
А что если я скажу вам, что новый продукт можно сразу начинать писать на микросервисной архитектуре, а не заниматься распилом монолита? Это вообще нормально? Удобно? Хотите узнать ответ?
Задача: необходимо написать за выходные (время ограниченно 10-15 часами) сферический блог на микросервисах, на php, не используя никаких фреймворков. Можно пользоваться здравым смыслом. А еще забудем о том что такое фронтенд и вспомним что мы жить не можем без виртуализации. Выберем Docker. Интересно? Вперед под кат.
Микросервисы
Если вам интересен микросервисный подход, но вы не знаете с чего начать, начните с книги "Building Microservices" Сэма Ньюмена. Постараюсь немного описать основные моменты данного подхода, если у вас будут какие-то дополнения, пишите пожалуйста в комментариях. И вообще по любому поводу пишите, я не претендую на истинность какого-либо из описанных ниже подходов, особенно в Вашем конкретном случае.
Будем рассматривать все на примере вышеупомянутого блога. Безусловно, это задача ради задачи, но хочется отметить что даже в таком варианте, это работать будет и будет работать неплохо (быстро и без проблем).
Суть микросервисов легко понять в сравнении с монолитной архитектурой. Как у нас выглядит обычный движок для блога? Грубо говоря это просто одно приложение. Работа с статьями, комментариями, страницами, пользователями и прочими функциональными единицами заключена в едином пакете исходного кода, который не делится никак.
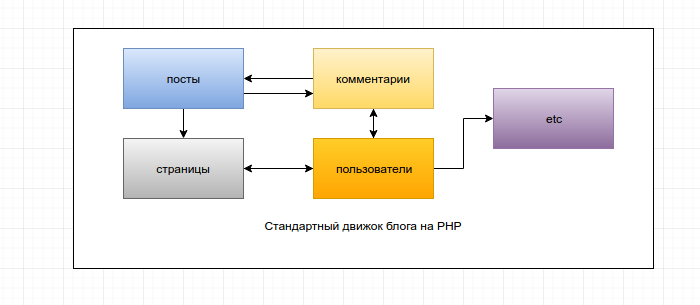
Где все связи между компонентами — это вызовы внутри кода, какие-то отношения между классами, паттерны и т.п. или даже просто говнокод, если нельзя отделить одно от другого.
Как будет выглядеть наш блог? Да примерно также, если честно.
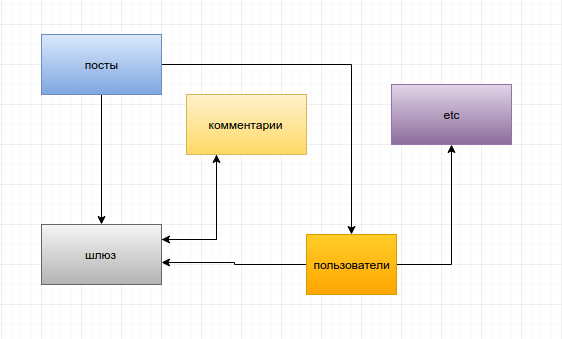
Единственное отличие, что квадратики с компонентами — это больше не компоненты заключенные в код одного приложения, а стрелочки — это больше не системные вызовы классов внутри этого кода. Теперь — это отдельные компоненты, а стрелочки — обычные запросы по http.
Зачем это нужно? Сразу определимся, что наверное, это нужно не всем. Это должно быть очень удобно, если вы — достаточно крупная компания, способная выделить по команде разработки на каждый сервис. Думаю, даже средним компаниям, если выделить по человеку на каждый сервис будет тоже неплохо. Впрочем, даже если ты один на всю компанию, ты сможешь найти в микросервисах что-то интересное.
Насколько большим должен быть сервис? Границы провести сложно, ошибка будет стоить вам дорого, но, если вкратце, то сервис это некая единица вашей системы, которую вы можете полностью переписать за короткое время. Эмпирически пусть за неделю вы или ваша команда должны справится с сервисом. Основная идея тут — сервисы должны быть небольшие. Они не должны превращаться в кучу монолитов.
Итак, позитивные вещи, которые я смог выделить для себя, в целом все они проходят под одним трендом: Невероятное удобство для разработки:
- Отказоустойчивость. Так как связи между сервисами больше не жесткие, сервис может умереть по чьей-то глупости (например сервис комментариев), но в целом на блоге это не скажется никак, кроме того что пропадут комментарии.
- Язык. Вы можете разработывать новый сервис на чем угодно. В общем выбор языка перестает напоминать поиск серебряной пули, для каждого компонента системы вы можете выбрать тот инструмент, который ей подходит больше всего в текущий момент времени. Почему? Потому что это больше не дорого для компании (сервис маленький), вы всегда можете выкатить старый сервис назад, вы даже можете использовать одновременно одинаковые сервисы написанные на разных языках, чтобы понять, что лучше. Цена ошибки неизмеримо меньше.
- Маштабируемость. Приложение тормозит и не справляется? Нужен новый огромный сервер для всего приложения, а лучше 10? Забудьте. Теперь вы можете масштабировать сервисы. Просто добавьте побольше сервисов :)
- В целом высокая скорость работы, как результат всего что выше.
Что должно уметь наше приложение? Так то не очень много.
Четыре страницы:
- Список постов
- Открытый пост с комментариями
- Добавление поста
- Авторизация
Функционал простой:
- Авторизованный пользователь может добавить пост
- Кто угодно может его комментировать.
Docker

