
В предыдущей статье от Питерской Вышки мы показывали, как при помощи машинного обучения можно искать баги в программном коде. В этом посте расскажем о том, как мы вместе с JetBrains Research пытаемся использовать один из самых интересных, современных и быстроразвивающихся разделов машинного обучения — обучение с подкреплением — как в реальных практических задачах, так и на модельных примерах.

О себе
Зовут меня Никита Сазанович. До июня 2018 года я три года учился в СПбАУ, а затем вместе с остальными моими одногруппниками перевелся в ВШЭ СПб, где и заканчиваю сейчас бакалавриат. С недавнего времени я также работаю исследователем в JetBrains Research. До поступления в университет я увлекался спортивным программированием и выступал за сборную Беларуси.
Обучение с подкреплением
Обучение с подкреплением — это такая ветвь машинного обучения, в которой агент, взаимодействуя со средой, получает подкрепление (отсюда и название) в виде положительной или отрицательной награды. В зависимости от этих подсказок, агент меняет свое поведение. Конечная цель этого процесса — получить как можно большую награду, или, по-другому, достигнуть тех действий, которые поставили перед агентом.
Агенты оперируют на состояниях и выбирают действия. Например, в задаче о выходе из лабиринта нашими состояниями будут координаты x и y, а действиями движения вверх/вниз/влево/вправо. Общая же схема выглядит вот так:
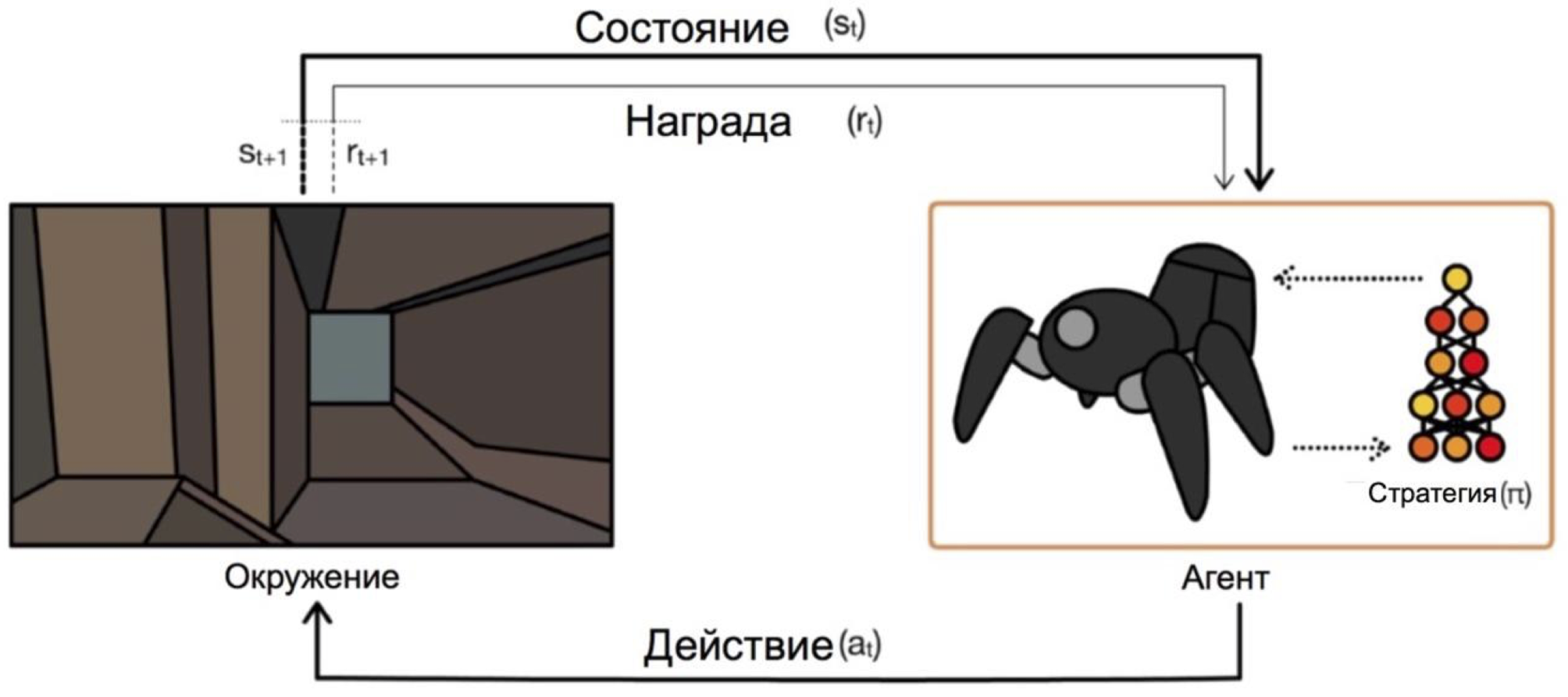
Основная проблема при переходе от выдуманных/простых задач (как этот же лабиринт) к реальным/практическим задачам такая: награды в таких задачах, как правило, очень редки. Если мы хотим, чтобы агент, к примеру, доставлял пиццу по карте города, то поймет он, что сделал что-то хорошо, только доставив заказ до двери, а это случится только если выполнить длинную и правильную последовательность действий.
