
Каждый раз, когда мы используем сложные математические алгоритмы и современные методы машинного обучения, мы ставим задачу получить тренд, понять внутренние зависимости, и в конечном счете произвести предсказания. Более точные результаты можно получить, если алгоритм может быть адаптирован под имеющиеся знания, под имеющуюся модель процесса. Одним из направлений в машинном обучении, которое позволяет создавать и обучать модели для получения предсказаний, является «порождающее (или Байесовское) моделирование» (в отличие от «дискриминативного» моделирования, например, нейронных сетей). Для создания вероятностных моделей и работы с ними существуют платформы, которые в последнее время относятся к направлению «вероятностным программированием». Более подробно о вероятностном программировании можно почитать в других статьях на Хабрахабре: «Вероятностное программирование», «Вероятностное программирование – ключ к искусственному интеллекту?» и «Вероятностное программирование».
Совсем недавно появился стартап Invrea, который в качестве вероятностного языка программирования предлагает использовать Excel: вероятностная модель может быть создана в Экселе и предсказания могут быть получены там же. Ниже находится перевод одной из статьи с сайта стартапа (перевод выполнен исключительно в образовательных целях). В статье авторы рассматривают пример «бытовой» ситуации. Им интересно понять, кто победит в теннисном турнире на Олимпийских играх 2016. Они производят предсказания о том, кто наиболее вероятный кандидат на победу. Статья была написана 7 августа, во время игр, после завершения всех игр первого тура.
***
«На наш взгляд, очень важно сделать машинное обучение простым в использовании и доступным каждому. Нужно максимально устранить необходимость подгонять имеющийся вопрос или задачу под необходимые рамки для возможных вычислений. Авторы представляют плагин «Сценарии Invrea» (для Excel), который может быть использован для принятия решений о текущих и регулярных событиях. Чтобы продемонстрировать это, авторы воспроизвели ход турнира в мужском одиночном турнире в электронной таблице Excel. Используя плагин, были определены вероятности победы для каждого из игроков, входящих в Ассоциацию теннисистов-профессионалов (АТП), основываясь на их рейтинге в этой организации.
Видео-демонстрация (на английском) использования Эксель-плагина для предсказания победителя мужского турнира по теннису на Рио 2016:
Предсказания относительно обладателя золотой медали после первого тура. Рассчитано с использованием плагина Invrea:
В мужском одиночном турнире участвуют 64 человека, каждый из которых сталкивается лицом к лицу один на один с другим игроком. Победитель проходит в следующий тур, проигравший выходит из соревнования. Это продолжается до финала, где победителю вручают золотую медаль. Вопрос в том, кто вероятнее всего получит золото? Было бы неплохо получить вероятности победы каждого игрока в турнире. Теннис имеет большую долю неопределенности. Тот факт, что Маррей имеет рейтинг выше, чем у Нисикори, не гарантирует, что Маррей пройдет дальше. Как и в любом спортивном состязании разочарования и сюрпризы могут произойти в любой момент.
К счастью, машинное обучение создано с целью найти возможность справиться с этой проблемой. С его использованием мы можем учесть определенную долю случайности при принятии решения, выиграет ли Маррей или Нисикори. Маррей имеет немного большую вероятность согласно рейтингу, но справедлива и возможность, что победит Нисикори.
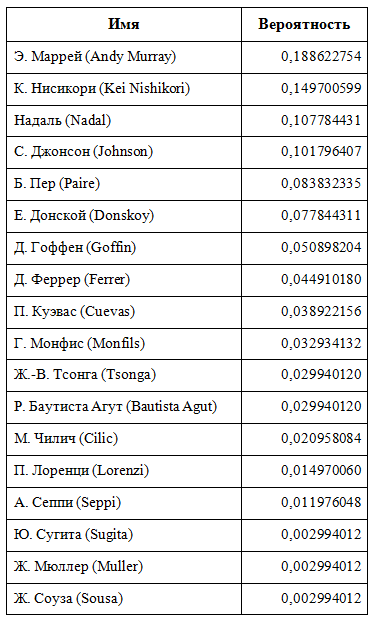
Далее представлена электронная таблица Excel, которую авторы создали с целью определить шансы на победу в Рио каждого игрока. Файл имеет два листа: первый содержит список всех игроков, его рейтинг и логарифм от этого рейтинга. К каждой из оценок была добавлена случайная величина, потому что количество очков не всегда имеет решающее значение в описании игрока (см. рис. 1). Например, Дель Потро имеет всего лишь 140 очков в рейтинге АТП, но в основном это так из-за небольшого игрового периода. Его последние результаты приводят нас к мысли, что он более хороший игрок, чем показывает его рейтинг. Случайность помогает учесть эти небольшие несоответствия.
