
Салют, Хабр! Ранее мы в SberDevices анонсировали предобученную на русском языке модель GigaAM (Giga Acoustic Model) и её дообученные состояния под распознавание речи (GigaAM-CTC) и определение эмоций (GigaAM-Emo). Сегодня же делимся с сообществом весами моделей и примерами использования.
Приглашаем под кат погрузиться в self-supervised learning для звучащей речи и оценить возможности предобученных моделей!
Self-Supervised Learning
Одним из вызовов в области машинного обучения является сбор обучающих данных. Для задач речевых технологий данный вопрос стоит тем более остро, поскольку используемые данные имеют сложную природу. Например, человеку трудно определить по звуковой записи эмоцию спикера и разобрать содержание речи в шумных условиях. Для уверенности в качестве данных одну и ту же аудиозапись размечает несколько экспертов. Это замедляет процесс разметки и повышает его стоимость.
К многообещающим подходам, призванным снижать количество размеченных данных, относится Self-Supervised Learning. В данной парадигме создание модели для прикладной задачи состоит из двух этапов. На первом из них модель обучают выявлению общих закономерностей в речи на большом репрезентативном корпусе. Второй этап направлен на дообучение с небольшим объемом размеченных данных под целевую задачу.
Self-Supervised Learning for Speech
Речевые данные имеют общие свойства как с текстами, так и с изображениями. С одной стороны, текстовые и речевые данные имеют последовательную структуру, временную составляющую. С другой — изображения и речь являются непрерывными сигналами. Как следствие, большая часть self-supervised подходов для звучащей речи основана на идеях, вдохновленных областью Natural Language Processing и / или Computer Vision.
Для предобучения GigaAM мы использовали подход Wav2Vec2.0, но перед его описанием рассмотрим HuBERT и BEST-RQ, которые позволят сформировать интуицию предобучения.
Predictive: HuBERT, BEST-RQ
Первый подход, который мы рассмотрим, нацелен на перенос идеи обучения BERT на звучащую речь: использовать архитектуру Transformer и задачу Masked Language Modeling (MLM). Основным препятствием для прямого применения такого подхода является отсутствие словаря дискретных токенов, которые необходимо предсказывать.
Авторы HuBERT обходят это ограничение с помощью применения k-means кластеризации к признакам, извлекаемым из аудиозаписей. После обучения алгоритма кластеризации вектору каждого сегмента аудио будет соответствовать индекс кластера, к которому он принадлежит.
Таким образом, во время обучения энкодер трансформера нацелен на предсказание меток кластеров для замаскированных участков входного сигнала. Подход стимулирует модель восстанавливать пропущенный контент речи. Описанная схема проиллюстрирована на изображении 1.

Стоит отметить, что обучение модели состоит из двух этапов. На первом из них кластеризация строится на MFCC-признаках, кодирующих низкоуровневые особенности сигнала. На втором этапе выходы промежуточных слоев модели проходят через алгоритм кластеризации для построения нового словаря, с которым энкодер обучается повторно. Это позволяет внести в целевые переменные больше семантической информации.
Метод показывает отличные результаты в few-shot learning-сценарии и вдохновил дальнейшее развитие предсказательного подхода, а именно BEST-RQ.
В BEST-RQ авторы предложили упростить процесс построения словаря. Идея подхода иллюстрирована на изображении 2.

Вместо кластеризации здесь используется модуль квантизации, который работает следующим образом:
Вектор признаков сегмента аудиозаписи проецируется в пространство codebook’а. Последний представляет из себя случайно инициализированную вещественную матрицу.
Вычисляется косинусное сходство между проекцией аудио-сегмента и каждым вектором codebook’а.
В качестве целевой переменной используется индекс ближайшего по косинусу вектора codebook’а.
После построения дискретных целевых переменных энкодер обучается на MLM-задачу. Обучение в сценарии BEST-RQ проходит в один этап и, что более важно, является стабильным и масштабируемым.
Contrastive: Wav2Vec2.0
В подходе wav2vec2.0 энкодер обучают с помощью Contrastive-задачи вместо MLM. Идея подхода: маскируем часть входных признаков (векторные представления, которые получены после сверточных преобразований) и тренируем энкодер восстанавливать пропущенные сегменты признаков по контексту (изображение 3).

