
Решил, раз есть такая возможность, то попробовать коснуться темы Машинного обучения, поскольку это стильно, модно и молодежно. Из предыдущих познаний в данной теме у меня были только пара презентаций от ведущего разработчика, которые имели скорее популяризаторский нежели информационный оттенок.
Я определил конкретную проблему, чтобы решить ее с помощью машинного обучения и начал копать. Хочу заметить, что имея конечную цель было легче ориентироваться в потоке информации.
Втыкаем лопату
Первым делом я отправился на официальный сайт TensorFlow и прочитал ML for Beginners и TensorFlow for beginners. Материалы на английском.
TensorFlow это поделка команды Google и наиболее популярная библиотека для работы с машинным обучением, которая поддерживает Python, Java, C++, Go, а также возможность использования вычислительных мощностей графической видеокарты для расчетов сложных нейросетей.
В своих поисках я нашел еще одну библиотеку для машинного обучения Scikit-learn ориентированную на Python. Плюс этой библиотеки, в большом количестве алгоритмов для машинного обучения прямо из коробки, что было несомненным плюсом в моем случае, так как презентация в пятницу, и очень хотелось продемонстрировать рабочую модель.
В поисках готовых примеров я наткнулся на туториал по определению языка на котором написан текст с помощью Scikit-learn.
Итак, моей задачей было обучить модель определять наличие SQL инъекции в текстовой строке. (Конечно, можно решить эту задачу с помощью регулярных выражений, но в образовательных целях можно
Первым делом, первым делом датасеты...
Тип задачи который я пытаюсь решить это классификация, то есть алгоритм должен в ответ на вскормленные данные выдать мне к какой из категорий эти данные относятся.
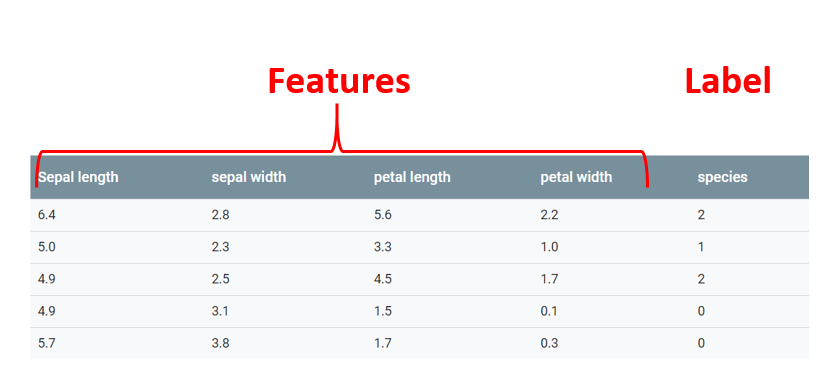
Данные в которых алгоритм будет искать закономерности называются features.
Категория, к которой относится та или иная feature, называется label. Важно отметить, что входные данные могут иметь несколько features, но всего один label.
В классическом примере машинного обучения, определения разновидностей цветков ириса по длине пестиков и тычинок, каждый отдельный столбец с информацией о размере это feature, а последний столбец, который означает к какому из подвидов ириса относится цветок с такими значениями это label
Способ, которым я буду решать проблему классификации, называется supervised learning, или обучение под надзором. Это значит, что в процессе обучения алгоритм будет получать и features и labels.
Шаг номер один в решении любой задачи с помощью машинного обучения это сбор данных, на которых эта самая машина и будет учится. В идеальном мире это должны быть реальные данные, но, к сожалению, в интернете я не смог найти ничего что бы меня удовлетворило. Решено было сгенерировать данные самостоятельно.
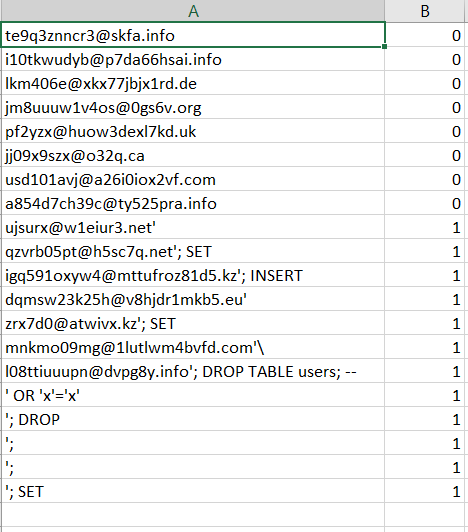
Я написал скрипт, который генерировал случайные адреса электронной почты и SQL инъекции. В итоге в моем csv файле получалось три типа данных: случайные имейлы (20 тыс.), случайные имейлы с SQL инъекцией (20 тыс.) и чистые SQL инъекции (10 тыс.). Выглядело это примерно вот так:
Теперь исходные данные нужно считать. Функция возвращает лист X, в котором содержатся features, лист Y, в котором содержатся labels для каждой feature и лист label_names, который просто содержит текстовое определения для labels, нужен для удобства при выводе результатов.
