
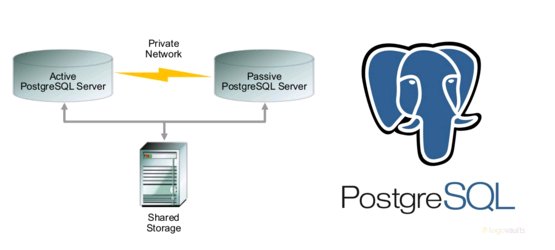
Описание
В данной статье рассматривается пример настройки Active/Passive кластера для PostgreSQL с использованием Pacemaker, Corosync. В качестве дисковой подсистемы рассматривается диск от системы хранения данных (CSV). Решение напоминает Windows Failover Cluster от Microsoft.
Технические подробности:
Версия операционной системы — CentOS 7.1
Версия пакета pacemaker — 1.1.13-10
Версия пакета pcs — 0.9.143
Версия PostgreSQL — 9.4.6
В качестве серверов(2шт) — железные сервера 2*12 CPU/ 94GB memory
В качестве CSV(Cluster Shared Volume) — массив класса Mid-Range Hitachi RAID 1+0
Подготовка узлов кластера
Правим /etc/hosts на обоих хостах и делаем видимость хостов друг друга по коротким именам, например:
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.66.23 node1.local.lan node1
10.1.66.24 node2.local.lan node2
Также делаем обмен между серверами через SSH-ключи и раскидываем ключи между хостами.
После этого надо убедиться, что оба сервера видят друг друга по коротким именам:
[root@node1 ~]# ping node2
PING node2.local.lan (10.1.66.24) 56(84) bytes of data.
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=1 ttl=64 time=0.204 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=2 ttl=64 time=0.221 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=3 ttl=64 time=0.202 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=4 ttl=64 time=0.207 ms
[root@node2 ~]# ping node1
PING node1.local.lan (10.1.66.23) 56(84) bytes of data.
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=1 ttl=64 time=0.202 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=2 ttl=64 time=0.218 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=3 ttl=64 time=0.186 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=4 ttl=64 time=0.193 ms
Установка пакетов для создания кластера
На обоих хостах ставим необходимые пакеты, чтобы затем собрать кластер:
yum install -y pacemaker pcs psmisc policycoreutils-python
Затем стартуем и включаем службу pcs:
systemctl start pcsd.service
systemctl enable pcsd.service
Для управление кластером нам потребуется специальный пользователь, создаем его на обоих хостах:
passwd hacluster
Changing password for user hacluster.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Pacemaker|Corosync
Для проверки аутентификации, с первой ноды необходимо выполнить команду:
[root@node1 ~]# pcs cluster auth node1 node2
Username: hacluster
Password:
node1: Authorized
node2: Authorized
Далее, стартуем наш кластер и проверяем состояние запуска:
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
pcs cluster start --all
pcs status --all
Вывод о состоянии кластера должен быть примерно такой:
[root@node1 ~]# pcs status
Cluster name: cluster_web
WARNING: no stonith devices and stonith-enabled is not false
Last updated: Tue Mar 16 10:11:29 2016
Last change: Tue Mar 16 10:12:47 2016
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 Nodes configured
0 Resources configured
Online: [ node1 node2 ]
Full list of resources:
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Теперь переходим к настройке ресурсов в кластере.
Настройка CSV
Заходим на первый хост и настраиваем LVM:
pvcreate /dev/sdb
vgcreate shared_vg /dev/sdb
lvcreate -l 100%FREE -n ha_lv shared_vg
mkfs.ext4 /dev/shared_vg/ha_lv
Диск готов. Теперь нам необходимо сделать так, что было на диск не применялось правило автомонтирования для LVM. Делается это внесением изменений в файле /etc/lvm/lvm.conf (раздел activation) на обоих хостах:
activation {.....
#volume_list = [ "vg1", "vg2/lvol1", "@tag1", "@*" ]
volume_list = [ "centos", "@node1" ]
Обновляем initrams и перезагружаем ноды:
dracut -H -f /boot/initramfs-$(uname -r).img $(uname -r)
shutdown -h now
Добавление ресурсов в кластер
Теперь необходимо создать группу ресурсов в кластере — диск c файловой системой и IP.
