

Давным-давно, когда небо было голубым, трава зеленее и по Земле бродили динозавры… Нет, забудьте про динозавров. Ну, в общем, когда-то тогда пришла в голову мысль отвлечься от стандартного web-программирования и заняться чем-то более безумным. Можно было, конечно, чем угодно, но выбор пал на написание своего интерпретатора. Что я могу сказать… Никогда не пишите свои языки программирования. Но некоторый опыт из всего этого я извлёк, так что вот и решил поделиться. Начнём с самой основы — лексера.
Предисловие
Перед тем, как начать понимать что за животное такое «лексер» — стоит разобраться из чего вообще состоят ЯП.
В современном мире каждый компилятор/интерпретатор/транспайлер/что-то-там-ещё-подобное (давайте, я просто буду называть далее это «компилятором», без разграничений на типы) делится на два куска. В терминологии умных дядек подобные куски называются «фронтендом» и «бекендом». Нет, это совсем не то, работая с web, что мы привыкли называть и фронт не написан на JS с HTML. Хотя… Ладно.
Задача первого, фронтенда — взять текст и превратить его в AST (абстрактное синтаксическое дерево), по дороге проверив правильность синтаксиса (и иногда семантики). Задача второго, бекенда — заставить всё это работать. Если код собирается внутри интерпретатора, то из AST создаётся набор команд для виртуального процессора (виртуальной машины), если компилятор, то набор команд для реального процессора. В жизни всё довольно сложнее и реализовываться может не совсем так. Например, в случае с GCC компилятором — там всё вперемешку, а вот Clang уже более каноничен, LLVM — это типичный представитель «бекенда» для компиляторов.
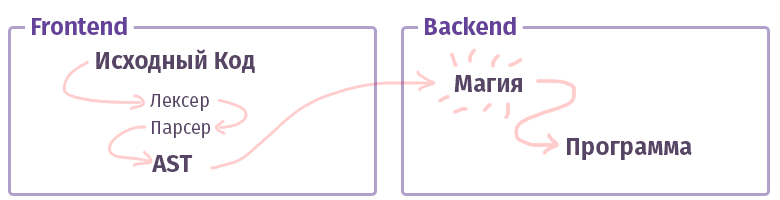
А теперь давайте познакомимся с куском, называемым «фронтендом».
Лексический анализ
Задача лексера и стадии лексического анализа — это получить на вход много-много букв и сгруппировать их по каким-то категориям — «токенам». По этому лексический анализ ещё называют «токенизацией». Это самая первая стадия обработки текста, которую производит каждый существующий компилятор.
Примерно вот так:
$tokens = ['class', '\w+', '}', '{'];
var_dump(lex('class Example {}', $tokens));
// array(4) {
// [0] => string(5) "class"
// [1] => string(7) "Example"
// [2] => string(1) "{"
// [3] => string(1) "}"
// }
К слову, тут у нас уже понаписана куча инструментов для облегчения жизни. Те же самые функции preg, которые мы привыкли использовать для парсинга текста — вполне себе справляется с данной задачей. Однако существуют и более удобные инструменты для этого дела:
- Phlexy, написанный Никитой Поповым.
- Hoa — инструментарий, состоящий из Лексера + Парсера + Грамматики.
- Порт Yacc, написанный Энтони Феррара, который так же представляет из себя комплексный инструментарий, и на котором написан небезызвестный PHP парсер Попова, применимый в инструментах, использующих анализ кода.
- Railt Lexer моя реализация под PHP 7.1+
- Parle — расширение для PHP, допускающее ограниченный набор PCRE выражений (нет lookahead и некоторых других синтаксических конструкций).
- Ну и наконец стандартная функция php token_get_all, которая предназначена непосредственно для лексического анализа PHP.
Ладно, понятно что штуковин, которые умеют делить текст по токенам — уйма, возможно я даже что-то забыл, вроде лексера Doctrine. Но что дальше?