import csv
def get_dataset():
X = []
y = []
label_names = ["safe data","Injected email"]
with open('trainingSet.csv') as csvfile:
readCSV = csv.reader(csvfile, delimiter='\n')
for row in readCSV:
splitted = row[0].split(',')
X.append(splitted[0])
y.append(splitted[1])
print("\n\nData set features {0}". format(len(X)))
print("Data set labels {0}\n". format(len(y)))
print(X)
return X, y, label_names
Далее эти данные нужно разбить на тренировочный сет и на тестовый. В этом нам поможет заботливо написанная для нас функция cross_validation.train_test_split(), которая перетасует записи и вернет нам четыре сета данных — два тренировочных и два тестовых для features и labels.
# Split the dataset on training and testing sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)Затем мы инициализируем объект vectorizer, который будет считывать переданные в него данные по одному символу, комбинировать их в N-граммы и переводить в числовые векторы, который способен воспринимать алгоритм машинного обучения.
#Setting up vectorizer that will convert dataset into vectors using n-gram
vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
Скармливаем данные
Следующий шаг мы инициализируем pipeline и передадим в него ранее созданный vectorizer и алгоритм, которым мы хотим анализировать наш дата сет. В данном мы будем использовать алгоритм логистической регрессии.
#Setting up pipeline to flow data though vectorizer to the liner model implementation
pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
Модель готова к перевариванию данных. Теперь просто передаем тренировочные сеты features и labels в наш pipeline и модель начинает обучение. Следующей строкой мы пропускаем тестовый сет features через pipeline, но теперь мы используем predict, чтобы получить число правильно угаданных данных.
#Pass training set of features and labels though pipe.
pipe.fit(X_train, y_train)
#Test model accuracy by running feature test set
y_predicted = pipe.predict(X_test)
Если хочется узнать насколько модель точна в предсказаниях, можно сравнить угаданные данные и тестовый лист labels.
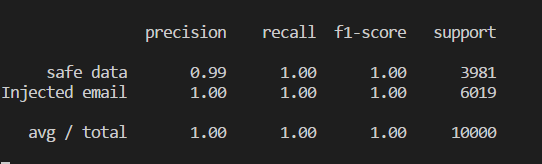
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))Точность модели определяется величиной от 0 до 1, и можно перевести в проценты. Эта модель дает правильный ответ в 100% случаев. Конечно, используя реальные данные, подобного результата будет добиться не так просто, да и задача достаточно простая.
Последний финальный штрих это сохранить модель в обученном виде, чтоб ее можно было без повторного обучения использовать в любой другой python программе. Мы сериализуем модель в pickle файл с помощью встроенной в Scikit-learn функции:
#Save model into pickle. Built in serializing tool
joblib.dump(pipe, 'injection_model.pkl')
Небольшая демонстрация того, как использовать сериализованную модель в другой программе.
import numpy as np
from sklearn.externals import joblib
#Load classifier from the pickle file
clf = joblib.load('injection_model.pkl')
#Set of test data
input_data = ["aselectndwdpyrey@gmail.com",
"andrew@microsoft.com'",
"a.johns@deloite.com",
"'",
"select@mail.jp",
"update11@nebuzar.com",
"' OR 1=1",
"asdasd@sick.com'",
"andrew@mail' OR 1=1",
"an'drew@bark.1ov111.com",
"andrew@gmail.com'"]
predicted_attacks = clf.predict(input_data).astype(np.int)
label_names = ["Safe Data", "SQL Injection"]
for email, item in zip(input_data, predicted_attacks):
print(u'\n{} ----> {}'.format(label_names[item], email))
На выходе мы получим вот такой результат:
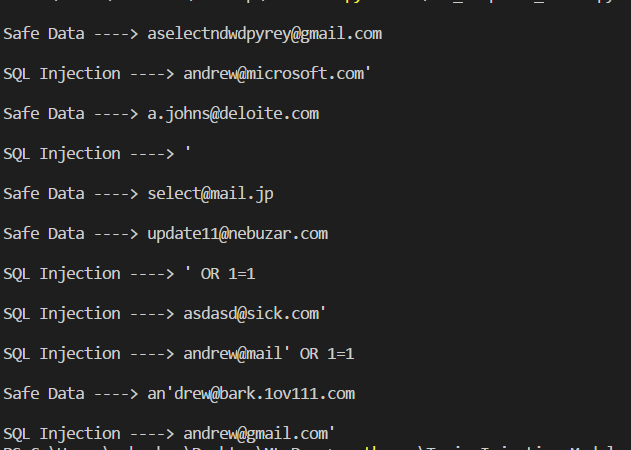
Как видите, модель достаточно уверенно определяет SQL инъекции.
