
Решаемые задачи
Основных задач две – это бинарная классификация и мультиклассовая классификация. Бинарная классификация даёт нам ответ, интересен вообще этот документ, или он вообще не в тему и читать его не стоит. Здесь мы имеем перекос по размерам классов примерно 1 к 20, то есть – на один хороший документ приходится двадцать негодных. Но и сама обучающая выборка проблемная – в ней присутствуют шумы как по полноте, так и по точности. Шум по полноте – это когда не все хорошие, годные документы размечены как хорошие (FalseNegative), а шум по точности – когда не все размеченные хорошими документы на самом деле хорошие (FalsePositive).
Мультиклассовая классификация ставит перед нами задачу определить тематику документа и отнести его к одному из сотни тематических классов. Обучающая выборка по этой задаче сильно зашумлена по полноте, но довольно чиста по точности – всё таки разметка идёт только вручную, не как в первом случае – на эвристиках. Но зато, благодаря большому числу классов, мы начинаем наслаждаться сильными перекосами по количеству документов на класс. Максимальный зафиксированный перекос – более 6-ти тысяч. То есть, когда в одном классе документов больше, чем в другом, в 6-ть тысяч раз. Просто потому, что во втором классе лежит один документ. Единственный. Но это не самый большой из доступных перекосов, поскольку есть классы, в которых лежит ноль документов. Ну, ассесоры не нашли подходящих документов – вертись как знаешь.
То есть, наши проблемы таковы:
- Зашумлённые обучающие выборки;
- Сильные перекосы по размерам классов;
- Классы, представленные малым числом документов;
- Классы, в которых вообще документов нет (но работать с ними надо).
Решать эти задачи мы будем последовательно, разработав один классификатор – сигнатурный, потом другой – закрывающий слабые места первого – шаблонный, а потом отполируем это всё машинным обучением в виде xgboostи регрессии. И поверх этого ансамбля моделей накатим метод, закрывающий недостатки всех перечисленных – а именно метод работы без обучающих выборок вообще.
Дистрибутивная семантика (Word2Vec)
Гугль и Яндекс знают, какой пост показывать первым, когда люди спрашивают про Word2Vec. Поэтому дадим краткую выжимку из того поста и уделим внимание тому, о чём там не написано. Разумеется, есть другие хорошие методы в разделе дистрибутивной семантики – GloVe, AdaGram, Text2Vec, Seq2Vec и другие. Но каких-то сильных преимуществ по сравнению с W2V в них я не увидел. Если научиться работать с векторами W2V, можно получать удивительные результаты.
Word2Vec:
- Обучается без учителя на любых текстах;
- Ставит каждому токену в соответствие вектор действительных чисел, такой, что:
- Для любых двух токенов можно определить метрику* расстояния между ними (косинусная мера);
- Для семантически связанных токенов расстояние оказывается положительным и стремится к 1:
- Взаимозаменяемые слова (модель Skipgram);
- Ассоциированные слова (модель BagofWords).
* На самом деле – нет
Взаимозаменяемые слова
Enter word or sentence (EXIT to break): кофе
коффе 0.734483
чая 0.690234
чай 0.688656
капучино 0.666638
кофн 0.636362
какао 0.619801
эспрессо 0.599390
Ассоциированные слова
Enter word or sentence (EXIT to break): кофе
зернах 0.757635
растворимый 0.709936
чая 0.709579
коффе 0.704036
mellanrost 0.694822
сублемированный 0.694553
молотый 0.690066
кофейные 0.680409
Обобщение нескольких слов (A+B)
Enter word or sentence (EXIT to break): мобильный телефон
сотовый 0.811114
телефона 0.776416
смартфон 0.730191
телфон 0.719766
мобильного 0.717972
мобильник 0.706131
Проецирование отношений (A-B+С)
Найти такое слово, которое относится к украине так-же, как доллар относится к сша (то есть – что является валютой украины?):
Enter three words (EXIT to break): сша доллар украина
гривне 0.622719
долар 0.607078
гривны 0.597969
рубля 0.596636
Найти такое слово, которое относится к germany так-же, как франция относится к france (то есть – перевод слова germany):
Enter three words (EXIT to break): france франция germany
германия 0.748171
англия 0.692712
нидерланды 0.665715
великобритания 0.651329
Преимущества и недостатки:
Учится быстро на неподготовленных текстах:
- 1.5 месяца на 100 Гб обучающий файл, модели BagOfWords и Skipgram, на 24-х ядрах;
- Снижает размерность:
- 2.5 млн. токенов словарь ужимается до 256 элементов вектора действительных чисел;
- Векторные операции быстро деградируют:
- Результат сложения 3-5 слов уже практически бесполезен => неприменимо для обработки текстов;
Элементы вектора смысла не имеют, имеют смысл только расстояния между векторами => метрика между токенами одномерна. Этот недостаток самый обидный. Вроде-бы, имеем аж 256 действительных чисел, целый килобайт памяти занимаем, а по факту единственная нам доступная операция – сравнить этот вектор с другим таким-же, и получить косинусную меру как оценку близости этих векторов. Обработать два килобайта данных, получить 4-ре байта результата. И более ничего.
Семантический вектор
- Пример с кофе показывает, что токены группируются по смыслу (напитки);
- Необходимо сформировать достаточное число кластеров;
- Размечать кластеры нет необходимости.