Типы лексеров
И как всегда всё не так просто, как казалось. Существует как минимум две разных категории лексеров. Есть обычный вариант, довольно тривиальный, которому подсовываешь правила, а он уже делит всё на токены. Конфигурация оного мало чем отличается от примера, показанного мною выше. Однако есть и другой вариант, который называется multistate. Такие лексеры чуть сложнее для понимания, поэтому, хочется поговорить о них чуть подробнее.
Задача multistate лексера выводить различные токены в зависимости от предыдущего состояния. Ну например в PHP такие «переходные» состояния образовываются с помощью тегов <?php + ?>, внутри строк, комментариев и HEREDOC/NOWDOC конструкций.
Помните предыдущий пример с 4мя токенами выше? Давайте его чуть-чуть модифицируем, чтобы понимать что это за состояния такие:
class Example
{
// class Example {}
}
В данном случае, если мы имеем простейший лексер без широких возможностей PCRE, то получим следующий набор токенов:
var_dump(lex(...));
// array(9) {
// [0] => string(5) "class"
// [1] => string(7) "Example"
// [2] => string(1) "{"
// [3] => string(2) "//"
// [4] => string(5) "class"
// [5] => string(7) "Example"
// [6] => string(1) "{"
// [7] => string(1) "}"
// [8] => string(1) "}"
//}
Как видно, мы получили совершенно банальный косяк на элементах 3-5: Комментарий воспринялся совершенно неожиданно и сам поделился на токены, хотя должен был считаться как цельный кусок.
Конечно, при наличии функционала PCRE такой токен можно было бы выдрать с помощью простенькой регулярки "//[^\n]*\n", но если его нет? Ну или мы руками хотим запилить? Короче, в случае с multistate лексером — можно сказать, что все токены должны быть в группе No1, как только будет найден токен "//", то должен произойти переход в группу No2. А внутри второй группы обратный переход, если найден токен "\n" — переход обратно в первую группу.
Примерно как-то так:
$tokens = [
'group-1' => [
'class',
'\w+',
'{',
'}',
'//' => 'group-2' // Переход после слешей в группу 2
],
'group-2' => [
"\n" => 'group-1', // Переход в группу 1 после переноса строки
'.*'
]
];
Думаю теперь становится понятнее как парсится какой-нибудь HEREDOC, ведь даже при наличии всей мощи PCRE написать регулярку для этого дела крайне проблематично, учитывая то, что этот синтаксис HEREDOC поддерживает интерполяцию переменных. Просто попробуйте распарсить что-нибудь такое с помощью встроенной функции token_get_all (обратите внимание на >12 токен):
<?php
$example = 42;
$a = <<<EOL
Your answer is $example !!!
EOL;
var_dump(token_get_all(file_get_contents(__FILE__)));
Ладно, кажется мы уже готовы приступать к практике.
Практика
Давайте вспомним что у нас есть в PHP для подобных дел? Ну конечно, preg_match! Ладно, сойдёт. Алгоритм на основе preg_match реализован в Hoa и вот в этой реализации Phelxy. Задача его довольно проста:
- Имеем на руках исходный текст и массив из регулярок.
- Матчим до тех пор, пока что-то не найдётся подходящее.
- Как только нашли кусок, вырезаем его из текста и матчим дальше.
В виде кода он будет выглядеть примерно так:
<?php
class SimpleLexer
{
/**
* @var array<string>
*/
private $tokens = [];
/**
* @param array<string> $tokens
*/
public function __construct(array $tokens)
{
foreach ($tokens as $name => $definition) {
$this->tokens[$name] = \sprintf('/\G%s/isSum', $definition);
}
}
/**
* @param string $sources
* @return iterable&\Traversable<string>
* @throws RuntimeException
*/
public function lex(string $sources): iterable
{
[$offset, $length] = [0, \strlen($sources)];
while ($offset < $length) {
[$name, $token] = $this->next($sources, $offset);
yield $name => $token;
$offset += \strlen($token);
}
}
/**
* @param string $sources
* @param int $offset
* @return array<string,string>
* @throws RuntimeException
*/
private function next(string $sources, int $offset): array
{
foreach ($this->tokens as $name => $pcre) {
\preg_match($pcre, $sources, $matches, 0, $offset);
$token = \reset($matches);
if (\count($matches) && \strpos($sources, $token, $offset) === $offset) {
return [$name, $token];
}
}
throw new \RuntimeException('Unrecognized token at offset ' . $offset);
}
}
$lexer = new SimpleLexer([
'T_CLASS' => 'class',
'T_CONST' => '\w+',
'T_BRACE_OPEN' => '{',
'T_BRACE_CLOSE' => '}',
'T_WHITESPACE' => '\s+',
]);
echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n";
foreach ($lexer->lex('class Example {}') as $name => $token) {
echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n";
}
Такой подход довольно тривиален и позволяет парой тычков по клавиатуре модифицировать лексер в районе метода next(), добавив переход между состояниями и превратив это поделие рукоблудства в примитивный multistate лексер. В районе $this->tokens достаточно добавить что-то вроде $this->tokens[$this->state].
Однако, помимо самого примитивизма есть ещё один недостаток, не фатальный как могло оказаться, но всё же… Подобная реализация невероятно медленно работает. На i7 7600k, обладателем которого я по чистой случайности оказался — подобный алгоритм обрабатывает примерно 400 токенов в секунду, а при увеличении их вариаций (т.е. определений, которые мы передали в конструктор) — может замедлиться до скорости смены президентов в РФ… кхм, простите. Я хотел сказать, конечно, что будет работать очень медленно.
Ладно, что мы можем сделать? Для начала можно понять что же идёт не так. Дело в том, что каждый раз, когда мы вызываем preg_match внутри дебрей языка поднимается компилятор со своим JIT, называемый PCRE (А с PHP 7.3 уже PCRE2). Он каждый раз парсит сами регулярки и собирает для них парсер, с помощью которого мы парсим текст для создания токенов. Звучит чуть-чуть странно и тавтологично. Но если кратко, то каждый токен требует компиляции от 1 до N регулярок, где N — это количество определений этих токенов. При этом, стоит заметить, что даже применённый флаг "S" и оптимизация с помощью "\G" в конструкторе, где формируются регулярные выражения для токенов, не помогают.
Выход из этой ситуации напрашивается один — надо парсить весь этот текст в один проход, т.е. с помощью выполнения лишь одной функции preg_match. Осталось решить две проблемы:
- Как обозначить что результат регулярного выражения N1 соответствует токену N2? Т.е. как обозначить, что "\w+", например — это именно T_CONST.
- Как определить последовательность токенов в результате. Как известно, результат preg_match или preg_match_all будет содержать всё вперемешку. И даже с помощью флагов, передаваемых в качестве четвёртого аргумента ситуация не изменится.
Тут можно сделать паузу и чуть-чуть подумать. Ну или нет.
Решение первой проблемы — это именованные группы PCRE, которые так же именуются «подмасками». С помощью правил: "(?<T_WHITESPACE>\s+|<T_WORD>\w+|...)" можно за один проход выгрести все токены сопоставив с их именами. В результате матчинга будет образовываться ассоциативный массив, состоящий из пар "[TOKEN_NAME => TOKEN_VALUE]".
Со второй чуть сложнее. Но тут можно применить тактическую хитрость и воспользоваться функцией preg_replace_callback. Особенность её в том, что анонимка, переданная в качестве второго аргумента будет вызываться строго последовательно, для каждого токена, от первого до последнего.