pcs resource create virtual_ip IPaddr2 ip=10.1.66.25 cidr_netmask=24 --group PGCLUSTER
pcs resource create DATA ocf:heartbeat:LVM volgrpname=shared_vg exclusive=true --group PGCLUSTER
pcs resource create DATA_FS Filesystem device="/dev/shared_vg/ha_lv" directory="/data" fstype="ext4" force_unmount="true" fast_stop="1" --group PGCLUSTER
pcs resource create pgsql pgsql pgctl="/usr/pgsql-9.4/bin/pg_ctl" psql="/usr/pgsql-9.4/bin/psql" pgdata="/data" pgport="5432" pgdba="postgres" node_list="node1 node2" op start timeout="60s" interval="0s" on-fail="restart" op monitor timeout="60s" interval="4s" on-fail="restart" op promote timeout="60s" interval="0s" on-fail="restart" op demote timeout="60s" interval="0s" on-fail="stop" op stop timeout="60s" interval="0s" on-fail="block" op notify timeout="60s" interval="0s" --group PGCLUSTER
Обратите внимание, что у всех ресурсов одна группа.
Также надо не забыть поправить dafault -параметры кластера:
failure-timeout=60s
migration-threshold=1
В конечно итоге, Вы должны увидеть подобное:
[root@node1 ~]# pcs status
Cluster name: cluster_web
Last updated: Mon Apr 4 14:23:34 2016 Last change: Thu Mar 31 12:51:03 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 nodes and 4 resources configured
Online: [ node1 node2 ]
Full list of resources:
Resource Group: PGCLUSTER
DATA (ocf::heartbeat:LVM): Started node2
DATA_FS (ocf::heartbeat:Filesystem): Started node2
virtual_ip (ocf::heartbeat:IPaddr2): Started node2
pgsql (ocf::heartbeat:pgsql): Started node2
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Проверяем статус службы PostgreSQL, на хосте, где ресурсная группа:
[root@node2~]# ps -ef | grep postgres
postgres 4183 1 0 Mar31 ? 00:00:51 /usr/pgsql-9.4/bin/postgres -D /data -c config_file=/data/postgresql.conf
postgres 4204 4183 0 Mar31 ? 00:00:00 postgres: logger process
postgres 4206 4183 0 Mar31 ? 00:00:00 postgres: checkpointer process
postgres 4207 4183 0 Mar31 ? 00:00:02 postgres: writer process
postgres 4208 4183 0 Mar31 ? 00:00:02 postgres: wal writer process
postgres 4209 4183 0 Mar31 ? 00:00:09 postgres: autovacuum launcher process
postgres 4210 4183 0 Mar31 ? 00:00:36 postgres: stats collector process
root 16926 30749 0 16:41 pts/0 00:00:00 grep --color=auto postgres
Проверяем работоспособность
Имитируем падение сервиса на ноде2 и смотрим, что происходит:
[root@node2 ~]# pcs resource debug-stop pgsql
Operation stop for pgsql (ocf:heartbeat:pgsql) returned 0
> stderr: ERROR: waiting for server to shut down....Terminated
> stderr: INFO: PostgreSQL is down
Проверяем статус на ноде1:
[root@node1 ~]# pcs status
Cluster name: cluster_web
Last updated: Mon Apr 4 16:51:59 2016 Last change: Thu Mar 31 12:51:03 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 nodes and 4 resources configured
Online: [ node1 node2 ]
Full list of resources:
Resource Group: PGCLUSTER
DATA (ocf::heartbeat:LVM): Started node1
DATA_FS (ocf::heartbeat:Filesystem): Started node1
virtual_ip (ocf::heartbeat:IPaddr2): Started node1
pgsql (ocf::heartbeat:pgsql): Started node1
Failed Actions:
* pgsql_monitor_4000 on node2 'not running' (7): call=48, status=complete, exitreason='none',
last-rc-change='Mon Apr 4 16:51:11 2016', queued=0ms, exec=0ms
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Как мы видим сервис уже прекрасно себя чувствует на ноде1.
ToDO: сделать зависимости от ресурсов внутри группы…
Литература:
clusterlabs.org
Комментарии (24)

kruft
04.04.2016 19:38+2на 2х нодах сплит-брейн как разруливается?

gotch
04.04.2016 23:44С интересом читаю про Open Source кластеризацию. У Микрософта такие ситуации разруливаются witness-ресурсом.
Как мне помнится, во времена 2003, было совсем по старомодному — у кого кворумный диск, тот и победил. С тех пор как появились кластеры более чем из двух узлов, побеждает та группа, у которой на 1 голос больше, на четном числе узлов можно так же давать диску голос.
