
Это продолжение
Добавляем поддержку PostgreSQL
Сначала адаптирую запрос для работы в PostgreSQL.
Попытка выполнения запросов из предыдущих частей в PostgreSQL 15.6 вызывает ошибку:
ERROR: в рекурсивном запросе «levels» столбец 4 имеет тип
character(2000)в нерекурсивной части, но в результате типbpchar
LINE 23:cast(parent_node_id as char(2000)) as parents,
^
HINT: Приведите результат нерекурсивной части к правильному типу.
Это несколько неожиданно (по крайней мере, для меня) - "bpchar" это "blank-padded char", по идее то же самое, что и char(с указанием длины). Не буду спорить, просто заменю повсеместно char() на varchar:
Все тот же длинный запрос из части 2
with recursive
Mapping as (
select
id as node_id,
parent_directory_id as parent_node_id,
name as node_name
from Files
),
RootNodes as (
select node_id as root_node_id
from Mapping
where -- Exactly one line below should be uncommented
-- parent_node_id is null -- Uncomment to build from root(s)
node_id in (3, 10, 17) -- Uncomment to add node_id(s) into the brackets
),
Levels as (
select
node_id,
parent_node_id,
node_name,
cast(parent_node_id as varchar) as parents,
cast(node_name as varchar) as full_path,
0 as node_level
from
Mapping
inner join RootNodes on node_id = root_node_id
union
select
Mapping.node_id,
Mapping.parent_node_id,
Mapping.node_name,
concat(coalesce(concat(prev.parents, '-'), ''), cast(Mapping.parent_node_id as varchar)),
concat_ws(' ', prev.full_path, Mapping.node_name),
prev.node_level + 1
from
Levels as prev
inner join Mapping on Mapping.parent_node_id = prev.node_id
),
Branches as (
select
node_id,
parent_node_id,
node_name,
parents,
full_path,
node_level,
case
when root_node_id is null then
case
when node_id = last_value(node_id) over WindowByParents then '└── '
else '├── '
end
else ''
end as node_branch,
case
when root_node_id is null then
case
when node_id = last_value(node_id) over WindowByParents then ' '
else '│ '
end
else ''
end as branch_through
from
Levels
left join RootNodes on node_id = root_node_id
window WindowByParents as (
partition by parents
order by node_name
rows between current row and unbounded following
)
order by full_path
),
Tree as (
select
node_id,
parent_node_id,
node_name,
parents,
full_path,
node_level,
node_branch,
cast(branch_through as varchar) as all_through
from
Branches
inner join RootNodes on node_id = root_node_id
union
select
Branches.node_id,
Branches.parent_node_id,
Branches.node_name,
Branches.parents,
Branches.full_path,
Branches.node_level,
Branches.node_branch,
concat(prev.all_through, Branches.branch_through)
from
Tree as prev
inner join Branches on Branches.parent_node_id = prev.node_id
),
FineTree as (
select
tr.node_id,
tr.parent_node_id,
tr.node_name,
tr.parents,
tr.full_path,
tr.node_level,
concat(coalesce(parent.all_through, ''), tr.node_branch, tr.node_name) as fine_tree
from
Tree as tr
left join Tree as parent on
parent.node_id = tr.parent_node_id
order by tr.full_path
)
select fine_tree, node_id from FineTree
;Этого оказалось достаточно, чтобы запрос заработал в соответствии с ожиданиями:
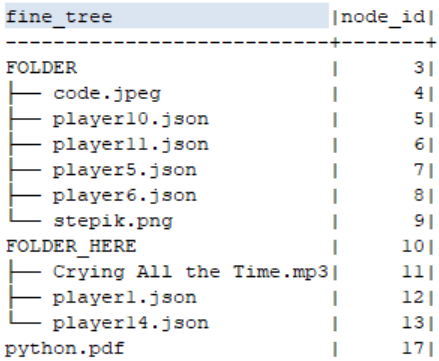
Возможно, использование varchar без указания длины несет в себе ограничения, с которыми не удается столкнуться на столь компактной иерархии - как обычно, "подозреваю" поле full_path
Чтобы проверить ограничения, нужна относительно большая иерархия, остается ее раздобыть.
