
Поэтому давайте разбираться, что там есть, как оно все устроено, где основные архитектурные сложности и где в АЭС можно применить модные технологии ML и VR.

Атомная электростанция это:
- В среднем 3-4 энергоблока со средней мощностью 1000 МВт на одну АЭС, потому что физические системы должны резервироваться, так же, как и сервисы в интернете.
- Порядка 150 специальных подсистем, которые обеспечивают функционирование данного объекта. Например, это система внутриреакторного контроля, система управления турбиной, система управления химводоочисткой и т.д. Каждая из этих подсистем интегрируется в огромную систему верхнего блочного уровня (СВБУ) автоматизированной системы управления технологическими процессами (АСУ ТП).
- 200-300 тысяч тэгов, то есть источников сигналов, которые изменяются в реальном масштабе времени. Нужно понять, что является изменением, что нет, не пропустили ли мы чего-нибудь, а если пропустили, то что с этим делать. За этими параметрами следят два оператора, ведущий инженер управления реактором (ВИУР) и ведущий инженер управления турбиной (ВИУТ).
- Два здания, в которых сконцентрировано большинство подсистем: реакторное и турбинное отделение. Два человека должны в реальном времени принимать решение в случае, если происходят нестандартные, или стандартные, события. Такая высокая ответственность накладывается всего на двух человек, потому что если их будет больше, то им нужно будет между собой договариваться.
О спикере: Вадим Подольный (electrovenic) представляет Московский завод Физприбор. Это не просто завод — это прежде всего инжиниринговое бюро, в котором разрабатывается как аппаратное, так и программное обеспечение. Название является данью истории предприятия, которое существует с 1942 года. Это не очень модно, но очень надежно – вот что хотели им сказать.
IIoT на АЭС
Физприбор предприятие производит весь комплекс оборудования, который необходим для обеспечения сопряжения всего огромного количества подсистем – это датчики, контроллеры низовой автоматики, платформы для построения контроллеров низовой автоматики и пр.
В современном исполнении контроллер – это просто промышленный сервер, у которого расширенное количество портов ввода-вывода для сопряжения оборудования со специальных подсистем. Это огромные шкафы — такие же, как серверные, только в них располагаются специальные контроллеры, которые обеспечивают вычисления, сбор, обработку, управление.
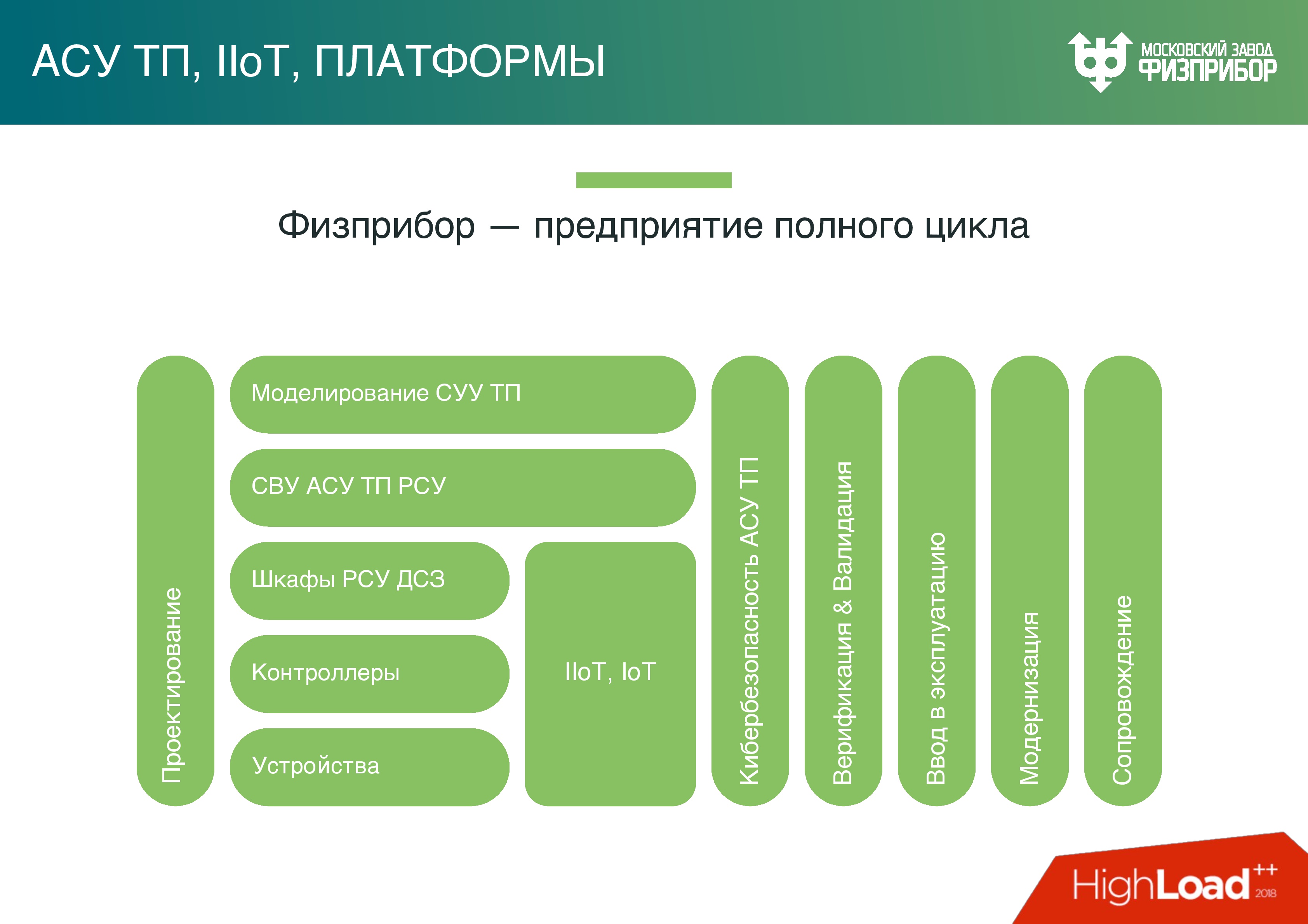
Мы разрабатываем программное обеспечение, которое устанавливается на эти контроллеры, на шлюзовое оборудование. Дальше также, как и везде, у нас есть ЦОДы, локальное облако, в котором происходит обсчет, обработка, принятие решения, прогнозирование и все, что необходимо для того, чтобы функционировал объект управления.
Следует отметить, что в наш век оборудование уменьшается, становится умнее. На многих элементах оборудования уже есть микропроцессоры – маленькие компьютеры, которые обеспечивают предварительную обработку, как это сейчас модно называть – граничные вычисления, которые производятся, чтобы не нагружать общую систему. Поэтому можно сказать, что современная АСУ ТП АЭС – это уже что-то типа индустриального интернета вещей.
Платформа, которая этим управляет – это платформа IoT, про которые многие слышали. Их сейчас немалое количество, наша – очень жестко привязана к реальному времени.
Поверх этого всего строятся механизмы сквозной верификации и валидации, чтобы обеспечить проверку совместимости и надежности. Туда же входит нагрузочное тестирование, регрессионное тестирование, модульное тестирование – все, что вы знаете. Только это делается вместе с железом, которое нами спроектировано и разработано, и ПО, которое работает с этим железом. Решаются вопросы кибербезопасности ( secure by design и т.д.).

На рисунке изображены процессорные модули, которые управляют контроллерами. Это 6-юнитовая платформа с шасси для размещения материнских плат, на которые мы производим поверхностный монтаж необходимого нам оборудования, в том числе процессоров. Сейчас у нас волна импортозамещения, мы стараемся поддерживать отечественные процессоры. Кто-то говорит, что в результате безопасность индустриальных систем повысится. Это действительно так, чуть позже объясню, почему.
Система безопасности
Любая АСУ ТП на АЭС резервируется в виде системы безопасности. Энергоблок АЭС рассчитан на то, что на него может упасть самолет. Система безопасности должна обеспечить аварийное расхолаживание реактора, для того чтобы вследствие остаточного тепловыделения, которое возникает из-за бета-распада, он не расплавился, как это произошло на АЭС Фукусима. Там не было системы безопасности, волной смыло резервные дизель-генераторы, и случилось то, что случилось. На наших АЭС такое невозможно, потому что там стоят наши системы безопасности.
Основа систем безопасности – это жесткая логика.
Фактически мы отлаживаем один или несколько алгоритмов управления, которые могут объединяться в функционально-групповой алгоритм, и всю эту историю распаиваем прямо на плату без микропроцессора, то есть получаем жесткую логику. Если когда-нибудь какой-то элемент оборудования нужно будет заменить, у него изменятся уставки или параметры, и потребуется внести изменения в алгоритм его работы – да, придется вынуть плату, на которой распаян алгоритм, и поставить новую. Но зато это безопасно – дорого, но безопасно.