Принцип работы:
Входная спектрограмма пропускается через сверточные слои для снижения длины последовательности. Получаем последовательность эмбеддингов
.
Случайно выбранные эмбеддинги заменяются обучаемым masked-вектором. Полученная последовательность пропускается через трансформер для формирования контекстно-обусловленных эмбеддингов
.
Оригинальные эмбеддинги
, которые были замаскированы, проходят через модуль квантизации для выбора векторов
из дискретного набора codebook’а .
Модель тренируют находить по контекстно-обусловленному вектору
истинный квантизованный вектор
в наборе из
квантизованных кандидатов
,
из которых являются случайными негативными примерами из маскированных сегментов той же аудиозаписи. В ходе обучения минимизируется InfoNCE-loss:
Здесь — косинусное сходство между векторами,
— регулируемый во время обучения параметр.
В отличие от BEST-RQ в подходе wav2vec2.0 используется обучаемый квантизатор. Чтобы решить проблему протекания градиентов через недифференцируемый выбор одного вектора из codebook’а используется Gumbel Softmax.
У обучения wav2vec2.0 имеются свои подводные камни, про них мы рассказывали на конференции Салют, Gigachat, запись доклада доступна по ссылке.
Обучение GigaAM
Существует большое количество открытых предобученных моделей. Например: wav2vec2-XLS-R, HuBERT, WavLM. Однако данные модели обучены либо на английской речи, либо сразу на нескольких языках, что ограничивает их качество на русскоязычных наборах данных.
Для достижения максимального качества на русском языке мы собрали датасет из 50 тысяч часов разнообразных русскоязычных данных.
Из описанных ранее подходов для предобучения мы остановились на wav2vec2.0, поскольку уже использовали его для улучшения production-распознавания и имеем опыт в стабилизации обучения.
В качестве архитектуры выбрали Conformer, поскольку данный энкодер показывает близкие к State-of-The-Art результаты в задачах обработки звучащей речи. Подобранная архитектура модели содержит около 240 миллионов параметров. Такой выбор связан с компромиссом между выразительностью модели и простотой дообучения в условиях ограниченных вычислительных ресурсов.
Метрики качества и функция потерь модели во время предобучения слабо интерпретируемы с точки зрения качества на прикладных задачах. Поэтому далее мы опишем сценарии дообучения и полученные результаты в задачах распознавания речи и определения эмоций спикера.
Дообучение для задачи распознавания речи

