

Привет всем,
цикл статей по написанию разных полезных штук для IDA Pro продолжается. В прошлый раз мы исправляли процессорный модуль, а сегодня речь пойдёт о написании модуля-загрузчика (лоадера) для одной винтажной операционной системы, а именно — для AmigaOS. Писать будем на Python. Также я постараюсь раскрыть некоторые тонкости при работе с релоками (они же relocations), которые встречаются во многих исполняемых файлах (PE, ELF, MS-DOS и т.п.).
Введение
Те, кто уже работал ранее с форматом Amiga Hunk (в AmigaOS так называются объекты, содержащие исполняемый код: executable-, library-файлы, и т.д.) и загружал хотя бы один такой файл в IDA, наверняка видели, что загрузчик-то уже существует (более того, имеются даже исходники в IDA SDK):

Да, действительно, всё уже написано до нас, но… Реализовано всё настолько плохо, что работать с хоть каким-то нормальным исполняемым файлом становится просто невозможно.
Проблемы текущей реализации
Итак, вот список проблем:
- Релокации. В файлах Amiga Hunk их наличие — нормальная практика. И в существующей реализации они даже применяются при загрузке файла. Но делается это не всегда корректно (итоговая ссылка может быть подсчитана неправильно).
Кроме того, вам не удастся сделать "Rebase program...". В лоадере эта функция отсутствует. - Файл загружается по базовому адресу
0x00000000. Это определённо неправильно, поскольку по нулевому смещению грузятся различные системные библиотеки. В итоге ссылки на эти библиотеки создаются в адресном пространстве загруженного файла - Загрузчику можно задавать различные флаги, которые не дают (либо, наоборот, позволяют) IDA выполнять те или иные «распознавательные» действия: определение указателей, массивов, ассемблерных инструкций.
В ситуациях, когда дело не касается x86/x64/ARM, часто после загрузки файла ассемблерный листинг выглядит так, что от одного взгляда на него хочется закрыть IDA(а также удалить исследуемый файл и научиться пользоваться radare2). Виной тому установленные по умолчанию флаги загрузчика.
Пишем шаблон загрузчика
Собственно, написать загрузчик несложно. Есть три колбэка, которые нужно реализовать:
1) accept_file(li, filename)
Через эту функцию IDA определяет, можно ли использовать данный лоадер для загрузки файла filename
def accept_file(li, filename):
li.seek(0)
tag = li.read(4)
if tag == 'TAG1': # check if this file can be loaded
return {'format': 'Super executable', 'processor': '68000'}
else:
return 02) load_file(li, neflags, format)
Здесь происходят загрузка содержимого файла в базу, создание сегментов/структур/типов, применение релоков и другие действия.
def load_file(li, neflags, format):
# set processor type
idaapi.set_processor_type('68000', ida_idp.SETPROC_LOADER)
# set some flags
idaapi.cvar.inf.af = idaapi.AF_CODE | idaapi.AF_JUMPTBL | idaapi.AF_USED | idaapi.AF_UNK | idaapi.AF_PROC | idaapi.AF_LVAR | idaapi.AF_STKARG | idaapi.AF_REGARG | idaapi.AF_TRACE | idaapi.AF_VERSP | idaapi.AF_ANORET | idaapi.AF_MEMFUNC | idaapi.AF_TRFUNC | idaapi.AF_FIXUP | idaapi.AF_JFUNC | idaapi.AF_NULLSUB | idaapi.AF_NULLSUB | idaapi.AF_IMMOFF | idaapi.AF_STRLIT
FILE_OFFSET = 0x40 # real code starts here
li.seek(FILE_OFFSET)
data = li.read(li.size() - FILE_OFFSET) # read all data except header
IMAGE_BASE = 0x400000 # segment base (where to load)
# load code into database
idaapi.mem2base(data, IMAGE_BASE, FILE_OFFSET)
# create code segment
idaapi.add_segm(0, IMAGE_BASE, IMAGE_BASE + len(data), 'SEG01', 'CODE')
return 13) move_segm(frm, to, sz, fileformatname)
Если в загружаемом файле есть релокации, то нельзя просто так взять и сменить базовый адрес. Необходимо пересчитать все релокации и пропатчить ссылки. В общем случае код будет всегда один и тот же. Здесь мы просто проходимся по всем созданным ранее релокам, добавляя к ним дельту и применяя патчи к байтам загруженного файла.
def move_segm(frm, to, sz, fileformatname):
delta = to
xEA = ida_fixup.get_first_fixup_ea()
while xEA != idaapi.BADADDR:
fd = ida_fixup.fixup_data_t(idaapi.FIXUP_OFF32)
ida_fixup.get_fixup(xEA, fd)
fd.off += delta
if fd.get_type() == ida_fixup.FIXUP_OFF8:
idaapi.put_byte(xEA, fd.off)
elif fd.get_type() == ida_fixup.FIXUP_OFF16:
idaapi.put_word(xEA, fd.off)
elif fd.get_type() == ida_fixup.FIXUP_OFF32:
idaapi.put_long(xEA, fd.off)
fd.set(xEA)
xEA = ida_fixup.get_next_fixup_ea(xEA)
idaapi.cvar.inf.baseaddr = idaapi.cvar.inf.baseaddr + delta
return 1import idaapi
import ida_idp
import ida_fixup
def accept_file(li, filename):
li.seek(0)
tag = li.read(4)
if tag == 'TAG1': # check if this file can be loaded
return {'format': 'Super executable', 'processor': '68000'}
else:
return 0
def load_file(li, neflags, format):
# set processor type
idaapi.set_processor_type('68000', ida_idp.SETPROC_LOADER)
# set some flags
idaapi.cvar.inf.af = idaapi.AF_CODE | idaapi.AF_JUMPTBL | idaapi.AF_USED | idaapi.AF_UNK | idaapi.AF_PROC | idaapi.AF_LVAR | idaapi.AF_STKARG | idaapi.AF_REGARG | idaapi.AF_TRACE | idaapi.AF_VERSP | idaapi.AF_ANORET | idaapi.AF_MEMFUNC | idaapi.AF_TRFUNC | idaapi.AF_FIXUP | idaapi.AF_JFUNC | idaapi.AF_NULLSUB | idaapi.AF_NULLSUB | idaapi.AF_IMMOFF | idaapi.AF_STRLIT
FILE_OFFSET = 0x40 # real code starts here
li.seek(FILE_OFFSET)
data = li.read(li.size() - FILE_OFFSET) # read all data except header
IMAGE_BASE = 0x400000 # segment base (where to load)
# load code into database
idaapi.mem2base(data, IMAGE_BASE, FILE_OFFSET)
# create code segment
idaapi.add_segm(0, IMAGE_BASE, IMAGE_BASE + len(data), 'SEG01', 'CODE')
return 1
def move_segm(frm, to, sz, fileformatname):
delta = to
xEA = ida_fixup.get_first_fixup_ea()
while xEA != idaapi.BADADDR:
fd = ida_fixup.fixup_data_t(idaapi.FIXUP_OFF32)
ida_fixup.get_fixup(xEA, fd)
fd.off += delta
if fd.get_type() == ida_fixup.FIXUP_OFF8:
idaapi.put_byte(xEA, fd.off)
elif fd.get_type() == ida_fixup.FIXUP_OFF16:
idaapi.put_word(xEA, fd.off)
elif fd.get_type() == ida_fixup.FIXUP_OFF32:
idaapi.put_long(xEA, fd.off)
fd.set(xEA)
xEA = ida_fixup.get_next_fixup_ea(xEA)
idaapi.cvar.inf.baseaddr = idaapi.cvar.inf.baseaddr + delta
return 1Пишем основной код загрузчика
Итак, с основами разобрались. Давайте подготовим себе «рабочее место». Не знаю, в чём кто любит писать код на Python, а я люблю это делать в PyCharm. Давайте создадим новый проект и добавим в пути для поиска импортов каталог из IDA:
Люди, которые уже сталкивались с вопросом эмуляции исполняемых файлов для AmigaOS, наверняка слышали о таком проекте, как amitools. В нём имеется практически полный набор инструментов для работы с Amiga Hunk (как для эмуляции, так и для просто парсинга). Предлагаю на его основе и сделать «загружалку» (лицензия проекта позволяет, да и наш загрузчик будет некоммерческим).
После непродолжительных поисков по amitools нашёлся файл BinFmtHunk.py. В нём реализованы парсинг файла, определение сегментов, релокаций и много чего ещё. Собственно, за само применение релоков отвечает файл Relocate.py.
Теперь самое сложное: нужно из всего этого дерева файлов amitools перетащить в наш файл загрузчика всё, на что есть ссылки в BinFmtHunk.py и Relocate.py, кое-где делая мелкие исправления.