Ниже пример троированной системы диверсной защиты, на которой выполняется алгоритм решения одной задачи системы безопасности в варианте исполнения два из трех. Бывают три из четырёх – это как RAID.

Технологическое разнообразие
Во-первых, важно использовать различные процессоры. Если мы делаем кроссплатформенную систему и общую систему набираем из модулей, работающих на различных процессорах, то в случае, если внутрь системы на каком-то из этапов жизненного цикла (проектирования, разработки, планово-предупредительного ремонта) попадет вредоносное программное обеспечение, то оно не поразит сразу все диверсное разнообразие техники.

Также есть количественное разнообразие. Вид полей со спутника хорошо отражает модель, когда мы максимально с точки зрения бюджета, пространства, возможности понимания и эксплуатации выращиваем разнообразные культуры, то, есть реализуем избыточность (redundancy), максимально копируя системы.
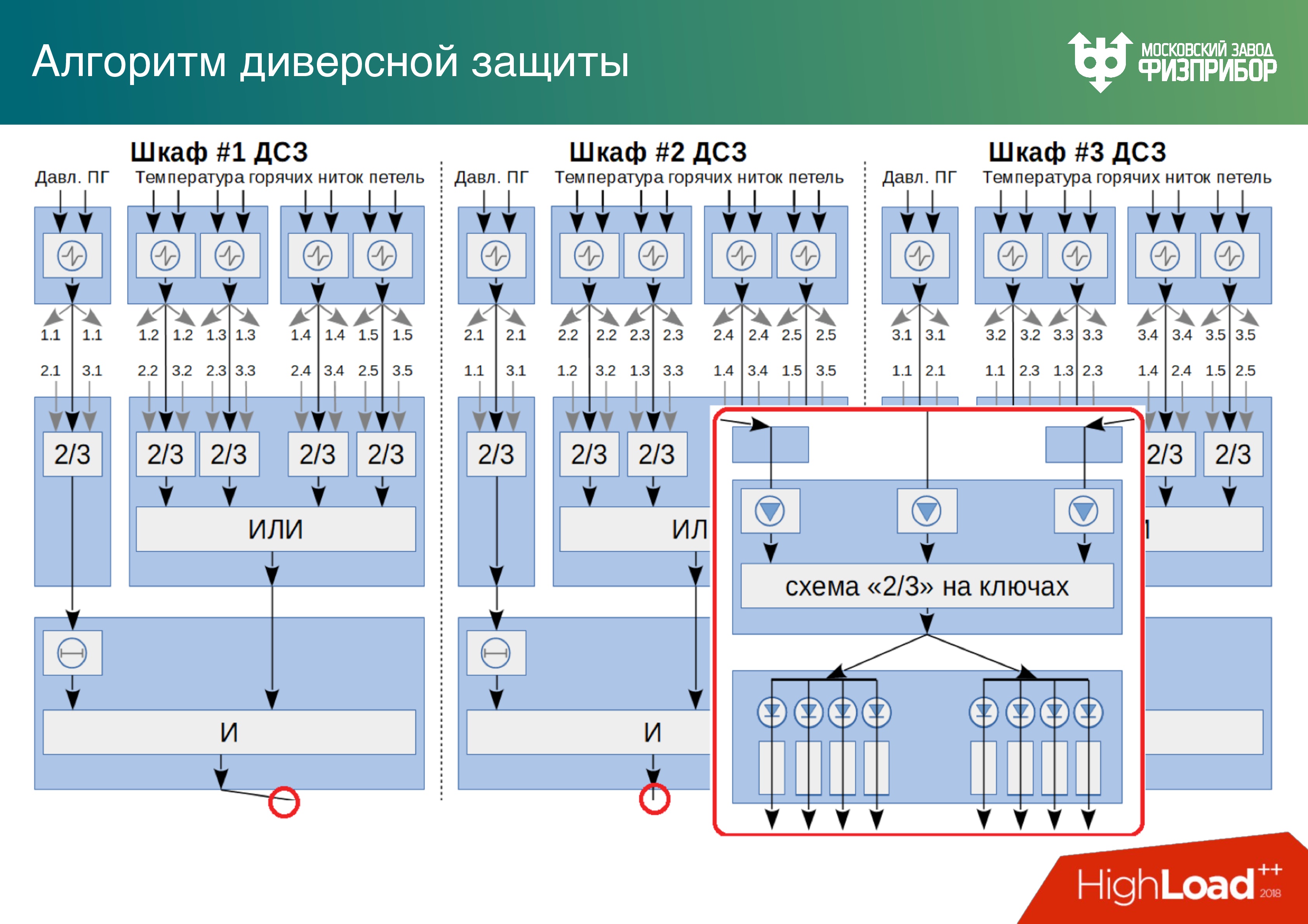
Ниже примерный алгоритм выбора решения на основе троированной системы диверсной защиты. Алгоритм считается правильным на основе двух из трех ответов. Мы считаем, что, если один из шкафов выйдет из строя, мы, во-первых, об этом узнаем, во-вторых, два остальных будут нормально работать. Таких шкафов на АЭС целые поля.

Про железо поговорили, перейдем к тому, что всем интереснее – к софту.
Программное обеспечение. Вершок и Корешок
Так выглядит система мониторинга как раз этих шкафов.

Система верхнего уровня (после низовой автоматики) обеспечивает надежный сбор, обработку, доставку информации оператору и другим интересующимся службам. Она должна прежде всего решать главную задачу – в момент пиковых нагрузок уметь все разруливать, поэтому в режиме нормальной эксплуатации система может быть загружена на 5-10%. Остальные мощности фактически работают вхолостую и предназначены для того, чтобы в случае нештатной ситуации все перегрузки мы смогли бы балансировать, распределять, обрабатывать.
Самый характерный пример – турбина. Она дает больше всего информации, и если начинает работать нестабильно, фактически случается DDoS, потому что вся информационная система забивается диагностической информацией с этой турбины. В случае, если QoS плохо отработает, могут возникнуть серьезные проблемы: оператор просто не увидит часть важной информации.
На самом деле все не так страшно. Оператор может проработать на физическом реактиметре 2 часа, но потерять при этом какое-то оборудование. Для того, чтобы этого не происходило, мы разрабатываем нашу новую программную платформу. Предыдущая версия сейчас обслуживает 15 энергоблоков, которые построены в России и за рубежом.

