
В данной статье обсудим создание REST-сервиса в “реактивном” исполнении. Приведу примеры кода на Kotlin в двух вариантах: Reactor и Сoroutines. Добавлю что почти всё, написанное в статье о реактивной реализации сервисов, относится и к SpringBoot.
Micronaut
Micronaut — это JVM-фреймворк для создания микросервисов, это JVM-инфраструктура для создания микросервисов на Java, Kotlin или Groovy. Создатель фреймворка Грэм Роше (Graeme Rocher). Он создал структуру Grails и применил многие свои знания для создания Micronaut. Micronaut предоставляет множество преимуществ в качестве платформы.
Быстрое время запуска
Низкое потребление памяти
Эффективное внедрение зависимостей во время компиляции
Реактивный.
Создание проекта Micronaut
Существует три способа создания проекта Micronaut.
Суть сервиса, описанного в статье
Для того, чтобы оценить все особенности реализации сервисов на Micronaut давайте рассмотрим пример, реализующий сервис REST API с CRUD-функциональностью. Информацию будем хранить во внешней базе данных PostgreSql. Сервис соберем в двух вариантах: 1) привычная JVM-сборка 2) нативная сборка. Напомню, нам любящим Java(Kotlin), теперь доступна возможность нативной сборки.
Я выбрал для демонстрации функциональность "Справочники". На пользовательском уровне это человекочитаемый ключ, к которому привязаны некие значения. Записями такого справочника могут быть, например: "типы документов" : { "Паспорт РФ", "Свидетельство о рождении" и тд }, "Типы валют": { "Рубль", "Доллар", "Евро", и др }. Примеров использования справочников можно примести много. Дополнительна ценность таких реализаций в том, что некие данные, претендующие на "константность", не "хардкодятся" в системе, а находятся за пределами кода со всеми вытекающими из такой реализации удобствами сопровождения систем. Т.е. это некая простая двухуровневая структура, где на верхнем уровне агрегирующая запись а на подчиненном уровне - связанные с записью элементы.
Код полного приложения можно скачать по ссылке в конце статьи. Также добавлю, что всё, что мы обсуждаем в части реализации, можно отнести и к SpringBoot, так как REST-контроллеры SpringBoot и Micronaut практически идентичны.
Пример учебный, не претендующий на идеальную реализацию концепции “чистой архитектуры”, местами реализация может показаться кому-то и спорной.
Также сервис будет уметь самодокументироваться: при запуске сервиса будет доступна информация по его endpoit-ам, т.е. будет визуальное представление его сутевых endpoit-ов в привычном виде swagger (OpenApi).
База данных (PostgreSql)
Записи будут хранится в базе данных PostgreSql. Структура записей - простая только для демонстрации технологий. В реальной системе “справочники” немного сложнее по своей структуре.
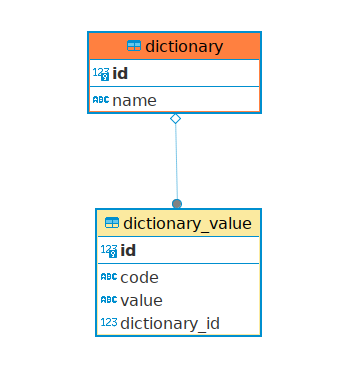
Скрипт создания записей в базе данных:
CREATE TABLE public."dictionary"
(
id int PRIMARY KEY GENERATED BY DEFAULT AS identity,
"name" varchar(255) NOT NULL,
CONSTRAINT unique_name UNIQUE ("name")
);
CREATE TABLE public.dictionary_value
(
id int PRIMARY KEY GENERATED BY DEFAULT AS identity,
code varchar(255) NOT NULL,
value varchar(255) NOT NULL,
dictionary_id int NULL references public."dictionary" (id)
);
Создание проекта Micronaut
Для работы создадим проект Micronaut со следующими feature:
data-r2dbc
r2dbc
postgres
http-client
kapt
kotlin-extension-function
micronaut-aot
micronaut-http-validation
netty-server
openapi
reactor
reactor-http-client
serialization-jackson
swagger-ui
yaml

В реализации будем придерживаться рекомендаций "чистой архитектуры"
Классы моделей
@Serdeable
data class Dictionary(
val id: Long?,
@Size(max = 255) val name: String,
val values: List<DictionaryValue>,
) {
constructor(id: Long? = null, name: String) : this(id, name, emptyList())
}
@Serdeable
data class DictionaryValue(
val id: Long = 0L,
@JsonProperty("parent_id")
val parentId: Long,
@Size(max = 80) val code: String,
@Size(max = 255) val value: String,
)
@Serdeable
data class ShortDictionaryValue(
@JsonProperty("parent_id")
val parentId: Long,
@Size(max = 80) val code: String,
@Size(max = 255) val value: String,
)Я не стал усложнять код и совместил модель и dto-шки.
Аннтонтация @Serdeable нужна, чтобы разрешить сериализацию или десериализацию типа. О об особенностях сериализации Micronaut в том числе и преимуществах реализации по сравнению с Jackson Databind можно почитать здесь: Micronaut Serialization .
Класс "ShortDictionaryValue" нужен для более чистого кода при реализации функциональности добавления записей значения словаря. Нам не нужно какими-то способами при добавлении записи "скрывать" лишнее в контексте данной операции поле "val id: Long". И OpenApi в представлении "swager" будет более корректным. Это распространенный приём, который часто можно встретить в разных реализациях.
Спецификации сервисов
Reactor
interface ReactorStorageService<M, K> {
fun findAll(): Flux<M>
fun findAll(pageable: Pageable): Mono<Page<M>>
fun save(obj: M): Mono<M?>
fun get(id: K): Mono<M?>
fun update(obj: M): Mono<M>
fun delete(id: K): Mono<K?>
}interface ReactorStorageChildrenService<C, K> {
fun findAllByDictionaryId(id: K): Flux<C>
}Coroutine
interface CoStorageService<M, K> {
fun findAll(): Flow<M>
suspend fun findAll(pageable: Pageable): Page<M>
suspend fun save(obj: M): M
suspend fun get(id: K): M?
suspend fun update(obj: M): M
suspend fun delete(id: K): K
}interface CoStorageChildrenService<C, K> {
suspend fun findAllByDictionaryId(id: K): Flow<C>
}Обратите внимание на разницу Reactor vs Coroutine:
fun noResultFunc(): Mono<Void>
suspend fun noResultFunc()fun singleItemResultFunc(): Mono<T>
fun singleItemResultFunc(): T?fun multiItemsResultFunc(): Flux<T>
fun mutliItemsResultFunc(): Flow<T>Реализация сервисов
Вся специфика имплементации - в другом модуле (пакете).
Классы-модели, связанные с конкретной СУБД
@Serdeable
@MappedEntity(value = "dictionary")
data class DictionaryDb(
@GeneratedValue
@field:Id val id: Long? = null,
@Size(max = 255) val name: String,
)
@Serdeable
@MappedEntity(value = "dictionary_value")
data class DictionaryValueDb(
@GeneratedValue
@field:Id val id: Long? = null,
@Size(max = 80) val code: String,
@Size(max = 255) val value: String,
@MappedProperty(value = "dictionary_id")
@JsonProperty(value = "dictionary_id")
val dictionaryId: Long,
)Классы-"репозитории"
Coroutine:
@R2dbcRepository(dialect = Dialect.POSTGRES)
abstract class CoDictionaryRepository : CoroutinePageableCrudRepository<DictionaryDb, Long> {
@Query("SELECT * FROM public.dictionary where id = :id;")
abstract fun findByDictionaryId(id: Long): Flow<DictionaryDb>
}@R2dbcRepository(dialect = Dialect.POSTGRES)
abstract class CoDictionaryValueRepository : CoroutinePageableCrudRepository<DictionaryValueDb, Long> {
@Query("SELECT * FROM public.dictionary_value where dictionary_id = :id;")
abstract fun findAllByDictionaryId(id: Long): Flow<DictionaryValueDb>
}Reactor
@R2dbcRepository(dialect = Dialect.POSTGRES)
abstract class DictionaryRepository : ReactorPageableRepository<DictionaryDb, Long>@R2dbcRepository(dialect = Dialect.POSTGRES)
abstract class DictionaryValueRepository : ReactorPageableRepository<DictionaryValueDb, Long> {
@Query("SELECT * FROM public.dictionary_value where dictionary_id = :id;")
abstract fun findAllByDictionaryId(id: Long): Flux<DictionaryValueDb>
@Query("SELECT * FROM public.dictionary_value where dictionary_id = :dictionaryId and code = :code;")
abstract fun findByCodeAndDictionaryId(
code: String,
dictionaryId: Long,
): Mono<DictionaryValueDb>
}Обратите внимание на похожесть реализации этих классов с подобной реализацией в SpringBoot.
Ну и все наши классы репозитории для работы с БД - реактивные (аннотоция @R2dbcRepository)
Имплементация сервисов
Для сохращения размера статьи буду показывать только принципиальные моменты. Весь код доступен по ссылке в конце статьи.
@Singleton
class DictionaryService(private val repository: DictionaryRepository) : ReactorStorageService<Dictionary, Long> {
override fun findAll(pageable: Pageable): Mono<Page<Dictionary>> =
repository.findAll(pageable).map {
it.map { itDict ->
itDict.toResponse()
}
}
override fun findAll(): Flux<Dictionary> = repository.findAll().map { it.toResponse() }
override fun save(obj: Dictionary): Mono<Dictionary?> = repository.save(obj.toDb()).mapNotNull { it.toResponse() }
override fun get(id: Long): Mono<Dictionary?> = repository.findById(id).map { it.toResponse() }
override fun update(obj: Dictionary): Mono<Dictionary> = repository.update(obj.toDb()).map { it.toResponse() }
override fun delete(id: Long): Mono<Long?> = repository.deleteById(id)
}@Singleton
class CoDictionaryValueService(private val repository: CoDictionaryValueRepository) :
CoStorageService<DictionaryValue, Long>, CoStorageChildrenService<DictionaryValue, Long> {
override fun findAll(): Flow<DictionaryValue> = repository.findAll().map { it.toResponse() }
override suspend fun findAll(pageable: Pageable): Page<DictionaryValue> = repository.findAll(pageable).map {
it.toResponse()
}
override suspend fun delete(id: Long): Long = repository.deleteById(id).toLong()
override suspend fun update(obj: DictionaryValue): DictionaryValue = repository.update(obj.toDb()).toResponse()
override suspend fun get(id: Long): DictionaryValue? = repository.findById(id)?.toResponse()
override suspend fun save(obj: DictionaryValue): DictionaryValue = repository.save(obj.toDb()).toResponse()
override suspend fun findAllByDictionaryId(id: Long): Flow<DictionaryValue> {
return repository.findAllByDictionaryId(id).map { it.toResponse() }
}
}Обратите внимание на аннотацию Singleton. По смыслу она близка аннотации Service в SpringBoot. И таких отличий очень немного. Т.е. я ещё раз акцентирую внимание на общую сильную схожесть Micronaut и SpringBoot. И как следствие на лёгкость перехода, если кому-то тоже понравится Micronaut.
Реализация контроллеров
Не буду веь код копировать а остановлюсь на наиболее на мой взгляд интересных моментах. Обратите внимание на аннотации. Аналогичны SpringBoot. Еще важный момент: все переменные-параметры контроллеров имеют тип интерфейсов, а не конкретных имплементаций. Контроллеры ничего не знают ни про специфику базы данных, ни про репозитории.
@Controller("/api/v1/co-dictionary")
open class CoDictionaryController(
private val service: CoStorageService<Dictionary, Long>,
private val dictionaryValueService: CoStorageChildrenService<DictionaryValue, Long>,
) {
@Get("/list")
fun findAll(): Flow<Dictionary> = service.findAll()
@Get("/list-pageable")
open suspend fun list(@Valid pageable: Pageable): Page<Dictionary> = service.findAll(pageable)
@Get("/list-with-values")
fun getAll(): Flow<Dictionary> {
return service.findAll().mapNotNull(::readDictionary)
}
// todo для статьи
@Get("/stream")
fun stream(): Flow<Int> =
flowOf(1,2,3)
.onEach { delay(700) }
@Post
suspend fun save(@NotBlank name: String): HttpResponse<Dictionary> {
return createDictionary(service.save(Dictionary(name = name)))
}
// ...
}@Controller("/api/v1/dictionary-value")
class DictionaryValueController(private val dictionaryService: ReactorStorageService<DictionaryValue, Long>) {
@Get("/list-pageable")
open fun list(@Valid pageable: Pageable): Mono<Page<DictionaryValue>> = dictionaryService.findAll(pageable)
@Get("/list")
fun findAll(): Flux<DictionaryValue> = dictionaryService.findAll()
@Post
fun save(@NotBlank @Body value: ShortDictionaryValue): Mono<HttpResponse<DictionaryValue>> {
return dictionaryService.save(value.toResponse()).mapNotNull {
createDictionaryValue(it!!)
}
}
@Get("/{id}")
fun get(id: Long): Mono<DictionaryValue?> = dictionaryService.get(id)
// ...
}Часто при реализации получения подобных иерархических данных спорят, нужно ли сразу получать дочерние элементы в общую структуру? Или получать в режиме lazy только при необходимости. У обоих подходах есть плюсы и минусы и нужно принимать решение, исходя их контекста задачи. Например, "фронту" иногда удобнее иметь и основную запись и дочерние записи сразу, чтобы сэкономить усилия и не делать дополнительный запрос в строну бэка. Я добавил такую реализацию для примера. Вот здесь появляется очень сильное и тонкое отличие между Coroutine и Reactor. Нужно применять преобразования реактивных потоков. Я напомню, что реактивно мы получаем и основную запись и реактивно получаем связанные с этой основной записью и её дочерние элементы. Реализация на Coroutine например выглядит так:
@Get("/list-with-values")
fun getAll(): Flow<Dictionary> {
return service.findAll().mapNotNull(::readDictionary)
}
// ...
private suspend fun readDictionary(dictionary: Dictionary): Dictionary {
if (dictionary.id == null) return dictionary
val values = dictionaryValueService.findAllByDictionaryId(dictionary.id).toList()
if (values.isEmpty()) return dictionary
return dictionary.copy(
values = values
)
}Реактивность сохранена, мы возвращаем Flow. Для версии с Coroutine я еще оставил такой "безполезный" код:
// todo для статьи
@Get("/stream")
fun stream(): Flow<Int> =
flowOf(1,2,3)
.onEach { delay(700) }Отдаем данные в реактивном стриме и при этом специально засыпаем :) .
Теперь давайте посмотрим как это всё вместе работает.
Работа сервиса
Сборку будет собирать в двух вариантах:
1) версия на JVM
2) Нативная сборка
Для нативной сборки удобно использовать соответсвующую задачу gradle:
./gradlew dockerBuildNativeПро сборку в docker-образ для Micronaut можно почитать здесь: Building a Docker Image of your Micronaut application
Сборку в нативном исполнении я также выложил в docker-hub который доступен для скачивания как "pawga777/micronaut-dictionary:latest".
Запустить на исполнение собранное приложение можно через docker compose используя следующий конфигурационный файл (docker-compose.yml):
version: '3.5'
services:
app:
network_mode: "host"
environment:
DB_HOST: localhost
DB_USERNAME: postgres
DB_PASSWORD: ZSE4zse4
DB_NAME: r2-dict-isn
DB_PORT: 5432
image: pawga777/micronaut-dictionary:latest
Запуск:


Обратите внимание на разницу времени старта: 1548ms vs 144ms. Впечатляет? При этом аналогичная версия на SpringBoot стартует около 3000ms (Micronaut принципиально быстрее чем SpringBoot). В JVM-версии Micronaut еще можно использовать технологию CRaC, что улучшит характеристика старта, если по каким-то причинам нативная сборка не подойдет. Пример с CRaC от Micronaut: Micronaut CRaC .
")

Для простого тестирования даже Postman не требуется так как есть работающий "swagger".
Тесты
Тема тестов также обширная. В примере используется Kotest. Micronaut умеет тестировать работу с базой данных через технологию "тестовых" контейнеров(Testcontainers). При этом в Micronaut добавлено дополнительно небольшое упрощение Testcontainers как "Test Resources". Ключевое в фразе выше "добавили", т..е оба подхода существуют. Хороший пример Micronaut, где они эти технологии описывает (СУБД H2 и PostgreSQL): REPLACE H2 WITH A REAL DATABASE FOR TESTING. Но мне показалось подозрительным, что у них нет примера на Kotlin. Оказалось есть причина, т е. у Micronaut есть именно с реализацией на Kotlin. Для демонстрационного примера я показал подход тестирования контроллеров на одном примере. Обходим тестирование репозиториев моками:
@MockBean(CoDictionaryRepository::class)
fun mockedPostRepository() = mockk<CoDictionaryRepository>()Код тестирования одной "ручки" выглядит так:
given("CoDictionaryController") {
`when`("test find all") {
val repository = getMock(coDictionaryRepository)
coEvery { repository.findAll() }
.returns(
flowOf(
DictionaryDb(
id = 1,
name = "test1",
),
DictionaryDb(
id = 2,
name = "test2",
),
)
)
val response = client.toBlocking().exchange("/list", Array<Dictionary>::class.java)
then("should return OK") {
response.status shouldBe HttpStatus.OK
val list = response.body()!!
list.size shouldBe 2
list[0].name shouldBe "test1"
list[1].name shouldBe "test2"
}
}Мы подменяем только запрос получения из базы данных непосредственно записей, оставляя без моков остальной код (сервисы, контроллеры).
Kotest, кстати, может дать разработчику некую свободу. В примере подход BehaviorSpec, который подходит для любителей стиля BDD. BehaviorSpec позволяет использовать context, given, when, then. Но есть еще и другие спецификации: FunSpec, AnnotationSpec, ShouldSpec, FeatureSpec и так далее. Их немного, можно подобрать для себя более привычный подход. AnnotationSpec, например, применяется при переходе с JUnit, позволяя перенести существующие тесты (каждый тест в виде отдельной функции с аннотацией Test:
class AnnotationSpecExample : AnnotationSpec() {
@BeforeEach
fun beforeTest() {
println("Before each test")
}
@Test
fun test1() {
1 shouldBe 1
}
@Test
fun test2() {
3 shouldBe 3
}
}FunSpec позволяет создавать тесты, вызывая функцию, вызываемую test со строковым аргументом для описания теста, а затем сам тест в виде лямбды. Если у вас есть сомнения, используйте этот стиль:
class MyTests : FunSpec({
test("String length should return the length of the string") {
"sammy".length shouldBe 5
"".length shouldBe 0
}
})Подробности о тестировании в Micronaut здесь: Micronaut Test
Эпилог
Код примера, описанного в статье: micronaut-dictionary
Напомню, что я докер-образ решения выложил в docker-hub.
Всем прочитавшим до конца мою статью — спасибо.
Happy Coding!
TerraV
Не впечатляет от слова совсем. Если вам нужен непрерывно работающий сервис, недоступность даже 144ms так же плоха как и 3s. Вам нужны несколько подов бегущих параллельно и наверное масштабирующиеся от нагрузки. В этом плане экономия на старте пода это экономия на спичках. Если вам не нужен непрерывно работающий сервис, 3 секунды на старт ничем не хуже 144 мс.
JajaComp
В процессе разработки быстрое время запуска идёт на пользу
TerraV
Так это же не бесплатно (за исключением случаев когда вы начинаете новый проект и вас окружают специалисты по Micronaut). Обычно Micronaut сравнивают со SpringBoot, и вот если рассматривать цену миграции ради 2 секунд экономии времени старта то это очень спорное решение. Опять же в плане рынка мало и проектов на Micronaut и специалистов.
Pawga777 Автор
Наверное, я допустил некорректную фразу в статье. Допустим есть два сервиса: один работает в нативно-откомплированном виде, практически без усилий со стороны разработки по причине выбора фрэймворка, второй сервис в виде байткода. Во втором сервисе всё работает (а не только старт) в десятки раз медленнее по своей природе. Не хочу чтобы дискуссию ушла ещё в сторону JIT или AOT, я очень неплохо разбираюсь и в этом. Далее, первый сервис можно точно также настроить в среде "бегущих" подов. Уход в другой контекст мне тоже непонятен. Если в том контексте атомарные сервисы будут быстрее работать, разве это плохо? Да, в среде K8S разница в скорости может быть и не так заметна, не в десятки раз, но эта разность будет уже по другим причинам. Мы сравниваем скорость работы атомарного процесса. Зачем тогда GraalVM или подобная технология? Можно подумать что "бегущих" подов это безполезные технологии? Заканчивую свой ответ. Я просто показал имеющуяся альтернативу. Использовать или не использовать быстрее в 10 раз работающий сервис или модуль - выбор архитектора. Выбор: попробовать Micronaut или остаться на SpringBoot? А может вообще уйти со SpringBoot в Quarkus. Я бы предложил попробовать откомпилировать в нативный вид сервис SpringBoot с JPA? В Golang компиляция в нативный вид присутсвует из коробки, например. И Golang при выборе технологии "побеждает" в том числе и из-за этого преимущества. Кстати, в Android-экосистеме подобный подход в видоизмененном виде уже давно используется. В упрощенном виде этот подход выглядит так: после установки на конкретное(!) устройство при первом запуске программа переводит себя в нативно-откомпилированный вид полностью, и далее работает уже нативно. Там уже давно не стоит вопрос о преимуществах нативно-откомпилированной программы. Если новые возможности не впечатлили, то можно остаться и на проверенных технологиях. Я знаю разработчиков, которые со мной захотели бы поспорить о ложных преимуществах Kotlin перед Java. Это была бы дискуссия на подобную тему. Кстати, в той же Android-экосистеме уже давно только Kotlin, и эффективность языка проверена на миллионах устройств и программ, как и нативная работа этих программ. Нашему enterprise-бэкэнду до такой статистики очень далеко. Но и Java для Android-разработки тоже осталась, если любишь Java продолжай на нём программировать. Так и здесь. Можно остаться на SpringBoot без возможности нативной компиляции. Нативная компиляция только формально есть, вспомни про JPA и "всё на рефлексии" . А можно попробовать почти идентичную технологию, которая позволяет делать сборку в нативный вид без "танцев с бубнами". Кто решения по выбору технологий принимает, многие знают и без меня :). Своим ответом никого обидеть не хочу. И на "религиозные" темы спорить тоже не хочу.
TerraV
Ну вы откровенно подменяете понятия. Приложение на Micronaut не работает быстрее в 10 раз. Оно только быстрее стартует. Происходит это только по причине компайл-тайм инъекций зависимостей. Все, точка. Неоткуда больше взяться приросту скорости.
Pawga777 Автор
Вы серьезно считаете, что программа работающая в связке "jvm + байт-код" работает с той же скоростью, что и тот же вариант программы, скомпилированный в нативный вид?
TerraV
Двадцать лет назад разрыв был в 10 раз. Сейчас я знаю примеры когда JIT дает более высокое быстродействие чем нативный код. Ни в коем случае не говорю что это правило, но тот разрыв что был 20 лет назад сейчас пренебрежимо мал. Другое дело что да, JIT требует "прогрева", тут не спорю.
Pawga777 Автор
@TerraV, спасибо. Полностью согласен, и про JIT-прогрев в частности. Добавлю, или акцентирую, что статья не про нативную сборку и не призыв, переходить на неё. И не призыв уходит с проверенного SpringBoot. Просто информация об ещё одном фрэймворке. Одна фраза в статье типа "эмоциональное" восхищение чем-то вызвало такую реацию? Автор же имеет право высказать свое отношение к чему-то? И если есть в новом фрэймворке, почему про это на написать. Я, когда читаю статьи, полезную информацию для себя просто помечаю, чтобы в свободное время поглубже разобраться. Только и всего. да, про скорость и вопрос про 10 раз. Естественно, после "прогрева" и работы JIT и оптимизаций, разница в скорости может сойти на нет. Я думал, это все понимают. Набросились на меня из GraalVM :)
mello1984
Вы действительно считаете, что нейтив-код в 10 раз быстрее в реальном приложении, а не в синтетических тестах?
Будет ли в 10 раз быстрее работать ваше приложение?
Запросы в БД
Запросы в иные сервисы
Pawga777 Автор
Ответил выше . Не считаю :). На скорость многое влияет. Сборка в обычном исполнении в режиме JIT-оптимизации (но осторожно напишу, что не сразу) может быть сравнима с нативно откомпилированной программой.
Sipaha
Здравствуй, путешественник из прошлого. У нас тут 2024 год и java уже давно оптимизирована настолько, что говорить о большой разнице между нативным кодом и jvm не приходится.
За последние ~10-15 лет очень многое изменилось. Советую разобраться заново.
Pawga777 Автор
@Sipaha, спасибо за комментарий. Вот уж JIT и AOT начали бурно обсуждать. Статью я хотел написать не про JIT и AOT :). Одна "неосторожная" фраза в статье увела дискуссию в эту сторону. Технологии JVM не стоят на месте и скорости работы могут быть соезмиримы. Просто есть у нас еще один фрэйморк. Статья про это. Ешё про реактивные возможности Kotlin. Я ещё для себя открыл не так давно Kotest, отличный фрэймворк. Моё субьективное мнение :) Есть еще отдельная тема о наличии JVM типа GraalVM в дополнение к "обычным". Ведь если целые компании тратят время на создание чего-то подобного, то значит в этом есть какой-то смысл. Я думаю, мы должны иметь информацию о подобных возможностях. А использовать или нет - это уже другой вопрос. Ещё раз спасибо.
mayorovp
Делать приложение, которое умеет работать параллельно со своей же более старой версией - трудно. И есть куча проектов, для которых простой нежелателен, но скорость разработки важнее.
Кроме того, не забывайте: не все используют кубы, кто-то и на docker compose сидит. А последний в rolling deploy не умеет в принципе!
TerraV
У нас с вами нет противоречий. Есть задача - под нее можно подбирать инструмент который соответствует желаемым метрикам. Я обычно руководствуюсь двумя метриками - "Time to market" и "Cost of ownership". Так вот в плане скорости разработки в подавляющем большинстве случаев выгоднее выбирать инструмент которым уже владеешь профессионально. А в плане стоимости владения лучше избегать экзотики, т.к. рынок кандидатов довольно тощий.
mayorovp
Я уверен что разработчику куда проще перейти с SpringBoot на Micronaut, чем с docker compose на кубы.
VanKrock
Трудно наверное разве что джуну, для всех остальных поддержка обратной совместимости, хоть на сколько-то версий, вполне обычная практика. Я даже представить не могу, что можно писать не волнуясь об обратной совместимости