

Введение
Информационная система с точки зрения пользователя хорошо определяется в ГОСТ РВ 51987 — «автоматизированная система, результатом функционирования которой является представление выходной информации для последующего использования». Если рассматривать внутреннюю структуру, то по сути любая ИС является системой реализованных в коде взаимосвязанных алгоритмов. В широком понимании тезиса Тьюринга-Черча алгоритм (а сл-но ИС) осуществляет трансформацию множества входных данных в множество выходных данных.
Можно даже сказать, что в трансформации входных данных и есть смысл существования информационной системы. Соответственно ценность ИС и всего комплекса ИС определяется через ценность входных и выходных данных.
Исходя из этого проектирование должно начинаться и брать за основу данные, подстраивая архитектуру и методы под структуру и значимость данных.
Хранимые данные
Ключевым этапом подготовки к проектированию является получение характеристик всех наборов данных, планируемых к обработке и хранению. Эти характеристики включают в себя:
— Объем данных;
— Информация о жизненном цикле данных (прирост новых данных, срок жизни, обработка устаревших данных);
— Классификация данных с т.з. влияния на основной бизнес компании (то триаде конфиденциальность, целостность, доступность) вместе с финансовыми показателями (напр. стоимость утери данных за последний час);
— География обработки данных (физическое расположение систем обработки);
— Требования регуляторов по каждому классу данных (напр. ФЗ-152, PCI DSS).
Информационные системы
Данные не только хранятся, но и обрабатываются (трансформируются) информационными системами. Следующим шагом после получения характеристик данных является максимально полная инвентаризация информационных систем, их архитектурных особенностей, взаимозависимостей и требований к инфраструктуре в условных единицах к четырем видам ресурсов:
— Процессорная вычислительная мощностьl;
— Объем оперативной памяти;
— Требования к объему и производительности системы хранения данных;
— Требования к сети передачи данных (внешние каналы, каналы между компонентами ИС).
Требования при этом должны быть на каждый сервис/микросервис в составе ИС.
Отдельно необходимо отметить обязательное для корректного проектирования наличие данных по влиянию ИС на основной бизнес компании в виде стоимости простоя ИС (рублей в час).
Модель угроз
В обязательном порядке должна быть в наличии формальная модель угроз, от которых планируется защищать данные / сервисы. При этом модель угроз включает в себя не только аспекты конфиденциальности, но и целостности и доступности. Т.е. например:
— Выход из строя физического сервера;
— Выход из строя коммутатора top-of-the-rack;
— Разрыв оптического канала связи между ЦОД;
— Выход из строя оперативной СХД целиком.
В некоторых случаях модели угроз пишутся не только для инфраструктурных компонентов, но и для конкретных ИС или их компонентов, как например отказ СУБД с логическим разрушением структуры данных.
Все решения в рамках проекта по защите против не описанной угрозы являются излишними.
Требования регуляторов
Если обрабатываемые данные попадают под действие специальных правил, устанавливаемых регуляторами, в обязательном порядке необходима информация о наборах данных и правилах обработки/хранения.
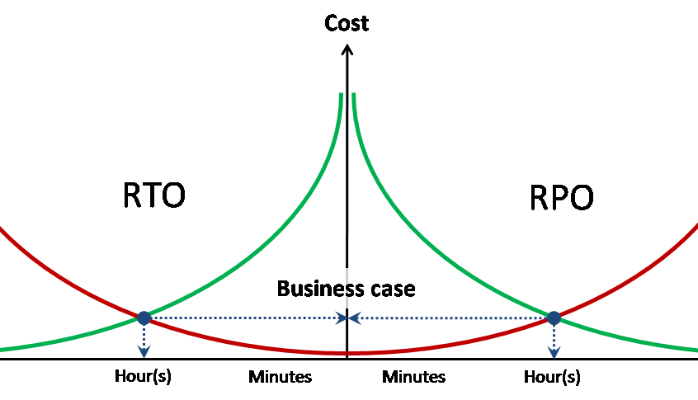
Целевые показатели RPO / RTO
Проектирование любого вида защиты требует наличия показателей целевой потери данных и целевого времени восстановления сервиса для каждой из описанных угроз.
При этом в идеале RPO и RTO должны иметь ассоциированные стоимости потери данных и простоя в единицу времени.
Разделение на пулы ресурсов
После сбора всей первичной вводной информации первым шагом является группировка наборов данных и ИС в пулы, исходя из моделей угроз и требований регуляторов. Определяется вид разделения различных пулов – программно на уровне системного ПО или физически.
Примеры:
— Контур, обрабатывающий персональные данные, полностью физически отделен от остальных систем;
— Резервные копии хранятся на отдельной СХД.
При этом пулы могут быть с неполной независимостью, например, определяется два пула вычислительных ресурсов (процессорная мощность + оперативная память), которые используют единый пул хранения данных и единый пул ресурсов передачи данных.
Процессорная мощность

Абстрактные потребности в процессорной мощность виртуализованного ЦОД измеряется в количестве виртуальных процессоров (vCPU) и коэффициенте их консолидации на физических процессорах (pCPU). В данном конкретном случае 1 pCPU = 1 физическое ядро процессора (без учета Hyper-Threading). Количество vCPU суммируется по всем определенным пулам ресурсов (каждый из которых может иметь свой коэффициент консолидации).
Коэффициент консолидации для нагруженных систем получают эмпирическим путем, исходя из уже существующей инфраструктуры, либо при пилотной установке и нагрузочном тестировании. Для ненагруженных систем применяются «best practice». В частности, VMware называет средним коэффициентом 8:1.
Оперативная память
Общая потребность в оперативной памяти получается путем простого суммирования. Использование переподписки по оперативной памяти не рекомендуется.
Ресурсы хранения
Требования по ресурсам хранения получаются путем простого суммирования всех пулов по объему и производительности.
Требования по производительности выражаются в IOPS в сочетании со средним соотношением чтение/запись и при необходимости максимальной задержкой отклика.
Отдельно должны быть указаны требования по обеспечению качества обслуживания (QoS) для конкретных пулов или систем.
Ресурсы сети передачи данных
Требования по сети передачи данных получаются путем простого суммирования всех пулов пропускной способности.
Отдельно должны быть указаны требования по обеспечению качества обслуживания (QoS) и задержек (RTT) для конкретных пулов или систем.
В рамках требований к ресурсам сети передачи данных так же указываются требования по изоляции и/или шифрованию сетевого трафика и предпочтительным механизмам (802.1q, IPSec и т.д.)
Выбор архитектуры
В рамках данного руководства не рассматривается иной выбор, кроме архитектуры x86 и 100% виртуализации серверов. Поэтому выбор архитектуры вычислительной подсистемы сводится к выбору платформы серверной виртуализации, форм-фактора серверов и общих требований по конфигурации серверов.
Ключевым моментом выбора является определенность в использовании классического подхода с разделением функций обработки, хранения и передачи данных или конвергентного.
Классическая архитектура подразумевает использование интеллектуальных внешних подсистем хранения и передачи данных, в то время как серверы привносят в общий пул физических ресурсов только процессорную мощность и оперативную память. В предельном случае серверы становятся полностью анонимными, не имеющими не только собственных дисков, но даже системного идентификатора. В этом случае используется загрузка ОС или гипервизора с встроенных флэш носителей либо с внешней системы хранения данных (boot from SAN).
В рамках классической архитектуры выбор между лезвиями (blade) и стоечными (rack) осуществляется прежде всего из следующих принципов:
— Экономическая эффективность (в среднем стоечные серверы дешевле);
— Вычислительная плотность (у лезвий выше);
— Энергопотребление и тепловыделение (у лезвий выше удельное на юнит);
— Масштабируемость и управляемость (лезвия в целом требует меньше усилий при больших инсталляциях);
— Использование карт расширения (для лезвий очень ограниченный выбор).
Конвергентная архитектура (также известная как гиперконвергентная) предполагает совмещение функций обработки и хранения данных, что ведет к использованию локальных дисков серверов и как следствие отказу от форм-фактора классических лезвий. Для конвергентных систем используются либо стоечные серверы, либо кластерные системы, совмещающие в едином корпусе несколько серверов-лезвий и локальные диски.
CPU / Memory
Для корректного расчета конфигурации нужно понимать тип нагрузки для среды или каждого из независимых кластеров.
CPU bound – среда, ограниченная по производительности процессорной мощностью. Добавление оперативной памяти ничего не изменит с точки зрения производительности (количества ВМ на сервер).
Memory bound – среда, ограниченная оперативной памятью. Большее количество оперативной памяти на сервере позволяет запустить большее количество ВМ на сервер.
GB / MHz (GB / pCPU) – среднее соотношение потребления данной конкретной нагрузкой оперативной памяти и процессорной мощности. Может использоваться для расчетов необходимого объема памяти при заданной производительности и наоборот.
Расчет конфигурации сервера

Для начала необходимо определить все виды нагрузки и принять решение о совмещении или разделении различных вычислительных пулов по различным кластерам.
Далее для каждого из определенных кластеров определяется соотношение GB / MHz при известной заранее нагрузке. Если нагрузка не известна заранее, но есть примерное понимание уровня загрузки процессорной мощности, можно использовать стандартные коэффициенты vCPU:pCPU для перевода требований пулов в физические.
Для каждого кластера сумму требований пулов vCPU делим на коэффициент:
vCPUсумм / vCPU:pCPU = pCPUсумм – требуемое количество физ. ядер
pCPUсумм / 1.25 = pCPUht – количество ядер с поправкой на Hyper-Threading
Предположим, что необходимо произвести расчет кластера на 190 ядер / 3.5ТБ ОЗУ. При этом принимаем целевую 50% загрузку процессорной мощности и 75% по оперативной памяти.
| pCPU | 190 | CPU util | 50% | |
| Mem | 3500 | Mem util | 75% | |
| Socket | Core | Srv / CPU | Srv Mem | Srv / Mem |
| 2 | 6 | 25,3 | 128 | 36,5 |
| 2 | 8 | 19,0 | 192 | 24,3 |
| 2 | 10 | 15,2 | 256 | 18,2 |
| 2 | 14 | 10,9 | 384 | 12,2 |
| 2 | 18 | 8,4 | 512 | 9,1 |
В данном случае всегда используем округление до ближайшего целого вверх (=ROUNDUP(A1;0)).
Из таблицы становится очевидно, что сбалансированными под целевые показатели являются несколько конфигураций серверов:
— 26 серверов 2*6c / 192 GB
— 19 серверов 2*10c / 256 GB
— 10 серверов 2*18c / 512 GB
Выбор из этих конфигураций в дальнейшем необходимо делать исходя из дополнительных факторов, как например тепловой пакет и доступное охлаждение, уже используемые серверы, или стоимость.
Особенности выбора конфигурации сервера
Широкие ВМ. При необходимости размещения широких ВМ (сравнимых с 1 узлом NUMA и более) рекомендуется по возможности выбирать сервер с конфигурацией, позволяющей таким ВМ остаться в пределах NUMA узла. При большом количестве широких ВМ возникает опасность фрагментирования ресурсов кластера, и в этом случае выбираются серверы, позволяющие разместить широкие ВМ максимально плотно.
Размер домена единичного отказа.
Выбор размера сервера также осуществляется из принципа минимизации домена единичного отказа. Например, при выборе между:
— 3 x 4*10c / 512 GB
— 6 x 2*10c / 256 GB
При прочих равных необходимо выбирать второй вариант, поскольку при выходе одного сервера из строя (или обслуживании) теряется не 33% ресурсов кластера, а 17%. Точно так же вдвое снижается количество ВМ и ИС, на которых отразилась авария.
Расчет классической СХД по производительности