Заключение
В итоге мы имеем тренированную модель для определения SQL инъекций, в теории, мы можем воткнуть ее в серверную часть, и в случае определения инъекции перенаправлять все запросы за фальшивую базу данных, чтоб отвадить взгляд от других возможных уязвимостей. Для демонстрации в конце недели я написал небольшой REST API на Flask.
Это были мои первые шаги в области машинного обучения. Надеюсь, что я смогу вдохновить тех, кто так же как и я долгое время с интересом смотрел на машинное обучение, но боялся прикоснутся к нему.
from sklearn import ensemble
from sklearn import feature_extraction
from sklearn import linear_model
from sklearn import pipeline
from sklearn import cross_validation
from sklearn import metrics
from sklearn.externals import joblib
import load_data
import pickle
# Load the dataset from the csv file. Handled by load_data.py. Each email is split in characters and each one has label assigned
X, y, label_names = load_data.get_dataset()
# Split the dataset on training and testing sets
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,y,test_size=0.2,random_state=0)
#Setting up vectorizer that will convert dataset into vectors using n-gram
vectorizer = feature_extraction.text.TfidfVectorizer(ngram_range=(1, 4), analyzer='char')
#Setting up pipeline to flow data though vectorizer to the liner model implementation
pipe = pipeline.Pipeline([('vectorizer', vectorizer), ('clf', linear_model.LogisticRegression())])
#Pass training set of features and labels though pipe.
pipe.fit(X_train, y_train)
#Test model accuracy by running feature test set
y_predicted = pipe.predict(X_test)
print(metrics.classification_report(y_test, y_predicted,target_names=label_names))
#Save model into pickle. Built in serializing tool
joblib.dump(pipe, 'injection_model.pkl')
Справочные Материалы
Оставляю список полезных ресурсов, которые помогли мне с данным проектом (почти все они на английском)
Tensorflow for begginers
Scikit-Learn Tutorials
Building Language Detector via Scikit-Learn
Нашел несколько отличных статей на Medium включая серию из восьми статей, которые дают хорошее представление, о машинном обучении на простых примерах. (UPD: русский перевод этих же статей)
Комментарии (15)

CheY
12.03.2018 18:14Вот бич любой хайповой технологии — гигантский разрыв между уровнем знаний от «вводных статей for beginners» и уровнем знаний, необходимых для успешного и эффективного применения технологии в реальных задачах.
Лет 10 назад можно было купить книжку PHP5+MySQL+JQuery, склеить куски плохого и непонятного кода в сайт и даже продавать кому-то эти навыки. А теперь всё то же самое, но про ML, Deep Learning и прочий Data Science. Вот только, когда хочешь уйти от уровня «установили питон, импортнули sklearn, обучили модель, посмотрели точность», то открывается бездна информации. Т.е. сегодня ты в эйфории от точности своего классификатора предложений, а завтра ты по несколько раз перечитываешь каждый абзац какой-нибудь каноничной книжки, типа The Elements of Statistical Learning, изо всех сил вспоминая все прогулянные пары матана, линала и матстата и силясь уложить этот фундамент в своей голове. И разрыв настолько огромен, что писать про простоту ML — это злостное введение в заблуждение.
Что, конечно, не отменяет того факта, что с помощью ML изредка можно с минимумом усилий всё-таки получить ограничено работоспособную функциональность, и она даже может иметь какую-то ценность.
ИМХО, конечно.abarkov Автор
12.03.2018 19:13Полностью с вами согласен. Если копнуть чуть глубже, то небходимо прочитать и усвоить неимоверное количество информации, которая достаточно непроста для восприятия. Именно это и подтолкнуло меня к использованию Scikit-learn вместо Tensorflow, который требует более глубокого понимания предмета. Пробелы в знаниях в области математики и статистики отпугивали меня от того, чтобы начать изучать тему, но вот такая простая демка дала запал продолжать копаться.
Если не трудно могли бы вы порекомендовать книги по данной теме, кроме уже упомянутой? Буду очень благодарен.Bionika
13.03.2018 13:44Можно начать с замечательной серии статей от сообщества ODS; там же найдете примеры кода и ссылки на источники.