Ещё одна штука, которую я хочу добавить, это определение для каждого сегмента позиции в файле, с которой были загруженные данные. Делается это путём добавления атрибута data_offset в два класса: HunkSegmentBlock и HunkOverlayBlock. Получается следующий код:
class HunkSegmentBlock(HunkBlock):
"""HUNK_CODE, HUNK_DATA, HUNK_BSS"""
def __init__(self, blk_id=None, data=None, data_offset=0, size_longs=0):
HunkBlock.__init__(self)
if blk_id is not None:
self.blk_id = blk_id
self.data = data
self.data_offset = data_offset
self.size_longs = size_longs
def parse(self, f):
size = self._read_long(f)
self.size_longs = size
if self.blk_id != HUNK_BSS:
size *= 4
self.data_offset = f.tell()
self.data = f.read(size)class HunkOverlayBlock(HunkBlock):
"""HUNK_OVERLAY"""
blk_id = HUNK_OVERLAY
def __init__(self):
HunkBlock.__init__(self)
self.data_offset = 0
self.data = None
def parse(self, f):
num_longs = self._read_long(f)
self.data_offset = f.tell()
self.data = f.read(num_longs * 4)Теперь нужно добавить этот атрибут в класс Segment, который создаётся позднее из Hunk-блоков:
class Segment:
def __init__(self, seg_type, size, data=None, data_offset=0, flags=0):
self.seg_type = seg_type
self.size = size
self.data_offset = data_offset
self.data = data
self.flags = flags
self.relocs = {}
self.symtab = None
self.id = None
self.file_data = None
self.debug_line = NoneДалее для класса BinFmtHunk добавим использование data_offset при создании сегментов. Делается это в методе create_image_from_load_seg_file в цикле перечисления сегмент-блоков:
segs = lsf.get_segments()
for seg in segs:
# what type of segment to we have?
blk_id = seg.seg_blk.blk_id
size = seg.size_longs * 4
data_offset = seg.seg_blk.data_offset
data = seg.seg_blk.data
if blk_id == HUNK_CODE:
seg_type = SEGMENT_TYPE_CODE
elif blk_id == HUNK_DATA:
seg_type = SEGMENT_TYPE_DATA
elif blk_id == HUNK_BSS:
seg_type = SEGMENT_TYPE_BSS
else:
raise HunkParseError("Unknown Segment Type for BinImage: %d" % blk_id)
# create seg
bs = Segment(seg_type, size, data, data_offset)
bs.set_file_data(seg)
bi.add_segment(bs)Пишем код для IDA-колбэков
Теперь, когда всё необходимое у нас есть, давайте напишем код для колбэков. Первым будет accept_file:
def accept_file(li, filename):
li.seek(0)
bf = BinFmtHunk()
tag = li.read(4)
tagf = StringIO.StringIO(tag)
if bf.is_image_fobj(tagf):
return {'format': 'Amiga Hunk executable', 'processor': '68040'}
else:
return 0Тут всё просто: читаем первые четыре байта, делаем из них виртуальный файл (StringIO) и передаём его в функцию is_image_fobj, которая возвращает True, если файл подходящего формата. В таком случае возвращаем словарь с двумя полями: format (текстовое описание загружаемого формата) и processor (под какую платформу написан исполняемый код).
Далее необходимо загрузить файл в IDB. Тут посложнее. Первое, что необходимо сделать, это принудительно установить тип процессора на необходимый Motorola 68040:
idaapi.set_processor_type('68040', ida_idp.SETPROC_LOADER)Установим флаги для загрузчика, чтобы не распознавалась всякая дичь и не делались массивы из всего подряд (описание флагов можно почитать здесь):
idaapi.cvar.inf.af = idaapi.AF_CODE | idaapi.AF_JUMPTBL | idaapi.AF_USED | idaapi.AF_UNK | idaapi.AF_PROC | idaapi.AF_LVAR | idaapi.AF_STKARG | idaapi.AF_REGARG | idaapi.AF_TRACE | idaapi.AF_VERSP | idaapi.AF_ANORET | idaapi.AF_MEMFUNC | idaapi.AF_TRFUNC | idaapi.AF_FIXUP | idaapi.AF_JFUNC | idaapi.AF_NULLSUB | idaapi.AF_NULLSUB | idaapi.AF_IMMOFF | idaapi.AF_STRLITПередадим содержимое загружаемого файла в BinFmtHunk (парсинг и всё такое):
li.seek(0)
data = li.read(li.size())
bf = BinFmtHunk()
fobj = StringIO.StringIO(data)
bi = bf.load_image_fobj(fobj)С нулевым адресом загрузки предлагаю расправиться выбрав другой ImageBase. К слову, исполняемые файлы в AmigaOS загружаются лишь по доступным адресам, виртуальных адресов там нет. Я выбрал 0x21F000, он красивый и вряд ли совпадёт с какой-нибудь константой. Применим его:
rel = Relocate(bi)
# new segment addresses are in this list
addrs = rel.get_seq_addrs(0x21F000)
# new segment datas with applied relocations are in this list
datas = rel.relocate(addrs)Добавим стартовый адрес, с которого начинается исполнение программы:
# addrs[0] points to the first segment' entry point
# 1 means that the entry point contains some executable code
idaapi.add_entry(addrs[0], addrs[0], "start", 1)Пора грузить сегменты в базу и создавать релоки (в терминологии IDA: reloc == fixup):
for seg in bi.get_segments():
offset = addrs[seg.id]
size = seg.size
to_segs = seg.get_reloc_to_segs()
for to_seg in to_segs:
reloc = seg.get_reloc(to_seg)
for r in reloc.get_relocs():
offset2 = r.get_offset()
rel_off = Relocate.read_long(datas[seg.id], offset2)
addr = offset + rel_off + r.addend
fd = idaapi.fixup_data_t(idaapi.FIXUP_OFF32)
fd.off = addr
fd.set(offset + offset2)
idaapi.mem2base(str(datas[seg.id]), offset, seg.data_offset)
idaapi.add_segm(0, offset, offset + size, 'SEG_%02d' % seg.id, seg.get_type_name())Финалочка для load_file:
return 1Код move_segm просто берём без изменений.
Итоговый код загрузчика и выводы
import idaapi
import ida_idp
import ida_fixup
import StringIO
import struct
HUNK_UNIT = 999
HUNK_NAME = 1000
HUNK_CODE = 1001
HUNK_DATA = 1002
HUNK_BSS = 1003
HUNK_ABSRELOC32 = 1004
HUNK_RELRELOC16 = 1005
HUNK_RELRELOC8 = 1006
HUNK_EXT = 1007
HUNK_SYMBOL = 1008
HUNK_DEBUG = 1009
HUNK_END = 1010
HUNK_HEADER = 1011
HUNK_OVERLAY = 1013
HUNK_BREAK = 1014
HUNK_DREL32 = 1015
HUNK_DREL16 = 1016
HUNK_DREL8 = 1017
HUNK_LIB = 1018
HUNK_INDEX = 1019
HUNK_RELOC32SHORT = 1020
HUNK_RELRELOC32 = 1021
HUNK_ABSRELOC16 = 1022
HUNK_PPC_CODE = 1257
HUNK_RELRELOC26 = 1260
hunk_names = {
HUNK_UNIT: "HUNK_UNIT",
HUNK_NAME: "HUNK_NAME",
HUNK_CODE: "HUNK_CODE",
HUNK_DATA: "HUNK_DATA",
HUNK_BSS: "HUNK_BSS",
HUNK_ABSRELOC32: "HUNK_ABSRELOC32",
HUNK_RELRELOC16: "HUNK_RELRELOC16",
HUNK_RELRELOC8: "HUNK_RELRELOC8",
HUNK_EXT: "HUNK_EXT",
HUNK_SYMBOL: "HUNK_SYMBOL",
HUNK_DEBUG: "HUNK_DEBUG",
HUNK_END: "HUNK_END",
HUNK_HEADER: "HUNK_HEADER",
HUNK_OVERLAY: "HUNK_OVERLAY",
HUNK_BREAK: "HUNK_BREAK",
HUNK_DREL32: "HUNK_DREL32",
HUNK_DREL16: "HUNK_DREL16",
HUNK_DREL8: "HUNK_DREL8",
HUNK_LIB: "HUNK_LIB",
HUNK_INDEX: "HUNK_INDEX",
HUNK_RELOC32SHORT: "HUNK_RELOC32SHORT",
HUNK_RELRELOC32: "HUNK_RELRELOC32",
HUNK_ABSRELOC16: "HUNK_ABSRELOC16",
HUNK_PPC_CODE: "HUNK_PPC_CODE",
HUNK_RELRELOC26: "HUNK_RELRELOC26",
}
EXT_SYMB = 0
EXT_DEF = 1
EXT_ABS = 2
EXT_RES = 3
EXT_ABSREF32 = 129
EXT_ABSCOMMON = 130
EXT_RELREF16 = 131
EXT_RELREF8 = 132
EXT_DEXT32 = 133
EXT_DEXT16 = 134
EXT_DEXT8 = 135
EXT_RELREF32 = 136
EXT_RELCOMMON = 137
EXT_ABSREF16 = 138
EXT_ABSREF8 = 139
EXT_RELREF26 = 229
TYPE_UNKNOWN = 0
TYPE_LOADSEG = 1
TYPE_UNIT = 2
TYPE_LIB = 3
HUNK_TYPE_MASK = 0xffff
SEGMENT_TYPE_CODE = 0
SEGMENT_TYPE_DATA = 1
SEGMENT_TYPE_BSS = 2
BIN_IMAGE_TYPE_HUNK = 0
segment_type_names = [
"CODE", "DATA", "BSS"
]
loadseg_valid_begin_hunks = [
HUNK_CODE,
HUNK_DATA,
HUNK_BSS,
HUNK_PPC_CODE
]
loadseg_valid_extra_hunks = [
HUNK_ABSRELOC32,
HUNK_RELOC32SHORT,
HUNK_DEBUG,
HUNK_SYMBOL,
HUNK_NAME
]
class HunkParseError(Exception):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
class HunkBlock:
"""Base class for all hunk block types"""
def __init__(self):
pass
blk_id = 0xdeadbeef
sub_offset = None # used inside LIB
@staticmethod
def _read_long(f):
"""read a 4 byte long"""
data = f.read(4)
if len(data) != 4:
raise HunkParseError("read_long failed")
return struct.unpack(">I", data)[0]
@staticmethod
def _read_word(f):
"""read a 2 byte word"""
data = f.read(2)
if len(data) != 2:
raise HunkParseError("read_word failed")
return struct.unpack(">H", data)[0]
def _read_name(self, f):
"""read name stored in longs
return size, string
"""
num_longs = self._read_long(f)
if num_longs == 0:
return 0, ""
else:
return self._read_name_size(f, num_longs)
@staticmethod
def _read_name_size(f, num_longs):
size = (num_longs & 0xffffff) * 4
data = f.read(size)
if len(data) < size:
return -1, None
endpos = data.find('\0')
if endpos == -1:
return size, data
elif endpos == 0:
return 0, ""
else:
return size, data[:endpos]
@staticmethod
def _write_long(f, v):
data = struct.pack(">I", v)
f.write(data)
@staticmethod
def _write_word(f, v):
data = struct.pack(">H", v)
f.write(data)
def _write_name(self, f, s, tag=None):
n = len(s)
num_longs = int((n + 3) / 4)
b = bytearray(num_longs * 4)
if n > 0:
b[0:n] = s
if tag is not None:
num_longs |= tag << 24
self._write_long(f, num_longs)
f.write(b)
class HunkHeaderBlock(HunkBlock):
"""HUNK_HEADER - header block of Load Modules"""
blk_id = HUNK_HEADER
def __init__(self):
HunkBlock.__init__(self)
self.reslib_names = []
self.table_size = 0
self.first_hunk = 0
self.last_hunk = 0
self.hunk_table = []
def setup(self, hunk_sizes):
# easy setup for given number of hunks
n = len(hunk_sizes)
if n == 0:
raise HunkParseError("No hunks for HUNK_HEADER given")
self.table_size = n
self.first_hunk = 0
self.last_hunk = n - 1
self.hunk_table = hunk_sizes
def parse(self, f):
# parse resident library names (AOS 1.x only)
while True:
l, s = self._read_name(f)
if l < 0:
raise HunkParseError("Error parsing HUNK_HEADER names")
elif l == 0:
break
self.reslib_names.append(s)
# table size and hunk range
self.table_size = self._read_long(f)
self.first_hunk = self._read_long(f)
self.last_hunk = self._read_long(f)
if self.table_size < 0 or self.first_hunk < 0 or self.last_hunk < 0:
raise HunkParseError("HUNK_HEADER invalid table_size or first_hunk or last_hunk")
# determine number of hunks in size table
num_hunks = self.last_hunk - self.first_hunk + 1
for a in xrange(num_hunks):
hunk_size = self._read_long(f)
if hunk_size < 0:
raise HunkParseError("HUNK_HEADER contains invalid hunk_size")
# note that the upper bits are the target memory type. We only have FAST,
# so let's forget about them for a moment.
self.hunk_table.append(hunk_size & 0x3fffffff)
def write(self, f):
# write residents
for reslib in self.reslib_names:
self._write_name(f, reslib)
self._write_long(f, 0)
# table size and hunk range
self._write_long(f, self.table_size)
self._write_long(f, self.first_hunk)
self._write_long(f, self.last_hunk)
# sizes
for hunk_size in self.hunk_table:
self._write_long(f, hunk_size)
class HunkSegmentBlock(HunkBlock):
"""HUNK_CODE, HUNK_DATA, HUNK_BSS"""
def __init__(self, blk_id=None, data=None, data_offset=0, size_longs=0):
HunkBlock.__init__(self)
if blk_id is not None:
self.blk_id = blk_id
self.data = data
self.data_offset = data_offset
self.size_longs = size_longs
def parse(self, f):
size = self._read_long(f)
self.size_longs = size
if self.blk_id != HUNK_BSS:
size *= 4
self.data_offset = f.tell()
self.data = f.read(size)
def write(self, f):
self._write_long(f, self.size_longs)
if self.data is not None:
f.write(self.data)
class HunkRelocLongBlock(HunkBlock):
"""HUNK_ABSRELOC32 - relocations stored in longs"""
def __init__(self, blk_id=None, relocs=None):
HunkBlock.__init__(self)
if blk_id is not None:
self.blk_id = blk_id
# map hunk number to list of relocations (i.e. byte offsets in long)
if relocs is None:
self.relocs = []
else:
self.relocs = relocs
def parse(self, f):
while True:
num = self._read_long(f)
if num == 0:
break
hunk_num = self._read_long(f)
offsets = []
for i in xrange(num):
off = self._read_long(f)
offsets.append(off)
self.relocs.append((hunk_num, offsets))
def write(self, f):
for reloc in self.relocs:
hunk_num, offsets = reloc
self._write_long(f, len(offsets))
self._write_long(f, hunk_num)
for off in offsets:
self._write_long(f, off)
self._write_long(f, 0)
class HunkRelocWordBlock(HunkBlock):
"""HUNK_RELOC32SHORT - relocations stored in words"""
def __init__(self, blk_id=None, relocs=None):
HunkBlock.__init__(self)
if blk_id is not None:
self.blk_id = blk_id
# list of tuples (hunk_no, [offsets])
if relocs is None:
self.relocs = []
else:
self.relocs = relocs
def parse(self, f):
num_words = 0
while True:
num_offs = self._read_word(f)
num_words += 1
if num_offs == 0:
break
hunk_num = self._read_word(f)
num_words += num_offs + 1
offsets = []
for i in xrange(num_offs):
off = self._read_word(f)
offsets.append(off)
self.relocs.append((hunk_num, offsets))
# pad to long
if num_words % 2 == 1:
self._read_word(f)
def write(self, f):
num_words = 0
for hunk_num, offsets in self.relocs:
num_offs = len(offsets)
self._write_word(f, num_offs)
self._write_word(f, hunk_num)
for i in xrange(num_offs):
self._write_word(f, offsets[i])
num_words += 2 + num_offs
# end
self._write_word(f, 0)
num_words += 1
# padding?
if num_words % 2 == 1:
self._write_word(f, 0)
class HunkEndBlock(HunkBlock):
"""HUNK_END"""
blk_id = HUNK_END
def parse(self, f):
pass
def write(self, f):
pass
class HunkOverlayBlock(HunkBlock):
"""HUNK_OVERLAY"""
blk_id = HUNK_OVERLAY
def __init__(self):
HunkBlock.__init__(self)
self.data_offset = 0
self.data = None
def parse(self, f):
num_longs = self._read_long(f)
self.data_offset = f.tell()
self.data = f.read(num_longs * 4)
def write(self, f):
self._write_long(f, int(self.data / 4))
f.write(self.data)
class HunkBreakBlock(HunkBlock):
"""HUNK_BREAK"""
blk_id = HUNK_BREAK
def parse(self, f):
pass
def write(self, f):
pass
class HunkDebugBlock(HunkBlock):
"""HUNK_DEBUG"""
blk_id = HUNK_DEBUG
def __init__(self, debug_data=None):
HunkBlock.__init__(self)
self.debug_data = debug_data
def parse(self, f):
num_longs = self._read_long(f)
num_bytes = num_longs * 4
self.debug_data = f.read(num_bytes)
def write(self, f):
num_longs = int(len(self.debug_data) / 4)
self._write_long(f, num_longs)
f.write(self.debug_data)
class HunkSymbolBlock(HunkBlock):
"""HUNK_SYMBOL"""
blk_id = HUNK_SYMBOL
def __init__(self, symbols=None):
HunkBlock.__init__(self)
if symbols is None:
self.symbols = []
else:
self.symbols = symbols
def parse(self, f):
while True:
s, n = self._read_name(f)
if s == 0:
break
off = self._read_long(f)
self.symbols.append((n, off))
def write(self, f):
for sym, off in self.symbols:
self._write_name(f, sym)
self._write_long(f, off)
self._write_long(f, 0)
class HunkUnitBlock(HunkBlock):
"""HUNK_UNIT"""
blk_id = HUNK_UNIT
def __init__(self):
HunkBlock.__init__(self)
self.name = None
def parse(self, f):
_, self.name = self._read_name(f)
def write(self, f):
self._write_name(f, self.name)
class HunkNameBlock(HunkBlock):
"""HUNK_NAME"""
blk_id = HUNK_NAME
def __init__(self):
HunkBlock.__init__(self)
self.name = None
def parse(self, f):
_, self.name = self._read_name(f)
def write(self, f):
self._write_name(f, self.name)
class HunkExtEntry:
"""helper class for HUNK_EXT entries"""
def __init__(self, name, ext_type, value, bss_size, offsets):
self.name = name
self.ext_type = ext_type
self.def_value = value # defs only
self.bss_size = bss_size # ABSCOMMON only
self.ref_offsets = offsets # refs only: list of offsets
class HunkExtBlock(HunkBlock):
"""HUNK_EXT"""
blk_id = HUNK_EXT
def __init__(self):
HunkBlock.__init__(self)
self.entries = []
def parse(self, f):
while True:
tag = self._read_long(f)
if tag == 0:
break
ext_type = tag >> 24
name_len = tag & 0xffffff
_, name = self._read_name_size(f, name_len)
# add on for type
bss_size = None
offsets = None
value = None
# ABSCOMMON -> bss size
if ext_type == EXT_ABSCOMMON:
bss_size = self._read_long(f)
# is a reference
elif ext_type >= 0x80:
num_refs = self._read_long(f)
offsets = []
for i in xrange(num_refs):
off = self._read_long(f)
offsets.append(off)
# is a definition
else:
value = self._read_long(f)
e = HunkExtEntry(name, ext_type, value, bss_size, offsets)
self.entries.append(e)
def write(self, f):
for entry in self.entries:
ext_type = entry.ext_type
self._write_name(f, entry.name, tag=ext_type)
# ABSCOMMON
if ext_type == EXT_ABSCOMMON:
self._write_long(f, entry.bss_size)
# is a reference
elif ext_type >= 0x80:
num_offsets = len(entry.ref_offsets)
self._write_long(f, num_offsets)
for off in entry.ref_offsets:
self._write_long(f, off)
# is a definition
else:
self._write_long(f, entry.def_value)
self._write_long(f, 0)
class HunkLibBlock(HunkBlock):
"""HUNK_LIB"""
blk_id = HUNK_LIB
def __init__(self):
HunkBlock.__init__(self)
self.blocks = []
self.offsets = []
def parse(self, f, is_load_seg=False):
num_longs = self._read_long(f)
pos = f.tell()
end_pos = pos + num_longs * 4
# first read block id
while pos < end_pos:
tag = f.read(4)
# EOF
if len(tag) == 0:
break
elif len(tag) != 4:
raise HunkParseError("Hunk block tag too short!")
