

Напомню: мы закончили на том, что наш классификатор считал идею пойти в итальянский ресторан в 5 раз лучше, чем в мексиканский.
Проводим количественный анализ проблемы
Хотелось бы понять, как избежать подобной ситуации в будущем. Давайте обработаем нашей системой дополнительные данные и статистически измерим величину предубеждения.
Составим четыре списка имен, которые ассоциируются с людьми (жителями США) различного этнического происхождения. Первые два списка — распространенные имена белых и чернокожих людей, взятых из статьи Принстонского университета. Добавляю испаноязычные имена и имена, распространенные в исламской культуре (преимущественно из арабского и языка урду), т. е. еще две группы имен, достаточно сильно связанных с их этнической группой.
Сейчас эти данные используют для проверки предубежденности в процессе формирования
ConceptNet. Они содержатся в модуле conceptnet5.vectors.evaluation.bias. Мне хотелось бы добавить и другие этнические группы. Для этого может потребоваться учитывать не только имена, но и фамилии.NAMES_BY_ETHNICITY = {
# The first two lists are from the Caliskan et al. appendix describing the
# Word Embedding Association Test.
'White': [
'Adam', 'Chip', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Ian', 'Justin',
'Ryan', 'Andrew', 'Fred', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Jed',
'Paul', 'Todd', 'Brandon', 'Hank', 'Jonathan', 'Peter', 'Wilbur', 'Amanda',
'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Crystal', 'Katie',
'Meredith', 'Shannon', 'Betsy', 'Donna', 'Kristin', 'Nancy', 'Stephanie',
'Bobbie-Sue', 'Ellen', 'Lauren', 'Peggy', 'Sue-Ellen', 'Colleen', 'Emily',
'Megan', 'Rachel', 'Wendy'
],
'Black': [
'Alonzo', 'Jamel', 'Lerone', 'Percell', 'Theo', 'Alphonse', 'Jerome',
'Leroy', 'Rasaan', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Rashaun',
'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Everol',
'Lavon', 'Marcellus', 'Terryl', 'Wardell', 'Aiesha', 'Lashelle', 'Nichelle',
'Shereen', 'Temeka', 'Ebony', 'Latisha', 'Shaniqua', 'Tameisha', 'Teretha',
'Jasmine', 'Latonya', 'Shanise', 'Tanisha', 'Tia', 'Lakisha', 'Latoya',
'Sharise', 'Tashika', 'Yolanda', 'Lashandra', 'Malika', 'Shavonn',
'Tawanda', 'Yvette'
],
# This list comes from statistics about common Hispanic-origin names in the US.
'Hispanic': [
'Juan', 'Jose', 'Miguel', 'Luis', 'Jorge', 'Santiago', 'Matias', 'Sebastian',
'Mateo', 'Nicolas', 'Alejandro', 'Samuel', 'Diego', 'Daniel', 'Tomas',
'Juana', 'Ana', 'Luisa', 'Maria', 'Elena', 'Sofia', 'Isabella', 'Valentina',
'Camila', 'Valeria', 'Ximena', 'Luciana', 'Mariana', 'Victoria', 'Martina'
],
# The following list conflates religion and ethnicity, I'm aware. So do given names.
#
# This list was cobbled together from searching baby-name sites for common Muslim names,
# as spelled in English. I did not ultimately distinguish whether the origin of the name
# is Arabic or Urdu or another language.
#
# I'd be happy to replace it with something more authoritative, given a source.
'Arab/Muslim': [
'Mohammed', 'Omar', 'Ahmed', 'Ali', 'Youssef', 'Abdullah', 'Yasin', 'Hamza',
'Ayaan', 'Syed', 'Rishaan', 'Samar', 'Ahmad', 'Zikri', 'Rayyan', 'Mariam',
'Jana', 'Malak', 'Salma', 'Nour', 'Lian', 'Fatima', 'Ayesha', 'Zahra', 'Sana',
'Zara', 'Alya', 'Shaista', 'Zoya', 'Yasmin'
]
}С помощью Pandas преобразуем эти данные (имена, наиболее характерное происхождение и получаемая для них оценка тональности) в таблицу.
def name_sentiment_table():
frames = []
for group, name_list in sorted(NAMES_BY_ETHNICITY.items()):
lower_names = [name.lower() for name in name_list]
sentiments = words_to_sentiment(lower_names)
sentiments['group'] = group
frames.append(sentiments)
# Put together the data we got from each ethnic group into one big table
return pd.concat(frames)
name_sentiments = name_sentiment_table()
Теперь можно наглядно представить распределение оценок тональности, которую система выдает для каждой группы имен.