Все, не будем больше о теории, давайте пилить приложение. Оно у нас будет на докере. Настолько распределенное приложение разрабатывать на одной машине без виртуализации почти невозможно. Описание работы докера будет представлено обрывками, поскольку выходит за тему данной статьи. Предполагается, что вы о нем что-то знаете.
Кстати, вот ссылка на репу, из которой вы можете скачать и запустить блог, посмотреть что-то по коду ниже. https://github.com/gregory-vc/blog
Сколько будет контейнеров в нашем простейшем блоге? Контейнер, это кстати по сути виртуализация отдельного сервера, который общается по сети с другими контейнерами, правда если проводить жесткую аналогию контейнер=сервер, от некоторых контейнеров нужно будет отказаться, но тем не менее. Для простейшей реализации блога на микросервисах я насчитал 24 контейнера. Давайте посмотрим.
- Общие контейнеры: база для сервиса авторизации, основная база блога, редис.
- Сервис-шлюз: php, контейнер для исходного кода, nginx.
- Сервис для работы с постами: (php, контейнер для исходного кода, nginx) х 2
- Сервис для работы с комментариями: тоже х 2
- Сервис авторизации и аутентификации: тоже х 2
Зачем на по две копии некоторых сервисов? Потому что с одной будет не интересно и не понятно.
Файл docker-compose, который развернет все это одной командой выглядит вот так:
https://github.com/gregory-vc/blog/blob/master/host/docker-compose.yml
Из самого интересного рассмотрим настройки php контейнера нашего шлюза.
'php_gate':
image: 'tattoor/blog_php'
container_name: 'php_gate'
volumes_from: ['source_gate']
volumes: ['./logs/php/gate/:/var/log/dev_php']
links:
- nginx_post_1:post1.blog
- nginx_post_2:post2.blog
- nginx_comment_1:comment1.blog
- nginx_comment_2:comment2.blog
- nginx_auth_1:auth1.blog
- nginx_auth_2:auth2.blog
- redis
environment:
- POST_1_HOST=post1.blog
- POST_1_PORT=80
- POST_2_HOST=post2.blog
- POST_2_PORT=80
- COMMENT_1_HOST=comment1.blog
- COMMENT_1_PORT=80
- COMMENT_2_HOST=comment2.blog
- COMMENT_2_PORT=80
- AUTH_1_HOST=auth1.blog
- AUTH_1_PORT=80
- AUTH_2_HOST=auth2.blog
- AUTH_2_PORT=80Раздел описания контейнера links, это по сути просто редактирование /etc/hosts/
docker exec php_gate cat /etc/hosts
172.17.0.36 auth1.blog 86b8b266477d nginx_auth_1
172.17.0.36 nginx_auth_1 86b8b266477d
172.17.0.21 comment1.blog 836bacb42e78 nginx_comment_1
172.17.0.19 comment2.blog c554a8888801 nginx_comment_2
172.17.0.20 post2.blog 37f81921419c nginx_post_2
172.17.0.7 redis a1932016be87
172.17.0.37 auth2.blog 5715045a213b nginx_auth_2
172.17.0.37 nginx_auth_2 5715045a213b
172.17.0.21 nginx_comment_1 836bacb42e78
172.17.0.19 nginx_comment_2 c554a8888801
172.17.0.22 nginx_post_1 1cc1ef5ab896
172.17.0.22 post1.blog 1cc1ef5ab896 nginx_post_1
172.17.0.20 nginx_post_2 37f81921419c
172.17.0.23 fafe93f31a67Где по обозначенному хосту мы просто имеем доступ к другому контейнеру через внутреннюю сеть докера.
А раздел environment — это просто обозначение переменных, которые мы сможем достать с вами внутри приложения через getenv(). Сделано так, чтобы файл docker-compose был единой точкой входа для настройки всего приложения.
В то время как структура наших сервисов выглядит как просто директории лежащие рядом,
- Auth
- Comment
- Gate
- Post
Но, на самом деле, при запуске докера хостов, каждая из этих директорий оказывается внутри отдельного изолированного соответствующего контейнера. Делается это как-то так:
'source_post_1':
volumes: ['../Services/Post:/home/gregory/source/']То есть, хоть сейчас они и рядом, при запуске не будет возможности из одного сервиса проинклудить класс другого сервиса или что-то типа того. Рядом они исключительно из удобства, в реальной жизни они должны быть каждый в своем репозитории, вообще не касаясь друг друга.
Сервис Gate

Этот сервис будет являтся точкой входа на наш блог, именно он будет рендерить шаблоны, отображать результат и дергать нужные ему сервисы. Кстати существуют разные подходы, например можно отказаться от единой точки входа и реализовать все на фронтенде. То есть браузер сам будет ходить в нужные сервисы и собирать результат прямо в браузере. Что сказать, все зависит от вашего конкретного случая и там и там есть свои плюсы и минусы.
Итак, у нас есть php и больше ничего. Хотя, давайте возьмем хотя бы composer, куда без него. Создадим еще две директории, одну с нашим микрофреймворком, который мы сейчас напишем, вторую для public скриптов, js, и прочих ресурсов.
Выглядит так:
- My
- public
- composer.json
В composer просто укажем, откуда осуществлять autoload, чтобы нам самим с этим не заморачиваться, и подключим сгенеренный autoload в public/index.php
Так, что-то у нас уже есть, давайте определимся что нам вообще еще будет надо?
- MVC, а значит контроллеры
- Место для бизнес логики
- Шаблоны
- Шаблонизатор
Неплохо, что еще?
- Немного di, самый простой, ввиде хранилища объектов.
- Само хранилище
- Запрос
- Ответ
- Роутинг, о да, с него стоит начать.
- Сессии и прочее по мелочи.
Напишем вот такое хранилище объектов, чтобы не создавать их где попало, а иметь возможность получить доступ (inject) к уже созданным в любой точке приложения со всем нужными зависимостями (dependency). Мы не будем развлекаться с Reflection и прочими интересными штуками, время у нас жестко ограничено.
Storage::set('Request', new Request());
Storage::set('Router', new Router());
Storage::set('Redirect', new Redirect());
Storage::set('App', new App());В Di, используя это хранилище просто добавляем все объекты что нам нужны.
В паблике стартуем Di, получаем роутер, регистрируем все урлы что нам пригодятся, получаем приложение и стартуем его.
$router->get('/logout/', 'AuthController@logout');
$router->get('/404', 'SystemController@notFound');
$router->post('/post/add_request/', 'PostController@add')В приложении получаем request, маппим в роутере существующий экшен существующего контроллера по этому реквесту, одновременно еще записываем в request все пост или гет переменные, что нам пришли.
Выполняем метод контроллера, получаем response, рендерим response и показываем результат нашей работы, все.
$current_request = $this->router->getCurrent();
$controller = new $current_request->controller;
$response = $controller->{$current_request->method}();
$response->render();Каркас есть, теперь нам надо работать с сервисами, создаем директорию с сервисами, создаем класс каждого сервиса, описываем точки доступа к каждому из сервисов. Наследуем их от основного класса сервисов, где реализуем варианты запросов.
https://github.com/gregory-vc/blog/blob/master/Services/Gate/My/Engine/Service.php
static public function get($method, $params = [])
{
$service = new static;
return $service->executeGet($method, $params);
}
static public function post($method, $params = [])
{
$service = new static;
return $service->executePost($method, $params);
}Там внутри при запросе выбираем рандомны коннектор из предоставляемых сервисом, как-то так
$rand_connector = rand(0, $count_connector) % $count_connector;Делаем запрос, из контроллера и рендерим, вот так:
$posts = Post::get('all');
return $this->response->html('posts', $posts);Нам нужно отрендерить, но как? Шаблонизаторов у нас нет. Писать свой? Ну нет. Просто используем php.
ob_start();
require_once($layout_template);
$contents = ob_get_contents();
ob_end_clean();
$this->content = $contents;Черезвычайно мощный шаблонизатор размером с 4 строчки.
Сервис post и comment
Что дальше? Теперь мы можем делать запросы и рендерить результат, теперь нам нужно написать сервисы отдающие ответ. Все просто копируем наш новый движок в другие сервисы, меняем урлы и пишем работу с моделями и бд, вместо удаленных сервисов.
Реализуем работу с моделями, стандартно findAll, findBy, add, save:
https://github.com/gregory-vc/blog/blob/master/Services/Auth/My/Engine/Model.php
Итак? Если честно, это почти все, что нам нужно, не считая авторизации.
Мы можем делать запросы gate на любой сервис, с любого другого сервиса на любой другой.
Сервис авторизации
Схема проста: мы имеем юзеров и их доступы на сервере авторизации, мы делаем из шлюза запрос на авторизацию, генерируем токен, возвращаем его шлюзу и еще юзера, кладем юзера и токен в сессию и все. Незабываем посылать токен вместе с запросом на добавление поста, потому что что? Правильно, сервис постов пойдет в сервис авторизации и спросит, а правда ли что этот токен хорош? В зависимости от результата генерим разные эксепшены.
public function login($user, $password) {
$hash = hash('sha256', $password);
$user = User::findBy([
'login' => $user,
'password' => $hash
]);
if (!empty($user) && is_array($user)) {
$user = current($user);
$user['token'] = bin2hex(random_bytes(30));
User::save($user);
return [
'login' => $user['login'],
'token' => $user['token']
];
} else {
throw new \Exception('Not found user');
}
}Результат
Вообще, можете скачать и развернуть его одной командой, напомню репозиторий: https://github.com/gregory-vc/blog
Где подходило по смыслу — я вывел для наглядности какой именно нодой был сгенерен тот или иной блок.
Еще меня впечатлило время генерации странички. Это 5-9 мс для странички с постом и несколькими комментариями (!). Да, все это необъективно, да, все это попугаи, да, микросервисы тут не при чем, да, смотря с чем сравнивать. Но. Тот же ларавель генерит свою страничку, вообще без запросов и данных, просто приветствие, за 90 мс, на моей же машине. Это в 10-20 раз дольше.
Я понимаю, что там происходит куда больше всего, не сравнить, но тем не менее, попытаюсь выразить мысль: для конкретно текущей задачи отдельного изолированного микросервиса всего этого и не надо. Для сервиса комментов я выкинул класс работы с сервисами по сети. Для сервиса шлюза я выкинул класс работы с базой. Для каждого конретного сервиса я собрал лишь то, что ему надо. А правильном сервису надо совсем чуть-чуть :)
А главное это невероятный потенциал для масштабирования этого блога под просто невероятные нагрузки. Никто не помешает например потом взять и переписать сервис комментариев на Go.
Проблемы
Сетевые накладные расходы
Не зная о том как работает другой сервис, мы можем вполне попасть в ситуацию, когда, он не то что работает плохо, и портит нам все, он еще и использует наш сервис (!) чтобы нам же отдать наши результаты.
Напомню как все это попробовать
Clone
git clone https://github.com/gregory-vc/blog.git .
Install Docker:
wget -qO- https://get.docker.com/ | sh
sudo usermod -aG docker user
sudo apt-get install python-pip
sudo pip install docker-compose
Compile
chmod 744 compile
./compile
chmod 744 upload_db
./upload_db
Run
http://gate.blog:30001/
admin
adminКомментарии (80)