Программная платформа – это кроссплатформенная микросервисная архитектура, которая состоит из нескольких слоев:
- Слой данных –база данных реального времени. Она очень простая — что-то типа Key-value, но value может быть только double. Больше никаких объектов там не хранится, чтобы напрочь убрать возможность переполнения буфера, стека или чего-то еще.
- Отдельная база данных для хранения метаданных. Используем PostgreSQL и другие технологии, в принципе настраивается любая технология, потому что тут нет жесткого real time.
- Архивный слой. Это оперативный архив (примерно сутки) для обработки текущей информации и, например, отчетов.
- Долгосрочный архив.
- Аварийный архив – чёрный ящик, который будет использован, если произойдет авария и будет поврежден долгосрочный архив. В него записываются ключевые показатели, тревоги, факт квитирования тревог (квитирование означает, что оператор увидел тревогу и и что-то начинает делать).
- Логический слой, в котором находится язык выполнения сценариев. На нем основано вычислительное ядро, и после вычислительного ядра так же, как модуль, находится генератор отчетов. Ничего необычного: можно напечатать график, сделать запрос, посмотреть, как менялись параметры.
- Клиентский слой – узел, который позволяет разрабатывать клиентские сервисы на базе кода, содержит API.
Существует несколько вариантов клиентских узлов:
- Оптимизированный на запись. На нем разрабатываются драйвера устройств, но это не классический драйвер. Это программа, которая собирает информацию с контроллеров низовой автоматики, проводит предварительную обработку, парсит всю информацию и любые протоколы, по которым работает оборудование низовой автоматики, – OPC, HART, UART, Profibus.
- Оптимизированный на чтение – для построения пользовательских интерфейсов, обработчиков и всего, что идет дальше.
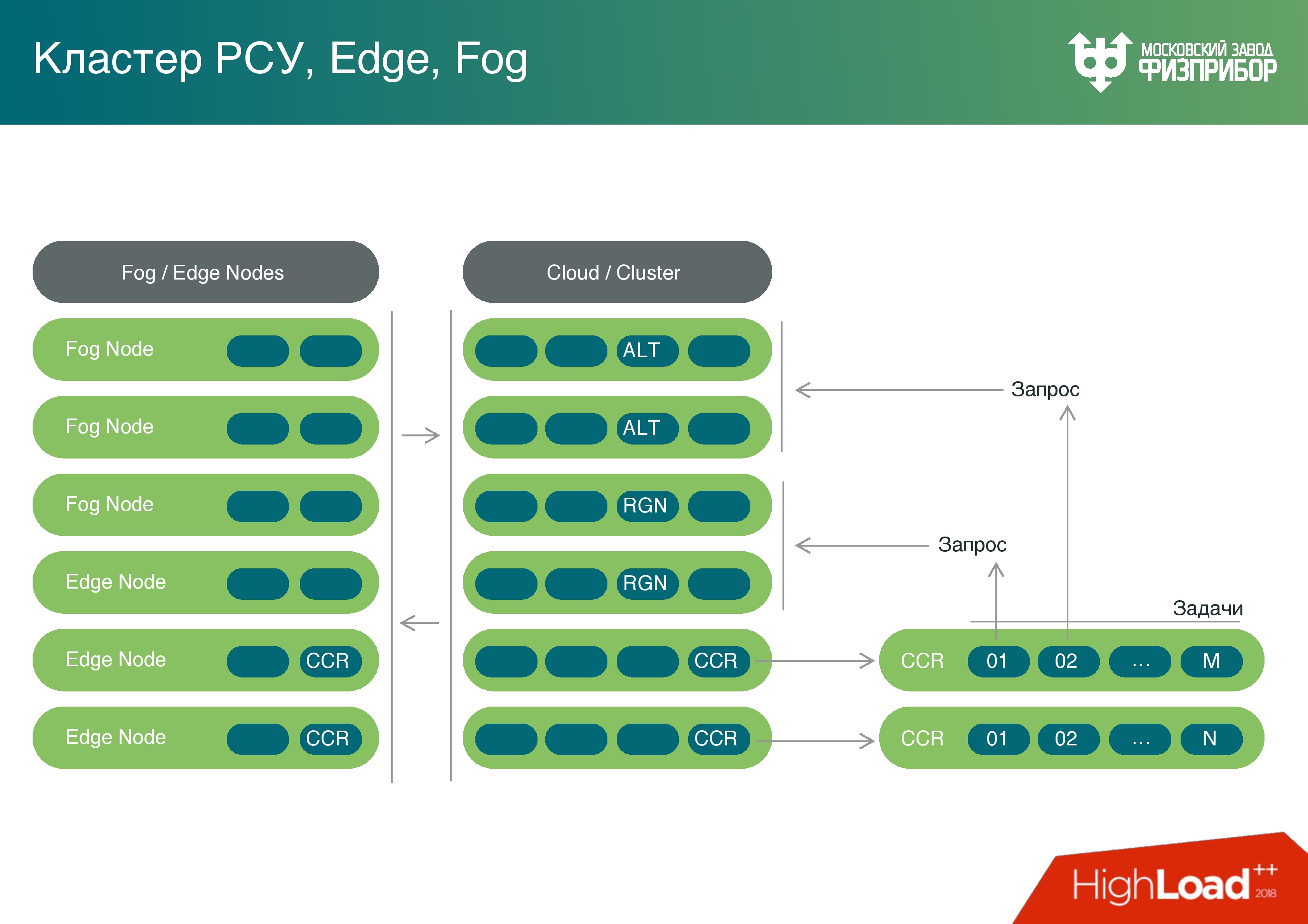
На основании этих узлов мы строим облако. Оно состоит из классических надежных серверов, которые управляются с помощью распространенных операционных систем. Мы используем в основном Linux, бывает QNX.
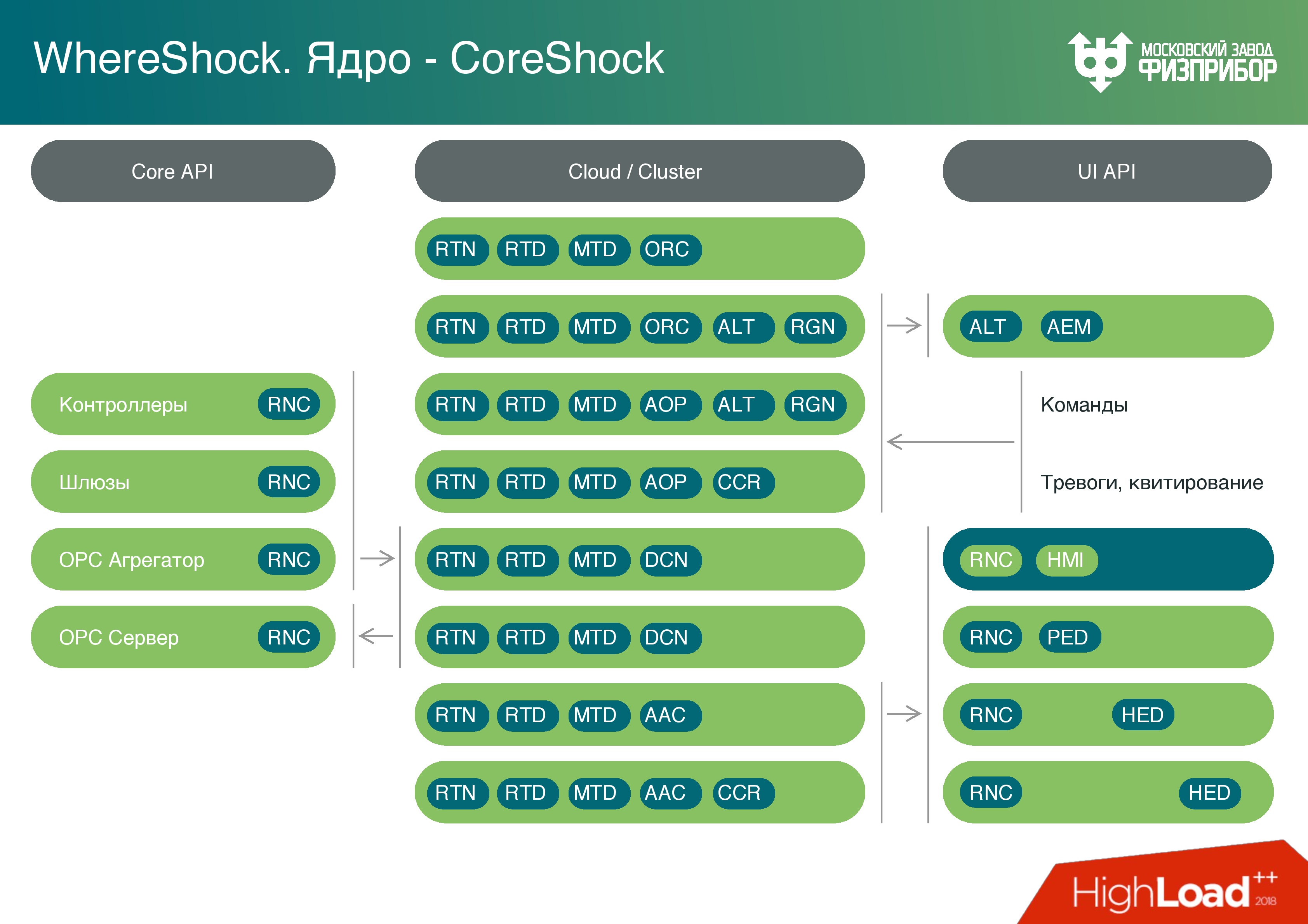
Облако нарезается на виртуальные машины, где-то запускаются контейнеры. В рамках контейнерной виртуализации запускаются различные типы узлов, которые по необходимости выполняют разные задачи. Например, можно раз в день запустить генератор отчетов, когда все необходимые отчетные материалы за день будут готовы, виртуальные машины будут выгружены, и система станет готова для решения других задач.
Свою систему мы назвали Вершок, а ядро системы Корешок – понятно, почему.

