

Привет, Хабр! Меня зовут Юрий Петров, я автор ютуб-канала «Мобильный разработчик» и Flutter Tech Lead в компании Friflex. Мы разрабатываем мобильные приложения для бизнеса и специализируемся на Flutter.
В версии Flutter 3.19 появился SDK для работы с генеративным ИИ. В этой статье разбираемся с возможностями google_generative_ai на примере простого Flutter-проекта.
Получаем API-ключ
Чтобы начать работу с SDK, нужно получить API-ключ. Для этого переходим на сайт:
.")



Генерируем текст из текстового ввода
Чтобы протестировать библиотеку, создадим простой проект на Flutter.
Добавим в pubspec.yaml зависимость:
dependencies:
flutter:
sdk: flutter
cupertino_icons: ^1.0.6
google_generative_ai: ^0.2.2Далее переходим в main.dart и создаем простую модель по умолчанию по инструкции из библиотеки:
final model = GenerativeModel(model: 'gemini-pro', apiKey: api);Создаем модель при помощи нейросети gemini-pro. Она генерирует текст на основе введенных запросов. Также с её помощью можно создавать изображения, чаты и использовать потоковую передачу данных для более быстрого взаимодействия.
В этой статье мы сгенерируем текст из промт-запроса. Про запросы посложнее, которые позволяют генерировать картинки или чаты, я напишу в следующей статье.
Примечание. В моделях Gemini один токен равен четырем символам. Сто токенов составляют около 60-80 английских слов. Ограничение скорости для моделей Gemini Pro — 60 запросов в минуту. При желании скорость можно увеличить.
В нижеприведённой талице, можно посмотреть основные характеристики моделей которые вы можете использовать:
Доступные модели
Вариация |
Атрибут |
Описание |
Gemini 1.5 Pro (Только превью) |
Последнее обновление модели |
Апрель 2024 |
Код модели |
models/gemini-1.5-pro-latest |
|
Что умеет делать |
Генерировать код, текст. Редактировать текст, извлекать информацию, извлекать и генерировать данные AI. |
|
Метод генерации |
generateContent |
|
Лимит токенов на ввод |
1048576 |
|
Лимит токенов на вывод |
8192 |
|
Безопасность модели |
Автоматические настройки безопасности, которые можно изменять под конкретные задачи. |
|
Лимит запросов |
Два запроса в минуту, 1000 запросов в день |
|
Gemini Pro |
Последнее обновление модели |
Февраль 2024 |
Код модели |
models/gemini-pro |
|
Что умеет делать |
Генерировать текст и изображения. Обрабатывать задачи без примеров, с одним и несколькими примерами. Обрабатывать многоходовый диалоговый формат (чаты). |
|
Метод генерации |
generateContent |
|
Лимит токенов на ввод |
30720 |
|
Лимит токенов на вывод |
2048 |
|
Безопасность модели |
Автоматические настройки безопасности, которые можно адаптировать под разные задачи. |
|
Лимит запросов |
60 запросов в минуту |
|
Названия моделей |
Последняя версия: gemini-1.0-pro-latest Стабильная версия: gemini-1.0-pro Стабильные версии: gemini-1.0-pro-001 |
|
Gemini 1.0 Pro Vision |
Последнее обновление модели |
Декабрь 2023 |
Код модели |
models/gemini-pro-vision |
|
Что умеет делать |
Генерировать текст и изображения. Обрабатывать задачи без примеров, с одним и несколькими примерами. |
|
Метод генерации |
generateContent |
|
Лимит токенов на ввод |
12288 |
|
Лимит токенов на вывод |
4096 |
|
Безопасность модели |
Автоматические настройки безопасности, которые можно адаптировать под разные задачи. |
|
Лимит запросов |
60 запросов в минуту [1] |
|
Embedding |
Последнее обновление модели |
Декабрь 2023 |
Код модели |
models/embedding-001 |
|
Что умеет делать |
Генерировать текстовые эмбеддинги для входного текста до 2048 токенов. |
|
Метод генерации |
embedContent |
|
Безопасность модели |
Нет настраиваемых настроек безопасности. |
|
Лимит запросов |
1500 запросов в минуту [1] |
|
Text Embedding |
Последнее обновление модели |
Апрель 2024 |
Код модели |
models/text-embedding-004 (text-embedding-preview-0409 в Vertex AI) |
|
Что умеет делать |
Генерировать текстовые эмбеддинги для входного текста до 768 токенов. |
|
Метод генерации |
embedContent |
|
Безопасность модели |
Нет настраиваемых настроек безопасности. |
|
Лимит запросов |
1500 запросов в минуту [1] |
|
AQA |
Последнее обновление модели |
Декабрь 2023 |
Код модели |
models/aqa |
|
Что умеет делать |
Отвечать на вопросы на основании представленных источниках. |
|
Метод генерации |
generateAnswer |
|
Поддерживает языки |
Английский |
|
Лимит токенов на ввод |
7168 |
|
Лимит токенов на вывод |
1024 |
|
Безопасность модели |
Автоматические настройки безопасности, которые можно адаптировать под разные задачи. |
|
Лимит запросов |
60 запросов в минуту |
Каждая модель решает разные задачи. Одна лучше генерируют текст, другая отлично работает с изображениями. Я рекомендую отдельно изучить функции каждой модели для решения ваших задач.
