
Кто очень хочет понимать Linux, но не поймет с чего начинать — прошу ко мне на канал.

Вместо введения: Graylog это open source программное обеспечение, предназначенное для сбора логов в гигантских сетях их огромного количества источников различными способами. В нем можно удобно организовать сбор событий, фильтрацию, поиск, автоматизацию (всякие алерты) и т.д. Аналогичных средств множество, но Graylog предлагает нереальную производительность с использованием современных компонентов, удобную аналитику и красивый интерфейс.
Для работы ему нужна Java, конфигурацию он будет хранить в MongoDB, для поиска и хранения логов — использовать ElasticSearch. Про сбор информации из WIndows будет ниже, но спойлер — агенту больше не нужна Java.
Итак, у нас есть официальный мануал, по которому мы должны с вами собрать Graylog. Но в нем очень многое упущено, это просто обрывки информации, поэтому пойдем поэтапно сами (использую Ubuntu 14.04, так как именно ее и советуют разработчики на данный момент). Так как изначально Graylog предназначен для огромнейших сетей, рекомендуется ставить БД, поисковый движок и сам Graylog на разные сервера, создавать из этого всего кластеры, узлы и т.д. Я беру простейший конфиг, в котором все крутится на одной машине.
Первая часть: установка Graylog. (видеоинструкция)
Сначала Java (не ниже восьмой версии):
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer
Затем MongoDB (вдруг что изменится, вот вам мануал):
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv EA312927
echo 'deb http://downloads-distro.mongodb.org/repo/debian-sysvinit dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list
sudo apt-get update
sudo apt-get install mongodb-org
Следом ElasticSearch (у которого тоже есть свой мануал):
sudo wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb http://packages.elastic.co/elasticsearch/2.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-2.x.list
sudo apt-get update
sudo apt-get install elasticsearch
Эластику нужны:
настройка автозапуска:
sudo update-rc.d elasticsearch defaults 95 10
редактирование файла конфигурации:
sudo vi /etc/elasticsearch/elasticsearch.yml
а именно указать имя кластера, например:
cluster.name: graylog
и запретить доступ к нему по сети (так как вся система у нас на одной машине):
network.bind_host: localhost
еще рекомендуют запретить динамические скрипты, но у меня эластик на эту опцию ругается:
script.disable_dynamic: true
Рестартуем Эластик:
sudo service elasticsearch restart
И проверяем
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
Если на выводе нет откровенных ошибок, то все в порядке.
Установка и пробный запуск Graylog:
sudo apt-get install apt-transport-https
wget https://packages.graylog2.org/repo/packages/graylog-2.0-repository_latest.deb
sudo dpkg -i graylog-2.0-repository_latest.deb
sudo apt-get update
sudo apt-get install graylog-server
sudo rm -f /etc/init/graylog-server.override
sudo start graylog-server
Теперь устанавливаем пароль доступа к нему (у меня «123456789»), шифрованный, как и полагается у взрослых (кому будет непонятен смысл команд ниже: смотрите видео, или пишите вопросы):
sudo apt-get install pwgen
SECRET=$(pwgen -s 96 1)
sudo -E sed -i -e 's/password_secret =.*/password_secret = '$SECRET'/' /etc/graylog/server/server.conf
PASSWORD=$(echo -n 123456789 | shasum -a 256 | awk '{print $1}')
sudo -E sed -i -e 's/root_password_sha2 =.*/root_password_sha2 = '$PASSWORD'/' /etc/graylog/server/server.conf
В том же файле конфигурации указываю ip своего будущего сервера Graylog и префикс (он же — имя кластера Эластика выше).
sudo vi /etc/graylog/server/server.conf
rest_listen_uri = http://10.0.1.10:12900/
web_listen_uri = http://10.0.1.10:9000/
elasticsearch_index_prefix = graylog
Перезапускаю Graylog и пробую войти в него через веб-интерфейс:
10.0.1.10:9000/(само собой все указанные в конфиге порты должны быть открыты). При старте Graylog может пару минут дурачится и писать в веб-интерфейсе что все плохо, не принимать пароль и выбрасывать на главную. Дайте ему время прийти в себя и пробуйте.
Вторая часть: настройка приема логов в Graylog из Linux. (видеоинструкция)
В консоль сервера приема логов нам больше попадать не нужно. Идем в веб-морду и создаем Input для логов. Расписывать навигацию по веб-интерфейсу дело гиблое, потому есть видео. Если кратко:
- в меню «Система» создается UDP Input;
- указывается syslog udp;
- указывается порт (по умолчанию 512, но чтобы graylog мог использовать порты ниже 1024 нужно много возьни), поэтому, например 1234;
- указывается адрес для прослушивания входящих сообщений, у меня 10.0.1.10;
- нажимаем Launch.
Для проверки работы Input можно в консоли того же сервера graylog выполнить
echo "Hello Graylog" | nc -w 1 -u 10.0.1.10 1234
Конфигурация машин Linux на отправку логов, в принципе проста. Почти везде релизы syslogd ведут себя одинаково. Кто ничего не помнит о демонах журналирования — освежите память у меня на канале. Итак debian и redhat.
Создается файл задания rsyslog:
sudo vi /etc/rsyslog.d/90-graylog2.conf
c текстом (адрес и порт взят из настроенного Input):
$template GRAYLOGRFC5424,"<%PRI%>%PROTOCOL-VERSION% %TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% %PROCID% %MSGID% %STRUCTURED-DATA% %msg%\n"
*.* @10.0.1.10:1234;GRAYLOGRFC5424
Демон журналов перезапукается командой
sudo service rsyslog restart
И можно смотреть в веб-интерфейсе Graylog полученные сообщения.
Третья часть: настройка приема логов в Graylog из Windows. (видеоинструкция)
В версиях Graylog младше второй использовался graylog collector на java. Во второй (актуальной) он просто игнорируется и дает ошибки (полдня пытался починить, пока не понял это). Вместо него используется graylog sidecar, который получает конфиг с сервера Graylog (что очень удобно, так как нет необходимости лазить по виндовым серверам для редактирования настроек) и передает его в nxlog (или что вам больше нравится), который события собирает и отправляет.
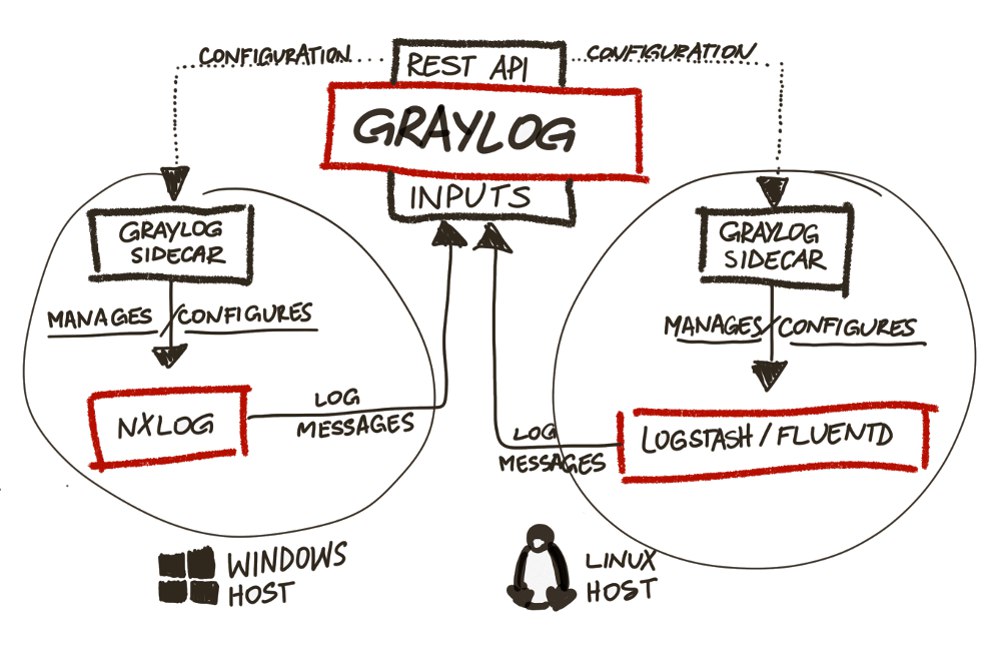
Для приема сообщений из Windows надо создать отдельный Input через веб-интерфейс:
- выбираем GELF UDP;
- указываем узел, айпишник сервера graylog;
- запоминаем или редактируем порт приема сообщений (по умолчанию 12201).
Для создания конфигурации отправки логов для nxlog на винде, нужно создать коллектор через веб-интерфейс в graylog:
- выбираем Collectors;
- выбираем Manage Configuration;
- создаем конфигурацию;
- указываем метку (именно по метке sidecar на windows поймет какую конфигурацию для nxlog ему скачивать к себе на машину);
- создаем Output для nxlog (в котором просто указываем настройки Input из предыдущего шага: GELF UDP Output, ip, порт);
- создаем Input для nxlog (указываем простейший вариант: Windows Event Log).
Отправляемся в Windows, Скачиваем и устанавливаем nxlog и graylog-sidecar.
Убираем как службу nxlog, и ставим как службу sidecar:
'C:\Program Files (x86)\nxlog\nxlog.exe' -u
'C:\Program Files (x86)\graylog\collector-sidecar\graylog-collector-sidecar.exe' -service install
Редактируем файл конфигурации Sidecar (C:\Program Files (x86)\graylog\collector-sidecar\collector_sidecar.yml), а именно указываем порт прослушки глобальный (12900), ip сервера, и самое главное: метку, по которой будет принят конфиг. У меня это выглядит так:
server_url: http://10.0.1.10:12900
node_id: graylog-collector-sidecar
collector_id: file:C:\Program Files (x86)\graylog\collector-sidecar\collector-id
tags: windows
log_path: C:\Program Files (x86)\graylog\collector-sidecar
update_interval: 10
backends:
- name: nxlog
enabled: true
binary_path: C:\Program Files (x86)\nxlog\nxlog.exe
configuration_path: C:\Program Files (x86)\graylog\collector-sidecar\generated\nxlog.conf
Запускаем sidecar
'C:\Program Files (x86)\graylog\collector-sidecar\graylog-collector-sidecar.exe' -service start
Создаем событие
eventcreate /l Application /t INFORMATION /id 1 /d “Suck it”
Смотрим логи в его директории (C:\Program Files (x86)\graylog\collector-sidecar\), и если все ок — отправляемся в веб-морду смотреть логи винды на инпуте.
Нюансы:
- бывает что файл конфига нужно создать вручную пустой C:\Program Files (x86)\graylog\collector-sidecar\generated\nxlog.conf;
- бывает что нужно перезапустить винду, чтобы все сервисы все схватили;
- у меня был косяк с опечаткой в названии метки, убил час, разбираясь;
- сама метка должна отметиться в веб-интерфейсе в рамочку, иначе это не метка.
Ну а дальше уже начинается работа в веб-интерфейсе: какие именно логи откуда брать, как на какие события реагировать, что отфильтровывать и т.д. Начнете копать — разберетесь. Вот на всякий случай еще раз мануал.
Комментарии (50)
tgz
05.05.2016 08:531. А оно может работать на паре серверов? Master/slave или master/master, например?
2. Наверняка же есть библиотеки для писания логов из java приложений сразу в greylog, без системного syslogd?
johndow
05.05.2016 08:58библиотеки для писания логов из java приложений
https://github.com/pukkaone/logback-gelf
https://github.com/Moocar/logback-gelf

DuD
05.05.2016 13:58Elasticsearch легко и непринужденно кластеризуется. Умеет сам находить ноды своего кластера.
www.elastic.co/guide/en/elasticsearch/reference/current/_installation.html

nucleusv
12.05.2016 09:42Может, скейлится горизонтально. Перед нодами graylog нужно установить балансировщик, haproxy например.
Механизм healthcheck поддерживается в веб-интерфейсе graylog, можно прям из морды выводить из баланса.

RicoX
05.05.2016 09:07-1Что в ELK что в GrayLog2 меня отталкивает необходимость использовать Java, может кто подскажет серверное решение не требующее особого напильника и умеющее:
1) Очень много логов в пиках до 10К/sec, не требующее сверхмощного железа.
2) Генерацию алярм по определенным шаблонам, например с одного узла сети за минуту пришло больше Х сообщений содержащих «Error»
3) Умеющее SNMP-trap или которое можно подружить с SNMP, а не только генерация mail, нужно для того чтоб подружить с общей системой мониторинга а не иметь 10 морд для разных аспектов.
4) Желательно cli для генерации выборок прямо в терминале или использования в скриптах, вебморда это конечно красиво, но на большом количестве событий медленно и неудобно.
Использоваться будет в сети ISP где более 10К управляемых железок шлют свои логи на сервер, сейчас используется syslog-ng с собственными фильтрами, плюс скриптовая обвязка, но ели ворочается и требует постоянного напильника, хочется более красивое и желательно готовое решение, но весь гугл забит ссылками на ELK и GrayLog, может я что-то упускаю.
rudenkovk
05.05.2016 09:18имхо: если opensource — то ничего не упускаешь.
А так, я живу на ELK, у меня среднее 5-7k/sec (очень разных событий, от однострочников a la «mail sand to ...», до портянок килобайт на 300-500 с дампами ошибок), в пике 25-30k/sec, все адекватно крутится на 3 головах ES (виртуалки не на ssd, 8 ядер, 8 гигов оперативы, глубина хранения от недели до месяца, в зависимости от типа), logstash выделен на отдельную машину. И в этой конфигурации я еще не особо игрался с настройками индексов, а это влияет на производительность. Виртуалки загружены на ~60%.RicoX
05.05.2016 09:48Похоже придется развернуть пару стендов и посмотреть в сторону elasticsearch и его api, он используется в обоих продуктах, а вебморда мне как таковая не нужна совсем. Нашел даже плагин для ES для своего syslog-ng, меньше всего переделывать придется — буду пробовать, раз альтернатив особо нет.
rudenkovk
05.05.2016 09:50посмотри logstash заодно, возможно не надо будет городить огород с плагинами.
А так же глянь на beats (это проект ребят эластика), возможно еще меньше огорода будет.RicoX
05.05.2016 10:20Если я правильно понял описание, то Beats заменяет logstash, то-есть занимается принятием логов и передачей их на ES, при этом для передачи используется что-то типа diff, а не логи целиком? Если я ничего не напутал из их описания проекта, то так должно быть еще быстрее и меньше нагрузка на систему принятия логов.
rudenkovk
05.05.2016 10:21Можно и так. Я все гоню в logstash на мутаторы. Пока этот момент я не смотрел глубоко и не перенастраивал. beats использую как локальные агенты.
RicoX
05.05.2016 10:25Спасибо за консультацию, буду пробовать в варианте когда логи принимает logstash и когда beats, сравню производительность, локальных агентов мне не нужно, т.к. почти все устройства — это коммутаторы и маршрутизаторы, на которые агента не поставить.
rudenkovk
05.05.2016 10:28Обращайтесь.
Думаю тогда имеет смысл смотреть на logstash
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-snmptrap.htmlRicoX
05.05.2016 10:44Не совсем, мне нужен не inputs трапов, а outputs смысл в том что принимать трапы умеет система мониторинга (zabbix) а вот от системы обработки логов требуется их генерация, так что от костыля zabbix_sender мне похоже никуда не деться.
rudenkovk
05.05.2016 10:46Ну тут я не очень готов вникать, голова совсем в другом. Если что обращайся по настройке ES.

rudenkovk
прошу меня простить, это не вброс guano на вентилятор. Но все же…
Мне кажется — это адский треш, если логи валятся очень быстро и очень много. ( ну скажем от 5k events/sec и масса среза, ну скажем >1Тб )
А вот почитать что-то вроде graylogUI vs kibana было бы интересно.
ZurgInq
Встречный вопрос, что не так в этой связке? MongoDB как NoSql база должна показывать хорошую производительность на вставку данных.
rudenkovk
С одной стороны компетентные товарищи говорят, что монгу, со времен 2,6 допилили. С другой стороны, в моем опыте использования mongo — это были вечные проблемы с консистентностью, и диском, с запутанной системой кластеризации. ES точно так же может выступать как nosql база, а масштабируется он куда проще и удобнее.
Возможно я не прав, но без должного ухода (читай как: elasticsearch, как хранилище его не требует) хранить в монге много много данных выглядит не целесообразно.
semaev
Мой косяк — действительно, теперь MongoDB используется только для хранения конфига graylog — всего того, что мы настраиваем через веб-интерфейс. Сами логи лежат в Эластике.
tubecleaner
Автор ошибся. Он уже давно не хранит логи в MongoDB ( сейчас там хранится только конфигурация ). Для хранения и поиска используется ElasticSearch.
Сам использую GrayLog2 и мне показалось, что документация у него довольно понятная и подробная, так что было бы интереснее узнать опыт реальной эксплуатации продукта, «подводные камни» и т.п.
Например: GraylogCollector не поддерживает новую архитектуру EventLog, так что его использование на Windows сильно ограничено. Бесплатный NXLog Community имеет ограниченный функционал ( правда, которого хватит почти всем ), за расширение надо доплачивать.
rudenkovk
Я давно и плотно сижу на ELK стеке, но приглядываю за конкурентами. Собственно а почему он не хранит конфигурацию в ES, как та же kibana например?
hc4
Например что бы иметь возможность стартовать без ES.
А ещё ES для хранения логов подразумевает возможность большой нагрузки на ES.
Будет неприятно, если из-за очередного запроса логов отвалятся все сессии у пользователей (ведь в эластике очередь запросов ограничена, и если очередь заполнена, запросы режектятся).
Ах да, ещё у ES есть проблема с изменением данных. Любое изменение — это создание новой записи и удаление старой (причём физически данные удаляются только после переиндексирования).
rudenkovk
а смысл?
при 150k event/sec на 4 головы ES + 1 голова только на http. Все машины 12 ядер на 16 гигов оперативы, обычные SAS диски, полет нормальный. А кластер работает с приличным запасом по мощности.
иииииииии? в чем тут проблема?
hc4
1. Graylog умеет скидывать логи в журнал, если не может залить их в elastic. Мне например это позволяет спокойно перезапускать/обновлять единственную ноду ELK без страха потерять данные (сыпятся не только логи, но и реалтайм статистика, которая не хранится на хостах)
2. А у меня один слабенький сервер на виртуалке и очередь эластика частенько забивается. Особенно если запускать поиски на большие периоды. А ещё я использую Grafana для графиков, а она не умеет отменять запросы. И если несколько раз тыкнуть refresh на графиге — генерятся тысячи запросов (хоть и не сложных).
3. В том что модификации внутри сессии веб-морды происходят постоянно => индекс будет распухать непонятно ради чего.
rudenkovk
1. Опять же — а смысл? При приличном потоке евентов память забьется моментально. А если эвентов мало, то и syslog достаточно. Хотя каждый городит свой огород. В моем понимании — это скорее минус. Прием который может привести к неявной деградации системы или падению.
2. Может просто перейти на syslog+grep? Я не троллю, просто не вижу смысла использовать подобные системы не имея для них железа.
3. ЭЭЭЭЭ… и? Я не понимаю то же тут проблемы. настроить чистку индекса не проблема от слова вообще. Я пользуюсь кибаной, и даже в объемных конфигурациях ее метаданные больше пары мегабайт не весили. Если что-то там так пухнет, такую систему надо на помойку.
А если хранить в монго — это лишняя память на сервис, лишние IO на перечитывание данных, это свои очереди, а не эластика.
hc4
1. Журнал хранится на диске. В грейлоге данные поступают в Input (которых может быть много и они плагины), оттуда в Process, либо в Journal, если очередь Process занята.
2. Syslog+grep вообще не пойму зачем. Я собираю логи с кучи хостов (на винде и лине) + с роутеров по SNMP.
3. ES предназначен для хранения огромных объёмов данных с возможность быстрого поиска. Mongo — быстрая in-memory база. По моему логично под каждую задачу использовать подходящий инструмент. Kibana использует ES думаю только для продвижения своей платформы.
rudenkovk
Угу, я понял. Комментариев больше не имею. Мы говорим о слишком разных объемах данных, стабильности и удобстве. :)
hc4
У вас «150k event/sec на 4 головы ES + 1 голова только на http» и syslog+grep удобнее? Или я что-то не так понял?
У меня действительно нагрузка поменьше — 3k/sec и одна нода ES.
rudenkovk
не так поняли :)
если мало логов, то и грепа достаточно. Если много, то зачем городить непонятные огороды.
hc4
Очень удобно, когда все логи с машин в одном месте.
Легче находить корреляции при анализе, можно строить дашборды, алерты, управлять доступом к логам.
Если например стоит один сервер apache, то наверное толку не оч много.
А если надо обслуживать несколько взаимодействующих между собой программ, разбросанных по разным хостам — то я не представляю жизни без грейлога.
rudenkovk
Я о том и говорю. Но только с моей точки зрения, использование двух сторов для этой цели — вещь избыточная, а значит костыльная и не стабильная.
hc4
Так mongo стоит только рядом с грейлогом, так же как и его журнал.
И оба они используются исключительно для внутренних нужд грейлога.
ES'же — это распределённое хранилище логов, которым может пользоваться не только сам graylog.
Я например графики строю при помощи Grafana напрямую по данным из ES, а грейлог использую для наполнения ES, анализа логов и алертов.
А ещё у меня ganglia для сбора реалтайм статистики, которая пишет в rrd, к которому имеет доступ graphite, через который Grafana может получать статистические данные и отображать их на одном графике с данными из ES :)
и как не странно — всё работает как часы.
rudenkovk
Я еще раз повторюсь: не понимаю ЗАЧЕМ нужна еще одна точка отказа. ELK прекрасно все хранит в ES и проблем нет, от слова вообще.