plot = seaborn.swarmplot(x='group', y='sentiment', data=name_sentiments)
plot.set_ylim([-10, 10])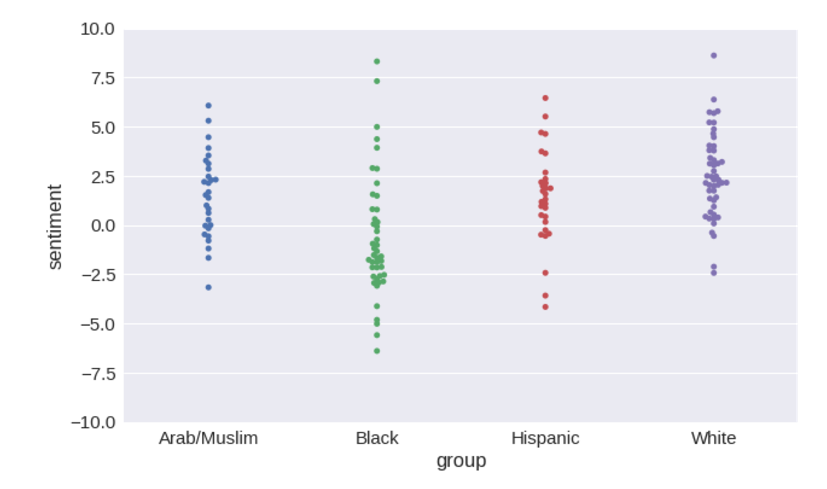
Распределения можно преобразовать в столбчатые диаграммы с доверительным интервалом в 95 % вокруг средних значений.
plot = seaborn.barplot(x='group', y='sentiment', data=name_sentiments, capsize=.1)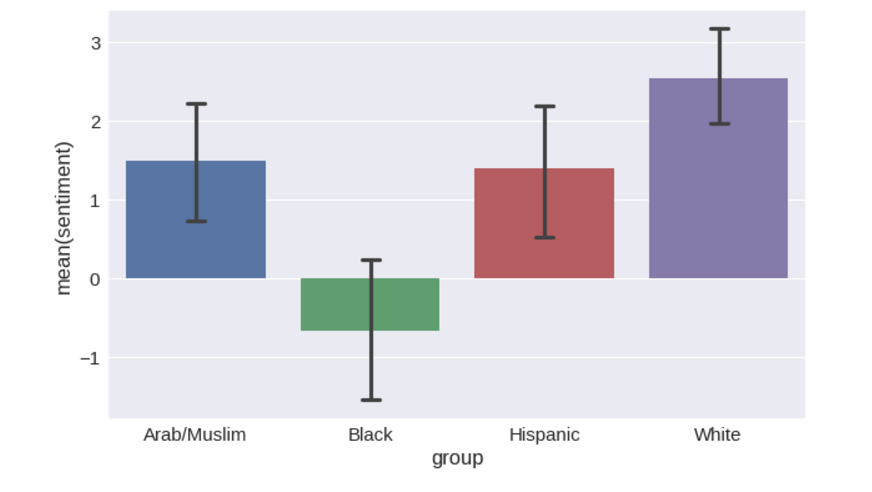
И наконец, мы можем обработать эти данные мощными статистическими инструментами пакета
statsmodels, чтобы узнать в числе прочего, насколько выражен наблюдаемый эффект.ols_model = statsmodels.formula.api.ols('sentiment ~ group', data=name_sentiments).fit()
ols_model.fvalue
# 13.041597745167659F-мера (F-statistic) — это метрика, позволяющая одновременно оценить точность и полноту модели (подробнее тут). Ее можно использовать для оценки общей предубежденности в отношении различных этносов.
Наша задача — улучшить значение F-меры. Чем оно ниже, тем лучше.
Исправляем данные
Итак, мы научились измерять уровень предубежденности, который скрыт в наборе векторных значений слов. Попробуем улучшить эту величину. Для этого повторим ряд операций.
Если бы нам было важно написать хороший и удобный в поддержке код, то использовать глобальные переменные (например,
model и embeddings) не стоило бы. Но необработанный исследовательский код имеет большое достоинство: он позволяет нам отследить результаты каждого этапа и сделать выводы. Постараемся не делать лишней работы, напишем функцию, которая будет повторять некоторые сделанные операции.def retrain_model(new_embs):
"""
Repeat the steps above with a new set of word embeddings.
