

Прошлого декабря прошла волна новостей о невероятной силы нового шахматного движка использующего искусственный интеллект AlphaZero компнании DeepMind. Сегодня они выпустили потрясающие результаты обновленной версии этого движка.
Результаты снова не оставляют никаких сомнений в том, что AlphaZero является одним из сильнейших шахматных движков в мире.
Обновленный AlphaZero разгромил Stockfish 8 в новом матче с 1000 партий с результатом: 155 побед, 6 поражений, 839 ничьих.
AlphaZero также переиграл Stockfish в серии партий с неравным контролем времени, побеждая традиционный движок даже при форе во времени в 10 раз.
По словам DeepMind, в дополнительных матчах новый AlphaZero превзошел «последнюю разрабатываемаю версию» Stockfish от 13 января 2018, показав практически идентичные результаты, как и в матче против Stockfish 8.
По словам DeepMind, их механизм машинного обучения также выиграл все матчи против «варианта Stockfish, который использует сильную дебютною книгу». Добавление дебютной книги, похоже, помогло Stockfish, который, наконец, выиграл значительное количество игр, когда AlphaZero играл черным, но недостаточно, чтобы выиграть матч.
Результаты были опубликованы в статье в журнале Science и предоставлены выбранным шахматным медиа.
Матч в 1000 игр был проведен в начале 2018 года. В матче AlphaZero и Stockfish были даны три часа каждой игры плюс 15-секундный прирост за ход. Этот контроль времени, по-видимому, сделает устаревшим один из самых больших аргументов против резутатов прошлогоднего матча, а именно то, что в 2017 году контроль времени на одну минуту за ход был сильным преимуществом для AlphaZero.
С тремя часами плюс 15-секундный прирост, такой аргумент не имеет смысла, так как это огромное количество игрового времени для любого шахматного движка. В играх с неравным временем, AlphaZero доминировал даже при соотношении времени 10-к-1. Stockfish начал побеждать только при соотношении 30-к-1.
Результаты AlphaZero в партиях с неравным временем показывают, что он не только намного сильнее, чем любой традиционный шахматный движок, но также использует гораздо более эффективный поиск ходов. Согласно DeepMind, AlphaZero использует поиск по дереву Монте-Карло и изучает около 60 000 позиций в секунду, по сравнению с 60 миллионами для Stockfish.
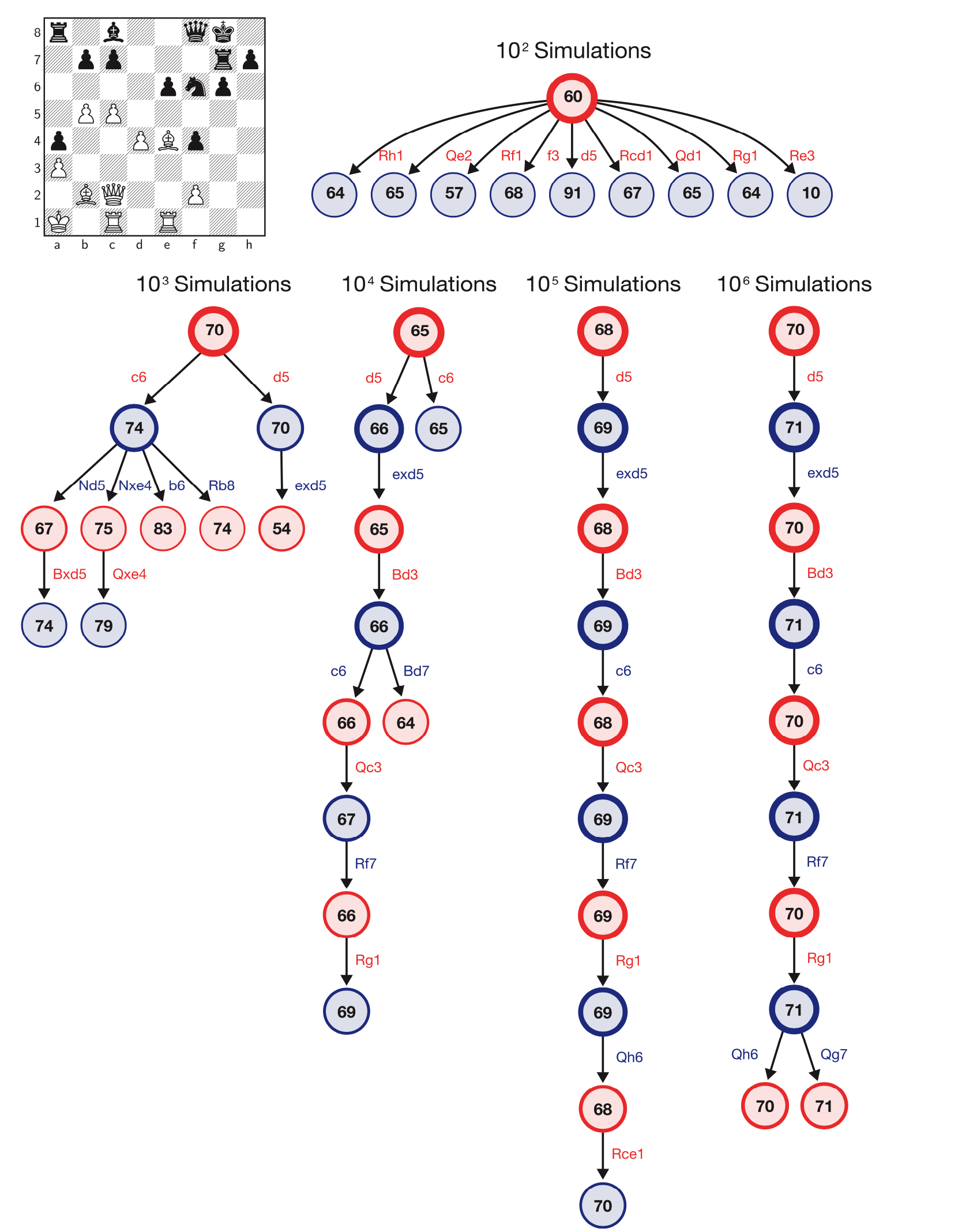
Иллюстрация алгоритма поиска ходов AlphaZero. Изображение DeepMind из статьи в Science.
Согласно статье, обновленный алгоритм AlphaZero идентичен в трех сложных играх: шахматах, сёги и го. Эта версия AlphaZero смогла победить лучших компьютерных движков всех трех игр после нескольких часов самообучения, начиная с простых правил игры.
DeepMind выпустили 210 игр из матча, которые вы можете скачать здесь.
Новая версия AlphaZero обучила себя играть в шахматы, начиная с правил игры, используя методы машинного обучения, чтобы постоянно обновлять свои нейронные сети. По данным DeepMind, для генерации первого набора игр для самостоятельной игры использовалось 5000 TPU (тензорный процессор Google, специализированная интегральная схема для ИИ), а затем 16 TPU использовались для обучения нейронных сетей.
Общее время обучения в шахматах заняло девять часов с нуля. Согласно DeepMind, новый AlphaZero потребовал всего четыре часа обучения, чтобы превзойти Stockfish; за девять часов он намного опередил чемпиона мира среди шахматных движков.
Для самих игр, Stockfish использовал 44 процессора, а AlphaZero использовал одну машину с четырьмя TPU и 44 ядрами процессора.
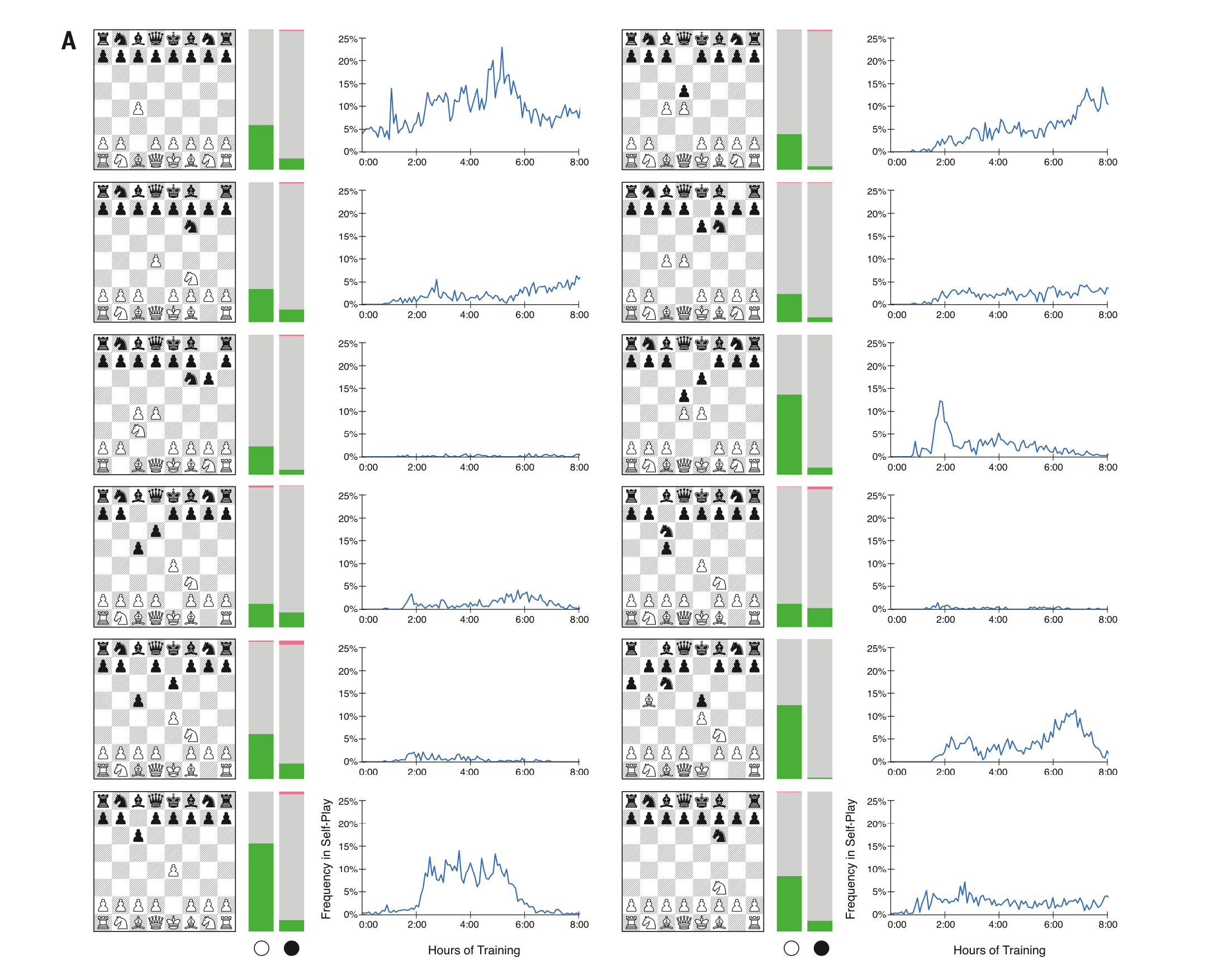
Результаты AlphaZero против Stockfish в самых популярных дебютах. Слева AlphaZero играет белыми; справа — черными.
DeepMind сами отметили уникальный стиль игры своей программы в статье:
«В нескольких играх AlphaZero пожертвовал фиграми для долгосрочного стратегического преимущества, предполагая, что он имеет более зависящую от контекста позиционную оценку, чем оценки, основанные на правилах, используемые в предыдущих шахматных программах», — сказали исследователи DeepMind.
Компания AI также подчеркнула важность использования той же версии AlphaZero в трех разных играх, рекламируя ее как прорыв в общем игровом интеллекте:
«Эти результаты приближают нас к выполнению многолетних амбиций искусственного интеллекта: общей игровой системы, которая может научиться освоить любую игру», — сказали исследователи DeepMind.
Комментарии (19)

olegshutov
07.12.2018 15:24Я вообще не люблю шахматы, но на самом деле разборы партий с комментами смотреть интересно

Gray5
07.12.2018 16:17+1Для самих игр, Stockfish использовал 44 процессора, а AlphaZero использовал одну машину с четырьмя TPU и 44 ядрами процессора.
Этим всё сказано.
Лучше бы сравнили с Lc0, который разрабатывался на основе идеи AlphaZero.
dmagin
07.12.2018 21:53+10Я посмотрел пару партий и снова, как и год назад, ощутил присутствие сверхразума. Его решения абсолютно непонятны, подражать ему невозможно. Не уверен, что можно извлечь пользу для шахматистов из этого разума, поскольку непонятно, как и чему можно научиться на таких партиях. Отдал 3 пешки за инициативу и выиграл через 30 ходов. Мда… Можно только восхищаться.
Akon32
08.12.2018 14:57Игроки в го вроде бы учатся у AlphaGo (говорят что учатся). И при анализе партий клоны AlphaGo Zero почти всегда используются.
dmagin
08.12.2018 18:49Шахматные программы и щас активно используются при подготовке и анализе. Удобно дебютные идеи проверять, ошибки смотреть и прочее. Но сама игра людей остается при этом вполне человеческой.
Вот только что закончился матч на первенство мира среди людей Карлсен — Каруана. Матч не особо получился интересным, но все партии вполне себе людские, понятны планы, ошибки и пр. Но матчи программ между собой (особенно альфы с рыбкой) — это вообще другие шахматы. С малодоступными идеями и приемами.
splxgf
08.12.2018 21:55Вы просто не так в шахматы играете, к примеру у меня всего второй разряд и пожертвовав на старте две-три пешки вполне неплохо себя чувствую против равных противников (правда это чаще блиц). Фигуры более мобильны и не скованы пешками. Хотя к этому пришел случайно, посмотрев обзор гамбитных дебютов.
Haber777 Автор
08.12.2018 21:59Среди современных топовых игроков тенденцию к использованию жертв фигур ради инициативы и мобильности можно увидеть например в партиях Магнуса Карслена, но все же в AlphaZero это какой-то совсем иной уровень.
dmagin
10.12.2018 10:09Да, известно, что чем короче контроль, тем сложнее защищаться. Поэтому в блице людей гамбитный стиль довольно популярен.
Вообще с приходом компов длинный контроль потерял свою привлекательность. При достижении определенного предела качество игры людей не увеличивается с ростом времени на раздумья. И чем сильнее шахматист, тем ниже этот предел.
Поэтому сейчас быстрые шахматы выходят на первый план. Некоторые известные гроссы вообще отказались играть при классическом контроле.
Akon32
08.12.2018 14:54Я слышал такую же новость (победа Alpha Zero в го и шахматы, обучение без использования базы человеческих партий) примерно год назад, в ноябре-декабре 2017.
В чём разница по сравнению с прошлым годом?
Откуда хайп сейчас?Haber777 Автор
08.12.2018 21:52+1В прошлом году использовался контроль времени в одну минуту за ход и это считалось большим преимуществом для AlphaZero, в этом году было отведено три часа на партию каждому движку плюс прирост времени в 15 секунд за ход. Кроме этого проводились партии с неравным контролем времени и AlphaZero начинал существенно проигрывать только при соотношении 30-к-1 на пользу Stockfish.
Вообще релиз партий AlphaZero всегда событие в шахматном мире не столько из-за условий матча и собственно победы, сколько из-за самых партий. Посколько AlphaZero не использует стандартной схемы анализа позиции (слон и конь — три пешки, ладья — пять и тд) которой пользуются классические движки, да и люди тоже, то партии получаются совсем необычные и очень интересные, а это уже событие на фоне некой общей стагнации в шахматах.
perfect_genius
08.12.2018 22:41-1А потом оно обучится понимать женщин, но не сможет поделиться этими знаниями с нами.
MyshinyjKorol
09.12.2018 13:02Было бы очень любопытно увидеть популярное описание значимости компьютерного железа для подобных результатов. Насколько сильно зависит сила игры этих и других программ от ресурсов использующейся машины. Вот то, что для этого матча по 44 процессора использовалось, — это некоторого рода уравнивание вычислительных мощностей или нет? Вроде довольно «небольшой комп»… Чтобы могло измениться в результатах, если бы классический движок играл бы на каком-нибудь суперкомпьютере из топ-500?
Nehc
10.12.2018 13:33А я бы с удовольствием почитал, желательно на русском, об общих принципах того, как именно там используется нейронная сеть… Т.е. она обучается, я бы даже сказал — самообучается, это понятно. Но вот чему именно? Особенно это интересно как раз в контексте жертвования фигур ради инициативы и тп.
Nehc
10.12.2018 13:35Черт… Не умею пользоваться поиском… ((
habr.com/post/279071
habr.com/post/343590
mikhaelkh
Опять основные результаты со Stockfish 8 двухлетней давности и без дебютной книги. И добавление дебютной книги привело к большему количеству поражений Stockfish белыми? Странно.
aksas
с дебютной книгой стокфиш смог выиграть больше партий белыми чем без. Вот тут есть картинки www.chess.com/news/view/updated-alphazero-crushes-stockfish-in-new-1-000-game-match