Очень интересно описание реализации как для SCSI-2, так и для SCSI-3
Суть такая, что текущий владелец держит диск, а конкуренты пытаются его "отобрать", но дают владельцу достаточно времени чтобы отбить нападки. Если владелец — не жилец, диск отбирается.
Работает эта микрософтова реализация просто и надежно. Здесь нельзя настроить по тому же принципу?

gunya
04.04.2016 20:28+2Две машины, shared storage и
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
Данная конструкция продержится до первого split-brain, при котором она радостно рухнет вместе с WAL-логами Postgres или ФС/LVM.
pbobrovnikov
04.04.2016 21:58Вижу, что split braint — больная тема). Диски — FC. В конфигурациях Active/Active такое быть может, несомненно. В Active/Passive — отнюдь. Единственное, что может быть в Active/Passive — база уйдет in recovery в момент переезда, когда данные не успеют сброситься на диск, но для этого надо тюнинг postgresql.conf (fsync, sync.commit)
Дабы закрыть тему со split braint, предлагаю Вам поднять на виртуалах данную конфигурацию и проверит все на деле.
thatsme
05.04.2016 07:20+1Диски — FC. В конфигурациях Active/Active такое быть может, несомненно. В Active/Passive — отнюдь.
FC диски доступны на обоих узлах одновременно. Если используется lvm2 (не clvm), то монтировать тома могут оба узла с негарантируемым результатом. С clvm результат более предсказуем, но при split brain также не гарантируется. Именно для избегания ситуации split brain в кластерном ПО предусмотерны такие фичи как fencing и в частности STONITH в pacemaker (который немного больше чем простой фэнсинг).
Вот эта часть:
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
Для lvm2, кластер А/А и A/P (без поддержки кластеризации в lvm), должна быть такой:
pcs property set stonith-enabled=true
pcs property set no-quorum-policy=ignore
Для clvm, кластер А/А:
pcs property set stonith-enabled=true
pcs property set no-quorum-policy=fence
Для clvm кластер А/P:
pcs property set stonith-enabled=true
pcs property set no-quorum-policy=ignore
Очевидно, что STONITH активирован в любой конфигурации.
Он будет нужен даже тогда, когда у Вас не разделяемое дисковое пространство используется, а независимые диски для каждого узла, и между ними репликация master/slave.
А ещё лучше, для fensinga предусмотреть сырой том (не lvm)! И всегда держать включённымthatsme
05.04.2016 07:26И всегда держать включённым
имеется в виду: pcs property set no-quorum-policy=fence
gunya
05.04.2016 17:44Единственное, при split brain такая схема войдет в состояние stonith deathmatch, когда оба сервера будут пытаться фенсить друг друга. Но это гораздо лучше, чем порча данных при split brain.
Sevchik403
05.04.2016 06:59А кто может поделиться опытом построения High Avaibility (99,9% — 99,99%) PostgreSQL в условиях Azure Maintance, когда машины сами включаются и выключаются попеременно?
Рассматривал вариант с PgPool, но в нем была проблема в том, что при выключении мастера и его восстановлении, он не знал о том, что другая машина стала мастером. PgPool некорректно работал одновременно на 2 машинах. Да и честно как то это костыльно выглядело.thatsme
05.04.2016 07:25Use STONITH. см. пост

DmitryKoterov
05.04.2016 08:59Объясните, пожалуйста, на пальцах, что будет делать stonith, если удаленная машина недоступна совсем — в том числе недоступен и stonith-девайс. Ведь, насколько я понимаю, сигнал о выключении посылается точно так же по сети, только через другой сетевой интерфейс. Что будет, если и он недоступен?
thatsme
05.04.2016 16:07На пальцах не получится, вот подробная статья с простым описанием ourobengr.com/ha
thatsme
05.04.2016 16:29Пробую объяснить на пальцах (не уверен что получится)
Если у Вас есть диск кворума, то именно с его помощью определяется живы ли соседи в кластере (при отсутствии сети и при условии, что SAN это отдельная сеть со своими коммутаторами).
Даже если у Вас пропала сеть передачи данных, то у Вас есть устройство для кворума (находящееся в сети хранения данных — SAN), ч-з которое ноды определяют кто из них главный в данный момент. И вот именно опция pcs property set no-quorum-policy=fence говорит нам, что если кворум недоступен данному узлу он должен поступить в соответствии с полиcи. fence — означает, — умереть. То есть узел перестаёт считать себя главным.
Split brain, — ситуация в которой каждый из узлов считает, что он главный.