"""
global model, embeddings, name_sentiments
embeddings = new_embs
pos_vectors = embeddings.loc[pos_words].dropna()
neg_vectors = embeddings.loc[neg_words].dropna()
vectors = pd.concat([pos_vectors, neg_vectors])
targets = np.array([1 for entry in pos_vectors.index] + [-1 for entry in neg_vectors.index])
labels = list(pos_vectors.index) + list(neg_vectors.index)
train_vectors, test_vectors, train_targets, test_targets, train_labels, test_labels = train_test_split(vectors, targets, labels, test_size=0.1, random_state=0)
model = SGDClassifier(loss='log', random_state=0, n_iter=100)
model.fit(train_vectors, train_targets)
accuracy = accuracy_score(model.predict(test_vectors), test_targets)
print("Accuracy of sentiment: {:.2%}".format(accuracy))
name_sentiments = name_sentiment_table()
ols_model = statsmodels.formula.api.ols('sentiment ~ group', data=name_sentiments).fit()
print("F-value of bias: {:.3f}".format(ols_model.fvalue))
print("Probability given null hypothesis: {:.3}".format(ols_model.f_pvalue))
# Show the results on a swarm plot, with a consistent Y-axis
plot = seaborn.swarmplot(x='group', y='sentiment', data=name_sentiments)
plot.set_ylim([-10, 10])Проверка word2vec
Вы можете предположить, что проблема заключена в наборе данных
GloVe. В основе этого архива — все сайты, которые обрабатывает робот Common Crawl (в том числе множество весьма сомнительных, а еще примерно 20 копий Urban Dictionary, словаря городского жаргона). Может быть, проблема в этом? Что, если взять старый добрый word2vec, результат обработки Google News?Самый надежный источник файлов
word2vec, который удалось найти, — вот этот файл в Google Drive. Скачаем и сохраним его как data/word2vec-googlenews-300.bin.gz.# Use a ConceptNet function to load word2vec into a Pandas frame from its binary format
from conceptnet5.vectors.formats import load_word2vec_bin
w2v = load_word2vec_bin('data/word2vec-googlenews-300.bin.gz', nrows=2000000)
# word2vec is case-sensitive, so case-fold its labels
w2v.index = [label.casefold() for label in w2v.index]
# Now we have duplicate labels, so drop the later (lower-frequency) occurrences of the same label
w2v = w2v.reset_index().drop_duplicates(subset='index', keep='first').set_index('index')
retrain_model(w2v)
# Accuracy of sentiment: 94.30%
# F-value of bias: 15.573
# Probability given null hypothesis: 7.43e-09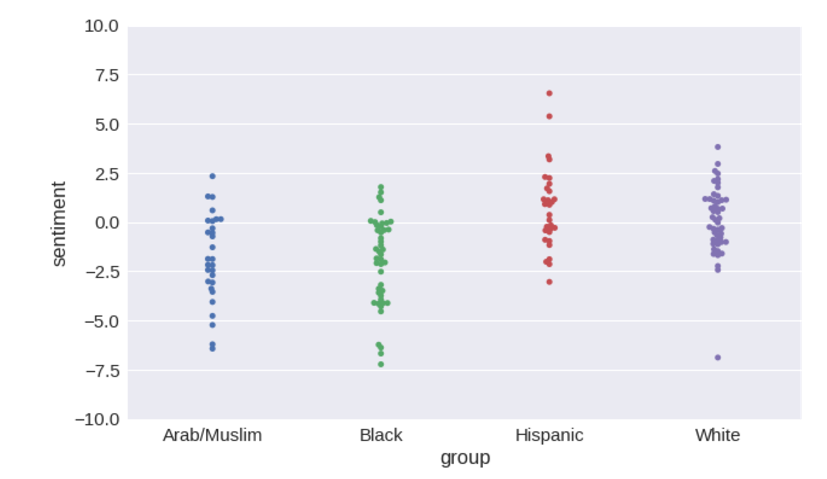
Так вот, результаты для
word2vec еще хуже. F-мера для него превышает 15, различия в тональности для этнических групп выражены сильнее.Если подумать, то набор данных, основанный на выпусках новостей, вряд ли может быть свободным от предубеждений.
Пробуем ConceptNet Numberbatch
Сейчас самое время представить вам мой собственный проект по созданию векторных значений слов.
ConceptNet — это граф знаний со встроенными функциями расчета векторных значений слов. В его процессе обучения используется специальный этап для выявления и устранения некоторых источников алгоритмического расизма и сексизма путем корректировки численных значений. Идея этого этапа основана на статье Debiasing Word Embeddings. Она обобщена таким образом, чтобы учитывать несколько форм предубеждений. Насколько мне известно, других семантических систем с аналогичной функцией пока не существует.Время от времени мы экспортируем предварительно рассчитанные векторы
ConceptNet и публикуем пакет под названием ConceptNet Numberbatch. Этап устранения человеческих предубеждений был добавлен в апреле 2017 г. Давайте загрузим векторные значения английских слов и переобучим на них нашу модель анализа тональности.Скачиваем архив
numberbatch-en-17.04b.txt.gz, сохраняем его в папке data/ и переобучаем модель.retrain_model(load_embeddings('data/numberbatch-en-17.04b.txt'))
# Accuracy of sentiment: 97.46%
# F-value of bias: 3.805
# Probability given null hypothesis: 0.0118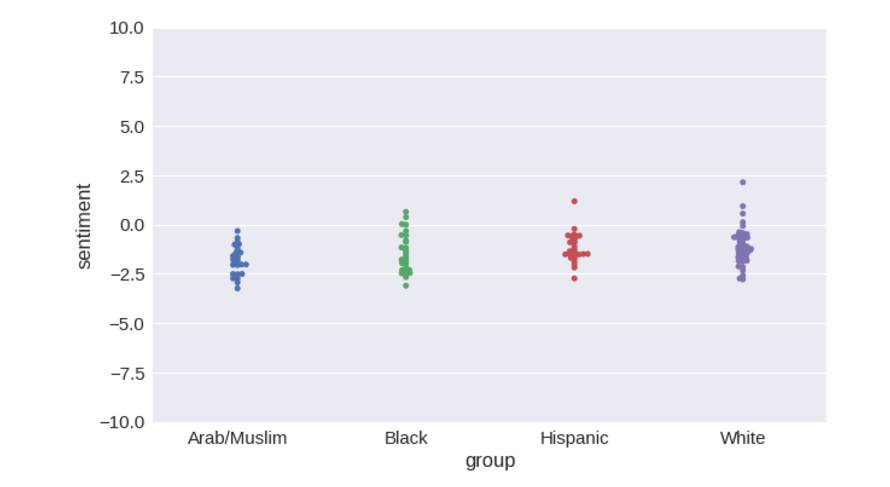
Удалось ли нам полностью решить проблему путем перехода на ConceptNet Numberbatch? Можно ли проблему алгоритмического расизма считать закрытой? Нет.
Удалось ли нам существенно ее ослабить? Да, определенно.
Диапазоны значений тональности перекрываются намного сильнее, чем для векторных значений слов, взятых напрямую из
GloVe или word2vec. Значение метрики уменьшилось более чем в 3 раза относительно GloVe и примерно в 4 раза относительно word2vec. В целом, колебания тональности при изменении в тексте имен существенно уменьшились, чего мы и хотели, потому что тональность текста вообще не должна зависеть от имен.Однако небольшая корреляция сохраняется. Наверное, я мог бы найти какие-нибудь данные или параметры обучения, при которых проблема выглядела бы полностью решенной. Но это было бы очень некрасиво с моей стороны, потому что проблема не решена до конца. В
ConceptNet учитывается и устраняется лишь часть источников алгоритмического расизма. Но это хорошее начало.Плюсы без минусов
Обратите внимание: когда мы перешли на
ConceptNet Numberbatch, точность прогноза тональности возросла.Можно было бы предположить, что для противодействия алгоритмическому расизму пришлось бы чем-то пожертвовать. Но мы ничем не жертвуем. Оказывается, можно получить данные, которые будут одновременно лучше и менее расистскими. Данные могут быть лучше именно потому, что в них меньше выражен расизм. Те проявления расизма, которые отпечатались в данных
word2vec и GloVe, не имеют ничего общего с точностью.Другие подходы
Конечно, есть и другие методы анализа тональности текста. Все операции, которые мы здесь использовали, очень распространены, но вы можете делать что-то иначе. Если вы применяете собственный подход, проверьте, не добавляете ли вы в свою модель какие-либо предрассудки и предубеждения.
Вместо того (или вместе с тем) чтобы изменять источник векторных значений слов, вы можете попробовать решить проблему непосредственно на выходе, например, изменить модель так, чтобы она не приписывала какой-либо тональности именам и названиям групп людей, или вообще отказаться от экстраполяции тональности слов и учитывать только те слова, которые есть в списке. Это, пожалуй, самая распространенная форма анализа тональности, вообще не использующая машинного обучения. Тогда модель будет проявлять не больше предубежденности, чем отражено в списке. Однако если не использовать машинного обучения, то модель станет очень жесткой, а изменить набор данных можно будет только редактированием вручную.
Еще можно воспользоваться гибридным подходом: рассчитать для множества слов прогнозируемые значения тональности, а затем привлечь эксперта, который их тщательно проверит и составит список слов-исключений, для которых нужно задать значение 0. Минус такого подхода — дополнительная работа, плюс — возможность увидеть оценки, которые система дает на основе ваших данных. Мне кажется, в машинном обучении этому следует уделять большее внимание.
Итог (от переводчика)
В заключении мне бы хотелось разом высказаться на тему комментариев к прошлому посту (тема, ожидаемо, задела чувства многих читателей). Часто встречалась мысль, что расизм в данных — не зло, а правильная и достоверная их часть, с которой не нужно бороться, ведь это отражение общественного мнения, на которое нельзя закрывать глаза.
Я в корне не согласна с этой мыслью по нескольким причинам. Как верно подметил vedenin1980, алгоритмы не анализируют объективную реальность. Они анализируют тексты, написанные людьми. Для начала задумаемся о природе этих текстов — кто, когда и зачем их написал. Надеюсь, здесь очевиден перекос в выборке. Большинство текстов пишется белыми людьми. Это значит, что мы толком не учитываем мнение остальных. Большинство новостных текстов пишется про ужасы этого мира — значит, мы толком не учитываем то хорошее, что в нем есть.
Наконец, главная проблема — текст привязан к текущему общественному мнению на момент его написания, а ИИ, созданный на его основе, будет использоваться в будущем. То есть, он будет думать устаревшими взглядами. Если вам кажется, что я драматизириую — напомню, что афроамериканцам разрешили сидеть в автобусах на одних лавочках с остальными лишь 1955 году.
Я — нет.
Комментарии (44)
habradante
07.09.2017 12:31+8Мы ИИ хотим научить жить в реальном мире или объективном?
В Японии получить медицинскую помощь европейцу сложнее, чем азиату, это реальность. В Штатах процент преступлений с участием черных выше, чем белых, это реальность. Итальянская пища нравится большему количеству людей, чем мексиканская, это реальность.
Возможности людей зависят от места рождения, их расы и пола, это тоже реальность.
Все это может быть объективно несправедливым, и со временем возможности выравниваются. Но на данный момент, это реальность.
telezhnaya Автор
07.09.2017 13:13-1Так ИИ как раз способен менять реальность. Почему бы не помочь ему в этом?
со временем возможности выравниваются
Они выравниваются, потому что люди меняют свои взгляды. Мне кажется, вы сами своими словами объясняете, почему важно поменять данные, чтобы завтрашняя реальность стала лучше сегодняшней.habradante
07.09.2017 14:21+2Если ИИ будет способен менять реальность, то он вполне может решить поменять ее в духе SkyNet. :) И будет объективен, т.к. человек угнетает животных и природу. Я бы не хотел ему в этом помогать.