Решить эту проблему можно, дав агенту на старте примеры того, как "нужно играть" — так называемые демонстрации экспертов.
Задача для обучения
Модельная задача, о которой пойдет речь в статье — это Dota 2.
Dota 2 — это популярная MOBA игра, в которой команда из пяти героев должна победить команду соперника, уничтожив их "крепость". Dota 2 считается довольно сложной игрой, в ней есть esports с призовыми на главном турнире в $25000000.
Вы могли слышать про недавние успехи OpenAI в Dota 2. Сначала они создали бота для игры один на один и победили профессиональных игроков, а потом перешли к игре 5x5 и этим летом показали впечатляющие результаты, хотя и проиграли профессиональным командам.

Единственной проблемой является то, что обучали они агента для игры один на один, по их же словам, на 60000 ЦПУ и 256 K80 GPU на облаке Azure. У них, конечно, есть возможность заказать столько мощи. Но если у вас мощности меньше, то приходится применять хитрости. Одной из такой хитростей и является использование уже сыгранных людьми игр.
Демонстрации в игре
В большинстве случаев демонстрации записываются искусственно: вы просто выполняете задачу/играете в игру и как-нибудь собираете действия, которые предприняли. Так вы соберете какие-то данные, которые можно разными способами встраивать в обучение. Я пока так и поступил, но как именно — будет понятно после части о схеме взаимодействия с клиентом игры.
Более масштабная и авантюрная цель — это достать большее количество данных из открытого доступа. Одной из причин при выборе Dota 2 для ускорения обучения был такой ресурс, как dotabuff. Там собрана разная статистика по игре, но более важно то, что там есть полные реплеи игр. И их можно сортировать по рейтингу.
Пока я еще не опробовал, как сильно поможет гигабайт таких данных в сравнении с несколькими эпизодами. Реализовать же сбор данных было довольно просто: вы получаете ссылки на игры на dotabuff, скачиваете игры и пользуетесь парсером игр Dota 2.
Связка с клиентом игры для обучения
У нас есть игра Dota 2, клиент которой существует под платформы Windows, Linux и macOS. Но все же обычно обучение происходит в каком-то скрипте на python, и в нем вы создаете среду, будь то лабиринт, подъем машины на горку или что-то в таком роде. Но среды для Dota 2 нет. Поэтому мне самому пришлось создавать эту обертку, что было довольно интересно технически. Получилось это сделать так:
{kind=link}
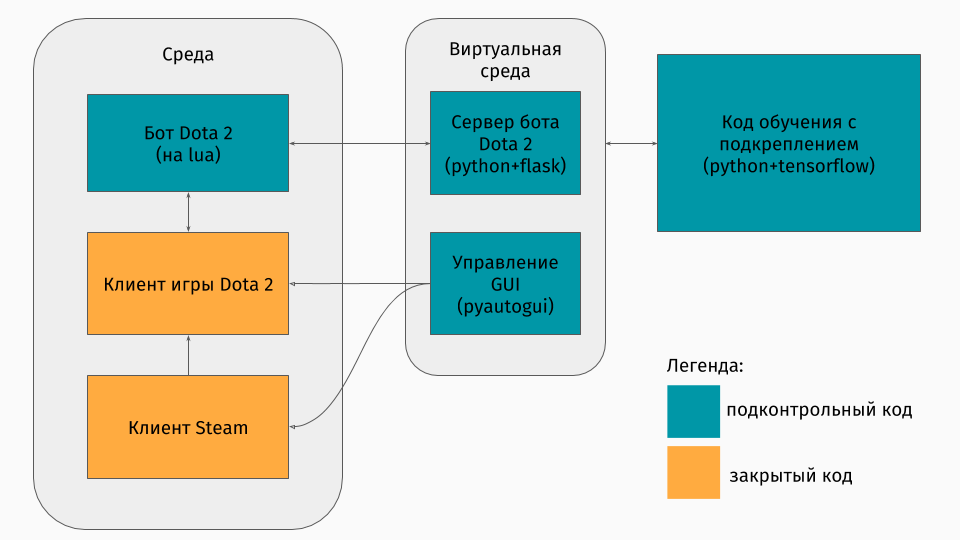
Первая часть — это скрипт для общения с клиентом игры. К счастью, для Dota 2 есть официальный API для создания ботов: Dota Bot Scripting. Реализован он как вставки на языке Lua, который, как оказалось, популярен в разработке игр. Скрипт бота же, взаимодействуя с клиентом игры, вытаскивает в нужный момент интересную нам информацию (например, координаты на карте, позиции противников) и отправляет json с ней на сервер.
