

Саймон Уордли в гостях у «Serverless Superheroes»
Добро пожаловать в «Serverless Superheroes»!
Здесь я общаюсь с создателями инструментов, новаторами и разработчиками, которые ведут нас в светлое бессерверное будущее.
Сегодня я беседую с Саймоном Уордли, консультантом Leading Edge Forum и специалистом по ситуационному восприятию, принципам и геймплею. Для удобства я отредактировал интервью.
Это обычная степень повторяемости. Поэтому я и говорю, что бессерверная архитектура (FaaS) ускорит разработку на несколько порядков. Любая ваша система уже на 99,9% кем-то написана. Фишка в том, чтобы найти нужный кусок. Контейнеры? Не смешите меня. Очередное неуклюжее приспособление. — Саймон Уордли
Форрест Брэзил (Forrest Brazeal): Ты не первый год в ИТ и сейчас горячо отстаиваешь бессерверные разработки. Давно этим интересуешься?
Саймон Уордли: В 2005 мы в Fotango планировали среду и поняли, что вычисления превращаются в коммунальные услуги, а значит, среды выполнения кода будут развиваться в ту же сторону.
В итоге мы создали Zimki, и, по сути, это была первая в мире платформа как услуга: сервер на Javascript, открытый через API, — настоящая среда выполнения кода с функциональным биллингом.
Мы сразу по-другому взглянули на разработку, обслуживание, вообще на все. Внезапно мы увидели новые уровни детализации в плане затрат. Такого еще ни у кого не было. Мы придумали всякие интересные концепции, вроде разработки с учетом ценности.
Увы, головная компания решила нас прикрыть, когда мы только набирали обороты. Но я годами думал об этом. В итоге возникла Lambda. По-моему, крутая штука.
Круче, чем, скажем… контейнеры?
Вы не подумайте, вообще-то я обожаю контейнеры. Этакие невидимые подсистемы. Но это не настоящий бой. Настоящий происходит в средах выполнения кода, особенно если говорить о функциональном биллинге.
Многие, кажется, до сих пор не признают, что бессерверная архитектура переворачивает мир, и продолжают спорить о значении этого слова. Тебя удивляет, что это затянулось?
Напоминает о EC2 в 2006. В Sun уже давно баловались с коммунальными вычислениями, но EC2 мало кто принял всерьез: «Фигня какая-то. Кому это надо?». И упирались они довольно долго.
В 2009 или 2010 все эти консультанты по менеджменту говорили что-то типа: «Будущее за частными системами, AWS не потянет». С тем же успехом можно сказать: «Ну нафиг эти ваши автомобили, пошли лучше сеном для лошадок запасемся». Все мы знаем, где теперь Amazon.
Их кто-нибудь догонит?
Это из той же оперы, что и разговоры, которые в 2008–09 крупные производители оборудования вели о EC2. Вычисления превращались в коммунальные услуги, и все остальное тянулось за ними. Сейчас мы зовем это DevOps: бурное развитие систем более высокого порядка, стремительные изменения, прерывистое равновесие.
А большие компании катились по инерции и утешали себя тем, что все это не станет популярным и не затронет их. Понятное дело, они просчитались.
В те времена у крупных производителей оборудования была вся тяжелая артиллерия. У Безоса был Amazon и рогатка. И он победил. Это была ошибка не инженеров, а руководства. Теперь они хотят вернуться в игру, но все силы на стороне Amazon.
С бессерверной архитектурой происходит то же самое. Другие компании, конечно, могли бы пободаться с Amazon, но не станут, потому что не верят в это. А когда поверят, поезд уйдет.
Если бессерверная архитектура так хороша, почему все хватаются за контейнеры?
Чтобы использовать Lambda, нужно много в чем разобраться. Это совершенно другая среда, большой скачок вперед. С контейнерами проще. Плюс они переносимые, и всех это страшно радует, особенно поставщиков.
Они же только об этом и говорят и стараются не замечать сдвиг в сторону сред выполнения кода. Контейнеры не заставляют менять архитектуру и не показывают, что почти весь ваш код уже кто-то написал.
Lambda и правда такой мощный инструмент, что стоит затраченных усилий?
Недавно я провел в Twitter опрос: сколько раз люди переписывали базовые функции регистрации пользователей. Оказалось — миллион.
… как пример. Если вы как минимум 10 лет в разработке, сколько раз вы переписывали функцию регистрации пользователя? — Саймон Уордли
Поразительно, какой высокий уровень повторяемости в компаниях. Люди думают, что правительства зря тратят ресурсы. Худший случай повторяемости, что я видел в правительстве, — 118 систем, которые делали почти одно и то же.
В частном секторе я видел банки с тысячей одинаковых систем управления рисками. А сколько их по всему миру? Миллионы и десятки миллионов одних и тех же систем.
Я дико извиняюсь, но мы целыми днями плодим макулатуру. А если радикально изменить архитектуру, можно потратить это время на реально полезные функции. Но, конечно, проще сказать: «Ух ты, контейнер! Входит и выходит — замечательно выходит! И среда почти как любимые тапки».
Вот кстати про «входит и выходит». Многие боятся, что бессерверная архитектура — это «худший случай привязки к поставщику в истории человечества». Это правда? Мы будем полностью зависеть от поставщика бессерверных вычислений?
Конечно, было бы круто, если бы у нас были разные конкурирующие поставщики. Но это не так важно, как польза и функциональность. Компании же все равно конкурируют друг с другом. А шанс, что поставщики договорятся, почти равен нулю. Все говорят: «Мы будем отличаться тем-то и тем-то».
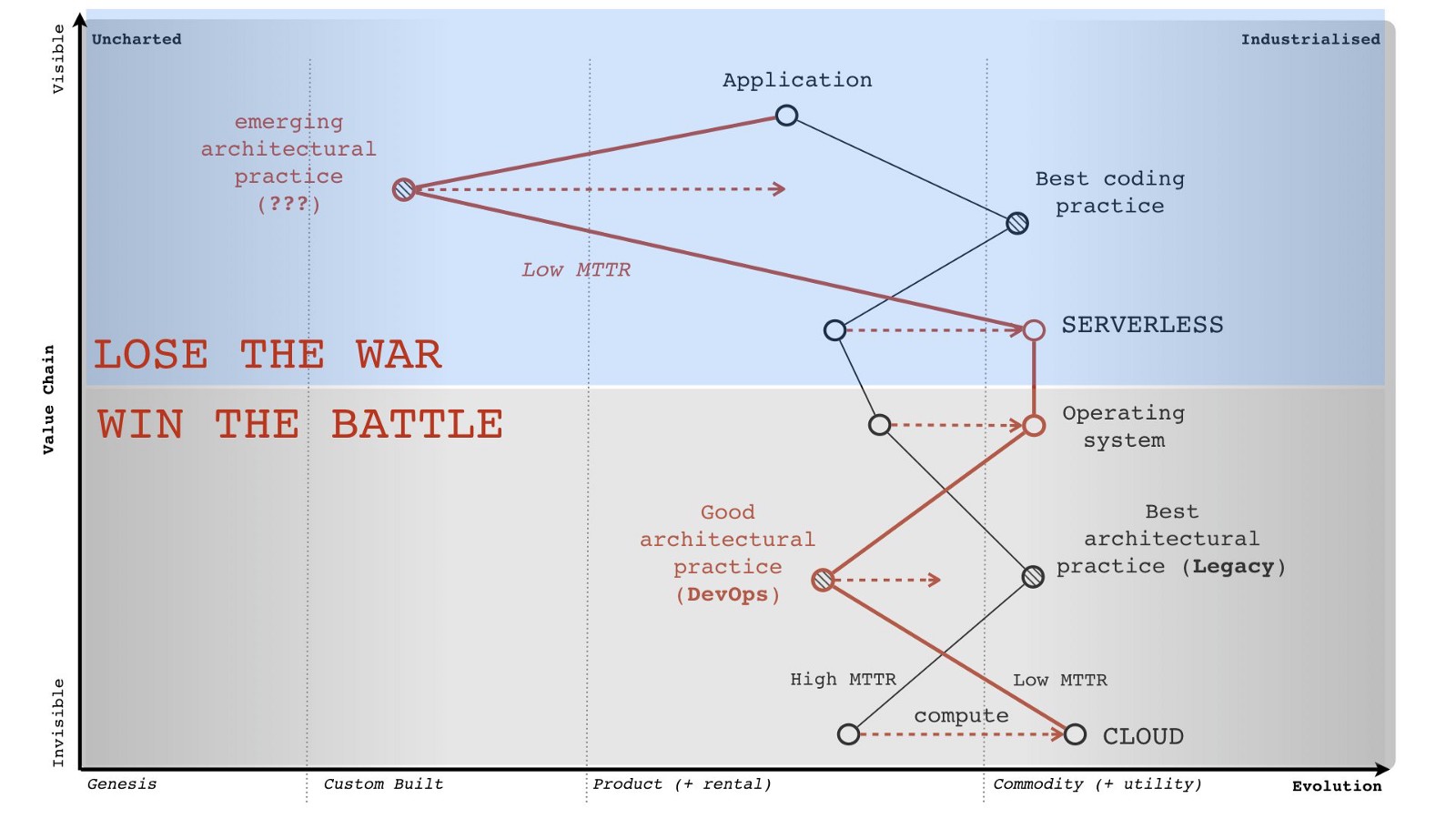
Единственное исключение — это, конечно, всеобщая любовь к контейнерам. Все носятся с контейнерами, но поле битвы сместилось. Вы выиграли бой, но проиграли войну.
Мы сегодня много говорим о битвах. Кто победит и кто проиграет, если бессерверные вычисления будут развиваться по твоему сценарию?
Сегодня побеждают Amazon и Alibaba, которые просекли фишку. Есть еще очень умные компании, типа Netflix, которые используют эти технологии и быстро адаптируются.
И, конечно, из ниоткуда будут появляться компании из одного–двух человек на миллиард долларов. У них будет одна функция. Никто не будет знать этих ребят, но все будут использовать эту функцию как услугу.
Что до проигравших… не хочу вас расстраивать, но среди них будут поклонники DevOps.
Помните, когда вычисления были продуктом, мы строили архитектурные методы на характеристиках этого продукта. Взять, например, высокое среднее время восстановления (MTTR). Мы увеличивали масштаб, планировали емкость, продумывали аварийное восстановление и все в таком духе.
А потом вычисления стали коммунальной услугой, среднее время восстановления сократилось, и мы создали новые методы: распределенные системы, страховка от сбоев, хаос-инжиниринг, непрерывный деплой. Со временем это стало называться DevOps. Вычисления как продукт устарели.
Теперь с бессерверной архитектурой нас ждут новые перемены, и пережитком прошлого станет уже DevOps. И про них начнут забывать.
Некоторые еще даже толком не успели перейти на DevOps.
Да, есть такие, кто только начинает свою пятилетку перехода на DevOps. В итоге они туда доберутся, а там уже никого. Обидно.
Как будет выглядеть разработка программного обеспечения лет через десять?
Мы пока даже не знаем, какие методы вырастут на бессерверной архитектуре. Точно не скажу, но пара догадок есть.
Разработчики озаботятся финансовыми вопросами. Стоимость функции будет важна как никогда. Появятся новые модели разработки с учетом ценности: одна компания построит для другой систему, но не по фиксированной цене, а за часть прибыли с этой системы.
Конечно, для этого компании сами должны понимать, какую прибыль приносит система.
Структура компании тоже изменится. Это обычное дело. Электричество превратилось из продукта в коммунальную услугу, и появилось множество систем более высокого порядка. То же было с производством, когда появился фордизм и американская система.
Когда такое происходит, появляются новые методы, и форма организации меняется. Думаю, с бессерверной архитектурой будет так же.
То есть, по-твоему, в разработке ПО будет меньше потерь и выше КПД?
Давай определимся с терминами. Не надо путать потери с расходам. Это разные вещи.
Мы увидим высокий КПД и быстрое развитие систем более высокого порядка. Что до расходов на ИТ, так говорили про EC2 еще в 2007–2008. И здравствуй парадокс Джевонса.
По факту получается, что чем эффективнее штука, тем больше нам ее надо. Люди думают, что сэкономят кучу денег с бессерверными вычислениями. Придется закатать губу. Мы просто будем брать больше.
И последний вопрос: что бы ты сказал человеку, который не может выбрать между бессерверной архитектурой и контейнерами?
[смеется] А он мне друг или как?
По-моему, у нас больше общего, чем разногласий. Меня больше волнуют сроки. Война разгорается на бессерверном поле боя. И вся риторика должна быть там же. Прерывистое равновесие — оно такое: думаешь, еще сто лет ждать, потом смотришь — приплыли. — Саймон Уордли
Допустим, друг.
Ну тогда пусть выбирает, что хочет, если проект краткосрочный. Я не против контейнеров.
Но если проект долгий, лучше не пожалеть времени и освоить бессерверные вычисления. За ними будущее.
Комментарии (11)

imanushin
27.02.2019 21:10+3Красивые утверждения, однако в основном — бездоказательные.
Например:
В частном секторе я видел банки с тысячей одинаковых систем управления рисками. А сколько их по всему миру? Миллионы и десятки миллионов одних и тех же систем.
Банков не миллионы, хотя преувеличение красивое. И не все банки пишут сами, можно просто заказать сервис от Блумберга. Более того, рисковые системы разные из-за оптимизации моделей. Приведу пример на пальцах:
- Государство просит застраховать все риски. И предлагает самый простой алгоритм: сумма резервного капитала — это сумма рисков по всем продуктам (ну точнее сумма страховки по каждому риску, по модулю, конечно).
- У банка могут быть разнонаправленные продукты. Например, банк может иметь и долг, и вклад в другом банке (например, если разные отделения нашего банка заключили такие сделки).
- В этом случае логичнее объединить продукты, а уже потом страховать.
- Однако кроме вкладов есть более сложные вещи, которые не описать сходу одним предложением.
- В итоге банк математически может доказать аудиторам, что реальный риск меньше (из-за корреляций в продуктах). И резервный капитал можно держать меньший.
- Получается, что в зависимости от услуг банка, реальная рисковая модель будет разной
- И как вишенка на торте: модель от Блумберга зачастую обходится дороже, чем самостоятельно разработанная. И, конечно, не даст конкурентного преимущества.
Далее, разные банки работают с разными клиентами:
- Разные страны
- Разные отрасли бизнеса
- Разный объём сделок по каждому клиенту
Получаем, что сейчас банкам просто дешевле держать дорогих докторов математических наук и штат разработчиков, чем пользоваться универсальным решением.
Или, чтобы подытожить: идея объединить IT системы банков очень похожа на идею «а зачем нам столько автопроизводителей? Давайте оставим один VW, чтобы не дублировать сущности». Ну или «а зачем столько кандидатов в президенты? Давайте оставим одного и ...»

bm13kk
27.02.2019 21:291 Я не могу понять откуда взялось противопоставление безсерверной и девопс архитектуре. Судя по документации лямбды — она сама работает на контейнерах.
2 Я согласен с тезисом что почти любая фича Х написана сотни (а иногда миллионы) раз в разных проектах. Однако проблема в том, что современное программирование больше занимается интеграцией этой фичи Х в свой конкретный проект сейчас. Чем, собственно, разрабатывает фичу Х. Тем более разрабатывает Х для других, те легкой интеграции с еще не известно с чем.
maxzh83
27.02.2019 21:44Судя по документации лямбды — она сама работает на контейнерах
Ага, а контейнеры — на серверах, такая вот бессерверная технология…
keydon2
27.02.2019 21:31+2Я параноик и не доверю свои вычисления.
Мне мб проще(и дешевле) своё облако один раз построить чем отдавать амазону или бессерверной архитектуре. Оставьте это стартапам, которым нечего терять и нет смысла планировать.CloudComputing
28.02.2019 21:02Стартап стартапу рознь. Убер — тоже стартап.
Компании должны концентрироваться на основном бизнесе, а не создавать свои облака.
Банки и другие игроки как финтех, так и классического сектора либо переходят в облака, либо смотрят в сторону перехода. AWS создал даже отдельный раздел для Financial Services Competency: aws.amazon.com/ru/blogs/apn/introducing-the-aws-financial-services-competency
immaculate
28.02.2019 02:52+1Из того, что облака стали успешными, а за облаками — контейнеры, можно сделать вывод, что лямбду тоже ждет успех. Ой, подождите, это какая-то альтернативная логика…
И вообще, вода на воде, много трескучих слов без какой-либо конкретики. Я не увидел ни единого строгого доказательства в данной статье, чем лямбды лучше любого другого подхода.

fzn7
28.02.2019 10:54Если они сделают распределенный дебаггер, то в принципе пофиг как и чем и где оно будет исполняться

DikSoft
02.03.2019 09:24Фанатизм, он такой. Накидать красивых лозунгов и «не заметить» того, что им, скажем так, противоречит. Или не укладывается в картинку.
Автор статьи, может и «хороший» фанатик, но отсутствие критичности в восприятии мира никогда до добра не доводило. (
amarao
Это пишут в 2019 году. Через год после spectre. Который с нами навсегда. От которого единственная реальная защита — не шарить CPU между доменами доверия, aka baremetal.
Окай… Разумеется, «контейнер как средство деплоя» уродливое решение. Разумеется, faas звучит как сказка, если не забывать о том, что рядом с вами работает faas того, кто хочет получить juicy data из вашей функции.
Алсо, faas предполагает database as a service. Чужой. А это уже больно и совсем не факт, что будущее.