Дабы не томить — реализация следующая:
class PregReplaceLexer
{
/**
* @var array<string>
*/
private $tokens = [];
/**
* @param array<string> $tokens
*/
public function __construct(array $tokens)
{
foreach ($tokens as $name => $definition) {
$this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition);
}
}
/**
* @param string $sources
* @return iterable&\Traversable<string,string>
*/
public function lex(string $sources): iterable
{
$result = [];
\preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) {
foreach (\array_reverse($matches) as $name => $value) {
if (\is_string($name) && $value !== '') {
$result[] = [$name, $value];
break;
}
}
}, $sources);
foreach ($result as [$name, $value]) {
yield $name => $value;
}
}
/**
* @return string
*/
private function compilePcre(): string
{
return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens));
}
}
А её использование ничем не отличается от предыдущего варианта. При этом скорость работы возрастает с 400 до 57000 токенов в секунду. Именно этот алгоритм я применил в своей реализации, взявшись за переписывание исходников Hoa. К слову, если воспользоваться Parle, то можно выжать до 600000 токенов в секунду. А общая картина выглядит примерно следующим образом (с включённым XDebug на PHP 7.1, так что цифры тут ниже, но соотношение можно приблизительно представить).
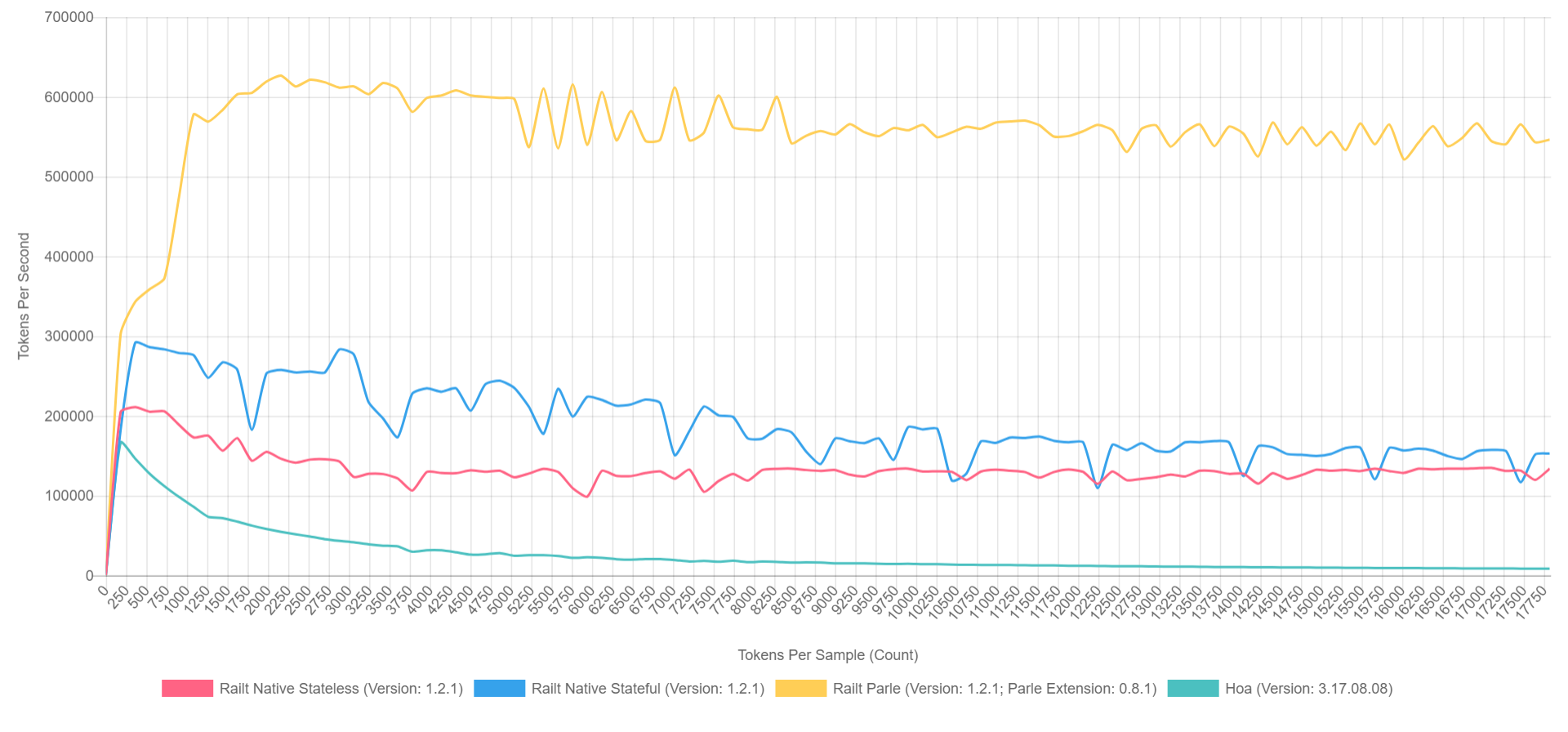
- Жёлтый — нативное расширение Parle.