Для нашего проекта мы выбираем gemini-pro. Последние обновления для нее появились в феврале 2024 года.
Для проверки работы модели напишем очень простой код:
Исходный код проекта
import 'package:flutter/material.dart';
import 'package:flutter_ai/env.dart';
import 'package:google_generative_ai/google_generative_ai.dart';
final model = GenerativeModel(model: 'gemini-pro', apiKey: api);
void main() {
runApp(MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text('Flutter AI'),
),
body: Padding(
padding: const EdgeInsets.all(8.0),
child: _GeminiChat(),
))));
}
class _GeminiChat extends StatelessWidget {
final ValueNotifier<String> _genText = ValueNotifier("");
final TextEditingController _textEditController = TextEditingController();
@override
Widget build(BuildContext context) {
return Column(
children: [
TextField(controller: _textEditController),
ElevatedButton(
onPressed: _fetchData,
child: const Text('Генерация'),
),
ValueListenableBuilder<String>(
valueListenable: _genText,
builder: (_, value, __) {
return SizedBox(
height: 300,
child: SingleChildScrollView(child: Text(value)));
},
)
],
);
}
Future<void> _fetchData() async {
final content = [Content.text(_textEditController.text)];
_genText.value = "Генерация...";
await model.generateContent(content).then((value) {
_genText.value = value.text ?? "Error";
});
}
}
Внимательно рассмотрим метод:
Future<void> _fetchData() async {
final content = [Content.text(_textEditController.text)];
_genText.value = "Генерация...";
await model.generateContent(content).then((value) {
_genText.value = value.text ?? "Error";
});
}Здесь мы создаем контент, который передадим модели. Контент получаем из контроллера, который связан с полем ввода текста.
Далее запускаем метод generateContent, который вернет нам результат:
await model.generateContent(content).then((value) {
_genText.value = value.text ?? "Error";
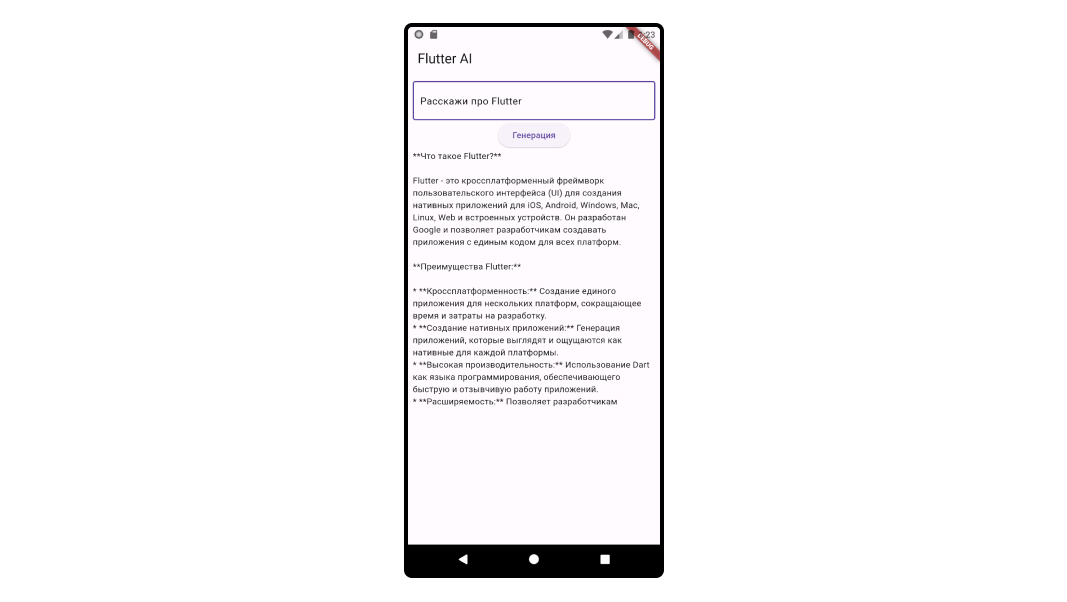
});Если сейчас вы запустите приложение, то получите такой результат:
GenerationConfig: настраиваем конфигурацию модели
Для объекта модели мы используем значения по умолчанию.
