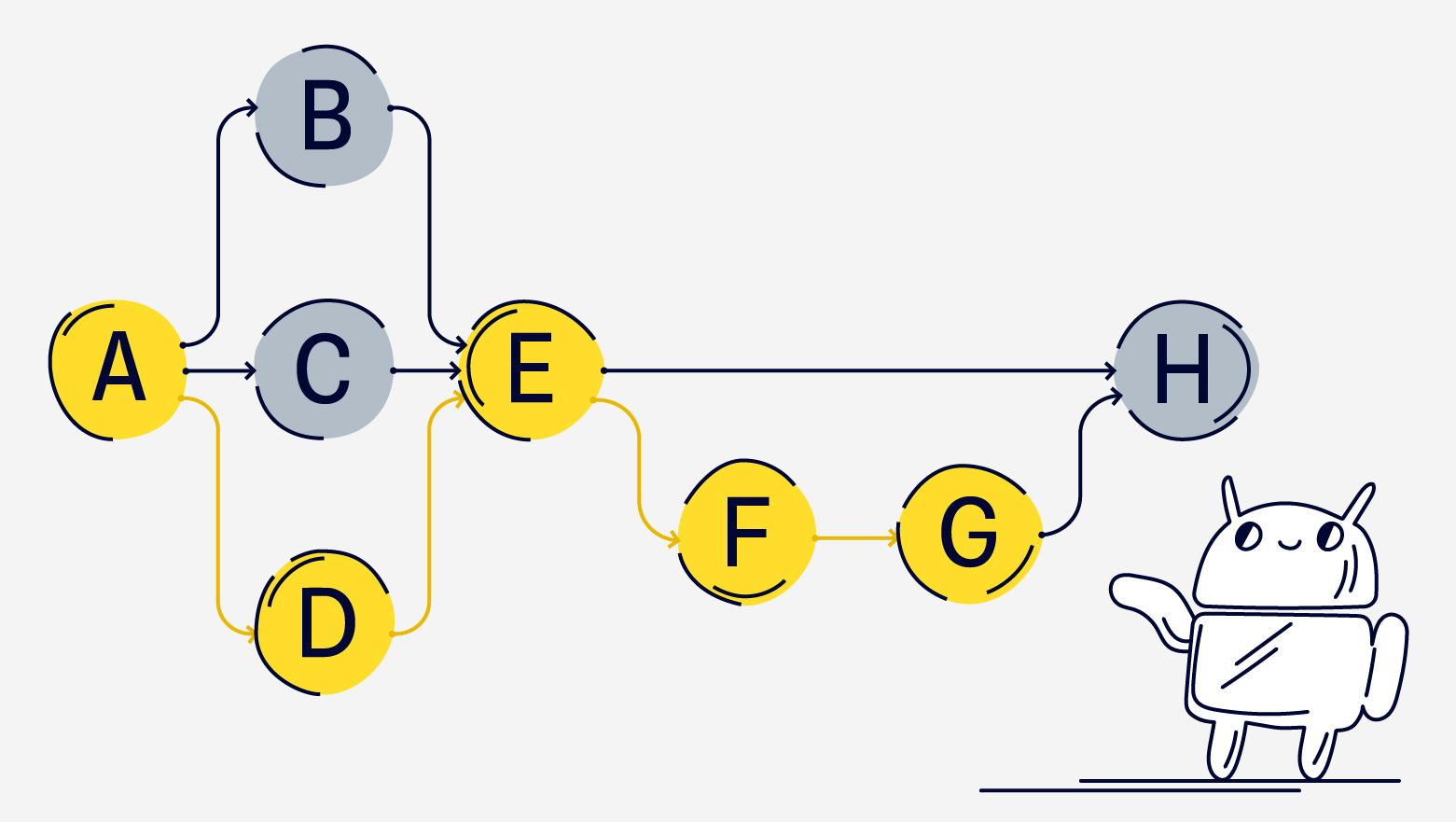
Допустим, у нас есть такой граф:

Клиент прошел путь — ADEFG. Допустим, при пересоздании процесса мы просто запоминаем текущую ноду клиента, в нашем случае ноду G. Тогда при навигации назад после пересоздания процесса мы не будем знать, куда возвращаться с ноды E. Было бы классно просто взять и сериализовать весь граф вместе с GraphCrawler. Но проблема в том, что там может быть много данных, и их лучше не закидывать в saved state. А еще в графах хранятся лямбды для условий переходов, которые тоже так просто не сериализуешь.
Вместо этого мы просто нумеруем все пути, которые у нас есть, из каждой ноды:

Для нашего случая, когда был путь ADEFG, запоминаем трек — тот путь, который был пройден. 2, 0, 1, 0:

При инициализации GraphCrawler мы заново вызываем билдер графа, а с помощью трека восстанавливаем currentNode и внутренний back stack графа.
Важный вопрос про progress bar: насколько он должен быть заполнен на каждом экране? Не очень понятно: например, клиент может пойти из E в H, а может из E пойти в F. Если он собирается пойти в H, то, получается, он прошел 75% заявки, а если в F, то 50%.
Если мы отобразим 75% — он пойдет в H, все будет ок. Но если он пойдет в F, то progress bar поползет назад к 66%. А это самое ужасное, что можно сделать для клиентского опыта: когда ты заполняешь заявку, нажимаешь на «Продолжить», и тут внезапно progress bar едет в обратную сторону.
На помощь приходят алгоритмы на графах! Для каждой ноды мы считаем самый длинный возможный дальнейший путь по графу и делим его на самый длинный путь от начала графа до его конца. Тем самым для каждой ноды мы отображаем минимально возможный прогресс. Это работает консистентно, стабильно и понятно клиенту.
Проблемы при разработке
Расскажу, когда стоит использовать графы, и о проблемах, которые у нас были при разработке, чтобы вы могли избежать наших ошибок, если вдруг будете делать такое же.
Когда стоит и не стоит использовать KotlinDSL для графов:
Использовать |
Не использовать |
Когда очень длинный флоу, много экранов, много переходов, сложно это переварить за раз |
Когда короткий флоу, все просто и понятно, это будет точно overkill |
Когда много условий переходов, сложно понять, откуда куда можно попасть |
Когда длинная цепочка экранов, но там все переходы безусловные, никакие экраны никогда не пропадают, всегда одна и та же последовательность, никаких условных переходов нет |
Когда много похожих экранов, но при этом они переиспользуются в разных контекстах, могут иметь разную бизнес-логику, но один UI |
Когда флоу содержит активити вперемешку с фрагментами |
Мы построили взаимодействие с хост-фрагментом на коллбеках к parent-фрагменту. Это усложнило нам тестирование: получается, сам по себе пейдж не может существовать без host-фрагмента. И нам в каждом тесте приходилось делать стабовые host-фрагменты, которые нужны просто для того, чтобы один изолированный пейдж смог отобразиться.
Аналогичная ситуация, если нам вдруг захочется переиспользовать пейдж. Например, есть экран выбора дизайна карты, он встречается в заявке на дебетовую карту, но может быть изолированно использован для изменения дизайна уже созданной виртуальной карты. И в этом случае нам тоже приходится делать отдельный хост-фрагмент, который умеет отображать только эту пейджу.
Так делать не надо. Лучше использовать конструкторы фрагментов и прямо в них явно прописывать все необходимые коллбеки и зависимости, необходимые для отображения и работы.
Тут кто-то может сказать, что во фрагмент нельзя ничего передавать через конструктор. Но на самом деле это можно делать с помощью FragmentFactory. Мы их очень активно используем и всем рекомендуем.
Абстракции — в корне фреймворка мы использовали абстрактный BasePage как минимальный элемент UI, который можно отобразить в нашем графе. И в будущем это привело к проблемам того, что мы не можем переиспользовать уже существующие фрагменты в наших заявках.
Допустим, бизнес захочет использовать флоу назначения встречи, который был всегда изолированным самостоятельным фрагментом, прямо в заявку. Мы это сделать не можем, потому что он не является наследником BasePage.
Вместо этого лучше использовать обычный фрагмент как абстракцию. Но тут возникает вопрос: если у нас есть обычный фрагмент, то как мы из него сообщим результат взаимодействия с этим фрагментом? Тут лучше применять какой-то универсальный подход, который будет легко использовать на стороне вашего host-фрагмента и без привязки к библиотеке навигации на графах, например Fragment Result API.
Статья — расшифровка моего доклада на канале IT’s Mobile Dev, заходите посмотреть доклады моих коллег и задавайте вопросы в комментариях, если они появятся.
Комментарии (7)

ggo
22.11.2023 06:43+1Когда очень длинный флоу, много экранов, много переходов, сложно это переварить за раз
По моему когда очень длинный флоу, то ни визуально, ни ...-as-code переварить очень сложно.
И спасает только декомпозиция.
А в целом, представлять флоу в виде человеко-ориентированного DSL (неважно какого, хоть Kotlin DSL, хоть любой прочий) - очень хорошая практика.

Dolios
22.11.2023 06:43-3Пишем Kotlin DSL для графов навигации в домашних условиях
Хм...
DSL, digital subscriber line, цифровая абонентская линия
Что вы пишите? При первом упоминании аббревиатуры следует давать её расшифровку. Особенно, когда ваша аббериатура совпадает с общеупотребительной, но вы явно что-то другое имеете в виду.

xaerom
22.11.2023 06:43Все верно.
Котлин — остров в Финском заливе Балтийского моря, в 30 км западнее центра Санкт‑Петербурга.
Совсем не понятно про что статья.
Dolios
22.11.2023 06:43Очень смешно (нет).
Совсем не понятно про что статья.
Мне было не понятно, даже нагуглить с ходу не получилось, я не программирую ни на колтине, ни на джаве. А гугл, ожидаемо, на первой странице выдачи по запросу "DSL" показывал исключительно про модемы и линии связи. Думаю, у 90% российских айтишников старше 30 эта аббревиатура ассоциируется прежде всего со способом получения доступа в интернет.
Ещё раз, давать расшифровку аббревиатур - правило хорошего тона, а не давать - неуважение к читателю. Если читателю приходится гуглить и выяснять, что там автор имел в виду, статья плохая. Если речь о научных статьях, то такое просто завернут.

HiroProtagonist
22.11.2023 06:43+2Тимур привет! Уберите из флоу такое явное согласие на сбор биометрии, спасибо!
ALEXfanat
Графы и навигация это уже пройденный этап. Jetpack compose вот куда надо смотреть
Mexator
В Compose вопрос навигации тоже актуален. От представления навигации в виде графа никуда не деться