yvm
07.06.2016 23:24+1Не уверен, но по моему RUN лучше однострочным делать, используя && и \

tattoor
07.06.2016 23:40Вообще да, вы правы, чем меньше слоев, тем лучше. Но пока их меньше 120 с чем-то, особых проблем не будет :)

Fesor
07.06.2016 23:40Именно так, таким образом мы создаем меньше промежуточных слоев и размер образа становится чуточку меньше.
Точно так же весьма спорная штука — контейнер для исходников. К сожалению есть масса проблем с этим. Выражаются эти проблемы в том, что при пересоздании контейнера с исходниками на хосте ничего не поменяется и наши контейнеры с php будут использовать старые исходники.
Я предпочита просто хранить исходники прямо в PHP контейнере.
tattoor
07.06.2016 23:44Не так и сложно пересоздать все зависимые контейнеры. А насчёт плюсов такого подхода… наверное все в угоду парадигме «Один сервис — один контейнер»
VolCh
11.06.2016 23:27Там проблемы с volumes всплывают, они заполняются только при создании тома, при пересоздании — нет. А использовать
(удалять и тома, а не только контейнеры и сети) — будут удаляться тома персистентных хранилищ (субд, редис и т. п.)docker-compose down --volumes
amaksr
07.06.2016 23:43+17В моей компании тоже все на микросервисах, только счастья это не приносит:
если ищу причину какого-то бага, то в большинстве случаев где-то по ходу анализа исходника приложения натыкаешься на вызов очередного endpoint-а, приходится скачивать его исходники тоже, а там опять endpoint куда-то еще, и т.д. О локальном дебаге речь вообще даже не поднимается, так как слишком много приложений-микросервисов придется локально конфигурировать. В итоге баги ищутся, в основном, путем смотрения на код.
микросервисы, как правильно заметил автор, зачастую написаны на разных версиях разных языков, что делает локальный дебаг трудным или невозможным
особенно странно видеть, как зоопарк микросервисов на разных версиях разных языков оперирует с одними и теми же логическими связанными данными. Я, конечно, понимаю, что хотели делать масштабируемо, но на уровне данных все SQL-запросы в итоге идут к одним и тем же базам данных, от чего БД становятся узким местом. Но отмасштабировать БД, как правило, намного труднее.
иногда базы данных пытаются сделать масштабируемыми путем разбиения на логически независимые базы. Микросервисы тогда зависимы только от своей БД, и чувствуют себя отлично, но при этом возникает необходимость в процессах копирования данных между БД, синхронизация, ETL и все такое, что тоже немалый источник хлопот.
при необходимости внесения изменений в микросервис в большой компании зачастую представляет проблему выявить и, тем более, протестировать, все приложения-юзеры, его использующие. Поэтому часто всместо внесения изменений в существующий микросервис, просто создается очередной модифицированный клон, который делает почти то же самое. В итоге подход, призванный снизить избыточность кода, дает ровно обратный эффект.
микросервисы, когда вызывают другие микросервисы по HTTP, работают существенно медленнее, чем если бы тот же код исполнялся из одного процесса, что часто приводит к необходимости все переделывать без микросервисов
- если любой из нужных микросервисов недоступен, то как правило пользоватетель получает не частично, а полностью неработающее приложение. Это из области мифив, что приложением можно будет пользоваться, но с ограниченниями. Я таких приложений не видел.
В общем идея микросервисов красиво выглядит на презентациях и в книжках. В реальной жизни лучше сто раз подумать, а надо ли.
Fesor
08.06.2016 00:07+3но при этом возникает необходимость в процессах копирования данных между БД, синхронизация, ETL и все такое, что тоже немалый источник хлопот.
Это не особо большая проблема, на самом деле. В целом если у вас выходит так что одни и те же данные хранятся в рамках разных микросервисов, возможно границы разделены неверно? Так же можно организовать CQRS и по изменению данных отправлять в очередь событие на перестройку read model всех сервисов (а сервисы уже сами все разрулят).
В итоге подход, призванный снизить избыточность кода, дает ровно обратный эффект.
микросервисы призваны раздробить систему. А проблема с сохранением обратной совместимости частично решается версионизацией API. Ну и опять же, если нужно много поменять на самом деле проще рядом завести еще один микросервис, хотя как по мне это скорее должно быть редким решением.
работают существенно медленнее, чем если бы тот же код исполнялся из одного процесса
что собственно более чем логично, но никто вам не мешает переделать транспорт на что-то более эффективное.
если любой из нужных микросервисов недоступен
single point of failure это называется. Это проблема не микросервисов а конкретной реализации. Критически важные вещи должны дублироваться.
В реальной жизни лучше сто раз подумать, а надо ли.
А вот тут соглашусь полностью. Далеко не у всех над одним проектом будет трудиться пара десятков разработчиков что бы была необходимость дробить систему. Но в целом подход с микросервисами очень даже хорошо подходит для реально больших проектов.amaksr
08.06.2016 00:52+1А вот тут соглашусь полностью. Далеко не у всех над одним проектом будет трудиться пара десятков разработчиков что бы была необходимость дробить систему.
Жизнь проекта разработкой не ограничивается. Потом начинается саппорт и мелкие доделки силами саппорта. У нас, например, в саппорте примерно человек 5, а количество микросервисов я даже не знаю сколько, думаю за сотню. И когда расследуешь баг, то не получается просто проследить всю последовательность вызовов до операций с БД, а приходится переключаться между разными частями раздробленной системы. Это замедляет расследование багов во много раз. Получается, сэкономили на разработке, но потеряли на саппорте.Fesor
08.06.2016 01:27Почти все продукты, которые используют микросервисы, подразумевают что работа над ними будет продолжаться довольно продолжительное время. А вот ситуации когда продукт переходит в суппорт и над ним трудятся всего 5 человек не означают что проект прекратил развитие?
amaksr
08.06.2016 03:47+1Это продукт для внутреннего пользования, его разработали, внедрили, и теперь им все пользуются. "Развитие" происходит только если какие-то бизнес-юзеры требуют новый функционал. В этом случае подключается отдельный девелоперский отдел и ведет всю разработку. Разработчики и бизнес-аналитики, кстати, все по уму делают: рисуют модели бизнес процессов, описывают сущности, генерируют структуры данных и WSDL-интерфейсы, кодят, в общем все по книжке. Но почему-то когда есть выбор пойти в БД напрямую, или через микросервис, они всегда выбирают микросервис. В результате получается ад микросервисов, в котором среднее время расследования бага во много раз больше, чем в просто большом приложении.

