

Представления, или views, это одна из концепций платформы CUBA, не самая расхожая в мире веб-фреймворков. Понять её — значит уберечь себя от глупых ошибок, когда из-за неполностью подгруженных данных приложение внезапно перестает работать. Давайте посмотрим, что представляют из себя представления (каламбур) и почему это на самом деле удобно.
Проблема незагруженных данных
Возьмём предметную область попроще и рассмотрим проблему на её примере. Предположим, у нас есть сущность Customer, которая ссылается на сущность CustomerType в отношении много-к-одному, иными словами, покупатель имеет ссылку на некий тип, его описывающий: например, "дойная корова", "грубиян" и т.п. Сущность CustomerType имеет атрибут name, в котором хранится имя типа.
И, наверное, все новички (а то и продвинутые пользователи) в CUBA рано или поздно получали такую ошибку:
IllegalStateException: Cannot get unfetched attribute [type] from detached object com.rtcab.cev.entity.Customer-e703700d-c977-bd8e-1a40-74afd88915af [detached].
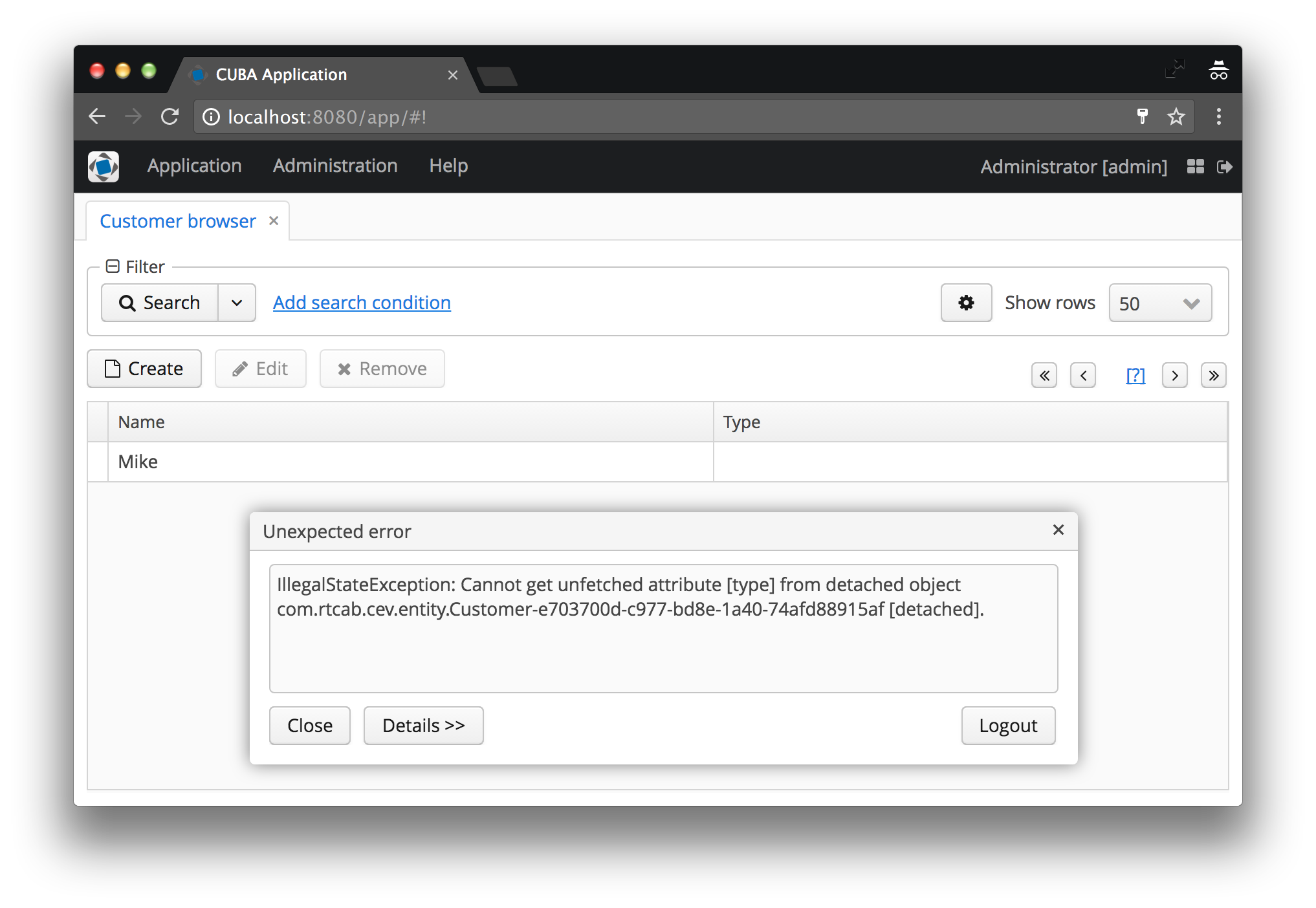
Признайтесь, вы же тоже это видели своими глазами? Я — да, в сотне разных ситуаций. В этой статье мы рассмотрим причину этой проблемы, почему она вообще существует и как её решить.