Тогда, получим набор кластеров, в которых токены сгруппированы по смыслу, и, при необходимости, каждому кластеру можно присвоить метку => каждый кластер имеет независимый от других смысл.
Более подробно о построении семантического вектора рассказано в этом посте.
Сигнатура текста
Текст состоит из токенов, каждый из которых привязан к своему кластеру;
Можно подсчитать количество вхождений токена в текст и перевести в количество вхождений кластера в текст (сумма всех токенов, входящих в кластер);
В отличии от размеров словаря (2.5 млн. токенов), количество кластеров много меньше (2048) => работает эффект снижения размерности;
Перейдём от общего количества подсчитанных в тексте токенов к их относительному количеству (доле). Тогда:
- Доля не зависит от длины текста, а зависит только от частоты появления токенов в тексте => появляется возможность сравнивать тексты разной длины;
- Доля характеризует тематику текста => тематика текста определяется теми словами, которые используются;
Отнормируем доли конкретных текстов мат. ожиданием и дисперсией, вычисленными по всей базе:
Это повысит значимость редких кластеров (встречающихся не во всех текстах – например, названия) по сравнению с частыми кластерами (например – местоимения, глаголы и прочие связующие слова);
Текст определяется своей сигнатурой – вектором 2048 действительных чисел, имеющих смысл как нормированные доли токенов тематических кластеров, из которых составлен текст.
Сигнатурный классификатор
Каждому текстовому документу ставится в соответствие сигнатура;
Размеченная обучающая выборка текстов превращается в размеченную базу сигнатур;
Для исследуемого текста формируется его сигнатура, которая последовательно сравнивается с сигнатурами каждого файла из обучающей выборки;
Решение по классификации принимается на основе kNN (k ближайших соседей), где k=3.
Преимущества и недостатки
Преимущества:
Нет потерь информации от обобщения (сравнение идёт с каждым оригинальным файлом из обучающей выборки). Суть машинного обучения – найти какие-то закономерности, выделить их и работать только с ними – кардинально сокращая размеры модели по сравнению с размерами обучающей выборки. Истинные это закономерности или ложные, возникшие как артефакты процесса обучения или из-за недостатка обучающих данных – неважно. Главное в том, что исходная обучающая информация более недоступна – приходится оперировать только моделью. В случае сигнатурного классификатора мы можем себе позволить держать в памяти всю обучающаую выборку (не совсем так, об этом позже – когда пойдёт речь о тюнинге классификатора). Главное — мы можем определить, на какой именно пример из обучающей выборки похож наш документ более всего и подключить при необходимости дополнительный анализ ситуации. Отсутствие обобщения – суть отсутствие потерь информации;
Приемлемая скорость работы – порядка 0.3 секунды на прогон базы сигнатур в 1.7 млн. документов в 24 потока. И это без SIMD инструкций, но уже с учётом максимизации попаданий в кэш. И вообще – папа может в си;
Возможность выделять нечёткие дубликаты:
- Бесплатно (сравнение сигнатур и так происходит на этапе классификации);
- Высокая избирательность (анализируются только потенциальные дубли, составленные преимущественно из тех-же самых токенов, т.е. – имеющих высокую меру близости сигнатур);
- Настраиваемость (можно занизить порог срабатывания и получать не просто дубли, а тематически и стилистически близкие тексты);
Нормированность оценок (0;1];
Лёгкость пополнения обучающей выборки новыми документами (и лёгкость исключения документов из неё). Новые обучающие образы подключаются на лету – соответственно, качество работы классификатора растёт по мере его работы. Он учится. А удаление документов из базы хорошо для экспериментов, построения обучающих выборок и так далее – просто исключите из базы сигнатур сигнатуру данного конкретного документа и прогоните его классификацию – получите корректную оценку качества работы классификатора;
Недостатки:
Никак не учитывается взаимное расположение токенов (словосочетания). Понятно, что словосочетания – сильнейший классифицирующий признак;
Большие неснижаемые требования к оперативной памяти (35+ Гб);
Плохо (никак) не работает, когда на класс приходится малое количество образцов (единицы). Представим себе 256-ти мерную поверхность сферы… Нет, лучше не надо. Просто есть область, в которой должны располагаться документы интересующей нас тематики. Если в этой области довольно много точек – сигнатур документов из обучающей выборки – шансы новому документу оказаться близко с тремя из таких точек выше (kNN-же), чем если на всю область гордо горят 1-2 точки. Поэтому, шансы сработать есть даже с единственным положительным примером на класс, но шансы эти, понятное дело, реализуются не так часто, как хотелось-бы.
Точность и полнота (бинарная классификация)

Как вычислить оценку для бинарной классификации? Очень просто – берём среднее расстояние до 3-х лучших сигнатур из каждого класса (положительного и отрицательного) и оцениваем как:
Положительный/(положительный + отрицательный).
Поэтому большинство оценок лежат в очень узком диапазоне, а человекам, как обычно, хочется видеть цифры, интерпретируемые в качестве процентов. Что 0.54 – это очень хорошо, а 0.46 – очень плохо – объяснять долго и не продуктивно. Тем не менее графики выглядят хорошо, классический крест.