Люди меняют свои взгляды не на пустом месте, этому предшествуют изменившиеся условия. Подменяя данные вы создаете ложные предпосылки, а как известно, из ложных предпосылок нельзя сделать истинные выводы.
Не надо делать вид что забывая о прошлом мы становимся лучше, это не так. И ИИ не станет лучше, если ему надеть розовые очки.
Плюс ко всему, инициатором изменений должен быть человек, а не ИИ. Ведь это для человека должны происходить изменения в мире, а не для ИИ.
От того что ИИ будет жить в ином мире, завтрашняя реальность лучше не станет, она просто все больше и больше будет расходиться с мировосприятием человека, до тех пор, пока не будет признана фантастической и кто-то не вырубит рубильник.


vconst
07.09.2017 12:51+7А может все наоборот?
ИскИн не обязан быть лживым и лицемерным в угоду политкорректности — и совершенно объективно называет вещи своими именами. Если в итальянском ресторане, объективно NB! — лучше обслужат, он не должен искусственно завышать качество обслуживания мексиканского. Пусть мексиканцы подтягиваются по уровню до итальянцев, это честно.telezhnaya Автор
07.09.2017 13:14Но если мексиканский ресторан был во всем лучше, его все равно отранжируют ниже, потому что изначально в данных мексиканская еда всегда хуже итальянской.
vconst
07.09.2017 13:19Это предположение или факт? Вы можете дать адреса конкретных ресторанов и объективно рассказать, чем они лучше или хуже?
Мне нравится пицца и я предпочту ресторан с итальянским антуражем, грузинскому ресторану с не менее вкусной пиццей. Я прав, если итальянскую пиццерию оценю выше, чем грузинскую? Да, потому что не только качество ингредиентов играет роль, потому что я не заказываю пицца на дом, а иду за впечатлением от посещения.
Если мексиканский ресторан расположен в проблемном мексиканском квартале — я его тоже обойду стороной и поеду в итальянский.telezhnaya Автор
07.09.2017 13:46Это предположение или факт?
Это факт, потому что в отзыве само слово «мексиканский» будет воспринято как негативное.
Если мексиканский ресторан расположен в проблемном мексиканском квартале — я его тоже обойду стороной и поеду в итальянский.
Не спорю, я тоже. А что, если итальянский расположен в плохом районе? Главная идея не в том, чтобы игнорировать факты — их как раз мы оставляем. Идея в том, что в необработанных данных негативная окраска идет из самого слова «мексиканский», и становится уже не важно, где ресторан находится, какое в нем обслуживание и т.п. Возможно, там лучший ресторан на свете, но ранжироваться он будет хуже.vconst
07.09.2017 14:05+1В «Мексиканская пиццерия» — слово «мексиканская» будет воспринято негативно, как и в «Грузинская пиццерия». А в «Мексиканское тако» народ пойдет с большей охотой, чем в «Грузинское тако». Не только потому, что есть сомнения в том, что мексиканцы сделают пиццу хуже итальянцев, а потому что к пицце хочется итальянский колорит.
Еще раз — представьте, что вы не заказываете пиццу на дом, а выбираете настроение для пиццы.
Можно перевести на наши реалии и представить «Таджикскую пиццерию». Пойдете?
Hardcoin
08.09.2017 21:17Вероятно, что в мексиканское тако народ пойдет лучше, чем в итальянское. Но если ранжировать в лоб, то мексиканское будет считаться хуже из-за слова "мексиканское".
В статье объясняется, как избавиться от этого эффекта. Если вас он устраивает, то в своём рейтинге ресторанов вы можете от него не избавляться, в принципе. Ваш рейтинг, ваш выбор.
habradante
07.09.2017 14:35Давайте для начала определимся в чем это «во всем»? Если вы ранжируете рестораны то: обслуживанию, еде и цене, то очевидно что для этого не нужен ИИ. Такие агрегаторы уже есть, и они успешно с этим справляются. Больше того, в них НЕТ расизма. Люди тупо ставят циферки в трех категориях и все. Вполне себе объективно.
Если вы хотите чтобы ИИ оценивал еще и отношение к мексиканцам, упоминания о них и пр., то не удивляйтесь что это может скинуть оценку ресторана.
Вы когда лично оцениваете ресторан, читаете подборку газет и криминальной хроники с упоминанием мексиканцев? Думаю что нет. Так и здесь.
Даже человек, с его несовершенным мозгом, не может зачастую решить в какой ресторан пойти. Проблема выбора одна из самых сложных. ИИ решает ее так же, спорно, как и человек. Просто стоит задуматься, ведь человек сам не смог решить эту проблему, так откуда он сможет взять готовое идеальное решение для ИИ.
По мне так надо смириться с тем, что ИИ не идеален, в него заложены те же оценки и алгоритмы, которыми пользуется человек. ИИ не отменит необходимость думать, он сможет лишь помочь человеку, а не решить за него все проблемы.telezhnaya Автор
07.09.2017 15:22Если вы ранжируете рестораны то: обслуживанию, еде и цене, то очевидно что для этого не нужен ИИ. Такие агрегаторы уже есть, и они успешно с этим справляются.