- Голубой — реализация через preg_replace_callback с предварительно собранной регуляркой.
- Красный — всё тоже самое, но с генерируемой регуляркой во время вызова preg_replace_callback.
- Зелёный — реализация через preg_match.
Зачем?
Ладно, всё это, конечно, замечательно, но нетерпеливые жаждут задать вопрос: «Кому это вообще нужно?». В абстрактном мире PHP, где главенствует принцип «фигак-фигак-и-сайт-готов» — подобные библиотеки не нужны, будем честными. Но если говорить об экосистеме в целом, то можно вспомнить небезызвестные библиотеки, вроде symfony/yaml или Doctrine. Аннотации в Symfony — это такой же подязык внутри PHP, требующий отдельного лексического и синтаксического разбора. Помимо этого есть ещё чуть менее известные транспайлеры CoffeeScript, Less и Scss/Sass, написанные на PHP. Ну или Yay и preprocess, основанный на нём. Я даже не буду упоминать инструменты анализа кода, вроде phpmd или phpcs. Да и генераторы документации, вроде phpDocumentnor или Sami — довольно тривиальны. Каждый и этих проектов в той или иной степени использует лексический анализ на первой стадии разбора текста/кода.
Это далеко не полный список проектов и возможно, надеюсь, мой рассказ поможет вам открыть что-то новое и пополнить его.
Послесловие
Забегая вперёд, если есть кто-либо заинтересованный в тематике парсеров и компиляторов, то есть несколько интересных докладов по этой теме, в частности от ребят из JetBrains:
Ещё, конечно, большинство выступлений Андрея Бреслава (abreslav), которые можно найти на просторах YouTube — советую к просмотру.
Ну а для любителей чтива есть вот такой ресурс, который был лично для меня крайне полезным.
Пост пост скриптум. Если где-то опечатался на просторах сего эпоса, то можете смело сообщать автору в любой удобной для вас форме.
В качестве бонуса, хотел бы привести пример простого лексера PHP, кажется это не так уж теперь и страшно, и теперь даже понятно что он делает, верно? Хотя кого я обманываю, от регулярок глаза кровоточат. =)
Спасибо!
Комментарии (18)

rjhdby
04.01.2019 11:06+2Есть у меня смутное подозрение, что самописный конечный автомат будет для этой задачи сильно производительней (и, возможно, проще для понимания)
PS Теги для поиска по ним, а не для чтения. Спасибо за статью! :)SerafimArts Автор
04.01.2019 11:18Fesor уже пытался запилить его следуя этой же логике, адаптировав для этой цели re2c. Но что получилось в итоге не совсем понятно. Думаю, когда увидит моё упоминание — сможет поподробнее написать к чему пришёл в комментах.
Но почему-то лично меня терзают смутные сомнения в успехе мероприятия, т.к. простой цикл с проходом по буковкам в PHP довольно тормозной.rjhdby
04.01.2019 11:40простой цикл с проходом по буковкам в PHP довольно тормозной.
Это да. С другой стороны, никто не мешает работать не со строкой, а с массивом байт. Оно, по идее, должно быть сильно быстрее.