Вспомогательная электронная таблица с априорными «силами» каждого из игроков, основанная на рейтинге Ассоциации теннисистов-профессионалов:

Рис. 1.
Второй лист содержит турнирную таблицу. Столбец C отражает первый раунд, который вы можете найти на любой странице, описывающей данный турнир. Но вы также можете видеть, что также заполнено и все дальнейшее состояние турнира, включая победителя (см. рис. 2). Как это получилось? Если обновить электронную таблицу (нажатием клавиши F9) вы можете заметить, что все игроки во втором раунде и после него поменяются. Другими словами, ячейки, которые отражают, кто пройдет в следующий раунд, содержат значения, рассчитанные на основе вероятности.
Основная электронная таблица для моделирования результатов матчей:
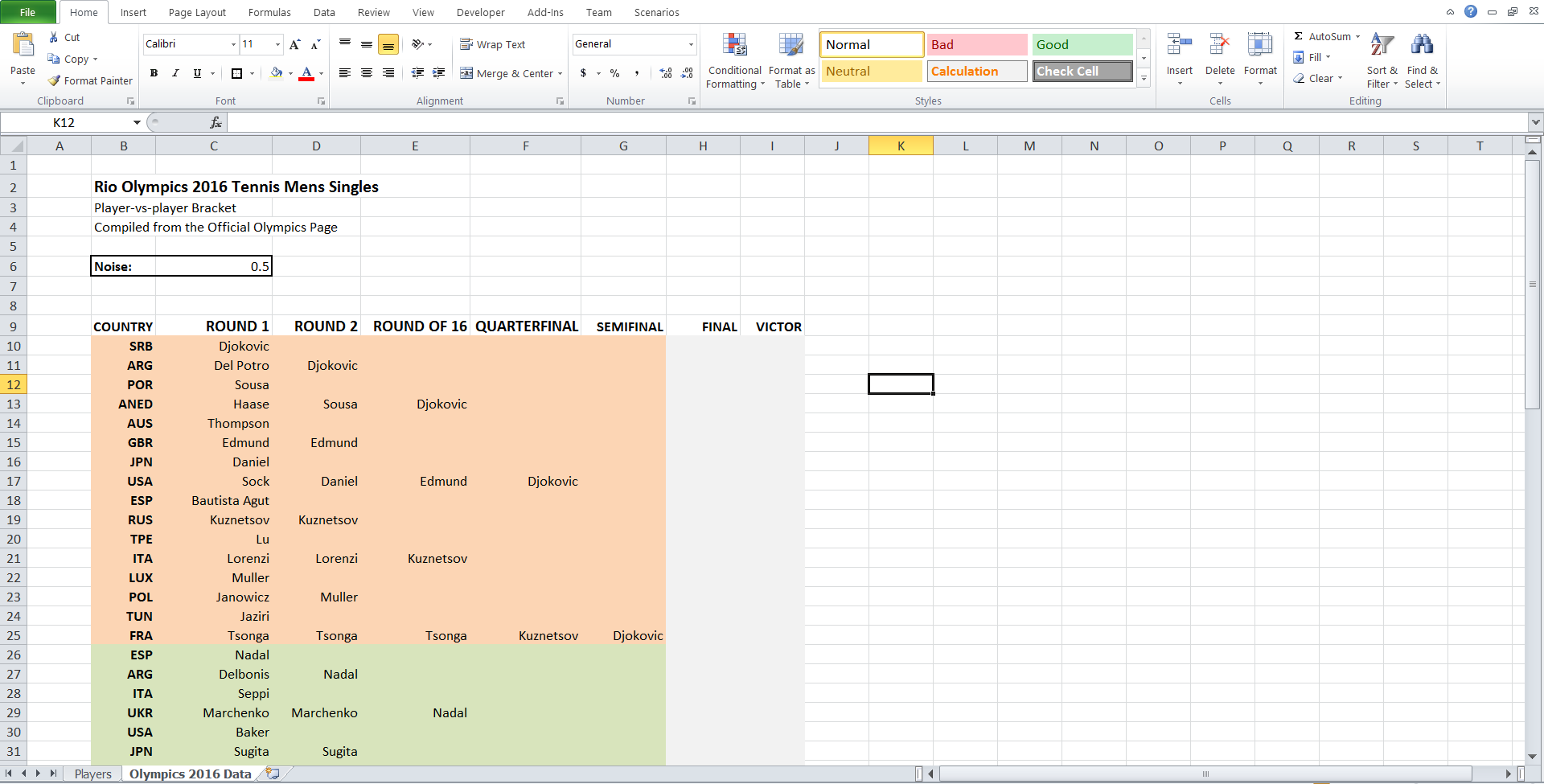
Рис. 2.
Но их случайный характер основан на правиле: представьте, что вы выбираете случайную величину, близкую к рейтингу игрока A и выбираете другую случайную величину, близкую к рейтингу игрока B. Иногда эти величины будут ниже, чем реальный рейтинг…иногда выше. В таком случае, правило: тот, у кого более высокая случайная величина, выигрывает. Таким образом, обладание более высоким рейтингом АТП означает, что у вас более высокий шанс победить вашего соперника, но у вас может быть неудачный день / вы можете страдать от травмы и условно приобрести низкое значение случайной величины. Отсюда, вещи повторяются. Третий раунд отображает такое же равенство для игроков, которые прошли во втором раунде. И так далее. Вот почему, если вы будете обновлять электронную таблицу много раз, различные люди будут объявляться победителями турнира.
Что «Сценарии» Invrea позволяют вам делать – так это определять эти случайные ячейки, используя такие функции, как GAUSSIAN, и этот плагин позволяет вам генерировать тысячи сценариев автоматически и отображать их. Можно увидеть, что из себя представляет распределение в каждой случайной ячейке: кто победит в первом туре? Во втором туре? В полуфинале? В финале? Вы можете взглянуть на вероятности в любой ячейке, которая вам интересна.
Гистограмма, которую вы видите ниже (см. рис. 3) – это апостериорные вероятности, рассчитанные на победу каждого игрока, не зная, что произошло по окончании первого раунда. Чем выше столбик, тем более вероятна победа соответствующего игрока. Лишь бросив взгляд на нее, мы видим, что Джокович имеет довольно хороший шанс. Единственные, кто потенциально может остановить его – это Маррей, Надаль и Нисикори (Федерер не участвует в соревновании). Благодаря этой информации вы можете быть иметь больше оснований сказать о своих ожиданиях на победу Джоковича.
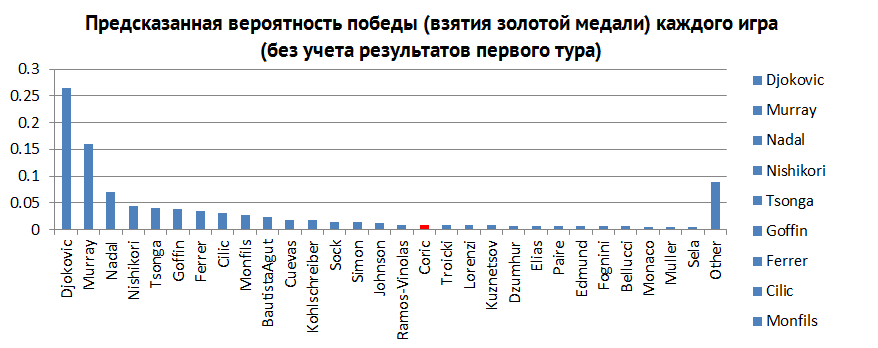
Рис. 3.
В действительности, можно поступить еще интереснее. Как только будут получены результаты по завершении раунда, вы можете учесть это в таблице, используя ACTUAL (специальную функцию Invrea). С учетом этого, мы можем увидеть сценарии, кто же победит в финале, ориентируясь на уже полученные результаты предыдущих раундов. Например, авторы использовали результаты всех матчей после первого раунда.
В их числе содержалось несколько непредвиденных ситуаций, в числе которых тот факт, что Джокович проиграл Дель Потро (см. рис. 4).
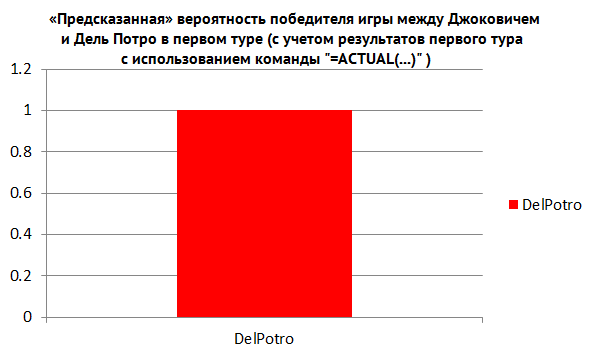
Рис. 4.
После запуска плагина с учетом новых данных можно увидеть (см. рис. 5) изменение распределения вероятностей того, кто победит в финале: теперь игроков меньше, и вероятность победы Джоковича теперь равна нулю, в то время, как результаты Маррея, Надаля и Нисикори повысились после первого раунда.
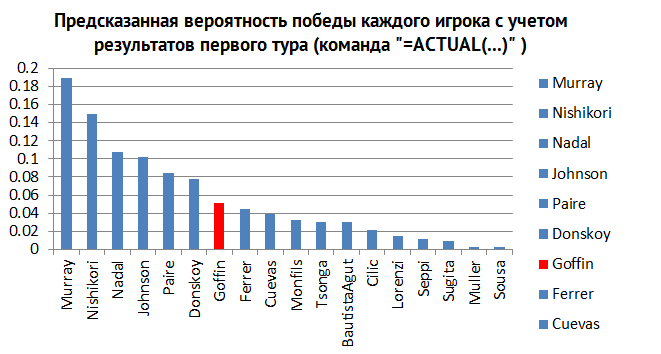
Рис. 5.
В действительности, распределение каждой случайной ячейки изменилось, потому что информация о результатах первого круга помогал плагина лучше рассчитать, кто будет наиболее вероятным победителем. Делая выводы по этим результатам, можно предположить победителя в лице Маррея или Нисикори. Можно следовать и далее, по ходу турнира добавляя информацию о происходящих событиях. Как только появятся результаты второго раунда, можно добавить их, используя ACTUALS, и предсказания станут еще лучше.
Также, существует большое количество информации, которое можно спрогнозировать по ходу турнира. Кто является наиболее вероятным победителем в 4-м четвертьфинале (рис. 6)? Втором полуфинале (рис. 7)? Глядя на гистограммы выше, мы можем получить ответы на каждый из этих вопросов.
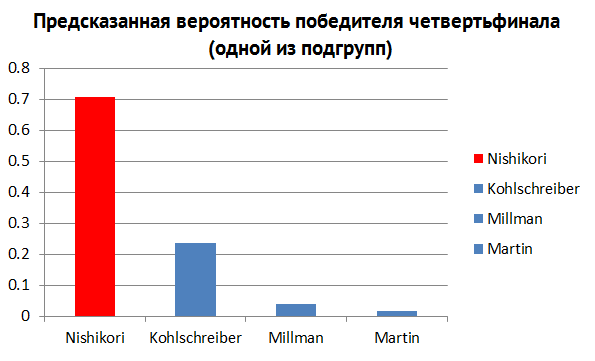
Рис. 6.
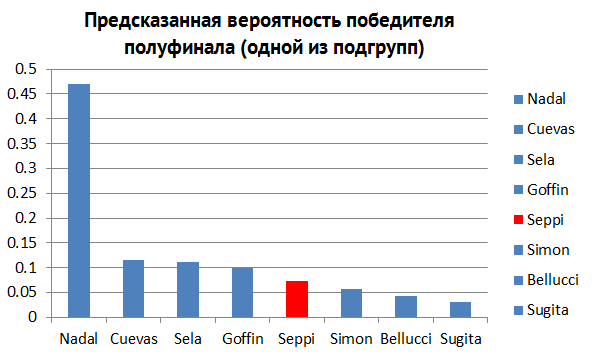
Рис. 7.
„Сценарии“ Invrea помогают с получением предсказаний такого рода, но это не все. Плагин может смоделировать неопределенность и предсказать что-либо, основываясь на допущениях, новой информации и новых данных для бизнес-решений, страхованию, графику выплат. Если возможно смоделировать свое решение как отношение между клетками в электронной таблице Excel, тогда есть достаточно вероятности, что Invrea сможет помочь. Далее, мы продолжим цикл статей, связанных с прогнозированием тех или иных событий, используя ситуации и задачи из других сфер нашей жизни».
***
Как мы упомянули ранее, статья была написана 7 августа, после окончания только первого тура мужского турнира. Как мы уже знаем, победителем на Рио 2016 стал Энди Маррей, победа которого была предсказана в статье с наибольшей вероятностью (см. рис. 5 в переводе).
Если вам интересно это направление и понравился перевод, есть планы по переводы других статей, связанных с машинным обучением в целом и с вероятностным программированием в частности. Также есть идеи рассказать о современных приложениях машинного обучения в образовательных и коммерческих проектах.
Совсем недавно появился стартап Invrea, который в качестве вероятностного языка программирования предлагает использовать Excel: вероятностная модель может быть создана в Экселе и предсказания могут быть получены там же. Ниже находится перевод одной из статьи с сайта стартапа (перевод выполнен исключительно в образовательных целях). В статье авторы рассматривают пример «бытовой» ситуации. Им интересно понять, кто победит в теннисном турнире на Олимпийских играх 2016. Они производят предсказания о том, кто наиболее вероятный кандидат на победу. Статья была написана 7 августа, во время игр, после завершения всех игр первого тура.
***
Описание задачи
«На наш взгляд, очень важно сделать машинное обучение простым в использовании и доступным каждому. Нужно максимально устранить необходимость подгонять имеющийся вопрос или задачу под необходимые рамки для возможных вычислений. Авторы представляют плагин «Сценарии Invrea» (для Excel), который может быть использован для принятия решений о текущих и регулярных событиях. Чтобы продемонстрировать это, авторы воспроизвели ход турнира в мужском одиночном турнире в электронной таблице Excel. Используя плагин, были определены вероятности победы для каждого из игроков, входящих в Ассоциацию теннисистов-профессионалов (АТП), основываясь на их рейтинге в этой организации.
Видео-демонстрация (на английском) использования Эксель-плагина для предсказания победителя мужского турнира по теннису на Рио 2016:
Предсказания относительно обладателя золотой медали после первого тура. Рассчитано с использованием плагина Invrea:
В мужском одиночном турнире участвуют 64 человека, каждый из которых сталкивается лицом к лицу один на один с другим игроком. Победитель проходит в следующий тур, проигравший выходит из соревнования. Это продолжается до финала, где победителю вручают золотую медаль. Вопрос в том, кто вероятнее всего получит золото? Было бы неплохо получить вероятности победы каждого игрока в турнире. Теннис имеет большую долю неопределенности. Тот факт, что Маррей имеет рейтинг выше, чем у Нисикори, не гарантирует, что Маррей пройдет дальше. Как и в любом спортивном состязании разочарования и сюрпризы могут произойти в любой момент.
К счастью, машинное обучение создано с целью найти возможность справиться с этой проблемой. С его использованием мы можем учесть определенную долю случайности при принятии решения, выиграет ли Маррей или Нисикори. Маррей имеет немного большую вероятность согласно рейтингу, но справедлива и возможность, что победит Нисикори.
Представляем вероятностную модель в электронной таблице
Далее представлена электронная таблица Excel, которую авторы создали с целью определить шансы на победу в Рио каждого игрока. Файл имеет два листа: первый содержит список всех игроков, его рейтинг и логарифм от этого рейтинга. К каждой из оценок была добавлена случайная величина, потому что количество очков не всегда имеет решающее значение в описании игрока (см. рис. 1). Например, Дель Потро имеет всего лишь 140 очков в рейтинге АТП, но в основном это так из-за небольшого игрового периода. Его последние результаты приводят нас к мысли, что он более хороший игрок, чем показывает его рейтинг. Случайность помогает учесть эти небольшие несоответствия.
Вспомогательная электронная таблица с априорными «силами» каждого из игроков, основанная на рейтинге Ассоциации теннисистов-профессионалов:
Рис. 1.
Второй лист содержит турнирную таблицу. Столбец C отражает первый раунд, который вы можете найти на любой странице, описывающей данный турнир. Но вы также можете видеть, что также заполнено и все дальнейшее состояние турнира, включая победителя (см. рис. 2). Как это получилось? Если обновить электронную таблицу (нажатием клавиши F9) вы можете заметить, что все игроки во втором раунде и после него поменяются. Другими словами, ячейки, которые отражают, кто пройдет в следующий раунд, содержат значения, рассчитанные на основе вероятности.
Основная электронная таблица для моделирования результатов матчей:
Рис. 2.