Тонкая настройка сигнатурного классификатора
Как видно из графика “точность и полнота” рабочая область классификатора достаточно узкая. Решение – разметить оригинальный текстовый обучающий файл, по которому учится Word2Vec. Для этого в текст документа внедряются метки, определяющие класс документа:
Как результат, кластеры располагаются в векторном пространстве не случайным образом, а разводятся так, что бы кластеры одного класса тяготели друг к другу и отстояли на максимальное расстояние от кластеров противоположного класса. Кластеры, характерные для обоих классов располагаются посередине.
Требования к памяти снижаются путём сокращения размеров базы сигнатур:
Сигнатуры обучающей выборки, содержащие излишнее количество образцов (более миллиона), последовательно кластеризуются на большое число кластеров и из каждого кластера используется одна сигнатура. Тем самым:
- Сохраняется относительно равномерное покрытие векторного пространства сигнатурами образцов;
- Удаляются сигнатуры образцов, излишне близких друг другу, и, соответственно, мало полезных для классификации.
Сигнатурный классификатор, резюме
- Быстрый;
- Легко дополняемый;
- Позволяет также обнаруживать дубликаты;
- Не учитывает взаимное расположение токенов;
- Не работает, когда в обучающей выборке мало примеров.
Шаблонный классификатор
Исправить недостатки сигнатурного классификатора призван классификатор на шаблонах. На нграммах, проще говоря. Если сигнатурный классификатор ставит тексту в соответствие сигнатуру и спотыкается, когда таких сигнатур мало, то шаблонный классификатор читает содержимое текста более вдумчиво и, если текст достаточно объёмен, даже единственного текста достаточно, что бы выделить большое количество классифицирующих признаков.
Шаблонный классификатор:
Основан на граммах длиной до 16-ти элементов:
Часть целевых текстов оформлена по стандартам (ISO). Есть много типовых элементов:
- Заголовки;
- Подписи;
- Листы согласования и архивные метки;
Часть целевых документов содержат в себе информацию по оформлению:
- Xml (включая все современные офисные стандарты);
- Html;
Практически все содержат устойчивые словосочетания, например:
- “строго конфиденциально, перед прочтением сжечь”;
Является упрощённой реализацией Наивного Баессового классификатора (без нормировки);
Генерит до 60-ти млн. классифицирующих грамм;
Работает быстро (конечный автомат).
Построение классификатора
Из текстов выделяются граммы;
Вычисляется относительная частота грамм на класс;
Если для разных классов относительная частота сильно отличается (в разы) грамма является классифицирующим признаком;
Редкие граммы, встреченные 1 раз, отбрасываются;
Обучающая выборка классифицируется, и по тем документам, по которым классификация была ошибочна, формируются дополнительные граммы, и добавляются в общую базу грамм.
Использование классификатора
Из текста выделяются граммы;
Суммируются веса всех грамм для каждого класса, к которому они относятся;
Побеждает класс, набравший наибольшую сумму весов;
При этом:
- Класс, в котором было больше обучающих текстов, формирует обычно больше классифицирующих грамм;
- Редкий класс (мало обучающих текстов) генерит мало грамм, но их средний вес выше (из-за преобладания длинных уникальных для данного класса грамм);
- Текст, в котором нет явного преобладания редких длинных грамм, будет отнесён к классу с большим числом обучающих примеров (апостериорное распределение стремится к априорному). Так работает оригинальный наивный Баесс и вообще все универсальные классификаторы;
- Текст, имеющий длинные уникальные граммы редкого класса, будет отнесён скорее к данному редкому классу (намеренно внесённое искажение в апостериорное распределение с целью повысить избирательность на редких классах). Деньги платят за результат, и чем труднее получить результат, тем больше денег. Это понятно. Самый трудный результат – это как раз редкие тематические классы. Поэтому имеет смысл исказить свой классификатор таким способом, что бы лучше искать редкие классы, пусть и проседая в качестве на больших, попсовых классах. В конце концов, с попсовыми классами прекрасно справляет сигнатурный классификатор.
Преимущества и недостатки
Преимущества:
- Относительно быстрый и компактный;
- Неплохо параллелится;
- Способен обучаться по единственному документу в обучающей выборке на класс;
Недостатки:
- Оценки ненормированы и в оригинальном виде не обеспечивают критерий pairwize (нельзя гарантировать, что оценка с большим весом более вероятна);
- Генерится огромное количество грамм с околонулевой вероятностью встретить их в реальных документах (не дублях). Но зато, встретив такую редкую грамму в документе, можно об этом документе сразу сказать много интересного. А памяти на сервере хватает – это не проблема;
- Огромные требования к памяти на этапе обучения. Да, нужен кластер, но их есть у нас (смотри поскриптум к данному посту).
Ненормированность оценок
Почему:
Нет необходимости делать нормировку – сильное упрощение кода;
Ненормированные оценки содержат больше потенциально доступной для классификации информации.
Как использовать:
Оценки классификатора являются хорошими признаками для использования в универсальных классификаторах (xgboost, SVM, ANN);
При этом, универсальные классификаторы сами определяют оптимальную величину нормировки.
Итоговый обобщённый классификатор (мультикласс)
Ответы сигнатурного и шаблонного классификаторов объединяются в единый вектор признаков, который подвергается дополнительной обработке:
- Нормировка оценок к единице, для получения их относительной доли на класс;
- Группировка редких классов для получения достаточного числа обучающих примеров на группу;
- Взятие разности групповых оценок для получения более пологой поверхности для градиентного спуска.
По результирующему вектору признаков строится модель xgboost, дающая прирост точности в пределах 3% к точности оригинальных классификаторов.
Бинарный обобщённый классификатор
Суть регрессия от:
- Сигнатурного классификатора:
- Шаблонного классификатора:
- XgBoost на выходах сигнатурного и шаблонного классификатора.
Критерий оптимизации – максимум площади под произведением полноты на точность на отрезке [0;1] при этом, выдача классификатора не попадающая в отрезок считается ложным срабатыванием.
Что даёт:
Максимизирует рабочую область классификатора. Человеки видят привычную оценку в виде процентов, от нуля до ста, при этом, эта оценка ложится так, что бы максимизировать и полноту и точность. Понятно, что максимум произведения находится в области креста, где и полнота и точность не обладают слишком маленькими значениями, а вот области справа и слева, где высокая полнота умножается на никакую точность и где высокая точность умножается на никакую полноту – неинтересны. За них денег не платят;
Отбрасывает часть примеров в область ниже нуля => является сигналом, что классификатор не в состоянии отработать данные примеры => классификатор даёт отказ. С инженерной точки зрения это вообще отличная способность – классификатор сам честно предупреждает, что да, в отброшенном потоке есть 1-2% хороших документов, но сам классификатор с ними работать не умеет – используйте другие методы. Или смиритесь.
Бинарный обобщённый классификатор, 1:20
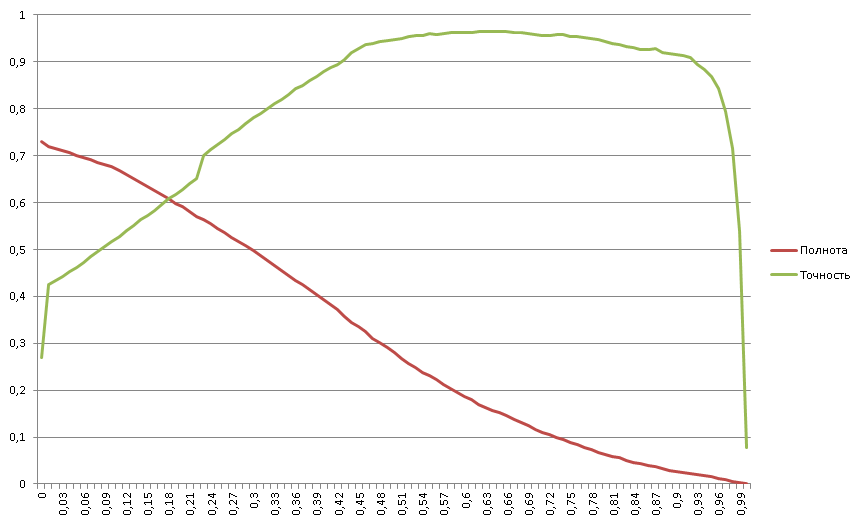
Шикарный график, особенно радует завал справа. Напоминаю, что у нас тут соотношение положительных примеров в потоке в двадцать раз меньше, чем отрицательных. Тем не менее, график полноты выглядит вполне канонично – выпукло-вогнутый с точкой перегиба посередине, в районе 0.3. Почему это важно, покажем дальше.
Бинарный обобщённый классификатор, 1:20, Анализ
Полнота начинается с 73% => 27% всех положительных примеров не могут быть эффективно отработаны классификатором. Эти 27% положительных примеров оказались в области ниже нуля именно из-за проводимой оптимизации регрессии. Для бизнеса лучше сообщить, что не умеем работать с этими документами, чем дать на них ложноотрицательные срабатывания. Зато рабочая область классификатора начинается с почти 30% точности – а это те цифры, которые уже нравятся бизнесу;
Наличествует завал точности от 96% до 0% => в выборке есть порядка 4% примеров, размеченных как негативные, хотя на самом деле они позитивные (проблема полноты разметки);
Явно видны пять областей:
- Область отказа классификатора (менее нуля);
- две квазилинейные области;
- Область насыщения (максимальная эффективность);
- Область завала (проблема полноты разметки).
Деление на области даёт возможность разработать дополнительные средства классификации для каждой из областей, особенно для 1-й и 5-й.
Бинарный обобщённый классификатор, 1:182
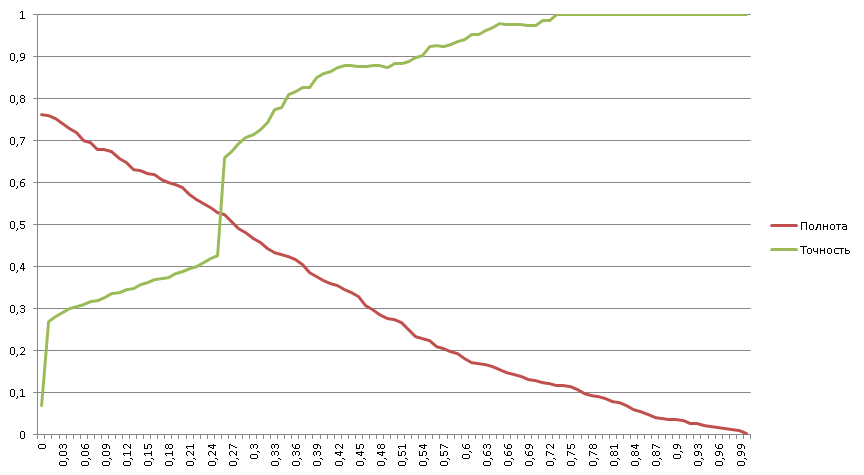
Тут мы решаем ту же задачу бинарной классификации, но при этом на один положительны пример приходится уже 182 отрицательных.