MuLLtiQ
08.06.2016 02:42+10Знаем, проходили. Все что вы описали — классический «distributed monolith» и о микросервисах тут речи не идет.
если ищу причину какого-то бага, то в большинстве случаев где-то по ходу анализа исходника приложения натыкаешься на вызов очередного endpoint-а, приходится скачивать его исходники тоже, а там опять endpoint куда-то еще, и т.д. О локальном дебаге речь вообще даже не поднимается, так как слишком много приложений-микросервисов придется локально конфигурировать. В итоге баги ищутся, в основном, путем смотрения на код.
Тут налицо сильная связность и неполное разделение ответственности. Сервис должен быть изолированным, дабы была возможность отлаживать его не устанавливая весь остальной landscape.
микросервисы, как правильно заметил автор, зачастую написаны на разных версиях разных языков, что делает локальный дебаг трудным или невозможным
Бывает, что поделать. Docker в помощь
особенно странно видеть, как зоопарк микросервисов на разных версиях разных языков оперирует с одними и теми же логическими связанными данными. Я, конечно, понимаю, что хотели делать масштабируемо, но на уровне данных все SQL-запросы в итоге идут к одним и тем же базам данных, от чего БД становятся узким местом. Но отмасштабировать БД, как правило, намного труднее.
У каждого сервиса — свое хранилище, общих БД должно быть по минимуму
иногда базы данных пытаются сделать масштабируемыми путем разбиения на логически независимые базы. Микросервисы тогда зависимы только от своей БД, и чувствуют себя отлично, но при этом возникает необходимость в процессах копирования данных между БД, синхронизация, ETL и все такое, что тоже немалый источник хлопот.
Опять же — неправильное разделение ответственности между сервисами. Плюс приложения в такой архитектуре обычно проектируют с учетом толерантности к eventual consistency и не самым свежим данным.
при необходимости внесения изменений в микросервис в большой компании зачастую представляет проблему выявить и, тем более, протестировать, все приложения-юзеры, его использующие. Поэтому часто всместо внесения изменений в существующий микросервис, просто создается очередной модифицированный клон, который делает почти то же самое. В итоге подход, призванный снизить избыточность кода, дает ровно обратный эффект.
Если вам требуется внести изменения в микросервис да так что при этом отвалятся все клиенты (т.е. никакой обратной совместимости) — то налицо проблема в проектировании API, а конкретно — в версировании. Обновление одного сервиса не должно каскадно вызывать одновременное обновление еще кучи других от него зависящих.
микросервисы, когда вызывают другие микросервисы по HTTP, работают существенно медленнее, чем если бы тот же код исполнялся из одного процесса, что часто приводит к необходимости все переделывать без микросервисов
Не обязательно использовать HTTP, или вообще решить проблему изменив deployment (например развернуть сервисы в одном сегменте сети или вообще на одних машинах) вместо переписывания кода.
если любой из нужных микросервисов недоступен, то как правило пользоватетель получает не частично, а полностью неработающее приложение. Это из области мифив, что приложением можно будет пользоваться, но с ограниченниями. Я таких приложений не видел.
Обычно это работает на уровен фич. Простой пример — оплата. Если сервис обслуживающий PayPal упал, то Яндекс.Деньги например все еще могут работать. Или блок комментариев к статье — если сервис, обслуживающий комментарии лежит, то это не значит что статья не должна отображаться. Терпимость к ошибкам должны быть заложена в архитектуре.
Вообще лучший подход — это представить что ваш микросервис — абсолютно самостоятельный продукт и должен работать независимо от всех остальных частей приложения.
defcon
08.06.2016 10:15+1плюс пять копеек к тому, что лучше 100 раз подумать. надо ли — микросервисы — это по разспределенная система с сервисами, которые имеют тенденцию отвалится чаще, чем если бы бежали в рамках одного процесса. Дизайнить такую систему в разы сложнее, дороже и дольше, чем обычный монолит, а плюсы от микросервисов не всегда уж такие очевидные.
oxidmod
08.06.2016 10:23кстати, монолит с нормальным DI и лейзи инициализацией вполне норм масштабируется.