Одна из задач для применения универсального аудиоэнкодера — распознавание речи (ASR: Automatic Speech Recognition) или транскрипция контента речи без учета пола, возраста, эмоций спикера.
Основной метрикой качества ASR является Word Error Rate (WER), которая рассчитывается между гипотезой модели и истинной транскрипцией с помощью расстояния Левенштейна и может быть интерпретирована как доля неправильно распознанных слов.
Существует несколько подходов к end-to-end-распознаванию речи. Например: CTC, RNN-T, LAS. Мы проводили эксперименты в CTC-подходе, который является контекстно-независимым (предсказания токена не зависит от предсказанных ранее, нет учета языковой информации). Такой выбор был сделан, чтобы продемонстрировать возможности encoder-only модели. Для дальнейшего улучшения качества читатели могут дообучить модель c другим декодером или использовать Shallow Fusion с внешней языковой моделью.
Большинство подходов в распознавании речи требуют наличия параллельных данных: аудиозапись и соответствующая ей транскрипция. Для дообучения мы остановились на следующих открытых параллельных корпусах данных:
Golos SberDevices, 1227 часов;
SOVA, 369 часов;
CommonVoice, 207 часов;
LibriSpeech, 93 часа.
Нашей целью было создание мульти-доменной модели, которой можно будет распознать как аудиокнигу, так и запрос к виртуальному ассистенту. Чтобы адаптировать GigaAM сразу к нескольким доменам, мы использовали взвешенное семплирование обучающих примеров. Каждый батч обучающих данных содержал в себе примеры из 4 датасетов в следующих пропорциях:
{
"golos": 0.6,
"sova": 0.2,
"common_voice": 0.1,
"librispeech": 0.1,
}Для обучения мы использовали фреймворк Nvidia NeMo. Дообучение на 64 видеокартах Nvidia V100 в режиме Mixed Precision, Distributed Data Parallel заняло около трех дней.
Подробная конфигурация обучения
trainer:
gpus: 8
num_nodes: 8
accelerator: gpu
strategy: ddp
max_steps: 100000
gradient_clip_val: 20
precision: 16
sync_batchnorm: true
accumulate_grad_batches: 4
model:
train_ds:
batch_size: 10
max_duration: 25.0
min_duration: 0.1
spec_augment:
_target_: nemo.collections.asr.modules.SpectrogramAugmentation
freq_masks: 2
time_masks: 10
freq_width: 27
time_width: 0.05
encoder:
_target_: nemo.collections.asr.modules.ConformerEncoder
feat_in: 64
feat_out: -1
n_layers: 16
d_model: 768
subsampling: striding
subsampling_factor: 4
subsampling_conv_channels: 768
ff_expansion_factor: 4
self_attention_model: rel_pos
pos_emb_max_len: 5000
n_heads: 16
xscaling: false
untie_biases: true
conv_kernel_size: 31
dropout: 0.1
dropout_emb: 0.1
dropout_att: 0.1
decoder:
_target_: nemo.collections.asr.modules.ConvASRDecoder
feat_in: 768
num_classes: 33
vocabulary:
- ' '
- а
- б
- в
- г
- д
- е
- ж
- з
- и
- й
- к
- л
- м
- н
- о
- п
- р
- с
- т
- у
- ф
- х
- ц
- ч
- ш
- щ
- ъ
- ы
- ь
- э
- ю
- я
optim:
name: adamw
lr: 5.0e-05
betas:
- 0.9
- 0.98
weight_decay: 0.01
sched:
name: CosineAnnealing
warmup_steps: 10000
warmup_ratio: null
min_lr: 1.0e-07Как и следовало ожидать, после предобучения модель быстро адаптировалась до WER < 10%. Оценка качества производилась на отложенной выборке, представляющей из себя смесь открытых наборов данных после внутренней валидации асессорами.

Для дальнейшего улучшения качества мы использовали semi-supervised learning подход (pseudolabeling): для ≈ 5700 часов речевых данных были восстановлены транскрипции с помощью адаптированной под распознавание GigaAM-CTC. Затем модель дообучалась на следующей смеси данных:
supervised (≈ 2000 часов), weight=0.85;
semi-supervised (≈ 5700 часов), weight=0.15.
Такой подход позволил улучшить качество на репрезентативном валидационном датасете: WER 8.0% → 7.5%. Также стоит отметить, что аугментация с помощью semi-supervised-данных может быть полезна при сдвиге домена. Например, если будет стоять задача распознавания подкаста.

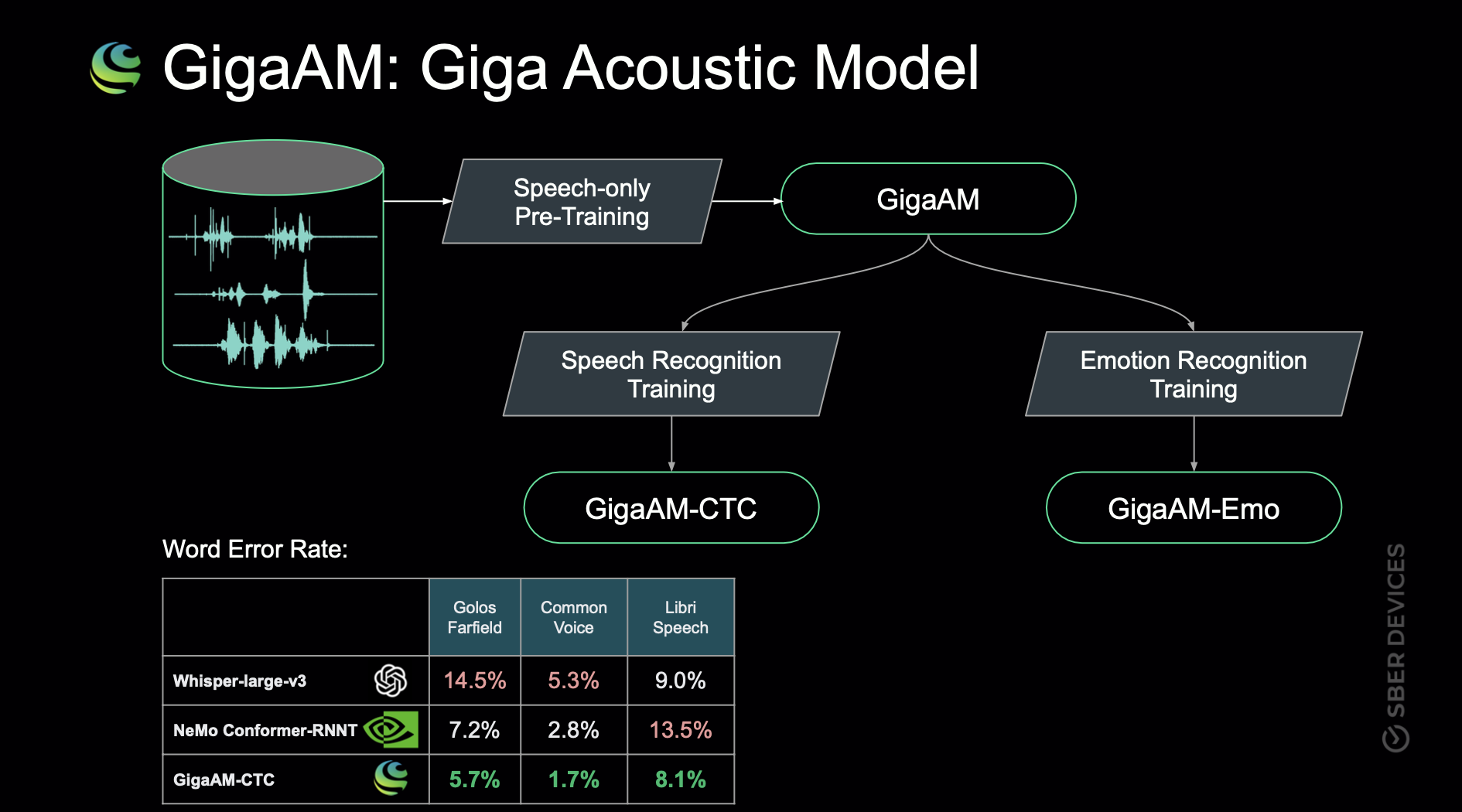
Для финальной оценки качества мы использовали 7 тестовых срезов данных. В том числе датасеты OpenSTT, которые не участвовали в обучении. Каждый из наборов данных состоит из коротких аудиозаписей (до 25 секунд) на русском языке с референсными транскрипциями. Мы проводили измерение на таком числе срезов, чтобы оценить использование модели в широком спектре приложений: от распознавания аудиокниг (Russian LibriSpeech) до запросов в голосовую колонку с расстояния в несколько метров (Golos Farfiled).
В таблице 1 представлены результаты сравнения GigaAM-CTC с популярными open-source моделями в терминах Word Error Rate
модель |
|||||||
Whisper‑large‑v3 (1.5B) |
17.4 |
14.5 |
21.1 |
31.2 |
17.0 |
5.3 |
9.0 |
NeMo Conformer‑RNNT (120M) |
2.6 |
7.2 |
24.0 |
33.8 |
17.0 |
2.8 |
13.5 |
GigaAM‑CTC (240M) |
3.1 |
5.7 |
18.4 |
25.6 |
15.1 |
1.7 |
8.1 |
В среднем, предлагаемая нами модель допускает на 20% меньше ошибок по сравнению с NeMo Conformer-RNNT и на 37% относительно Whisper-large-v3. При этом стоит отметить, что как NeMo Conformer, так и Whisper содержат в себе более выразительный декодер, который добавляет в модель языковую информацию и позволяет лучше выучивать выравнивание между звуком и текстом. Таким образом, дообучение GigaAM с RNNT или Transformer декодером может привести к дальнейшему улучшению качества распознавания.
SaluteSpeech App
Сравнение выше относится к открытым моделям. Еще более качественное распознавание для широкого спектра доменов доступно в SaluteSpeech API. Например, на базе наших технологий можно автоматизировать колл-центры.
При этом технологии SaluteSpeech могут быть полезны не только в бизнесе, но и в повседневных задачах — распознавание записей совещаний, оформление протокола встречи, транскрибация лекций в учебных заведениях.
Для решения этих задач мы сделали приложение SaluteSpeech App, доступное для Windows и MacOS. С помощью него можно транскрибировать любые аудио/видеофайлы, сделать саммари встречи, выделить ключевые мысли.
Отметим, что для всех пользователей после регистрации доступен freemium-режим, благодаря которому можно протестировать приложение и оценить применимость технологий к своим задачам.
Дообучение для задачи определения эмоций