Бинарный обобщённый классификатор, 1:182, Анализ
Полнота начинается с 76% => 24% всех положительных примеров не могут быть эффективно отработаны классификатором;
12% всех положительных примеров однозначно узнаются классификатором (100% точность);
Явно видны четыре области:
- Область отказа классификатора (менее нуля);
- две квазилинейные области;
- Область 100% точности.
График полноты вогнут без точек перегиба => классификатор обладает высокой избирательностью (соответствует правой части классического графика полноты с точкой перегиба посередине).
Построение классификатора для классов, у которых нет обучающих примеров
Реальность такова, что существует достаточно большое количество классов, к которым не размечено ни одного документа, и единственная доступная информация – это сообщение Заказчика, какие именно документы он желает классифицировать в данный класс.
Построение обучающей выборки вручную невозможно, поскольку на 1.7 млн. имеющихся в базе документов можно ожидать только несколько документов, подпадающих под данный класс, а возможно – и не одного.
Класс “Маркетинговые исследования косметики”
Из анализа названия класса мы видим, что Заказчику интересны документы, имеющие отношение к “Маркетинговые исследования” и “Косметика”. Для обнаружения таких документов необходимо:
Сформировать семантическое ядро из текстов по заданным тематикам, при этом, на всех представляющих интерес языках;
Найти те тематики, которые не имеют отношения к заданному классу – их использовать в качестве негативных примеров (например – политика);
Найти в базе документов несколько образцов документов, которые имеют частичное либо точное отношение к заданному классу;
Разметить найденные документы силами ассесоров Заказчика;
Построить классификатор.
Сборка семантического ядра текстов.
Идём в википедию и находим статью которая называется, как ни странно,“маркетинговые исследования”. Внизу там есть неприметная ссылочка «категории». В категориях даны все статьи Википедии по данной тематике и вложенные категории со своими статьями. В общем – богатый источник тематических текстов.
Но и это не всё. Справа в меню лежат ссылки на аналогичные статьи и категории на других языках. Тексты той-же тематики, но на интересующих нас языках. Или на всех подряд – классификаторы сами разберутся.
Использование семантических ядер
У нас есть три тематики:
- Маркетинговые исследования;
- Косметика;
- Политика.
Используем шаблонный классификатор на данные три класса. Обработаем все документы в базе документов и получим:
- Маркетинговые исследования 20%;
- Косметика 6%;
- Политика 74%.
Данные доли не показывают фактическое распределение документов по тематикам, они показывают только средние веса признаков каждого класса, выделенных шаблонным классификатором.
Однако, если исследуется документ, имеющий распределение долей 30%, 20%, 50% о таком документе можно утверждать, что он содержит больше признаков текста с заданными тематиками против негативной тематики (политика), соответственно – данный текст потенциально интересен:
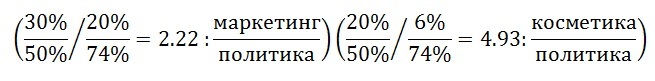
Результаты поиска документов
В результате обработки всей базы документов было выделено ~80 документов, из которых: Два оказались имеющими полное соответствие классу:
- не были найдены ранее при обработке документов вручную;
- На разных языках, отличных от языка точки входа в семантическое ядро (русского);
~36 % всех найденных документов имеют частичное отношение к классу;
Остальные не имеют отношения к классу вообще.
Важно, что в результате оценки получена размеченная выборка ~80 документов, содержащих как позитивные, так и негативные примеры.
Построение классификатора
Более 60% ложных срабатываний сигнализируют о том, что одной политики в качестве негативного примера недостаточно.
Решение:
Найти автоматическим способом другие тематики текстов, которые могут использоваться в качестве негативных и, потенциально, позитивных примеров. Для этого:
Сформировать автоматически наборы текстов на большое количество тематик и выделить те из них, что коррелируют (негативно или положительно) с размеченной выборкой ~80 документов.
Онтология DBPedia
Если кто-то ещё не знает, вся Википедия уже любезно распаршена и разложена по файликам в формате RDF. Бери и пользуйся. Представляют интерес:
- ShortAbstracts – краткая аннотация статьи;
- LongAbstracts – длинная аннотация статьи;
- Homepages – ссылки на внешние ресурсы, домашние страницы;
- Article Categories – категория страницы;
- Categorylabels – читаемые названия категорий;
- Externallinks – ссылки на внешние ресурсы по теме;
- Interlanguagelinks – Эта же статья на других языках.