velvetcat
12.06.2016 10:16Разработка монолита нормально не масштабируется, вот в чем весь прикол микросервисов.
oxidmod
12.06.2016 12:39разработка то почему не масштабируется? Всеравно в монолите есть некие подсистемы отдельные. у этих подсистем есть публичный интерфейс. Проблемы только когда меняется интерфейс надо лезть в другие места исправлять. Но это все решаемо. В конце концов, если меняется интерфейс микросервисов, то все равно нужно лезть по пользователям сервиса и переключать на другую версию АПИ.
VolCh
12.06.2016 13:25Как минимум потому что, даже если связанность модулей в монолите по факту нулевая (что большая редкость), то всё равно при любом изменении нужно проводить полный набор тестов, потому что сейчас она нулевая, а какой-то коммит может сделать её ненулевой. А полный набор тестов на большой системе — это долго и дорого. Да и тупо IDE может тормозить на больших проектах.
oxidmod
12.06.2016 13:41внезапно тесты на взаимодействие между микросервисами тоже нужно проводить. Да и вообще тестировать все нужно всегда.
внезапно, говно-коммиты не проходят код-ревью. и внезапно же, говнокоммиты могут быть и в микросервисах.
стоимость и длительность тестов косвенно указывает на качество кода. В случае микросервисов тестов будет даже больше, ведь нужно тестировать и взаимодействие микросервисов между собой.
в IDE можно исключить из индексации ненужные модули. Но, как мне кажется, стоимость нормальной железки для программиста не должна влиять на архитектуру приложения. Связность в монолите можно контролировать. Собственно и микросервисы могут быть сильно связными. и если вы не можете сделать нормальный монолит, то до микросервисов вы еще не доросли. не имею ввиду именно Вас, говорю в общем.Fesor
12.06.2016 16:05внезапно тесты на взаимодействие между микросервисами тоже нужно проводить
Да. интеграционные и end-to-end тесты нужно проводить. Но это не сложно и на это можно хоть отдельную команду QA выделить. Но эти тесты будут выявлять именно баги при интеграции микросервисов, то есть ошибки взаимодействия в одном микросервисе, как он формирует запросы.
То есть в принципе те же проблемы и для монолита, но их решать чуть сложнее поскольку при увеличении числа разработчиков будет увеличиваться энтропия. Когда у вас много маленьких команд — этим управлять удобнее и контролировать процесс так же удобно. При том что далеко не все команды будут взаимодействовать между собой.
Я занимаюсь разработкой API для мобильных приложений и у меня эти же проблемы (обратная совместимость, отсутствие контроля за клиентами) и эти же задачи встают чуть ли не каждый день и они решаемы.
Но, как мне кажется, стоимость нормальной железки для программиста не должна влиять на архитектуру приложения.
У меня на одном проектике из-за ошибки проектирования есть один микросервис, который потребляет 140 гигов оперативки. Ну это я так, к вопросу стоимости железок.
Связность в монолите можно контролировать. Собственно и микросервисы могут быть сильно связными.
Можно контролировать. Точно так же как и в случае микросервисов. То есть в случае монолита подавляющее большинство забивают болт. А в случае микросервисов это "забиваение болтов" ооочень быстро приведет к проблемам и они всплывут весьма рано.
и если вы не можете сделать нормальный монолит, то до микросервисов вы еще не доросли.
в точку. Вот только в случае микросервисов количество людей которые могут сделать нормальный монолит может быть значительно меньше чем в случае собственно монолита. Проще вводить новых людей, проще менять команды. Именно это подразумевается под "масштабированием".
Ну а если у нас большая команда людей, не способных написать монолит, да, профита от микросервисов мы тем более не получим. Разве что быстрее придем к тому что нужно нанимать кого-то более компетентного.
velvetcat
12.06.2016 13:45+2> разработка то почему не масштабируется?
Ну там мифический человеко-месяц, все такое…
> Всеравно в монолите есть некие подсистемы отдельные. у этих подсистем есть публичный интерфейс.
Это у Вас очень крутой монолит, представляющий собой набор независимых сервисов, работающих в одном адресном пространстве :) Я бы предпочел работать именно с таким «монолитом», нежели с «микросервисами», сидящих поверх одной реляционной БД.
Обычно под монолитом понимают приложение, концептуально представляющее собой некое глобальное состояние + кучу методов для его изменения.Fesor
12.06.2016 16:06нежели с «микросервисами», сидящих поверх одной реляционной БД.
Я принципиально не хочу называть такую архитектуру микросервисами. Это ближе к ESB нежели к микросервисам. Высокая связанность от одной зависимости.
meln1k
08.06.2016 12:13+2если любой из нужных микросервисов недоступен, то как правило пользоватетель получает не частично, а полностью неработающее приложение. Это из области мифив, что приложением можно будет пользоваться, но с ограниченниями. Я таких приложений не видел.
У вас не микросервисы, а просто распределенный монолит. Общение между микросервисами должно происходить полностью асинхронно, через какую-нибудь кафку например. Это решит проблему продолжения работы всего приложения при одном умершем сервисе. Он просто обработает данные из кафки позже, когда восстановится, а остальные этого даже и не заметят.amaksr
08.06.2016 18:12При асинхронном общении между сервисами приходится еще что-то выдумывать, чтобы помечать состояния сущностей, которые находятся в обработке и ожидают ответа какого-то микросервиса — ведь юзерам надо показать, что его действие уже исполняется, чтобы он еще раз Submit не нажимал. А если еще надо обработать асинхронный ответ какого-то микросервиса — то вот уже и в нашем микросервисе надо заводить еще один endpoint (ну или subscriber), который будет это событие слушать. И где здесь простота и элегантность? А как в этом ловить баги, или дебажить локально?
Но вообще-то, говоря о полностью неработающем приложении я имел в виду тот факт, что любая ошибка в нужных сервисах не даст пользователю возможности сделать то, что он хотел. Ему, по большому счету, без разницы, видит он ошибку 500, или красивую надпись "сервис ХХХ недоступен". В обоих случаях это будет тикет в саппорт. Пример блога с неработающим сервисом комментариев от реальной жизни несколько оторван.
У нас, кстати, есть MQ (Websphere), иногда приходится дебажить и там тоже, и это еще больше усложняет саппорт. Но видимо совсем без MQ не получится, т.к. много разнородных систем.
meln1k
08.06.2016 18:51+1Идея в том, чтобы сервису для отдачи данных пользователю не нужно ползти в другие сервисы и что-то там дергать. Сервис просто сидит и ждет апдейтов которые приходят через шину от других. Это сильно уменьшит зависимости между сервисами, что позволит сосредоточиться на обеспечении доступности user-facing сервисов, и меньше думать про сервисы которые работают в фоне.
amaksr
08.06.2016 19:34Сервисы бывают разные. Приведу пример расследования бага из недавнего...
Внешний пользователь на лендинг-странице не может ввести свою информацию — системе не нравится его емайл. Иду в приложение лендинг-страницы. Вижу, что приложение проверяет инфу, введенную пользователем, путем вызова микросервиса, в котором хранятся все внешние потенциальные клиенты. Скачиваю исходники этого микросервиса. Вижу, что емайл он проверяет вызовом еще одного микросервиса проверки емайлов. Скачиваю его исходники тоже. Вижу, что там у нас вообще-то есть приложение, которое используется отделом маркетинга, где они в числе прочего ведут небольшую базу правил для емайлов, чтобы иметь возможнось делать черные/белоые/серые списки. Вижу, что для емайла определяется список, и если это серый список, то наш микросервис вызывает микросервис проверки емайлов из сторонней компании, которая проверяет емайл уже путем коннекта по SMTP и отправки всяких там HELO заголовков, но без отправки письма.
Все красиво и логично, не прикопаться. Но на поиски бага ушел день с лишним, так как всю эту архитектуру пришлось постигать самостоятельно. В моем случае была ошибка в базе правил черных/белых/серых списков.
oxidmod
08.06.2016 19:59+2у вас явный затык в архитектуре.
1. путем вызова микросервиса, в котором хранятся все внешние потенциальные клиенты. задача микосервиса хранить клиентов или валидировать мейлы?
2. Вижу, что емайл он проверяет вызовом еще одного микросервиса проверки емайлов.
вот, оказывается для проверки мейлов естьсервис, но вы к нему не обращаетесь почемуто
3. Скачиваю его исходники тоже. Вижу, что там у нас вообще-то есть приложение, которое используется отделом маркетинга, где они в числе прочего ведут небольшую базу правил для емайлов, чтобы иметь возможнось делать черные/белоые/серые списки.
это списки дял маркетинга, они сортируют клиентов для своих нужд? почему тогда их списки используются для валидации?
зы. естесвенно без понимания вашего приложения это лишь догадки.amaksr
09.06.2016 17:15у вас явный затык в архитектуре.
А мне кажется наоборот, архитектура очень даже продуманная, вполне годится для презентаций по микросервисам.
задача микосервиса хранить клиентов или валидировать мейлы?
Задача — хранить информацию обо всех внешних пользователях, которые еще не стал клиентами, но которые каким-то образом к нам обращались и у нас есть о них какая-то, как правило частичная, информация: кто-то заполнил форму на лендинге, кто-то оставил контакты на промо-акции, кто-то позвонил, и т.п. В виде сервиса (слово «микро» тут не очень подходит) сделано потому, что им пользуемся не только мы, но и наши дилеры партнеры. Они могут сделать свой промоушен, лендинг, рассылку и т.п, но данные в итоге поступают в наш сервис. По-моему очень даже умно придумано.
вот, оказывается для проверки мейлов естьсервис, но вы к нему не обращаетесь почемуто
Да, в самом лендинг приложении мы ничего не делаем, потому что задача состоит еще и в том, чтобы по неполной информации попытаться определить есть ли у нас этот клиент в базе, и если да, то не создавать клона. Отдел маркетинга, кроме прочего, ведет базу правил для нечетких совпадений, и это все для того, чтобы не плодить копии и не раздражать одного и того же клиента по разным каналам. Понятно, что лучше всю эту логику сделать в одном месте, а не кодить по новой для каждого нового лендинга.
это списки дял маркетинга
Это списки правил валидации емайлов, которым пользуется сервис валидации емайлов. Сами емайлы у них тоже есть, но в других базах/приложениях.oxidmod
09.06.2016 17:53+2>> Задача — хранить информацию обо всех внешних пользователях, которые еще не стал клиентами, но которые каким-то образом к нам обращались и у нас есть о них какая-то, как правило частичная, информация: кто-то заполнил форму на лендинге, кто-то оставил контакты на промо-акции, кто-то позвонил, и т.п. В виде сервиса (слово «микро» тут не очень подходит) сделано потому, что им пользуемся не только мы, но и наши дилеры партнеры. Они могут сделать свой промоушен, лендинг, рассылку и т.п, но данные в итоге поступают в наш сервис. По-моему очень даже умно придумано.
тогда почему у этого сервиса есть ендпойнты для валидации мейла? имхо, логичней чтобы был сервис валидации мейлов, который принимает решение валидный мейл или нет на основании различных данных. чтото типа такого алгоритма:
1. проверяем мейл, что он валидный с точки зрения стандарта.
2. дальше запрашиваем у сервиса с потенциальынми клиентами, а не обращался ли к нам ктото с таким мейлом по какимто каналам.
3. дальше запрашиваем в какую категорию попадает мейл с точки зрения правил которые ведут маркетологи
4. Если есть сомнения (серый список), запрашиваем у стороннего сервиса валидации
5.…
6. PROFIT
какие плюсы:
— сервис делает одну четкую вещь и дает отет да/нет
— сервис постепенно использует все возможные способы проверки мейла
— вам не нужно перебирать мотор через выхлопную трубу
зы. идея микросервисов как раз в том, что они микро. они делают одну простую вещь.
ззы. запросы в пунктах 2 и 3 это запросы к другим микросервисам вашей системыoxidmod
09.06.2016 17:59зззы. опционально можно исключить запросы к сервисам, с которых пришел запрос на валидацию. тобишь сервис хранящий партнеров неверняка спросит, а валидный ли это мейл перед тем как сделать новую запись, потому обращатсья к нему с впросом знает ли он такой мейл глупо. хотя ответ тогда всеравно будет что не знает, ведь запись еще не сделана.
но это уже детали реализации и небольшие оптимизации
amaksr
09.06.2016 18:17тогда почему у этого сервиса есть ендпойнты для валидации мейла
У него нет своих ендпоинтов для валидации емайла. Он вызывает отдельный микросервис если ему надо отвалидировать емайл. В микросервисе валидаций емайлов есть небольшая база с правилами валидации. В общем все разбито на независимые части, примерно так как вы и пишете. Только трудоемкость саппорта от этого получается слишком высока.oxidmod
09.06.2016 18:28+1тогда я не понимаю как так вышло, что ваш изначальный сервис полез валидировать мейл в сервис потенциальных клиентов… ладно, что переливать из пустого в порожнее. у каждого своя точка зрения. моя в том, что если авторы микросервисов придерживаются unix way, то проблем возникать не должно
0b1101
09.06.2016 09:54+2Если проект уже сдан и находится на поддержке, то почему у вас нет документации по взаимодействию микросервисов?
Если есть хотя бы простенькая диаграмма с описанием связей, то ваше расследование превращается в 10 минутный просмотр такой диаграммы и исправление бага.
Если такой диаграммы нет — по моему логично потратить неделю на её создание чем тратить каждый раз тратить день на поиск 1 простого бага.
VolCh
11.06.2016 23:49особенно странно видеть, как зоопарк микросервисов на разных версиях разных языков оперирует с одними и теми же логическими связанными данными. Я, конечно, понимаю, что хотели делать масштабируемо, но на уровне данных все SQL-запросы в итоге идут к одним и тем же базам данных, от чего БД становятся узким местом. Но отмасштабировать БД, как правило, намного труднее.
иногда базы данных пытаются сделать масштабируемыми путем разбиения на логически независимые базы. Микросервисы тогда зависимы только от своей БД, и чувствуют себя отлично, но при этом возникает необходимость в процессах копирования данных между БД, синхронизация, ETL и все такое, что тоже немалый источник хлопот.
Если принято решение делить базу между сервисами (большой плюс — простое обеспечение ссылочной целостности), то очень облегчает жизнь принцип «у каждой схемы/таблицы/столбца только один владелец, имеющий право INSERT/UPDATE/DELETE, остальные только SELECT» (лучше зафиксировать через права на уровне СУБД). Это позволит считать SELECT запросы лишь ещё одним дополнительным транспортом (на HTTP API мир клином не сошёлся) на query запросы к сервису-владельцу.
Если же у сервисов свои базы, то нужно очень стремиться копировать не данные, а только идентификаторы. На моей практике для операционной деятельности (включая оперативные отчёты) вполне достаточно когда одна (пускай даже денормализованная в целях оптимизации скорости/памяти) база выделяется под один сервис, оперирующий одной (или несколькими логически очень близкими) сущностью, её агрегатами и справочниками, ссылаясь на другие лишь по идентификатору, а аналитические отчёты по произвольным разрезам и периодам строятся средствами DWH или другими агрегаторами, умеющими собирать и связывать данные (и по запросу от потребителя, и по расписанию, и по событиям от сервиса-владельца) из многих разнотипных источников.
velvetcat
12.06.2016 10:12> но на уровне данных все SQL-запросы в итоге идут к одним и тем же базам данных
Эмм… У вас и близко никакие не микросервисы.