blk_id = struct.unpack(">I", tag)[0]
# mask out mem flags
blk_id = blk_id & HUNK_TYPE_MASK
# look up block type
if blk_id in hunk_block_type_map:
blk_type = hunk_block_type_map[blk_id]
# create block and parse
block = blk_type()
block.blk_id = blk_id
block.parse(f)
self.offsets.append(pos)
self.blocks.append(block)
else:
raise HunkParseError("Unsupported hunk type: %04d" % blk_id)
pos = f.tell()
def write(self, f):
# write dummy length (fill in later)
pos = f.tell()
start = pos
self._write_long(f, 0)
self.offsets = []
# write blocks
for block in self.blocks:
block_id = block.blk_id
block_id_raw = struct.pack(">I", block_id)
f.write(block_id_raw)
# write block itself
block.write(f)
# update offsets
self.offsets.append(pos)
pos = f.tell()
# fill in size
end = f.tell()
size = end - start - 4
num_longs = size / 4
f.seek(start, 0)
self._write_long(f, num_longs)
f.seek(end, 0)
class HunkIndexUnitEntry:
def __init__(self, name_off, first_hunk_long_off):
self.name_off = name_off
self.first_hunk_long_off = first_hunk_long_off
self.index_hunks = []
class HunkIndexHunkEntry:
def __init__(self, name_off, hunk_longs, hunk_ctype):
self.name_off = name_off
self.hunk_longs = hunk_longs
self.hunk_ctype = hunk_ctype
self.sym_refs = []
self.sym_defs = []
class HunkIndexSymbolRef:
def __init__(self, name_off):
self.name_off = name_off
class HunkIndexSymbolDef:
def __init__(self, name_off, value, sym_ctype):
self.name_off = name_off
self.value = value
self.sym_ctype = sym_ctype
class HunkIndexBlock(HunkBlock):
"""HUNK_INDEX"""
blk_id = HUNK_INDEX
def __init__(self):
HunkBlock.__init__(self)
self.strtab = None
self.units = []
def parse(self, f):
num_longs = self._read_long(f)
num_words = num_longs * 2
# string table size
strtab_size = self._read_word(f)
self.strtab = f.read(strtab_size)
num_words = num_words - (strtab_size / 2) - 1
# read index unit blocks
while num_words > 1:
# unit description
name_off = self._read_word(f)
first_hunk_long_off = self._read_word(f)
num_hunks = self._read_word(f)
num_words -= 3
unit_entry = HunkIndexUnitEntry(name_off, first_hunk_long_off)
self.units.append(unit_entry)
for i in xrange(num_hunks):
# hunk description
name_off = self._read_word(f)
hunk_longs = self._read_word(f)
hunk_ctype = self._read_word(f)
hunk_entry = HunkIndexHunkEntry(name_off, hunk_longs, hunk_ctype)
unit_entry.index_hunks.append(hunk_entry)
# refs
num_refs = self._read_word(f)
for j in xrange(num_refs):
name_off = self._read_word(f)
hunk_entry.sym_refs.append(HunkIndexSymbolRef(name_off))
# defs
num_defs = self._read_word(f)
for j in xrange(num_defs):
name_off = self._read_word(f)
value = self._read_word(f)
stype = self._read_word(f)
hunk_entry.sym_defs.append(HunkIndexSymbolDef(name_off, value, stype))
# calc word size
num_words = num_words - (5 + num_refs + num_defs * 3)
# alignment word?
if num_words == 1:
self._read_word(f)
def write(self, f):
# write dummy size
num_longs_pos = f.tell()
self._write_long(f, 0)
num_words = 0
# write string table
size_strtab = len(self.strtab)
self._write_word(f, size_strtab)
f.write(self.strtab)
num_words += size_strtab / 2 + 1
# write unit blocks
for unit in self.units:
self._write_word(f, unit.name_off)
self._write_word(f, unit.first_hunk_long_off)
self._write_word(f, len(unit.index_hunks))
num_words += 3
for index in unit.index_hunks:
self._write_word(f, index.name_off)
self._write_word(f, index.hunk_longs)
self._write_word(f, index.hunk_ctype)
# refs
num_refs = len(index.sym_refs)
self._write_word(f, num_refs)
for sym_ref in index.sym_refs:
self._write_word(f, sym_ref.name_off)
# defs
num_defs = len(index.sym_defs)
self._write_word(f, num_defs)
for sym_def in index.sym_defs:
self._write_word(f, sym_def.name_off)
self._write_word(f, sym_def.value)
self._write_word(f, sym_def.sym_ctype)
# count words
num_words += 5 + num_refs + num_defs * 3
# alignment word?
if num_words % 2 == 1:
num_words += 1
self._write_word(f, 0)
# fill in real size
pos = f.tell()
f.seek(num_longs_pos, 0)
self._write_long(f, num_words / 2)
f.seek(pos, 0)
# map the hunk types to the block classes
hunk_block_type_map = {
# Load Module
HUNK_HEADER: HunkHeaderBlock,
HUNK_CODE: HunkSegmentBlock,
HUNK_DATA: HunkSegmentBlock,
HUNK_BSS: HunkSegmentBlock,
HUNK_ABSRELOC32: HunkRelocLongBlock,
HUNK_RELOC32SHORT: HunkRelocWordBlock,
HUNK_END: HunkEndBlock,
HUNK_DEBUG: HunkDebugBlock,
HUNK_SYMBOL: HunkSymbolBlock,
# Overlays
HUNK_OVERLAY: HunkOverlayBlock,
HUNK_BREAK: HunkBreakBlock,
# Object Module
HUNK_UNIT: HunkUnitBlock,
HUNK_NAME: HunkNameBlock,
HUNK_RELRELOC16: HunkRelocLongBlock,
HUNK_RELRELOC8: HunkRelocLongBlock,
HUNK_DREL32: HunkRelocLongBlock,
HUNK_DREL16: HunkRelocLongBlock,
HUNK_DREL8: HunkRelocLongBlock,
HUNK_EXT: HunkExtBlock,
# New Library
HUNK_LIB: HunkLibBlock,
HUNK_INDEX: HunkIndexBlock
}
class HunkBlockFile:
"""The HunkBlockFile holds the list of blocks found in a hunk file"""
def __init__(self, blocks=None):
if blocks is None:
self.blocks = []
else:
self.blocks = blocks
def get_blocks(self):
return self.blocks
def set_blocks(self, blocks):
self.blocks = blocks
def read_path(self, path_name, is_load_seg=False):
f = open(path_name, "rb")
self.read(f, is_load_seg)
f.close()
def read(self, f, is_load_seg=False):
"""read a hunk file and fill block list"""
while True:
# first read block id
tag = f.read(4)
# EOF
if len(tag) == 0:
break
elif len(tag) != 4:
raise HunkParseError("Hunk block tag too short!")
blk_id = struct.unpack(">I", tag)[0]
# mask out mem flags
blk_id = blk_id & HUNK_TYPE_MASK
# look up block type
if blk_id in hunk_block_type_map:
# v37 special case: 1015 is 1020 (HUNK_RELOC32SHORT)
# we do this only in LoadSeg() files
if is_load_seg and blk_id == HUNK_DREL32:
blk_id = HUNK_RELOC32SHORT
blk_type = hunk_block_type_map[blk_id]
# create block and parse
block = blk_type()
block.blk_id = blk_id
block.parse(f)
self.blocks.append(block)
else:
raise HunkParseError("Unsupported hunk type: %04d" % blk_id)
def write_path(self, path_name):
f = open(path_name, "wb")
self.write(f)
f.close()
def write(self, f, is_load_seg=False):
"""write a hunk file back to file object"""
for block in self.blocks:
# write block id
block_id = block.blk_id
# convert id
if is_load_seg and block_id == HUNK_RELOC32SHORT:
block_id = HUNK_DREL32
block_id_raw = struct.pack(">I", block_id)
f.write(block_id_raw)
# write block itself
block.write(f)
def detect_type(self):
"""look at blocks and try to deduce the type of hunk file"""
if len(self.blocks) == 0:
return TYPE_UNKNOWN
first_block = self.blocks[0]
blk_id = first_block.blk_id
return self._map_blkid_to_type(blk_id)
def peek_type(self, f):
"""look into given file obj stream to determine file format.