Стоит помнить, что в качестве источника текстов для машинной лингвистики DBPedia не заменяет Википедию, так как размер аннотации обычно – 1-2 параграфа, и ни в какое сравнение не идёт с большинством статей по объёмам. Но никто не запрещает выкачать понравившиеся статьи и их категории из Википедии в дальнейшем, правильно?
[Ожидаемые] результаты поиска коррелированных тематик в DBPEdia
Результатом поиска коррелированных тематик будут являться:
- Наборы текстов на всех языках по заданным тематикам;
- Оценка степени коррелированности текстов по отношению к классу;
- Человекочитаемое (словестное) описание тематик.
При этом, коррелированные тематики зависят не только от класса “Маркетинговые исследования косметики”, но и от тематик документов, содержащихся в базе (для тематик с отрицательной корреляцией). Что позволяет использовать найденные тематики:
- для ручного построения классификаторов на другие темы;
- как дополнительные признаки для текстов, классифицируемых итоговым обобщённым классификатором;
- Для создания дополнительных измерений метрик подобия текстов в векторном пространстве сигнатурного классификатора: тут я отсылаю к своей статье в сборнике Диалога 2015 года по обучению по аналогии в смешанных онтологических сетях. И к соответствующему посту.
Постскриптум
Данный пост показал те технологии, которые мы используем в настоящий момент и куда мы планируем двигаться в дальнейшем (а это онтологии). Пользуясь случаем хочу сказать, что в мою группу набираем людей, начинающих/продолжающих изучать машинную лингвистику, особенно рады студентам/выпускникам сами знаете каких вузов.
Комментарии (20)


elingur
24.03.2017 10:01Вопрос:
2.5 млн. токенов словарь ужимается до 256 элементов вектора действительных чисел;
— это принудительно сжать, типа k-mean-ом? Или более хитро?
ServPonomarev
24.03.2017 10:55Это основное свойство Word2Vec — он каждому токену ставит в соответствие вектор. И неважно, сколько всего токенов. Хоть десятки миллионов (больше 26-ти в оригинале не потянет — хеш таблица кончится). А размер вектора задаётся в настройках. По моему опыту и кое-каким публикациям, для векторов выше 200-т элементов практически заметная разница уже отсутствует.
kdenisk
24.03.2017 14:00Если в оригинальном корпусе было 2.5 миллиона токенов (грубо — словоформ), то и word2vec выдаст вам словарь размером в 2.5 миллиона токенов. Другое дело, что если построить матрицу совстречаемости слов в корпусе, то её размер будет 2.5M x 2.5M и работать с таким объёмом не удобно (если вообще возможно).
Алгоритм w2v ужимает матрицу совстречаемости токенов в 2.5M x 256, при этом сохраняя меру семантической близости. Если эспрессо и капучино часто встречаются в похожих контекстах, то косинусное расстояние между их w2v-векторами будет заметным (чем ближе токены по контекстам, тем ближе к единице).
P.S. word2vec предполагает контекстную близость, а семантическая является приятным побочным эффектом, выражаемым фразой:
A word is known by the company it keeps (Firth, J. R. 1957)
ServPonomarev
24.03.2017 14:52Я, как инженер, смотрю на полезность, которую мне даёт инструмент. Может семантическая близость и есть артефакт контекстной близости, но она есть и с ней можно работать.
kdenisk
24.03.2017 14:59Да, это я сформулировал неудачно) Мысль была в том, что сам алгоритм считает контекстную близость, но язык так устроен, что контекстная близость оказывается довольно близкой к семантической.
Просто тем, кто не сталкивался с w2v, может показаться, что машина понимает смысл слов. А по факту мы имеем дело с голой математикой, даже и с лингвистикой не связанной напрямую.ServPonomarev
24.03.2017 15:01+2Парадокс китайской комнаты. Я лично не уверен, что у нас в мозгу существенно сложнее всё устроено. По крайней мере в неокортексе.
kdenisk
24.03.2017 16:32Похоже, что у нас в голове действительно есть статистический анализатор похожий на w2v. Например когда читаешь корявый текст и чётко видишь — эти два слова не сочетаются.
Но текст является глубоко вторичным к смыслам и первообразам, которые хранятся у нас в голове совершенно непонятно как. Не зря, читая художественную литературу нам так просто понять значение слова, употреблённого в переносном смысле, просто нарисовав в голове картинку-образ. Машины к этому пока даже не подступились.
Не говоря уже о том, что следуя теореме Гёделя о неполноте, можно сделать вывод о том, что наше мышление не алгоритмично своей природе. (замечательная книга на тему — Роджер Пенроуз. Новый ум короля)elingur
25.03.2017 14:13Все верно. Я бы назвал это не семантической близостью, а ассоциативной (ассоциативно-семантической, ассоциативно-синтаксической). По этому принципу работает не только «понимание», но и распознавание речи, например, модель когорты. Мышление не алгоритмично, потому что не логично в рамках формальной логики. Но дело не только в «первообразах», но и причине их выбора из множества почти одинаковых. Неокортекс отвечает за отработку уже обозначенной доминанты, причина возникновения которой уже где-то в паралимбической области (про это книга Свердлик: Как эмоции влияют на абстрактное мышление ...). Т.е. кора — это необходимое условие мышления, но далеко не достаточное.
kdenisk
24.03.2017 13:26Удивился, почему так долго обучалась модель. (У меня такой объём считался всего пару дней.) Потом понял: вы почему-то не стали снимать морфологию и это привело к гигантскому росту словаря (в среднем x25 — x40), а следовательно и росту времени обсчёта модели.