Temmokan
08.06.2016 07:39+4Косметическая придирка. Пользуйтесь хотя бы средствами проверки орфографии, что в самом браузере несложно включить. Чесслово, при такой концентрации уже глаз режет.
Навскидку:
«в кратце»: «вкратце» пишется слитно
«все зависит от вашего конертного случая»: от «конкретного» случая, надо полагать?
«одну с нашим микрофремворком»: «микрофреймворком»
«существующего контролера»: «контроллера», надо полагать — не билеты же он у вас во фреймворке проверяет
«Незабываем посылать токен»: «не забываем» пишется раздельно
Я всё понимаю, что и стиль изложения должен быть весь из себя стремительный, но хоть каплю уважения, блин, к читателям!
«Извините, если кого обидел».dmitry_ch
08.06.2016 08:18Как раз такие ошибки орфопроверялка в браузере как раз и пропустит процентов на 70. Ей что «контролера», что «контроллера» — и то, и другое слово есть в словаре. Из приведенных поймает «конертного» да, внезапно, любой из вариантов «микрофремворк»/«микрофреймворком».
Вообще, если пользоваться до степени доверия компьютерной проверкой слов, лучше всего перейти на упрощенный вариант языка, где больше одного варианта у слова нет, и нет мешающих стремительности мысли «похожестей» вроде «в кратце»/«вкратце» )Temmokan
08.06.2016 09:11Ну, сказано было «хотя бы». Вычитка другим человеком обычно достаточно эффективна — свои собственные опечатки — особенно, если орфографическая проверка их не укажет — заметить обычно сложнее.