final model = GenerativeModel(model: 'gemini-pro', apiKey: api);Но у класса GenerativeModel очень гибкие настройки.
Класс GenerationConfig — это конечные настройки конфигурации для генерации модели и вывода данных. Они важны для ответа, который сгенерирует модель.
Конструктор:
GenerationConfig({
this.candidateCount,
this.stopSequences = const [],
this.maxOutputTokens,
this.temperature,
this.topP,
this.topK,
});Рассмотрим отдельно свойства:
candidateCount: количество сгенерированных ответов, которые должны быть возвращены. Значение варьируется в диапазоне от одного до восьми включительно. Если не установлено, по умолчанию оно будет равно одному.stopSequences: набор последовательностей символов (до пяти), который останавливает генерацию вывода. ЕслиstopSequencesуказан, API остановится при его появлении. Самостоятельно он не появится в ответе.maxOutputTokens: максимальное количество токенов, которое нужно включить в кандидата. ЕслиmaxOutputTokensне установлен, по умолчанию будет использоватьсяoutput_token_limit.temperature: контролирует случайность вывода. Значение может варьироваться от 0.0 до бесконечности. Показатель всегда должен быть больше 0.0.topP: максимальная совокупная вероятность токенов, которые следует учитывать при выборке. Модель использует комбинированную выборку Top-k и ядерную выборку. Токены сортируются по их вероятностям, потому что учитываются только самые вероятные токены. Выборка Top-k напрямую ограничивает максимальное количество токенов, которые рассматривает. Ядерная выборка ограничивает количество токенов на основе их совокупной вероятности. По умолчанию она равна 0.95topK: максимальное количество токенов, которые следует учитывать при выборке. Модель использует комбинированную выборку Top-k и ядерную выборку. Выборка Top-k рассматривает набор самых вероятных токенов top_k. По умолчанию она равна 40.
Чтобы хорошо сконфигурировать модель, важно понимать, как она работает и что значит каждый ее параметр. Давайте разберем их отдельно:
candidateCount: определяет, сколько различных вариантов ответа вы хотите получить от модели за один запрос. Чем больше кандидатов, тем разнообразнее ответы. При этом увеличиваются вычислительные затраты и время ответа.stopSequences: последовательности символов, которые прекращает генерацию текста. Стоп-сигналы ограничивают длину текста и не дают модели создавать ненужный контент.maxOutputTokens: устанавливает верхний предел количества токенов в каждом кандидате ответа. Ограничивает длину текста и управляет вычислительными ресурсами.temperature: влияет на предсказуемость ответов. Чем ниже показатель, тем консервативнее результат мы получаем. Важно найти баланс, чтобы ответы были релевантными.topP: используется, чтобы регулировать разнообразие ответов за счет ограничения набора токенов. Чем больше значениеtopP, тем разнообразнее набор токенов.topK: ограничивает количество самых вероятных токенов, которые рассматриваются при выборке. Этот параметр контролирует разнообразие и предсказуемость текста.