Можете объяснить, почему решили не делать нормализацию текста и считать на базовых формах?ServPonomarev
24.03.2017 15:00+1Есть слово «уважение», есть токен «уважением,». Довольно сильно различные в качестве признаков. Есть «периметр», есть «Периметр» (которая система мёртвой руки). Есть очень характерные опечатки, по которым можно легко устанавливать авторство текста (меня так вычисляли кое-где по характерной для меня «что-бы»). Даже есть разница между «Москва» и «Москва.». В общем, приведение к нижнему регистру, отлепление знаков препинания, лемматизация и стемминг — в первую очередь это необратимая потеря информации, а соответственно — занижение теоретически доступного максимального качества классификации.
Но главное — такие методы как LSA, LDA и им подобные очень плохо себя чувствуют на больших словарях, а потому для их использования проводить нормализацию, отсекать низкочастотные слова (а всякие коды, имена собственные, жаргонизмы — это очень сильные признаки) необходимо, и это — вынужденная мера, от бедности.
Здесь мы можем себе позволить работать с полным словарём.kdenisk
24.03.2017 15:18Спасибо за исчерпывающий ответ! Насколько понимаю вы работаете с документами и отсюда специфика с нежелательностью отсечения низкочастотных токенов.

vba
24.03.2017 13:47Добрый день, спасибо за объемный пост. Мы пару тройку лет назад использовали Max Entropy (и эту библиотеку) классификаторы, для авто классификации юр текстов. В целом тогда это было очень даже перспективное направление.
Скажите а не знакомы ли вам техники классификации когда нужно выбрать не одну а несколько категорий, например фильмы могут быть комедиями и мелодрамами одновременно? Заранее благодарен.
ServPonomarev
24.03.2017 15:07В мультиклассовой классификации мы всегда на выходе имеем не единственный класс в качестве ответа, а сортированный вектор, в котором все классы отсортированы по оценке. Никто не препятствует нам брать не только первый элемент этого вектора (то есть — класс с максимальной оценкой), а первые несколько элементов. При этом, если первый существенно выше второго — то у нас получается единственный класс, а если первый и второй близко друг к другу (и отстают на заметное расстояние от остальных) — то можно утверждать, что документ принадлежит к обоим классам (к какому-то больше, к какому-то меньше — тут вопрос, как настроить пороги).
Ananiev_Genrih
24.03.2017 19:20+2Сергей, добрый день.
Затронули очень болезненную для меня тему.
Дико извиняюсь что написал ниже много букв, но без такой вводной не смогу получить правильного ответа.
У нас текущий бизнес процесс сильно завязан на классификацию мастер-данных (справочников), если чуть детальней-то речь про работу с вином: ежедневно приходит массив грязных зашумленных данных от внешних поставщиков информации о продажах вин в крупнейших розничных сетях по всей России с детализацией до точки продаж. Речь не только про продажи Российских вин, а о всех винах вообще (со всего мира).
Операторы получают новые вариации названий вин ежедневно и должны их классифицировать, т.е. правильно привязать в справочниках новые объекты на вина заведенный в стандартах нашей компании (а если не нашлось ничего похожего то создать такой класс и привязать к этому созданному)
Естественно поток информации настолько велик, что приходится задейстовать машинное обучение: там где модель уверенна выше чем на 99%, то классификация происходит автоматически, там где модель уверенна ниже- она участвует в системе в роли рекомендательного алгоритма с которым оператор либо соглашается либо нет.
Итого сейчас у нас 31925 классов, из них пустых (то о чем Вы писали -не разметили еще ассесоры)= 1761
Дисбаланс классов на картинке ниже

Отличие от классических задач текст-майнинга в следующем:
Вина именуются в системах наших сетевых ритейлеров чаще всего на кириллице как правило из франко-итальянских словоформ с "трудностями перевода" — где-то двойные буквы, где то одинарные(напр. количество букв "с" подряд может быть в любом месте произвольным: Вино игристое Ламбруско ТМ Массимо Висконти бел.слад. 0,75*6 Италия /Аква Вита ТК/)-решается регулярками
Длина строки при вводе в систему у сетевых ритейлеров ограничена и их операторы что бы уместиться не теряя общего смысла начинают сокращать (например приходит к нам такой вот треш: "Вин.ПР.РОБ.РИБ.Д.ДУЭ.ДО кр.сух.0.75л" который становится у нас в классе "Вино Протос Робле Рибера дель Дуэро кр сух 0,75")- решается Гуглом и вангованием на стеклянном шаре с привлечением Астрологов
Очень много шума в тексте (импортеры, сетевой артикул и т.д.) -решается поддержкой списка стоп-слов
Слияния слов (AVESвиноМЕРЛО МаулеВелле кр.сух.0.75л)-решается регулярками
Разная степень сокращений ключевых для моделей термов ({красн, кр, крас};{п/сл, полусл, п-слад},{крпсл}) — решается регулярками
- Разная степень сокращений важных для моделей термов (Молоко любимой женщины; Мол.люб.жен...) — тут стеммер Портера приказал долго жить (из-за вышеописанных проблем), писал свой алгоритм обучения по термам, который рекурсивно ищет цепочку предок-наследник для термов с высокой степенью вероятности сокращенных до своих наследников и выдает на выходе такой вот справочник автозамены — "взять term и заменить на abbr отбросив цепочки с неоднозначными вариантами сокращений (там где может быть несколько разных предков)":

Далее по классике: токенизация, document-term matrix, tfidf, и удаление sparce-термов которые встречаются лишь в одном документе (не важно-в обучающей или предсказательной части матрицы).