Для начала — небольшое введение в концепцию представлений.
Что такое представление?
Представление в CUBA — это, по сути, набор столбцов в базе данных, которые должны быть загружены вместе единым запросом.
Допустим, мы хотим создать UI с таблицей покупателей, где первая колонка — это имя покупателя, а вторая — имя типа из атрибута customerType (как на скриншоте выше). Логично предположить, что в этой модели данных у нас будет две отдельные таблицы в БД, одна для сущности Customer, другая для CustomerType. Запрос SELECT * from CEV_CUSTOMER вернёт нам данные только из одной таблицы (атрибут name и т.д.). Очевидно, чтобы получить данные также из других таблиц, мы будем использовать JOIN-ы.
В случае использования классических SQL-запросов при использовании JOIN иерархия ассоциаций (ссылочных атрибутов) разворачивается из графа в плоский список.
Примечание переводчика: иначе говоря, взаимосвязи между таблицами стираются, и результат представляется в едином массиве данных, представляющем объединение таблиц.
В случае CUBA используется ORM, который не теряет информацию о связях между сущностями и представляет результат запросов в виде целостного графа запрошенных данных. В качестве языка запросов в этом случае используется JPQL — объектный аналог SQL.
Тем не менее, данные по-прежнему надо как-то выгрузить из базы и трансформировать в граф сущностей. Для этого в механизме объектно-реляционного отображения (коим является JPA) есть два основных подхода к запросам в базу.
Lazy loading vs. eager fetching
Ленивая загрузка и жадная загрузка — две возможных стратегии получения данных из базы. Принципиальное различие между ними заключается в том, в какой момент загружаются данные из связанных таблиц. Небольшой пример для лучшего понимания:
Помните сцену из книги "Хоббит, или туда и обратно", где группа гномов в компании Гэндальфа и Бильбо пытается напроситься на ночлег в дом Беорна? Гэндальф приказал гномам появляться строго по очереди и только после того, как он осторожно договорился с Беорном и начал представлять их по одному, чтобы не шокировать хозяина необходимостью разместить сразу 15 гостей.

Итак, Гэндальф и гномы в доме Беорна… Наверное, это не первое, что приходит в голову при мысли о ленивой и жадной загрузках, но сходство определённо есть. Гэндальф здесь поступил мудро, так как отдавал себе отчёт об ограничениях. Он, можно сказать, сознательно выбрал ленивую загрузку гномов, так как понимал, что загрузка всех данных сразу будет слишком тяжёлой операцией для этой базы. Однако после 8-го гнома Гэндальф переключился на жадную загрузку и подгрузил пачку оставшихся гномов, потому что заметил, что слишком частые обращения к базе данных начинают её нервировать не меньше.
Мораль в том, что и ленивая, и жадная загрузка имеют свои плюсы и минусы. Что применять в каждой конкретной ситуации, решать вам.
Проблема запроса N+1
Проблема запроса N+1 часто возникает в том случае, если вы бездумно используете ленивую загрузку где ни попадя. Для иллюстрации давайте посмотрим на кусок кода Grails. Это не означает, что в Grails всё загружается лениво (на самом деле, способ загрузки вы выбираете сами). В Grails запрос в базу данных по умолчанию возвращает экземпляры сущностей со всеми атрибутами из её таблицы. По сути, выполняется SELECT * FROM Pet.
Если вы хотите пройти вглубь по отношениям между сущностями, это приходится делать пост-фактум. Вот пример:
function getPetOwnerNamesForPets(String nameOfPet) {
def pets = Pet.findAll(sort:"name") {
name == nameOfPet
}
def ownerNames = []
pets.each {
ownerNames << it.owner.name
}
return ownerNames.join(", ")
}Обход графа здесь выполняет одна-единственная строка: it.owner.name. Owner (хозяин) — это отношение, которое не было загружено в изначальном запросе (Pet.findAll). Таким образом, при каждом вызове этой строки GORM выполнит что-то вроде SELECT * FROM Person WHERE id=’…’. Чистой воды lazy loading.
Если посчитать итоговое количество SQL-запросов, получится N (по одному хозяину на каждый вызов it.owner) + 1 (для изначального Pet.findAll). Если вы захотите пройти глубже по графу связанных сущностей, велика вероятность, что ваша база данных быстро нащупает предел своих возможностей.
Как разработчик, вы вряд ли это заметите, ведь с вашей точки зрения вы всего лишь обходите граф объектов. Эта скрытая вложенность в одной короткой строчке причиняет базе данных реальную боль и делает ленивую загрузку подчас опасной.
Развивая хоббичью аналогию, проблема N+1 могла бы проявиться так: представим, что Гэндальф не способен хранить в памяти имена гномов. Поэтому, представляя гномов одного за другим, он вынужден отходить назад к своей группе и спрашивать у гнома его имя. С этой информацией он возвращается назад к Беорну и представляет Торина. Затем повторяет этот манёвр для Бифура, Бофура, Фили, Кили, Дори, Нори, Ори, Ойна, Глойна, Балина, Двалина и Бомбура.

Нетрудно представить, что и такой сценарий Беорну вряд ли бы понравился: какой получатель захочет ждать запрошенную информацию так долго? Поэтому не стоит бездумно использовать этот подход и слепо полагагаться на дефолтные установки своего persistence mapper'а.
Решаем проблему запросов N+1 с помощью CUBA views
В CUBA с проблемой запросов N+1 вы, скорее всего, никогда не столкнётесь, так как в платформе решено вообще не использовать скрытую ленивую загрузку. Вместо неё в CUBA ввели понятие представлений. Представления являются описанием того, какие атрибуты должны быть выбраны и загружены вместе с экземплярами сущностей. Нечто вроде
SELECT pet.name, person.name FROM Pet pet JOIN Person person ON pet.owner == person.idС одной стороны, представление описывает столбцы, которые нужно загрузить из основной таблицы (Pet) (вместо загрузки всех атрибутов через *), с другой стороны, оно описывает и столбцы, которые должны быть загружены из с-JOIN-ненных таблиц.
Вы можете представлять себе CUBA view как SQL view для OR-Mapper’а: принцип действия примерно тот же.
В платформе CUBA вы не можете вызывать запрос через DataManager без использования view. В документации приведён такой пример:
@Inject
private DataManager dataManager;
private Book loadBookById(UUID bookId) {
LoadContext<Book> loadContext = LoadContext.create(Book.class)
.setId(bookId).setView("book.edit");
return dataManager.load(loadContext);
}Здесь мы хотим загрузить книгу по её ID. Метод setView("book.edit") при создании Load context указывает, с каким представлением книга должна быть загружена из базы. В случае, если вы не передаёте никакого представления, data manager использует одно из трёх стандартных представлений, которые есть у каждой сущности: представление _local. Локальными здесь именуются атрибуты, которые не ссылаются на другие таблицы, всё просто.