Еще одним применением предобученного аудиоэнкодера является определение эмоций спикера. Для дообучения в этом сценарии мы остановились на датасете Dusha — на сегодняшний день, это самый большой датасет для классификации эмоций. Выбранный набор данных состоит из коротких записей речи (до 20 секунд). Часть аудиозаписей была получена с помощью актеров озвучки (Crowd domain), остальные собраны из разнообразных подкастов (Podcast domain). Каждой из аудиозаписи сопоставлена одна из четырех эмоций спикера: злость, грусть, нейтральная эмоция или счастье.
Задаче определения эмоций свойственен дисбаланс классов целевых переменных: большую часть времени спикер произносит речь спокойно, без выражения каких-либо эмоций. Этот эффект проявляется во всех датасетах, за исключением тех ситуаций, когда датасет был собран в искусственных условиях (например, Dusha Crowd). Для корректной оценки качества модели с учетом специфики задачи мы выбрали следующие метрики:
Unweighted Accuracy — доля правильно предсказанных моделью ответов.
Weighted Accuracy — среднее арифметическое доли правильных ответов по каждому из классов.
MacroF1 — арифметическое среднее F1-меры по каждому из классов.
Для решения этой задачи мы добавили к предобученному аудиоэнкодеру классификационный модуль. Эмбеддинги на выходе из энкодера усреднялись вдоль временной оси и проецировались в размерность целевой переменной. Мы намеренно выбрали максимально простой классификационный модуль, чтобы наиболее наглядно показать качество представлений энкодера.
Некоторые детали обучения:
Никакие слои модели во время обучения не замораживались.
Батчи формировались так, чтобы в среднем в батч попадало одинаковое количество примеров всех классов.
В качестве функции потерь использовалась кросс-энтропия.
Обучение заняло один день на одной видеокарте Nvidia A100.
Всего за несколько эпох модель сошлась к оптимальным метрикам, значения которых представлены в таблице 2.
Crowd |
Podcast |
|||||
|---|---|---|---|---|---|---|
Unweighted Accuracy |
Weighted Accuracy |
Macro F1-score |
Unweighted Accuracy |
Weighted Accuracy |
Macro F1-score |
|
DUSHA baseline (MobileNetV2 + Self-Attention) |
0.83 |
0.76 |
0.77 |
0.89 |
0.53 |
0.54 |
0.84 |
0.77 |
0.78 |
0.90 |
0.50 |
0.55 |
|
GigaAM-Emo |
0.90 |
0.87 |
0.84 |
0.90 |
0.76 |
0.67 |
Заключение
В данной статье мы представили линейку моделей для обработки звучащей речи:
GigaAM предобучена на разнообразной русской речи и может быть быстро адаптирована к разным задачам (распознавание речи / эмоций / диктора) и доменам (колл-центр, подкасты, farfield).
GigaAM-CTC допускает на 20–37% меньше ошибок в словах на коротких русскоязычных запросах по сравнению с такими популярными решения как NeMo-Conformer-RNNT и Whisper-Large-v3.
GigaAM-Emo показывает, что адаптировать GigaAM можно не только под распознавание речи: в ходе дообучения модель начинает быстро «улавливать» паттерны сигнала, ответственные за эмоциональное состояние говорящего.
Надеемся, что Open Source модели и описанные подходы для дообучения ускорят прогресс в области речевых технологий, будут полезны в написании дипломных работ и научных статей.
Над проектом и статьей работали ML-специалисты отдела речевых технологий SberDevices: Александр Максименко, Никита Корягин, Георгий Господинов, Павел Богомолов. Особую благодарность выражаем Олегу Кутузову и Александру Глаголеву за неоценимую помощь в сборе данных.
Если вы хотели бы вместе с нами улучшать распознавание речи от колонок до высоконагруженных колл-центров, строить единую речевую модель под несколько задач, квантовать модели в формат менее байта на параметр и решать нетривиальные NLP задачи в суммаризации и поиске по длинным диалогам, смело пишите Юле!
Если вы хотели бы глубже погрузиться в задачи речевых технологий в целом и self-supervised/semi-supervised подходы в частности, приглашаем на курс от нашей команды!
Также приглашаем вас в Telegram-канал Salute AI, где ML-специалисты SberDevices делятся наработками в NLP, CV, Speech и других сферах!
Комментарии (12)