SerafimArts Автор
04.01.2019 11:49+1Заголовок спойлера<?php $data = \file_get_contents(__FILE__); $attempts = 100000; $before = \microtime(true); for ($i = 0; $i < $attempts; $i++) { foreach (\str_split($data) as $chars => $char) { // Do something } } /// ===================================== echo \number_format(\microtime(true) - $before, 4) . 's / ' . $chars . "\n"; $before = \microtime(true); for ($i = 0; $i < $attempts; $i++) { foreach (\unpack('C*', $data) as $bytes => $byte) { // Do something } } echo \number_format(\microtime(true) - $before, 4) . 's / ' . $bytes . "\n";rjhdby
05.01.2019 10:41Как чувствовал — убрал упоминание unpack раньше появления вашего ответа. :)
Про массив байт — это я конечно маху дал, PHP же, какой массив байт?..
Зато добавил к вашему «тесту» третий вариант, с интересным результатом.
Заголовок спойлера<?php $data = \file_get_contents(__FILE__); $attempts = 10000; $before = \microtime(true); for ($i = 0; $i < $attempts; $i++) { $data = \file_get_contents(__FILE__); foreach (\str_split($data) as $chars => $char) { // Do something } } echo 'str_split: ' . \number_format(\microtime(true) - $before, 4) . 's / ' . $chars . "\n"; $before = \microtime(true); for ($i = 0; $i < $attempts; $i++) { $data = \file_get_contents(__FILE__); foreach (\unpack('C*', $data) as $bytes => $byte) { // Do something } } echo 'unpack : ' . \number_format(\microtime(true) - $before, 4) . 's / ' . $bytes . "\n"; $before = \microtime(true); for ($i = 0; $i < $attempts; $i++) { $handle=fopen(__FILE__,"r"); while ($char = fread($handle,1)) { // Do something } fclose($handle); } echo 'fread : ' . \number_format(\microtime(true) - $before, 4) . 's / ' . $bytes . "\n";SerafimArts Автор
05.01.2019 11:46fread: 0.1524s / 968
Я пробовал этот вариант, и он медленнее оказался побуквенного чтения из строки. Но зато сейчас проверил с чтением из памяти, а он уже оказался самым быстрым. Не буду томить:
Код тестов<?php $data = \file_get_contents(__FILE__); $attempts = 10000; function test(string $title, int $attempts, \Closure $expression) { $before = \microtime(true); for ($i = 0; $i < $attempts; $i++) { $expression(); } $after = number_format(\microtime(true) - $before, 4); echo \sprintf('%-13s: %ss', $title, $after) . "\n"; } test('str_split', $attempts, function() { $data = \file_get_contents(__FILE__); foreach (\str_split($data) as $chars => $char) { // Do something } }); test('unpack', $attempts, function() { $data = \file_get_contents(__FILE__); foreach (\unpack('C*', $data) as $bytes => $byte) { // Do something } }); test('fread', $attempts, function() { $handle = fopen(__FILE__, 'rb+'); while (! feof($handle)) { $char = fread($handle, 1); } fclose($handle); }); test('$data[$i]', $attempts, function() { $data = \file_get_contents(__FILE__); for ($i = 0, $bytes = strlen($data); $i < $bytes; ++$i) { $char = $data[$i]; } }); test('fread + mem', $attempts, function() { $handle = fopen('php://memory', 'ab+'); stream_copy_to_stream(fopen(__FILE__, 'rb+'), $handle); while (! feof($handle)) { $char = fread($handle, 1); } fclose($handle); });bashkarev
05.01.2019 17:41В тесте ошибка, после
stream_copy_to_streamуказатель не сбрасываетсяSerafimArts Автор
05.01.2019 17:46Это не обязательно. Интерпретатор автоматом закрывает потоки чтения/записи при refcount=0 (т.е. в данном случае при выходе за пределы анонимной функции). Но да, действительно так писать не очень хорошо и с моей стороны была допущена опечатка.