Вторая часть — это собственно сама обертка. Это оформлено в виде сервера, который обрабатывают всю логику запуска Steam-а, Dota-ы и получением json-ов от скрипта внутри игры. Управление запуском игр и клиентов устроено через pyautogui, а общение с lua-вставкой в игре — через Flask сервер.
Третья часть состоит собственно из алгоритма обучения. Этот алгоритм выбирает действия, получает следующие состояния и награды от сервера, за которым скрыто все общение с игрой, и улучшает свое поведение.
Учимся у экспертов
Сам алгоритм не особо важен в этой статье, ведь эти техники можно применять с любым алгоритмом. Мы использовали DQN (о котором можно почитать на хабре). По сути, это глубокая нейронная сеть + алгоритм Q-обучения. Да, это именно тот DQN, который создал DeepMind, чтобы играть в Atari игры.
Здесь же интереснее рассказать о том, как использовать предыдущие игры. Я испытал два подхода: potential-based reward shaping и action advice.
Общая идея подходов состоит в том, что награду агент будет получать не только по целям задачи (например, по завершению лабиринта или по подъему на гору), но и во время обучения на каждом шаге. Эта дополнительная награда будет показывать, насколько хорошо агент действует, чтобы достичь финальной цели. Задавать бы ее, конечно, хотелось бы автоматически, а не подбирать правилами/условиями. Следующие подходы помогают этого достичь.
Суть potential-based reward shaping в том, что какие-то состояния нам изначально кажутся более перспективными чем другие, и на основе этого мы модифицируем реальные награды, которые получает алгоритм. Делаем мы это вот таким образом: , где — награда модифицированная, — награда реальная, — discount factor из алгоритма обучения (не особо нам важен), а вот и есть наш потенциал для состояния, которое мы посетили во время . Простой пример — это преодоление лабиринта.
Допустим, есть лабиринт, в котором мы хотим из клетки (0,0) прийти в клетку (5,5). Тогда нашим потенциалом для состояния (x,y) может стать минус евклидово расстояние от (x,y) до нашей цели (5,5): . То есть чем ближе мы к финишу, тем больший потенциал у состояния (к примеру, , , ). Так мы мотивируем агента любыми способами приближаться к цели.
Для Dota 2 идея такая же, но потенциалы задаются немного сложнее:

Представьте, что мы просто хотим пройти по тем же состояниям, что и демонстратор. Тогда чем больше состояний мы пройдем, тем выше потенциал. Мы ставим потенциал состояния по проценту завершения реплея, если там есть состояние, близкое нашему. Это имеет разный смысл в различных задачах. Но именно в Dota 2 это означает, что сначала мы хотим, чтобы бот дошел до центра (ведь в начале демонстраций есть только шаги к центру), а потом держался состояний игрока-человека (большое здоровье, безопасное расстояние до противников и т.д.).
Второй же метод, action-advice, был взят из этой статьи. Его суть в том, что сейчас мы советуем агенту не полезность состояний, а полезность действий. Например, в нашей игре Dota 2 могут быть такие советы: если около тебя есть вражеский миньон, то атакуй его; если же ты не дошел до центра, то иди в его направлении; если теряешь здоровье, то отступай к своей башне. И в этой статье описан метод задания таких советов без каких-нибудь раздумий самим программистом — автоматически.
Потенциалы сгенерированы по такому принципу: потенциал действия в состоянии
увеличивается при наличии близких состояний с таким же
действием в демонстрациях. Дальше награда за действие на схеме выше
изменяется как .
Здесь стоит заметить, что потенциалы мы задаем уже для действий в состояниях.
Результаты
Для начала замечу, что цель игры была слегка упрощена, ведь обучал я это все на своем ноутбуке. Целью агента было нанести как можно больше атак, что похоже на реальную цель в каком-то приближении. Для этого сначала нужно добраться в центр карты и потом атаковать противников, стараясь не умереть. Для ускорения обучения были использованы всего несколько (от 1 до 3) двухминутных демонстраций записанных мною самим.
