
 Не так давно Google зарелизил Cloud Firestore. Cloud Firestore — это облачная NoSQL база данных, которую Google позиционирует как замену Realtime Database. В этой статье я хочу рассказать как начать ей пользоваться.
Не так давно Google зарелизил Cloud Firestore. Cloud Firestore — это облачная NoSQL база данных, которую Google позиционирует как замену Realtime Database. В этой статье я хочу рассказать как начать ей пользоваться.
Возможности
Cloud Firestore позволяет хранить данные на удаленном сервере, легко получать к ним доступ и следить за изменениями в режиме реального времени. В документации есть отличное сравнение Cloud Firestore и Realtime Database.
Создание и подключение к проекту
В консоли Firebase выбираем Database и нажимаем на Create database. Дальше выбираем настройки доступа. Для ознакомления нам будет достаточно тестового режима, но на проде лучше подойти к этому вопросу серьезнее. Подробнее про режимы доступа можно почитать здесь.
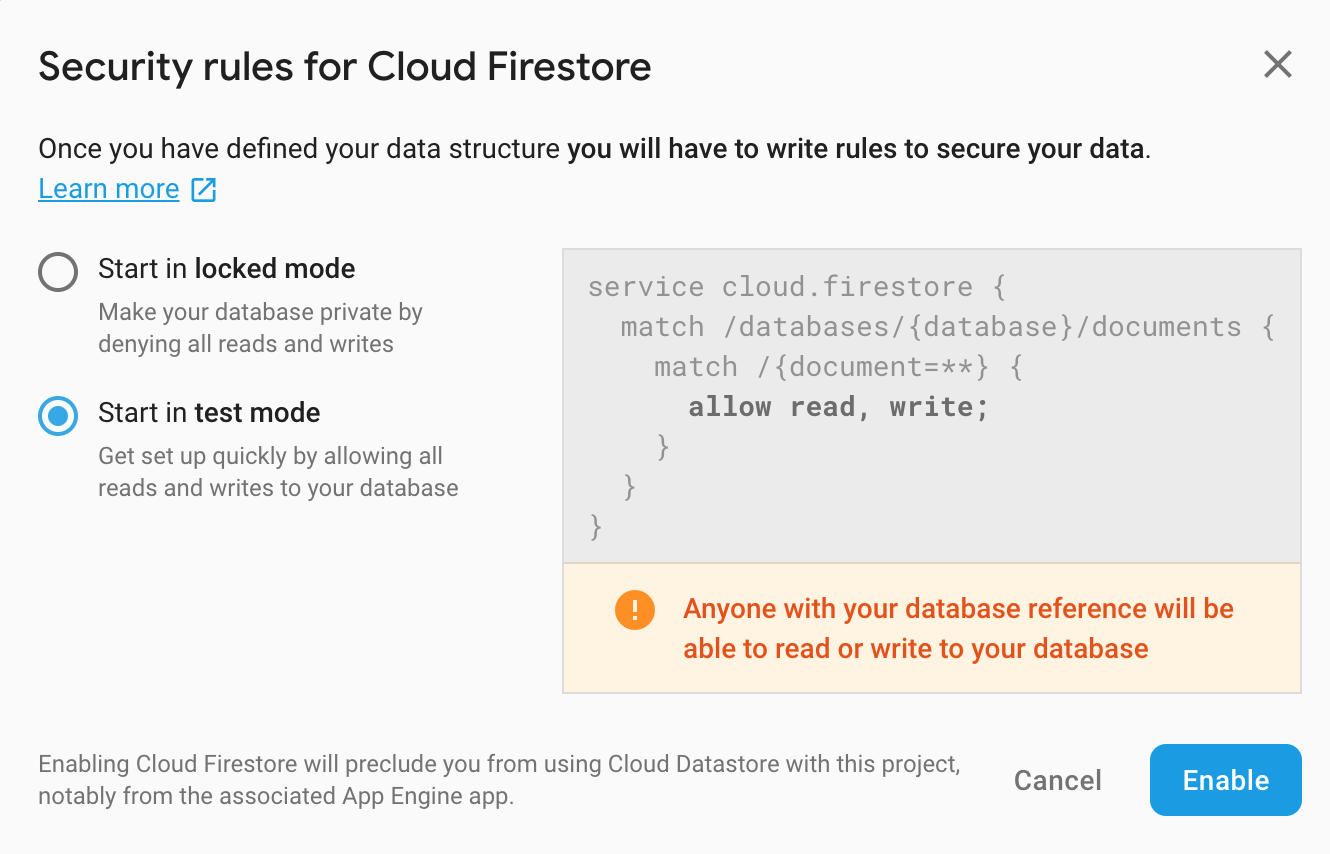
Для настройки проекта проделываем следующие шаги:
- Добавить Firebase к проекту по инструкции от сюда
- Добавить зависимость в app/build.gradle
implementation 'com.google.firebase:firebase-firestore:18.1.0'
Теперь все готово.
Для ознакомления с базовыми приемами работы с Cloud Firestore я написал простенькое приложение. Для его работы необходимо создать проект в консоли Firebase и добавить файлик google-services.json в проект в Android Studio.
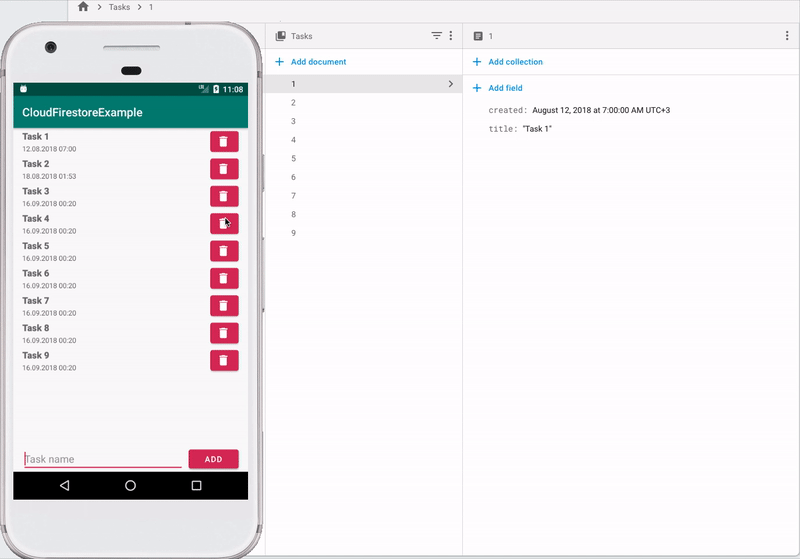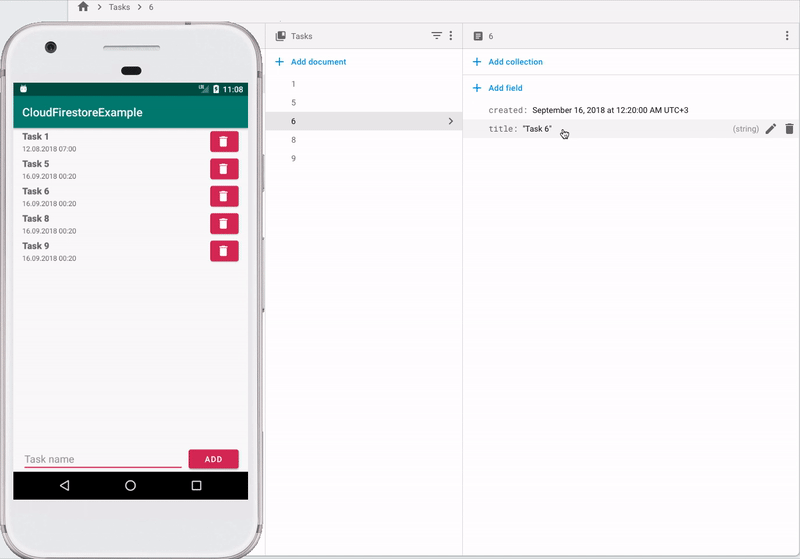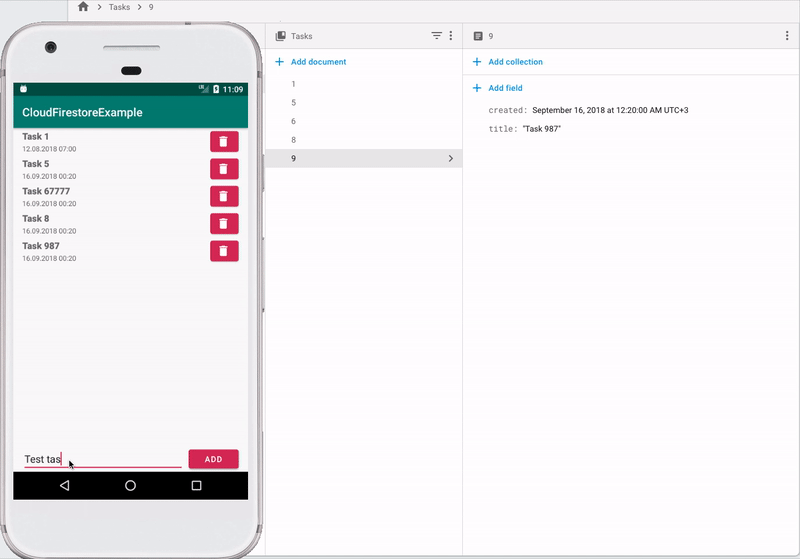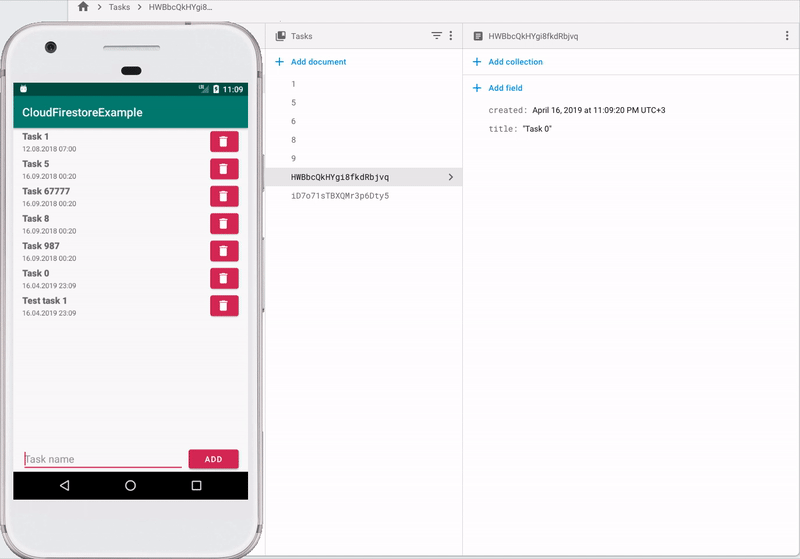
Структура хранения данных
В Firestore для хранения данных используются коллекции и документы. Документ — это запись, которая содержит какие-либо поля. Документы объединяются в коллекции. Также документ может содержать вложенные коллекции, но на андроиде это не поддерживается. Если проводить аналогию с SQL-базой, то коллекция — это таблица, а документ — это запись в этой таблице. Одна коллекция может содержать документы с разным набором полей.
Получение и запись данных
Для того чтобы получить все документы какой-либо коллекции достаточно следующего кода
remoteDB.collection(“Tasks”)
.get()
.addOnSuccessListener { querySnapshot ->
// Успешно получили данные. Список в querySnapshot.documents
}
.addOnFailureListener { exception ->
// Произошла ошибка при получении данных
}
}Здесь мы запрашиваем все документы из коллекции Tasks.
Библиотека позволяет формировать запросы с параметрами. Следующий код показывает как получить документы из коллекции по условию
remoteDB.collection(“Tasks”)
.whereEqualTo("title", "Task1")
.get()
.addOnSuccessListener { querySnapshot ->
// Успешно получили данные. Список в querySnapshot.documents
}
.addOnFailureListener { exception ->
// Произошла ошибка при получении данных
}
}Здесь мы запрашиваем все документы из коллекции Tasks, у которых поле title соответсвует значению Task1.
При получении документов, их можно сразу конвертировать в наши data-классы
remoteDB.collection(“Tasks”)
.get()
.addOnSuccessListener { querySnapshot ->
// Успешно получили данные. Список в querySnapshot.documents
val taskList: List<RemoteTask> = querySnapshot.toObjects(RemoteTask::class.java)
}
.addOnFailureListener { exception ->
// Произошла ошибка при получении данных
}
}Для записи необходимо сформировать Hashmap с данными (где в качестве ключа выступает название поля, а в качестве значения — значение этого поля) и передать библиотеке. Следующий код это демонстрирует
val taskData = HashMap<String, Any>()
taskData["title"] = task.title
taskData["created"] = Timestamp(task.created.time / 1000, 0)
remoteDB.collection("Tasks")
.add(taskData)
.addOnSuccessListener {
// Успешная запись
}
.addOnFailureListener {
// Произошла ошибка при записи
}В данном примере будет создан новый документ и Firestore сгенерирует ему id. Чтобы задать собственный id необходимо сделать следующее
val taskData = HashMap<String, Any>()
taskData["title"] = task.title
taskData["created"] = Timestamp(task.created.time / 1000, 0)
remoteDB.collection("Tasks")
.document("New task")
.set(taskData)
.addOnSuccessListener {
// Успешная запись
}
.addOnFailureListener {
// Произошла ошибка при записи
}В этом случае если нет документа с id равном New task, то он будет создан, а если есть, то указанные поля будут обновлены.
Еще один вариант создания/обновления документа
remoteDB.collection("Tasks")
.document("New task")
.set(mapToRemoteTask(task))
.addOnSuccessListener {
// Успешная запись
}
.addOnFailureListener {
// Произошла ошибка при записи
}Подписываемся на изменения
Firestore позволяет подписаться на изменения данных. Подписаться можно как на изменения коллекции, так и на изменения конкретного документа
remoteDB.collection("Tasks")
.addSnapshotListener { querySnapshot, error ->
// querySnapshot - список изменений
// error - ошибка
}querySnapshot.documents — содержит обновленный список всех документов
querySnapshot.documentChanges — содержит список изменений. Каждый объект содержит измененный документ и тип изменения. Возможны 3 типа изменений
ADDED — документ добавлен,
MODIFIED — документ изменен,
REMOVED — документ удален
Загрузка большого количества данных
Realtime Database предоставляет более менее удобный механизм загрузки большого количества данных, который заключается в ручном редактировании json-файла и его загрузки. Firestore из коробки ничего такого не предоставляет. Было очень неудобно добавлять новые документы, пока я не нашел способ как можно легко загрузить большой объем информации. Чтобы у вас не было таких проблем как у меня, ниже приложу инструкцию как быстро и легко загрузить большой объем данных. Инструкция была найдена на просторах интернета.