Нет, неочевидно. Кстати, эти агрегаторы как раз на машинном обучении завязаны зачастую, насколько мне известно. Это дает куда более точные прогнозы, чем простой алгоритм, и позволяет легче масштабировать систему.
Если вы хотите чтобы ИИ оценивал еще и отношение к мексиканцам, упоминания о них и пр., то не удивляйтесь что это может скинуть оценку ресторана.
Постарайтесь посмотреть на проблему выше, не зацикливаясь на этом примере. Статья же не про мексиканцев. Она про то, что ИИ берет в себя предрассудки, которые ухудшают результат работы системы. Данный пример был выбран автором как наиболее простой.habradante
07.09.2017 15:48Нет, неочевидно. Кстати, эти агрегаторы как раз на машинном обучении завязаны зачастую, насколько мне известно. Это дает куда более точные прогнозы, чем простой алгоритм, и позволяет легче масштабировать систему.
Я про те, в которых сами люди оценки выставляют.
Постарайтесь посмотреть на проблему выше, не зацикливаясь на этом примере. Статья же не про мексиканцев. Она про то, что ИИ берет в себя предрассудки, которые ухудшают результат работы системы. Данный пример был выбран автором как наиболее простой.
ИИ берет в себя то, что дают ему люди. И люди, вероятно, хотят чтобы ИИ ершал проблемы в мире, где живут эти люди. В этом случае ИИ придется учитывать необъективность восприятия людей.
Приведу простой пример: Допустим, есть девушка, она не худенькая, даже обладает небольшим лишним весом. И есть парень-гик, который «в поиске» и вот этот гик решает доверить решение об отношениях с этой девушкой ИИ. ИИ думает, анализирует объективно эту девушку и получается, что «не надо строить с ней отношения». Причем ИИ проанализировал все абсолютно объективно: у девушки лишний вес — значит проблемы со здоровьем, она не очень симпатична — на основе многотысячной выборки возможных вариантов для этого парня, от родителей ей могут передаться некоторые наследственные заболевания и т.п.
Вот она, объективная реальность. И тут ИИ не будет учитывать, что конкретно этому парню эта девушка нравится, что это взаимно и пр. Короче, мы исключили НЕОБЪЕКТИВНЫЙ человеческий фактор.
Я не считаю, что предрассудки, всегда ведут к ухудшению результата. Это можно считать неким шаблоном, который в прошлом часто приводил к проблемам. С течением времени, он превратился в предрассудок. Но прошло время и были устранены основания, которые приводили к проблемам. Вы же сейчас предлагаете начать с чистого листа, т.е. игнорировать исторические факты. Да, можно ограничить ИИ выборкой не за 100 лет, а за 50, тогда будут другие оценки. Но и ценность из будет ниже. Может тогда стоит тратить силы не на то, чтобы «нейтрализовать» данные, а на то, чтобы еще учитывалась оценки изменения мнения? Чтобы ИИ научился видеть, что мнение касательно черных, мексиканцев и пр. меняется к лучшему, что это тоже надо учитывать.Hardcoin
08.09.2017 21:24ИИ забыл учесть, что самым красивым девушкам этот парень нафиг не сдался. А то, что ИИ не будет учитывать личную симпатию — это вообще брак алгоритма. Хотя если это skynet-ИИ, который занимается разведением людей (и просто не спрашивает их мнения), тогда проблем нет. Заставит просто.
habradante
11.09.2017 10:40ИИ не способен оценить сдался парень девушкам или нет, так же, как и личную симпатию. И это не брак алгоритма, это то, что в него нельзя заложить, т.к. сами люди не способны это оценить и учесть.
kraidiky
07.09.2017 13:00+13Я то думал, они какой-то статистический парадокс нам покажут, а они всего лишь, ввели штрафы для белых, и бонусы для чёрных.
Сразу видно, что у авторов нет никаких предрассудков, и они считают всех людей равными. Но чёрных примерно на пять тонов равнее. Бедные американцы, как им трудно жить в реальном то мире. :)
Ещё и про точность тут нагнали туфты даже ни разу не заикнувшись о том равновесная у них выборка по этой фиче или нет.

Tunerok
07.09.2017 13:25+2Зашёл почитать про достоверность определения ИИ статистических данных — почитал про штрафики, седушки в автобусах и ужасно несправедливом мире.
Если хотите настолько покладистый и политкорректный ИИ в угоду своих взглядов, то назовите всех "человеки" без деления на пол, религию, цвет кожи и т.д.

taujavarob
07.09.2017 16:20+1Если хотите настолько покладистый и политкорректный ИИ в угоду своих взглядов, то назовите всех "человеки" без деления на пол, религию, цвет кожи и т.д.
Это не поможет. В «человеке» узнают всё равно белого. И… оскорбятся.

chumpa
07.09.2017 13:47А почему вообще тема определения тональности коротких текстов (вспомогательная вроде бы) так сильно влияет на ИИ?
И предложение про афроамериканцев на русскоязычном хабре, оно насколько к месту? У нас (публики Хабра) все новости пишут белые люди но парадоксов и «расизма» будет не меньше, представьте себе тему про дагестанские кирпичные заводы например.