Обучение агента с использованием любого из подходов занимает всего 20 часов на персональном компьютере (большую часть времени занимает отрисовка игры Dota 2), а судя по графикам OpenAI, обучение на их серверах идет на порядки недель.
Небольшая выдержка игры при использовании подхода potential-based reward shaping:
И для подхода action advice:
Эти записи были сделаны на скорости тренировки — x10. Все еще видны неточности в поведении агента при перемещении к центру, но все равно борьба в центре показывает выученные маневры. К примеру, отступление назад при малом здоровье.
Также можно видеть разницы подходов: при potential-based reward shaping агент передвигается плавно, т.к. "идет по потенциалу"; при action advice бот играет более агрессивно в центре, так как получает подсказки по атаке.
Итоги
Сразу отмечу, что некоторые моменты были намеренно опущены: какой был алгоритм в точности, каким образом представлялось состояние, а можно ли обучить агента для игры с реальными игроками, и т.д.
Прежде всего, мне в этой статье хотелось показать, что в случае обучения с подкреплением вам не всегда нужно выбирать между очень простой средой (побег из лабиринта) или очень большой стоимостью обучения (по моим беглым подсчетам, OpenAI обходились те сервера для обучения на Azure $4715 в час). Существуют техники, которые позволяют ускорить обучение, и я рассказал лишь об одной из них — использование демонстраций. Важно отметить, что таким образом вы не просто повторяете демонстратора, а лишь "отталкиваетесь" от него. Важно, что при дальнейшем обучении у агента есть возможность превзойти экспертов.
Если вам интересны детали, то код процесса обучения можно найти на GitHub.
helgihabr
Можно больше деталей по подсчетам стоимости серверов в Azure? А то ценник впечатляет.
miksaz Автор
Да конечно.
В блоге по ссылке из поста выше они упоминали, что использовали 60000 ЦПУ и 256 K80 GPU. В другом блоге про их инфраструктуру они рассказывали, как им помогает Kubernetes в управлении их виртуалками с Azure моделей D15 v2 и NC24.
На сайте с ценами Azure можно глянуть, что D15 v2 имеет 20 ЦПУ и стоит $1.495/час, а NC24 включает 4X K80 и стоит $3.60/час.
Получается, что все это стоит 60000/20*$1.495/час+256/4*$3.60/час=$4715.4/час. Но это такая беглая оценка на случай, если кто-то вдруг захочет это повторить прямо сейчас. У OpenAI наверняка виртуалки забронированы на несколько лет, и там скидки есть.
ingvard
Я могу ошибаться, но Azure может спонсировать образовательные программы или «пиар акции», поэтому если очень сильно попросить (в обмен на рекламу), можно получить бесплатные ресурсы.
Я не эксперт в машинном обучении, но мне меня удивило то, что подсчет идет по ядрам CPU, а не GPU?
А ваше решение может учится распределено, те используя кластер? Мне интересен вопрос распараллеливания среды, как понимаю tensorflow из коробки делает распределенную обработку?
Очень жалко АУ, хорошо, что где-то ребята делают полезные работы бакалавров;)
miksaz Автор
Не знал об этом, но вы правы насчет стоимости серверов, и они действительно сотрудничают в этом деле. Приведенная цена больше подходит под стоимость для «обособленного пользователя».
А про ядра и параллельности я вот как понимаю: большинство ml framework-ов (tensorflow, pytorch) поддерживают распределенную обработку, и проблем с этим не должно возникать. Среды же обычно, из моего опыта, просто независимо запускают на машинах.
К примеру, в другой задаче по RL мы использовали 72 ЦПУ и 1 V100 GPU. И расстановка была такая: на 72 ЦПУ мы запустили разные конфигурации сред, которые работали независимо друг от друга, и отправляли данные на GPU. А сервер с видеокартой обучал сеть из полученных со всех сред данных (ведь большинство RL алгоритмов не требуют однородного опыта). Эти среды зачастую очень CPU-intensive. Ведь считается только логика (обновление позиций, пересечения), без прорисовки, и там нет особого простора для каких-то однородных вычислений (с чем помогает GPU).
Поэтому я полагаю, что в OpenAI посчитали, что для 256 GPU нужно X опыта, и получили его, играя независимо несколько десятков тысяч Dota игр на всех ЦПУ.
У меня решение пока не адаптировано для обучения на кластере. Ведь хотелось не сразиться с OpenAI, а лишь проверить насколько «легко» можно обучить бота, используя демонстрации. (: