
Каждый хороший разработчик должен знать, что происходит под капотом после того, как пользователь введет URL сайта в адресной строке браузера и нажмет кнопку "Перейти". На самом деле это самый частый вопрос на собеседовании. В этой статье мы разберем, что происходит во время обработки HTTP-запроса.
Терминология
Для того, чтобы понять, как обрабатывается запрос вам нужно знать следующие определения:
- веб-сервер — программное обеспечение на сервере, которое позволяет принять и обработать входящий запрос
- DNS — сокращение от Domain Name System (система доменных имен), которая просто как телефонная книга, связывает адрес сайта с IP-адресом
- код ответа — число, которое обозначает тип ответа сервера. Общеизвестными являются 200 (все хорошо), 404 (не найдено), 302 (перенаправление), 500 (внутренняя ошибка сервера)
Шаг 1: поиск DNS
На самом деле веб-адреса представляют собой простую строку, которую выглядит как-то так: 216.58.198.174. Если вы перейдете по этому адресу с помощью браузера, то откроется Google. Доменное имя (google.com) это просто псевдоним, который позволяет пользователю легче запомнить адрес.
Итак, когда пользователь вводит доменное имя (например, google.com), браузер делает запрос к DNS и получает IP-адрес, который связан с этим именем.
Думайте о DNS как о телефонной книге. Вместо того, что запоминать номер Вани, вы можете записать его в телефонную книгу. Затем вы можете просто нажать "позвонить Ване" и ваш телефон найдет его номер в базе, и позвонит по этому номеру. В этой аналогии имя "Ваня" — это доменное имя, его номер — это IP-адрес, а телефонная книга — это DNS.
Шаг 2: выполнение запроса
После того, как браузер получил IP-адрес сервера от DNS, он может приступить к созданию запроса. Запрос содержит в себе заголовок и также может содержать тело запроса (например, данные из формы, которую отправил пользователь).
Заголовок содержит в себе следующие параметры:
- Request method (метод запроса) — чаще всего это либо GET, либо POST. Обычно GET-запрос используется для получения данных (например при отображении веб-страницы), а POST — при отправке формы или данных (например, при авторизации или отправке почты).
- Request URL (URL-запроса) — это полный URL, который говорит серверу, какую страницу запрашивает пользователь
- Protocol (протокол) — версия протокола HTTP (обычно 1.2)
В итоге запрос будет выглядеть так:
GET /about.html HTTP/1.1Дополнительная информация может быть добавлена ниже. Они представлены в виде пар ключ/значение, где ключ — это идентификатор, название, а значение — собственно сам кусочек информации. Пример ниже включают в себя информацию о браузере пользователя (user-agent), куки (cookies), тип содержимого (content type), хост (host), которое в данном случае является названием домена и т.д. Полный HTTP-запрос выглядит как-то так:
GET /culture/anatomy-web-request HTTP/1.1[CRLF]
Host: viacreative.co.uk[CRLF]
Connection: close[CRLF]
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36
Accept-Encoding: gzip[CRLF]
Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7[CRLF]
Cache-Control: no-cache[CRLF]
Accept-Language: de,en;q=0.7,en-us;q=0.3[CRLF]Шаг 3: ответ сервера
После того, как сервер получил запрос, он генерирует ответ. Так же как и запрос ответ содержит различную информацию, включая:
- HTTP-код ответа (смотрите раздел "Терминология"). Если запрос прошел успешно, он (код) обычно равен 200 (все хорошо)
- дата и время генерации ответа
- HTML-содержимое страницы
Обычный ответ сервера выглядит как-то так:
HTTP/1.x 200 OK
Transfer-Encoding: chunked
Date: Mon, 19 Dec 2016 15:32:21 GMT
Server: nginx/1.11.5
Connection: close
Content-Type: text/html; charset=UTF-8
Content-Encoding: gzip
Vary: Accept-Encoding, Cookie, User-Agent
<!doctype html>
<html lang="en">
<!-- Rest of the HTML -->Поле Content-Type говорит, браузеру, какой тип содержимого ему следует ожидать. В данном случае это простой HTML. Таким образом, браузер узнает, что ему нужно отрендерить и показать HTML. Тип содержимого может быть также указан как картинка, видео, JSON и т.д. Это поле говорит браузеру, как нужно обработать полученную информацию.