lain8dono
08.06.2016 09:36+3А когда контейнеров становится слишком много, то получается вот так:

Т.е. теперь пованивает не только код, но и вообще всё, включая администрирование. Мы сами себе создали дополнительные проблемы. Ведь для каждого сервиса надо выполнить следующее:
- накодить сервис
- оттестировать сервис
- документировать сервис
- оттестировать api сервиса
- документировать api сервиса
- встроить сервис в систему сервисов
- оттестировать работу сервиса вместе с другими сервисами
- следить за адом явных и неявных зависимостей одних сервисов от других сервисов
- администрировать всё это дело внутри и снаружи
Это сложно.
Нет, я не имею ввиду, что использовать контейнеризацию это плохо. Я имею ввиду, что надо тщательно прорабатывать всю архитектуру, вооружившись такими полезными орудиями труда, как Бритва Оккама, принцип KISS и здравый смысл.
На мой взгляд гораздо лучше использовать большие и толстые сервисы. В вашем случае я бы сделал так:
- Nginx
- Контейнер приложения ? несколько штук во имя возможности обновлять приложение без перезагрузки всего
- Одна или несколько DB по вкусу
Это дешевле. Это работает быстро. Это не требует много ума. Это достаточно безопасно. Это неплохо документируется. Это вполне масштабируемо.
В дальнейшем сюда может добавиться контейнер для небезопасного кода. Например дать возможность постить юзерам webm, для чего может потребоваться дырявый ffmpeg или ещё что либо подобное. Или запилить рядом какой либо ещё сервис вроде wiki-платформы или irc-сервера (ну для примера).
Могу предложить примерно такой эврестический алгоритм отделения чего либо в отдельные сервисы:
- всё, что небезопасно (например код третьих лиц сомнительного качества) стоит порезать на сервисы
- если для поддержки сервиса требуется более 5-15 человек, то подумать о разделении этого на два-три сервиса
- если нам нужно симулировать бурную деятельность и/или освоить бюджет (под эту причину вполне подходит статья, которую я комментирую)
Кроме того стоит рассмотреть различные другие крутые штуки, которые делают контейнеризацию и инфраструктуру вокруг контейнеров. rkt/CoreOS, LXC/LXD, OpenVZ, kvm, OpenStack и другие. Тысячи их. Одно из сравнений можно посмотреть вот тут: https://coreos.com/rkt/docs/latest/rkt-vs-other-projects.html Не забывайте про вариант с самописной системой контейнеризацией и/или инфраструктурой вокруг этого на том или ином уровне (в конце концов у вас может быть в наличии админ с достаточными знаниями). Один день на гуглинг и пара дней на обработку его результатов может сэкономить месяцы и даже годы разработки.
tattoor
08.06.2016 10:27В вашем случае я бы сделал так
Я напомню, что эта задача чисто академическая, с непреодолимым желанием попробовать именно микросервисы.
Кроме того стоит рассмотреть различные другие крутые штуки, которые делают контейнеризацию и инфраструктуру вокруг контейнеров. rkt/CoreOS, LXC/LXD, OpenVZ, kvm, OpenStack и другие. Тысячи их. Одно из сравнений можно посмотреть вот тут: https://coreos.com/rkt/docs/latest/rkt-vs-other-projects.html Не забывайте про вариант с самописной системой контейнеризацией и/или инфраструктурой вокруг этого на том или ином уровне (в конце концов у вас может быть в наличии админ с достаточными знаниями). Один день на гуглинг и пара дней на обработку его результатов может сэкономить месяцы и даже годы разработки.
Я не очень понял как отказ от докера в пользу самописных контейнеров или даже каких-то других поможет сэкономить мне время. Докер настолько плох?Fesor
08.06.2016 11:32-2Докер настолько плох?
Все с ним хорошо. У меня он уже пол года в продакшене и я счастлив.
lain8dono
08.06.2016 11:41Я не очень понял как отказ от докера в пользу самописных контейнеров или даже каких-то других поможет сэкономить мне время. Докер настолько плох?
Я не говорю, что докер плох (хотя об этом можно поспорить тоже). Я говорю о том, что совершенно не ясно, какие задачи вы пытаетесь им решить. Академическая задача? Так явно напишите об этом.tattoor
08.06.2016 11:49Вот тут я упомянул об этом
Безусловно, это задача ради задачи, но хочется отметить что даже в таком варианте, это работать будет и будет работать неплохо (быстро и без проблем).
Да и еще в паре мест. Суть в том, что я хотел написать маленький и как следствие, максимально простой продукт (но работающий минимальным функционалом) на микросервисах, чтобы на примере было несложно понять (и мне в том числе) как же собственно все это выглядит? Еще хотелось услышать мнение обо всем этом тех людей, которые реально работают с сотнями микросервисов, и я их кстати услышал, за что им огромное спасибо.
Fesor
08.06.2016 11:23+1Что-то у вас смешалось в кучу все.
Это сложно.
Это сложнее чем монолит. Но чем больше проект тем меньше становится технических проблем и тем больше организационных. Скоординировать работу 40-а разработчиков над одним проектом знаете ли тоже весьма сложная задача.
Я имею ввиду, что надо тщательно прорабатывать всю архитектуру, вооружившись такими полезными орудиями труда, как Бритва Оккама, принцип KISS и здравый смысл.
И Здравый смысл рано или поздно подскажет что проще разделить проект на маленькие проекты со своей командой разработчиков, что бы процесс стал более управляем.
На мой взгляд гораздо лучше использовать большие и толстые сервисы. В вашем случае я бы сделал так:
это называется монолит. И при работе большого количества разработчиков у вас будут проблемы с управлением этой командой. А проблемы проектирования архитектуры будут не менее критичны чем в случае микросервисов.
Это дешевле. Это работает быстро. Это не требует много ума. Это достаточно безопасно. Это неплохо документируется. Это вполне масштабируемо.
До определенных масштабов. Проблема монолитных приложений в том, что они очень быстро выйдут из под контроля и код скорее всего превратится в кашу. Микросервисы же позволяют изолировать говнокод. Это существенно снижает риски при разработке новых фич так как все изолировано.
А проблемы с документированием у вас будут примерно одинаковые.
В дальнейшем сюда может добавиться контейнер для небезопасного кода.
вы путаете контейнеры и микросервисы как мне кажется. Я вот монолиты с докером делаю, и меня все устраивает.
всё, что небезопасно (например код третьих лиц сомнительного качества) стоит порезать на сервисы
Фреймворки типа? для отделения инфраструктурного кода от остального придумали гексагональную архитектуру. Микросервисы решают другие проблемы.
если для поддержки сервиса требуется более 5-15 человек, то подумать о разделении этого на два-три сервиса
более 3-х как по мне. При команде больше 5-ти человек энтропия разьест проект.
если нам нужно симулировать бурную деятельность и/или освоить бюджет (под эту причину вполне подходит статья, которую я комментирую)
Проекты с "бюджетом" никто не делает на микросервисах. Это больше нужно для продуктов которые планируется достаточно долго развивать.
Кроме того стоит рассмотреть различные другие крутые штуки, которые делают контейнеризацию и инфраструктуру вокруг контейнеров.
Зачем? Docker дефакто стандарт индустрии, им пользуются тысячи разработчиков, проще найти devops-ов. И не забывайте что сила докера (да и рокет о котором вы говорите) не в самой контейнеризации, оно там LXC просто использует, а в возможности делать образы системы и наследовать их. То есть если у меня есть 100 образов отнаследованных от 3-4 мне будет существенно проще поддерживать систему с точки зрения администрирования.
Не забывайте про вариант с самописной системой контейнеризацией
Это мы снова про распиливание бюджета?
Один день на гуглинг и пара дней на обработку его результатов может сэкономить месяцы и даже годы разработки.
велосипеды спасут мир.
foxmuldercp
08.06.2016 12:03А убийство велосипеда спасет котика.
/me как раз цинично убивает велостоянку которая по возрасту скоро паспорт получить может, и это даже без разговоров о суммах на поддержку этой, кхм, стоянки