stream is read and later on seek'ed back."""
pos = f.tell()
tag = f.read(4)
# EOF
if len(tag) == 0:
return TYPE_UNKNOWN
elif len(tag) != 4:
f.seek(pos, 0)
return TYPE_UNKNOWN
else:
blk_id = struct.unpack(">I", tag)[0]
f.seek(pos, 0)
return self._map_blkid_to_type(blk_id)
@staticmethod
def _map_blkid_to_type(blk_id):
if blk_id == HUNK_HEADER:
return TYPE_LOADSEG
elif blk_id == HUNK_UNIT:
return TYPE_UNIT
elif blk_id == HUNK_LIB:
return TYPE_LIB
else:
return TYPE_UNKNOWN
def get_block_type_names(self):
"""return a string array with the names of all block types"""
res = []
for blk in self.blocks:
blk_id = blk.blk_id
name = hunk_names[blk_id]
res.append(name)
return res
class DebugLineEntry:
def __init__(self, offset, src_line, flags=0):
self.offset = offset
self.src_line = src_line
self.flags = flags
self.file_ = None
def get_offset(self):
return self.offset
def get_src_line(self):
return self.src_line
def get_flags(self):
return self.flags
def get_file(self):
return self.file_
class DebugLineFile:
def __init__(self, src_file, dir_name=None, base_offset=0):
self.src_file = src_file
self.dir_name = dir_name
self.base_offset = base_offset
self.entries = []
def get_src_file(self):
return self.src_file
def get_dir_name(self):
return self.dir_name
def get_entries(self):
return self.entries
def get_base_offset(self):
return self.base_offset
def add_entry(self, e):
self.entries.append(e)
e.file_ = self
class DebugLine:
def __init__(self):
self.files = []
def add_file(self, src_file):
self.files.append(src_file)
def get_files(self):
return self.files
class Symbol:
def __init__(self, offset, name, file_name=None):
self.offset = offset
self.name = name
self.file_name = file_name
def get_offset(self):
return self.offset
def get_name(self):
return self.name
def get_file_name(self):
return self.file_name
class SymbolTable:
def __init__(self):
self.symbols = []
def add_symbol(self, symbol):
self.symbols.append(symbol)
def get_symbols(self):
return self.symbols
class Reloc:
def __init__(self, offset, width=2, addend=0):
self.offset = offset
self.width = width
self.addend = addend
def get_offset(self):
return self.offset
def get_width(self):
return self.width
def get_addend(self):
return self.addend
class Relocations:
def __init__(self, to_seg):
self.to_seg = to_seg
self.entries = []
def add_reloc(self, reloc):
self.entries.append(reloc)
def get_relocs(self):
return self.entries
class Segment:
def __init__(self, seg_type, size, data=None, data_offset=0, flags=0):
self.seg_type = seg_type
self.size = size
self.data_offset = data_offset
self.data = data
self.flags = flags
self.relocs = {}
self.symtab = None
self.id = None
self.file_data = None
self.debug_line = None
def __str__(self):
# relocs
relocs = []
for to_seg in self.relocs:
r = self.relocs[to_seg]
relocs.append("(#%d:size=%d)" % (to_seg.id, len(r.entries)))
# symtab
if self.symtab is not None:
symtab = "symtab=#%d" % len(self.symtab.symbols)
else:
symtab = ""
# debug_line
if self.debug_line is not None:
dl_files = self.debug_line.get_files()
file_info = []
for dl_file in dl_files:
n = len(dl_file.entries)
file_info.append("(%s:#%d)" % (dl_file.src_file, n))
debug_line = "debug_line=" + ",".join(file_info)
else:
debug_line = ""
# summary
return "[#%d:%s:size=%d,flags=%d,%s,%s,%s]" % (self.id,
segment_type_names[self.seg_type], self.size, self.flags,
",".join(relocs), symtab, debug_line)
def get_type(self):
return self.seg_type
def get_type_name(self):
return segment_type_names[self.seg_type]
def get_size(self):
return self.size
def get_data(self):
return self.data
def add_reloc(self, to_seg, relocs):
self.relocs[to_seg] = relocs
def get_reloc_to_segs(self):
keys = self.relocs.keys()
return sorted(keys, key=lambda x: x.id)
def get_reloc(self, to_seg):
if to_seg in self.relocs:
return self.relocs[to_seg]
else:
return None
def set_symtab(self, symtab):
self.symtab = symtab
def get_symtab(self):
return self.symtab
def set_debug_line(self, debug_line):
self.debug_line = debug_line
def get_debug_line(self):
return self.debug_line
def set_file_data(self, file_data):
"""set associated loaded binary file"""
self.file_data = file_data
def get_file_data(self):
"""get associated loaded binary file"""
return self.file_data
def find_symbol(self, offset):
symtab = self.get_symtab()
if symtab is None:
return None
for symbol in symtab.get_symbols():
off = symbol.get_offset()
if off == offset:
return symbol.get_name()
return None
def find_reloc(self, offset, size):
to_segs = self.get_reloc_to_segs()
for to_seg in to_segs:
reloc = self.get_reloc(to_seg)
for r in reloc.get_relocs():
off = r.get_offset()
if offset <= off <= (offset + size):
return r, to_seg, off
return None
def find_debug_line(self, offset):
debug_line = self.debug_line
if debug_line is None:
return None
for df in debug_line.get_files():
for e in df.get_entries():
if e.get_offset() == offset:
return e
return None
class BinImage:
"""A binary image contains all the segments of a program's binary image.
"""
def __init__(self, file_type):
self.segments = []
self.file_data = None
self.file_type = file_type
def __str__(self):
return "<%s>" % ",".join(map(str, self.segments))
def get_size(self):
total_size = 0
for seg in self.segments:
total_size += seg.get_size()
return total_size
def add_segment(self, seg):
seg.id = len(self.segments)
self.segments.append(seg)
def get_segments(self):
return self.segments
def set_file_data(self, file_data):
"""set associated loaded binary file"""
self.file_data = file_data
def get_file_data(self):
"""get associated loaded binary file"""
return self.file_data
def get_segment_names(self):
names = []
for seg in self.segments:
names.append(seg.get_type_name())
return names
class HunkDebugLineEntry:
def __init__(self, offset, src_line):
self.offset = offset
self.src_line = src_line
def __str__(self):
return "[+%08x: %d]" % (self.offset, self.src_line)
def get_offset(self):
return self.offset
def get_src_line(self):
return self.src_line
class HunkDebugLine:
"""structure to hold source line info"""
def __init__(self, src_file, base_offset):
self.tag = 'LINE'
self.src_file = src_file
self.base_offset = base_offset
self.entries = []
def add_entry(self, offset, src_line):
self.entries.append(HunkDebugLineEntry(offset, src_line))
def __str__(self):
prefix = "{%s,%s,@%08x:" % (self.tag, self.src_file, self.base_offset)
return prefix + ",".join(map(str, self.entries)) + "}"
def get_src_file(self):
return self.src_file
def get_base_offset(self):
return self.base_offset
def get_entries(self):
return self.entries
class HunkDebugAny:
def __init__(self, tag, data, base_offset):
self.tag = tag
self.data = data
self.base_offset = base_offset
def __str__(self):
return "{%s,%d,%s}" % (self.tag, self.base_offset, self.data)
class HunkDebug:
def encode(self, debug_info):
"""encode a debug info and return a debug_data chunk"""
out = StringIO.StringIO()
# +0: base offset
self._write_long(out, debug_info.base_offset)
# +4: type tag
tag = debug_info.tag
out.write(tag)
if tag == 'LINE':
# file name
self._write_string(out, debug_info.src_file)
# entries
for e in debug_info.entries:
self._write_long(out, e.src_line)
self._write_long(out, e.offset)
elif tag == 'HEAD':
out.write("DBGV01\0\0")
out.write(debug_info.data)
else: # any
out.write(debug_info.data)
# retrieve result
res = out.getvalue()
out.close()
return res
def decode(self, debug_data):
"""decode a data block from a debug hunk"""
if len(debug_data) < 12:
return None
# +0: base_offset for file
base_offset = self._read_long(debug_data, 0)
# +4: tag
tag = debug_data[4:8]
if tag == 'LINE': # SAS/C source line info
# +8: string file name
src_file, src_size = self._read_string(debug_data, 8)
dl = HunkDebugLine(src_file, base_offset)
off = 12 + src_size
num = (len(debug_data) - off) / 8
for i in range(num):
src_line = self._read_long(debug_data, off)
offset = self._read_long(debug_data, off + 4)
off += 8
dl.add_entry(offset, src_line)
return dl
elif tag == 'HEAD':
tag2 = debug_data[8:16]
assert tag2 == "DBGV01\0\0"
data = debug_data[16:]
return HunkDebugAny(tag, data, base_offset)
else:
data = debug_data[8:]
return HunkDebugAny(tag, data, base_offset)
def _read_string(self, buf, pos):
size = self._read_long(buf, pos) * 4
off = pos + 4
data = buf[off:off + size]
pos = data.find('\0')
if pos == 0:
return "", size
elif pos != -1:
return data[:pos], size
else:
return data, size
def _write_string(self, f, s):
n = len(s)
num_longs = int((n + 3) / 4)
self._write_long(f, num_longs)
add = num_longs * 4 - n
if add > 0:
s += '\0' * add
f.write(s)
def _read_long(self, buf, pos):
return struct.unpack_from(">I", buf, pos)[0]
def _write_long(self, f, v):
data = struct.pack(">I", v)
f.write(data)
class HunkSegment:
"""holds a code, data, or bss hunk/segment"""
def __init__(self):
self.blocks = None
self.seg_blk = None
self.symbol_blk = None
self.reloc_blks = None
self.debug_blks = None
self.debug_infos = None
def __repr__(self):
return "[seg=%s,symbol=%s,reloc=%s,debug=%s,debug_info=%s]" % (self._blk_str(self.seg_blk),
self._blk_str(self.symbol_blk),
self._blk_str_list(self.reloc_blks),
self._blk_str_list(self.debug_blks),
self._debug_infos_str())
def setup_code(self, data):
data, size_longs = self._pad_data(data)
self.seg_blk = HunkSegmentBlock(HUNK_CODE, data, size_longs)
def setup_data(self, data):
data, size_longs = self._pad_data(data)
self.seg_blk = HunkSegmentBlock(HUNK_DATA, data, size_longs)
@staticmethod
def _pad_data(data):
size_bytes = len(data)
bytes_mod = size_bytes % 4
if bytes_mod > 0:
add = 4 - bytes_mod
data = data + '\0' * add
size_long = int((size_bytes + 3) / 4)
return data, size_long
def setup_bss(self, size_bytes):
size_longs = int((size_bytes + 3) / 4)
self.seg_blk = HunkSegmentBlock(HUNK_BSS, None, size_longs)
def setup_relocs(self, relocs, force_long=False):
"""relocs: ((hunk_num, (off1, off2, ...)), ...)"""