Решение проблемы с IllegalStateException через views
Теперь, когда мы немного разобрались в концепции представлений, давайте вернёмся к первому примеру из начала статьи и попробуем предотвратить выбрасывание исключения.
Сообщение IllegalStateException: Cannot get unfetched attribute [] from detached object означает всего лишь, что вы пытаетесь отобразить некий атрибут, которые не включен в представление, с которым загружена сущность.
Как видите, в дескрипторе экрана browse screen я использовал представление _local, и в этом вся проблема:
<dsContext>
<groupDatasource id="customersDs"
class="com.rtcab.cev.entity.Customer"
view="_local">
<query>
<![CDATA[select e from cev$Customer e]]>
</query>
</groupDatasource>
</dsContext>Чтобы избавиться от ошибки, нужно, во-первых, включить customer type в представление. Так как мы не можем изменить дефолтное представление _local, мы можем создать своё собственное. В Studio это можно сделать, например, так (правый клик на сущности > create view):
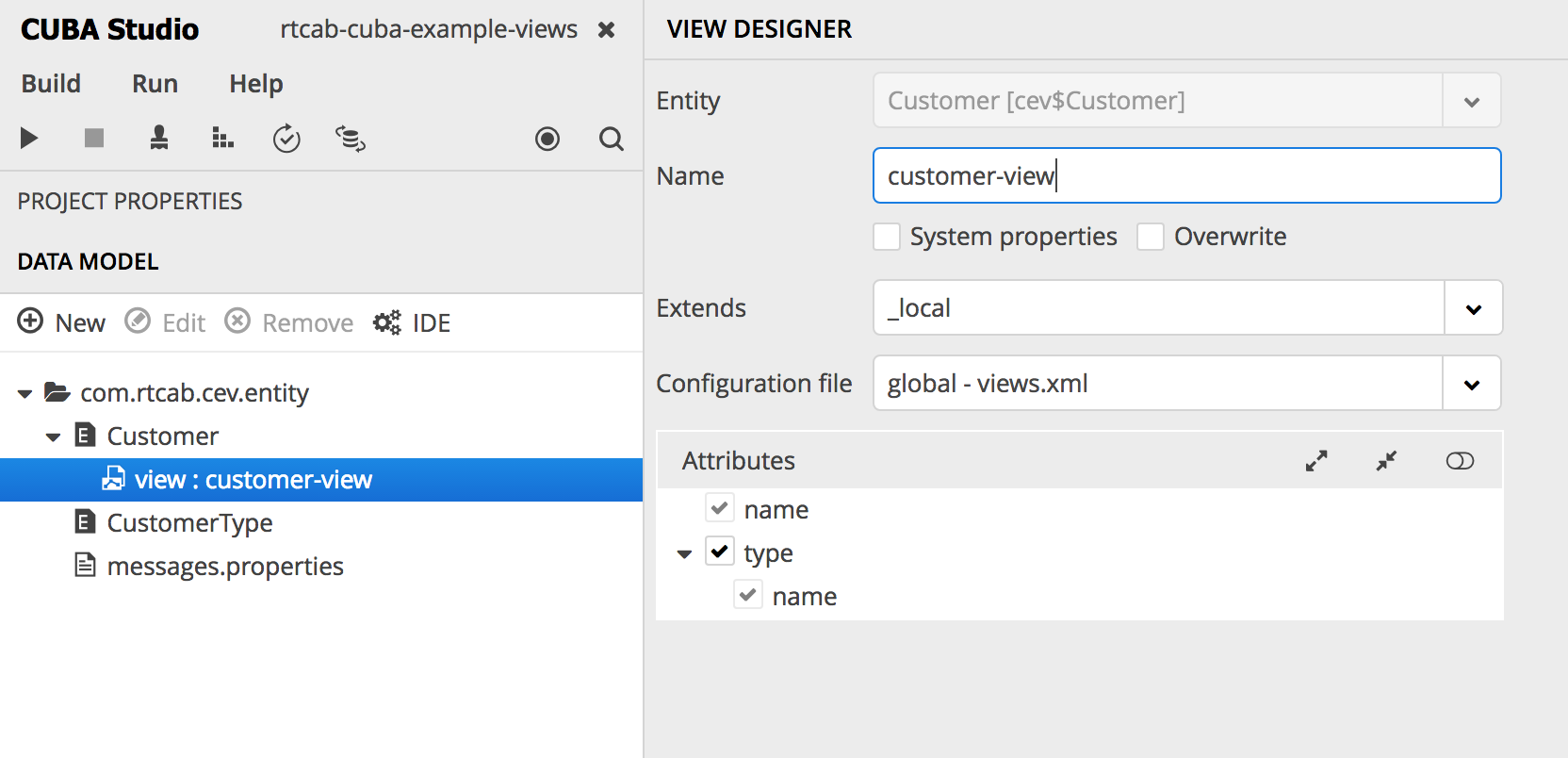
либо напрямую в дескрипторе views.xml нашего приложения:
<view class="com.rtcab.cev.entity.Customer"
extends="_local"
name="customer-view">
<property name="type"
view="_minimal"/>
</view>После этого мы изменяем ссылку на представление в экране browse screen, вот так:
<groupDatasource id="customersDs"
class="com.rtcab.cev.entity.Customer"
view="customer-view">
<query>
<![CDATA[select e from cev$Customer e]]>
</query>
</groupDatasource>Это полностью решает проблему, и теперь ссылочные данные отображаются в экране просмотра покупателей.
Представление _minimal и понятие instance name
О чём ещё стоит упомянуть в контексте представлений, это _minimal view. У локального представления есть вполне чёткое определение: в него входят все атрибуты сущности, которые являются непосредственными атрибутами данной таблицы (которые не являются внешними ключами).
Определение минимального представления не такое очевидное, но тоже достаточно чёткое.
В CUBA есть понятие имени экземпляра сущности — instance name. Имя экземпляра — это эквивалент метода toString() в старой доброй Java. Это строковое представление сущности для отображения на UI и использования в ссылках. Имя экземпляра задаётся с помощью аннотации сущности NamePattern.
Используется оно так: @NamePattern("%s (%s)|name,code"). Результатов имеем целых два:
Имя экземпляра определяет отображение сущности в UI
Прежде всего, именем экземпляра определяется, что и в каком порядке будет отображаться в UI, если некая сущность ссылается на другую сущность (как Customer ссылается на CustomerType).
В нашем случае, тип покупателя будет отображаться как имя экземпляра CustomerType, к которому к скобках добавлен код. Если имя экземпляра не задано, будет отображено имя класса сущности и ID конкретного экземпляра, — согласитесь, это совсем не то, что хотел бы видеть пользователь. Примеры обоих случаев смотрите ниже на скриншотах “до и после”.
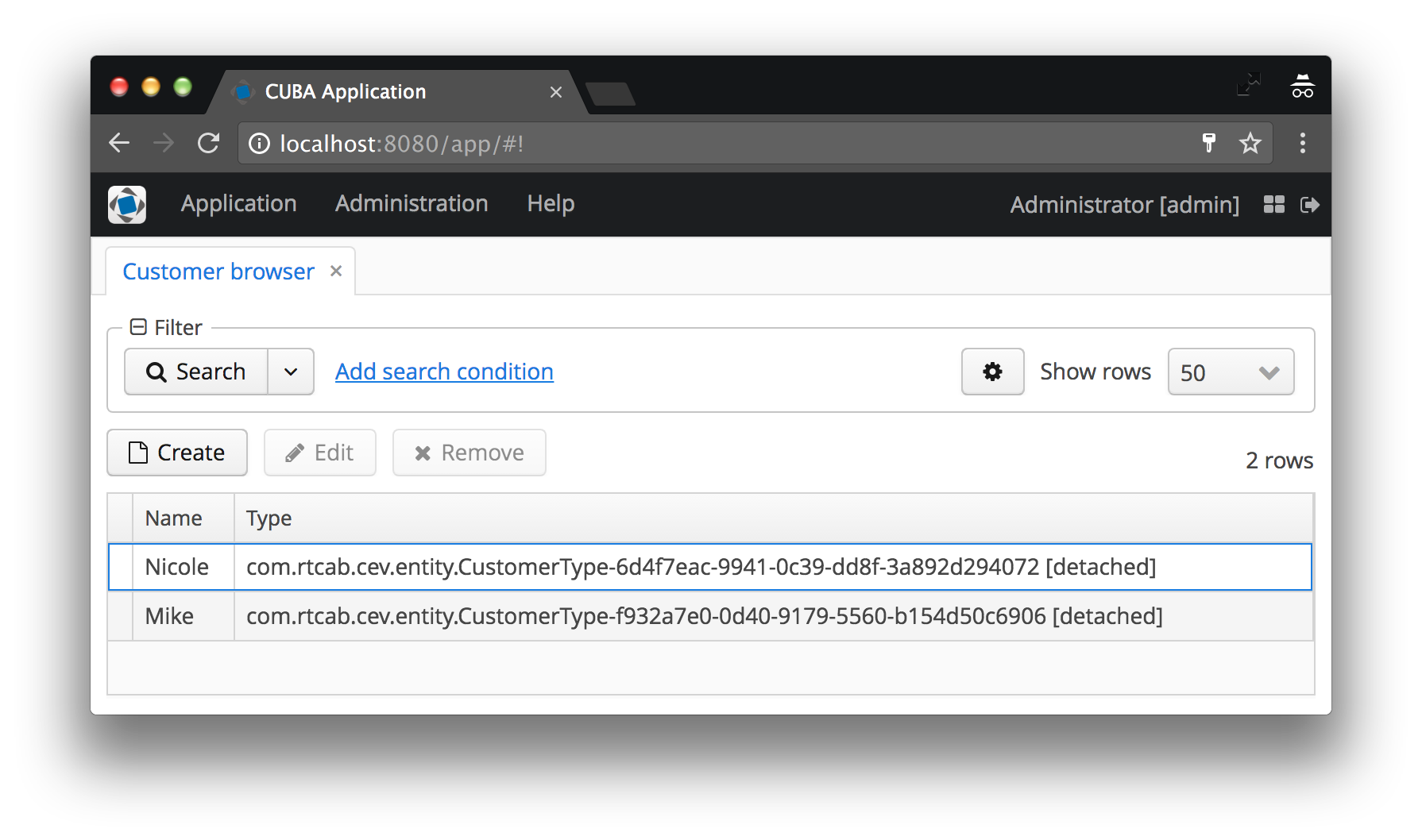
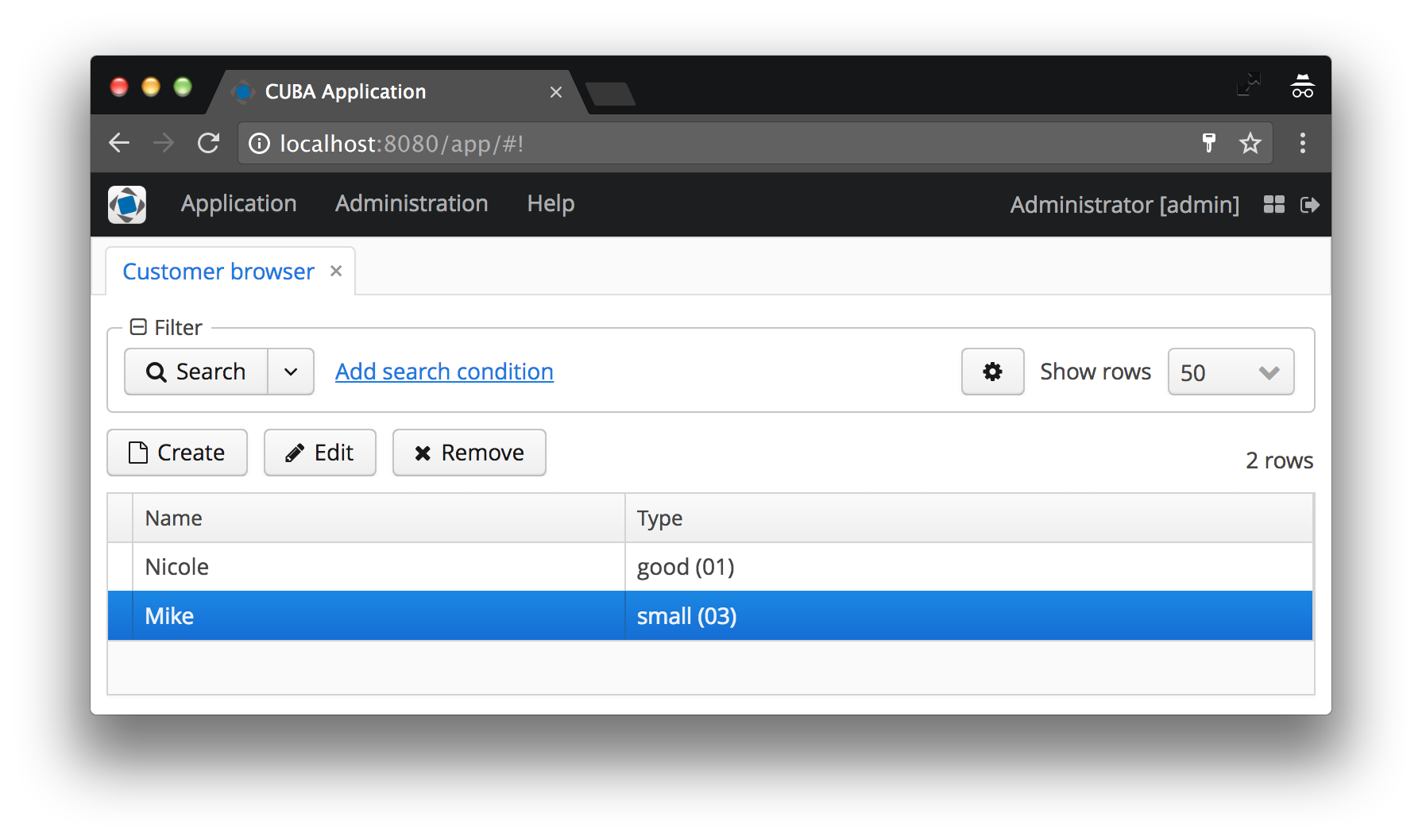
Имя экземпляра определяет атрибуты минимального представления
Второе, на что влияет аннотация NamePattern: все атрибуты, указанные после вертикальной черты автоматически формируют _minimal view. На первый взгляд это кажется очевидным, ведь данные в каком-то виде нужно отобразить в UI, а значит, сначала их нужно загрузить из базы. Хотя, если честно, я об этом факте задумываюсь нечасто.
Здесь важно обратить внимание, что минимальное представление, если сравнить с локальным, может содержать ссылки на другие сущности. Например, для покупателя из примера выше я задал instance name, в которое входит один локальный атрибут сущности Customer (name) и один ссылочный атрибут (type):
@NamePattern("%s - %s|name,type")Минимальное представление может использоваться рекурсивно: (Customer [Instance Name] --> CustomerType [Instance Name])
Примечание переводчика: с момента публикации статьи появилось еще одно системное представление — _base view, которая включает в себя все локальные несистемные атрибуты и атрибуты, заданные в аннотации @NamePattern (т.е. фактически _minimal + _local).
Заключение
В завершение подытожим самое важное по теме. Благодаря представлениям, в CUBA мы можем явно обозначить, что должно быть загружено из базы данных. Представления определяют, что будет загружено жадным образом, в то время как большинство других фреймворков скрыто выполняют ленивую загрузку.
Представления могут показаться громоздким механизмом, но в долгосрочной перспективе они оправдывают себя.
Надеюсь, у меня получилось доступно объяснить, чем на самом деле являются эти загадочные views. Конечно, есть и более продвинутые сценарии их использования, равно как и подводные камни в работе с представлениями вообще и с минимальными представлениями в частности, но об этом я как-нибудь напишу отдельным постом.