Имея достаточно мощные вычислительные ресурсы на шлюзовых контроллерах, мы подумали – а почему бы не использовать их мощности не только для предварительной обработки? Мы же можем превратить это облако и все пограничные узлы в туман, и нагружать эти мощности задачами, например, такими, как выявление погрешностей.

Иногда бывает так, что датчики приходится тарировать. Со временем показания плывут, мы знаем, по какому графику во времени они изменят свои показания, и вместо того, чтобы эти датчики менять, уточняем данные и делаем поправки – это называется тарировка датчиков.
Мы получили полноценную Fog-платформу. Да, она выполняет ограниченное количество задач в тумане, но мы будем потихонечку увеличивать их число и разгружать общее облако.
Кроме того, у нас есть вычислительное ядро. Мы подключаем язык сценариев, умеем работать с Lua, с Python (например, библиотекой PyPy), с JavaScript и TypeScript для решения задач с пользовательскими интерфейсами. Эти задачи мы можем одинаково хорошо выполнять как внутри облака, так и на граничных узлах. Каждый микросервис может запускаться на процессоре абсолютно любого объема памяти и любой мощности. Просто он будет обрабатывать тот объём информации, который возможно на текущих мощностях. Но система одинаково работает абсолютно на любом узле. Она же подходит для размещения на простых IoT устройствах.
Сейчас в эту платформу попадает информация из нескольких подсистем: уровня физической защиты, системы контроля управлением доступом, информация с видеокамер, данные пожарной безопасности, АСУ ТП, IT-инфраструктуры, события информационной безопасности.
На основе этих данных строится Behavior Analytics – поведенческая аналитика. Например, оператор не может быть залогинен, если камера не зафиксировала, что он прошел в операторскую. Или другой кейс: видим, что какой-то канал связи не работает, при этом фиксируем, что в этот момент времени изменилась температура стойки, была открыта дверца. Кто-то зашел, открыл дверцу, вытащил или задел кабель. Такого, конечно, быть не должно, но мониторить это все равно нужно. Необходимо описывать максимально большое количество кейсов, чтобы когда что-то вдруг случится, мы точно знали, что.

Выше примеры оборудования, на котором все это работает, и его параметры:
- Слева – обычный сервер Supermicro. Выбор пал на Supermicro, потому что с ним сразу доступны все возможности железа, возможно применение отечественного оборудования.
- Справа – контроллер, который выпускается на нашем заводе. Мы полностью доверяем ему и понимаем, что там происходит. На слайде он полностью загружен вычислительными модулями.
Наш контроллер работает с пассивным охлаждением, и с нашей точки зрения это намного надежнее, поэтому стараемся перевести максимальное количество задач на системы с пассивным охлаждением. Любой вентилятор в какой-то момент выйдет из строя, а срок службы АЭС – это 60 лет с возможностью продления до 80. Понятно, что за это время будут сделаны планово-предупредительные ремонты, оборудование будет заменено. Но если сейчас взять объект, который запускался в 90-х или в 80-х, то даже невозможно найти компьютер, чтобы запустить программное обеспечение, которое там работает. Поэтому все приходится переписывать и менять, в том числе алгоритмику.
Наши сервисы работают в режиме Multi-Master, нет единой точки отказа, все это кроссплатформенное. Узлы самоопределяются, можно делать Hot Swap, за счет чего можно добавлять и менять оборудование, и нет зависимости от выхода из строя одного или нескольких элементов.

Есть такое понятие, как деградация системы. До определенной степени оператор не должен замечать, что с системой что-то происходит не так: сгорел процессорный модуль, или пропало питание на сервере и он отключился; канал связи перегрузился, потому что не справляется система. Эти и подобные проблемы решается за счет резервирования всех компонентов и сети. Сейчас у нас работают топология «двойная звезда» и mesh. Если какой-то узел выходит из строя, то топология системы позволяет продолжить нормальную работу.