if force_long:
use_short = False
else:
use_short = self._are_relocs_short(relocs)
if use_short:
self.reloc_blks = [HunkRelocWordBlock(HUNK_RELOC32SHORT, relocs)]
else:
self.reloc_blks = [HunkRelocLongBlock(HUNK_ABSRELOC32, relocs)]
def setup_symbols(self, symbols):
"""symbols: ((name, off), ...)"""
self.symbol_blk = HunkSymbolBlock(symbols)
def setup_debug(self, debug_info):
if self.debug_infos is None:
self.debug_infos = []
self.debug_infos.append(debug_info)
hd = HunkDebug()
debug_data = hd.encode(debug_info)
blk = HunkDebugBlock(debug_data)
if self.debug_blks is None:
self.debug_blks = []
self.debug_blks.append(blk)
@staticmethod
def _are_relocs_short(relocs):
for hunk_num, offsets in relocs:
for off in offsets:
if off > 65535:
return False
return True
def _debug_infos_str(self):
if self.debug_infos is None:
return "n/a"
else:
return ",".join(map(str, self.debug_infos))
@staticmethod
def _blk_str(blk):
if blk is None:
return "n/a"
else:
return hunk_names[blk.blk_id]
@staticmethod
def _blk_str_list(blk_list):
res = []
if blk_list is None:
return "n/a"
for blk in blk_list:
res.append(hunk_names[blk.blk_id])
return ",".join(res)
def parse(self, blocks):
hd = HunkDebug()
self.blocks = blocks
for blk in blocks:
blk_id = blk.blk_id
if blk_id in loadseg_valid_begin_hunks:
self.seg_blk = blk
elif blk_id == HUNK_SYMBOL:
if self.symbol_blk is None:
self.symbol_blk = blk
else:
raise Exception("duplicate symbols in hunk")
elif blk_id == HUNK_DEBUG:
if self.debug_blks is None:
self.debug_blks = []
self.debug_blks.append(blk)
# decode hunk debug info
debug_info = hd.decode(blk.debug_data)
if debug_info is not None:
if self.debug_infos is None:
self.debug_infos = []
self.debug_infos.append(debug_info)
elif blk_id in (HUNK_ABSRELOC32, HUNK_RELOC32SHORT):
if self.reloc_blks is None:
self.reloc_blks = []
self.reloc_blks.append(blk)
else:
raise HunkParseError("invalid hunk block")
def create(self, blocks):
# already has blocks?
if self.blocks is not None:
blocks += self.blocks
return self.seg_blk.size_longs
# start with segment block
if self.seg_blk is None:
raise HunkParseError("no segment block!")
self.blocks = [self.seg_blk]
# has relocations
if self.reloc_blks is not None:
self.blocks += self.reloc_blks
# has debug?
if self.debug_blks is not None:
self.blocks += self.debug_blks
# has symbols?
if self.symbol_blk is not None:
self.blocks.append(self.symbol_blk)
# store blocks
blocks += self.blocks
# return size of segment
return self.seg_blk.size_longs
class BinFmtHunk:
"""Handle Amiga's native Hunk file format"""
def __init__(self):
pass
def is_image(self, path):
"""check if a given file is a hunk LoadSeg file"""
with open(path, "rb") as f:
return self.is_image_fobj(f)
@staticmethod
def is_image_fobj(fobj):
"""check if a given fobj is a hunk LoadSeg file"""
bf = HunkBlockFile()
bf_type = bf.peek_type(fobj)
return bf_type == TYPE_LOADSEG
def load_image(self, path):
"""load a BinImage from a hunk file given via path"""
with open(path, "rb") as f:
return self.load_image_fobj(f)
def load_image_fobj(self, fobj):
"""load a BinImage from a hunk file given via file obj"""
# read the hunk blocks
bf = HunkBlockFile()
bf.read(fobj, is_load_seg=True)
# derive load seg file
lsf = HunkLoadSegFile()
lsf.parse_block_file(bf)
# convert load seg file
return self.create_image_from_load_seg_file(lsf)
def save_image(self, path, bin_img):
"""save a BinImage to a hunk file given via path"""
with open(path, "wb") as f:
self.save_image_fobj(f, bin_img)
def save_image_fobj(self, fobj, bin_img):
"""save a BinImage to a hunk file given via file obj"""
lsf = self.create_load_seg_file_from_image(bin_img)
bf = lsf.create_block_file()
bf.write(fobj, is_load_seg=True)
def create_load_seg_file_from_image(self, bin_img):
"""create a HunkLodSegFile from a BinImage"""
lsf = HunkLoadSegFile()
for seg in bin_img.segments:
seg_type = seg.get_type()
# create HunkSegment
lseg = HunkSegment()
lsf.add_segment(lseg)
if seg_type == SEGMENT_TYPE_CODE:
lseg.setup_code(seg.data)
elif seg_type == SEGMENT_TYPE_DATA:
lseg.setup_data(seg.data)
elif seg_type == SEGMENT_TYPE_BSS:
lseg.setup_bss(seg.size)
else:
raise HunkParseError("Unknown Segment Type in BinImage: %d" % seg_type)
# add relocs
self._add_bin_img_relocs(lseg, seg)
# add symbols
self._add_bin_img_symbols(lseg, seg)
# add debug info
self._add_bin_img_debug_info(lseg, seg)
return lsf
@staticmethod
def _add_bin_img_relocs(hunk_seg, seg):
reloc_segs = seg.get_reloc_to_segs()
hunk_relocs = []
for reloc_seg in reloc_segs:
seg_id = reloc_seg.id
reloc = seg.get_reloc(reloc_seg)
relocs = reloc.get_relocs()
offsets = []
for r in relocs:
if r.get_width() != 2 or r.get_addend() != 0:
raise HunkParseError("Invalid reloc: " + r)
offsets.append(r.get_offset())
hunk_relocs.append((seg_id, offsets))
if len(hunk_relocs) > 0:
hunk_seg.setup_relocs(hunk_relocs)
@staticmethod
def _add_bin_img_symbols(hunk_seg, seg):
sym_tab = seg.get_symtab()
if sym_tab is not None:
hunk_sym_list = []
for sym in sym_tab.get_symbols():
hunk_sym_list.append((sym.get_name(), sym.get_offset()))
hunk_seg.setup_symbols(hunk_sym_list)
@staticmethod
def _add_bin_img_debug_info(hunk_seg, seg):
debug_line = seg.get_debug_line()
if debug_line is not None:
for file in debug_line.get_files():
src_file = file.get_src_file()
base_offset = file.get_base_offset()
dl = HunkDebugLine(src_file, base_offset)
for e in file.get_entries():
offset = e.get_offset()
src_line = e.get_src_line()
flags = e.get_flags()
hunk_src_line = src_line | (flags << 24)
dl.add_entry(offset, hunk_src_line)
hunk_seg.setup_debug(dl)
def create_image_from_load_seg_file(self, lsf):
"""create a BinImage from a HunkLoadSegFile object"""
bi = BinImage(BIN_IMAGE_TYPE_HUNK)
bi.set_file_data(lsf)
segs = lsf.get_segments()
for seg in segs:
# what type of segment to we have?
blk_id = seg.seg_blk.blk_id
size = seg.size_longs * 4
data_offset = seg.seg_blk.data_offset
data = seg.seg_blk.data
if blk_id == HUNK_CODE:
seg_type = SEGMENT_TYPE_CODE
elif blk_id == HUNK_DATA:
seg_type = SEGMENT_TYPE_DATA
elif blk_id == HUNK_BSS:
seg_type = SEGMENT_TYPE_BSS
else:
raise HunkParseError("Unknown Segment Type for BinImage: %d" % blk_id)
# create seg
bs = Segment(seg_type, size, data, data_offset)
bs.set_file_data(seg)
bi.add_segment(bs)
# add relocations if any
bi_segs = bi.get_segments()
for seg in bi_segs:
# add relocations?
hseg = seg.file_data
reloc_blks = hseg.reloc_blks
if reloc_blks is not None:
self._add_hunk_relocs(reloc_blks, seg, bi_segs)
# add symbol table
symbol_blk = hseg.symbol_blk
if symbol_blk is not None:
self._add_hunk_symbols(symbol_blk, seg)
# add debug infos
debug_infos = hseg.debug_infos
if debug_infos is not None:
self._add_debug_infos(debug_infos, seg)
return bi
@staticmethod
def _add_hunk_relocs(blks, seg, all_segs):
"""add relocations to a segment"""
for blk in blks:
if blk.blk_id not in (HUNK_ABSRELOC32, HUNK_RELOC32SHORT):
raise HunkParseError("Invalid Relocations for BinImage: %d" % blk.blk_id)
relocs = blk.relocs
for r in relocs:
hunk_num = r[0]
offsets = r[1]
to_seg = all_segs[hunk_num]
# create reloc for target segment or reuse one.
rl = seg.get_reloc(to_seg)
if rl is None:
rl = Relocations(to_seg)
# add offsets
for o in offsets:
r = Reloc(o)
rl.add_reloc(r)
seg.add_reloc(to_seg, rl)
@staticmethod
def _add_hunk_symbols(blk, seg):
"""add symbols to segment"""
syms = blk.symbols
if len(syms) == 0:
return
st = SymbolTable()
seg.set_symtab(st)
for sym in syms:
name = sym[0]
offset = sym[1]
symbol = Symbol(offset, name)
st.add_symbol(symbol)
@staticmethod
def _add_debug_infos(debug_infos, seg):
dl = DebugLine()
seg.set_debug_line(dl)
for debug_info in debug_infos:
# add source line infos
if isinstance(debug_info, HunkDebugLine):
src_file = debug_info.src_file
# abs path?
pos = src_file.rfind('/')
if pos != -1:
dir_name = src_file[:pos]
src_file = src_file[pos + 1:]
else:
dir_name = ""
base_offset = debug_info.base_offset
df = DebugLineFile(src_file, dir_name, base_offset)
dl.add_file(df)
for entry in debug_info.get_entries():
off = entry.offset
src_line = entry.src_line & 0xffffff
flags = (entry.src_line & 0xff000000) >> 24
e = DebugLineEntry(off, src_line, flags)
df.add_entry(e)
class HunkLoadSegFile:
"""manage a LoadSeg() hunk file starting with HUNK_HEADER"""
def __init__(self):
self.hdr_blk = None
self.segments = []
def get_segments(self):
return self.segments
def add_segment(self, seg):
self.segments.append(seg)
def parse_block_file(self, bf):
"""assign hunk blocks into segments"""
# get file blocks
blks = bf.get_blocks()
if blks is None or len(blks) == 0:
raise HunkParseError("no hunk blocks found!")
# ensure its a HUNK_HEADER
hdr_blk = blks[0]
if hdr_blk.blk_id != HUNK_HEADER:
raise HunkParseError("no HEADER block found!")
self.hdr_blk = hdr_blk
# first round: split block list into sections seperated by END
first = []
cur = None
for blk in blks[1:]:
blk_id = blk.blk_id
# split by END block
if blk_id == HUNK_END:
cur = None
# add non end block to list
else:
# check validity of block
if blk_id not in loadseg_valid_begin_hunks and blk_id not in loadseg_valid_extra_hunks:
raise HunkParseError("invalid block found: %d" % blk_id)
if cur is None:
cur = []
first.append(cur)
cur.append(blk)
# second round: split list if two segments are found in a single list
# this is only necessary for broken files that lack END blocks
second = []
for l in first:
pos_seg = []
off = 0
for blk in l:
if blk.blk_id in loadseg_valid_begin_hunks:
pos_seg.append(off)
off += 1
n = len(pos_seg)
if n == 1:
# list is ok
second.append(l)
elif n > 1:
# list needs split
# we can only split if no extra block is before next segment block
new_list = None
for blk in l:
if blk.blk_id in loadseg_valid_begin_hunks:
new_list = [blk]
second.append(new_list)
elif new_list is not None:
new_list.append(blk)
else:
raise HunkParseError("can't split block list")
# check size of hunk table
if len(hdr_blk.hunk_table) != len(second):
raise HunkParseError("can't match hunks to header")
# convert block lists into segments
for l in second:
seg = HunkSegment()
seg.parse(l)
self.segments.append(seg)
# set size in segments
n = len(second)
for i in xrange(n):
self.segments[i].size_longs = hdr_blk.hunk_table[i]
self.segments[i].size = self.segments[i].size_longs * 4
def create_block_file(self):
"""create a HunkBlockFile from the segments given"""
# setup header block
self.hdr_blk = HunkHeaderBlock()
blks = [self.hdr_blk]
sizes = []
for seg in self.segments:
size = seg.create(blks)
sizes.append(size)
# add HUNK_END
blks.append(HunkEndBlock())
# finally setup header
self.hdr_blk.setup(sizes)
# create HunkBlockFile
return HunkBlockFile(blks)
class Relocate:
"""Relocate a BinImage to given addresses"""
def __init__(self, bin_img):
self.bin_img = bin_img
def get_sizes(self):
"""return a list of the required sizes for all sections"""
sizes = []
for segment in self.bin_img.get_segments():
size = segment.size
sizes.append(size)
return sizes
def get_total_size(self, padding=0):
"""return the total size of all segments appended. useful for one large blob"""
sizes = self.get_sizes()
total = 0
for s in sizes:
total += s + padding
return total
def get_seq_addrs(self, base_addr, padding=0):
"""generate a sequence of addresses for continous segments in one blob"""
sizes = self.get_sizes()
addrs = []
addr = base_addr
for s in sizes:
addrs.append(addr)
addr += s + padding
return addrs
def relocate_one_block(self, base_addr, padding=0):
total_size = self.get_total_size(padding)
data = bytearray(total_size)
addrs = self.get_seq_addrs(base_addr, padding)
offset = 0
segs = self.bin_img.get_segments()
for segment in segs:
self._copy_data(data, segment, offset)
self._reloc_data(data, segment, addrs, offset)
offset += segment.size + padding
return data
def relocate(self, addrs):
"""perform relocations on segments and return relocated data"""
segs = self.bin_img.get_segments()
if len(segs) != len(addrs):
raise ValueError("addrs != segments")
datas = []
for segment in segs:
# allocate new buffer
data = bytearray(segment.size)
self._copy_data(data, segment)
self._reloc_data(data, segment, addrs)
datas.append(data)
return datas
@staticmethod
def _copy_data(data, segment, offset=0):
# allocate segment data
size = segment.size
src_data = segment.data
if src_data is not None:
src_len = len(src_data)
data[offset:src_len + offset] = src_data
def _reloc_data(self, data, segment, addrs, offset=0):
# find relocations
to_segs = segment.get_reloc_to_segs()
for to_seg in to_segs:
# get target segment's address
to_id = to_seg.id
to_addr = addrs[to_id]
# get relocations
reloc = segment.get_reloc(to_seg)
for r in reloc.get_relocs():
self._reloc(segment.id, data, r, to_addr, to_id, offset)
def _reloc(self, my_id, data, reloc, to_addr, to_id, extra_offset):
"""relocate one entry"""
offset = reloc.get_offset() + extra_offset
delta = self.read_long(data, offset) + reloc.addend
addr = to_addr + delta
self.write_long(data, offset, addr)
@staticmethod
def read_long(data, offset):
d = data[offset:offset + 4]
return struct.unpack(">i", d)[0]
@staticmethod
def write_long(data, offset, value):
d = struct.pack(">i", value)
data[offset:offset + 4] = d
def accept_file(li, filename):
li.seek(0)
bf = BinFmtHunk()
tag = li.read(4)
tagf = StringIO.StringIO(tag)
if bf.is_image_fobj(tagf):
return {'format': 'Amiga Hunk executable', 'processor': '68040'}
else:
return 0
def load_file(li, neflags, format):
idaapi.set_processor_type('68040', ida_idp.SETPROC_LOADER)
idaapi.cvar.inf.af = idaapi.AF_CODE | idaapi.AF_JUMPTBL | idaapi.AF_USED | idaapi.AF_UNK | idaapi.AF_PROC | idaapi.AF_LVAR | idaapi.AF_STKARG | idaapi.AF_REGARG | idaapi.AF_TRACE | idaapi.AF_VERSP | idaapi.AF_ANORET | idaapi.AF_MEMFUNC | idaapi.AF_TRFUNC | idaapi.AF_FIXUP | idaapi.AF_JFUNC | idaapi.AF_NULLSUB | idaapi.AF_NULLSUB | idaapi.AF_IMMOFF | idaapi.AF_STRLIT
li.seek(0)
data = li.read(li.size())
bf = BinFmtHunk()
fobj = StringIO.StringIO(data)
bi = bf.load_image_fobj(fobj)
rel = Relocate(bi)
addrs = rel.get_seq_addrs(0x21F000)
datas = rel.relocate(addrs)
idaapi.add_entry(addrs[0], addrs[0], "start", 1)
for seg in bi.get_segments():
offset = addrs[seg.id]
size = seg.size
to_segs = seg.get_reloc_to_segs()
for to_seg in to_segs:
reloc = seg.get_reloc(to_seg)
for r in reloc.get_relocs():
offset2 = r.get_offset()
rel_off = Relocate.read_long(datas[seg.id], offset2)
addr = offset + rel_off + r.addend
fd = idaapi.fixup_data_t(idaapi.FIXUP_OFF32)
fd.off = addr
fd.set(offset + offset2)
idaapi.mem2base(str(datas[seg.id]), offset, seg.data_offset)
idaapi.add_segm(0, offset, offset + size, 'SEG_%02d' % seg.id, seg.get_type_name())
return 1
def move_segm(frm, to, sz, fileformatname):
delta = to
xEA = ida_fixup.get_first_fixup_ea()
while xEA != idaapi.BADADDR:
fd = ida_fixup.fixup_data_t(idaapi.FIXUP_OFF32)
ida_fixup.get_fixup(xEA, fd)
fd.off += delta
if fd.get_type() == ida_fixup.FIXUP_OFF8:
idaapi.put_byte(xEA, fd.off)
elif fd.get_type() == ida_fixup.FIXUP_OFF16:
idaapi.put_word(xEA, fd.off)
elif fd.get_type() == ida_fixup.FIXUP_OFF32:
idaapi.put_long(xEA, fd.off)
fd.set(xEA)
xEA = ida_fixup.get_next_fixup_ea(xEA)
idaapi.cvar.inf.baseaddr = idaapi.cvar.inf.baseaddr + delta
return 1Ссылка на исходник: https://github.com/lab313ru/amiga_hunk_loader
Написать загрузчик для IDA, на самом деле, совершенно не сложно. Если вы «плюсовик» или немного умеете кодить на Python и, конечно же, обладаете большим терпением (а куда без него в реверс-инжиниринге?), сделать это можно за один вечер.