- Установить Node.js и npm
- Установить пакет firebase-admin выполнив команду
npm install firebase-admin --save - Сформировать json-файл с данными коллекции. Пример можно посмотреть в файле Tasks.json
- Для загрузки нам понадобиться ключ доступа. Как его получить хорошо описано в этой статье
- В файле export.js проставить свои данные
require('./firestore_key.json') — файл с ключом доступа. У меня лежал в папке со скриптом
<YOU_DATABASE> — название вашей firestore-базы
"./json/Tasks.json" — путь до файла в котором лежат данные
['created'] — список имен полей с типом Timestamp - Выполнить скрипт
node export.js
В скрипте используются наработки dalenguyen
Заключение
Cloud Firestore я использовал в одном из своих проектов и не испытал никаких серьезных проблем. Одна из моих коллекций содержит около 15000 документов и запросы по ней проходят довольно быстро и это без использования индексов. Используя Cloud Firestore совместно с Room и Remote Config можно существенно сократить количество обращений к базе и не выходить за бесплатные лимиты. На бесплатном тарифе в день можно прочитать 50000 документов, записать 20000 и 20000 удалить.
Комментарии (8)

Carduelis
17.04.2019 10:30Статья затрагивает довольно простой пласт документации. Было бы здорово, если бы вы выпустили вторую часть статью про счетчики. Они всегда были головной болью что SQL, что NoSQL.
Но в Firestore появился недавноFieldValue.increment(). А также не забудьте рассказать и про шардирование. Оно, конечно, в рамках to-do приложения как собаке пятая нога, но если вдруг ваша тудушка станет популярно-залайканной, без него никак.
LAVElek Автор
17.04.2019 11:04Статья и планировалась такой, чтобы дать вводную информацию. Если расписывать все возможности, то она бы получилась довольно большой. Видимо и правда нужно будет написать еще статью с более детальным разбором некоторых моментов. А так в большинстве случаев шардирование сразу и не нужно.
androidovshchik
На мой взгляд, firestore больше подходит для постоянного хранения данных, тогда как realtime бд для временных (или не совсем важных), которые требуют быстрой синхронизации, хотя спорно, если это чат. Было бы интресно узнать о подводных камнях или что под капотом кэша этих технологий. Например, спотыкаюсь постоянно, что закэшированные данные не вызывают ошибку загрузки, когда это необходимо (да, можно задать source server у документа, но этого нет у коллекции). У realtime бд аналогичные есть проблемы, пока я с этим разбираюсь. Кэш — вещь нужная, потому что мне никто не будет платить, если я по своей воли буду добавлять в проект Room или IndexedDB для экономии ресурсов, в ТЗ вы это наврятли когда-н. увидите отдельным пунктом. Надо разбираться как правильно работать с тем, что идет из коробки. А так статья совсем для новичков
Carduelis
Я не думаю, что firestore вынуждает вас не использовать кеш. Иначе бы система кеширования не шла бы из коробки.
Единственное, насколько я слышал, клиентский кеш firestore слабоуправляемый, и больше похож на то, как сам браузер кеширует данные.
И дополнительный слой кеша никто не запрещает реализовывать. Только вот проблема в том, что на практике, проще заплатить за лишние 1кк запросов в день, чем писать впопыхах кеширующий слой.
нет, для холодной хранилки уж лучше пользоваться Storage API и хранить снапшотами.
Firestore — это realtime database 2.0. И обе вполне подходят для realtime-приложений — вроде чата со счетчиком лайков. Просто Firestore удобнее и более гибкая. Ни разу не жалею, что пересел с лица Realtime database на Firestore одобрение.
androidovshchik
Тогда существенная разница только в том, что у realtime ограничение по одновременному подключению, а у firestore это счетчик чтения/записи документов. Ну и по структуре: в realtime данные следует представлять в mapping структуре, когда у firestore это априори массив, не считая данные документа, который ограничен по размеру. Кэш везде слабоуправляемый
LAVElek Автор
Не встречал в документации информации об ограничении кол-ва полей в документе. В своем проекте я от встроенного кеша отказался сразу.
androidovshchik
Не количество полей, а размер документа. Это, по-моему, 1 Мб