Попробуем применить все эти знания и немного поправим модель. Ограничим ответ 600 токенами.
final _generationConfig = GenerationConfig(
maxOutputTokens: 600,
temperature: 1,
topP: 0.95,
topK: 40,
);
final model = GenerativeModel(
generationConfig: _generationConfig,
model: 'gemini-pro',
apiKey: api,
);Генерация прошла успешно, но ответ получился короче:
Результат
Увеличиваем температуру до 2.0:
final _generationConfig = GenerationConfig(
maxOutputTokens: 600,
temperature: 2.0,
topP: 0.95,
topK: 40,
);Результат

Ответ уже не совсем корректный. А именно, предложение «Flutter — это открытая и бесплатная структура…»
Устанавливаем стоп-слово:
final _generationConfig = GenerationConfig(
maxOutputTokens: 600,
temperature: 2.0,
topP: 0.95,
topK: 40,
stopSequences: ['Flutter'],
);И получаем картину, где ответа нет:
Результат

Вот так, меняя параметры, вы можете получить совершенно разные результаты.
Настройки безопасности
SDK позволяет гибко фильтровать контент, который может оказаться опасным или нежелательным. За это отвечает параметр safetySettings. Он же — класс SafetySetting.
Класс SafetySetting принимает два параметра.
Настройка категории:
final HarmCategory category;Порог вероятности, при котором блокируется вред:
final HarmBlockThreshold thresholdHarmCategory — категории оценок разных видов вреда. Мы можем использовать их, чтобы настраивать и фильтровать контент, который генерируют системы или приложения.
unspecified(Неуказанный). Это значение используется по умолчанию или когда категория вреда не определена.harassment(Домогательство). Включает в себя негативные комментарии в адрес другого пользователя.hateSpeech(Разжигание ненависти). Включает негативные или вредоносные комментарии об идентичности другого пользователя. К идентичности относятся раса, этническая принадлежность, религия, половая ориентация, гендер и другие понятия.sexuallyExplicit(18+). Содержит ссылки на непристойный контент. Категория включает материалы, которые подходят не для всех аудиторий или ситуаций.dangerousContent(Опасный контент). Пропагандирует или позволяет получить доступ к вредным товарам, услугам или деятельности.
Вторая важная настройка — HarmBlockThreshold. Она определяет пороговые значения вероятности вреда. При достижении или превышении этих значений контент будет заблокирован. Они используются в настройках безопасности. Например, в SafetySetting.threshold пороговые значения помогают определить, когда контент считается небезопасным. Вот какие значения относятся к пороговым:
unspecified(Неуказанный). Если порог не указан, система будет автоматически применять стандартные настройки, чтобы определить, какой контент считать небезопасным. И при необходимости блокировать его.low(Низкий). Блокирует контент, если есть высокая или средняя вероятность, что он опасный. Система будет блокировать контент даже при относительно низком уровне риска. Это может быть полезным в консервативных или чувствительных контекстах.medium(Средний). Блокирует контент, если вероятность, что он опасный, средняя или высокая. Этот уровень может использоваться как стандартный уровень безопасности. Он обеспечивает умеренный баланс между свободой выражения и цензурой.high(Высокий). Блокирует контент только при высокой вероятности небезопасного содержания.none(Отсутствует). Всегда все виды контента. Этот уровень подходит для ситуаций, когда свобода выражения важнее рисков. Или когда пользователь осознанно решает видеть весь контент без фильтров.
Выбор порога блокировки зависит от контекста и необходимого баланса между безопасностью и свободой выражения. Важно подходить к нему внимательно, особенно в среде, где могут присутствовать уязвимые группы пользователей. Или когда контент может иметь серьезные последствия.
Попробуем применить:
final model = GenerativeModel(
generationConfig: _generationConfig,
model: 'gemini-pro',
apiKey: api,
safetySettings: [
SafetySetting(HarmCategory.hateSpeech, HarmBlockThreshold.low),
],
);Вот так мы указываем, что надо блокировать вредоносные комментарии с высоким порогом реакции.
Настройка httpClient
Это третий параметр. Вы можете настроить httpClient со своими метаданными заранее. Или SDK сама создаст httpClient.
final model = GenerativeModel(
generationConfig: _generationConfig,
httpClient: http.Client(),
model: 'gemini-pro',
apiKey: api,
safetySettings: [
SafetySetting(HarmCategory.hateSpeech, HarmBlockThreshold.low),
],
);На этом все! Мы научились создавать своего клиента для Gemini без бэкенда. С помощью SDK вы можете создать собственного помощника с гибкими настройками под разные задачи.
Если у вас что-то не получилось, можно клонировать проект из гитхаба. Надеюсь, статья будет вам полезна. С удовольствием отвечу на вопросы в комментариях.
1nvader
Спасибо за хорошие статьи!