Классическая СХД всегда рассчитывается по худшему варианту (worst case scenario), исключая влияние оперативного кэша и оптимизации операций.
В качестве базовых показателей производительности принимаем механическую производительность с диска (IOPSdisk):
— 7.2k – 75 IOPS
— 10k – 125 IOPS
— 15k – 175 IOPS
Далее количество дисков в дисковом пуле рассчитывается по следующей формуле: = TotalIOPS * ( RW + (1 –RW) * RAIDPen) / IOPSdisk. Где:
— TotalIOPS – суммарная требуемая производительность в IOPS с дискового пула
— RW – процентная доля операций чтения
— RAIDpen – RAID penalty для выбранного уровня RAID
Подробнее об устройстве RAID и RAID Penalty рассказывается здесь - Производительность СХД. Часть первая. и Производительность СХД. Часть вторая. и Производительность СХД. Часть третья
Исходя из полученного количества дисков рассчитываются возможные варианты, удовлетворяющие требованиям по емкости хранения, включая варианты с многоуровневым хранением.
Расчет систем с использованием SSD в качестве уровня хранения рассматривается отдельно.
Особенности расчета систем с Flash Cache
Flash Cache – общее название для всех фирменных технологий использования флэш-памяти в качестве кэша второго уровня. При использовании флэш кэша СХД как правило рассчитывается для обеспечения с магнитных дисков установившейся нагрузки, в то время как пиковую обслуживает кэш.
При этом необходимо понимать профиль нагрузки и степень локализации обращений к блокам томов хранения. Флэш кэш – технология для нагрузок с высокой локализацией запросов, и практически неприменима для равномерно нагруженных томов (как например для систем аналитики).
Расчет гибридных систем low-end / mid-range
Гибридные системы нижнего и среднего классов используют многоуровневое хранение с перемещением данных между уровнями по расписанию. При этом размер блока многоуровневого хранения у лучших моделей составляет 256 МБ. Данные особенности не позволяют считать технологию многоуровневого хранения технологией повышения производительности, как ошибочно считается многими. Многоуровневое хранение в системах нижнего и среднего классов – это технология оптимизации стоимости хранения для систем с выраженной неравномерностью нагрузки.
Для многоуровневого хранения рассчитывается прежде всего производительность по верхнему уровню, в то время как нижний уровень хранения считается лишь вносящим недостающую емкость хранения. Для гибридной многоуровневой системы обязательно использование технологии флэш кэша для многоуровневого пула с целью компенсации просадки производительности для внезапно нагревшихся данных с нижнего уровня.
Использование SSD в многоуровневом дисковом пуле

Использование SSD в многоуровневом дисковом пуле имеет вариации, в зависимости от особенностей реализации алгоритмов флэш кэша у данного производителя.
Общая практика политики хранения для дискового пула с SSD уровнем — SSD first.
Read Only Flash Cache. Для флэш кэша только на чтение уровень хранения на SSD появляется при значительной локализации операций записи вне зависимости от кэша.
Read / Write Flash Cache. В случае с флэш кэшем на запись сначала устанавливается максимальный объем кэша, а уровень хранения на SSD появляется лишь при недостаточности размера кэша для обслуживания всей локализованной нагрузки.
Расчет производительности SSD и кэша производится каждый раз исходя из рекомендаций производителя, но всегда для наихудшего варианта.
Поделиться с друзьями
Комментарии (10)

bayonet
05.02.2017 06:31Антон, хорошая статья! Можешь написать формулы по которым ты считал количество серверов с учетом поправки на утилизацию

AntonVirtual
05.02.2017 06:44=ROUNDUP(pCPU / CPUUtil / (SrvSockets * CoresPerSocket * 1.25);0)
=ROUNDUP(Mem / MemUtil / SrvMem;0)

dserov
06.02.2017 13:52Антон, отличная статья. Спасибо.
«Магический коэффициент» 1.25 при расчете процессоров взят из какой-то универсальной best practice?
mikkisse
06.02.2017 16:04+1Это примерный процесс прироста производительности при включенном HT. Во многих документах по best practices фигурирует значение 20-40%
PSVITAmins
Спасибо за интересный материал! Хотелось бы услышать авторитетное мнение о том, как правильно защититься от угрозы — «Выход из строя коммутатора top-of-the-rack». Потому что как спланировать сервера и каналы между ЦОДами вполне понятно, а вот как обезопасить себя от поломки корневого маршрутизатора — не совсем. Понятно, что они кластеризуются, но всё равно остаются близко друг от друга и пожар/потоп порушит всю такую сеть целиком.
AntonVirtual
Определитесь пожалуйста, от чего защищаемся — от поломки TOR коммутатора или ядра сети?
А если у вас в датацентре пожар / потоп, то уверяю, что работоспособность TOR отходит на второй план.
ovcharuk
Вот тут — https://www.cisco.com/c/en/us/td/docs/solutions/Enterprise/Campus/HA_campus_DG/hacampusdg.html — хороший обзор технологий построения redundant core. Если речь идет все же именно о защите от поломок. Если речь идет от затопления или пожара, то тут уже больше вопрос в сторону грамотного выбора ЦОДа для размещения.
shapa
А реально — лучше двух+ ЦОДов от разных поставщиков услуг.
Причем при выборе надо изучать вплоть до того как энерговводы сделаны (в РФ имеет мало смысла), пути подвода оптики и прочие радости.
Karroplan
Достаточно простой ответ — дублировать коммутатор ToR — подойдет? ) подключать все физические сервера не к одному, а к двум коммутаторам. Каждый из коммутаторов запитан от двух независимых power grid, соединен с двумя или более коммутаторами ядра/аггрегации