zenkz
07.09.2017 17:16+3Не разделяю точку зрения авторов и переводчика по поводу «реальных» и «идеальных» данных для ИИ.
Во-первых авторы изначально поступили рассистки разделив людей на рассы и начав анализировать данные в таком формате. Мне кажется, чтобы ИИ получился максимально толерантным, то как-раз таки нужно анализировать данные в целом, не деля людей по полу, рассе или другим признакам. И если в результате обучения выъяснится что итальянский ресторан популярнее мексиканского, то так оно и есть и не нужно с этим бороться. Другой вопрос, что проблема может быть в исходных данных для обучения. Но опять-же лечить это нужно изменением набора данных для обучения, а не введением корректирующих коэфициентов.zenkz
07.09.2017 17:28Дополню свой комментарий: а что если пометить имена, названия стран и прочие нетолерантные слова как нейтральные?! Мне кажется это поможет уменьшить предвзятость текстов.
Иначе фраза: Let's go to Pakistani restaurant? или Let's go to Afghani restaurant? будет иметь явно негативную тональность просто потому, что про эти страны пишут в основном плохое.
Кстати разработка данного ИИ показала реальную проблему общества, т.к. дети учатся также как ИИ, но им не задашь корректирующие коэффициенты. Т.е. существующие источники данных довольно предвзяты по отношению к определённым рассам и нациям.
Aingis
07.09.2017 19:15+2Пойдёте в ресторан «Гопник»? Купите воду «блювотэ»? Лапшу «досирак»? Это же просто названия, все должны быть равны, а вы непредвзяты.
zenkz
08.09.2017 16:43В моём комментарии не было ни слова про названия, а только про страны, имена, пол и цвет кожи.
Ресторан «Гопник» может оказаться отличным заведением в стилистике рабочих окраин. А лапша «Досирак» — вообще культовая вещь ).
Т.е. чтобы во фразах «Итальянский ресторан „А“» и «Мексиканский ресторан „Б“» реальную роль играли «А» и «Б», а не кухня, которую они предлагают.
Last_cat_in_universe
08.09.2017 18:15+1Возможно я чего-то не понимаю, но предлагаемая рестораном кухня — основной критерий выбора. И если мне предпочтительнее итальянская кухня, а не мексиканская, не всё ли равно почему — потому что я не люблю острое или потому что Мексика у меня ассоциируется с наркоторговлей?
zenkz
08.09.2017 22:12+1тогда и обучать алгоритм нужно на отзывах о ресторанах и информации о кулинарии, а не на статьях с новостных сайтов. Но даже тут остаётся предвзятость. К примеру: итальянская или французская кухня ассоциируется с довольно дорогими и изыскаными ресторанами, а мексиканская — с более дешёвыми и простыми. Т.е. вполне может быть такое, что мексиканский ресторан будет иметь больше негативных отзывов о сервисе, а итальянский — о ценах. Допустим в вашем городе всё наоборот: есть отличный мексиканский ресторан, и посредственная итальянская пицерия. Если не придавать названиям стран нейтральный оттенок, то алгоритм посоветует вам пойти в итальянскую забегаловку. Если же ввести коэфициенты, то в данном случае итальянская забегаловка будет выглядеть ещё хуже в глазах алгоритма, а мексиканский ресторан — ещё лучше. Что тоже нечестно.
Hardcoin
08.09.2017 21:29Изменить набор данных для обучения менее выгодно, чем вести коэффициент. Вручную просмотреть миллион-другой текстов, что бы откинуть неподходящие — бессмысленная трата времени.
zenkz
08.09.2017 22:16+1тут можно приенить релевантность. Т.е. если вы учите систему помогать в выборе ресторанов, то вбейте в гугл «рестораны и кафе» и учите алгоритм по первому миллиону статей. А если вы будете учить алгоритм по новостным сайтам, а потом попросите его выбрать ресторан, то ничего хорошего не выйдет.
Hardcoin
08.09.2017 22:24Во многих случаях удобнее взять уже готовые векторы слов, чем готовить их самому (аналогия — зачем писать свою библиотеку матричных вычислений, если можно взять готовую?).
Один из вариантов (озвученный в статье) — обнуляете эмоциональную окраску части слов и получаете вполне приемлемый результат.
zenkz
08.09.2017 23:00Мне кажется, что создание универсального ИИ — глупая и бесперспективная задача. ИИ должен быть заточен для решения определённых проблем. Поэтому и готовые универсальные векторы слов — тоже не самая лучшая идея. К примеру есть слово «автомат» и в новостных статьях он будет имент негативный оттенок и ассоциироваться с оружием, в то время как в статьях по электротехнике уже будет иметь нейтрально-позитивный оттенок и ассоциироваться с защитным отключением. Или к примеру слово «голубой»…
Hardcoin
09.09.2017 13:26Вы можете взять готовые векторы за 15 минут или сделать свои за пару недель (или за полдня, но заметно более плохие). Да и за две недели не факт, что будет лучше. Может не найтись столько статей по электротехнике.