Добавил fclose внутреннего ресурса. Соотношение по скорости, естественно, не изменилось (всё на уровне погрешностей).
Заголовок спойлераtest('fread + mem', $attempts, function() { $handle = fopen('php://memory', 'ab+'); stream_copy_to_stream($fp = fopen(__FILE__, 'rb+'), $handle); while (! feof($handle)) { $char = fread($handle, 1); } fclose($handle); fclose($fp); });bashkarev
05.01.2019 18:21+1код во while не выполняется
test('fread + mem',$attempts, function () { $handle = fopen('php://memory', 'ab+'); stream_copy_to_stream($fp = fopen(__FILE__, 'rb+'), $handle); echo 'ftell:', ftell($handle), ', feof:', feof($handle) ? 'true' : 'false', PHP_EOL; while (!feof($handle)) { $char = fread($handle, 1); } fclose($handle); fclose($fp); } );SerafimArts Автор
05.01.2019 18:25Блин, точно! Добавил fseek на 0 и скорость сразу же просела до 1.6541s
netch80
04.01.2019 12:58+1> Есть у меня смутное подозрение, что самописный конечный автомат будет для этой задачи сильно производительней (и, возможно, проще для понимания)
Для освоения идеи — наверно, да. Но постоянно такое писать слишком неудобно, а часто и сопровождать.
К счастью, такие возможности медленно, но планомерно проникают в средства.
Даже во flex есть, там это зовётся conditions. re2c — аналогично; вообще, слово conditions тут, похоже, становится основным, хотя я бы предпочёл contexts.
Lure_of_Chaos
04.01.2019 19:36Есть два вопроса:
Почему бы не сделать конечный автомат, а апгрейдить регулярки?
Зачем использовать php для такого хардкора?
Я понимаю, что можно и даже проще так, особенно если пока нет более глубокого понимания, но очень хочется, но всё же…
И да, ещё более странно, что говоря о компиляторах, парсерах, лексерах — ни разу не всплыл термин «грамматика», и далее уж КС, ЛКС и вот это вот все…SerafimArts Автор
04.01.2019 20:02Почему бы не сделать конечный автомат, а апгрейдить регулярки?
Насколько я понял вопрос — имеется ввиду «почему не запилить НКА, вместо использования регулярок»?
Если есть желание поэкспериментировать с этим и/или переписать какой-нибудь re2c на php с сомнительным результатом (т.е. я намекаю на то, что в PREG, написанном на сях вполне возможно будет это дело работать быстрее, нежели на нативном php), то пожалуйста. Лично мне было откровенно лениво это всё писать, а задачи ДКА/НКА переложил на LL(k) парсер.
Зачем использовать php для такого хардкора?
Потому что для PHP есть огромное количество задач, требующих качественного разбора текста в AST. В эпилоге я перечислил большинство из них.
Заголовок спойлераВ моём случае это был GraphQL SDL, который я реализовал полностью с нуля, включая парсер и «комплятор-компиляторов» грамматик: github.com/railt/railt/blob/master/resources/grammar/grammar.pp2, реализацию полноценного интерпретатора с прикручиванием отладчиков:
Но пилить до стабильной версии там ещё довольно много чего, хотя на продакшене уже кое-где используется.pbatanov
05.01.2019 11:08+1Рискну предположить, что в терминах грамматик под КС подразумевалась группа контекстно-свободных грамматик (то, что идет у вас под перечислением LL/LR/LALR/SLR)
SmartyTimmi
05.01.2019 22:31Хоть совершенно не люблю php и стараюсь его обходить, было интересно, особенно удивила обработка 600000 t/s.
Большое спасибо за материалы, сам сейчас занимаюсь разработкой языка, очень кстати подобные статьи, пилите еще, пожалуйста!))
P.S. А любителям Питона зайдет SLY, я думаю
RussDragon
Что ж за неделя своих языков, парсеров и компиляторов такая? :)
prospero78su
А я, например, только за. И вообще: даёшь год Оберонов!))