Это сравнения параметров Supermicro (сверху) и нашего контроллера (внизу), которые мы получаем по апдейтам на базе данных реального времени. Цифры 4 и 8 – это количество реплик, то есть база данных поддерживает актуальное состояние всех узлов в реальном масштабе времени – это multicast и real-time. В тестовой конфигурации примерно 10 млн тэгов, то есть источников изменения сигналов.
Supermicro показывает в среднем 7 M/c или 5 М/с, при увеличении числа реплик. Мы боремся, чтобы не терять мощность системы, с ростом числа узлов. К сожалению, когда возникает необходимость обработки уставок и других параметров, мы теряем скорость с увеличением количества узлов, но чем больше узлов, тем потери меньше.
На нашем контроллере (на Atom) параметры на целый порядок меньше.
Пользователю для построения тренда выводится набор тэгов. Ниже touch-ориентированный интерфейс для оператора, в котором он может выбрать параметры. На каждом клиентском узле есть копия базы данных. Разработчик клиентского приложения работает с локальной памятью и не думает о синхронизации данных по сети, просто делает Get, Set через API.
Разработка клиентского интерфейса АСУ ТП не сложнее, чем разработка сайта. Раньше мы боролись за real-time на клиенте, использовали C++, Qt. Сейчас мы от этого отказались и сделали все на Angular. Современные процессоры позволяют поддерживать надежность работы таких приложений. Веб уже достаточно надежен, хотя память, конечно, плывет.
Задача обеспечить работу приложения в течение года без перезапуска уже не актуальна. Все это упаковывается в Electron и фактически дает платформенную независимость, то есть возможность запускать интерфейс на планшетах и панелях.
Тревога
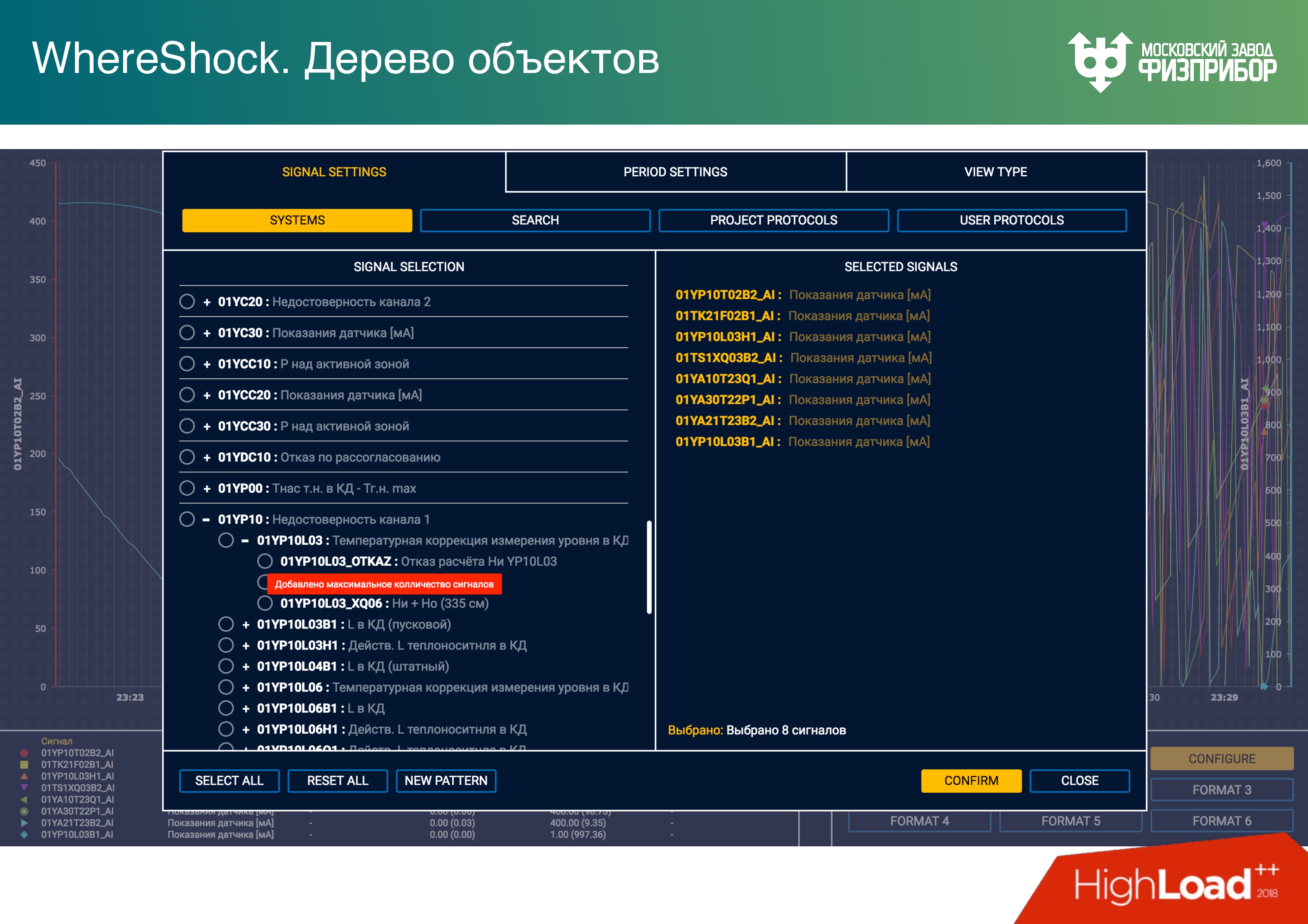
Тревога – это единственный динамический объект, который появляется в системе. После того, как система запускается, все дерево объектов фиксируется, удалить оттуда ничего нельзя. То есть модель CRUD не работает, можно только сделать пометку «mark as deleted». Если необходимо удалить тэг, он просто помечается и прячется от всех, но не удаляется, потому что операция delete сложная и может повредить состояние системы, ее целостность.
Тревога – это некий объект, который появляется, когда параметр сигнала от того или иного оборудования выходит за пределы уставок. Уставки – это нижняя и верхняя предупредительные границы значений: аварийные, критические, закритические и т.д. При попадании параметра в то или иное значение шкалы появляется соответствующая тревога.
Первый вопрос, который возникает, когда случается тревога, кому показывать сообщение о ней. Показывать тревогу двум операторам? Но наша система универсальная, операторов может быть больше. На АЭС “чуть-чуть” отличаются базы данных у турбиниста и у реакторщика, потому что оборудование разное. Понятно, конечно, если уровень сигнала вышел за рамки в реакторном отделении, то это увидит ведущий инженер управления реактором, в турбинном – турбиной.
Но представим, что операторов много. Тогда тревогу всем показывать нельзя. Или если ее кто-то берет под квитирование, ее нужно немедленно блокировать для квитирования на всех остальных узлах. Это real-time операция, и когда два оператора возьмутся квитировать одну и ту же тревогу, они тут же начнут управлять оборудованием и алгоритмами. Все это связано с сетевым многопоточным программированием и может привести к серьезным системным конфликтам. Поэтому любой динамический объект нужно показывать, давать возможность им управлять и “гасить” тревогу только одному оператору.
Более того, все тревоги друг от друга зависят. Какое-нибудь оборудование начинает “глючить” – тысяча тревог выскакивает. На самом деле, чтобы их все погасить, нужно найти только одну из них, ее квитировать, и тогда пропадает “дерево” остальных тревог. Это отдельная наука и мы как раз работаем над тем, как такие тревоги представлять. Единого мнения пока нет: либо дерево, либо прятать как вложенное. Сейчас модуль тревоги выглядит так, с вложенными данными.
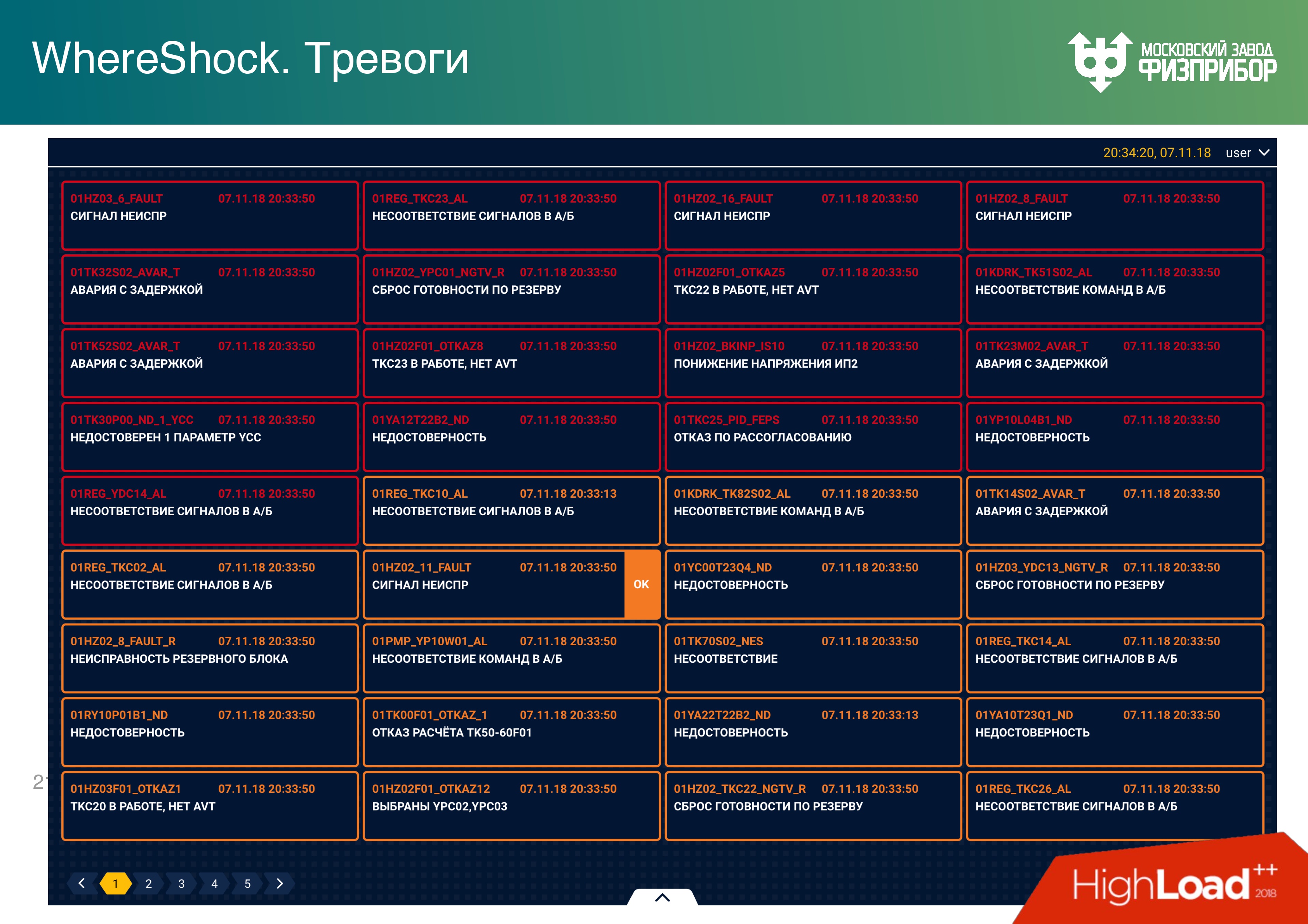
Привожу примеры видеокадров, которые видит оператор, для общего представления.

- Слева вверху – реакторное отделение,
- слева внизу – видеокадр для ветропарка,
- справа внизу — график,
- cправа сверху – парогенераторы реакторного отделения.
Желтые ссылки – переходы на другие видеокадры.
У нас на заводе сделан стенд. Примерно так выглядят дашборды на панели, у оператора примерно то же самое.

Конфигурация системы
Мы предоставляем достаточно универсальный режим работы с базой данных.

Редактор, который позволяет создавать объекты, удалять их, задавать параметры, которые передаются в базу данных реального времени и базу метаданных.
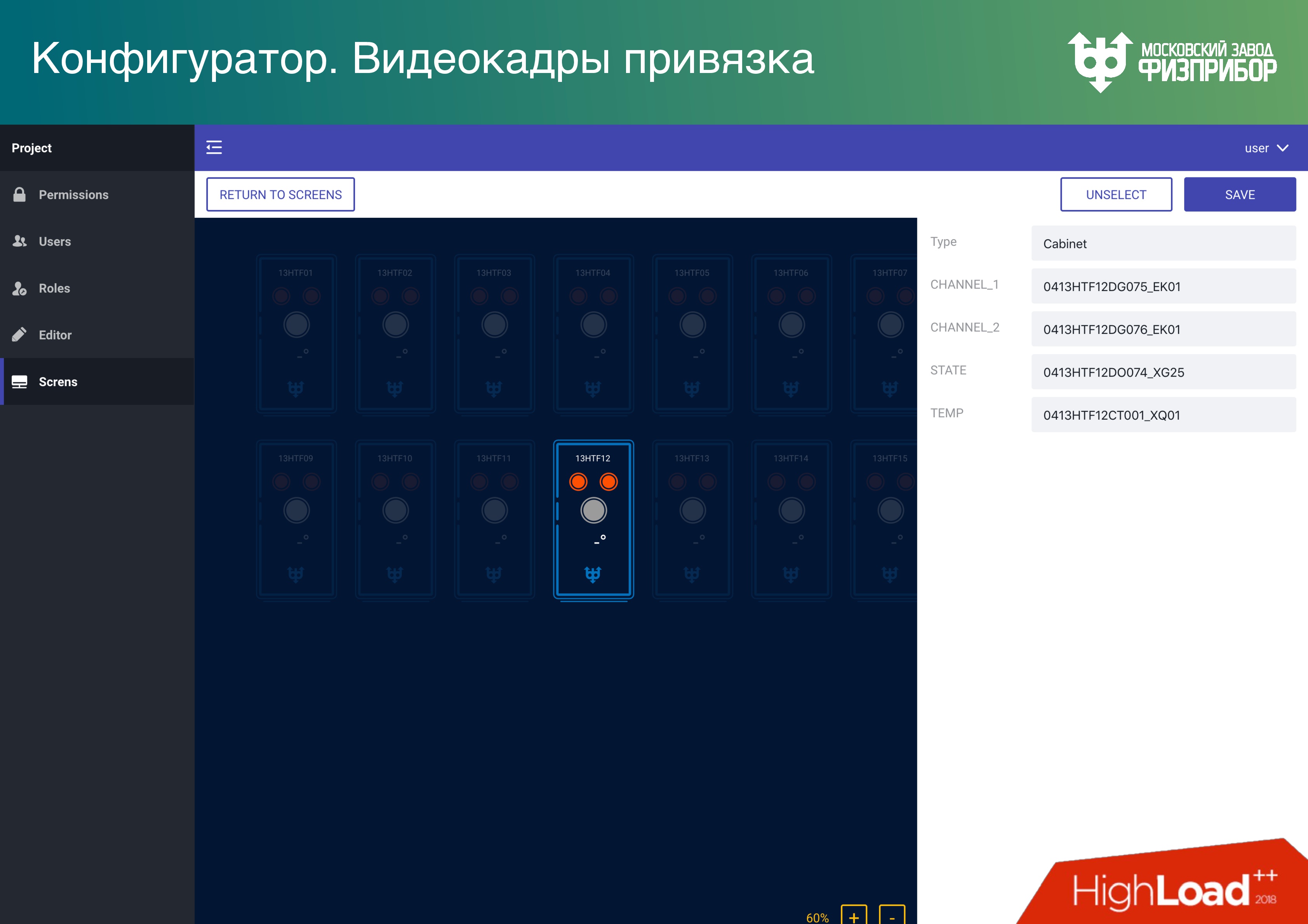
Видеокадры – это элементы пользовательских интерфейсов, с которыми больше всего проблем. Каждый производитель SCADA/HMI пытается сделать свой редактор, а потом, когда увольняются разработчики, концов не найдешь – появляются баги, все падает, этим невозможно управлять. Нам это надоело, поэтому мы решили: «Делайте, на чем хотите! Хоть на Illustrator, хоть в Sketch – в любой программе, которая выдаст канонический SVG». Мы даём возможность открыть SVG и прицепить его к тегам БДРВ. Если примитивы в редакторе правильно называть, то больше ничего не нужно и все будет нормально работать сразу.
Создание пользовательского интерфейса в АСУ ТП или платформы выглядит не сложнее, чем создание сайта. Мы даем все необходимые API, чтобы это было так. Ни одна другая система, которая сейчас используется на подобных объектах, так не работает, везде есть свои сложные редакторы и убогие интерфейсы. Представляю, каково операторам, которые смотрят на них каждый день. Конечно, многие думают, что не так важно, как это выглядит, главное – безопасность. Но мы хотим, чтобы и выглядело это красиво, потому что, на наш взгляд, это важно.
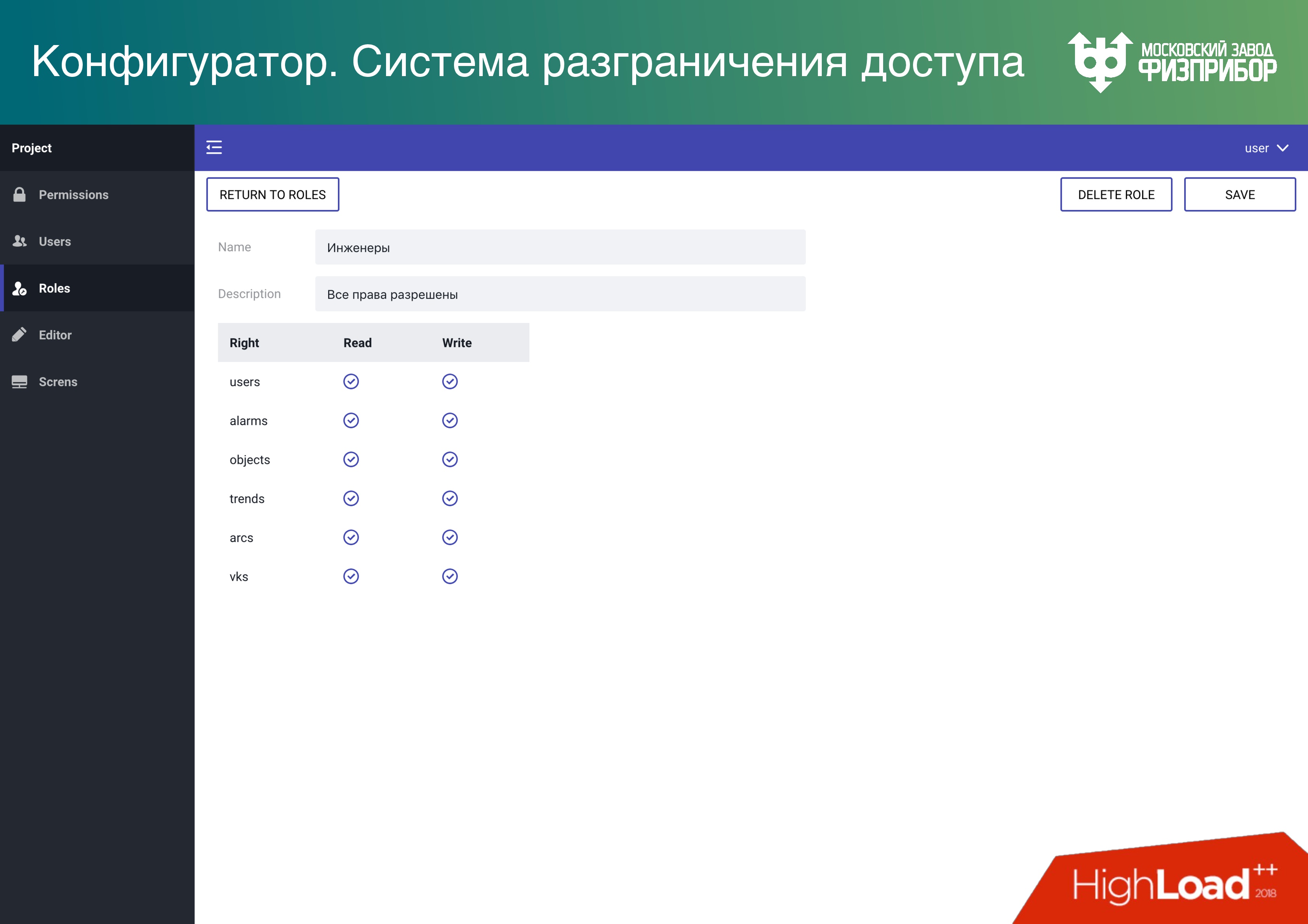
Как везде, у нас есть система разграничения доступа. Мы поддерживаем несколько режимов, чтобы было надежно и дешево. Кроме контейнерной и обычной виртуализации мы даем возможность сделать Data Lake. Тогда все помещаются в одну большую оперативную память, а режим multitenancy обеспечивает возможность разделения доступа к элементам дерева (объектам, данным). Поэтому можно держать несколько проектов фактически на достаточно недорогом железе.
Также чем больше железа, тем дороже синхронизация и тем больше вероятность ошибки. Поэтому, если мы сможем на большем количестве узлов просто скопировать эту базу, даже в таком режиме, то совокупная надежность всей системы растет.
Более того, следует отметить один момент: в режиме реального времени и большого количества объектов в памяти мы не можем работать с кэшем процессора. Он превратился в тыкву, потому что когда нужно обеспечивать навигацию и поиск по 10 или 100 млн объектов, то кэша нет – всё руками.
Прогнозирование
Мы делаем прогнозную аналитику с помощью нейросетей, машинного обучения. Расскажу, как это работает и сколько стоит в деньгах.
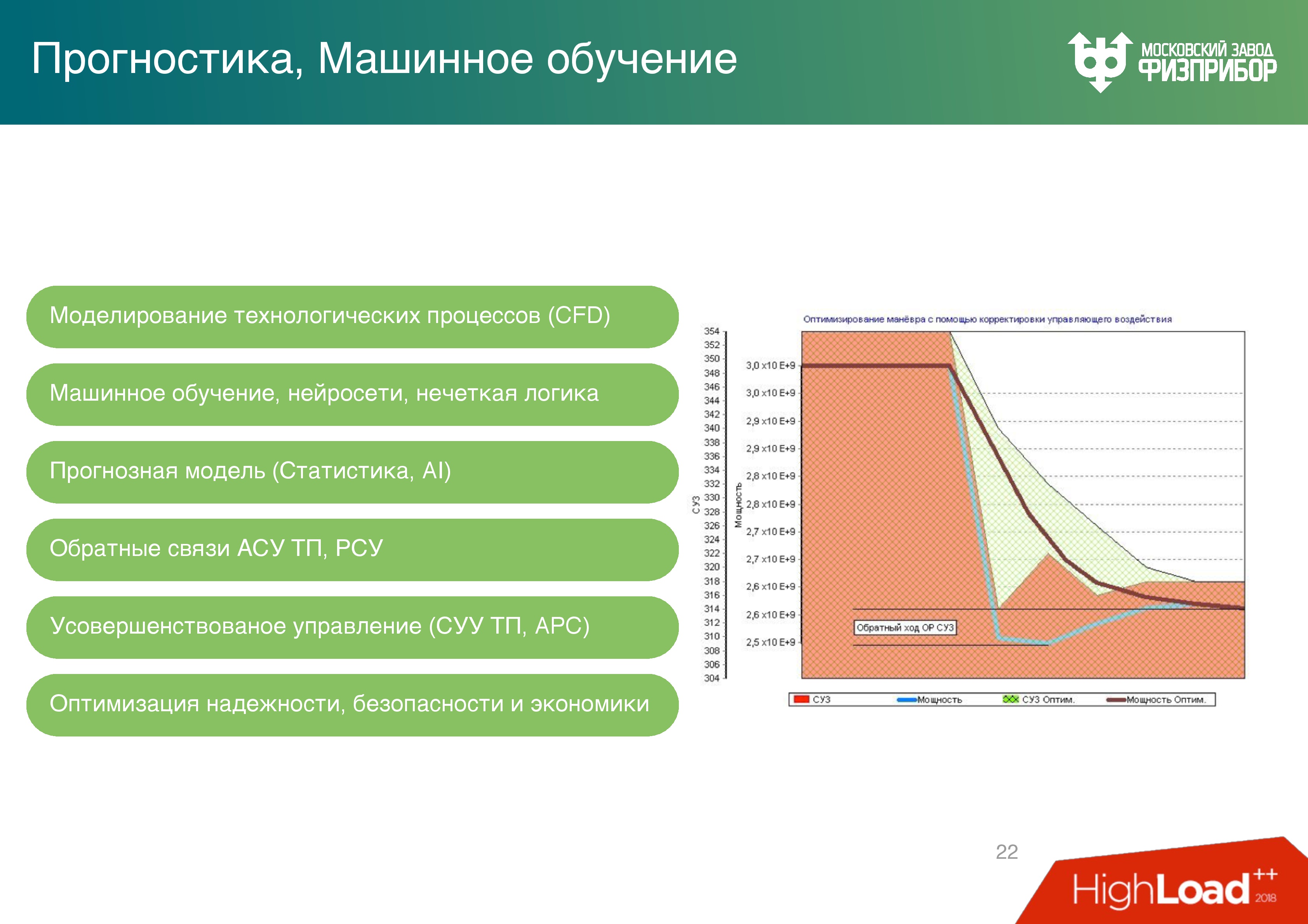
Справа график изменения мощности реактора при движении органов регулирования системы управления защитой — стержней регулирования. Вообще реактор регулируется концентрацией борной кислоты в воде, но когда производятся маневры мощности, то используются стержни. Каждое движение стержней – это пережоги топлива, а топливо достаточно дорогое: загрузка современного реактора ВВЭР-1200 примерно 10 тонн диоксида урана.
График, который дает обратный ход показывает, как оператор управляет всем вручную, то есть изменяет параметры мощности, видит, что мощность чуть-чуть ниже, чем нужно, чуть прибавляет и т.д… Ориентируясь на обратную связь оператор в итоге доводит мощность до нужного уровня.
Мы же обучили нейронную сеть на предыдущих показаниях. Но просто нейросеть никогда точно не спрогнозирует физический процесс. В реакторе 5 физических процессов: нейтронная кинетика, гидродинамика, химия и радиохимия вследствие различных превращений, и физика прочности. Любой расчет выглядит как моделирование каждого этого технологического процесса.
В основном есть два метода:
- Монте-Карло для нейтронов и радиохимии (на CPU);
- Computational Fluid Dynamics (CFD) для всего остального (на GPU).
Эти методы чрезвычайно медленны, их невозможно использовать в система реального времени. Мы увеличили пространственно-временной шаг, а корректировку сделали на нейросетях, и получили достаточно серьезную оптимизацию (верхний график). Теперь нет необходимости в обратном ходе стержней.
По расчетным характеристикам оптимизация на отсутствие обратного хода позволит сэкономить до 60 млн долларов в год, за трехлетнюю топливную кампанию (это значит, каждый год треть топлива меняется). Это хорошая цифра для суммарного KPI сотрудников, которые работают на блоке.
Пульт управления
Обычный блочный пульт управления выглядит так.

Слева – Нововоронежская АЭС, справа – Калининская АЭС и модель.
Но мы пошли дальше. Блочный пульт управления – это очень дорогая история. Есть много разработчиков, которые производят и оборудование, и ПО, которое туда сводится – это десятки и сотни компаний. Мы сделали VR-операторскую, загрузили в нее нашу систему.

Надеваешь очки, и получаешь такую же картину, как и на блоке, только без щита. Раньше был БЩУ (блочный щит управления) — оператор шел, крутил какие-то штуки. Потом ему поставили компьютер, он в него смотрел, но все равно вставал к щиту и крутил. Потом мы сделали возможность управления с монитора — БПУ (блочный пульт управления), а теперь – ВПУ (виртуальный пульт управления), за которым будущее.
Хотя будущее, конечно, за блоком без операторов — за искусственным интеллектом. Оператор превратится в супервизора. Потом будет можно управлять всей станцией целиком из общего пульта управления. А потом операторская сможет находиться за пределами АЭС.
Уже сейчас реализуется такой проект ITER. Сама станция находится в городе Кадараш во Франции, а пульт управления – в Японии в городе Рокасё. Это сделано, чтобы отладить технологии, используется квантовая связь и квантовая криптография. Можно сказать, будущее уже здесь!
Больший уклон в разработку программного и аппаратного обеспечения для интернета вещей мы сделаем на InoThings Conf 4 апреля. В прошлом году были доклады и про IIoT, и про электроэнергию. В этом году планируем сделать программу еще более насыщенной. Пишите заявки, если готовы нам в этом помочь.
Комментарии (31)

5oclock
08.02.2019 13:58Вершок/корешок…
У вас военные — работают? :)electrovenic
08.02.2019 14:12С чего Вы это взяли? ;)
5oclock
08.02.2019 15:10+1У них обычно названия убойные.
Всякие там…
Огнемётная система — «Буратино» и «Солнцепёк».
Граната для подствольника — «Подкидыш».
Система постановки помех — «Мошкара».
Или система ПВО «Куб» и её упрощённый, экспортный вариант… правильно — «Квадрат»
=D
ChePeter
08.02.2019 14:18А как идентифицируете датчики?
Ведь во время профилактики/ремонта/сборки можно два однотипных датчика поменять местами и тарирование будет ошибочным.

zacat
08.02.2019 14:39Спасибо, интересная обзорная статья.
Надеюсь будет продолжение с бОльшим количеством технических подробностей :)
P.s. Какую Linux используете?electrovenic
08.02.2019 14:52Любую =) CentOS, AltLinux. QNX и FreeRTOS еще

da-nie
09.02.2019 10:00Любую
В смысле, ваши приложения управления АЭС идут и под QNX и под AltLinux и под FreeRTOS просто после перекомпиляции? И почему QNX и прочие вдруг стали Linux?

claygod
08.02.2019 15:00с Lua, с Python (например, библиотекой PyPy), с JavaScript и TypeScript
А что именно делается на этих языках? Дело в том, что перечисленное не ассоциируется у меня со словом надёжность, поэтому и вопрос, (не для холивара, а сугубо для лучшего понимания).
sav6622
08.02.2019 15:51С удивлением смотрю на платы, требования по ЭМС к Вам не предьявляют? разьемы USB успешно проходят?
electrovenic
08.02.2019 21:21+1У нас испытательная лаборатория своя есть, включая оборудование ЭМС. Все проверено!
1Fedor
09.02.2019 01:26+1В целом хорошо, когда о работе физприбора.
Как только про АЭС, проблемы, например, что написано я не могу понять:
Атомная электростанция это:
«В среднем 3-4 энергоблока со средней мощностью 1000 МВт на одну АЭС, потому что физические системы должны резервироваться, так же, как и сервисы в интернете
АЭС это несколько блоков мощностью 440 электрических мегаватт (например Кольская) до 1000 мвт на блок (ВВЭР и РБМК) Новые АЭС строятся мощностью 1200 мВт. Каждый блок имеет полноценный набор всех защит и каналов безопасности. Оптимальное количество блоков АЭС- 4 с точки зрения загрузки общестанционных систем и стабильности работы станции.
И количество блоков никак не строится для резервирования физических систем как интернете (Это, вообще. о чем?)
Зачем АЭС низводить до птицефабрики из двух зданий, которой управляют два человека:
»Атомная электростанция это:
Два здания, в которых сконцентрировано большинство подсистем: реакторное и турбинное отделение. Два человека должны в реальном времени принимать решение в случае, если происходят нестандартные, или стандартные, события. Такая высокая ответственность накладывается всего на двух человек, потому что если их будет больше, то им нужно будет между собой договариваться"
Да вы что, АЭС — это десятки зданий, эстакады, подземные коммуникации, системы отвода тепла и охлаждения конденсаторов турбин, береговые насосные станции и/или градирни, сотни тысяч кабеля и трубопроводов и так далее. А у вас два здания с двумя человеками, которые должны договариваться. Резервируется не только физические ресурсы-насосы, системы… Но и человеческие- есть лицензированные начальники смен реактрного, турбинного отделений, начальник смены блока, АЭС (на разных станциях и разных странах по разному называются)
Некорректные данные, например про Фукусиму, срок службы АЭС 60 лет плюс продление срока эксплуатации до 80…
Про 10 тонн урана -откуда это? Я понимаю, что вы не работали на АЭС, но и придумывать не надо.
«Начальная загрузка реактора Белорусской АЭС будет содержать 163 модернизированные тепловыделяющие сборки (ТВС) со средним обогащением 2,68% по урану-235. Вес топлива в одной ТВС — 571 килограмм. Вес топливной загрузки в реактор составляет около 93 тонн», — рассказал Михадюк в ходе онлайн-конференции в среду в Минске".
Про СУЗы, про пережог топлива, про экономию 60 млн $ ???
Про виртуальное управление, наверное, хорошо для виртуальных АЭС.
Про искусственный интеллект немного опоздали, давно на АЭС есть, хоть и не так пафосно называется.
Про Итер тоже интересно узнать, ссылку дайте.
Вот интересно бы узнать, у нас жесткая логика, а в других странах, например Украина?
dimonoid
09.02.2019 07:31+1Пожалуйста расскажите подробнее про пережог топлива и обратный ход стержней. Разве более быстрое изменение мощности реактора не экономит топливо, когда допустим мощность резко упала?
TrueMaker
09.02.2019 08:58+1доля атомной энергетики в мире будет расти
Скорее сокращаться, возобновляемые источники энергии и системы хранения энергии медленно, но уверенно, вытесняют классические системы генерации энергии. В пределах отдельно взятой страны, это утверждение могло быть справедливым, но вот в масштабах всего мира, сомневаюсь.
immaculate
09.02.2019 15:04+1Скорее сокращаться, возобновляемые источники энергии и системы хранения энергии медленно, но уверенно, вытесняют классические системы генерации энергии.
Вообще-то нет. Это происходит в отдельных странах за счет колоссальных дотаций и компенсации неравномерной выработки за счет соседей, использующих АЭС и ТЭС. И то недолго продлится, так как сети требуют модернизации, чтобы выдерживать неравномерную генерацию, а когда подсчитали затраты на модернизацию, схватились за голову (https://www.transnetbw.de/de/presse/presseinformationen/presseinformation/uebertragungsnetzbetreiber-veroeffentlichen-ersten-entwurf-des-netzentwicklungsplans-2030-version-2019).
Так что, кто умеет считать, понимают, что будущее только за АЭС.
yetanotherman
10.02.2019 13:56Система безопасности должна обеспечить аварийное расхолаживание реактора, для того чтобы вследствие остаточного тепловыделения, которое возникает из-за бета-распада, он не расплавился, как это произошло на АЭС Фукусима. Там не было системы безопасности, волной смыло резервные дизель-генераторы, и случилось то, что случилось. На наших АЭС такое невозможно, потому что там стоят наши системы безопасности.
А можно подробнее, как это работает без электричества?da-nie
10.02.2019 14:40Полагаю, что на выбеге ротора.
yetanotherman
10.02.2019 14:50А что делать с остаточным тепловыделением?
tlv
Спасибо, довольно интересно. Хотя в будущем хотелось бы увидеть более подробный разбор какой-либо из подсистем.
Скажите, а есть ли ссылка на источник информации? Потому что она вызывает скепсис, право слово.
И еще, вот этот слайд нужно перерисовать:
Я понимаю, что логотип intel вы затёрли потому, что «Сейчас у нас волна импортозамещения, мы стараемся поддерживать отечественные процессоры.» — но во втором контроллере стоит Vertex 3 — десктопный SSD, старый десктопный SSD на sandforce — это очень плохо для промышленных компов. Надеюсь, что это только ошибка дизайнера, и на самом деле вы их не использовали.
electrovenic
Это реальный комп, там действительно Интел, но это тестовая конфигурация, так что можно.
tlv
Реально Intel — не страшно. Реально OCZ Vertex3 — вот это страшно.
electrovenic
Ну это из лабы же, в продакшен немного по другому =)