Но их случайный характер основан на правиле: представьте, что вы выбираете случайную величину, близкую к рейтингу игрока A и выбираете другую случайную величину, близкую к рейтингу игрока B. Иногда эти величины будут ниже, чем реальный рейтинг…иногда выше. В таком случае, правило: тот, у кого более высокая случайная величина, выигрывает. Таким образом, обладание более высоким рейтингом АТП означает, что у вас более высокий шанс победить вашего соперника, но у вас может быть неудачный день / вы можете страдать от травмы и условно приобрести низкое значение случайной величины. Отсюда, вещи повторяются. Третий раунд отображает такое же равенство для игроков, которые прошли во втором раунде. И так далее. Вот почему, если вы будете обновлять электронную таблицу много раз, различные люди будут объявляться победителями турнира.
Что «Сценарии» Invrea позволяют вам делать – так это определять эти случайные ячейки, используя такие функции, как GAUSSIAN, и этот плагин позволяет вам генерировать тысячи сценариев автоматически и отображать их. Можно увидеть, что из себя представляет распределение в каждой случайной ячейке: кто победит в первом туре? Во втором туре? В полуфинале? В финале? Вы можете взглянуть на вероятности в любой ячейке, которая вам интересна.
Генерируем и производим анализ апостериорного распределения
Гистограмма, которую вы видите ниже (см. рис. 3) – это апостериорные вероятности, рассчитанные на победу каждого игрока, не зная, что произошло по окончании первого раунда. Чем выше столбик, тем более вероятна победа соответствующего игрока. Лишь бросив взгляд на нее, мы видим, что Джокович имеет довольно хороший шанс. Единственные, кто потенциально может остановить его – это Маррей, Надаль и Нисикори (Федерер не участвует в соревновании). Благодаря этой информации вы можете быть иметь больше оснований сказать о своих ожиданиях на победу Джоковича.
Рис. 3.
В действительности, можно поступить еще интереснее. Как только будут получены результаты по завершении раунда, вы можете учесть это в таблице, используя ACTUAL (специальную функцию Invrea). С учетом этого, мы можем увидеть сценарии, кто же победит в финале, ориентируясь на уже полученные результаты предыдущих раундов. Например, авторы использовали результаты всех матчей после первого раунда.
В их числе содержалось несколько непредвиденных ситуаций, в числе которых тот факт, что Джокович проиграл Дель Потро (см. рис. 4).
Рис. 4.
После запуска плагина с учетом новых данных можно увидеть (см. рис. 5) изменение распределения вероятностей того, кто победит в финале: теперь игроков меньше, и вероятность победы Джоковича теперь равна нулю, в то время, как результаты Маррея, Надаля и Нисикори повысились после первого раунда.
Рис. 5.
В действительности, распределение каждой случайной ячейки изменилось, потому что информация о результатах первого круга помогал плагина лучше рассчитать, кто будет наиболее вероятным победителем. Делая выводы по этим результатам, можно предположить победителя в лице Маррея или Нисикори. Можно следовать и далее, по ходу турнира добавляя информацию о происходящих событиях. Как только появятся результаты второго раунда, можно добавить их, используя ACTUALS, и предсказания станут еще лучше.
Также, существует большое количество информации, которое можно спрогнозировать по ходу турнира. Кто является наиболее вероятным победителем в 4-м четвертьфинале (рис. 6)? Втором полуфинале (рис. 7)? Глядя на гистограммы выше, мы можем получить ответы на каждый из этих вопросов.
Рис. 6.
Рис. 7.
„Сценарии“ Invrea помогают с получением предсказаний такого рода, но это не все. Плагин может смоделировать неопределенность и предсказать что-либо, основываясь на допущениях, новой информации и новых данных для бизнес-решений, страхованию, графику выплат. Если возможно смоделировать свое решение как отношение между клетками в электронной таблице Excel, тогда есть достаточно вероятности, что Invrea сможет помочь. Далее, мы продолжим цикл статей, связанных с прогнозированием тех или иных событий, используя ситуации и задачи из других сфер нашей жизни».
***
Послесловие
Как мы упомянули ранее, статья была написана 7 августа, после окончания только первого тура мужского турнира. Как мы уже знаем, победителем на Рио 2016 стал Энди Маррей, победа которого была предсказана в статье с наибольшей вероятностью (см. рис. 5 в переводе).
Если вам интересно это направление и понравился перевод, есть планы по переводы других статей, связанных с машинным обучением в целом и с вероятностным программированием в частности. Также есть идеи рассказать о современных приложениях машинного обучения в образовательных и коммерческих проектах.
Поделиться с друзьями
Alibek24
Есть книга Джона Формана — Много цифр, там много интересных вещей делается на том же Excel. Единственное примеры мне не сильно понравились.