Новый вариант запроса корректно работает в SQLite (в нем все текстовые типы, похоже, эквивалентны), но не в MySQL, в нем возникает ошибка вызова функции преобразования CAST():
Error occurred during SQL query execution
Причина:
SQL Error [1064] [42000]: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'varchar)) as parents,cast(node_name as char(2000)) as full_path,
0 as nod' at line 23
Большая иерархия (80 000+ элементов)
Не буду рассуждать на тему "зачем нужно визуализировать столь объемную иерархию".
Это делается для проверки работы скрипта, и выявления его возможных ограничений.
Удобный способ получения объемных иерархий - использовать структуру zip-архива. В качестве подопытного можно взять большой проект с Git'а - например, OpenJDK (83499 папок и файлов для использованной мною версии 22).

Чтобы скачать архив, нужно из раскрывающегося меню выбрать Download ZIP (объем архива 181 МБ)
gen_table()
Для генерации SQL-скрипта создания таблицы и вставки в нее строк со структурой архива я написал функцию gen_table() на Python
#
# Generate SQL-script for creation of hierarchical table by zip-archive structure
#
from zipfile import ZipFile
from itertools import count
def file_size_b(file_size):
""" Returns file size string in XBytes """
for b in ["B", "KB", "MB", "GB", "TB"]:
if file_size < 1024:
break
file_size /= 1024
return f"{round(file_size)} {b}"
def gen_table(zip_file, table_name='ZipArchive', chunk_size=10000, out_extension='sql'):
"""
by iqu 2024-04-28
params:
zip_file - zip archive full path
table_name - table to be created
chunk_size - limit values() for each insert into part
out extension - replaces zip archive file extension
-> None, creates file with SQL script.
Create table columns:
id, name, parent_id, file_size - obvious,
bytes - string with file size generated by file_size_b()
"""
def gen_create_table(file):
print(f"drop table if exists {table_name};", file=file)
print(f"create table {table_name} (id int, name varchar(255), parent_id int, file_size int, bytes varchar(16))"
, file=file)
def gen_insert(file):
print(f";\ninsert into {table_name} (id, name, parent_id, file_size, bytes) values", file=file)
out_file = ".".join(zip_file.split(".")[:-1] + [out_extension])
cnt = count()
parents = ['NULL']
with open(out_file, mode='w') as of:
gen_create_table(of)
with ZipFile(zip_file) as zf:
for zi in zf.infolist():
zi_id = cnt.__next__()
if zi_id % chunk_size == 0:
gen_insert(of)
delimiter = ''
else:
delimiter = ','
level = zi.filename.count("/") - zi.is_dir()
name = zi.filename.split("/")[level]
file_size = -1 if zi.is_dir() else zi.file_size
file_size_s = 'DIR' if zi.is_dir() else file_size_b(zi.file_size)
if zi.is_dir():
if len(parents) < level + 2:
parents.append(f"{zi_id}")
else:
parents[level + 1] = f"{zi_id}"
print(f"{delimiter}({zi_id}, '{name}', {parents[level]}, {file_size}, '{file_size_s}')", file=of)
print(';', file=of)
gen_table(r"C:\TEMP\jdk-master.zip") # Sample archive https://github.com/openjdk/jdk/archive/refs/heads/master.zip
Объяснять код в деталях не буду, это совсем не по теме статьи. Существенно, что скрипт разбивается на части длиной максимум chunk_size (10 000 по-умолчанию) в каждом блоке values()
Кроме ИД, имени и ссылки на родителя, каждая запись содержит поле file_size с длиной в байтах (-1 для папок) и поле bytes с длиной, преобразованной к строке в байтах, килобайтах и т.д. ('DIR' для папок)
Передав функции параметром путь к скачанному выше архиву, я получил SQL-скрипт создания иерархии. Прикладывать его не буду, его архив "весит" почти 1МБ, способ его получения детально описан
Скрипт добавления записей состоит из 9 частей. Он успешно выполнился во всех трех "подопытных" СУБД. Индексы не создавались.