Основной проблемой в написании чего-либо под IDA является отсутствие нормальной справки, во многих вещах приходится разбираться самостоятельно. К счастью, разработчики уже делают кое-что в этом направлении, и доки теперь не те, что раньше.
Всем спасибо.
Комментарии (3)

xvilka
27.09.2018 19:40Раз уж упомянули radare2, то я раскрою тему. У нас в книге есть про написание плагинов на Python (и других языках). Radare2 позволяет сделать что-то быстро из консоли:
Скриншот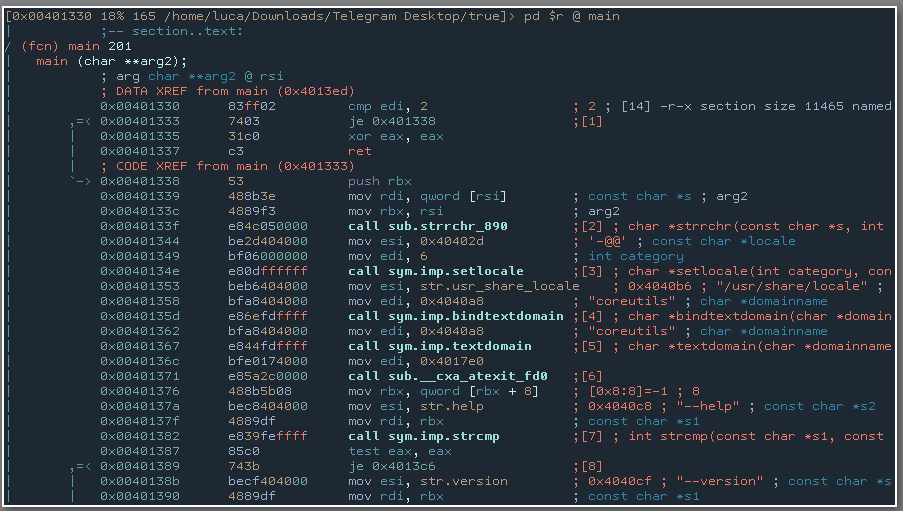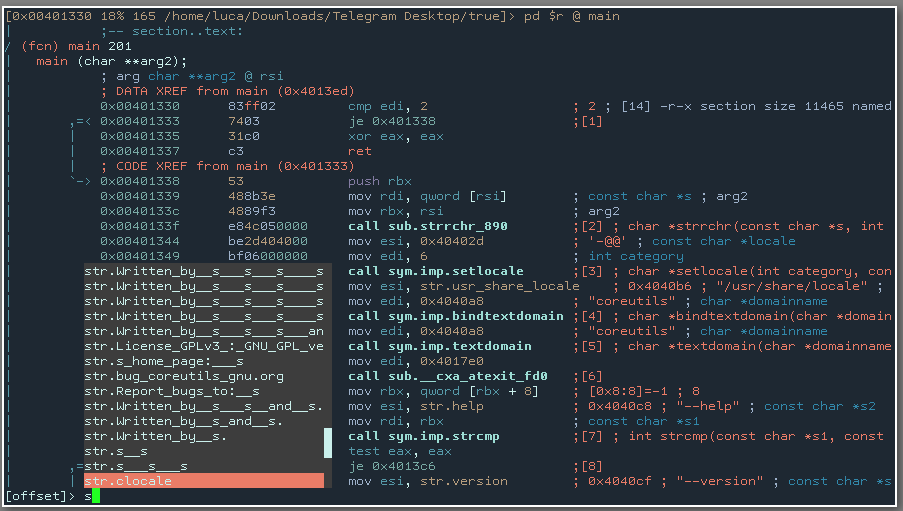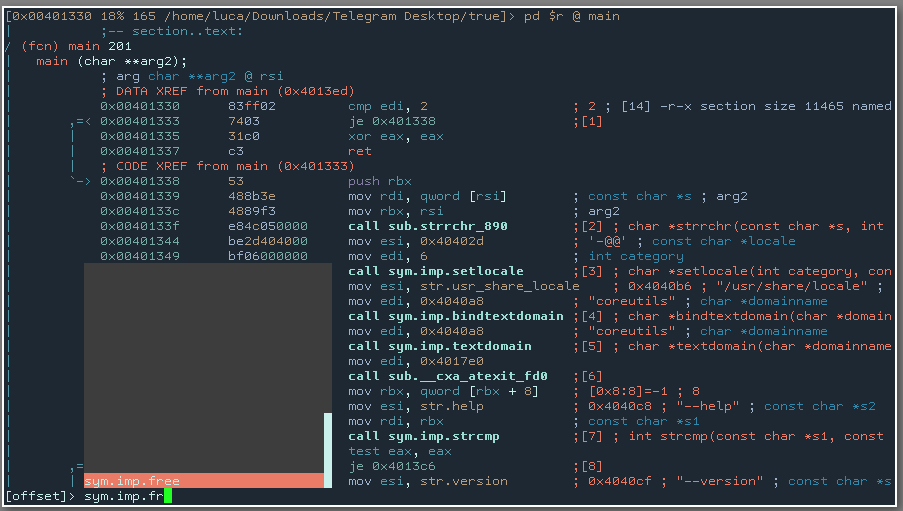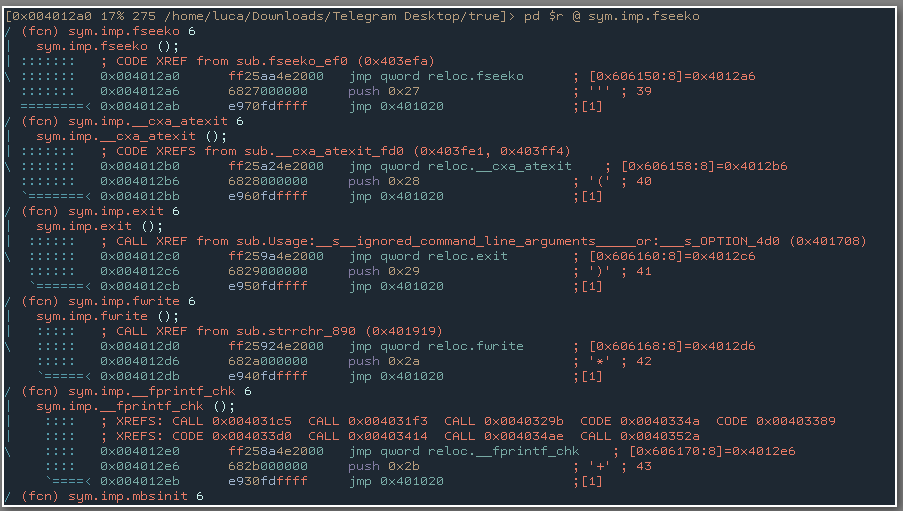
MadHacker
28.09.2018 13:08Если есть желание привлечь разработчиков — сделайте хорошие статьи по архитектуре radare2. Что в основе, как работает, что под капотом.
Наверняка читали «Образ мышления — дизассемблер IDA.» от Криса Касперски? Вот наверное чего-то такого не хватает для radare2.
BiosUefi
>>Positive Technologies
Будут ли представлены ваши новые доклады на «HITBSecConf2018 – Beijing»?