И тут еще одна проблема: высокочастотные термы (красное, белое, розовое, сладкое, полусладкое, сухое, 0.75, 0.7, и т.д.) которые по понятным причинам имеют самый низкий tfidf оказывают решающую роль в классификации: если в векторном представлении бренды/винодельни или провиции произростания совпали но цвет вина или емкость оказались другими. то последствия такой ошибки классификации высоки — это мастер-данные к которым привязываются в системе продажи (в виде большого числа транзакций) и одна ошибка в цвете/емкости/сахарности транслируется многократно в отчетности.
Поэтому ничего не остается как такие ключевые высокочастотные термы с tfidf стремящимся к нулю докручивать до значений = 10000, что бы их вес был решающим.
Далее уже алгоритмы классификации: один — свой самописный (который возвращает еще и меру сходства с классом) и еще LIBLINEAR
Собственно сам вопрос:
можно ли из вышеописанных алгортимов Вашей статьи взять какую то часть на вооружение и улучшить текущий процесс с учетом вышеописанных проблем?ServPonomarev
24.03.2017 19:52Нет, нельзя. Причина, насколько я понял задачу, в том, что основная проблема — искажения слов (транслитерация, сокращения, ошибки). А это суть разные токены.
Вашу задачу я бы решал через расстояние редактирования (Левенштейна). То есть, есть полные названия вин, производителей, объёмы, градусы и другая должнествующая быть информация. Есть некий код, который пришёл из региона и который и человеку не всегда легко разобрать. Следует высчитать расстояние редактирования для всех обязательных полей и просуммировать результаты. Чем меньше сумма, тем лучше. Значит — нашлись все необходимые поля с хорошей достоверностью. Первую часть проблемы — взаимное расположение значимой информации мы уже сняли, не важно, где указан, к примеру, объём — важно, что он нашёлся.
Расстояние редактирования вычислять по словам (ну, или тому, что на них похоже), при этом:
1. штраф за вставку/удаление слов в крайних позициях — минимален (нулевой). Это позволяет нам искать нужные соответствия по всему тексту, вне зависимости от его фактического расположения;
2. штраф за удаление/вставку внутри последовательности — высокий (мол люб жен — не должен транслироваться в молодой женьшень, к примеру. Люб — значимое слово, его не просто так туда написали).
3. Стоимость замены слов. Если слова похожи на сокращения (укороченная первая часть слова, может быть с точкой), похожи на опечатки, на кривую транслитерацию — то штраф за такую замену низкий, если не похожи — высокий. При этом, факт похожести слова на сокращение, опечатку или кривую транслитерацию определяется тем же алгоритмом расстояния редактирования, но уже не на словах, а на буквах.
Хорошо то, что можно взять уже размеченные вручную соответствия, прогнать их указанным алгоритмом расстояния редактирования, и автоматически набрать словарь типовых сокращений, опечаток, транслитерации. И даже определить размеры штрафов. То есть — получается классическая задача машинного обучения на размеченной выборке.
kdenisk
24.03.2017 21:08Вопрос в практической плоскости:
«Критерий оптимизации – максимум площади под произведением полноты на точность на отрезке [0;1] при этом, выдача классификатора не попадающая в отрезок считается ложным срабатыванием.»
Каким образом задавали такой objective для XGBoost, писали пользовательскую целевую функцию?ServPonomarev
24.03.2017 21:16+1XGboost отработал на предыдущем шаге. А тут мы берём результаты трёх классификаторов, и делаем регрессию вида:
R = a1 + a2C1 + a3C2 + a4C3, где C1,C2,C3 — выходы соотвествующих классификаторов, а a1-4 — параметры.
При этом, один из классификаторов — это сигнатурный, с очень узкой рабочей областью (допустим это C2).
Регрессия получается вида
R = -10 + 0.6C1 + 21C2 + 1.1C3
Узкая область сигнатурного классификатора растянута, и сдвинута примерно так, что бы соответствовать отрезку [0;1]. Без регрессии комбинировать узкий сигнатурный, широкий xgboost и средний шаблонный было бы трудно
zodiak
Вот тут вы что-то недоговариваете…
Предположу что 1.5 месяца вы обучаете модель если исходные документы вытягиваете в 1 строчку и проходите по ним гигантским окном слов в 15+
Грешен, сам ставил похожие опыты. Обучение на ~170Гб текста (книги, википедия, поисковые запросы — все вперемешку) одной модели с окном 5-7 слов и размером вектора 500 занимало не больше недели на макбуке.
P.S.
Макбук кипел и его было жалко
ServPonomarev
Почти угадали. размер окна — 16-ть элементов. И не забывайте, что Bag of Words делается примерно в 4-ре раза медленнее Skipgram.