snakers4
08.04.2024 07:00В том числе датасеты OpenSTT, которые не участвовали в обучении.
Тут ведь используются как-то дополнительно почищенные валидационные датасеты? Можете на них тоже приложить ссылку?

ggospodinov Автор
08.04.2024 07:00Мы использовали минимальную подготовку данных: понижение регистра, замена
ёнае. Применяли такие преобразования, поскольку предлагаемая нами модель и NeMo Conformer транскрибируют речь с таким словарем символов

nkarpov
08.04.2024 07:00круто, а облейшн претрейн моделей какой делали: MLM, Contrastive, MLM+Contrastive ?
ggospodinov Автор
08.04.2024 07:00Спасибо!
Для данной статьи ablation study не проводили. Предобучали энкодер в wav2vec2 режиме, поскольку имеем большой опыт стабилизации обучения с этим подходом
В настоящий момент экспериментируем с Predictive-подходами. Планируем скоро поделиться результатами :)

Lagovi
08.04.2024 07:00Подскажите, у вас в SaluteSpeech App и в Telegram боте одна модель подключена? Как-то мне показалось что качество отличается.
ggospodinov Автор
08.04.2024 07:00На данный момент модели действительно отличаются. Стоит использовать ту, которая лучше решает ваши задачи
Lagovi
08.04.2024 07:00Так при доступе через API вы разве выбор даете?
ggospodinov Автор
08.04.2024 07:00Имел в виду, что пользоваться либо telegram-ботом, либо desktop-приложением / API
Модель из бота сейчас доступна только в боте
Ваш запрос увидели, спасибо!

entze
Что насчет диаризации? Разделение по голосам позволит транскрибировать записи встреч и подкасты.
Lagovi
Она описана в API, в демке под вин почему то не стали реализовывать.
ggospodinov Автор
В настоящий момент в SaluteSpeech API доступна опция разделения дикторов:
SpeakerSeparationOptionsРанее мы писали техническую статью с деталями реализации и примерами возможностей этой технологии: Как мы сделали распознавание речи нескольких говорящих
Запрос на диаризацию увидели, спасибо :)