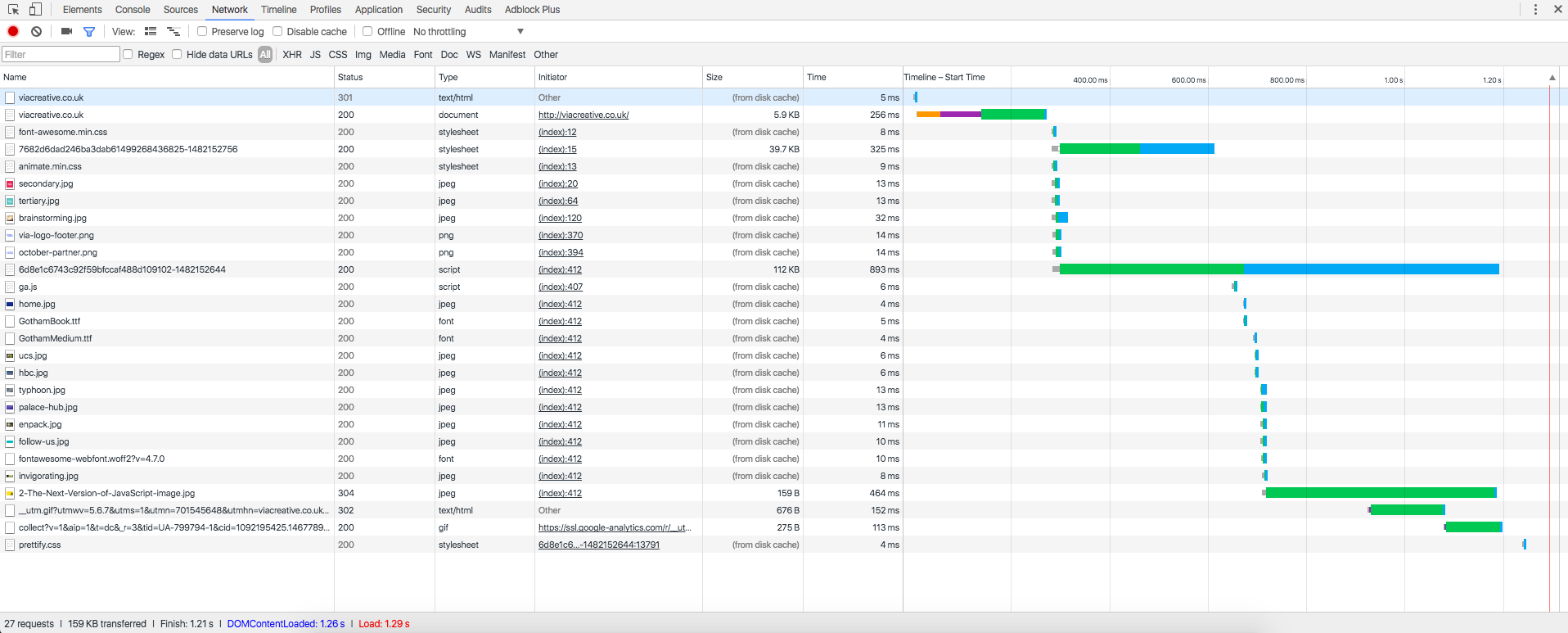
HTML также подключает различные ресурсы, такие как изображения, видео, шрифты или внешние CSS и JavaScript-файлы. Браузер отправляет запросы к серверу для получения этих ресурсов, а затем размещает их на странице. Если вы откроете инструменты разработчика в Google Chrome (Ctrl+Shift+J) и откроете какой-нибудь сайт, то увидите запросы, которые выполнил браузер (вкладка Network).
Заключение
Итак, теперь у вас есть общее представление как работают HTTP-запросы. Конечно все становится намного сложнее, когда дело доходит до отправки формы и загрузки файлов, но это уже совсем другая история.
Оригинал: The Anatomy of a Web Request
Комментарии (3)

lair
27.12.2016 16:48+2А почему в ответ на вопрос "что происходит" выбран именно этот уровень абстракции? Почему не разбираются детали TCP/IP соединения? Или HTTPS, которого сейчас много? Или почему не разбирается, что происходит в браузере между моментом нажатия на Enter и отправкой собственно HTTP-запроса?
В конце концов, почему переход на страницу в браузере приравнивается к HTTP-запросу?
Grief
27.12.2016 16:48+2Статья очень-очень базовая. На мой взгляд, ее польза несколько сомнительна, но тем не менее, позволю себе оставить пару замечаний.
Мне кажется, что упоминание того, что заголовок Host с доменным именем используется веб-сервером для возможности одновременной работы нескольких веб-ресурсов на одном IP-адресе заслуживает упоминания даже в такой базовой статье. Хотя бы для того, чтобы новичку было понятно, почему при блокировке одного IP блокируются другие сайты, хостящиеся на том же адресе.
"Заголовок" — это на самом деле "строка запроса" (request line), чтобы не создавать путаницы с заголовками (headers), это проблема не перевода, а оригинала. "Пары ключ-значение" — это как раз заголовки.
И еще, мне кажется, что в самых базовых статьях стоит освещать тот факт, что уже 17 лет протокол HTTP/1.1, позволяет не закрывать соединение после каждого запроса-ответа для того чтобы ускорить работу сети, избавившись от затрат на переподключение для каждого ресурса. Для того, чтобы сервер и клиент понимали, когда данные завершились, используется, на мой взгляд один из самых главных заголовков Content-length, значением которого является размер тела сообщения в байтах. Если игнорировать этот заголовок в своих приложениях, даже при указании HTTP/1.1 в строке ответа сервера, соединение будет фактически HTTP/1.0 (Конечно, если не указан Transfer-Encoding, но вот это уже advanced ИМХО) Вообще, последняя спека написана вполне себе человеческим языком и не слишком длинная.
grossws
Во-первых, для "оригинал тут" есть выбор публикация/перевод.
Во-вторых статей такого вида уже даже на хабре тонна и непонятно зачем этот мусор нужен ещё раз, да ещё и в хабе "программирование".