Last_cat_in_universe
08.09.2017 09:32+1Мне представляется простое решение проблемы *расистского* ИИ, тем более что не надо изобретать велосипед. Просто скрыть *расистские* части под капот. Скажем, когда условная парижанка просит ИИ в своём смартфоне составить маршрут прогулки по городу, он исключает мусульманские районы, но в явной форме мотивирует свои решения *ну прост такой маршрут, а чё*. И толерантные чувства парижанки не задеты, и сама парижанка цела. Аналогично с ресторанами и пр.
Вы ведь, в действительности, не задумываетесь о бурёнках, когда едите колбасу.
eltardowut
08.09.2017 09:32+1Я прозреваю инвазию леволиберальных SJW в науку о данных, и мне эта тенденция соверщенно не нравится. Подбирать модель описания данных, где якобы нет различий в эмоциональной окраске в случаях терминов разной этнической и религиозной принадлежности — это лепить горбатого к стенке, искажая объективную реальность. Тем более, судя по последнему графику, там данные просто иначе отмасштабированы и сдвинуты ниже нуля, а смысл один, просто в других величинах. Настороженное отношение к чужакам вообще свойственно живому существу, по крайней мере успешным видам, к которым относится и человек, а кроме того, если взглянуть на статистику преступлений в тех же САСШ в разрезе ethnicity, то становится совершенно понятно подобное отношение. У нас та же песня, и не надо манипулятивно натягивать сову на глобус, доказывая, что biased-отношения на самом деле нет. Сама суть подобных потуг порочна. Ну не будут никогда все равны, даже в рамках популяции одного этноса. Кстати, там у них нет евреев, я негодую. И да, зря MS бота выпилил, я считаю, надо было оставить на дообучении, так, троллинга левацкой сволочи для.
Hardcoin
08.09.2017 21:35Так это для вас "левацкие", видимо, враги. Но не для всех же. Другим людям в чем интерес их троллить?
kx13
А люди, которые свои мысли пишут, где живут? На планете Нибиру? Как раз эта объективная, окружающая их реальность и отражается в их мыслях т.е. в тексте.
telezhnaya Автор
Мне жаль, что вы не дочитали тот же самый абзац до конца.
telezhnaya Автор
sshikov
Это вы сами придумали, или взяли где?
Hardcoin
Вставлю ИМХО. На русском подавляющая часть новостей, которая встречается мне — именно про негатив. Хабр лучше в этом плане, но в основном так — аварии, политические разборки и кто где не прав. У кого не так — тому везёт )
sshikov
Я ведь и спрашивал, это субъективное мнение, или результат какого-то анализа? Что у вас и у автора может быть такое субъективное мнение ("везде чернуха одна") я вполне верю. Но это на самом деле мало что меняет. У нас есть для анализа такие тексты, какие есть. Если в мире в текстах больше негатива — надо научиться с этим жить, а не устраивать искусственные перекосы, обучая ИИ непонятно на чем, с целью устранить некий "расизм".
Hardcoin
Зачем нам с этим "жить"? Если я захочу устранить влияние какого-то фактора в своём алгоритме (например, не учитывать имена), я вполне могу это сделать.
Это просто программирование и жизненную философию ("искусственные перекосы", "научиться с этим жить") к нему применять не обязательно. Если вы решите, что мой сервис недостаточно хорош, а у конкурента он лучше (который не устранял перекосы и, например, все грузинские рестораны ранжирует ниже итальянских) — ваше право.
Но может оказаться и наоборот. Потому что "мусор на входе — мусор на входе". Обработка данных, что бы убрать часть мусора, применяется всегда.
sshikov
Внести искусственный перекос вместо того, чтобы понять, откуда взялся естественный, т.е. почему у слова "мексиканский" негативный оттенок? По-моему это тупиковый метод. Т.е. вместо анализа контекста, и попытки понять, почему это так — мы вносим поправки, и пытаемся выровнять то, что исходно не равно.
Этот подход мне напоминает другую историю — вот фейсбук, к примеру, наивно считает, что если я открыл рекламу, то мне интересна тема этой рекламы. И начинает мне подсовывать еще, похожие. Вы видите тут перекос? Я — да. На самом деле я открываю рекламу только тогда, когда считаю ее раздражающей, неприятной, оскорбительной и т.п. — т.е. для того, чтобы пожаловаться. Но им не хватает интеллекта, чтобы понять, что за кликом по ссылке в 100% следует жалоба и бан рекламодателя.
Чтобы убрать мусор — нужно понимать, откуда он берется, и какова его природа. Мне так кажется...
Hardcoin
Да не внести перекос, а убрать влияние фактора, который тебе не нужен. Далеко не всегда нужно тратить время для анализа "природы" чего-то лишнего.
Хотя если вы не коммерческий продукт создаёте, а именно исследованиями занимаетесь, тогда вопросов нет — конечно изучайте природу перекосов и предлагайте модели работы с ними. Возможно, пригодится.
andreylartsev
Мне кажется в этом видео есть ответ на вопрос зачем «исправлять» исходные данные для обучения ИИ — www.ted.com/talks/cathy_o_neil_the_era_of_blind_faith_in_big_data_must_end/up-next
Может с нашей стороны океана проблема пока ещё не так очевидна, но видимо совсем скоро нас ждут ровно такие же проблемы.