Для решения этой ситуации есть два механизма:
а) STONITH — пристрели соседний узел. Очевидно, что данный метод будет работать только если осталась возможность узлов коммуницировать. Для этого оборудование и интерфейсы в кластерной инфраструктуре должны быть избыточно резервированы и желательно иметь внешнее устройство (например ИБП APC, которые считаются очень надёжными), к которому узлы кластера всё время обращаются, для того что-бы определить, есть-ли сеть вообще.
б) fencing — умри сам. см. выше.

crazylh
06.04.2016 10:26+1Ничего хорошего — кластер превратится в тыкву, вплоть до того что corosync от количества служебных сообщений начнет падать в корку, перезапускаться и снова падать.
pbobrovnikov
05.04.2016 13:31Sevchik403, настраивал как с отдельно стоящими PGPOOL-II (2 хоста+WatchDog), так и с PGPOOL-II непосредственно на самих хостах с БД.
Когда мастер падал, отрабатывал Failover.sh на слэйве — создавал trigger_file и слэйв становился мастером — это билет в один конец, т.е. мастер упавший придется восстанавливать ручками, например, через pg_basebackup со слэйва, потому как если упавший мастер поднять — вуаля! и у нас 2 мастера (во всяком случае тесты показывали именно такое).Sevchik403
05.04.2016 13:46Как раз таки такого я и добился, но это критично при Azure Maintance. Машины выключаются/включаются с перерывом в 30 минут и это происходит в течении 3 суток. То есть неизвестно в какой именно момент времени это произойдет. Вы можете спать, а машины в этот момент могут перезагрузиться и вы просто не успеете ничего сделать.
DmitryKoterov
05.04.2016 09:28К автору поста. Вы меня извините, но это статья из серии "установил линукс — напиши пост на хабре". Даже про кворум ничего не сказано, а ведь это минимально-необходимая и важнейшая штука. Про stonith я выше вопрос задал — может быть, кто-нибудь сможет разъяснить, наконец, имеет ли stonith вообще смысл, если все машины, например (для вырожденного случая), виртуалки и разбросаны по разным датацентрам по всему миру.
JuriM
05.04.2016 10:24В случае виртуалок stonith настраивается с участием гипервизора. Гипервизор делает turn off (выдернуть кабель питания) виртуалке для предотвращения split brain.
gunya
05.04.2016 14:07К использованию stonith надо применять немного другой подход. Он должен применяться в ситуациях, когда ресурс должен гарантированно обслуживаться или использоваться только одним сервером в кластере. Необходимость применения не зависит от конфигурации серверов, будь то виртуалки в разных ДЦ или физические машины в одной стойке.
В случае shared storage — необходимо убедиться, что ни один другой сервер не использует том (иначе крайне вероятно разрушение ФС) — в данной ситуации должен использоваться STONITH.
В случае shared ip — опять же, если два сервера подцепят один IP, будут проблемы (здесь хотя бы руками можно откатиться на рабочий вариант).
С другой стороны, если фенсинг не нужен, как правило, можно обойтись вообще без pacemaker.
rino906
Идея интересная, но что будет при split brain? Более безопасный вариант http://clusterlabs.org/wiki/PgSQL_Replicated_Cluster
pbobrovnikov
Здесь не идет речи о split brain, так как в один момент времени инстанс PostgreSQL крутится на одном хосте, репликация не используется и группа представляется как единый сервис и все операции записи/чтения идут в одно место.
В случае выхода из строка VIP (моргнет сеть) либо сервиса, вся группа переедет на другую ноду.
rino906
При split brain оба хоста будут считать себя мастер нодой: примонтируют директорию с базой и каждый запустит свой экземпляр postgres'а
pbobrovnikov
в статье указано, что сделать чтобы это не происходило.
Когда группа STARTED на конкретном хосте в кластере, на другой ноде — данного lvm диска даже не числится. Диском управляет кластер — где группа, там и диск.
Проверено.
rino906
Ситуация: node1.local.lan работает группа на нем, в момент времени node2.local.lan перестает "видеть" по сети node1.local.lan(с самим node1.local.lan при этом все хорошо). Тогда node2.local.lan начинает считать, что node1.local.lan отвалилась, поэтому поднимает у себя Resource Group: PGCLUSTER.
Это не редкий случай при виртуализации.
gunya
На физическом железе это тоже не редкость — если моргнет сеть/дернется сетевой провод/случайно добавится правило в FW, получится split-brain. Так как раздел с базой подключается, судя по всему, через SAS, то обеим машинам ничего не помешает подмонтировать раздел на запись и начать крушить ФС.