grossws
09.06.2016 04:15Про полезность статьи судить не Вам(возможно, что многим примеры будут полезны).
just for the sake of truth, это давно не так. Docker используетlibcontainer, который работает с cgroups и namespaces напрямую.

acmnu
09.06.2016 12:23+1А что монолит не надо «кодить, тестировать, документировать и прочее»? На самом деле микросервис это подход для тех, кто уже понимает важность документации, тестов, стабильности библиотечных API. Для них выгода есть, для тех, кто привык кодить монолит в стиле «быстрее, быстрее» все это выглядит бредом.


amstr1k
08.06.2016 10:03Мы в компании импользуем микросервисы и они очень сильно облегчили нам жизнь. На каждый продукт создаётся микросервис с приватной и публичной частью. Всё это грамотно логирует ошибку, где зачастую понятно какой микросервис упал.
Конечно есть и свои минусу, но все эти минусы основаны на непонимании концепции разработки микросервисной архитектуры.
Ближайшие планы: при увеличении нагрузки на тот или иной микросервис, автоматически поднимать еще один инстансkohus
08.06.2016 10:23А можете сказать, насколько стоимость разработки выросла (ну или уменьшилась)?
amstr1k
08.06.2016 10:29+1Уменьшилась поддержка, но увеличилась реализация. В целом получили профит в некоторых случаях до 20%. Тут главное правильно структурировать код, вынести всю инфраструктуру и инжектить её между проектами
foxmuldercp
08.06.2016 12:05С логами это правильно. Особенно когда по всем инстансам можно по конкретному идентификатору найти, что, собственно творилось.
Особенно в рамках толстых сборщиков логов, вроде logstash какого
kohus
08.06.2016 10:03+1Мне интересно, а где во всех этих микросервисах находится контроль доступа к данным? Например, какие посты может пользователь видеть, а какие редактировать. Каждый сервис это по своему решает? Или у вас есть сервис, который права раздает/проверяет, а все остальные от него зависят?
tattoor
08.06.2016 10:34Да, есть сервис auth, который пока что решает просто, если человек вообще авторизован, значит он что-то может. Модифицируя сервис auth можно добавить, права, роли, группы и прочее.
amstr1k
08.06.2016 10:36По хорошему это микросервис который работает с пользователем. Сервис получает права пользователя по роли, либо другим признакам, кеширует данные по определённому условию и при очередном обращении данные берутся из кеша.
В нашем случае всё основано на роли пользователя, поэтому независимо от Id пользователя, если в кеше есть данные с определённой ролью, мы их возвращаем.kohus
08.06.2016 10:49И этот микросервис знает о всех правах в системе, то есть фактически о всех ее сущностях?
oxidmod
08.06.2016 10:56+1не совсем. В той же symfony роли это всего лишь строка и это дело конкретного сервиса что он формально будет делать с результатами проверки
->isGranted($user, 'WRITE_POST')
тоесть сервис тупой до безобразия. Его спрашивают, для такогото токена такая строка. Он дает ответ да/нет, но при этом он понятия не имеет что такое WRITE_POST
RouR
08.06.2016 13:53Усложним.
Допустим форум разбит на разделы. Тему только в конкретном разделе может отредактировать сам автор в первые 5 минут (меняется как настройка раздела) после её создания. Какой микросервис будет проверять? Auth? Posts?
amstr1k
08.06.2016 11:24+1Микросервис работает с правами и знает только о них. А дальше вопрос реализации, либо вы определяете доступ по роли, либо по праву, либо еще что то…
acmnu
09.06.2016 12:30+1Доступ определяет тот сервис, который владеет данными (БД, например, в простейшем случае). Т.е. данные не отдаются на сторону для принятия решения. Никогда. А вот использовать ли один сервис для хранения ACL, вопрос очень любопытный.

Jenyay
08.06.2016 15:07Как раз сегодня начал читать упомянутую в посте книгу про создание микросервисов. И сразу же возник вопрос, стоит ли ориентироваться на микросервисы, если разрабатывается небольшой проект, который будет выполняться на одном сервере и не планируется для каждого микросервиса выделять свой сервер?
tattoor
08.06.2016 15:44-1Если готов изучить еще виртуализацию, решать новые проблемы в дополнение к старым и прочее, то почему бы и нет :)

maxru
08.06.2016 16:56А что делать с потерями на накладные расходы HTTP?
А если HTTPS это ещё + 100-200 ms на handshake.
Не лучше ли через unix sockets?tattoor
08.06.2016 17:05Можно и web socket даже, почему бы и нет
maxru
08.06.2016 17:15Я как-то ожидал чуть больше информации, например:
«а у меня микросервисы висят на persistent connections и я трачу время только при запуске или когда connection отвалился» :)tattoor
08.06.2016 17:53Ах если бы :) Дело в том, что у меня нет микросервисов на сокетах на продакшене. Но может быть кто-нибудь еще подскажет.
Fesor
08.06.2016 19:51Все кто уперся в HTTP обычно переходят на очереди (zeromq в основном, хотя есть ребятки которые кафку используют). В этом случае, поскольку у нас приложение на PHP, он не должен умирать. И это налагает свои нюансы на разработчиков. Сейчас с этим не так плохо как скажем еще 2 года назад.
VolCh
12.06.2016 10:42+1Зачем на по две копии некоторых сервисов? Потому что с одной будет не интересно и не понятно.
Гораздо интересней использовать docker-compose scale, делегируя решать вопросы масштабирования, обнаружения сервисов и балансировки инфраструктуре докера, а не хардкодя её в коде и конфигах.
develop7
https://phoenixframework.org/ — те же микросервисы, только без оверхеда в виде контейнеров. бложек-Helloworld в development-режиме отрабатывает за ~100?s
tattoor
К сожалению в данный момент сервер не доступен по этому урлу, но было бы интересно посмотреть. А вы что-то знаете про оверхед контейнеров? Мне кажется он настолько мал, что им можно пренебречь в некоторых масштабах.
develop7
И правда. Вот так работает — http://www.phoenixframework.org/
Fesor
Оверхэд может быть только за счет использования дополнительных инстансов nginx-а. Ну мол не из-за контейнеров а потому что nginx-ов много. Можно взять nginx-proxy например и на основе него сделать единый nginx для того что бы разруливать все в пределах одной машины. А можно еще просто использовать в качестве транспорта zeromq.