CheY
13.03.2018 14:18Чтобы что-то советовать, нужно самому хорошо в этом разбираться) Я могу лишь сказать, какие источники мне понравились:
— курс лекций Воронцова по Машинному обучению www.youtube.com/playlist?list=PLJOzdkh8T5kp99tGTEFjH_b9zqEQiiBtC
— канал Основы Анализа Данных funbox.slack.com/messages/office-msk
— если хороший английский (а я не знаю, как без него можно заниматься ML), то канал Den Lambert с его лекциями по эконометрике www.youtube.com/channel/UC3tFZR3eL1bDY8CqZDOQh-w
— опять же, если хороший английский, то лекции MIT OpenCourseWare по всему тому, что забылось со времён вуза: линал, матан, матстат.
— с книгами сложнее. очень много книг сделаны по принципу «пробежимся по верхам с примерами на R/Python». есть неплохие, они позволяют быстро познакомиться с библиотеками. но если хочется что-то более фундаментальное, то это либо огромные талмуды про один конкретный подход (типа 1000 чтраниц про Deep Learning или 1000 страниц про регрессию), либо очень абстрактные книги (как указанная выше ESL), либо опять же всё по верхам. Мне понравилась книжка Питера Флаха «Machine Learning: The Art and Science of Algorithms That Make Sense of Data». Есть на русском от ДМК-Пресс.
И да, ниже правильно упомянули сообщество ODS, у которого есть слак канал с кучей информации и отзывчивыми пользователями. Туда же сообщество machinelearning.ru.

Chumicheff
13.03.2018 09:05Подпишусь под каждым словом. Полное осознание того, где мне в итоге пригодилось бы столько знаний по линейке (и не только), которыми меня пичкали в ВУЗе 15 лет назад, пришло совсем недавно, когда я обратил внимание на ML. Пытаюсь наверстать и освежить в памяти, но тяжко, очень. Хоть и действительно инетерсно.

savostin
13.03.2018 11:13Понимаете, проблема новичков ML не в том, чтобы разобраться как скачивать, устанавливать и подключать Scikit-learn/Tensorflow/новая модная либа, а именно в этом моменте:
В данном мы будем использовать алгоритм логистической регрессии.
Т.е. на данный момент написано, отлажено и выложено в открытый доступ огромное количество качественных библиотек. Появляются каждый день новые, клевые. Без понимания сути алгоритмов затык у начинающего произойдет именно в этот момент — какой алгоритм выбрать, какие параметры поставить, как понимать результаты?
voucher
13.03.2018 13:46А как вы добавляли лейблы в исходный датасет? При случайной генерации адресов и иньекций?
abarkov Автор
13.03.2018 13:58Да, прямо во время генерации датасета, сразу приписивал 0 или 1:
def generate_random_emails_pure(nb): return [[get_random_name(letters) + '@' + get_random_domain(domains), "0"] for i in range(nb)] def generate_random_emails_malicious(nb): return [[get_random_name(letters) + '@' + get_random_domain(domains) + get_random_injection(injections), "1"] for i in range(nb)] def generate_random_injections(nb): return [[get_random_injection(injections), "1"] for i in range(nb)] def main(): emails = generate_random_emails_pure(20000) malicious_emails = generate_random_emails_malicious(20000) pure_injections = generate_random_injections(10000)
Повторюсь, что данные были сгенерированы самостоятельно, только потому что было невозможно найти сет разнообразных SQL инъекций. Можно было взять за основу готовый лист имейлов, но все те что я находил усиленно избегали специальных символов в локальной части адреса, хотя по определению любой из этих символов "!#$%&'*+-/=?^_`{|}~" может в ней присутсвовать.

lumaxy
13.03.2018 16:47Кстати, задача расстановки пропущенных запятых в русском тексте может быть решена с помощью ML? Текст этого поста как-то навеял…
morphi
15.03.2018 16:15Я правильно понимаю, что в Ваш датасет входят данные с sql injection и данные без sql запросов? То есть Вы не классифицируете нормальные sql запросы и инъекции?
abarkov Автор
15.03.2018 16:29Да все правильно. Модель проводит анализ данных, которые пользователь вводит в поле email, и если во входных данных присутствуют следы SQL Injection, то сигналит об этом, чтобы можно ответить котнрмерами на атаку.
Различать обычный SQL запрос и вредоносный не было моей целью.
SicYar
Интересно, спасибо за статью!
При поиске полезных ресурсов, тоже находил фактически только на английском, поэтому вопрос:
попадалось ли что на русском, достойное внимания?
(Лично не находил, но может ваш опыт более успешен)
abarkov Автор
Если честно, я на русском языке материалы не искал. Беглый гуглинг показал, что есть перевод на русский язык цикла статей с Медиума, который я указал в конце статьи. Добавил ссылку на перевод туда же.