Проверка в MySQL, SQLite и PostgreSQL
Для проверки MySQL и SQLite буду использовать скрипт из второй части статьи, для PostgreSQL - приложенный в начале этой статьи.
Приведу время выполнения скриптов на своем домашнем ПК под Windows 10. Все СУБД установлены в разделе C:\, находящемся на SSD, файлы баз данных расположены на нем же. Все настройки при установке СУБД по-умолчанию.
Все скрипты выполняются из DBeaver 24.0.2, время округлено - задача не сравнить СУБД между собою, а проверить работоспособность скриптов в их средах.
Для разнообразия при визуализации иерархии к имени узла будет добавляться строковый размер файла в скобках, а из финального CTE будет извлекаться так же уровень узла в иерархии:
with recursive
Mapping as (
select
id as node_id,
parent_id as parent_node_id,
concat(name, ' (', bytes, ')') as node_name
from ZipArchive
),
...
select fine_tree, node_id, node_level from FineTree
;Так же будет выполнен скрипт для проверки иерархий (показана только нижняя строка), вычисляющий сумму длин поля full_path всех узлов, и максимальную длину этого поля:
...
select sum(length(full_path)), max(length(full_path)) from FineTree
;Скрипт |
MySQL 8.2 |
SQLite 3 |
PostgreSQL 15.6 |
|
1800 ms |
200 ms |
500 ms |
Визуализация иерархии |
2 s |
1 s |
3 s |
|
Проверка иерархии sum(length(full_path)) max(length(full_path)) |
2 s
|
1 s
|
3 s
|
При создании и наполнении таблицы я ориентировался на статистику, отображаемую после выполнения скрипта

Пример для SQLite
Наибольшая вложенность иерархии - 16
Порядок отображения иерархии несколько отличается между СУБД - для SQLite он регистрозависимый, а регистронезависимые MySQL и PostgreSQL по-разному сортируют некоторые строки:


Для целей визуализации иерархии эти различия не принципиальны. В рамках одной СУБД вывод стабилен
Выводы
Результаты проверки иерархии во всех СУБД совпали, даже с учетом разных типов данных в MySQL и PostgreSQL. Максимальная длина поля full_path превышает 255, таким образом, можно смело "снять подозрения" с варианта запроса для PostgreSQL с использованием varchar без указания длины, обрезки строки не происходит, можно использовать запрос в этом варианте так же для SQLite.
В целом удалось достичь цели, используя практически одинаковый запрос для трех разных СУБД.
Делитесь в комментариях, какие наиболее объемные иерархии вам удалось визуализировать, и удалось ли добиться аномалий при работе запроса.
На этом цикл статей окончен, спасибо всем за проявленный интерес - он стал для меня неожиданностью, так как практической составляющей в статьях нет )))
Комментарии (6)

IVNSTN
30.04.2024 23:02+8Некоторые соображения про большой запрос (в основном из контекста MSSQL, но кое-что в доках Postgresql перепроверил и там вроде всё то же самое):
В блоке Levels UNION, который даёт доп. сортировку и DISTINCT, кажется, что можно смело заменить на UNION ALL, потому как по крайней мере колонка
node_levelточно ни на каком уровне иерархии не совпадет. Фрагментconcat(coalesce(concat(prev.parents, '-'), ''), cast(Mapping.parent_node_id as varchar))Можно бы упростить: CONCAT игнорирует NULL и COALESCE выглядит просто лишним. Такой же coalesce есть в блоке FineTree. Конвертацию инта в строку вроде бы concat в postgres тоже делает автоматически, т.е. как будто достаточноconcat(prev.parents, '-', Mapping.parent_node_id). Если хочется единообразия, то можно сделать по аналогии со строчкой нижеconcat_ws('-', prev.parents, Mapping.parent_node_id)В блоке Branches два схожих фрагмента:
case when root_node_id is null then case when node_id = last_value(node_id) over WindowByParents then '└── ' else '├── ' end else '' end as node_branch,если перевернуть первое условие, то код станет более прямолинейным:
case when root_node_id is not null then '' when node_id = last_value(node_id) over WindowByParents then '└── ' else '├── ' end as node_branch,В Tree UNION тоже больше похож на UNION ALL. Финальную сортировку корректнее в финальном же запросе и разместить, а то cte FineTree как сортированная вьюха получается. В Branches сортировка выглядит просто лишней.
Множественные джойны на RootNodes кажется, что не нужны - у всех корневых узлов
nest_level = 0и можно пользоваться этим знанием. Избавиться от этого джойна возможно в Branches и в Tree. Вместе с этим можно будет выкинуть два CTE: Mapping и RootNodes. Фильтр `parent_node_id is null / node_id in (3, 10, 17)`идеально подходит для первого запроса рекурсивного CTE Levels. И в кейсах (рассмотренных чуть выше) получится более естественное для восприятия условиеwhen nest_level = 0 then ''И очень желательно во всех запросах колонкам алиас источника расставить: СУБД разберётся, где чьё, а человеку читать тяжело. Большую часть, если не всё, из того, что происходит в Branches и Tree, как будто можно сделать ещё в Levels и повторно большую рекурсию не гонять.

iqu Автор
30.04.2024 23:02Спасибо, по большей части замечания по делу!
В целом я не занимался оптимизацией, т.к. эффект от нее будет заметен на объемных иерархиях (1 млн строк и более), а необходимость их визуализации довольно сомнительна. Но почему бы не оптимизировать то, что может быть оптимизировано?
Отвечу по пунктам:
В блоке Levels UNION, который даёт доп. сортировку и DISTINCT, кажется, что можно смело заменить на UNION ALL, потому как по крайней мере колонка
node_levelточно ни на каком уровне иерархии не совпадет.Принято, и в Tree тоже!
node_idдолжен быть уникален в иерархии, поэтомуDISTINCTздесь никогда не даст эффекта.
Интересно, что в случае PostgreSQL план запроса одинаковый дляALLиDISTINCT, а в MySQL дляALLэффект виден - на плане запроса, выигрыш в быстродействии заметить я не смог на иерархии в 85000 строкФрагмент
concat(coalesce(concat(prev.parents, '-'), ''), cast(Mapping.parent_node_id as varchar))Можно бы упростить: CONCAT игнорирует NULL и COALESCE выглядит просто лишним.Нет, здесь вы не совсем правы. В моем варианте в PostgreSQL поле
parentsу узлов первого уровня выглядит как'-0'вместо'0'в MySQL, что не критично для партиционирования в окне по значению в этом поле. Но в MySQLCONCAT()не игнорируетNULL, и в вашем варианте все значения вparentsбудутNULL. Моя задача была написать максимально универсальный код, поэтому оставлю свой вариант.В блоке Branches два схожих фрагмента ...
Полностью соглашусь, переписал изначально использовавшийся мною тернарный
IF()не самым удачным образомМножественные джойны на RootNodes кажется, что не нужны - у всех корневых узлов
nest_level = 0и можно пользоваться этим знанием. Избавиться от этого джойна возможно в Branches и в Tree.Да, здесь можно пожертвовать единообразием (определения начальных узлов соединением с
RootNodes) ради экономии 2 строк кода, плюс в MySQL план запроса сокращается на 2 строки.В реальных условиях это может быть не столь однозначно - например, если в таблице создан индекс по полю
node_id, соединение сRootNodesпо нему будет происходить быстро, в отличие от применения условияnode_level = 0- это вычисляемое поле, все записи будут сканироваться.У меня изначально была идея сохранять уровень
node_levelоригинальным, т.е. если в качестве начального указан узел с уровнем 4, то именно это значение и будет у него в полеnode_level, но я отказался от этой идеи, так как в RootNodes может быть передано несколько начальных узлов из разных уровней, но визуализированы они будут как одинаковые по уровню - поэтому принимаю предложение.Вместе с этим можно будет выкинуть два CTE: Mapping и RootNodes.
Здесь не могу согласиться. И одно, и другое служит для параметризации запроса, по сути это интерфейсные CTE, их удобно располагать в начале, чтобы не "трогать" смысловую часть.
Mappingпозволяет использовать запрос без каких-либо изменений с любой структурой данных - это более дружественная для новичков реализация, а опытные в любом случае адаптируют запрос к своим условиям.И очень желательно во всех запросах колонкам алиас источника расставить: СУБД разберётся, где чьё, а человеку читать тяжело. Большую часть, если не всё, из того, что происходит в Branches и Tree, как будто можно сделать ещё в Levels и повторно большую рекурсию не гонять.
Каждый CTE использует только предыдущий, указанный в FROM - как сформулировано в задаче. При таком варианте алиасы избыточны кмк.
Идею "все сделать в
Levels" предоставлю возможность реализовать кому-то другому, мне по душе подход с разделением большого на меньшее и решение "слона по частям" ))В целом интересно проверить на большой иерархии, от 1 млн. строк. Видимо, придется продолжить...
Собственно, результат оптимизации:
PostgreSQL и SQLite
with recursive Mapping as ( select id as node_id, parent_id as parent_node_id, concat(name, ' (', bytes, ')') as node_name from ZipArchive ), RootNodes as ( select node_id as root_node_id from Mapping where -- Exactly one line below should be uncommented parent_node_id is null -- Uncomment to build from root(s) -- node_id in (27233) -- Uncomment to add node_id(s) into the brackets ), Levels as ( select node_id, parent_node_id, node_name, cast(parent_node_id as varchar) as parents, cast(node_name as varchar) as full_path, 0 as node_level from Mapping inner join RootNodes on node_id = root_node_id union all select Mapping.node_id, Mapping.parent_node_id, Mapping.node_name, concat(coalesce(concat(prev.parents, '-'), ''), cast(Mapping.parent_node_id as varchar)), concat_ws(' ', prev.full_path, Mapping.node_name), prev.node_level + 1 from Levels as prev inner join Mapping on Mapping.parent_node_id = prev.node_id ), Branches as ( select node_id, parent_node_id, node_name, parents, full_path, node_level, case when node_level = 0 then '' when node_id = last_value(node_id) over WindowByParents then '└── ' else '├── ' end as node_branch, case when node_level = 0 then '' when node_id = last_value(node_id) over WindowByParents then ' ' else '│ ' end as branch_through from Levels window WindowByParents as ( partition by parents order by node_name rows between current row and unbounded following ) order by full_path ), Tree as ( select node_id, parent_node_id, node_name, parents, full_path, node_level, node_branch, cast(branch_through as varchar) as all_through from Branches where node_level = 0 union all select Branches.node_id, Branches.parent_node_id, Branches.node_name, Branches.parents, Branches.full_path, Branches.node_level, Branches.node_branch, concat(prev.all_through, Branches.branch_through) from Tree as prev inner join Branches on Branches.parent_node_id = prev.node_id ), FineTree as ( select tr.node_id, tr.parent_node_id, tr.node_name, tr.parents, tr.full_path, tr.node_level, concat(coalesce(parent.all_through, ''), tr.node_branch, tr.node_name) as fine_tree from Tree as tr left join Tree as parent on parent.node_id = tr.parent_node_id order by tr.full_path ) select fine_tree, node_id from FineTree ;MySQL и SQLite
with recursive Mapping as ( select id as node_id, parent_id as parent_node_id, concat(name, ' (', bytes, ')') as node_name from ZipArchive ), RootNodes as ( select node_id as root_node_id from Mapping where -- Keep uncommented exactly one line below parent_node_id is null -- Uncomment to build from root(s) -- node_id in (27233) -- Uncomment to add node_id(s) into the brackets ), Levels as ( select node_id, parent_node_id, node_name, cast(parent_node_id as char(2000)) as parents, cast(node_name as char(2000)) as full_path, 0 as node_level from Mapping inner join RootNodes on node_id = root_node_id union all select Mapping.node_id, Mapping.parent_node_id, Mapping.node_name, concat(coalesce(concat(prev.parents, '-'), ''), cast(Mapping.parent_node_id as char(2000))), concat_ws(' ', prev.full_path, Mapping.node_name), prev.node_level + 1 from Levels as prev inner join Mapping on Mapping.parent_node_id = prev.node_id ), Branches as ( select node_id, parent_node_id, node_name, parents, full_path, node_level, case when node_level = 0 then '' when node_id = last_value(node_id) over WindowByParents then '└── ' else '├── ' end as node_branch, case when node_level = 0 then '' when node_id = last_value(node_id) over WindowByParents then ' ' else '│ ' end as branch_through from Levels window WindowByParents as ( partition by parents order by node_name rows between current row and unbounded following ) order by full_path ), Tree as ( select node_id, parent_node_id, node_name, parents, full_path, node_level, node_branch, cast(branch_through as char(2000)) as all_through from Branches where node_level = 0 union all select Branches.node_id, Branches.parent_node_id, Branches.node_name, Branches.parents, Branches.full_path, Branches.node_level, Branches.node_branch, concat(prev.all_through, Branches.branch_through) from Tree as prev inner join Branches on Branches.parent_node_id = prev.node_id ), FineTree as ( select tr.node_id, tr.parent_node_id, tr.node_name, tr.parents, tr.full_path, tr.node_level, concat(coalesce(parent.all_through, ''), tr.node_branch, tr.node_name) as fine_tree from Tree as tr left join Tree as parent on parent.node_id = tr.parent_node_id order by tr.full_path ) select fine_tree, node_id from FineTree ;SQLite всеяден, оба варианта работают в нем одинаково
iqu Автор
30.04.2024 23:02Похоже, я несколько ввел всех в заблуждение - последний вариант запроса для PostgreSQL корректно исполняется в SQLite, но не в MySQL, что-то я вчера в ночи попутал. Исправлю текст в статье.

ALexKud
30.04.2024 23:02Когда переносил из xml объёмом в 116 станиц в mssql в пять связанных таблиц, то рекурсию не стал использовать, а использовал фильтрацию по параметрам, так как их было больше 50 плюс пустые уровни только для связности в исходной таблице иерархии с узлами и данными. И задача была практическая. А вообще, когда разрабатывал запросы из этих таблиц для sqlite и мssql,то с множеством CTE запросы были идентичны и за исключением замены ТОP на Limit.
miksoft
А что там за символ внутри "nbm (DIR)" ? Почему MySQL поставил его после "-" ?
Если пробел, то у меня не воспроизводится:
https://www.db-fiddle.com/f/fdUqqzXid62pqBxanhxusu/0
iqu Автор
Сортировка производится по full_path, для этих узлов поле содержит:
IdealGraphVisualizer (DIR) branding (DIR) src (DIR) main (DIR) nbm (DIR)и
IdealGraphVisualizer (DIR) branding (DIR) src (DIR) main (DIR) nbm-branding (DIR)У меня стабильно по-разному выводятся, но я подписи перепутал, сейчас исправлю ))