У меня схема другая, у меня ELK + Influxdb + grafana. Logstas, еще до ES считает нужные метрики по логам, и кидает эти метрики в influx. RRD мне не удобен, так как бывают нужны детализированные данные. Частично kibana и grafana перекрывают друг друга по визуализации, но это скорее взаимодополнение.
hc4
Думаю на вопрос ЗАЧЕМ могут ответить только сами разработчики :)
С моей точки зрения mongo больше подходит для хранения небольшого количества часто меняющихся данных.
А ещё у них в доке написано, что планируется сделать возможность использовать любое хранилище вместо mongo.
rudenkovk
Ну вот мы друг друга и поняли. :)
Для меня, если нет альтернатив, монго лучше вообще не использовать. Все же graylog догоняющий, от от ELK отстает сильно.
hc4
Кстати мы относительно недавно озадачились системой сбора логов (около полугода назад)
И при выборе пробовали в том числе Kibana.
Но graylog понравился больше, хоть он и догоняющий.
rudenkovk
У kibana порог вхождения повыше, на сколько я понял по документации graylog. Но она гораздо гибче.
Во-первых ELK у нас исторически.
Во-вторых он используется для визуализации данных не только для саппорта, разрабов или девопсов, но и PM и прочих бизнес-аналитиков.
hc4
В Kibana можно дать доступ только к части логов?
В graylog мы роутим эвенты в разные стримы и доступ даём только к конкретным стримам.
rudenkovk
Мы не заморачивались с этой темой, но думаю можно. Так как каждый лог пишется в свой индекс (это очень условно, просто долго расписывать иначе).
А дальше преднастроенные дашборды.
nucleusv
Graylog позволяет парсить и обогащать данные по условиям. Logstash тоже умеет и в последних версиях logstash в этом вопросе улучшили. Но в grayloge это удобней. Graylog прекрасно скейлится, ставите перед ним haproxy например и будет вам счастье. Самое не приятное в graylog — пишет ВСЕ сообщения только в «один» индекс, нельзя роутить собщения в разные индексы, надеюсь в следующих версиях поправят.
nucleusv
Основная причина — в ELK нет аунтификации без Shield. Поэтому и используется база с разграничением прав доступа.
chesterfie1d
Пол года назад ставил Graylog2. Необходимость была хранить логи с прод серверов глубиной до года, и иметь возможность посмотреть логи за определенный период. Но столкнулся с проблемой хранения. Логи сыпались 1.5к-2к/s, каждый индекс Elastic'a имел лимит 5гб. В неделю забивилось около 18 индексов по 5 гигов каждый итого ~90 гигов. В настройках ES можно настроить сколько индексов держать(старые закрываются и удаляются). Если увеличивать кол-во индексов, то поиск происходит дольше. Штатного инструмента по архивации старых индексов насколько я помню не было. Были некоторые самописные скрипты(http://tech.superhappykittymeow.com/?p=296), которые закрывали индексы и мувили их из ES допустим в /backup. В случае необходимости просмотра этих индексов, приходилось мувить их в хранилище ES и строить переиндексацию. Для долгосрочного хранения Graylog2 увы не подошел, из-за нехватки штатных инструментов. Возможно сейчас что изменилось?
hc4
Изменилось.
Теперь они используют elastic 2, в котором значительно улучшена работа doc_value индексов.
doc_value — это такой индекс, которым можно пользоваться не загружая его в память.
У меня на старом грейлоге хранилось порядка 1млрд сообщений в эластике (около 50 индексов) и любой запрос выполнялся десятки секунд минимум. Теперь же при наличии >2млрд сообщение и более 60 индексов графики строятся за секунды. При этом железо не менялось.
Ну и кроме того очень сильно улучшена вебка + теперь графики это тоже плагины + pipeline для обработки сообщений
tubecleaner
Надо добавить, что эти возможности появились в версии 2.0, которая зарелизилась в конце апреля. Архивация индексов появилась в ней, но как «коммерческая» функция.
hc4
Можете попробовать WinLogBeat + BeatsInput
semaev
Спасибо, ошибся с хранением, поправил. Про новую архитектуру читаю сейчас. Фишка нового graylog как раз в том, что он использует не collector, а sidecar для windows: https://www.graylog.org/blog/55-announcing-graylog-v2-0-ga и у меня все логи хорошо читаются
hc4
Sidecar же просто удобняшка для настройки collector через web-интерфейс грейлога, не?